Kotlin이 무슨 Java로 코딩할 때 도와주는 라이브러린가? 했었는데 최근에 공부해보니 이것도 하나의 언어였다.
문제는 자바랑 비슷해보이면서 괴랄하게 생긴 문법때문에 진입 장벽이 다소 높다.
문법이야 뭐..프로그래밍 언어를 많이 다뤄본 사람이라면 그냥 공부하면서 익히는 게 좋다고 생각하므로 따로 정리할 생각은 없다.
참고로 절대 쉬운 내용이 아니다.
나처럼 기본적인 Kotlin 문법도 모른 상태로 도전하면서 머리 깨지는 걸 즐기는 사람은 아무래도 상관없다.
그보다 문제는 개인 정리용으로 쓰는 포스트라 잘못된 정보가 섞여있을 수도 있다. 😅 주기적으로 업데이트 할 예정.
목차
1. What is Coroutine?
2. Coroutine Scope (Coroutine Context)
3. Coroutine Suspend
4. Coroutine Builder
5. Coroutine Job
6. Coroutine Context
7. Coroutine Exception Handling
8. Channel & Flow
1. What is Coroutine?
Co(Cooperation, 협력) + Routines(function, 함수같은 일련의 명령)의 합성어이다.
정의를 먼저 설명하자면, Thread보다 더 작은 단위에서 비동기적으로 멀티태스킹 작업을 하는 서브 루틴이다.
(서브 루틴은 시작과 종료되는 지점이 각각 하나밖에 없지만, 코루틴은 시작과 종료지점이 여러개다. 즉, 서브루틴 != 코루틴이 된다.)
혹시 리액트를 공부했었는데 비동기 작업을 처리했었다면, 동일한 개념이라 봐도 무방하다.
[React] 8. 외부 API 연동
이 글은 김민준(velopert)님의 리액트를 다루는 기술을 참조하였습니다. 목차 1. 비동기 작업 2. Callback Function 3. Promise Object 4. async/await keyword 5. axios로 API 호출 6. 참고 자료 1. 비동기 작업 synchronous(
jaeseo0519.tistory.com
리액트를 해보지 않은 사람을 위해 예시를 하나 들어보자면,
내가 코딩을 하다가 어떤 에러가 발생했다고 가정하자. 그런데 지금 나는 너무 피곤하고 화장실도 다녀오고 싶은데, 동기적으로 일을 처리하면 이 에러를 해결하기 전까지 나는 아무것도 하지 못 한다.
그래서 일단 이 에러를 나중에 해결하기로 미뤄두고 그 동안 화장실도 다녀오고 커피도 타오는 거라고 보면 된다.
(이딴 게 예시..?)
대충 의미만 파악할 수 있으면 된다.
이런 특성을 비선점형 멀티태스킹이라고 하는데, task가 scheduler로부터 cpu 사용권을 할당받기만 한다면, scheduler가 다시 강제로 cpu 사용권을 뺐을 수는 없다.
이게 왜 필요하냐면, 처음에 Coroutine이 Thread보다 작은 단위라고 했는데, 문제는 Thread는 선점형 멀티태스킹이다.
Thread는 실제로 동시에 작업이 처리(병렬성)되는 반면, Coroutine은 동시에 실행되는 건 아닌데 시간 조절을 엄청나게 잘해서 하나의 할당받은 cpu를 서로 잘 나누어서 사용한다. (병행성)
Thread는 실제로 일을 동시에 처리하기 때문에 교체에 비용이 많이 들지만, Coroutine은 그렇지 않다.
하나의 cpu를 두고 여러 개를 동시에 처리하는 것'처럼' 보이게 하는 것이다. (훨씬 가볍다.)
class CoroutineTest {
@Test
fun example() = runBlocking{ // Coroutine Function
CoroutineScope(this.coroutineContext).launch {
ex()
println("hi!")
}
println("bye")
}
}
private suspend fun ex() {
println("hello!")
}뭐, 대충 이런 식의 함수를 실행해보았다고 치자. (자세한 건 밑에서 다룰 거니 무시하고 넘어가면 된다.)
example 함수 안에서 suspend 키워드가 붙은 함수를 호출하면, example함수는 Coroutine Function이 된다.
(이유는 밑에서 다룰 것이니, 일단 그렇다 치자.)
위에서 부터 아래로 코드를 읽다가 ex함수를 호출하면 단순히 함수 호출한 아니라 example 함수를 탈출한다.
그러면 어느 영역에서 ex 함수가 실행되고 있는 동안, example함수를 실행시키던 Thread는 이때다 하면서 example이 아닌 밑에 있던 다른 코드를 실행한다. (가히 개인주의 코드라 볼 수 있다.)

웃긴 건 ex 함수 호출하겠다고 집 나갔던 흐름이 다시 돌아오는 지점이 함수가 멈췄던 부분이라는 점이다.
실행 결과를 보면 coroutine 실행한다고 집 떠난 동안 bye가 먼저 출력되긴 했는데, hello 다음에 hi도 충실히 출력하고 있는 모습이다.
즉, 위의 실행 결과만 봐도 뭔가 기존에 알고 있던 flow 방식대로 흘러가지 않음을 알 수 있다.
이런 비동기 작업은 보통 서버랑 통신하는 과정에서 자주 쓰이는데, 솔직히 프로젝트를 아직 진행해보질 않아서 이 내용은 추후 보완하도록 해야겠다.
