drf 개발을 하면서 배운 내용들을 정리하기 위해선 ORM부터 view와 serializer의 내부 작동 원리와 로직,
관계형 모델의 정보를 참조/역참조를 통해 정보를 조회하는 것부터 차근차근 정리하는 것이 맞지만
해당 기술은 너무 신박하고 재밌는 반면 DRF로 트랜잭션을 사용한 포스팅이 많이 보이지 않아서
우선적으로 포스팅을 하여 정리해두기로 했다.
기본적인 DB 개념과 DRF에서 모델 참조/역참조를 할 수 있으며,
View와 Serializer 등 기초적인 개념들은 모두 숙지하고 있다는 가정하에 진행된다.
목차
1. What is Transaction?
2. ACID
3. use Transaction
4. transaction.atomic() 주의사항
5. 참고 자료
1. What is Transaction?
트랜젝션은 DRF가 아니라 Django에서 지원하는 기능이다.
더 엄밀히 따지자면 DB의 기초 개념에 속하기 때문에 DRF보단 DB 카테고리에 어울리지 않을까 싶다.
Database transactions | Django documentation | Django
Django The web framework for perfectionists with deadlines. Overview Download Documentation News Community Code Issues About ♥ Donate
docs.djangoproject.com

Transactions은 DataBase State 변화를 유발하는 논리적 기능을 수행하기 위한
하나 혹은 다수의 동시 수행을 하는 일련의 연산을 말한다.
Transactions이 활성 상태가 아니면 쿼리는 즉시 DB에 저장된다.
간단하게 한 줄 요약하면 DB 관리할 때, 안전성을 보장하기 위한 기능이다.
예를 들어서 계좌에서 지인에게 돈을 송금을 하는 상황을 가정하자.
분명히 내 통장에서 돈은 빠져나갔는데, 지인에게 송금하는 과정에서 시스템이 멈춘다면 내 돈은 증발해버린다.
이 상황을 조금 시스템 내부적으로 들여다보면 여러 DB를 Read하고 Update하는 과정에서 일부 로직이 수행되지 않았음을 의미한다.
그렇다면 이 일련의 과정을 transaction으로 묶어버리고 한 가지 연산에서 이슈가 발생하면 해당 연산 자체를 무효화 시켜버림으로써 데이터의 유효성을 보장하는 것이다.
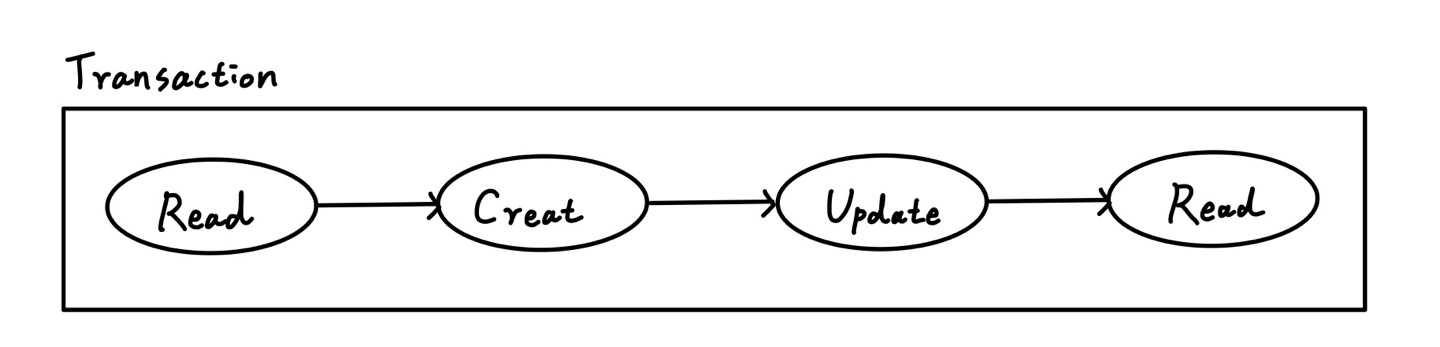
하나의 Transaction은 Commit 되거나 Rollback 되는데, 이런 일련의 과정이 안전하게 작동하기 위해 ACID가 지켜져야 한다.
여기서부턴 혼자 공부하려고 찾아본 개념파트라 실제 사용 방법과 예시는 저 아래로 내려가면 된다.
