💡 전 안드로이드 개발자는 아니기 때문에 틀리거나, 이상한 컨벤션을 따르는 코드가 많을 수 있습니다.
1. Introduction
📌 Purpose
모든 코드는 깃헙에서 확인 가능합니다.
SpeechRecognizer 썼다가 된통 당하고 AudioRecord로 넘어왔다.
그런데 그냥 SpeechRecognizer 구현체에 SDK 쑤셔넣고, 원하는대로 동작하도록 개조하는 게 편하지 않았을까 싶다.
다만 이렇게 하려니, STT API 변경할 때마다 Android, iOS 둘 다 반영해줘야 하는 게 번거롭기도 하고, 앱 업데이트 강제할 거 아니면 레거시 자원도 계속 유지해줘야 하고,
심지어 CLOVA STT API(CSR인가 뭔가 하는 거)는 최대 60초까지 밖에 지원을 안 한다.
FAQ에서 60초 이상도 가능하도록 개발 중이라고는 하는데, 돈 되는 사업이 아닌 이상 빨리 런칭되길 기원하긴 어려울 듯.
그럼 추후 상황에 따라 60초 이상도 지원 가능한 CLOVA AI를 쓰거나, Google Cloud STT를 사용하도록 유연한 변경이 필요한데, 아무래도 역시 SpeechRecognizer는 후보 순위에 올라가긴 어려웠다.
아, 물론 내가 그냥 앱 개발에 무지해서 그럴 수도 있음을 감안하고 있긴 한데, 런칭이 최우선 목표라 내 분야도 아닌 앱 개발에 이 이상 몰두할 수는 없는데 어떡하나...
여튼 이런 이유로 AudioRecord를 사용해서 음성을 메모리에 적재(어차피 녹음 허용이 최대 4~5분까지 예상 중이라 문제는 없을 거 같다)하고, 서버로 byte 배열을 전달하는 게 목적이다.
왜 file 안 만드냐면, I/O 장치에 태스크 돌아가는 것도 자원 아깝고, 저장 후엔 바로 삭제해야 하는데 이거 실패해서 앱 크기 불어났을 때 이슈 핸들링하는 것도 귀찮기 때문이다.
⚠️ 현재 코드는 완벽하지 않습니다.
안 그래도 익숙치 않은 언어와 프레임워크로 무장을 해버리는 상황에서, 앱과 서버 모두 개발하다보니 디테일 측면에서 상당히 퀄리티가 떨어집니다.
OkHTTP 커넥션 해제나 응답 수신 후 적절한 상태 변경 등 미흡한 부분이 많으나, 여기선 오로지 AudioRecord가 성공적으로 동작하는 것만을 보장합니다.
2. Design
📌 Rough

목표는 심플하다.
- 사용자가 녹음 버튼을 누르면, 타이머가 60초 동작하면서 녹음을 시작한다.
- Audio 접근 권한이 없다면, 사용자에게 요청한 후 재수행
- 사용자가 녹음 중지 버튼을 누르거나, 60초가 지나면 자동으로 녹음 중단.
- 녹음은 PCM 형태에서 WAV 형태로 감싼 후, 추가 작업(ex: 서버 요청, 로컬 파일 저장 등) 수행
이를 위해, 클래스를 크게 4가지로 나누었다.
- VoiceRecordViewModel: UI 상태 반영을 위한 클래스
- AudioRecorder: 녹음 버퍼를 메모리에 누적하기 위한 코루틴 상태 관리 클래스
- RecordingTimer: 녹음 시간
- WavUtil: PCM을 WAV 파일로 변환하기 위한 유틸 클래스
자바였다면 처음부터 클래스 나누고 시작했겠지만, 난 아직 코틀린이랑 친해지고 있는 단계라 무리해서 일을 벌리고 싶진 않았다.
그래서 VoiceRecordViewModel에 모든 코드를 몽땅 때려놓고 모든 작업이 끝난 후에 분리를 해놓은 터라, 구조가 좀 이상하게 보일 수도 있다.
그리고 AudioRecorder와 RecordingTimer를 분리해놨더니, 일이 좀 귀찮아져서 괜히 분리했나 싶기도 했다..개인 취향껏 고치면 될 듯.
3. AudioRecord
📌 Document
AudioRecord | API reference | Android Developers
developer.android.com
처음 봤을 때, 난해하기 짝이 없는 녀석이었다.
이 API를 다루려면 아래 항목을 이해해야 한다.
- 생성자 파라미터: record sample rate, audio source 등 여러 인자들
- 상수 정보: getState과 getRecordingState가 반환하는 정보
- 버퍼 관리
저것들이 가장 어렵고, 나머진 그냥 시작, 종료 함수 뭐 이런 거라 그닥.
📌 AudioRecordBuilder
AudioRecord.Builder | API reference | Android Developers
developer.android.com
AudioRecord 객체를 생성자로 만들어도 되긴 하는데, Builder를 통해서 만들어도 된다.
Builder가 있는데 굳이 생성자로 만들 이유가 없어서 Builder로 객체를 생성했다.
참고로 Builder를 쓰려면, 반드시 RECORD_AUDIO 권한을 검증하는 로직이 선행되어야 한다.
검증하고 객체 생성 메서드를 불러도 안 되고, 그냥 무조건 객체 생성 메서드 스택 내에 권한 검증이 수행되어야 하는 거 같다. (안 그러면 컴파일 에러가 없어지질 않는다.)
if (ContextCompat.checkSelfPermission(context, Manifest.permission.RECORD_AUDIO) != PackageManager.PERMISSION_GRANTED) {
...