시작하기 전에 의존성을 추가해줄 필요가 있다.
dependencies {
...
implementation("org.jetbrains.kotlinx:kotlinx-coroutines-core:1.6.4")
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-android:1.6.4'
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-test:1.6.4'
}
중요한 것만 하나 짚고 넘어가자.
Coroutine을 처음 배울 때 굉장히 혼란스러울 수 있는데, 3가지만 기억하면 된다.
Coroutine을 사용할 때 생각해야 하는 것.
1. 어느 환경(Thread)에서 작동하게 할 것인가?
2. 언제까지 작동하게 할 것인가?
3. 리턴값이 필요한가? (존재하는가?)
자, 그럼 지긋지긋한 Coroutine을 한 번 찢어보자.
참고로 이제 고작 합쳐서 6시간 정도 공부함.
2. Coroutine Scope
어느 Thread에서 작동하게 할 것인지를 명시한다.
coroutine을 생성하면서 그 안에서 실행되는 job(보통 job이라고 표현함.)들을 정의한다.
이 일련의 작업들은 서로 코루틴 별로 그룹으로 묶여있다보니 다른 작업을 처리하다가 실패하면 전체 작업이 취소된다.
GlobalScope.launch {
// ...code
}우선, 다른 블로그를 보면 GlobalScope를 많이 사용하던데, 이건 권장되지 않는 방법 정도가 아니라 아예 안 쓴다.
이미 네이밍부터 전역이라고 떡하니 명시되어 있는데, GlobalScope의 실행 시간은 예측할 수가 없다.
심지어 공부하려고 GlobalScope 써보는데 처음에 자꾸 온갖 에러뜨고 난리나서 스트레스 받아 죽는 줄 알았다.

CoroutineScope라는 함수가 있는데, 인자값으로 context를 받는다.
여기서 context란 coroutine이 실행될 thread를 알려달라는 뜻이다.
CoroutineScope(Dispatchers.Main).launch {
// code...
}
CoroutineScope(Dispatchers.IO).launch {
// code...
}
CoroutineScope(Dispatchers.Default).launch {
// code...
}
Coroutine Context에는 Main, IO, Default 세 가지가 있다.
- Main : 메인 스레드로써 UI나 View 작업에서 사용된다.
- IO : 네트워킹이나 DB 접근 같은 백그라운드 작업을 수행할 때 사용된다.
- Default : 좀 더 복잡한 로직들을 처리할 때 사용한다.
참고로 나처럼 test 파일에서 돌리는 사람이 있다면 Main이나 IO를 쓰면 에러가 뜬다.
이건 Application 환경에서 사용할 수 있는 쓰레드라 테스트 환경에서는 사용할 수 없으므로 Default를 쓰면된다.
만약 MainActivity에서 코드를 작성하고 있다면 알아서 잘 쓰면 된다.
참고로 이런 꼼수도 쓸 수 있긴 하다.
class CoroutineTest {
@Test
fun test() = runBlocking{
CoroutineScope(this.coroutineContext).launch {
//...code
}
joinAll()
}
}this를 써서 class의 환경과 일치시키는 건데, 여러모로 복잡하다.
애초에 runBlocking을 나중에 다루긴 할 건데 별로 권장되는 방법은 아니니까 참고만 하고 넘어가도 무방하다.
3. Coroutine suspend
함수 앞에 suspend를 붙이면 일반적인 함수와는 조금 다른 의미를 내포한다.
suspend fun은 선언된 함수가 비동기적으로 실행될 수 있다는 것을 알리기 때문에, 마찬가지로 다른 suspend 함수나 Coroutine 안에서만 호출할 수 있다.
다른 개념이지만 static 메서드를 일반 메서드 따위가 호출 할 수 없다는 걸 상기해보자.
이 suspend라는 단어의 의미가 '유예하다'라는 걸 떠올리면 흐름을 쉽게 이해할 수 있을 것이다.
class CoroutineTest {
@Test
fun test2() = runBlocking {
val job1 = CoroutineScope(Dispatchers.Default).launch {
run()
}
val job2 = CoroutineScope(Dispatchers.Default).launch {
run()
}
joinAll(job1, job2)
println("안녕~")
}
}
private suspend fun run() {
println("유예..당했다")
}coroutine function은 suspend를 만나면 말그대로 현재 진행중이던 작업이 유예된다.
하나의 스레드에서 작업중이던 코루틴이 suspend(유예)되면, 현재 스레드에서 resume(재개)할 다른 코루틴을 탐색한다.
영어를 잘하면 코딩 잘 한다는 말이 틀린 말은 아니다.
4. Coroutine Builder
launch, async/await, withContext, runBlocking, actor, produce와 같이 실질적으로 코루틴을 만드는 함수들을 통틀어서 Coroutine Builder라고 부른다.
참고로 개인적으로 생각했을 때, 이 부분이 진짜 굉장히 중요하다.
CoroutineScope로 쓰레드를 지정했으면, 이제 어떤 식으로 실행할 것인지를 정한다.
여기서 코루틴을 '만드는' 함수라고 언급했음에 유의하자.
- launch() → return Job
- async() → return Deffered<T>
- withContext() → return T
- runBlocking() → return T
- actor() → return SendChannel<E>
- produce() → return ReceiveChannel<E>
1. launch
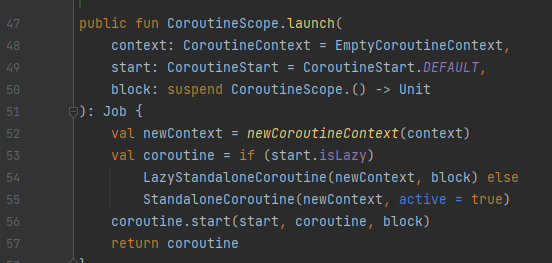
결과가 없는 Coroutine을 생성한다. 엥, 위에서는 Job을 리턴한다면서요?