2. ACID
ACID - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 다른 뜻에 대해서는 애시드 문서를 참고하십시오. ACID(원자성, 일관성, 고립성, 지속성)는 데이터베이스 트랜잭션이 안전하게 수행된다는 것을 보장하기 위한
ko.wikipedia.org
트랜잭션 - 해시넷
트랜잭션(transaction)이란 "쪼갤 수 없는 업무 처리의 최소 단위"를 말한다. 거래내역이라고도 한다. '트렌젝션'이 아니라 '트랜잭션'이 올바른 표기법이다. 영어로 간략히 Tx라고 표기하기도 한다.
wiki.hash.kr
acid는 산을 의미하는 것이 아니라, Atomicity-Consistency-Isolation-Duration의 앞글자를 딴 용어이다.
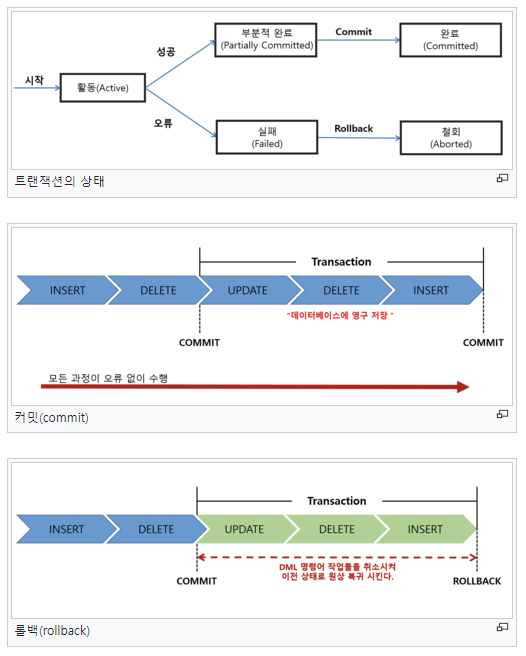
1. 원자성 (Atomicity)
- 이름 그대로 하나의 트랜잭션을 더이상 쪼갤 수 없는 최소한의 업무 단위
- 트랜잭션과 관련된 작업이 부분적 실행되다 중단되지 않는 것을 보장한다.
- 위의 예시처럼 보내는 쪽의 돈만 빠져나가고 받는 쪽에 돈을 넣는 작업을 실패하는 상황을 방지한다.
- 트랜잭션의 결과는 DB에 모두 반영하던가 모두 반영하지 않는 All or Noting이어야 한다.
- 즉, 작업의 부분 수행 혹은 중단이 아닌 전체 수행 결과 성공과 실패만이 허용된다.
- 원자성을 지키지 않으면 오작동 시, 디버깅이 굉장히 어려워진다.
원자성 보장
수행 중인 트랜잭션은 변경된 내용과 이전의 커밋 상태를 임시 영역에 저장함으로써 둘 다 유지한다.
여기서 임시 영역을 롤백 세그먼트, 트랜잭션에 의해 새롭게 변경되는 항목을 데이터 베이스 테이블이라 한다.
오류가 발생하면 DB table을 날리고 롤백 세그먼트에 저장된 상태로 되돌아간다.
다만, 트랜잭션이 포함하는 연산작업이 너무 길면 처음부터 하는 것이 비효율적일 수 있으므로
확실하게 오류가 발생하지 않는 부분에 대해서는 롤백상태로 넘어가지 않도록 세이브 포인트를 지정할 수도 있다.
2. 일관성 (Consistency)
- 정확성을 따진다. 처음 트랜잭션이 진행됐을 때의 DB를 참조하기 때문에 일관성을 지킬 수 있다.
- 트랜잭션 실행 이전과 이후에도 DB State는 이전과 같이 유효해야 한다.
- PK같은 무결성 제약 조건이 변경되면 해당 PK를 참조하는 테이블의 PK가 변경되어야 한다. (명시적 일관성 조건)
- A와 B가 돈을 거래했을 때, 둘의 계좌에서 잔액의 총합은 같아야 한다. (비명시적 일관성 조건)
- 해당 테이블은 무조건 이름을 가지고 있어야 한다는 제약 조건이 있다면 이름 없는 정보를 담은 쿼리를 추가하거나 기존 데이터의 이름 정보를 삭제하는 쿼리는 일관성을 위배한다고 볼 수 있다.
일관성 보장
트랜잭션 수행 전·후에 데이터 모델의 모든 제약조건을 만족해야만 한다.
