DRF가 아니라 Django의 개념이지만 꼭 알아야하는 기초 개념이므로 짚고 넘어가자.
목차
1. Object-Relational Mapping (ORM)
2. queryset read
3. 조회 조건
4. Reference(참조) & Dereference(역참조)
1. Object-Relational Mapping (ORM)
DRF는 결국 프론트 엔드에서 DB가 필요하기 때문에 사이에서 중재해주는 역할임을 잊지말자.
(물론 훨씬 많은 일을 처리하지만 일단 그렇다치자..! 안 그러면 설명이 힘들어진다.)
예를 들어, React에서 간단한 DB작업을 위해 직접적으로 연결하는 것이 불가능하지는 않지만 별로 좋은 방법은 아니다.
그래서 node.js가 됐건, DRF가 됐건 데이터를 컨트롤해주는 백엔드가 필요하고, 백엔드에서는 API를 만들어서 프론트와 요청과 응답을 통해 서로 통신하는 방법을 택한다.
즉, DRF가 DB는 아니라는 셈이다. 프론트에서 요청을 보내면 DB의 데이터를 가공해서 약속된 포맷 형식에 맞춰서 Response를 해주는 매개체에 가깝다.
DB는 데이터를 query Type으로 저장한다.
그런데 DRF는 기본적으로 파이썬을 기반 언어로 두기 때문에 query를 직접적으로 컨트롤할 수 없다.
이걸 해결하기 위한 것이 query를 Object와 연관지음으로써 Django에서 컨트롤할 수 있게 만들었다.
원래 SQL을 사용해서 관리해야 하는 것을 python 언어로 손쉽게 CRUD할 수 있게 된 것이다.
[DRF] Concept Part - Model, Url, View, Serializer
DRF를 처음 쓸 때만 해도 뭐가 뭔지 하나도 모르겠어서 어려웠는데 이젠 할만 하다. 엄청 복잡한 DB를 설계해서 관리를 하는 게 아닌 이상 사실상 리액트랑 연동해서 데이터를 관리하는게 어렵지
jaeseo0519.tistory.com
정말 기초 중의 기초만 담은 내용이니까 이해가 안 간다면 참고하면 된다.
🤔 Django의 ORM이 실제 SQL 질의문을 확인할 수 있을까?
쿼리란 데이터 베이스에 정보를 요청하는 것이다.
내가 Pet이라는 모델이 있다고 쳤을 때, Pet.objects.all()을 입력하면 쿼리문으로 번역되어 DB에 요청되어 queryset을 가져오는 건데, 그렇다면 여기서 쿼리문이 어떤 식으로 보내지는지 직접 확인할 수 있다.
class PetViewSet(ModelViewSet):
queryset = Pet.objects.all()
def list(self, request, *args, **kwargs)
print(self.queryset.query)
SELECT * FROM "pets_pet"원래는 SELECT로 위의 내용을 직접 작성해서 데이터를 요청해야 했는데 Pet.objects.all() 한 줄로 끝나버렸다.
지금부터 다뤄볼 .filter()나 .exclude() 같은 메서드는 모두 Django가 알아서 쿼리문으로 번역하여 DB에 요청하고 있는 것이다.
2. queryset read
위에서 작성한 코드에서 query가 아니라, 요청을 통해 실제로 가져온 데이터를 확인해보자.
class PetViewSet(ModelViewSet):
queryset = Pet.objects.all()
def list(self, request, *args, **kwargs)
print(self.queryset)
보다시피 QuerySet 을 잘 가져오고 있음을 확인할 수 있다.
그런데 만약 내가 원하는 데이터만 골라내고 싶다면 어떻게 해야할까?
그럴 땐, 매우 다양한 방법들이 있다. 하지만 반드시 하나만 기억하자.
ORM을 사용하는 이유는 쿼리문이 아니라 파이썬 언어로 필터링을 하기 위함이다.
따라서 여기 나오는 모든 메서드는 실제로 SQL에서 다룰 수 있는 필터링 방법들이다.