}뭐 이런 거 있지 않은가?
나같은 서버 개발자는 앱 개발 관련해선 설명에 한계가 있다.
공식 문서에 의하면 뭐가 이것저것 많은데, setContext랑 setPrivacySensitive는 어차피 API 버전이 안 맞아서 적용이 불가능했다.
audioRecord = AudioRecord.Builder()
.setAudioSource(RECORDER_AUDIO_SOURCE)
.setAudioFormat(
AudioFormat.Builder()
.setEncoding(RECORDER_AUDIO_ENCODING)
.setSampleRate(sampleRate)
.setChannelMask(RECORDER_CHANNELS)
.build()
)
.setBufferSizeInBytes(minBufferSize)
.build()공식 문서의 예제랑 비교해보면, 얼추 이런 식으로 구현하라는 말 같은데...
저 상수들은 대체 어떻게 정해야 하나 싶을 것이다.
(아무 값이나 때려넣지는 말자.)
1️⃣ Audio Source
- 오디오의 입력 타입을 의미
- AudioSource에 정의된 주요 상수들
- DEFAULT: 기본 오디오 소스
- MIC: 기본 마이크
- VOICE_RECOGNITION: 음성 인식을 위해 조정된 마이크
- VOICE_COMMUNICATION: VoIP와 같은 통신 앱에 적합한 소스
난 사용자 음성을 받고 싶은 것이므로, 당연히 VOICE_RECOGNITION을 선택했다.
확실히 주위에 음악 깔아놓고 녹음해봤는데, 내 음성만 인식해서 들리는 것 같긴 하다.
물론, MIC로 테스트해본 건 아니니 나의 믿음일 뿐이다.
2️⃣ Encoding
- 오디오 샘플이 저장될 포맷
- Encoding 주요 상수들
- ENCODING_PCM_8BIT
- ENCODING_PCM_16BIT
- ENCODING_PCM_FLOAT
✒️ PCM(Pulse Code Modulation)
PCM은 아날로그 오디오 신호를 디지털 형식으로 변환하는 표준 방법이다.
원본 신호를 일정 간격으로 샘플링하면서 각 샘플의 진폭을 수치로 표현한다.
이걸 이해했다면, 8bit, 16bit, float이 순서대로 audio의 품질이 좋아질 것이라는 것도 눈치챘을 것이다.
진폭의 범위가 2^8, 2^16, 32-bit IEEE 부동소수점 형식을 가지니 당연하다.
다만, 그만큼 큰 저장 공간을 요구하게 되므로 trade-off가 필요하며, 안드로이드 버전에 따라 지원을 안 할 수도 있다.
내 서비스가 고품질의 음성 녹음 지원을 해야하는 게 아니라면 PCM_16BIT로 충분하고, 만족스럽지 않으면 추후 float으로 바꾸는 것도 하나의 방법이 될 수 있다.
3️⃣ Sample Rate
- 초당 오디오 샘플 수를 Hz 단위로 표현한 것
- 아날로그 오디오 신호를 디지털로 변환할 때, 얼마나 자주 sample을 취할 것인지 결정한다.
- 일반적으로 8000, 16000, 22050, 44100, 48100을 사용하며, HW가 해당 sample rate를 지원해야 사용할 수 있다.
- (공식 문서에 따르면) 44100Hz는 현재 모든 장치에서 작동이 보장되어있다고 한다.
이걸 어떻게 검증하는 지는 ChannelMask까지 하고, 마지막 BufferSizeInBytes할 때 확인해보자. (왜냐면 BufferSizeInBytes 계산하기 위한 API 사용할 때, 예외 정보를 통해 확인이 가능하기 때문)
val sampleRateCandidates = intArrayOf(44100, 22050, 11025, 16000)
for (sampleRate in sampleRateCandidates) {
// 대입해보고 가능한 sampleRate 적용
}sampleRate를 44100으로 고정시키고 진행해도 되지만, 나는 위와 같이 적용했다.
왜냐하면 44100Hz는 모든 장치에서 작동을 보장한다는 내용을 방금 처음 알았기 때문이다.
후회하고 있다.
4️⃣ ChannelMask
- 캡처하려는 오디오 채널 구성을 정의한다.
- ChannelMask 주요 상수
- CHANNEL_IN_MONO: 단일 채널 오디오
- CHANNEL_IN_STEREO: 스테레오 (두 채널) 오디오
오디오 처리에서 채널(channel)이란 결국 소리가 녹음되거나 재생되는 독립적 오디오 경로를 의미한다.
여기서 STEREO를 선택하면, 두 개의 채널(좌/우)로 오디오가 녹음되므로 공간감 있는 오디오가 제공되긴 한다.
하지만 그 말은 즉, PCM 데이터가 좌/우 샘플 번갈아 저장되므로 처리가 더 까다롭다.
내가 제공할 서비스는 ASMR 플랫폼을 운영할 것도 아니니 MONO면 충분하다.
5️⃣ BufferSizeInBytes
- 오디오 HW에서 데이터를 읽을 때 사용할 버퍼의 크기를 bytes 단위로 지정하는 것
- AudioRecord.getMinBufferSize()가 반환하는 값보다 크거나 같아야 한다.
- 버퍼는 말 그대로 녹음된 오디오 데이터를 임시로 저장하는 메모리 크기
- 너무 작으면 오버런이 발생할 수 있고, 너무 크면 지연 시간이 길어진다.