CoroutineBuilder에서 return 값은 보통 결과를 의미하는데, 여기선 Job instance를 반환한다.
비동기 작업의 결과물을 리턴하는 것이 아니라, 코루틴 작업에 대한 instance 자체를 돌려줌을 뜻한다.
class CoroutineTest {
@Test
fun test2() {
CoroutineScope(Dispatchers.Default).launch {
run()
}
println("안뇽")
}
}
private suspend fun run() {
val job = CoroutineScope(Dispatchers.Default).launch {
println("run")
}
job.cancel()
}이렇게 launch를 통해 돌려받은 instance는 곧 coroutine 작업을 의미하는데, 이걸 cancel하고 join하는 등.
여러가지 전략을 세워 제어함으로써 작업을 수행할 수 있도록 만든다.
2. async/await
리액트의 async/await와 동일하다고 보면 된다.
launch와는 달리 결과를 가지는 coroutine을 생성하는데, async로 Deferred<T>를 리턴받으면, await함수로 결과를 받을 수 있다.
private suspend fun forTest() {
print("Start...")
GlobalScope.launch(Dispatchers.Main) { // Main, IO는 application 환경에서만 살아있는 거라 에러가 발생한다.
val job1 = async(Dispatchers.Default) {
var total = 0
for (i in 1..10) {
total += i
delay(100)
}
print("job1")
total
}
val job2 = async(Dispatchers.Default) {
var total = 0
for (i in 1..10) {
delay(100)
total += i
}
print("job2")
total
}
val result1 = job1.await()
val result2 = job2.await()
println("result are $result1 and $result2")
}
print("End")
}이 코드를 공부할 때 참고한 블로그가 있었는데, 한참을 뒤져도 다시 못 찾겠다..죄송합니다.
이번에는 async를 통해 작업을 했기 때문에 total이라는 특정 결과값이 있는 Coroutine을 리턴받았고, 값을 조회하기 위해서는 await()함수를 사용하면 된다.
굳이 저렇게 분리 안 하고 바로 async함수 뒤에 바로 .await()을 붙여버리면 값을 리턴받을 수 있다.
또한 launch도 그렇고 내부적으로 코루틴이 실행될 환경을 다시 정할 수도 있다.
결론적으로 계산 결과가 명확하게 예측되면서 결과를 통해 다른 작업에 활용할 때 사용하면 된다.
3. withContext
async와 await을 하나로 묶어버렸다고 생각하면 된다.
굳이 Deferred<T>객체를 받고 await()함수로 결과값을 받을 게 아니라 바로 결과(T)를 받을 때 사용하면 된다.
그럼 무조건 withContext가 좋은 것 아닌가? 라고 생각할 수 있지만, async로 받으면 결과값을 원하는 시점에 await으로 받을 수 있는 장점이 있다.
그런데 사실 병렬 작업이 필요한 경우가 아니라면, 동일한 로직에서 작업량이 많아질 수록 withContext의 성능이 훨씬 좋다.
심지어 async/await은 밑에서 나올 예외처리에서 설명할 거지만, 굉장히 귀찮고 복잡한 반면에 withContext는 매우 간편하게 작성이 가능하다.
다만 이게 가능한 이유가 withContext는 값을 반환할 때까지 해당 코루틴이 일시정지 되기 때문인데,
비동기 작업을 하기 위해 보통 코루틴을 쓰는데 이걸 굳이 다시 순차적으로 처리한다는 게..이건 이거 나름대로 단점이 있다.
따라서 그때그때 뭘 사용할지 적절히 판단하는 능력을 기르는 게 우선이다.
class CoroutineTest {
@Test
fun test() = runBlocking{
println("doing something in main thread")
CoroutineScope(this.coroutineContext).launch {
// delay(3000)
println("done something in Coroutine")
forTest() // coroutineScope가 달라서 생기는 issue인가??
}
joinAll()
println("done in main thread")
CoroutineScope(this.coroutineContext).launch {
val job1 = withContext(Dispatchers.Default) {
var total = 0
for (i in 1..10) {
total += i
delay(100)
}
println("job1")
total
}
val job2 = withContext(Dispatchers.Default) {
var total = 0
for (i in 1..10) {
delay(100)
total += i
}
println("job2")
total
}
println("result are $job1 and $job2")
}
joinAll()
}
}코드로 구현해보면 대충 이런 식이 되지 않을까?
근데 아까부터 왜 runBlocking이 별로 좋은 방법이 아니라고 해놓고 계속 쓰고 있는 거냐는 의문이 생길 수 있는데
이제 밑에서 해명하겠습니다.
4. runBlocking
runBlocking은 Scope 내의 Coroutine들이 작업이 수행될 때까지 스레드를 점유한다.
이 말은 반대로 풀이하자면 원래는 CoroutineScope로 coroutine을 build하면 점유하지 않기 때문에 작업이 완수되지 않았는데도 Main 함수가 종료되어 버리는 경우가 있다.
조금 간단한 코드를 예시로 보면,
@Test
fun test2() {
println("doing something in main thread")
CoroutineScope(Dispatchers.Default).launch {
delay(3000)
println("done something in Coroutine")
forTest()
}
println("done in main thread")
}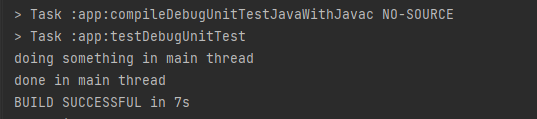
CoroutineScope 내의 작업이 끝나지도 않았는데 main thread가 닫혀버려서 그냥 끝나버렸다.