모든 내용을 다루기엔 양이 너무 방대하므로 자주 사용하던 것들 위주로 정리할 것이다.
SQL을 모른다고 해도 충분히 사용할 수 있다.
1. filter
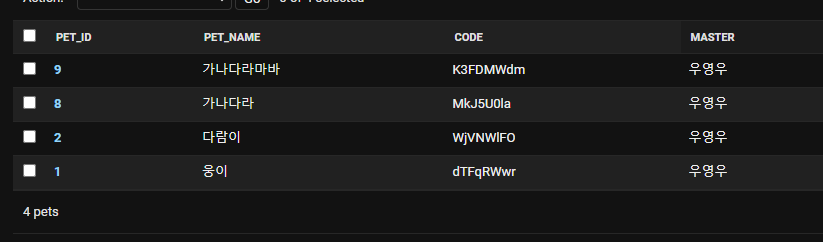
현재 DB의 Pet table에 저장해둔 데이터 리스트이다.
좀 더 상세한 정보를 살펴보면 각 Pet은 성별이라는 필드를 가지고 있다.
만약 쿼리셋 중에 성별이 male인 경우만 걸러내고 싶다면 아래처럼 작성하면 된다.
class PetViewSet(ModelViewSet):
queryset = Pet.objects.all()
def list(self, request, *args, **kwargs)
print(" === 1. queryset === ")
print(self.queryset.filter(gender='male'))
print(" === 2. query ===")
print(self.queryset.filter(gender='male').query) # SQL 질의문 확인용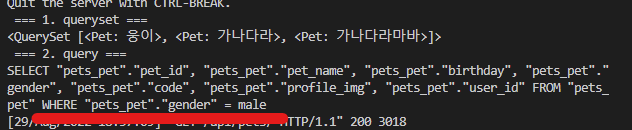
query문에 WHERE이 추가되어 필터링이 되고 있다는 것을 알 수 있다.
이외에도 filter는 매우 다양한 방법으로 쓸 수 있다.
특히 AND, OR, NOT 연산을 통해서 여러 개의 조건을 동시에 걸 수도 있다.
중간에 Q라는 애가 나오는데 이건 django.db.models에서 지원하는 객체이므로 import 해야한다.
(Q는 이후에 더욱 복잡한 필터링을 돕는다.)
from django.db.models import Q워낙 방법이 다양하기 때문에 원하는 방식을 택하면 된다.
- AND
- queryset.objects.filter( 조건1, 조건2 )
- queryset.objects.filter( Q(조건1) & Q(조건2) )
- queryset.objects.filter(조건1) & queryset.object.filter(조건2)
- OR
- queryset.objects.filter( Q(조건1) | Q(조건2) )
- queryset.objects.filter(조건1) | queryset.object.filter(조건2)
- NOT
- exclude(조건)
- filter(~Q(조건))
이 정도는 워낙 자주 쓰니까 알아두면 굉장히 유용하다.
더 강력하고 효율적으로 filter 조건을 걸 수 있는 방법이 있는데, 중요하기도 하고 양이 좀 많아서 따로 다뤄야겠다.
2. get
get과 filter안에 조건을 거는 것은 같지만, 가장 큰 차이를 기억해두자.
filter는 값이 하나라도 쿼리셋을 리턴한다. 따라서, 여러 데이터를 걸러낼 수 있다. 하나의 데이터만 리턴되더라도 쿼리셋 타입으로 리턴시킨다.
get은 단 하나의 객체만 리턴한다. 만약 여러 개의 데이터가 조건에 포함되는 경우 에러가 발생한다.
따라서 get은 모델의 고유값을 통해서 참조해야 한다.
굳이 따지자면 get은 filter().first()와 동일한 기능을 한다.
문제는 get은 객체를 리턴하기 때문에 queryset이 사실상 queryset이 아닌 객체가 된다.
객체는 .query라는 속성을 가지고 있지 않기 때문에 SQL문을 확인하지는 못 한다.
