DRF를 처음 쓸 때만 해도 뭐가 뭔지 하나도 모르겠어서 어려웠는데 이젠 할만 하다.
엄청 복잡한 DB를 설계해서 관리를 하는 게 아닌 이상 사실상 리액트랑 연동해서 데이터를 관리하는게 어렵지
간단한 모델에선 한 번 '이런 거구나!'하고 감을 잡으면 그 뒤로는 항상 하던 작업의 연속이다.
그렇다고 서비스를 개발하자니 DRF가 아니라 DB 개념에서 막히기 때문에 정작 DRF를 공부한만큼 쓸 일이 없다..
이번 포스팅에선 매우 기초적인 내용을 다룰 거긴 한데, 워낙 한국어로 된 블로그의 내용들이 공식문서 번역해놓은 뻔한 내용들밖에 없어서 처음 시작할 때 너무 어려웠었기 때문에 내 나름대로의 방식대로 정리해보려고 벼르고 있었다.
설명은 최대한 쉽고 재미있게 적으려고 노력했다. 다시 읽어봤는데 재미는 없는 것 같다.
목차
1. Model
2. Url, View, Serializer의 관계
3. DRF의 흐름을 이해하는 가장 빠른 방법
1. Model
※ 상속받는 클래스에 대한 설명을 할 생각은 없다. 그럼 포스팅이 너무 길어지므로 개념만 치고 간다.
[DB] Data Modeling
목차 1. 개념적 데이터 모델링 (feat. ERD) 2. 논리적 데이터 모델링 3. 물리적 데이터 모델링 4. 효율적 데이터 모델링 5. 참고 자료 1. 개념적 데이터 모델링 (feat. ERD) 모델링 이전에 가장 중요한 건
jaeseo0519.tistory.com