- 최대 녹음 시간이 60초일 때, 사람이 60초 이내에 발화할 수 있는 최대 바이트 수를 계산하고 버퍼를 할당하기라도 할 게 아니라면, 지속적으로 버퍼를 다른 곳에 옮겨 저장하고 비워주는 메커니즘을 구현한다고 보는 게 이롭다.
참고로 이 값은 공식 문서에도 나와있듯이 AudioRecord.getMinBufferSize()라는 정적 메서드가 존재한다.
public static int getMinBufferSize (int sampleRateInHz,
int channelConfig,
int audioFormat)그런데 파라미터를 보면 이미 위에서 결정한 값들 뿐이다.
즉, getMinBufferSize()는 해당 값들을 기반으로 AudioRecord 객체를 성공적으로 생성하는데 필요한 최소 버퍼 크기를 bytes 단위로 반환해준다.
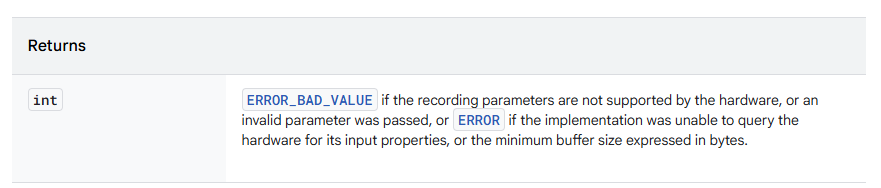
그리고 반환 값이 AudioRecord.ERROR_BAD_VALUE와 동일하다면, HW가 지원하지 않는 사양으로 값을 설정한 것이므로 조정이 필요함을 의미한다.
📌 getState()
공식 문서를 보면 getState()가 있고, getRecordingState()가 있는데 둘의 차이는 이렇다.
- getState(): AudioRecord 객체가 올바르게 생성되었는가?
- getRecordingState(): AudioRecord 객체가 녹음 중인가?
이 말은 즉슨, AudioRecord 객체 생성 후 startRecording()를 호출하기 전에 audioRecord.getState()로 정상 초기화 여부를 검증할 필요가 있다는 것이다.
아래는 예시.
if (audioRecord.state == AudioRecord.STATE_INITIALIZED) {
log.info { "AudioRecord initialized with sample rate: $sampleRate, buffer size: $minBufferSize" }
return audioRecord
} else {
audioRecord.release() // null은 아니면서 상태는 오류이므로, release() 호출해서 GC가 수거하도록 만듦
}
📌 Implementation
위 내용을 모두 종합하면 AudioRecord 생성 로직은 다음과 같다.
private val log = KotlinLogging.logger {}
/**
* 오디오 녹음을 담당하는 클래스
*/
class AudioRecorder(
private val context: Context,
private val coroutineScope: CoroutineScope
) {
companion object {
const val RECORDER_AUDIO_SOURCE = AudioSource.VOICE_RECOGNITION
const val RECORDER_CHANNELS = AudioFormat.CHANNEL_IN_MONO
const val RECORDER_AUDIO_ENCODING = AudioFormat.ENCODING_PCM_16BIT
}
private var audioRecord: AudioRecord? = null
// sample rate는 wav 파일 변환할 때 필요, bufferSizeInBytes는 버퍼 관리하는 코루틴에서 필요
private var recordSampleRate = 0
private var bufferSizeInBytes = 0
/**
* 오디오 녹음 시작
* @return 성공 여부
*/
fun startRecording(): Boolean {
audioRecord = createCompatibleAudioRecord() ?: run {
log.error { "AudioRecord is not initialized" }
return false
}
audioRecord!!.startRecording() // 녹음 시작 메서드
return true
}
/**
* 사용 가능한 오디오 레코드 생성을 시도합니다.
* 여러 샘플링 레이트를 시도하여 가장 먼저 초기화에 성공한 AudioRecord를 반환합니다.
*
* @return 초기화에 성공한 AudioRecord 인스턴스 또는 null (권한 없음 포함)
*/
private fun createCompatibleAudioRecord(): AudioRecord? {
// Builder로 만드는 경우엔 권한 검사 스탭 없으면 컴파일 에러
if (ContextCompat.checkSelfPermission(context, Manifest.permission.RECORD_AUDIO)
!= PackageManager.PERMISSION_GRANTED
) {
log.info { "No audio permission" }
return null
}
var audioRecord: AudioRecord?
val sampleRateCandidates = intArrayOf(44100, 22050, 11025, 16000)
for (sampleRate in sampleRateCandidates) { // 이럴 필요 없이 그냥 44100 상수 넣어도 됨..
val minBufferSize = AudioRecord.getMinBufferSize(
sampleRate,
RECORDER_CHANNELS,
RECORDER_AUDIO_ENCODING
)
if (minBufferSize == AudioRecord.ERROR_BAD_VALUE) { // 버퍼 설정이 기기에서 미지원하는 경우
log.error { "Invalid parameter for AudioRecord for sample rate $sampleRate" }
continue
}
audioRecord = AudioRecord.Builder()
.setAudioSource(RECORDER_AUDIO_SOURCE)
.setAudioFormat(
AudioFormat.Builder()
.setEncoding(RECORDER_AUDIO_ENCODING)
.setSampleRate(sampleRate)
.setChannelMask(RECORDER_CHANNELS)
.build()
)
.setBufferSizeInBytes(minBufferSize)
.build()
if (audioRecord.state == AudioRecord.STATE_INITIALIZED) {
log.info { "AudioRecord initialized with sample rate: $sampleRate, buffer size: $minBufferSize" }
recordSampleRate = sampleRate
bufferSizeInBytes = minBufferSize
return audioRecord
} else {
audioRecord.release()
}
}
log.error { "Failed to initialize AudioRecord with any sample rate" }
return null
}
}코드 이렇게 올려놓는 거 별로 안 좋아하는데, 내 github은 더 난장판이라 올려두었다.