하고 싶다면 filter().first().query를 하면 get이 어떤 식으로 작동하는지 SQL문을 확인할 수 있다.
class PetViewSet(ModelViewSet):
queryset = Pet.objects.all()
def list(self, request, *args, **kwargs)
print(" === 1. filter === ")
print(self.queryset.filter(pet_id=1))
print(type(self.queryset.filter(pet_id=1)))
print(self.queryset.filter(pet_id=1).query)
print(" === 2. get ===")
print(self.queryset.get(pet_id=1))
print(type(self.queryset.get(pet_id=1)))
# print(self.queryset.get(pet_id=1).query) # 불가능!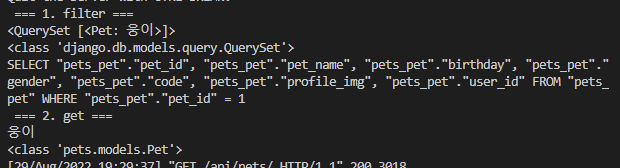
get은 보통 직렬화를 위함이 아니라, 데이터 가공을 위해 특정 값을 확인할 때 사용한다.
쿼리셋이 아니므로 .query 속성은 없지만 오히려 해당 객체의 값을 가져오긴 훨씬 유용하다.
class PetViewSet(ModelViewSet):
queryset = Pet.objects.all()
def list(self, request, *args, **kwargs)
print(self.queryset.get(pet_id=1).gender) # '웅이'의 성별인 male 리턴이후에 serializer을 다루면 알게 되겠지만 역직렬화는 QuerySet 타입이 아닌, 그 안의 객체를 던져주어야 한다.
물론 filter로 걸러낸 쿼리셋도 serializer에 넘기는 방법이 있지만, 하나의 특정 객체만 필요로 한다면 get을 쓰는 것이 편하다.
3. values, values_list
그렇다면 get으로 객체를 리턴하지 않고, 쿼리셋의 특정 열만 조회하고 싶다면 어떻게 할까?
반복문을 돌려서 get 조건을 계속 바꿔가면서 리스트에 추가해야 할까? 그렇지 않다.
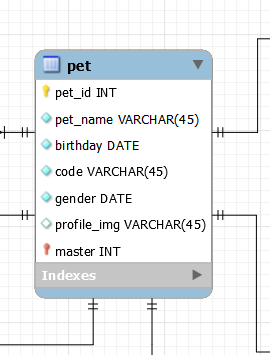
Pet이라는 테이블에 id, name, birthday, code 등의 여러 정보 중에서 gender가 male인 레코드의 name과 code만 추출해보자.
class PetViewSet(ModelViewSet):
queryset = Pet.objects.all()
def list(self, request, *args, **kwargs)
print(self.queryset.filter(gender='male').values('pet_name', 'code')
print(" === query === ")
print(self.queryset.filter(gender='male').values('pet_name', 'code').query)
query문이 pet_name과 code만 조회하도록 작성된 것을 확인할 수 있다.
다만 이렇게 하면 QuerySet 안에 dict타입의 데이터가 여러개 생기는데 안에 있는 특정 값이 다수 필요할 때, dict 타입으로 필드명과 값을 동시에 가져온다.
그런데 만약 dict 타입이 거슬리거나, key-value가 아닌 value만 리스트에 모아두고 싶을 수 도 있다.
예를 들어, gender가 male인 펫만 골라서 id 리스트를 뽑아내고 싶다고 한다면 훨씬 간단한 방법이 있다.
바로 values_list 메서드를 사용하는 것이다.
class PetViewSet(ModelViewSet):
queryset = Pet.objects.all()
def list(self, request, *args, **kwargs)
print(self.queryset.filter(gender='male').values_list('pet_code')
print(" === query === ")
print(self.queryset.filter(gender='male').values_list('pet_code').query)
엥, 위에서 있는 대로 큰소리 쳐놓고 values_list를 썼더니 set로 value가 감싸져있다.