Data Base 카테고리에서 데이터 모델링과 관련된 포스팅을 했었는데, DB를 모르면 모델을 이해할 수 없다.
왜냐하면 DRF에서 models.py에 작성하는 모델이 바로 요놈이기 때문.
물리적 데이터 모델링에서 SQL 환경의 코드로 작성하지 않고, Django에서 정의하는 것이다.
모델을 정의하면 항상 bash에 python manage.py makemigrations를 한 다음, migrate를 하지 않던가?
그게 바로 Django에서 정의한 Model을 DB에 등록하는 것이다.
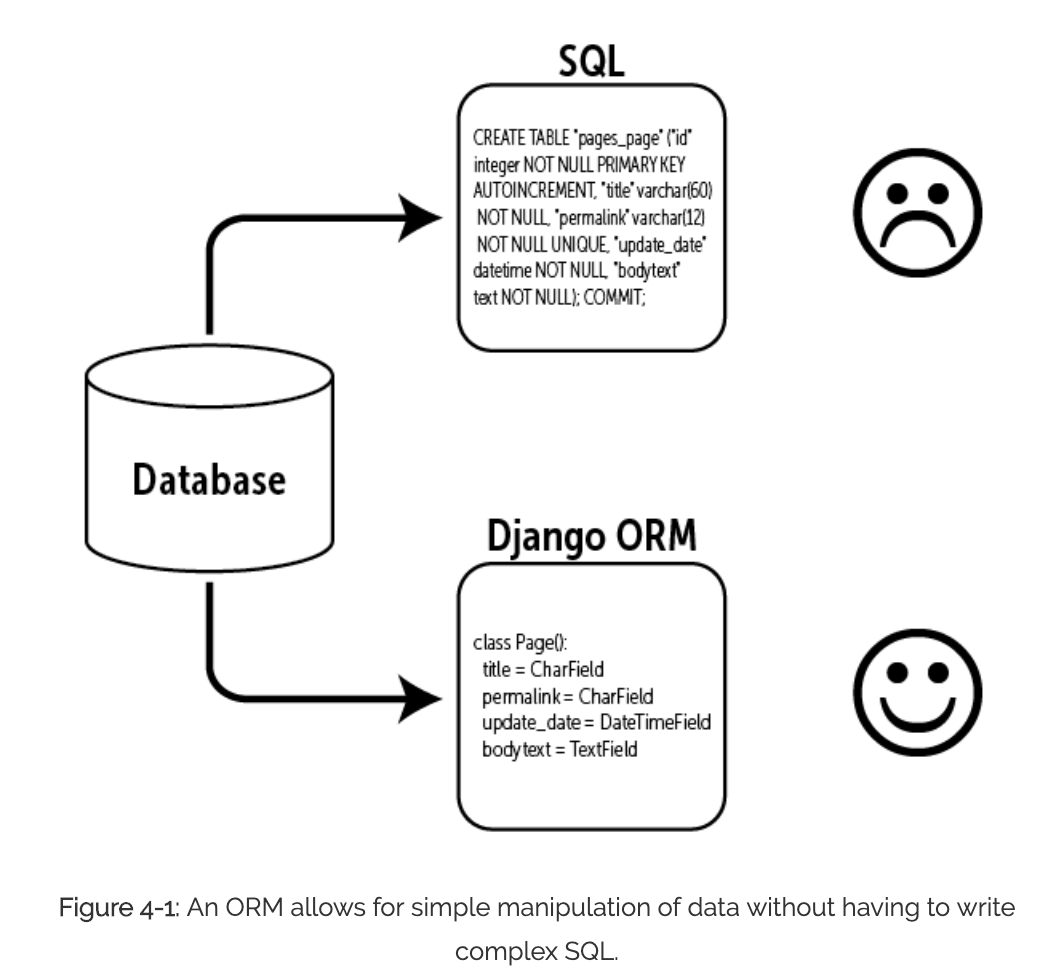
ORM은 Django의 핵심 기능이라고 볼 수 있다. (DRF는 Serializer가 핵심)
Object-Relational Mapping을 사용하여 데이터 베이스에 데이터를 쉽게 Create, Read, Update, Delete 할 수 있게 된다.
이게 무슨 소리냐하면 모델명.objects.all() 라는 코드만으로 SQL쿼리문 없이 쿼리셋을 불러와 작업할 수 있는 이유가 Django가 테이블을 Object와 연결시켜주기 때문이다.
Object와 연결됨으로써 재미있는 기능들을 사용할 수 있게 되는데, 그건 나중에 따로 다루도록 하자.
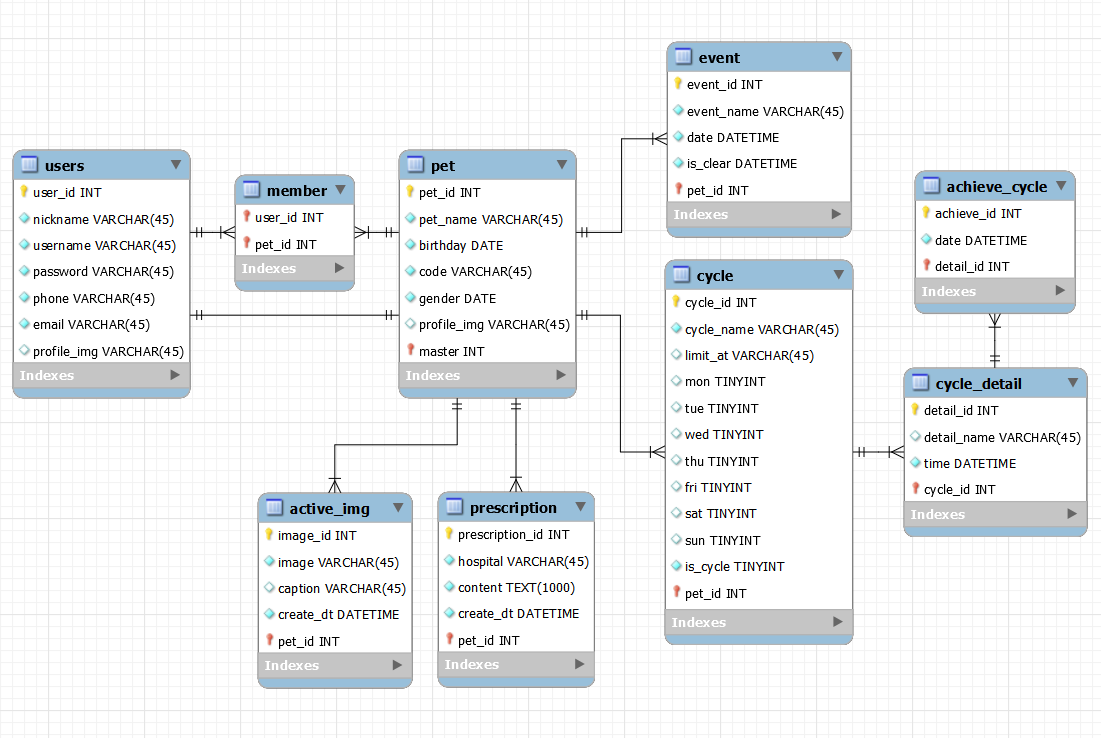

유저 모델의 경우엔 좀 다르긴 하지만, 일반적으로 models.Model을 상속받아서 모델을 만든다.