한 쪽에서만 일방적인 데이터 변경 작업이 수행되어서는 안 된다는 것이다.
일관성을 보장하기 위해 트리거 장치를 통해 DB 시스템이 자동적으로 수행할 동작을 명시한다.
즉, 특정 이벤트가 발생했을 때 DB가 자동적으로 관련 테이블의 정보를 수정토록 지정하는 것이다.
3. 고립성 (Isolation)
- 모든 트랜잭션은 다른 트랜잭션에 종속되어서는 안 된다.
- 트랜잭션 실행 중에 변경된 데이터는 해당 작업이 완료할 때까지 다른 트랜잭션이 참조할 수 있어선 안 된다.
- 10,000원이 있는 A의 계좌에서 B, C에게 6,000원씩 동시에 송금한다고 마이너스 통장이 되지는 않는다.
- 한 가지 작업이 수행될 때, 다른 트랜잭션이 A 계좌를 참조할 수 없으며, 작업이 수행될 때까지 대기해야 한다.
- 실행 결과는 동시 실행 결과와 연속 실행 결과의 DB State가 동일해야 한다.
고립성 보장
하나의 트랜잭션이 데이터를 읽을 때, 다른 여러 개의 트랜잭션이 읽을 수는 있어야 하므로 shared_lock을 한다. read_only로써 접근을 허용하는 것이다.
하나의 트랜잭션이 데이터를 쓸 때, 다른 트랜잭션이 접근하지 못 하게 막는 exclusive_lock을 한다.
작업이 끝나면 다른 트랜잭션이 접근할 수 있게 lock을 풀어주기 위해 unlock을 해주어야 하는데,
이 과정에서 로직 순서가 잘못 되면 두 개 이상의 작업이 서로의 작업이 끝나길 기다리는 교착 상태(dead_lock) 상태에 빠져 결과적으로 아무런 작업도 수행할 수 없는 상태가 될 수 있다.
4. 지속성 (Duration)
- 하나의 트랜잭션이 성공적으로 수행했다면, 해당 트랜잭션에 대한 로그가 남아야 한다.
- 설령 런타임 에러나 시스템적 오류가 발생하더라도 해당 기록은 영구적이어야 한다.
- 은행에서 계좌 이체를 성공적으로 실행한 뒤에 은행 DB에 오류가 발생해 종료 되더라도 계좌이체 내역은 로그로 남아야 한다.
- 로그를 기록하기 전에 오류가 발생한다면, 해당 이체 내역 전체를 실패로 간주하고 롤백한다.
- 트랜잭션은 로그에 모든 것이 저장되어야만 Commit 상태로 간주된다. 그 외는 모두 작업을 취소시킨다.
3. use Transaction
django에서는 DB autocommit을 사용하고 자체 transaction management를 사용한다.
별도 설정이 없다면 autocommit을 base로 DB를 구성하여 트랜잭션이 필요 없다고 인식하여 즉시 commit한다.
반대로 트랜잭션이 실행되면 atuocommit을 비활성화 하여 기능을 사용할 수 있게 된다.
Django autocommit은 transaction이 없음을 의미하는 것일까?
정확히 따지자면 틀렸다.
autocommit 기능이 켜져있으면 각 SQL 쿼리는 하나의 트랜잭션으로 wrapping 된다.
해당 쿼리는 트랜잭션의 시작과 commit / rollback을 자동 실행하는 것이다.
다만 개발자가 모든 경우를 커버하기에는 어려움이 있기 때문에 대부분 DB는
autocommit을 default로써 제공하고, 사용자의 필요에 의하여 트랙잭션 기능을 활성할 수 있는 것이다.
따라서, 트랙잭션을 활성화하는 경우는 하나의 api에서 복합적 DB CRUD 로직을 개발하는 로직을 작성하는 경우에 trasaction을 활성화하거나 함수를 작성하여 에러를 컨트롤한다.
다시 한 번 언급하지만 트랜잭션은 DB 신뢰성을 위한 작업이다.
1. 데코레이터(decorator)와 Context Manager을 이용한 트랜잭션
난 이 방법을 딱히 선호하지 않는다.
Django라면 몰라도 굳이 DRF에서..? 하지만 있으니까 공부해두자.
def create_category(name, products):
category = Category.objects.create(name=name)
product_api.add_products_to_category(category, products)
activate_category(category)>>> create_category('clothing', ['shirt', 'trousers', 'tie'])
---------------------------------------------------------------------------
ValueError: Product 'trousers' already exists위와 같은 에러가 발생한다고 가정하자.
