💡 단점이 명확해서 저는 채택하지 않은 방식입니다. 재미삼아 한 번 구현해보기엔 좋은 주제입니다.
1. Introduction
📌 Usecase
📎 현재 만들고 있는 서비스에서 사용자의 음성을 입력받아 Text로 치환하는 기능을 구현하고자 했다.
Client에서 할 지, Server에서 처리할 지 고민하다가 Android의 내장 API로 STT 기능을 구현할 수 있길래 괜찮으면 사용하려고 구현해봤다.
- 사용자 디바이스의 마이크 권한을 요청할 수 있어야 한다.
- 사용자의 음성(영어)을 Text로 변환할 수 있어야 한다.
- 음성 입력이 없어도 1분 동안 listening 상태가 유지되어야 한다. (실패)
- 음성 입력 도중에 끊김이 발생해도, 사용자가 확인 버튼을 누르기 전까지는 listening 상태가 유지되어야 한다. (실패)
참고로 MVVM 구조로 진행했으며, 하위 주요 의존성을 참고해주시길 바랍니다.
- Android Compose 1.10.0
- Android Lifecycle Viewmodel Compose 2.8.5
- Hilt Android 2.51.1
- kotlinx Coroutines 1.10.1
코틀린이 아직 익숙칠 않아서 자바처럼 일단 쓰고 개선하려고 했는데, 난 이 방식을 채택을 안 할 거라 굳이 더 작업할 필요성을 못 느껴서 관뒀다.
2. Android Speech API
📌 SpeechRecognizer
SpeechRecognizer | API reference | Android Developers
developer.android.com

공식 문서가 워낙 친절해서 사용에는 문제가 없다.
- 직접 인스턴스 만들지 말고 SpeechRecognizer.createSpeechRecognizer(Context)나, SpeechRecognizer.createOnDeviceSpeechRecognizer(Context)를 호출해라.
- SpeechRecognizer 생성 메서드는 반드시 메인 스레드에서 실행해라
- 사용 다 끝났으면, 반드시 destroy() 호출해서 제거해라
- RECORD_AUDIO 권한을 받아야 한다.
그런데 3번째 문단을 보면 경고 문구에 이렇게 적혀있다.
이 API의 구현 방식은 음성을 원격 서버로 스트리밍하여 음성 인식을 수행할 가능성이 있습니다.
그러나 엄밀히 말해, 이 API는 상당한 양의 배터리와 네트워크 대역폭을 소모하는 지속적인 음성 인식을 위해 사용하도록 설계되지 않았습니다.
as such를 "그러므로"라고 해석해야 할 지, "엄밀한 의미에서"라고 해석해야 할 지 고민이 많았다.
"엄밀한 의미에서"라고 하면 앞의 내용을 부정하는 것이고, "그러므로"라고 하면 앞의 근거로 결론을 내리는 맥락이므로 의미가 완전히 달라진다.
그런데 맥락을 보면 후자가 맞는 거 같은데, GPT가 자꾸 전자가 맞다고 박박 우기길래 혼란이 와버렸다.
그래서 링크드인 내용이랑, 공식 문서의 격식체, 그리고 'thus'를 쓰면 앞 뒤 문장이 말이 안 된다는 걸 고려해서 "그러나 엄밀히 말해,"라고 의역을 했다.
API 구현 방식이 스트리밍 수행할 가능성이 있다면서, "그래서 지속적인 음성 인식은 고려하지 않았다"라고 해석하면 도저히 말이 안 되지 않은가;;;;
여튼 말이 길어졌는데, 중요한 건 이 API는 지속적인(Streaming) 인식에는 적합하지 않다고 한다.
하지만 나도 스트리밍까진 할 생각이 아직 없었으므로, 그냥 사용해보기로 했었다.
📌 Audio Permission
우선 공식 문서에 나온대로 기기의 오디오 권한을 사용자에게 받아야 한다.
AndroidManifest.xml에 다음 스니펫을 추가해주자.
<uses-permission android:name="android.permission.RECORD_AUDIO"/>
internet의 경우, SpeechRecognizer 커스텀 설정할 때 offline에서도 동작 가능하게 할 건지 정하는 옵션이 있다.
아마도 offline 모드로 하면 필요없을 거 같긴 한데, 모르겠으면 그냥 추가해두자.
어차피 인터넷 권한은 민감한 정보도 아니라서, 추가로 사용자에게 권한 확인 요청을 받을 필요도 없다.
이걸 코드로 구현할 때는 다음과 같이 만들었다.