Django model data types
If you look closely at some of the DDL generated for the different Django model fields in table 7-1 (e.g. models.CharField(), models.FileField()), you'll notice Oracle generates DB columns with the NULL constraint, where as the other three database brands
www.webforefront.com
데이터 타입은 위 링크에서 참고하면 된다.
다만 이제 Field에 옵션을 설정해줄 수 있는데 기본적으로 숙지해두면 좋다. (어차피 쓰다보면 알게 된다.)
필드마다 공통으로 적용되는 옵션도 있고, 고유 옵션이 존재하는 경우도 있기 때문에 주의하자.
- null (DB option) : DB Field에 Null 허용 여부 (default: False)
- unique (DB option) : 유일성 여부 (default: False)
- blank : 입력값 유효성 검사 시에 empty 값 허용 여부 (default: False)
- default : 디폴트 값 지정. 값이 들어오지 않으면 해당 값이 저장된다.
- verbose_name : 필드 레이블. 지정되지 않으면 필드명이 쓰인다.
- validators : 입력값 유효성 검사를 수행할 함수를 여러개 지정. (ex. 패스워드 입력)
- auto_now_add : Bool, True인 경우, 레코드 생성시간이 저장된다.
models.py에서 정의하는 건 결국 SQL문으로 작성할 걸 Python 문법으로 작성한다고 생각하면 된다.
create table user_tbl (
user_id bigint primary key auto_increment,
username varchar(45) not null,
nickname varchar(45) unique not null,
password varchar(45) not null,
(...)
);이런식으로 작성할 걸
class CustomUser(AbstractBaseUser, PermissionsMixin):
user_id = models.BigAutoField(
primary_key=True,
unique=True,
editable=False,
verbose_name="user_id",
)
username = models.CharField(
max_length=45,
)
nickname = models.CharField(max_length=45, unique=True)
(...)이런 식으로 대체하는 것.
def __str__(self):
return self.username모델을 쓰다보면 __str__ 이란 걸 정의하는 경우가 있는데, 될 수 있으면 정의해주는 게 편하다.
중요한 건 아니지만 나중에 해당 테이블에서 쿼리를 가져오면 __str__에서 정의한 정보를 보여준다.

CustomUser는 username을 리턴하도록 정의했고, Member 테이블의 경우엔 따로 선언해두지 않았기 때문에 Member Object (num)로 표시되기 때문에 구분이 용이하지 않다.
이거 말고도 되게 중요하게 쓰이던 때가 있었긴 했는데 너무 심화된 내용이므로 나중에 기회되면 다시 설명하자.
🔐 PK & FK로 Relationship 정의하기
PK와 FK 개념은 가장 처음에 걸어둔 링크에서 확인하면 된다.
Django에서 PK는 정의하지 않으면 디폴트로 id 값이 등록된다.
pet_id = models.BigAutoField(primary_key=True, unique=True, verbose_name="pet_id")굳이 직접 정의해주고 싶다면 primary_key 옵션을 True로 설정해주면 끝난다.
그렇다면 외래키는 어떻게 설정해야 할까?
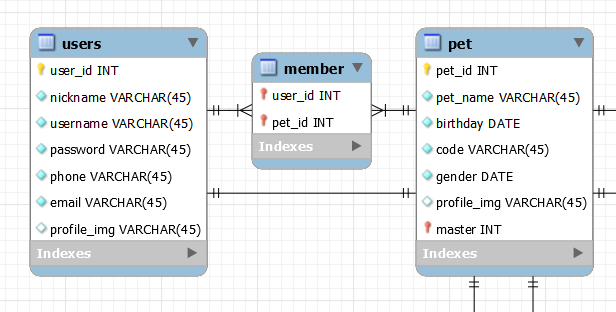
위의 관계에서 다대다 관계를 분리해내기 위해 멤버 테이블을 분리하여 중계하도록 하고,
Pet 테이블의 master를 일대일 관계로 User에게 받아야 하는 경우에 이렇게 정의해줄 수 있다.
class Pet(models.Model):
master = models.OneToOneField(
CustomUser, on_delete=models.CASCADE, db_column="user_id", related_name="master"
)
class Member(models.Model):
user_id = models.ForeignKey(
CustomUser,
on_delete=models.CASCADE,
db_column="user_id",
)
pet_id = models.ForeignKey(
Pet,
on_delete=models.CASCADE,
db_column="pet_id",
)on_delete는 데이터 무결성 옵션으로써 CASCADE의 경우엔 참조하고 있는 부모 쿼리가 삭제되면 자식 쿼리도 같이 삭제해버린다.
