request와 response 먼저 다루려고 했는데, 생각해보니 직렬화와 역직렬화를 이해하지 못하면 의미가 없다.
둘을 한 번에 써버리자니 내용이 중구난방일 것 같아 분리했다.
아직까진 클라이언트로 받는 데이터가 아닌 drf 내부에서 자체적으로 예시를 만들어서 출력 결과만 확인할 것이다.
목차
1. What is Serializer?
2. Serializer & Deserializer
3. Mutiple Serializer
4. Nested Serializer
1. What is Serializer?
[DRF] 1. What is DRF?
원래 장고부터 차근차근 포스팅을 해야 하는데 티스토리는 일일 포스팅 제한 수가 15개다. 알고리즘 문제 솔루션만 100문제에 언어 카테고리만 올려도 포스팅이 200~300개는 그냥 넘어갈텐데 컨텐
jaeseo0519.tistory.com
직렬화의 개념은 가장 첫 포스팅에서 다뤘었다.
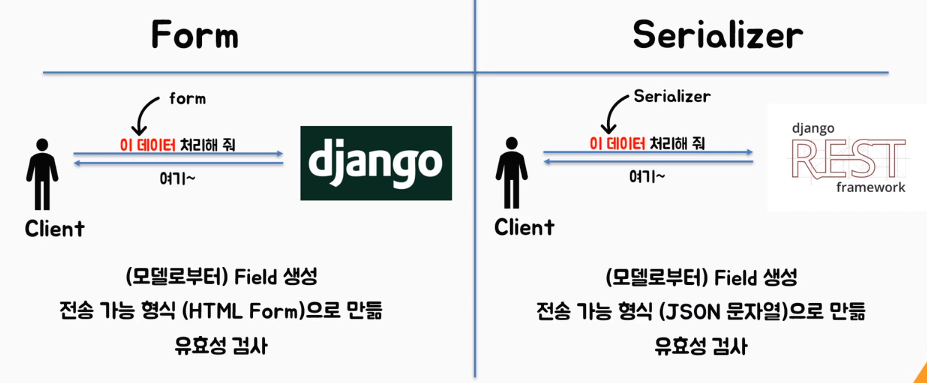
DB와 프론트에서 다루는 언어가 다르다보니 중간에서 번역을 해줄 필요성이 생겼는데 이 번역이라는 게 바로 직렬화라고 생각하면 된다.
프론트 엔드 개발을 리액트로 한다고 가정하면 폼 태그에서 입력받은 정보를 DRF로 보내서 DB에 저장해야 하는 경우 Json 타입의 데이터를 DB는 해석할 수 없다.
반대로 쿼리셋의 타입을 그대로 리액트에게 던져주면 똑같은 현상이 벌어진다.
이로 인해 중재자인 DRF가 직렬화의 경우 Json을 byte로 바꾸고, 역직렬화의 경우엔 byte data를 Object나 특정 데이터 타입으로 변경해주는 것을 의미한다.
어렵게 생각하지 말고 있는 그대로 받아들이면 된다.
다만, serializer가 DRF의 핵심적인 기능이라고 말할 수 있는 이유는 단순 번역 이상의 기능을 지원하기 때문이다.
2. Serializer & Deserializer
1. Serializer
보통 JSON을 DB에 저장하기 위해 byte data로 만드는 직렬화의 경우는 클라이언트의 요청에 의해 새로운 정보를 추가하는 경우일 확률이 높다. 어디까지나 확률론이다.
어쨌든 원래라면 POST 요청을 받아서 DB에 등록을 해야하는데, 아직까진 request에 대해 다룬 적이 없으므로 GET 요청으로 순수하게 serializer가 돌아가는 것까지만 확인할 것이다.
밑에서 create를 한다면서 list 함수를 오버라이딩하고 있다고 헷갈리지 말자.