현재 바지 제품을 추가하는 과정에서 Exception이 발생했는데, 문제는 create는 이미 실행되어버렸다.
그러면 해당 함수를 수정하고 다시 호출하기 전에 이미 실행된 코드로 인해 commit 되어버린 데이터를
수동으로 조회하여 삭제하는 과정을 거쳐야 한다.
물론 이런 오작동이 배포 단계에서 발생한다면 대참사지만, 개발 과정에서는 충분히 발생할 수 있다.
심지어 오작동이 날 것을 알면서도 이후의 출력값을 얻어내기 위해 노가다를 해야할 수도 있다.
이런 귀찮음을 해소하고 DB 테이블의 신뢰성을 향상시키기 위한 방법이 transaction이다.
from django.db import transaction
@transaction.atomic
def create_category(name, products):
category = Category.objects.create(name=name)
product_api.add_products_to_category(category, products)
activate_category(category)transaction으로 create_category 함수를 하나의 트랜잭션으로 묶어버린다.
이 방법은 가장 간단한 atomic(원자성)을 띄는 트랜잭션을 처리하기 위한 방법이다.
def create_category(name, products):
with transaction.atomic():
category = Category.objects.create(name=name)
product_api.add_products_to_category(category, products)
activate_category(category)함수 단위에서도 with 명령어를 이용한 메서드 내부의 부분만 지정해줄 수도 있다.
하지만 나는 DRF를 사용하고 있으므로 함수형은 그만 알아보도록 하자.
2. with 명령어를 이용한 트랜잭션
내가 개발 중인 프로젝트에 이런 테이블이 있다.
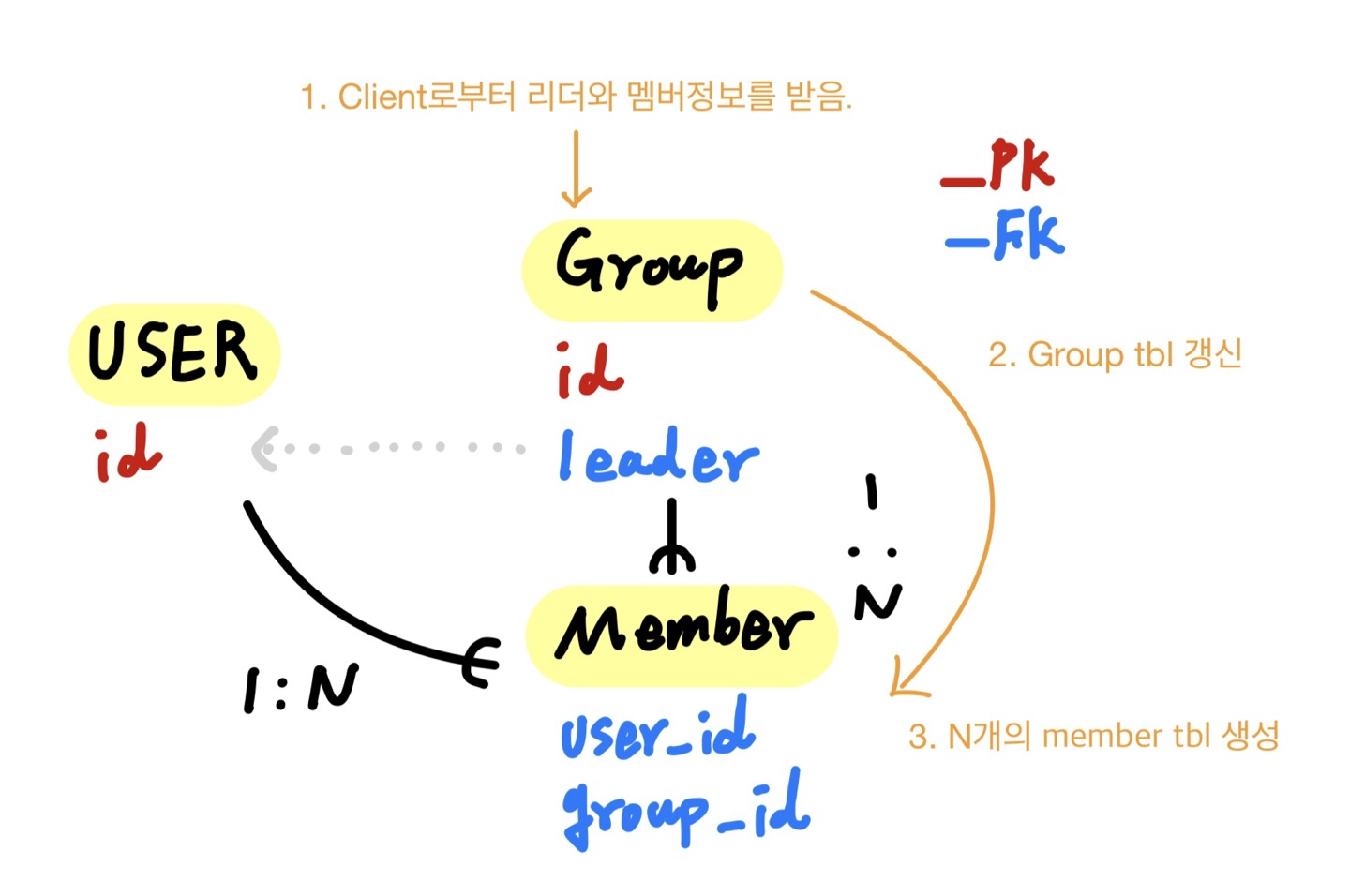
처음에 Group tbl 내부의 Member Field를 중계 테이블로 분리함으로써 다대다 관계 테이블을 제거하였다.
문제는 Group tbl을 create하기 위해서 그룹 이름과 초대할 멤버 정보를 Client에게 request로써 받았는데,
처음에는 무식하게 쿼리셋 돌려 데이터를 가공했었다.
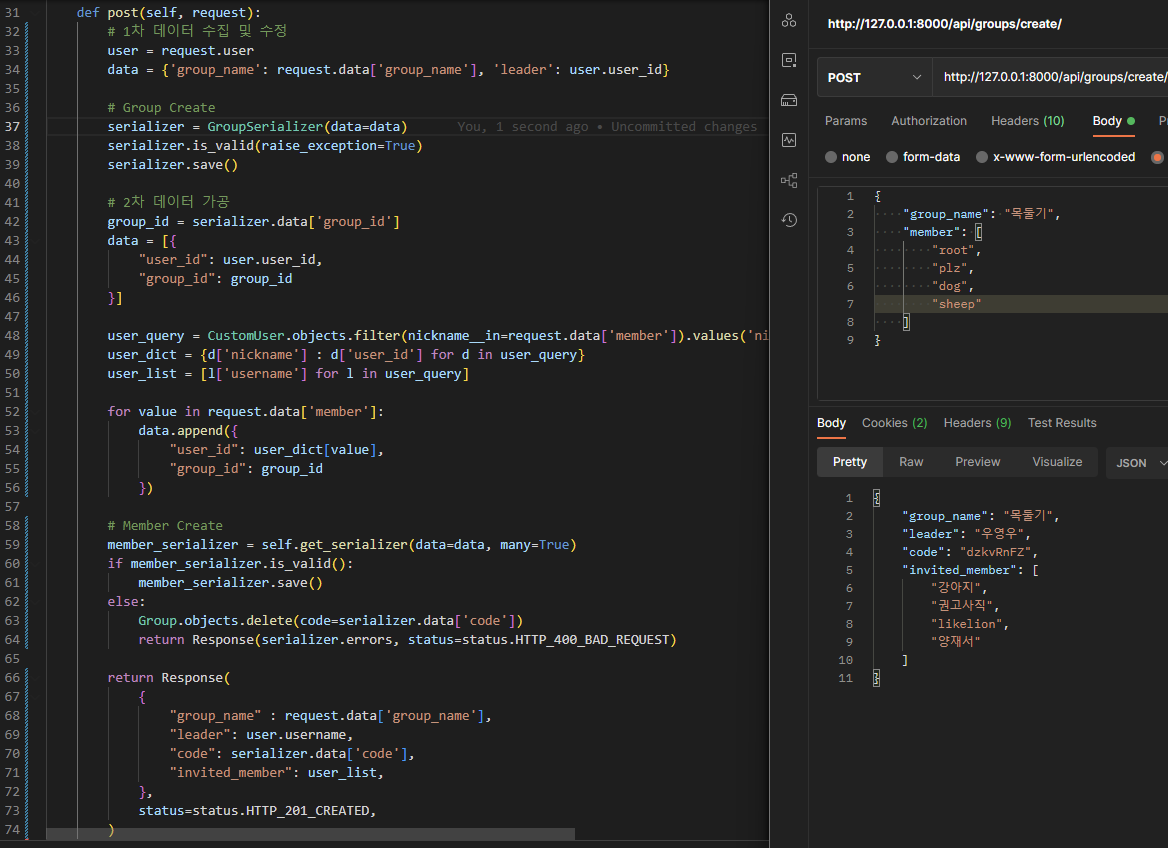
그룹 테이블을 일단 만들어 group_id를 얻어내면 Member tbl에 넘길 data list를 생성하여
Member Serializer을 돌려 유효하지 않으면, 방금전 생성된 Group Query를 날리는 방식이었다.