참고로 내 프로젝트를 보면 AudioRouting.OnRoutingChangedListener() 이런 것도 사용 중인데, 이건 도중에 오디오 기기 변경(ex: 마이크 쓰다가 무선 이어폰 연결)에 대응하는 로직에 필요한 것 같았다.
테스트가 워낙 어렵다 보니, 일단 로그만 남겨두고 아무런 작업도 하지 않고 있다.
4. Move Recording Buffer to Memory
📌 Buffer
난 이게 제일 어려웠다.
우선 AudioRecord 객체의 버퍼에 쌓인 사용자 음성은 read() 메서드를 통해 가져올 수 있다.
현재 블로그 글을 작성하고 있던 때만 해도 가장 마지막 방식을 택했었다.
public int read (byte[] audioData, int offsetInBytes, int sizeInBytes)이유는 그냥 뭐..가장 직관적이고 쓰기 편했기 때문이었다.
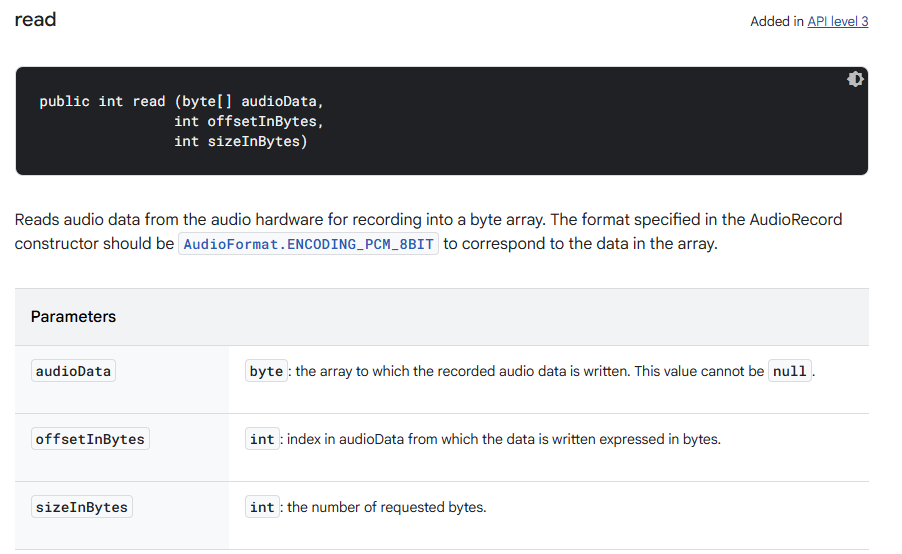
그런데 공식 문서를 보면, 이건 ENCODING_PCM_8BIT 용이었다. ㅠㅠㅠㅠㅠ
나는 16bit이므로, 아래 둘 중 하나로 바꿔야만 했다.
public int read (short[] audioData, int offsetInShorts, int sizeInShorts, int readMode)
public int read (short[] audioData, int offsetInShorts, int sizeInShorts)
여튼 이렇게 하면 audioRecord의 buffer에 담긴 정보를 audioData 배열로 옮겨올 수가 있는데, 처음에는 녹음이 다 끝나고 한 번에 가져올 수 있는 건가 싶어서 stopAudioRecord()에서 한 번에 가져오려고 시도했었다.
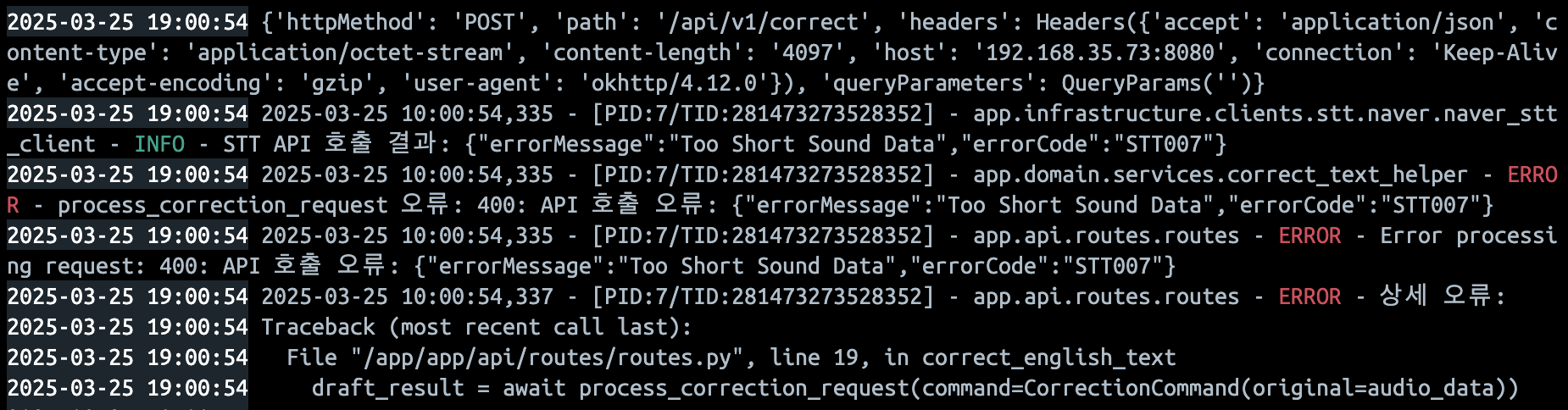
그런데 음성 길이가 400ms 이하여야 나는 Too Short Sound Data 에러가 계속해서 발생했고, 뭔가 문제가 있는 거 같아서 read 메서드로 읽은 audioData의 volume을 측정해보니 0.0으로 나오고 있었다.