ManyToManyField도 있긴 한데, DB에서 다대다 관계는 미완성 모델로 간주하기 때문에 되도록 사용을 지양하자.
2. Url, View, Serializer
DRF 입문 시에 가장 까다로운 것이 url과 view, serializer의 차이를 분간하는 것이었다.
심지어 각각 뭐하는 놈들인지 이론을 알게 됐음에도 불구하고 막상 사용하려면 여간 헷갈린 게 아니었다.
나는 얘네를 설명할 땐, 주로 오락실 커맨드 키에 빗대어 설명한다. (정작 해본 적은 없다.)
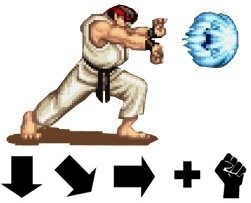
스트리트 파이터에서 방향키 '↓↘→'를 누르면 필살기 '아도겐'이 발동된다.
여기서 방향키가 url이고 필살기가 view(사실상 Controller)라고 생각해보자.
models.py에서 아도겐의 데미지, 사정거리, 이미지 등을 정의해놓고, views.py에서는 아도겐의 정보를 가져올 수 있게끔 만들면 된다.
views.py에서 정의한 아도겐의 정보를 가져오는 클래스에 클라이언트가 접근할 수 있게 경로를 알려주어야 하는데, 이게 바로 특정 방향키를 눌렀을 때 정의된 view가 실행되도록 만드는 것이다.
엥, 그럼 serializer는 뭐하는 놈인데요?
serializer는 번역기다. 데이터 베이스에서 아도겐을 쿼리 타입으로 저장해놓기 때문에, 게임기에서 방향키를 입력하여 View가 아도겐 데이터를 가져온다 한들 게임기는 데이터를 해독하지 못 한다.
따라서 View가 가져온 쿼리 타입을 게임기가 이해할 수 있는 언어에 맞게끔 번역하여 돌려주면 그제서야 게임기가 인식하고 아도겐이 발사되는 것.
해보지도 않은 게임으로 제법 잘 써먹고 있는 예시긴 한데, 이해가 잘 될지는 모르겠다.
문제는 이론이 완벽하다고해서 사용할 수 있는 것은 아니라는 것이다.
우선 View와 Serializer에 대한 내용만 정리하고 이후에 따로 Viewset과 Router, NestedRouter에 대해 다룰 것이다.
1. View
Django REST Framework 3.13 -- Classy DRF
What is this? Django REST framework is a powerful and flexible toolkit that makes it easy to build Web APIs. It provides class based generic API views and serializers. We've taken all the attributes and methods that every view/serializer defines or inherit
www.cdrf.co
View만 해도 상속받을 수 있는 애들이 엄청나게 많다.
그런데 서로 다 상관없는 내용이 아니라 두번, 세번 상속 받을 거 클래스 하나로 퉁치게 만들려고
개발자들이 Mixins를 묶어서 CreateAPIView를 만들고, 이런 애들을 또 죄다 묶어서 ViewSet을 만들었다고 보면 된다.
실제로 위의 링크에 들어가서 CreateAPIView 클래스를 살펴보면 조상 클래스가 누구인지 알 수 있다.
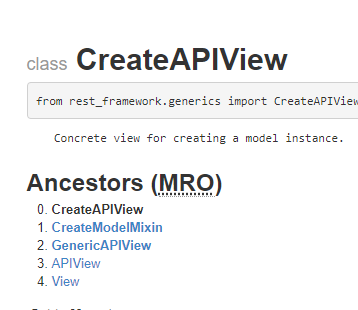
즉, CreateAPIView라는 건 완전 동떨어진 새로운 개념의 클래스가 아니라 기존의 APIView를 사용하기 쉽도록 이것저것 개조해놓은 상태인 것이다.