pets/models.py
from django.db import models
from django.contrib.auth import get_user_model
from django.utils import timezone
import uuid
import base64
import codecs
def generate_random_slug_code(length=8): # 랜덤 문자열 생성
"""
generates random code of given length
"""
return base64.urlsafe_b64encode(codecs.encode(uuid.uuid4().bytes, "base64").rstrip()).decode()[
:length
]
CustomUser = get_user_model()
class Pet(models.Model):
pet_id = models.BigAutoField(primary_key=True, unique=True, verbose_name="pet_id")
pet_name = models.CharField(max_length=45, verbose_name="pet_name")
birthday = models.DateField()
gender = models.CharField(max_length=45)
code = models.CharField(
max_length=45,
unique=True,
editable=False,
default=generate_random_slug_code,
verbose_name="code",
)
profile_img = models.ImageField(blank=True, null=True)
master = models.ForeignKey(
CustomUser, on_delete=models.CASCADE, db_column="user_id", related_name="master"
)
def __str__(self):
return self.pet_nameapi/pets/views.py
class PetViewSet(ModelViewSet):
queryset = Pet.objects.all()
serializer_class = PetSerializer
def list(self, request):
passapi/pets/serializers.py
from rest_framework import serializers
from pets.models import *
class PetSerializer(serializers.ModelSerializer):
class Meta:
model = Pet
fields = '__all__'현재로써 PetViewSet은 아무런 기능도 하지 않는다.
여기서 유저로부터 새로운 Pet 데이터를 입력받아서 DB에 등록하고 싶다는 상황을 가정하고 직접 데이터를 일단 만들어보자.
def list(self, request):
request_data = {
'pet_name': "새로운 반려동물",
"birthday": "2022-08-30",
"gender": "male",
"master": 1
}
pet_serializer = self.get_serializer(data=request_data)
print(pet_serializer)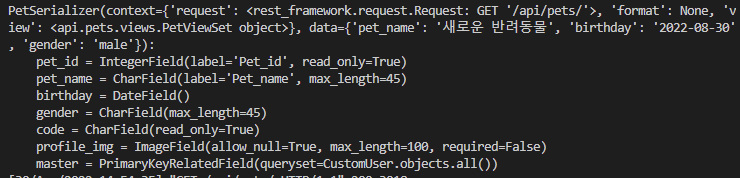
직렬화 과정에선 serializer의 data 매개변수에 던져주어야 한다.
request data를 임의로 작성해서 serializer를 돌려보았더니 뭐가 되긴 됐는데 이해할 수 없는 용어로 가득차 있다.
serializer 안의 데이터를 직접 확인하고 싶다면 어떻게 해야할까? 총 3가지 방법이 있다.
def list(self, request):
request_data = {
'pet_name': "새로운 반려동물",
"birthday": "2022-08-30",
"gender": "male",
"master": 1
}
pet_serializer = self.get_serializer(data=request_data)
print(" === 1. initial_data === ")
print(pet_serializer.initial_data)
pet_serializer.is_valid(raise_exception=True) # 유효성 검사
print(" === 2. validated_data === ")
print(pet_serializer.validated_data)
pet_serializer.save() # DB 등록
print(" === 3. data === ")
print(pet_serializer.data)
- initial_data : 유효성 검사를 하기 전에 접근 가능
- validated_data : 유효성 검사를 통과한 후에 접근 가능
- data : 유효성 검사를 통과하고 save된 후에 접근 가능
💡 직렬화가 끝난 serializer의 data 접근 방법이 다른 이유?
역직렬화와 달리 직렬화는 클라이언트로 부터 입력받은 검증되지 않는 정보를 번역과 동시에 '검증된' 데이터임을 낙인찍는 과정이다.
그런데 이 데이터를 백엔드 개발자가 또 조회한다면 그 과정에서 어떤 오류가 발생할지 예측할 수 없게 된다.
따라서 serializer가 유효성 검사를 하기 전과 후에 따라 접근 방법이 달라지는 것이다.
역직렬화의 경우에는 이미 검증된 데이터를 클라이언트에게 던져주는 과정이므로 물고 씹고 뜯든 개의치 않는다.
2. Deserializer
이번엔 반대로 DB에 등록된 데이터를 꺼내올 것이다.

방금 전에 등록된 펫의 pet_id 값이 10인 것을 이용하여 받아오자.
def list(self, request):
pet_query = Pet.objects.get(pet_id=10)
pet_serializer = self.get_serializer(pet_query)
print(pet_serializer.data)
직렬화 과정과는 달리 역직렬화가 끝나자마자 data에 접근이 가능하다.
참고로 역직렬화의 경우엔 data가 아니라 instance의 인자로써 넘어가게 된다.
3. 정리
위의 과정들이 가능했던 이유는 모두 serializer를 통해 번역 과정을 거쳐갔기 때문이다.