따라서 이걸 해결하려면 coroutine이 아직 작업이 끝나지 않았다면 Thread를 붙잡아둬야 하기 때문에 runBlocking을 쓴다.
private suspend fun forTest() {
print("Start...")
GlobalScope.launch(Dispatchers.Default) { // Main, IO는 application 환경에서만 살아있는 거라 에러가 발생한다.
val job1 = withContext(Dispatchers.Default) {
var total = 0
for (i in 1..10) {
total += i
delay(100)
}
print("job1")
total
}
val job2 = withContext(Dispatchers.Default) {
var total = 0
for (i in 1..10) {
delay(100)
total += i
}
print("job2")
total
}
print("result are $job1 and $job2")
}
print("End")
}
class CoroutineTest {
@Test
fun test2() = runBlocking {
println("doing something in main thread")
CoroutineScope(this.coroutineContext).launch {
delay(3000)
println("done something in Coroutine")
forTest()
}
joinAll()
println("done in main thread")
}
}이렇게 하면 CoroutineScope가 this.coroutineContext를 인자로 넘겨주었기 때문에 해당 코루틴의 작업이 끝날 때까지는 Thread가 멈추지 않는다.
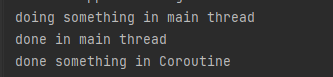
그런데 fortest()의 내용은 실행되지 않은 것을 볼 수 있는데, 얘네는 scope가 Default에서 돌아가기 때문에 test2 함수 입장에선 얘네까지 신경쓰지 않는다. 그래서 done something in Coroutine 출력까지만 보장하고 fortest() 함수따위 기다려주지 않는다.
진짜 개인주의 그 자체.
그런데 runBlocking이 왜 안 좋은가?
현재 함수 내에 선언된 모든 코루틴 작업이 끝날 때까지 쓰레드를 점유하면서 무한정 기다리게 되는 게 바로 문제점이다.
안드로이드에서 UI Thread에 시간이 오래걸리는 어떠한 작업을 runBlocking 함수를 걸어버렸다고 치자.
그런데 긴 시간동안 점유하면서 사용자의 입력을 처리하지 못 하면(보통 5초 이상), ANR(Application Not Responding) 에러가 발생한다.
즉, Coroutine이 Thread를 독점하면서 오랜 시간 응답이 없으면 안드로이드에서는 해당 Thread가 중단되었다고 판단하고 에러로써 간주해버리게 된다.
혹은 다른 작업들을 수행하지 못 하게 막아버림으로써 시스템 전반적인 에러를 야기할 수 있다.
애초에 공식 문서에 따르면 runBlocking은 Main Thread와 Test 용으로만 사용하도록 권장하지만,
개발자들의 이야기를 들어보면 runBlocking을 사용하는 시점부터 이미 Coroutine의 장점을 짓밟아 버리는 것이나 다름 없으니 되도록 사용하지 말라고 한다.
Kotlin Coroutines의 runBlocking은 언제 써야 할까? 잘 알고 활용하자! |
I’m an Android Developer.
thdev.tech
좀 더 자세한 케이스를 알고 싶다면 위 블로그를 참조하면 좋다!
5. actor & produce
여기서 부턴 잠시 넘어갔다가 Channel과 Flow에서 다루도록 하자.
5. Coroutine Job
Kotlin Coroutines의 Job 동작을 알아보자 |
I’m an Android Developer.
thdev.tech
사실 다른 블로그도 엄청나게 참조하고 있는데, 여기가 가장 잘 정리되어 있다.
Job
Job common A background job. Conceptually, a job is a cancellable thing with a life-cycle that culminates in its completion. Jobs can be arranged into parent-child hierarchies where cancellation of a parent leads to immediate cancellation of all its childr
kotlinlang.org
이건 공식 문서 내용이니 참고하자.
위에서 언급했 듯이 launch는 리턴값으로 Job, 즉 coroutine instance를 던져주는데 Job이란 대체 뭘까.
바로 coroutine의 상태를 가지고 있다고 생각하면 된다.
coroutine의 상태는 총 6가지고 3가지로 다시 분류할 수 있다.
| state | notion | |
| New | optional initial state | Job이 생성된다. |
| Active | default initial state | Job이 실행 중이다. |
| Completing | transient state | Job이 실행 완료 중이다. |
| Cancelling | transient state | Job이 취소되는 중이다. |
| Completed | final state | Job이 실행 완료되었다. |
| Cancelled | final state | Job이 실행 취소되었다. |
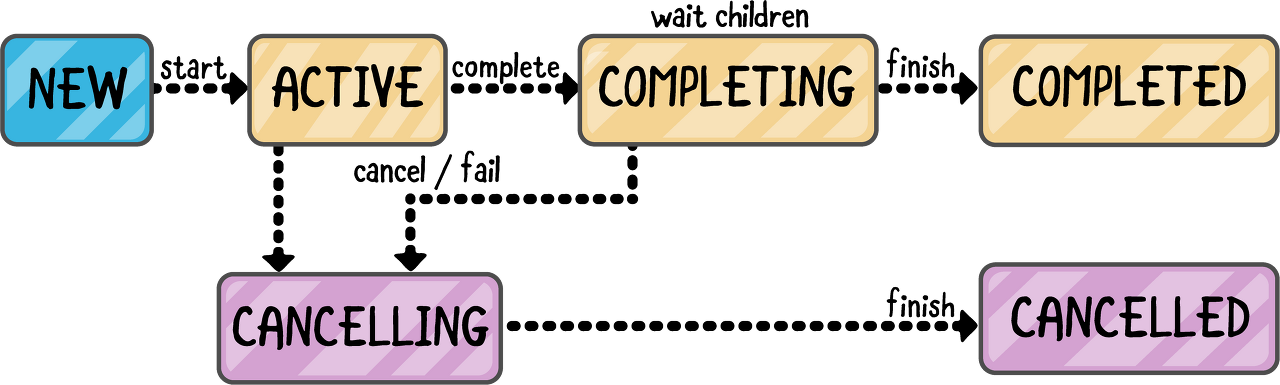
즉, launch를 이용해서 coroutine의 state 정보를 얻었기에, 임의로 흐름을 컨트롤할 수 있게 되는 것이다.