이럴거면 오히려 values 메서드가 더 나은 거 아닐까?
하지만 여기서 values_list의 옵션으로 flat=True를 걸어주면 상당히 흥미로운 결과가 나온다.
class PetViewSet(ModelViewSet):
queryset = Pet.objects.all()
def list(self, request, *args, **kwargs)
print(self.queryset.filter(gender='male').values_list('pet_code', flat=True)
print(" === query === ")
print(self.queryset.filter(gender='male').values_list('pet_code', flat=True).query)
이렇게 뽑은 리스트를 이용하면 filter의 조회 조건으로 '__in'을 사용하면 엄청난 시너지 효과를 발휘한다.
(values로 얻은 dict 타입의 쿼리셋도 똑같이 작동하긴 한다. ㅋㅋ)
관련 내용은 3. 조회조건 파트에서 확인하면 된다.
4. order_by
쿼리셋을 가져올 때, 정렬 순서를 정할 수 있게 한다.
class PetViewSet(ModelViewSet):
queryset = Pet.objects.all()
def list(self, request, *args, **kwargs)
print(self.queryset.order_by('-birthday').values('pet_name', 'birthday'))
print(" === query === ")
print(self.queryset.order_by('-birthday').values('pet_name', 'birthday').query)
앞에 -를 붙이면 내림차순으로 정렬된다.
결과를 확인해보면 2018 - 2010 - 2000 년 순으로 쿼리셋이 정렬되었음을 알 수 있다.
5. annotate
from django.db.models import Fannotate를 사용할 때 거의 동시에 자주 사용되는 F 객체도 import한다.
annotate는 다른 필드 값을 복사하거나, 다른 필드 값을 가공한 값을 새로운 필드를 추가하여 '주석을 단다'.
모델을 수정하는 것은 아니고 컬럼을 임시로 하나 추가해준다고 생각하면 된다.
나중에 설명할 내용이긴 하지만 정참조를 통해 Pet의 master인 user의 name 정보를 가져오려면 다음과 같이 작성한다.
class PetViewSet(ModelViewSet):
queryset = Pet.objects.all()
def list(self, request, *args, **kwargs)
print(self.queryset.values('master__username'))
print(" === query === ")
print(self.queryset.values('master__username').query)
분명 가져오긴 가져왔는데 key값의 이름이 너무 길다.
그렇다고 values_list로 뽑아버리자니 key값이 필요하긴 한 경우라면 그냥 저대로 내보내기 보다 임시 필드를 추가해서 거기에 기존 값을 복사하면 된다.
class PetViewSet(ModelViewSet):
queryset = Pet.objects.all()
def list(self, request, *args, **kwargs)
print(self.queryset.annotate(
name = F('master__username')
).values('name'))
print(" === query === ")
print(self.queryset.annotate(
name = F('master__username')
).values('name').query)
사실 annotate는 잘만 활용하면 정말 DRF의 효율을 극대화시킬 수 있다.
F 객체 외에도 Case, Count, Sum, When 객체를 활용할 수 있다.
(엑셀만큼 쉬운) Django Annotation/Aggregation
Django ORM을 강력하게 만들어주는 기능 중 하나는 바로 애너테이션(annotate)과 애그리게이션(aggregate)입니다. 이 두 기능이 명쾌하게 와닿지 않아서 사용하지 못하다가, 엑셀에 빗대어 이해해보니
blog.raccoony.dev
자세히 알아보고 싶다면 위의 블로그를 참조하자. 엄청나게 정리를 잘 해놓으셨다.
이걸 보고 annotate를 공부하진 않았었는데, 처음부터 이 블로그를 알았다면 좋았을 걸 ㅎㅎㅎㅎㅎ...