애초에 buffer는 임시 메모리 할당 영역을 의미하는 well-known 용어이므로, 내가 처음 예상한 대로 동작하지 않을 것이란 건 쉽게 짐작할 수 있었다.
다만 구현이 귀찮아서 현실을 부정하고 싶었을 뿐..
📌 RecordingJob
지금부터 구현해야 할 것은 [MIC HW → Android Audio System → AudioRecord Buffer]를 통해 누적된 bytes를 주기적으로 읽어들인 후, 클래스 멤버 변수로 할당된 메모리로 옮겨오는 것이다.
/**
* 오디오 녹음을 담당하는 클래스
*/
class AudioRecorder(
private val context: Context,
private val coroutineScope: CoroutineScope
) {
private var audioRecord: AudioRecord? = null
private var recordingJob: Job? = null
private var isRecording = AtomicBoolean(false)
private var bufferSizeInBytes = 0
private lateinit var audioData: ByteArrayOutputStream
/**
* 오디오 녹음 시작
* @return 성공 여부
*/
fun startRecording(): Boolean {
audioRecord = createCompatibleAudioRecord() ?: run {
log.error { "AudioRecord is not initialized" }
return false
}
startRecordingCoroutine() // 버퍼를 주기적으로 비우기 위한 코루틴 실행
audioRecord!!.startRecording()
return true
}
/**
* 오디오 녹음 코루틴을 시작합니다.
*/
private fun startRecordingCoroutine() {
audioData = ByteArrayOutputStream()
isRecording.set(true)
recordingJob = coroutineScope.launch(Dispatchers.IO) {
val shortBuffer = ShortArray(bufferSizeInBytes / 2)
while (isRecording.get() && audioRecord?.recordingState == AudioRecord.RECORDSTATE_RECORDING) {
val shortsRead = audioRecord?.read(shortBuffer, 0, shortBuffer.size, AudioRecord.READ_BLOCKING) ?: 0
if (shortsRead > 0) {
collectAudioData(shortBuffer, shortsRead)
}
}
log.info { "Recording finished, total bytes: ${audioData.size()}" }
}
}
}갑자기 여기서부터 난이도가 급상승하기 시작하는데, AudioRecord 메커니즘과 bytes 단위로 데이터를 조작할 수 잇는 이해 지식을 필요로하기 때문이다.
우선 kotlin을 사용하는 만큼, Thread를 사용하지 않고 보다 가벼운 Coroutine을 사용했다.
(Java20?? 이상을 사용하고 있다면 VirtualThread를 써볼 수도 있을 것이다. 정확히 버전 몇인지 잊어먹었다.)
여기선 while문을 사용해서, recording 상태라면 busy waiting 상태로 buffer의 데이터를 지속적으로 가져온다.
- shortBuffer: audioRecord의 buffer에서 가져온 데이터를 담을 그릇
- shortsRead: 성공적으로 읽은 샘플 수를 의미 (PCM_16bit 표준 방식에 맞춰 short 타입으로 받아왔으며, 실시간 스트리밍이 아니기 때문에 구현이 쉬운 BLOCKING 방식을 택했다.)
✒️ 실시간 스트리밍 환경에서 AudioRecord 버퍼와 데이터 읽기 최적화
나는 60초 이내의 음성 데이터를 누적했다가 한 번에 서버로 전달하는 방식을 취하고 있지만, 만약 실시간 스트리밍 목적으로 이를 사용한다면 shortBuffer 사이즈를 더 작게 잡는 것을 고민해봐야 할 필요가 있다.
Stackoverflow - Record buffers smaller than AudioRecord's minBufferSize 글을 읽어보면, 한 기기에서 다른 기기로 오디오를 실시간으로 전송하는 시스템에서 쉽게 발생할 수 있는 문제를 공유하고 있다.
내용를 보면, Android 기기에서 48kHz, 16 bits MONO PCM 설정으로 getMinBufferSize()를 사용한 결과, 최소 버퍼 크기가 3,840 bytes = 1,920 samples = 40 ms of audio로써 지연 최소값을 결정 짓고 있다.
이를 통해 50ms 이하의 저지연(near real-time) 오디오 전송은 달성했으나, 두 장치 간의 불안정한 핑(ping) 차이가 언더플로우/오버플로우 이슈를 유발하고 있는 것이다.
• 언더플로우(underflow): 오디오 전송 속도가 재생 속도보다 느려져서 소리가 끊어짐
• 오버플로우(overflow): 오디어 패킷이 너무 빨리 도착해서 이전 데이터를 덮어씌우거나 잘려서 들림
그래서 질문자는 가장 쉽게 떠올릴 수 있는 해결책을 제시하고 있는데, 바로 모든 오디오 패킷 재생을 수동으로 10ms 지연시키는 것.