@HiltViewModel
class VoiceViewModel @Inject constructor(
@ApplicationContext private val context: Context
) : ViewModel() {
private val _permissionRequest = MutableStateFlow(false)
val permissionRequest: StateFlow<Boolean> = _permissionRequest.asStateFlow()
/**
* 음성 인식 모드 토글
*/
fun toggleListeningMode() {
viewModelScope.launch {
if (!hasAudioPermission()) { // 오디오 권환 확인
requestAudioPermission() // 없으면 요청
return@launch
}
...
}
}
fun resetPermissionRequest() {
_permissionRequest.value = false
}
/**
* 마이크 권한 체크
*/
private fun hasAudioPermission(): Boolean {
return ContextCompat.checkSelfPermission(
context,
Manifest.permission.RECORD_AUDIO
) == PackageManager.PERMISSION_GRANTED
}
/**
* 마이크 권한 요청 이벤트 발행
*/
private fun requestAudioPermission() {
log.info { "Request audio permission" }
_permissionRequest.value = true
}
}- 사용자가 음성 인식 버튼을 클릭한다.
- audio 권한 검사를 하고, 권한이 없으면 permission request 이벤트를 발행한다.
- view에서 permission request 이벤트를 수신하면, 사용자에게 권한을 요청한다.
왜, 굳이 이런 번거로운 이벤트 핸들링 방식을 할 수 없었냐면
@Composable
fun HomeScreen(
viewModel: VoiceViewModel = hiltViewModel()
) {
val permissionRequest by viewModel.permissionRequest.collectAsState()
val requestPermissionLauncher = rememberLauncherForActivityResult(
contract = ActivityResultContracts.RequestPermission(),
onResult = { isGranted ->
if (isGranted) { // 3. 사용자가 승인 했다면?
viewModel.resetPermissionRequest() // 4. permission request를 다시 false로 변경
viewModel.toggleListeningMode() // 5. 음성 인식 메서드 재실행
}
}
)
// 1. permission request 이벤트 감지
LaunchedEffect(permissionRequest) {
if (permissionRequest) { // 2. true로 바뀌었으면, 사용자에게 audio 권한 요청
requestPermissionLauncher.launch(Manifest.permission.RECORD_AUDIO)
}
}
}rememberLauncherForActivityResult가 Composable 함수 내에서만 사용할 수 있다고 해서, VM에서 사용이 안 된다고 한다. 머쓱;
끝나고 이런 UI가 잘 뜨면 해결된 것.
📌 RecognitionIntent
RecognizerIntent | API reference | Android Developers
developer.android.com
기본 설정을 그대로 사용할 게 아니라면, 사용자 정의를 해주어야 한다.
여기서 RecognizerIntent가 있는데, 본인 서비스에 맞는 설정을 해주면 된다.
private fun createSpeechRecognitionIntent() = Intent(RecognizerIntent.ACTION_RECOGNIZE_SPEECH).apply {
putExtra(RecognizerIntent.EXTRA_LANGUAGE_MODEL, RecognizerIntent.LANGUAGE_MODEL_FREE_FORM)
putExtra(RecognizerIntent.EXTRA_LANGUAGE, "en-US")
putExtra(RecognizerIntent.EXTRA_LANGUAGE_PREFERENCE, "en-US")
putExtra(RecognizerIntent.EXTRA_ONLY_RETURN_LANGUAGE_PREFERENCE, true)
putExtra(RecognizerIntent.EXTRA_SPEECH_INPUT_COMPLETE_SILENCE_LENGTH_MILLIS, 10000);
putExtra(RecognizerIntent.EXTRA_SPEECH_INPUT_POSSIBLY_COMPLETE_SILENCE_LENGTH_MILLIS, 10000);
putExtra(RecognizerIntent.EXTRA_SPEECH_INPUT_MINIMUM_LENGTH_MILLIS, 15000);
putExtra(RecognizerIntent.EXTRA_PARTIAL_RESULTS, true)
putExtra(RecognizerIntent.EXTRA_CALLING_PACKAGE, context.packageName)
}이런 식으로 적용을 할 수 있는데,
- 난 영어 음성을 입력받을 것이므로 설정, 선호 언어 모두 영어로 하고, 오직 선호 영어로만 해석하도록 고정했다.
- 처음 사용할 때 계속 음성 인식 안 되면 3~4초 정도 후에 자동 종료되길래, EXTRA_SPEECH_INPUT 요소들을 지정해서 10초 간 대기하도록 설정
그런데 이게 좀 어이없게 동작한다.
