📌 Introduction
미리 자백하자면, 나는 LLM, RAG, MCP, AI Agent와 관련하여 모두 얕은 지식들 뿐이다.
그래서 아래에 적은 내용들이 일부(혹은 전부) 틀렸을 수 있음을 미리 알리고 시작한다.
LLM은 예전에 혼자 논문 읽어보고 그러긴 했는데, 워낙 예전 정보들인데다, 취미 삼아 읽은 정도라 의미가 없다.
그래서 어려운 표나 자료 같은 거 들고 오지도 않았다. 나도 모르는데 어떻게 인용함 ㅋㅋ
최근 사내에서 사용할 AI Agent를 개발하고 있는데, 우습게도 난 AI Agent가 뭔지 정의하지도 못했다.
뭘 만들어야 하는지도 모르겠지만, 만들다 보면 알게 되는 것들이 있을 것이라는 믿음 하나로 그냥 만들고 있을 뿐이었다.
처음엔 사내 인프라에서 제공하는 AI API를 연동해서 질문을 했다.
하지만 우리 서비스 도메인을 알지는 못했다.
다음으로 MCP를 연결해서 사내 문서를 조회할 수 있도록 context를 제공했다.
그러나 MCP의 토큰 비용은 결코 값싸지 않았고, 응답 시간도 느렸다.
embedded vector DB를 하나 붙여주기로 했다.
vector DB에 데이터를 넣기 위해서 text를 의미있는 단위로 나누고, tokenization하고, 좌표계로 임베딩을 했다.
조금 바보같긴 하지만 성실히 답해주는 친구가 생겼다.
하지만 자꾸 대화를 하고 있는 상대인 내 이름 하나 제대로 기억하질 못했다.
("내 이름은 OOO이야"라고 알려줬는데, 갑자기 "안녕하세요, 저는 OOO입니다. 무엇을 도와드릴까요?"이러면서 내 이름을 뺏긴 해프닝도 있었다.)
모든 질문을 임베딩하기엔 조금 그래서, 메모리 공간 일부를 덧붙여 세션 간 기억을 유지할 수 있도록 만들었다.
런타임에 온갖 빨간불이 켜지면서 난리를 치는 덕에 아직까지는 당췌 써먹을 수 없는 녀석이지만,
확실한 건 역시 만들어봐야 알게 될 것이라는 나의 믿음이 맞았다는 것이다.
📌 생각하는 뇌, LLM

대규모 언어모델(Large Language Model, LLM)은 생각한다. (고로 존재한다...ㅎㅎ...)
ChatGPT, Claude, Gemini 등 대부분의 AI라고 지칭하는 것들의 중심에는 LLM이 있다.
텍스트 생성, 텍스트 이해, 패턴 추론, 문제에 대한 해결 방안 제시 등을 수행하는 추론 엔진을 가진 이 녀석들은 방대한 학습을 통한 만들어진 천재들이다.
그러나 ChatGPT 첫 출시부터 사용해봤던 사람은 알겠지만, 당시 이들의 한계는 너무나도 명확했다.
학습이 종료된 시점에서 시간이 멈춰있으며, 개인이나 회사 내부 데이터는 학습되어 있지도 않았다.
그렇다고 대외비 문서를 업로드하면 보안상 문제가 발생할 우려가 있었고, context window(모델이 한 번에 처리하고 이해할 수 있는 전체 텍스트 문맥 범위)를 넘어서는 맥락이 주어질 수록 환각(hallucination) 현상은 심해졌다.
LLM은 눈을 가리고 과거만을 더듬는 고립된 천재요, 거짓말쟁일 뿐이었다.
📌 기억하는 뇌, RAG

검색 증강 생성(Retreval-Argumented Generation, RAG)은 이러한 고독한 천재에게 기억 장치를 달아주는 것과 같다.
위 그림은 내가 만들었지만 다소 오해의 여지가 있다.
마치 특정 도메인에 특화된 모델을 만들기 위한 fine-tuning과 헷갈릴 수 있으나, 그것과는 많이 다르다.