이렇게 되면 기존 문제가 해결은 되지만, 전체 지연 시간이 40ms + 10ms = 50ms가 되며, ping spike가 최대 20ms까지 발생할 수 있는 환경에선 60ms까지 늘려야할 수도 있다는 것이 문제. (VoIP의 경우 총 지연 시간이 150ms를 넘기면 안 되므로 이상적이지 않은 해결책)
여기서 답변자는 AudioRecord 공식문서에 나온 내용을 기반으로 두 가지 제안을 하고 있다.
• getMinBufferSize()는 말 그대로 최소 버퍼 크기이며, 부하가 걸리는 상황에선 원할한 녹음을 보장하지 않는다. 따라서 객체에서 데이터를 얼마나 자주 fetch하냐에 따라 더 큰 버퍼를 지정할 필요성이 있을 수 있다.
• 데이터는 전체 녹음 버퍼 크기보다 작은 크기의 청크로 Audio HW에서 읽어와야 한다.
ㅎ...이건 몰랐는데, 버퍼 전체를 한꺼번에 읽으려고 하지말라고 명시가 되어있었네.
혹시 무슨 소린지 이해가 안 가는 분들을 위해 좀 더 쉽게 설명하자면,
• AudioRecord 객체 생성할 때, 내부 버퍼를 getMinBufferSize()로 받은 값보다 더 큰 값으로 잡아라
• 읽기 버퍼(위 예제에선 shortBuffer)를 AudioRecord 내부 버퍼보다 작게 만들어서 자주 읽어라.
단, 이건 실시간 스트리밍을 구현할 필요가 있는 개발자에게나 해당되는 얘기다.
난...난 버그만 안 나면 돼.
📌 Collect Audio Data
AudioRecord 내부 버퍼에서 ShortArray를 가져온 것까진 좋은데, AudioData를 bytesArray로 잡아놔서 조정하느라 혼났다.
(위에서 말했다시피 처음에 read() 메서드를 PCM 16bit용을 써버리는 바람에..ㅠㅠ 실시간으로 고치면서 포스팅하는 중)
private lateinit var audioData: ByteArrayOutputStreamShort는 2 bytes, 그걸 ByteArray 타입으로 치환하기 위해선 우선 shortsRead * 2크기의 ByteArray 배열을 준비해야 한다.
// ShortArray
[S0] [S1] [S2]...
↑ ↑ ↑
샘플1 샘플2 샘플3
// ByteArray
[B0][B1][B2][B3][B4][B5]...
↑ ↑ ↑ ↑ ↑ ↑
샘플1 샘플2 샘플3PCM 16 bits에선 각 오디오 샘플이 정확히 2bytes (= 16bits)를 차지하기 때문에, 이를 bytes로 옮긴다면 shortBuffer[i] 번째의 bit를 상/하위 8 bit로 나눈 후, bytesBuffer[i*2], bytesBuffer[i*2 + 1]에 잘 나누어주면 된다.
이걸 구현한다면,
val byteBuffer = ByteArray(shortsRead * 2)
for (i in 0 until shortsRead) {
byteBuffer[i * 2] = (shortBuffer[i].toInt() and 0xFF).toByte()
byteBuffer[i * 2 + 1] = (shortBuffer[i].toInt() shr 8 and 0xFF).toByte()
}참고로 안드로이드는 리틀 엔디안 방식이 표준이라고 들어서 그렇게 한 건데, 일단 해보고 안 되면 빅 엔디안 방식으로 바꾸려고 했으나 잘 동작하길래 냅뒀다. (왜 되는 거지;;)
이렇게 만든 byteArray를 audioData에 써주면 끝난다.
audioData.write(byteBuffer, 0, byteBuffer.size)
📌 Calculate Average Volume
💡 구현 안 해도 지장 없습니다.
녹음이 정상적으로 되고 있는지 확인이 하고 싶어서 만든 클래스라 없어도 무방.
이게 buffer를 bytes로 받냐, shorts로 받냐에 따라 구현 난이도가 달라진다.
ShortArray에서는 각 요소가 이미 하나의 16-bits 오디오 샘플이 되므로, 다음 로직으로 구현이 끝난다.
/**
* 오디오 데이터의 평균 볼륨을 계산합니다.
*
* @param shortBuffer 오디오 데이터 버퍼 (shorts)
* @param numberOfReadShorts 읽은 short 수
*/
private fun calcAverageVolume(shortBuffer: ShortArray, numberOfReadShorts: Int): Double {
var totalAbsValue = 0.0
for (i in 0 until numberOfReadShorts) {
totalAbsValue += abs(shortBuffer[i].toDouble())
}
return if (numberOfReadShorts > 0) totalAbsValue / numberOfReadShorts else 0.0
}
근데 ByteArray가 오면 상/하위 바이트를 따로 읽어가면서 16 bits의 sample을 만들어줘야 한다.
그리고 1,000 bytes 데이터를 500개 samples로 만들었다치면, 평균 계산에선 또 readBytes를 절반으로 나눠줘야 한다.
/**
* 오디오 데이터의 평균 볼륨을 계산합니다.
*
* @param buffer 오디오 데이터 버퍼 (bytes)
* @param numberOfReadBytes 읽은 바이트 수
*/
private fun calcAverageVolume(buffer: ByteArray, numberOfReadBytes: Int): Double {
var totalAbsValue = 0.0
for (i in 0 until numberOfReadBytes step 2) {
if (i + 1 < buffer.size) {
val sample = (buffer[i].toInt() and 0xFF) or ((buffer[i + 1].toInt() and 0xFF) shl 8)
totalAbsValue += abs(sample)
}
}
val sampleCnt = numberOfReadBytes / 2
return if (numberOfReadBytes > 0) totalAbsValue / sampleCnt else 0.0
}뭐, 대충 이런 느낌???