애초에 Coroutine을 왜 사용하는가? 비동기적인 작업을 통해서 뭔가 개선하고 싶었던 건데,
그 중 하나가 다양한 작업을 cpu에 부담을 주지 않으면서 거의 동시에 해결할 수 있다는 점이었고
다른 하나는 서버에 데이터를 요청했을 때, 응답이 없다면 그걸 무한정 기다릴 것이 아니라 일정 시간을 넘어가면 coroutine의 실행 성공 여부와 상관없이 즉시 중단해야 한다.
물론 중단 뿐만 아니라 다른 것들에 대한 컨트롤이 필요한데 종류는 총 5가지이다.
- start : 현재 coroutine 동작 상태 확인. 동작 중이라면 true, 준비 혹은 완료 상태라면 false
- join : 현재 coroutine 작업이 끝날 때까지 대기한다. async/await처럼 쓸 수 있다.
- cancel : 현재 coroutine의 종료 신호를 보내고, 정상 종료 여부에 대해 대기하지 않는다.
- cancelAndJoin : 현재 coroutine을 종료하라고 신호를 보내고, 정상 종료까지 대기.
- cancelChildren : Scope 내의 children coroutine들을 종료하고 부모는 취소하지 않는다.
class CoroutineTest {
@Test
fun test2() = runBlocking(Dispatchers.Default) {
val job = CoroutineScope(Dispatchers.Default).launch {
delay(1000)
println("I'm job")
}
println("end")
}
}아까 전부터 계속해서 나왔던 코드였는데 여기서 join을 썼던 이유를 드디어 설명할 수 있다!
우선 runBlocking을 자꾸 해주는 이유는 내가 Main에서 실행을 시키지 않고, 테스트 환경에서 실행하다보니 결과를 기다리기도 전에 자꾸 Thread가 종료되어 버려서 CoroutineTest와 일치하는 coroutineScope를 지정해줄 필요가 있었다.
방법 중 하나는 runBlocking을 함으로써 점유할 Thread를 알려주기 위해 this.coroutineContext로 인자값을 주거나, 점유할 Thread를 따로 던져줘서 일치시킬 수도 있다.
문제는 위의 상태만으로는 launch로 build된 코루틴의 작업이 완료될 때까지 기다린다는 보장이 없다.
class CoroutineTest {
@Test
fun test2() = runBlocking(Dispatchers.Default) {
val job = CoroutineScope(Dispatchers.Default).launch {
delay(1000)
println("I'm job")
}
job.join()
println("end")
}
}하지만 job.join() 혹은, job이 여러 개가 있다면 joinAll() 등을 호출해서 특정 코루틴의 작업이 종료될 때까지 기다릴 수 있다.
마치 async 함수로 리턴된 값을 await()으로 받지 않으면 코루틴이 계속 실행되고 있는 것과 같다.
반대로 취소하기 위해서는 .cancel()을 해주면 되는데 정확히 어떤 이유로 취소되었는지 알고 싶으니 인자를 좀 더 추가해보자.
class CoroutineTest {
@OptIn(InternalCoroutinesApi::class)
@Test
fun test2() = runBlocking(Dispatchers.Default) {
val job = CoroutineScope(Dispatchers.Default).launch {
delay(1000)
println("I'm job")
}
// job.cancel()
job.cancel("job cancelled", InterruptedException("cancelled"))
println(job.getCancellationException())
println("end")
}
}
필요에 의해 코루틴을 직접 취소해야 하는 경우 이런 방식을 사용할 수 있다.
🤔 Job이 N개라면, N개의 state를 모두 들고 있어야 하는가?
개발자들은 N개의 데이터를 각각 모두 선언해야 하는 꼴을 절대 두고 보지 못 한다.
하나의 Job을 생성해 CoroutineScope 혹은 launch의 인자로 던져주어, N개의 job을 한 번에 종료할 수 있다.
물론, 특정 Job만을 따로 컨트롤하고 싶다면 val job = CoroutineScope() 로 받아주면 된다.
class CoroutineTest {
@Test
fun test2() = runBlocking {
val job = Job()
CoroutineScope(Dispatchers.Default + job).launch {
println("I'm job1")
CoroutineScope(Dispatchers.Default + job).launch {
for (nbr in 0..10) {
if (isActive) {
println("job2 $nbr")
delay(1)
} else {
break
}
}
}
val job3 = launch {
for (nbr in 0..10) {
if (isActive) {
println("job3 $nbr")
delay(1)
} else {
break
}
}
}
job3.join()
}
delay(10)
job.cancel()
println("end")
}
}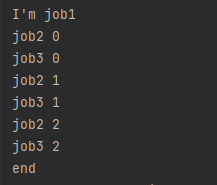
나는 이런 결과가 나왔는데, 실행 환경에 따라 결과는 천차만별이다.