하지만 알고리즘 공부로 인한 최악의 경우를 상정하는 버릇 때문에 무분별한 반복문의 사용이
도저히 스스로에게 용납될 수 없었고, 코드 또한 너무 지저분했다.
이걸 해결하기 위해 중첩 Serializer로 동시에 작업을 수행하는 방법을 연구해보았다.
하지만 결론은 DRF에서는 DB 중첩 개체 쓰기를 지원하지 않기 때문에 불가능했다.
강력한 기능들을 지원하는 Viewset 내부 로직을 파헤쳐보아도 이런 복잡한 기능을 수행하지는 않았다.
심지어 해당 로직의 가장 큰 어려움은 Member tbl에 들어갈 group_id 값을 얻어내기 위해선
필수적으로 Group을 우선적으로 .save()해야만 하기 때문에 결국 나는 한 번의 Group serializer와
N번의 Member serializer을 연속적으로, 그것도 순차적으로 수행해야만 했다.
문제는 이 과정에서 단 한 번이라도 에러가 발생한다면 '내 DB가 처리할 수 있는가?'가 맹점이었고
나조차도 이 부분에 있어서 내 코드를 신뢰할 수 없었다.
난 이 문제의 해결책을 DB의 기초 개념인 transaction에서 찾아내었고 DRF에 적용하는 것에 성공했다.
준비물은 request로 날아온 그룹 데이터와 상위/하위 테이블의 Serializer면 충분하다.
views.py
class CreateGroupView(CreateAPIView):
permission_classes = [IsAuthenticated]
queryset = Group.objects.all()
serializer_class = GroupSerializer
def create(self, request, *args, **kwargs):
try:
request.data['leader'] = request.user.user_id
member = request.data.pop('member')
member.append(request.user.nickname)
except KeyError:
return Response({}, status=status.HTTP_400_BAD_REQUEST)
serializer = self.get_serializer(data=request.data)
serializer.is_valid(raise_exception=True)우선 create 메서드 도입부에서 입력받은 data를 가공하는 작업을 끝마친다.
request data로 부터 group 쿼리에 넣을 leader의 FK값을 얻어내고 member 데이터는 빼서 따로 저장한다.
그 다음 try-catch문을 벗어나 Group Serializer을 통해 직렬화를 하여 유효성 체크를 하자.
with transaction.atomic():
instance = serializer.save()
id_list = CustomUser.objects.filter(nickname__in=member).values_list('user_id', flat=True)
for id in id_list:
s = GroupMemberSerializer(data={"user_id": id, "group_id": instance.group_id})
s.is_valid(raise_exception=True)
s.save()
headers = self.get_success_headers(serializer.data)
users = CustomUser.objects.filter(nickname__in=member).values('nickname', 'username', 'profile_img')
users_s = UserListSerializer(users, many=True)
return Response({
"group_info": {
"group_name": instance.group_name,
"code": instance.code,
"leader": request.user.username,
},
"member_info": users_s.data,
},status=status.HTTP_201_CREATED, headers=headers)DB에 저장하기 전에 Context Manager인 with과 함께 transaction.atomic()으로 트랜잭션을 활성화시킨다.
그리고 트랙잭션이 활성화 되어있는 동안 Group tbl 저장과 Member tbl의 create를 수행한다.
만약, 단 한 번의 작업이라도 에러가 발생한다면 이 과정에서 모든 작업은 무효화 처리되고
DB State는 초기 상태로 Rollback한다.
드디어 N+1 번의 DB State 작업 속에서 이 코드는 DB의 일관성을 유지할 수 있다고 말할 수 있게 되는 것이다.
심지어 이 방법은 개발하는 과정에서도 굉장히 편리하게 작동한다.