하지만 직렬화 과정에서 봤던 것처럼 serializer란 검증된 데이터를 판단하는 메서드 또한 존재한다.
.is_valid() 를 실행했을 때 validate 함수가 실행된다.
class CustomUserSerializer(serializers.ModelSerializer):
class Meta:
model = CustomUser
fields = "__all__"
extra_kwargs = {"password": {"write_only": True}}
def create(self, validated_data):
password = validated_data.get("password")
instance = self.Meta.model(**validated_data)
if password is not None:
instance.set_password(password)
instance.save()
return instance
def validate(self, attrs):
nickname = attrs["nickname"]
password = attrs["password"]
if CustomUser.objects.filter(nickname=nickname).exists():
raise serializers.ValidationError("이미 존재하는 닉네임입니다.")
validate_password(password)
return attrs한 가지 예시로써 회원가입 시에 nickname 중복 검사를 수행하는 기능을 구현할 수도 있다.
이 외에도 serializer의 메서드를 오버라이딩하여 다양한 기능을 만들 수는 있다.
serializer을 잘 활용하면 View의 코드를 획기적으로 줄일 수 있게 된다.
3. Multiple Serializer
만약 여러 개의 데이터를 때려넣어도 serializer는 제대로 작동할까?
def list(self, request):
pet_query = self.queryset.all()
pet_serializer = self.get_serializer(pet_query)
print(pet_serializer.data)
에러창이 뜨면서 뭐라고 알려주는데, 잘은 모르겠지만 QuerySet 타입을 넘겨주는 것이 문제인 듯 하다.
serializer는 정확히 말하자면 Queryset이 아니라 쿼리셋 안에 들어있는 Object를 넘겨주어야 한다.
마치 for문으로 list 요소 값을 in 을 이용하여 하나씩 던져주듯이 Serializer를 호출할 때도 미리 알려주면 된다.
def list(self, request):
pet_query = self.queryset.all()
pet_serializer = self.get_serializer(pet_query, many=True)
print(pet_serializer)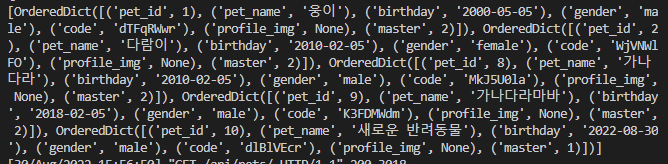
many=True를 추가해주면 쿼리셋 내의 모든 객체에 대해 역직렬화를 수행한다.
직렬화의 경우에도 동일하게 수행하면 된다.
def list(self, request):
request_data = [
{
'pet_name': "새로운 반려동물2",
"birthday": "2022-07-30",
"gender": "male",
"master": 5
},
{
'pet_name': "새로운 반려동물3",
"birthday": "2022-06-30",
"gender": "female",
"master": 8
}
]
pet_serializer = self.get_serializer(data=request_data, many=True)
pet_serializer.is_valid(raise_exception=True)
pet_serializer.save()
print(pet_serializer.data)
🤔 여러 모델의 instance를 생성하는 방법
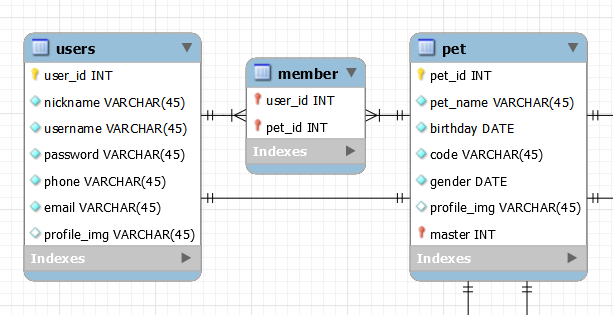
위에서 언급을 안 했었지만 사실 Pet data를 추가할 때, 추가해야할 정보가 한 두가지가 아니다.
그 중 하나는 Pet을 관리하는 N명의 member의 정보를 만들기 위해 닉네임을 입력받는데 포맷 형식이 이렇다.
그런데 입력받은 Pet의 정보가 N마리라면 member data를 따로 빼놨다가 펫에 대한 데이터가 정상적으로 DB에 저장되어 pet_id가 할당되면 그 후에 멤버 테이블을 저장할 수 있다.
이 과정에서 many=True를 해도 정상적으로 작동하지 않을 수 있는데 이 경우 해결방법은 2가지이다.