6. SubQuery
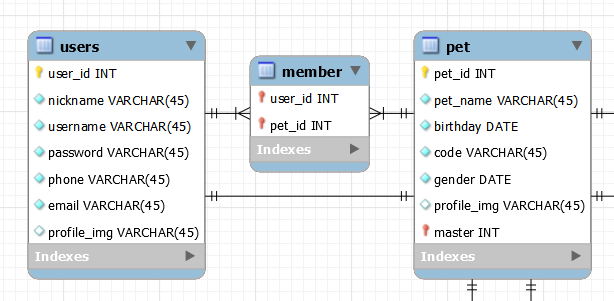
이건 조회 조건과 참조, 역참조 개념이 선행되므로 모르면 일단 넘어가자!!!
SQL문의 서브 쿼리식 또한 DRF에서 사용할 수 있다.
위의 모델은 pet의 master로써 user와 1대1로 대응하고 있다.
from django.db.models import OuterRef, Subquery우선 Subquery를 import 해놓자.
Pet의 master로서 등록된 User를 필터링하기 위해서 Subquery를 쓰면 다음과 같다.
class PetViewSet(ModelViewSet):
queryset = Pet.objects.all()
def list(self, request, *args, **kwargs)
pets = self.queryset.filter(gender='male')
qs = CustomUser.objects.filter(
user_id__in = Subquery(pets.values('master'))
)
print(qs)
print(" === query === ")
print(qs.query)
SELECT * FROM "users"
WHERE "users"."user_id" IN (SELECT U0."user_id" FROM "pets_pet" U0 WHERE U0."gender" = male)values를 썼을 때랑 같은 결과를 보여주지만 전혀 다른 로직이 쓰이고 있음에 주의하자.
이렇게 간단한 작업의 경우엔 Subquery를 쓰지 않는 것이 더 직관적이지만, 서브 쿼리문은 filter 메서드로도 커버하기 까다로운 복잡한 조건을 걸 때 사용한다.
예를 들어, 생일이 가장 빠른 pet의 master에게 해당 정보를 user의 쿼리셋 안에 추가하고 싶다고 한다면 다음과 같이 작성하면 된다.
class PetViewSet(ModelViewSet):
queryset = Pet.objects.all()
def list(self, request, *args, **kwargs)
pets_qs = self.queryset.filter(
master=OuterRef('pk')
).order_by('-birthday')
print(CustomUser.objects.annotate(
earliest_birth = Subquery(
pets_qs.values('pet_name')[:1]
)
).values('earliest_birth'))
근데 소규모 프로젝트에서는 이렇게까지 할만 한 일이 없어서 아쉽다.
정작 실전에서 못 써보고 있어서 설명이 힘들다. ㅠ
3. 조회 조건
데이터를 조회(filter, get)할 때 사용할 수 있는 검색 조건이라는 것이 있다.
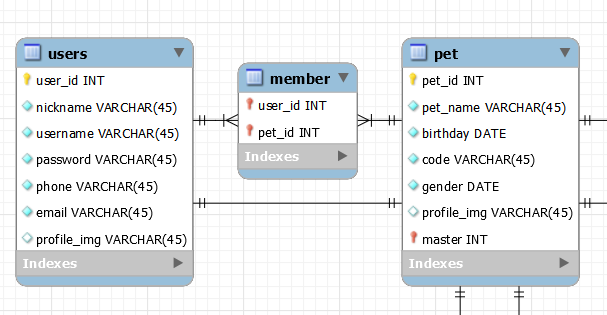
클라이언트가 펫의 정보를 알기 위해 API에 GET 요청을 보냈다고 하자.
그럼 요청을 보낸 유저의 정보를 갖고, 해당 유저가 멤버로써 속해있는 Pet의 정보를 얻고 싶다고 한다면
user와 member는 1:N 관계이므로 Pet의 조건은 N개의 멤버 데이터가 담긴 쿼리셋을 받게 될 것이다.
조건은 Pet의 pet_id와 member의 FK값은 pet_id가 일치하는지만 알면 되는데, member의 pet_id가 너무 많다면 반복문으로 처리를 해야하는 문제일까?