6. Coroutine Context
Coroutine Scope의 인자값으로 던져주어야 하는 값이다.

쉽게 설명하자면 Coroutine Scope를 어느 환경에서 실행시킬 것인지를 묻는 것이라고 생각하면 된다.
지금까지 Dispatcher를 이용해서 넘겼었는데, Dispatcher는 코루틴이 실행될 Thread 풀을 관리하는 역할을 가지기 때문에 Main, IO, Default 의 스레드 환경을 명시해주었다고 보면 된다.
이것말고도 CoroutineExceptionHandler도 CoroutineContext 자리에 들어갈 수 있는데, 둘 다 CoroutineContext를 확장하는 인터페이스이기 때문이다.
CoroutineDispatcher
public abstract class CoroutineDispatcher :
AbstractCoroutineContextElement(ContinuationInterceptor), ContinuationInterceptor {CoroutineExceptionHandler
public inline fun CoroutineExceptionHandler(crossinline handler: (CoroutineContext, Throwable) -> Unit): CoroutineExceptionHandler =
object : AbstractCoroutineContextElement(CoroutineExceptionHandler), CoroutineExceptionHandler {
override fun handleException(context: CoroutineContext, exception: Throwable) =
handler.invoke(context, exception)
}
결과적으로 Thread를 넘겨주는 Dispatcher나, 예외 처리를 다루는 ExceptionHandler 모두 Coroutine이 실행되는 환경 일부라고 판단하는 것이다.
자, 이제 Coroutine Context 내부 로직을 전부 까보자!
보다 자세한 내용이 필요하다면 공식 문서를 참고하자.
public interface CoroutineContext {
/**
* Returns the element with the given [key] from this context or `null`.
*/
public operator fun <E : Element> get(key: Key<E>): E?
/**
* Accumulates entries of this context starting with [initial] value and applying [operation]
* from left to right to current accumulator value and each element of this context.
*/
public fun <R> fold(initial: R, operation: (R, Element) -> R): R
/**
* Returns a context containing elements from this context and elements from other [context].
* The elements from this context with the same key as in the other one are dropped.
*/
public operator fun plus(context: CoroutineContext): CoroutineContext =
if (context === EmptyCoroutineContext) this else // fast path -- avoid lambda creation
context.fold(this) { acc, element ->
val removed = acc.minusKey(element.key)
if (removed === EmptyCoroutineContext) element else {
// make sure interceptor is always last in the context (and thus is fast to get when present)
val interceptor = removed[ContinuationInterceptor]
if (interceptor == null) CombinedContext(removed, element) else {
val left = removed.minusKey(ContinuationInterceptor)
if (left === EmptyCoroutineContext) CombinedContext(element, interceptor) else
CombinedContext(CombinedContext(left, element), interceptor)
}
}
}
/**
* Returns a context containing elements from this context, but without an element with
* the specified [key].
*/
public fun minusKey(key: Key<*>): CoroutineContext
/**
* Key for the elements of [CoroutineContext]. [E] is a type of element with this key.
*/
public interface Key<E : Element>
/**
* An element of the [CoroutineContext]. An element of the coroutine context is a singleton context by itself.
*/
public interface Element : CoroutineContext {
/**
* A key of this coroutine context element.
*/
public val key: Key<*>
public override operator fun <E : Element> get(key: Key<E>): E? =
@Suppress("UNCHECKED_CAST")
if (this.key == key) this as E else null
public override fun <R> fold(initial: R, operation: (R, Element) -> R): R =
operation(initial, this)
public override fun minusKey(key: Key<*>): CoroutineContext =
if (this.key == key) EmptyCoroutineContext else this
}
}
CoroutineContext interface 내부에는 4가지 메서드가 있음을 확인할 수 있다. 각각의 기능을 알아보자.
1. Coroutine Context Method
- public operator fun <E : Element> get(key: Key<E>): E?
인자로 던져진 key에 해당하는 Context 요소를 반환한다.
- public fun <R> fold(initial: R, operation: (R, Element) -> R): R
초기값(initial Value)을 베이스로 하여 제공되어진 병합 함수(operation)를 사용해 컨텍스트 요소들을 병합 후 결과를 반환하는 함수
- public operator fun plus(context: CoroutineContext): CoroutineContext = ...impl...
기존의 Context와 parameter로 주어진 context가 가지는 요소들을 모두 포함하여 새로운 Context를 반환한다.
- public fun minusKey(key: Key<*>): CoroutineContext
기존의 Context에서 key를 가지는 요소를 제외한 새로운 Context를 반환한다.
2. key와 Element
코드에 선언되어 있듯이 key는 Element타입을 Generic으로 가진다. 나중에 Context에 Element를 등록시킬 때, Key를 이용한다고 보면 된다.
Element는 CoroutineContext를 상속하고 있다. 멤버 변수로 키를 가지고 있음을 알 수 있다.
즉, Key에 속하는 Element는 CoroutineContext를 구성하고 있는 요소들을 말하며 Dispatcher, CoroutineIntercepter, CoroutineExceptionHandler 등이 있다.