Member tbl에 쿼리를 저장하기 전에 유효한 값이 들어가고 있는지 확인하기 위해 출력값을 확인할 때,
굳이 group 테이블을 수동으로 삭제할 필요가 없다.
유효한 데이터가 들어가지 않았다면 애초에 group 테이블이 갱신될리가 없기 때문이다.
3. savepoint를 지정해주는 트랜잭션
여기서부턴 직접 사용해본 적이 없기 때문에 다시 임의의 예시를 통해 다룰 것이다.
2번의 경우에선 exception이 발생해도 자동적으로 롤백이 되기 때문에 예외처리를 따로 해줄 필요가 없다.
하지만 savepoint를 지정하는 경우에는 예외처리 또한 별도로 작업해주어야 한다.
class PayViewSet(ModelViewSet):
@action(methods=['PATCH'], detail=True)
@transaction.atomic
def approval(self, request, *args, **kwargs):
sid = transaction.savepoint() # 세이브 포인트
success = something
if success:
transaction.savepoint_commit(sid) # 해당 시점 세이브 포인트 커밋
return success_response('yes')
else:
transaction.savepoint_rollback(sid) # 이전 시점 세이브 포인트로 롤백
return error_response('no')
4. transaction.atomic() 주의사항
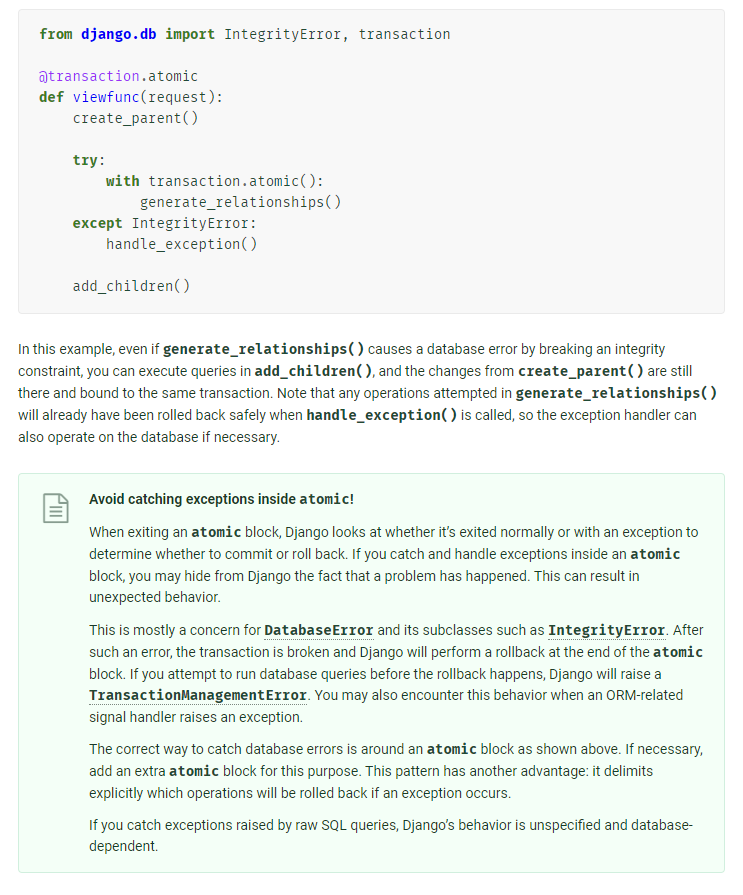
공식문서에서 명시된 바대로 with transaction.atomic 블럭 내에서 try-except를 사용해선 안 된다.
정 사용하고 싶다면 아래와 같이 처리해야 한다.
from django.db import IntegrityError, transaction
@transaction.atomic
def viewfunc(request):
(...)
try:
with transaction.atomic():
(...)
except IntegrityError:
raise handle_exception()이런 식으로 사용해야 하는 이유는 transaction.atomic 블록 내부에서 예외가 발생하면
Django에서는 atomic이 정상적으로 종료가 되었는지 예외처리 되었는지 판단할 수가 없게 된다.
이런 한 가지 문제로 인해 api 전체가 망가질 수 있다.