이럴 때는 filter의 조회 조건으로 '__in'을 걸면 끝난다.
class PetViewSet(ModelViewSet):
queryset = Pet.objects.all()
def list(self, request, *args, **kwargs)
member = Member.objects.filter(user_id=request.user)
pet_list = self.queryset.filter(pet_id__in=member.values('pet_id'))
pet_id 정보가 담긴 리스트를 던져줌으로써 filter가 알아서 값을 가져온다.
| 조회 조건 | 내용 |
| __contains | 특정 문자열을 포함하는 데이터 조회 |
| __icontains | 특정 문자열의 대소문자 구분없이 포함하는 데이터 조회 |
| __lt | 값이 작은 경우 (less than) |
| __lte | 값이 작거나 같은 경우 (less than or equal) |
| __gt | 값이 큰 경우 (greater than) |
| __gte | 값이 크거나 같은 경우 (greater than or equal) |
| __in | 주어진 리스트에 포함되는 데이터 조회 |
| __year | 특정 년도 조회 |
| __month | 특정 월 조회 |
| __day | 특정 일 조회 |
| __isnull | 해당 열이 null인 데이터 조회 |
| __startswith | 해당 문자열로 시작하는 데이터 조회 |
| __istartswith | 대소문자 구분 없이 해당 문자열로 시작하는 데이터 조회 |
| __endswith | 해당 문자열로 끝나는 데이터 조회 |
| __iendswith | 대소문자 구분 없이 해당 문자열로 끝나는 데이터 조회 |
| __range | 범위를 지정하여 조회한다. sql의 between과 같으며 'pet_id__range=(1, 10)'이런 식으로 사용할 수 있다. |
4. Reference(정참조) & Dereference(역참조)
이 내용은 정말 기초중의 기초로써 알아두어야 한다.
이걸 알아야 나중에 serializers.py를 작성할 때 특히 고생하지 않는다.
class CustomUser(AbstractBaseUser, PermissionsMixin):
user_id = models.BigAutoField(
primary_key=True,
unique=True,
editable=False,
verbose_name="user_id",
)
username = models.CharField(max_length=45,)
nickname = models.CharField(max_length=45, unique=True)
create_dt = models.DateTimeField(default=timezone.now, blank=True, null=True)
email = models.CharField(max_length=100, blank=True, null=True)
phone = models.CharField(max_length=45, blank=True, null=True)
profile_img = models.ImageField(upload_to="users/%Y/%m/%d/", blank=True, null=True)
is_staff = models.BooleanField(default=False)
is_active = models.BooleanField(default=True)
objects = CustomAccountManger()
USERNAME_FIELD = "nickname"
REQUIRED_FIELDS = ["username"]
class Meta:
db_table = "users"
verbose_name = _("user")
verbose_name_plural = _("users")
def __str__(self):
return self.username
class Pet(models.Model):
pet_id = models.BigAutoField(primary_key=True, unique=True, verbose_name="pet_id")
pet_name = models.CharField(max_length=45, verbose_name="pet_name")
birthday = models.DateField()
gender = models.CharField(max_length=45)
code = models.CharField(
max_length=45,
unique=True,
editable=False,
default=generate_random_slug_code,
verbose_name="code",
)
profile_img = models.ImageField(blank=True, null=True)
master = models.ForeignKey(
CustomUser, on_delete=models.CASCADE, db_column="user_id", related_name="master"
)
def __str__(self):
return self.pet_name
class Member(models.Model):
user_id = models.ForeignKey(
CustomUser,
on_delete=models.CASCADE,
db_column="user_id",
)
pet_id = models.ForeignKey(
Pet,
on_delete=models.CASCADE,
db_column="pet_id",
)와우 드릅게 길다.
정참조란 ForeignKey를 가지고 있거나 1대1 관계인 부모 모델을 참조하는 것이고,
역참조는 현재 객체를 참조하는 객체나 다대다 관계를 찾는다.