난 말을 안 하고 있어도 10초간 대기해주기를 바랬는데,
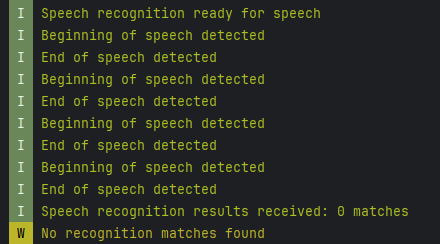
1초 단위로 껐다 켜젔다를 반복한다. ㅋㅋㅋㅋㅋ (값을 늘려도 여전함)
공식 문서를 다시 확인해보니
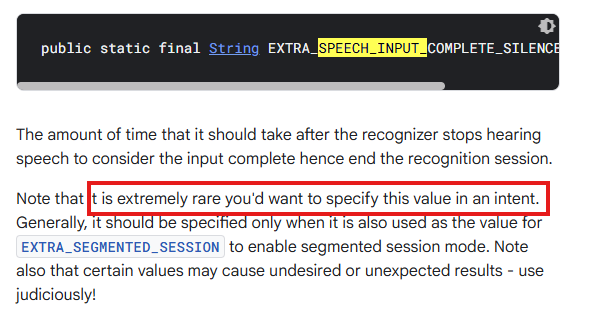
이 값들을 수정하는 경우는 드물고, 그냥 놔두는 것이 바람직하다고 한다.
아니, 그래도 적용은 되야 할 거 아닌가 싶어서 확인해보니
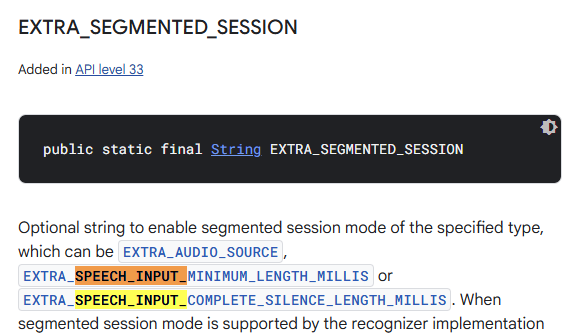
난 레거시 SW도 수용하려고 API 27 채택했는데, 이 기능은 API 33부터 추가되었다고 한다. ^^
그래서 경고 문구에 나온대로 "니가 예상한 것과 다르게 동작할 수도 있다"의 표본이 된 셈.
애초에 SpeechRecognizer가 본질적으로 짧은 음성 인식에 최적화 되어 있는 만큼, 불순하게 사용하려 했던 내 잘못이긴 하다.
📌 RecognitionListener
RecognitionListener | API reference | Android Developers
developer.android.com
나중에 SpeechRecognition한테 작업을 맡기고 난 후에, 각 이벤트에 따라 세밀한 제어를 하고 싶을 때 사용한다.
예를 들어, speech의 시작, 음성 듣는 중, 인식 종료 등에 대한 상태 별로 로그를 남긴다거나, 일련의 작업을 수행하고 싶을 때 event 별로 메서드 재정의해서 쓰라는 의미다.
예시를 보여주자면,
/**
* 음성 인식 리스너
*/
private val recognitionListener = object : RecognitionListener {
override fun onReadyForSpeech(params: Bundle?) { // 음성 인식 준비 됐을 때
log.info { "Speech recognition ready for speech" }
}
override fun onBeginningOfSpeech() { // 음성 인식 시작했을 때
log.info { "Beginning of speech detected" }
}
override fun onRmsChanged(rmsdB: Float) {}
override fun onBufferReceived(buffer: ByteArray?) {}
override fun onEndOfSpeech() { // 음성 인식 끝났을 때
log.info { "End of speech detected" }
}
override fun onError(error: Int) { // 음성 인식하다 에러났을 때
val errorMessage = getSpeechRecognitionErrorMessage(error)
log.error { "Speech recognition error: $errorMessage (code: $error)" }
when (error) {
SpeechRecognizer.ERROR_NO_MATCH, SpeechRecognizer.ERROR_SPEECH_TIMEOUT -> {