궁금해서 transaction의 __exit__ 구문을 전부 읽어보았다.
def __exit__(self, exc_type, exc_value, traceback):
connection = get_connection(self.using)
if connection.savepoint_ids:
sid = connection.savepoint_ids.pop()
else:
# Prematurely unset this flag to allow using commit or rollback.
connection.in_atomic_block = False
try:
if connection.closed_in_transaction:
# The database will perform a rollback by itself.
# Wait until we exit the outermost block.
pass
elif exc_type is None and not connection.needs_rollback:
if connection.in_atomic_block:
# Release savepoint if there is one
if sid is not None:
try:
connection.savepoint_commit(sid)
except DatabaseError:
try:
connection.savepoint_rollback(sid)
# The savepoint won't be reused. Release it to
# minimize overhead for the database server.
connection.savepoint_commit(sid)
except Error:
# If rolling back to a savepoint fails, mark for
# rollback at a higher level and avoid shadowing
# the original exception.
connection.needs_rollback = True
raise
else:
# Commit transaction
try:
connection.commit()
except DatabaseError:
try:
connection.rollback()
except Error:
# An error during rollback means that something
# went wrong with the connection. Drop it.
connection.close()
raise
else:
# This flag will be set to True again if there isn't a savepoint
# allowing to perform the rollback at this level.
connection.needs_rollback = False
if connection.in_atomic_block:
# Roll back to savepoint if there is one, mark for rollback
# otherwise.
if sid is None:
connection.needs_rollback = True
else:
try:
connection.savepoint_rollback(sid)
# The savepoint won't be reused. Release it to
# minimize overhead for the database server.
connection.savepoint_commit(sid)
except Error:
# If rolling back to a savepoint fails, mark for
# rollback at a higher level and avoid shadowing
# the original exception.
connection.needs_rollback = True
else:
# Roll back transaction
try:
connection.rollback()
except Error:
# An error during rollback means that something
# went wrong with the connection. Drop it.
connection.close()
finally:
# Outermost block exit when autocommit was enabled.
if not connection.in_atomic_block:
if connection.closed_in_transaction:
connection.connection = None
else:
connection.set_autocommit(True)
# Outermost block exit when autocommit was disabled.
elif not connection.savepoint_ids and not connection.commit_on_exit:
if connection.closed_in_transaction:
connection.connection = None
else:
connection.in_atomic_block = False대충 읽어보면 Exception 발생했을 때, connection.needs_rollback=True 으로 변하고
이 변수를 감지하여 트랜잭션 Rollback을 수행해야 하는데
exception이 내부에서 처리돼버리니 해당 rollback이 정상 수행되지 못하고
connection.needs_rollback는 여전히 True 상태로 존재하게 된다.
이러면 uWSGI(u Web Server Gateway Interface)로 연결되어 있는 모든 트랜잭션을 사용하는 request에서
connection이 깨지면서 uWSGI가 맛이 가버리는 대참사가 벌어진다.
TransactionManagementError가 발생했을 때, 개발자는 해당 에러가 발생하는 지점을 찾아내기가
굉장히 힘들어진다.
따라서 사용하지 말자.
5. 참고 자료
데이터베이스 | Transaction(+ django @transaction.atomic 사용)
@transaction을 공부하기 전에, 먼저 transaction의 올바른 정의가 무엇인지 알아야 할 필요가 있다.트랜잭션은 데이터베이스의 상태를 변화시키는 하나의 논리적 기능을 수행하기 위한 작업의 단위
velog.io
[DB] Transaction 과 ACID란?
DB의 기초개념인 트랜젝션과 ACID에 대해서 알아봅니다.
chrisjune-13837.medium.com
DRF - Serializer Multiple Models
How can I POST this JSON { "campaign": 27, "campaignName": "Prueba promo", "promotionType": 999, "items": [ { "item_nbr":
stackoverflow.com
Django with transaction.atomic() 사용시 주의점
...
lee-seul.github.io
[Django] 장고 트랜잭션 활용하기
장고에서 DB 트랜잭션을 이용하는 방법을 알아보겠습니다.DB 트랜잭션에 관한 내용은 DataBase Transaction 이란?이전에 작성했던 포스팅에 있습니다.django에서 트랜잭션을 이용하는 가장 쉬운 방법으
velog.io
[데이터베이스] 트랜잭션의 ACID 성질 - 하나몬
트랜잭션이란 여러 개의 작업을 하나로 묶은 실행 유닛을 말한다. 데이터베이스 트랜잭션은 ACID라는 특성을 가지고 있다. ACID는 데이터베이스 내에서 일어나는 하나의 트랜잭션(transaction)의 안
hanamon.kr