구현할 때 머리가 좀 아프긴 했지만, 그래서 재밌었던 부분.
5. Recording Time
📌 CounterDownTimer
이거 클래스 괜히 나눴던 거 같다.
비동기 함수 실행 꼬였는데, 상태 좀 그만 만들고 싶어서 발광하다가 진땀 뺐다.
/**
* 녹음 타이머를 관리하는 클래스
*
* @property maxTimeMs 타이머 최대 시간 (기본값: 60초)
* @property intervalMs 타이머 간격 (기본값: 1초)
* @property onFinish 타이머 종료 시 실행할 람다 함수
*/
class RecordingTimer(
private val maxTimeMs: Long = 60000L,
private val intervalMs: Long = 1000L
) {
private val _timerValue = MutableStateFlow((maxTimeMs / 1000L).toInt())
val timerValue: StateFlow<Int> = _timerValue.asStateFlow()
private val _isFinished = MutableStateFlow(false)
val isFinished: StateFlow<Boolean> = _isFinished.asStateFlow()
private var countDownTimer: CountDownTimer? = null
/**
* 타이머 시작
*/
fun start() {
_timerValue.value = (maxTimeMs / 1000L).toInt()
countDownTimer = object : CountDownTimer(maxTimeMs, intervalMs) {
override fun onTick(millisUntilFinished: Long) {
_timerValue.value = (millisUntilFinished / 1000).toInt()
_timerValue.value.takeIf { it % 10 == 0 }
?.let { log.info { "Timer: ${_timerValue.value} seconds remaining" } }
}
override fun onFinish() {
log.info { "Timer finished" }
_isFinished.value = true
}
}.start()
}
/**
* 타이머 취소
*/
fun cancel() {
countDownTimer?.cancel()
countDownTimer = null
_isFinished.value = false
}
}이건 AudioRecording이랑 관련도 없는 내용이니까 대충 적고 치우기로 했다.
CountDownTimer를 사용하면 정말 쉽게 Thread 타이머를 구현할 수가 있는데,
- onTick(): intervalMs 마다 호출
- onFinish(): 타이머가 종료되면 호출
원래는 onFinish에서 callback function을 호출하도록 만들었다가 머리가 아파져서, 그냥 isFinished 상태를 호출자 측에서 구독하고 알아서 처리하게 만들어버렸다.
예를 들어, ViewModel에서 이렇게 만들면 된다.
@HiltViewModel
class VoiceRecordViewModel @Inject constructor(
@ApplicationContext private val context: Context,
private val correctUseCase: CorrectUseCase
) : ViewModel() {
private val recordingTimer = RecordingTimer(
maxTimeMs = MAX_RECORDING_TIME_MS,
intervalMs = COUNTDOWN_INTERVAL
)
init {
viewModelScope.launch {
recordingTimer.isFinished
.filter { it }
.collect {
stopVoiceRecord()
}
}
}
private fun stopVoiceRecord() {
log.info { "Stop voice record" }
recordingTimer.cancel()
return convertPcmToWav()
}
}별로 어려운 내용 아니니 패스.
6. Converting PCM to WAV
📌 PCM vs WAV
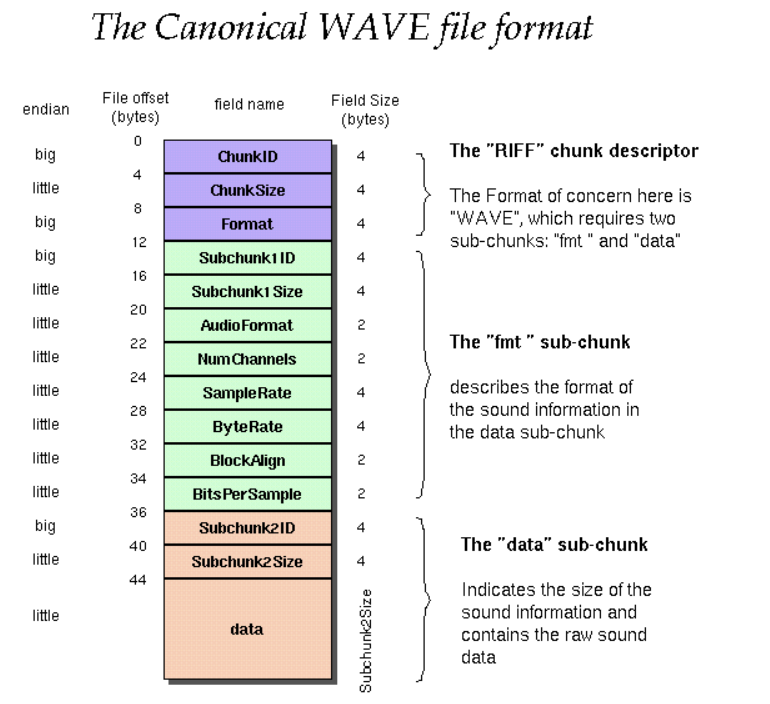
AudioRecorder의 ByteArray를 잘 저장해놨다면, 이걸 PCM 데이터라고 보면 된다.
그럼 wav는 뭔데요? 어떻게 pcm을 wav로 치환하나요?
이런 질문을 하는 우둔한 자들을 위해 스택 오버플로우 현자께서 친절히 설명을 달아놓으셨다.