_voiceState.value = VoiceRecognitionState.NoInput
}
else -> {
_voiceState.value = VoiceRecognitionState.Error(errorMessage)
}
}
}
override fun onResults(results: Bundle?) { // 음성 인식 결과가 있을 때
val matches = results?.getStringArrayList(SpeechRecognizer.RESULTS_RECOGNITION)
log.info { "Speech recognition results received: ${matches?.size ?: 0} matches" }
if (!matches.isNullOrEmpty()) { // 결과가 null 혹은 empty가 아니라면
val recognizedText = matches[0]
if (recognizedText.isNotBlank()) { // 결과가 blank가 아니면, 결과 출력
log.info { "Successfully recognized: \"$recognizedText\"" }
_voiceState.value = VoiceRecognitionState.Success(recognizedText)
} else { // blank면 noinpu
log.warn { "Recognized text was blank" }
_voiceState.value = VoiceRecognitionState.NoInput
}
} else {
log.warn { "No recognition matches found" }
_voiceState.value = VoiceRecognitionState.NoInput
}
}
override fun onPartialResults(partialResults: Bundle?) {}
override fun onEvent(eventType: Int, params: Bundle?) {}
}
private fun getSpeechRecognitionErrorMessage(error: Int): String = when (error) {
SpeechRecognizer.ERROR_AUDIO -> "오디오 에러"
SpeechRecognizer.ERROR_CLIENT -> "클라이언트 에러"
SpeechRecognizer.ERROR_INSUFFICIENT_PERMISSIONS -> "권한 에러"
SpeechRecognizer.ERROR_NETWORK -> "네트워크 에러"
SpeechRecognizer.ERROR_NETWORK_TIMEOUT -> "네트워크 타임아웃"
SpeechRecognizer.ERROR_NO_MATCH -> "인식 결과 없음"
SpeechRecognizer.ERROR_RECOGNIZER_BUSY -> "음성 인식 서비스 사용 중"
SpeechRecognizer.ERROR_SERVER -> "서버 에러"
SpeechRecognizer.ERROR_SPEECH_TIMEOUT -> "음성 입력 없음"
else -> "알 수 없는 에러"
}이런 식으로 현재 SpeechRecognizer가 어떤 상태인지에 따라 동작을 정의하면,