3. Coroutine Context implementation
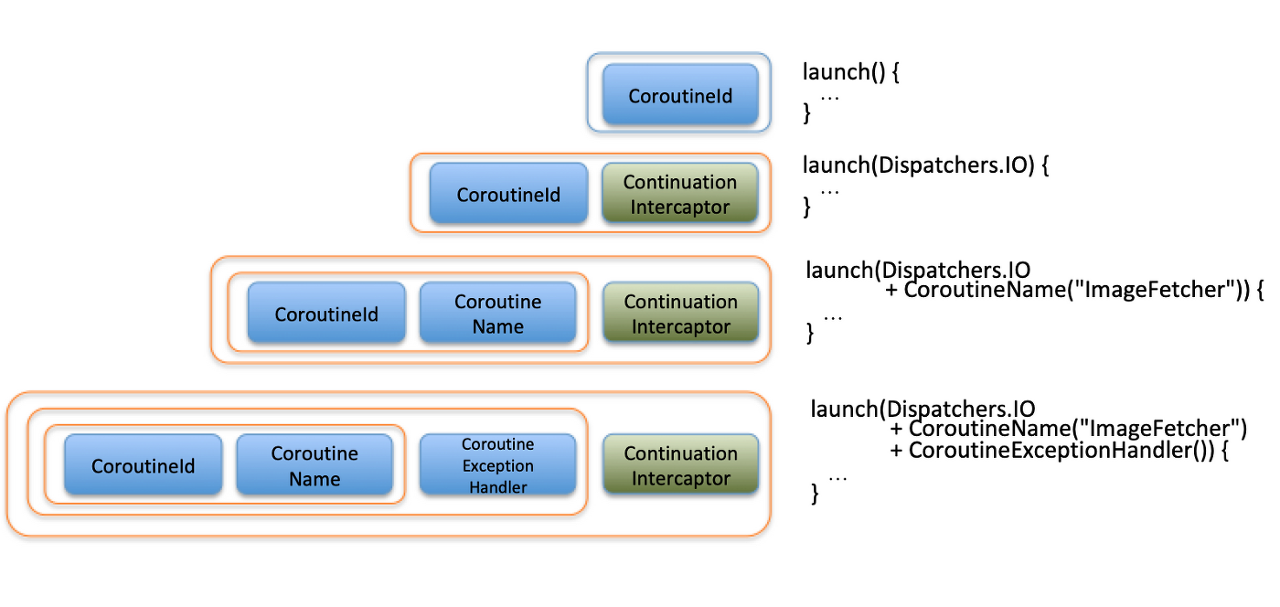
CoroutineContext는 3가지 구현체가 존재한다.
① EmptyCoroutineContext(default Context) : Context를 명시하지 않으면, GlobalScope에 사용된 context이다.
② CombinedContext : 2개 이상의 컨텍스트를 명시해주면 Context간 연결을 해주는 컨테이너 역할 담당의 Context
③ Element : Context의 각 요소들도 CoroutineContext를 구현한다.
아..힘들어 죽겠다.
좀 더 친절한 설명과 작동 원리를 이해하고 싶다면 아래의 블로그를 참조하자.
[Coroutine] 11. Coroutine CoroutineContext를 다루는 방법 : Coroutine Dispatcher과 ExceptionHandler을 CoroutineContext를
CoroutineContext 앞서 우리는 다음의 내용들을 배웠다. Dispatcher: 코루틴이 실행될 스레드 풀을 잡고 있는 관리자 CoroutineExceptionHandler: 코루틴에서 Exception이 생겼을 때의 처리기 그런데 이 두 가지 요
kotlinworld.com
추가적으로 어쩌다 찾은 내용인데
@Test
fun test2() = runBlocking {
CoroutineScope(newSingleThreadContext("my Thread"))
}Dispatcher을 이용하지 않고 이런 방법도 가능하다고 한다...🙄
7. Coroutine Exception Handling
이 부분은 내용이 너무 많고 복잡해서, 위에서도 대충 슥 넘어갔는데 여긴 진짜 나중에 안드로이드 앱 개발하면서 다시 수정하러 올 예정..너무 어렵다.
코루틴이 작업을 수행하다가 예외가 발생한다면 어떻게 처리해야 할까?
일단 두 가지로 보통 분류를 한다.
- 예외를 외부로 전파(propagation)하는 부류: launch, actor
- 예외를 노출(exposing)시키는 부류: async, produce
이게 무슨 말인가 싶지만 launch와 async만 놓고 비교를 해보자.
launch는 코루틴을 실행하는 빌더였고, exception에 걸린다면 바로 예외가 발생할 것이다.
그런데 async는 await()로 값을 받기 전까지는 exception에 걸린 부분이 드러나지가 않는다.
따라서 예외를 처리하는 방법도 바뀐다.
Job이랑 withContext에 대해서도 다뤄야 하는데 너무 많아서 설명을 깔끔하게 못 하겠다.
우선적으로 알아야 할 것은 Coroutine은 (취소를 제외한)예외가 발생했을 때, 부모의 코루틴까지 모두 취소시켜버린다.
structured concurrency를 유지하기 위한 수단으로써 이건 막을 수 없는 과정이다.
다만 앱이 종료되는 최악의 상황은 방지해야 하므로 CoroutineExceptionHandler를 설정하여 사후 처리만을 할 수 있다.