(나도 덕분에 계몽할 수 있었다.)
- wav: 일종의 상자. mp4, zip 같은 것들을 말하는 것
- pcm: wav같은 상자 안에 들어가는 data
"네가 하려는 질문은 zip 내부 텍스트 파일을 어떻게 zip 파일로 변환할 수 있나요?"라고 묻는 것과 같다며 일침을 놓고 있다.
여튼 MP3나 MP4가 아닌, wav 확장자로 변환하려는 이유는 겁나 쉽기 때문이다. (진짜 그게 다임)
위 사진을 보면 알겠지만, 저 양식에 맞게 bit를 잘 채워넣어주기만 하면 끝난다.
(더 자세히 써놓고 싶은데, 벌써 새벽 1시를 넘어가는 바람에 슬슬 지치기 시작했다.)
📌 Implementation
변환이 진짜 쉽다고 해놓고 이런 말 하면 폼이 안 나긴 한데, 내가 구현한 방법은 자꾸 wav 파일이 깨져서 잘 안 들리는 이슈가 있었다.
그래서 어디선가 솔루션을 얻고 아래처럼 구현했는데, 출처를 남기고 싶은데 다시 찾으려니 도저히 못 찾겠다
혹시나 Velog에서 자바로 아래 코드를 구현한 글을 본다면 거기가 원본이고 난 짝퉁이다.
/**
* PCM 데이터에 WAV 헤더를 추가하는 함수
*
* @param pcmData PCM 오디오 데이터
* @param recordSampleRate 녹음 샘플 레이트
* @return WAV 헤더가 포함된 바이트 배열
*/
fun addWavHeader(pcmData: ByteArray, recordSampleRate: Int): ByteArray {
val totalAudioLen = pcmData.size.toLong()
val totalDataLen = totalAudioLen + 36 // 헤더 크기 더하기
val sampleRate = recordSampleRate.toLong()
val channels = 1 // 모노
val bitsPerSample = 16 // 16비트
val byteRate = sampleRate * channels * bitsPerSample / 8
val blockAlign = (channels * bitsPerSample / 8).toInt()
val header = ByteArray(44)
// "RIFF" 청크 디스크립터
header[0] = 'R'.code.toByte()
header[1] = 'I'.code.toByte()
header[2] = 'F'.code.toByte()
header[3] = 'F'.code.toByte()
// 파일 크기
header[4] = (totalDataLen and 0xffL).toByte()
header[5] = (totalDataLen shr 8 and 0xffL).toByte()
header[6] = (totalDataLen shr 16 and 0xffL).toByte()
header[7] = (totalDataLen shr 24 and 0xffL).toByte()
// "WAVE" 포맷
header[8] = 'W'.code.toByte()
header[9] = 'A'.code.toByte()
header[10] = 'V'.code.toByte()
header[11] = 'E'.code.toByte()
// "fmt " 서브청크
header[12] = 'f'.code.toByte()
header[13] = 'm'.code.toByte()
header[14] = 't'.code.toByte()
header[15] = ' '.code.toByte()
// 서브청크 크기 (16 for PCM)
header[16] = 16
header[17] = 0
header[18] = 0
header[19] = 0
// 오디오 포맷 (1 = PCM)
header[20] = 1
header[21] = 0
// 채널 수
header[22] = channels.toByte()
header[23] = 0
// 샘플 레이트
header[24] = (sampleRate and 0xffL).toByte()
header[25] = (sampleRate shr 8 and 0xffL).toByte()
header[26] = (sampleRate shr 16 and 0xffL).toByte()
header[27] = (sampleRate shr 24 and 0xffL).toByte()
// 바이트 레이트
header[28] = (byteRate and 0xffL).toByte()
header[29] = (byteRate shr 8 and 0xffL).toByte()
header[30] = (byteRate shr 16 and 0xffL).toByte()
header[31] = (byteRate shr 24 and 0xffL).toByte()
// 블록 얼라인
header[32] = blockAlign.toByte()
header[33] = 0
// 비트 뎁스
header[34] = bitsPerSample.toByte()
header[35] = 0
// "data" 서브청크
header[36] = 'd'.code.toByte()
header[37] = 'a'.code.toByte()
header[38] = 't'.code.toByte()
header[39] = 'a'.code.toByte()
// 데이터 크기
header[40] = (totalAudioLen and 0xffL).toByte()
header[41] = (totalAudioLen shr 8 and 0xffL).toByte()
header[42] = (totalAudioLen shr 16 and 0xffL).toByte()
header[43] = (totalAudioLen shr 24 and 0xffL).toByte()
// 결과 WAV 파일 생성
val wavData = ByteArray(header.size + pcmData.size)
System.arraycopy(header, 0, wavData, 0, header.size)
System.arraycopy(pcmData, 0, wavData, header.size, pcmData.size)
return wavData
}
7. Conclusion
📌 I'm Done
위에서 만든 wavData를 안드로이드 로컬에도 저장해보고, 서버로 전달해서 저장해보고, STT API로 보내봤는데 모두 잘 동작하고 있다.
사실 글만 보면 디게 쉽게 구현한 것 같겠지만, 요새 면접 보면서 시간 쪼개가며 개발했더니 뇌가 과부화 와서 도중에 별짓을 다 했었다;;
Spring + Java 탈출한 건 좋은데, 진득하게 kotlin 공부할 시간이 없다보니 내가 제대로 구현을 하고 있는지도 파악이 어려워서...어려워서...즐겁다.
역시 문제는 어려워야 재밌지.