위에서 보여줬던 사진처럼, Recognition의 현재 상태에 따른 작업을 수행할 수 있다는 의미.
참고로 VoiceRecognitionState는 내가 추가로 정의한 object다.
android.speech에서 제공해주는 기능이 아님.
📌 start void recognition
/**
* 음성 인식 시작
*/
private fun startVoiceRecognition() {
val intent = createSpeechRecognitionIntent()
val speechRecognizer = SpeechRecognizer.createSpeechRecognizer(context)
speechRecognizer.setRecognitionListener(recognitionListener)
speechRecognizer.startListening(intent)
}마지막은 위에서 만든 재료들을 잘 넣어주기만 하면 된다.
- 공식 문서에서 얘기한 것처럼 SpeechRecognizer.createSpeechRecognizer(Context)로 인스턴스 생성
- listener 주입
- 시작할 때, intent 인스턴스 주입
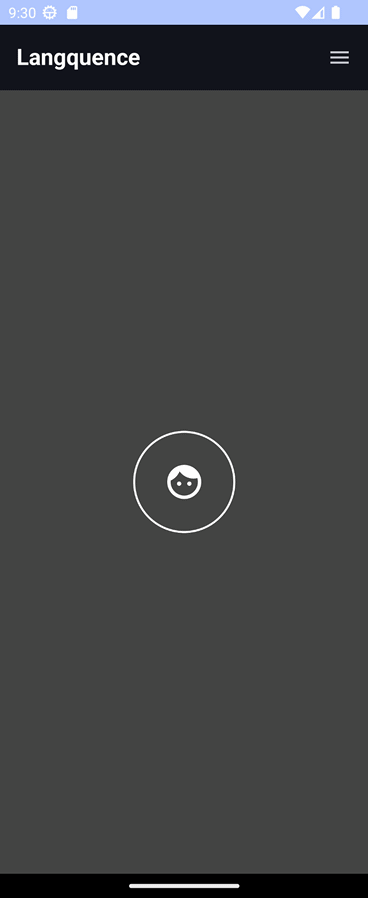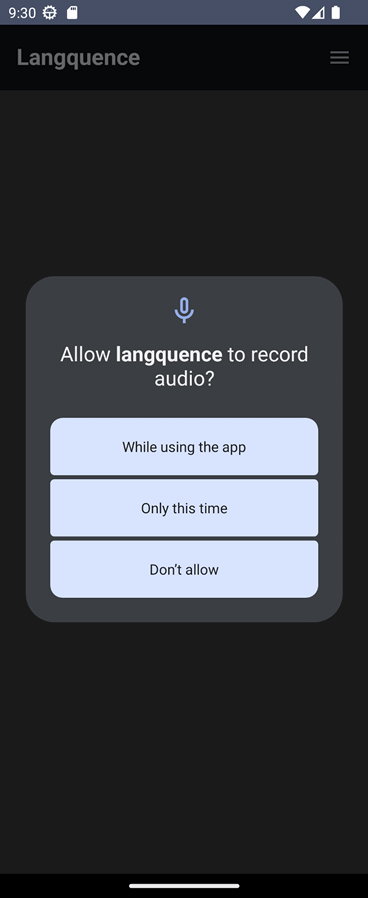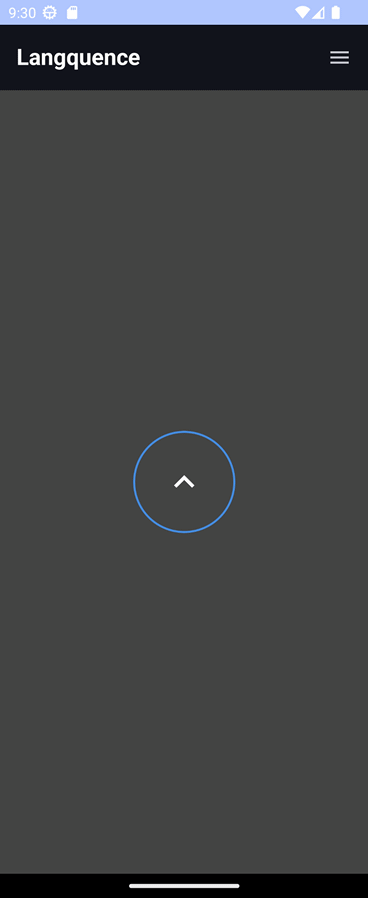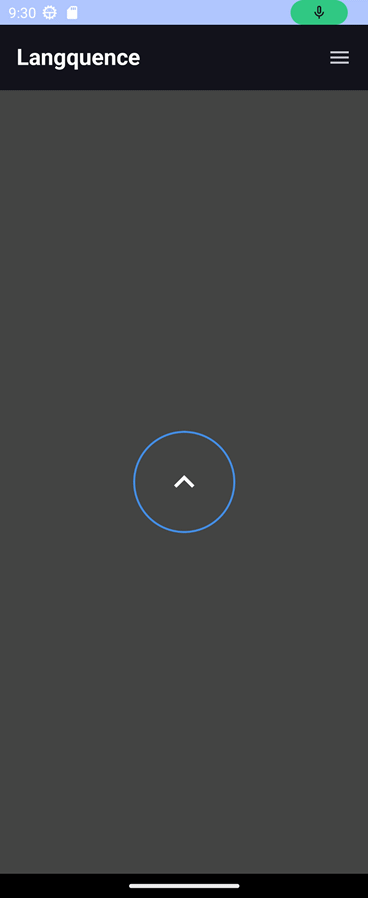
여기까지 하면 위와 같이 "마이크 허용 > 리스닝 모드"로 전환되며, 음성을 입력하면 다음과 같이 로그가 나온다.

3. Conclusion
📌 근데 전 안 씁니다.
내 서비스에선 이게 적합하지 않다고 느낀 게,
- 침묵 시간에 대한 제어가 어렵다. (애초에 그런 의도로 설계된 API가 아님)
- 구글 인식 기능 언어 모델의 단어 제한도 어렵고, 자기 멋대로 좋은 문장을 만들려고 하는 경향이 있다.
- (내 발음 때문인지) 문장이 길어지면 정확도가 떨어진다.

- 내가 말한 문장: "However, the accuracy is quite low. I might as well connect it to the server via a stream if I'm going to change API anyway"
- 해석된 문장: "Harbor address is quite low I might as well are connected to the Suburbia stream if I'm going to change the API anyway"
ㅋㅋ 실화냐.
나름 스픽 앱에서 발음 평가 95% 이상 받는 입장에서, 내 발음 문제라고 하면 좀 억울할 거 같다.
그리고 마침 라인 야후 붙고, 취직 전까지 빈둥거리던 친구가 iOS 앱 개발 해볼 겸 프로젝트 참여해도 되냐고 연락이 왔다.
iOS랑 Android 양 쪽 다 내장 API가 있긴 한데, 이거 각자 튜닝해서 정확도 높이는 것도 좀 아닌 거 같고,
나는 추후 서버에서 STT API를 사용하는 쪽으로 수정할 예정이다.