1. serializer __init__ overriding
class ThingSerializer(serializers.ModelSerializer):
def __init__(self, *args, **kwargs):
many = kwargs.pop('many', True)
super(ThingSerializer, self).__init__(many=many, *args, **kwargs)
class Meta:
model = Thing
fields = ('loads', 'of', 'fields', )2. get_serializer overriding
class CreateListModelMixin(object):
def get_serializer(self, *args, **kwargs):
""" if an array is passed, set serializer to many """
if isinstance(kwargs.get('data', {}), list):
kwargs['many'] = True
return super(CreateListModelMixin, self).get_serializer(*args, **kwargs)처음에 몇 번 써봤었는데 경험상 어지간히 쓸 일이 없다.
대부분 view와 serializer만 잘 쓸 수 있으면 다른 해결방법이 수두룩하다.
4. Nested Serializer
위의 모델을 다시 끌고 와서 이번에는 펫 정보와 함께 멤버 정보도 함께 얻는 경우를 생각해보자.
master의 이름을 가져오는 건 FK로 연결되어 있으므로 별도의 serializer가 필요하진 않다.
하지만 member 정보의 경우 닉네임을 이용해서 user의 정보를 가져와야만 하는데
request.data에서 member의 nickname 리스트를 따로 빼서 2~3개의 역직렬화를 수행해야 할까?
이런 케이스를 중첩된 시리얼라이저라고 하는데 매우 간단하게 해결할 수 있는 방법이 존재한다.
def list(self, request):
pet_query = self.queryset.get(pet_id=1)
serializer = MemberListSerializer(pet_query)MemberListSerializer라는 클래스에 pet_query를 치자.
1번 펫은 master을 참조하는 FK를 가짐과 동시에 자신을 참조하는 N개의 member 레코드 또한 존재한다.
이걸 굳이 view에서 찾아서 넘겨주지 않아도 serializer는 해당 모델이 그런 요소들을 가지고 있음을 인지하고 있다.
그말은 즉슨 그냥 역참조 해버리면 끝나버린다.
class MemberSerializer(serializers.ModelSerializer):
master = serializers.StringRelatedField()
member = serializers.SerializerMethodField(source='member_set')
class Meta:
model = Pet
fields = ['pet_id', 'master', 'member']
def get_member(self, obj):
return obj.member_set.annotate(
username = F('user_id__username'),
nickname = F('user_id__nickname'),
profile_img = F('user_id__profile_img')
).values('user_id', 'username', 'nickname', 'profile_img')master는 serializers.StringRelatedField를 이용하면 User의 __str__함수가 리턴하는 username 정보를 가져온다.
member의 경우에는 원래 member_set이라는 필드명으로 받아야 하지만 source 값으로 원래 필드명을 던져주고 대체 필드명으로 값을 받는 것이 가능하다.
serializers.SerializerMethodField를 이용하면 'get_(필드명)'을 정의함으로써 현재 pet_id가 1인 펫 객체를 obj가 받아온다. 여기서 method_name을 함수 안에 인자로 던져주면 함수 이름도 변경할 수 있다.
obj를 이용하여 역참조를 써버리면 member의 정보를 가져올 수 있게 된다.
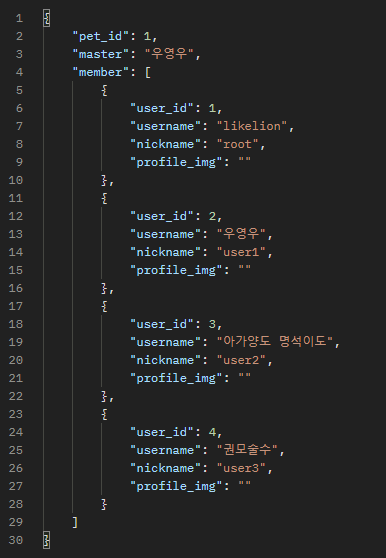
다만 데이터를 받아서 DB에 저장해야 하는 경우엔 멤버 테이블을 분리해야 하므로 아래 포스팅을 참고하면 된다.
[DRF] Concept Part - Transaction
drf 개발을 하면서 배운 내용들을 정리하기 위해선 ORM부터 view와 serializer의 내부 작동 원리와 로직, 관계형 모델의 정보를 참조/역참조를 통해 정보를 조회하는 것부터 차근차근 정리하는 것이
jaeseo0519.tistory.com