정참조가 염탐꾼 느낌이라면, 역참조는 스토커 뚜드려 잡는 경찰 느낌이다. (현재 새벽이라 비유가 개판)
1. Reference
FK에서 PK로 조회하는 것이 정방향이다. 이 경우는 굉장히 간단하다.
외래키나 OneToOneField가 걸려있는 필드에 '__'를 붙여주면 해당 객체를 참조한 상태가 되고
여기서 원하는 필드 값을 가져오면 된다.
annotate를 설명할 때 사용한 예시를 또 써먹어보자.
class PetViewSet(ModelViewSet):
queryset = Pet.objects.all()
def list(self, request, *args, **kwargs)
print(self.queryset.values('master__username', 'master__nickname'))
print(" === query === ")
print(self.queryset.values('master__username', 'master__nickname').query)
참고로 정참조에 한하여 딱히 제한이 걸려있지 않다.
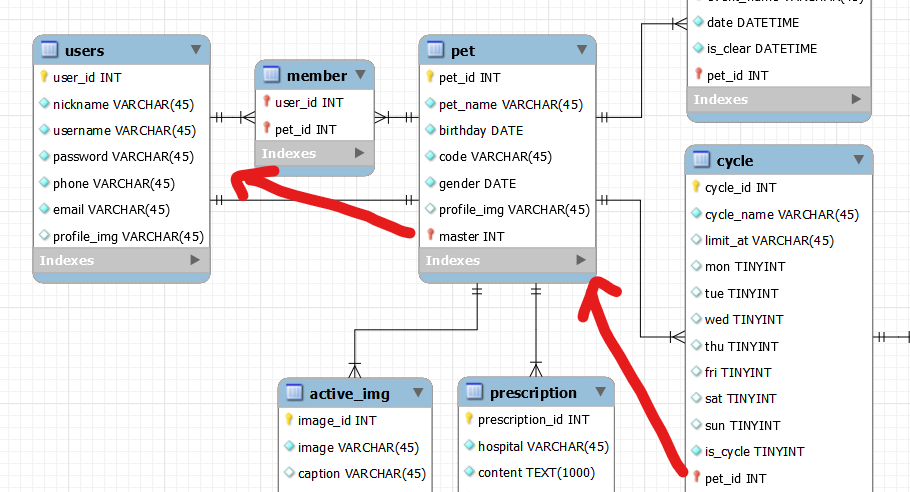
특정 Cycle 쿼리셋에 해당하는 user 정보를 한 줄만에 조회할 수 있다.
class PetViewSet(ModelViewSet):
def list(self, request, *args, **kwargs)
cycle = Cycle.objects.filter(cycle_id=2)
print(cycle.values('pet_id__master__username'))
print(" === query === ")
print(cycle.query)
여러 가지 쿼리셋을 가져올 수도 있지만 내 DB상 데이터가 전부 같은 유저 정보를 가리키게 만들어놔서 그냥 cycle_id에 조건을 걸어버렸다.
2. Dereference
역참조란 현재 나를 참조하는 쿼리셋을 찾는 방법인데 조금 헷갈릴 수도 있다.
위의 예시로 만든 모델에서 pet_id가 1인 펫을 참조하는 모델을 찾아보자.
class PetViewSet(ModelViewSet):
queryset = Pet.objects.all()
def list(self, request, *args, **kwargs)
print(self.queryset.get(pet_id=1).member_set.all())
print(" === type === ")
print(type(self.queryset.get(pet_id=1).member_set))
print(" === query === ")
print(self.queryset.get(pet_id=1).member_set.all().query)
나를 참조하는 모델명에 '_set'을 붙여주거나 FK 필드의 속성으로 related_name을 정한 것이 있다면
member_set 자리에 related_name을 넣어주어야 한다. (선택사항이 아니다.)
참고로 이 정도는 자유자재로 할 줄 알아야 이후에 serializer가 쉽다. 연습을 많이 하자.
이외에도 select_related나 prefetch_related 메서드로 참조할 수도 있지만 위의 두 가지 방법으로 커버 가능하다.