[Kotlin] Coroutines - Exception Handling and Supervision
목차 예외 전달 CoroutineExceptionHandler 코루틴의 취소와 예외 예외가 여러 개라면 Supervision Supervision job Supervision scope Supervisor job에서의 예외 처리 참고 문헌 코루틴이 취소되면 CancellationException이 발
thinking-face.tistory.com
Coroutine의 Async와 await 사용시 Exception Handling에 관하여 #Kotlin
Coroutine을 사용하면서 한가지 주의해야 할 부분이 있는데요. Async와 await메소드를 사용할 때, Exception Handling에 관한 부분입니다. 오늘은 이것에 관해서 정리해 보겠습니다. 1. await와 Exception Handling
developer88.tistory.com
[Kotlin] 코틀린 - 코루틴#5 - exception
이 글은 아래 링크의 내용을 기반으로 하여 설명합니다. https://github.com/Kotlin/kotlinx.coroutines/blob/master/coroutines-guide.md 또한 예제에서 로그 print시 println과 안드로이드의 Log.e()를 혼용합니다. Exception
tourspace.tistory.com
Coroutine 에서의 Error handling
코루틴에서의 예외처리를 한번 살펴봅니다.
co-zi.medium.com
진짜 아무리 내용을 수정해도 잘 설명할 자신이 아직 없어서 그냥 참고하던 블로그 전부 올려버렸다.
올해 안으로 수정하러 온다..!
8. Channel & Flow
이건 Coroutine을 어느정도 이해했다면 너무 당연한 이야기들이라 개념적으로 어려운 내용은 아니다.
물론 안다고 해서 실제로 사용할 수 있는 건 아니더라..빨리 어플리케이션 개발을 해봐야 할 듯하다.
시작하기 전에 한 가지 코드를 보고 넘어가자.
class CoroutineTest {
@Test
fun test2() = runBlocking {
val values = withContext(Dispatchers.Default) {
getValue()
}
for (v in values) println("value : $v")
}
}
private fun getValue() : MutableList<Int> {
val list = mutableListOf<Int>()
repeat(5) {
list.add(it)
}
return list
}지금은 runBlocking을 걸어버렸으니 당연히 값을 가져오는데 문제가 없겠지만 UI Thread 환경에서 runBlocking이 걸리지 않은 상태라고 가정해보자.
getValue는 단순히 0부터 5까지의 값을 list에 넣어서 돌려주기만 하는 기능이지만, 뭐 대충 연속적인 일련의 수를 가져오는 어떠한 함수라고 치자.
getValue는 coroutine에서 돌아가는데 만약 정상적으로 list를 리턴하지 못 하고 종료되어 버리는 경우도 있겠지만, 그보다 값을 받아오기 전에 for문으로 넘어가버리면 뭔가 로직 자체가 꼬일 수 있다.
이걸 해결하기 위해서 Coroutine에서 생성된 값을 파이프 라인을 통해 전달해준다고 보면 된다.
그렇다면 Channel과 Flow는 뭐가 다른 걸까?
1. Channel
class CoroutineTest {
@Test
fun test2() = runBlocking {
val channel = Channel<Int>()
CoroutineScope(Dispatchers.Default).launch {
repeat(5) {
channel.send(it)
}
}
CoroutineScope(Dispatchers.Default).launch {
for (value in channel) {
println("value : $value")
}
}
println("")
}
}혹은
@Test
fun test2() = runBlocking {
val channel = Channel<Int>()
launch {
repeat(5){
channel.send(it)
}
}
repeat(5) {
println("value : ${channel.receive()}")
}
}이런 식으로도 받을 수 있다.
아직 능숙하질 않아서 여러가지 예시를 들지는 못 하지만 channel이 한 쪽에서 보내면, 다른 한 쪽에선 받을 수 있게끔 통로 역할을 해준다는 것 정도는 알 수 있을 것이다.
이거 말고도 이 과정을 더 간단히 만들어주는 것이 있는데 produce를 사용하면 된다.
@Test
fun test2() = runBlocking {
val channel = produce<Int> {
repeat(5) {
channel.send(it)
}
}
repeat(5) {
println("value : ${channel.receive()}")
}
}하지만 Channel에는 한 가지 단점이 있는데, receive하는 곳에 닿기도 전에 데이터를 일단 보내기 시작한다.
이것때문에 Channel을 Hot이라고 하는데, 그럼 Flow는? Cold라고 부른다. (뻔하다 뻔해.)
2. Flow
@Test
fun test2() = runBlocking {
val flow: Flow<Int> = flow {
repeat(5) {
emit(it)
}
}
launch {
flow.collect { value ->
println("value : $value")
}
}
println("")
}Flow는 collect를 호출하기 전까지는 emit도 하지 않는다.
즉, 작업을 정의해놓고 정작 호출부는 따로 있는 셈이다.
Flow는 몇가지 재밌는 점이 있는데, flow builder 내에서 다른 suspend함수나 delay 등을 호출하는 것은 가능하지만, Coroutine Builder를 호출해 dispatcher를 변경하는 것은 불가능하다.
만약 Flow가 수행되는 Thread를 변경하고자 한다면 flowOn Method를 사용해야 한다.
@Test
fun test2() = runBlocking {
val flow: Flow<Int> = flow {
repeat(5) {
emit(it)
}
}.flowOn(Dispatchers.Default)
launch {
flow.collect { value ->
println("value : $value")
}
}
println("")
}flow에 stream으로 전달되는 값들은 당연히 map함수 같은 람다식으로 가공할 수 있다.
@Test
fun test2() = runBlocking {
val flow: Flow<Int> = flow {
repeat(5) {
emit(it)
}
}.flowOn(Dispatchers.Default)
launch {
flow.map {
it * 10
}.collect { value ->
println("value : $value")
}
}
println("")
}
Callback으로 전달받은 데이터를 Coroutines의 Channel로 처리해보자. |
I’m an Android Developer.
thdev.tech
이 부분도 나중에 보완할 내용이긴 한데, 미래의 나를 위해 여기 남겨둔다.