그렇다면 APIView보다 CreateAPIView가 더 좋고, CreateAPIView보다 ModelViewSet이 무조건 더 좋은 것인가?
그렇지 않다. 클래스를 상속받는다는 것은 이미 필요한 로직이 모두 구현되어 있어서 편한 것은 사실이지만
그만큼 제약이 많이 뒤따르기 때문에 내게 맞지 않다 싶으면 가장 날 것의 APIView를 사용하는 것이 바람직하다.
View는 어디까지나 Model에서 원하는 데이터를 끌어와서 Serializer로 번역 후 돌려주거나
반대로 입력받은 정보를 Serializer로 역직렬화하여 Model에 데이터를 추가해주기 위한 중간 유통업체 정도로 생각해주면 된다.
말이 View지 하는 일은 완전히 Controller다.
웹 서비스를 위해 Django를 만들었다가 REST하게 만들면서 이름 바꾸기 귀찮아서 그냥 view로 유지하는 건 아닐까 하는 혼자만의 상상도 해보는 중이다.
2. Serializer
어찌보면 serializer라는 놈 때문에 가장 큰 고생을 했던 것 같다.
이론은 알고 있는데, 대체 view와 차이가 뭔지, 얘를 어떻게 쓰라는 건지 감이 잘 안 잡혔었다.
DB 구조가 조금만 복잡해져도 반복문의 양이 너무 많아졌고, 코드가 너무 길어지는 불편함이 있었다.
그러다 문득 절대 내가 작성한 코드가 최선일리 없다는 생각에 빠져들었고 문제점을 찾은 결과
Serializer가 번역기임을 알고 있으면서 그걸 제대로 활용을 하지 못 하고 있었다는 것이다.
정말 놀라운 점은 Serializer의 기능은 생각 이상으로 강력하다.
이딴 식으로 넣어줘도 돌아가려나 싶어도 돌아간다.
한 번에 여러 개의 모델을 직렬화할 때도 방법이 정말 다양하다.
그렇다고 serializer가 엄청 복잡해질까? 아니다.
오히려 view로만 데이터를 가공하려고 했을 때보다 훨씬 코드가 짧아진다.
포맷 형식 맞춘다고 조금 길어진 거 빼면, 대부분 이 정도 선에서 끝난다.
물론 validate 함수를 오버라이딩하거나 하면 조금 길어질 수는 있지만, 유저 모델 외에 그런 기능을 얼마나 쓰겠는가?
사용하는 방법에 대해서는 Serializer만 따로 또 포스팅을 분리해서 다루어볼 예정이다.
(아, 컨텐츠 너무 많다.)
3. DRF의 흐름 이해하는 가장 빠른 방법
나는 개발 관련 공부를 책 사서 하는 것을 굉장히 싫어하는 사람이다.
물론 이론을 알면 좋긴 한데, 일단 닥치고 개발을 해보고 머리 한 번 깨져본 사람들이나 책을 폈을 때
'아하, 그때 그게 이런 원리였구나'하고 이해가 가는 것이라고 생각한다.
대부분의 사람들을 가르쳐 보면, 이해가 가질 않아서 사용하지 못 하겠다고 하는데 코딩 공부는 그런 식으로 접근해선 안 된다고 생각한다.
솔직히 처음 날 키운 건 구글과 스택 오버플로우였지, 학원이나 책은 그다지 큰 도움을 주지 못 했다.
내가 DRF에 대해 급속도로 빠르게 이해할 수 있었던 시점은 디버깅하는 방법을 찾아냈을 때였다.
url, view, serializer를 대충 어느 블로그에서 가져온 걸 적어놓고 얘가 어떤 원리로 동작하는지 알고 싶다면
전부 터미널에 출력해보면 된다.
url로 넘긴 pk값이 어떻게 넘어오는지, 그걸로 모델이 어떤 타입으로 받아지는지, serializer를 돌리면 거기서는 어떻게 작동하는지 궁금하다면 전부 print문으로 뽑아서 육안으로 확인해보면 된다.
만약 원하는 값이 나오지 않고 에러가 나는 경우가 있다면 대충 어디쯤에서, 왜 에러가 났을지 판단하는 것도 좋은 개발자가 되기 위한 길이다.
에러를 두려워 하는 사람들이 있던데, 개발 시점에서 발생하는 에러를 두려워하는 개발자는 절대 성장할 수 없다.
책? 제발 그런 거는 라면 받침대로나 쓰고, 일단 개발하라.