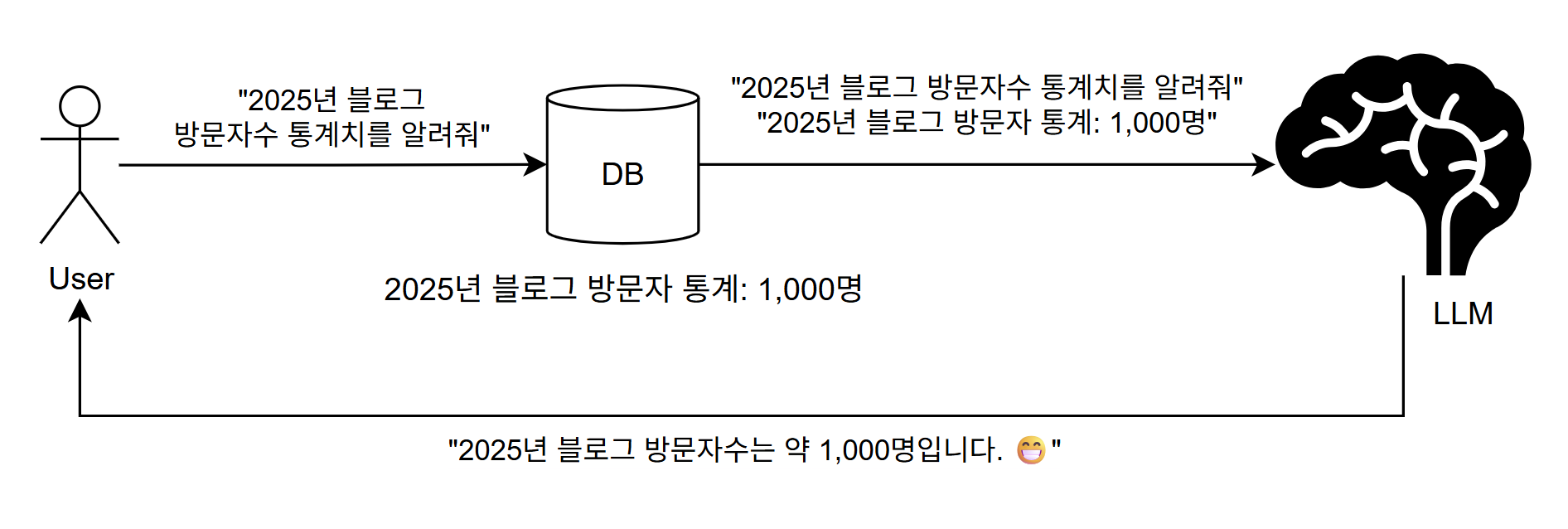
사용자가 쿼리를 보내면, 곧장 LLM에게 질문을 하는 것이 아니라 유사도를 측정해 DB에서 관련 Context를 조회하는 과정을 선행한다.
그리고 여기서 추출한 Context를 쿼리에 덧붙여서 LLM에게 보내면, LLM은 이 모든 정보들을 종합하여 문맥을 이해하고 적절한 응답을 반환하는 프로세스가 가장 보편적이다.
(이것마저 동적으로 처리하는 Agentic RAG라는 것도 있긴 한데, 내가 차마 아직 여기까진 넘보질 못하겠다.)
우리가 DB의 내용을 정기적으로 최신화 해주기만 한다면, LLM을 재학습 시킬 필요가 없어진다.
DB에 도메인 정보와 대외비를 담아둔다면, LLM은 private한 질문에 대한 답변까지 수행할 수 있게 된다. (그렇다고 Open AI 쓰면 위험하겠지만)
심지어 context window와 별개로 계속 데이터를 축적할 수 있다!
이로써 LLM은 과거의 지식만을 되짚는 고립된 천재에서 해방될 수 있게 되었다.
하지만 여전히 럭키 심심이에 지나지 않는다.
우리가 원하는 것은 단순히 질문에 대한 응답만을 하는 챗봇이 아니라, 주체적인 행위를 수행하는 존재를 만드는 것이다.
🤔 fine-tuning이랑 뭐가 다른데요?
풀스택 개발자에게 "계산기 애플리케이션을 만들어오세요"라고 요청하면 어떤 언어로 구현을 할까?
주로 사용하던 언어를 택할 수도 있고, 가장 구현이 쉬운 언어를 택할 수도 있고, 새로운 도전을 해볼 수도 있을 것이다.
반면 각각 js, kotlin이 주언어인 프론트 개발자, 백엔드 개발자 "계산기 애플리케이션을 만들어오세요"라고 해보자.
프론트 개발자는 js로, 백엔드 개발자는 kotlin으로 구현해올 것이다.
js는 결론만 간결하게 말하는 개발자일 수도 있고, kotlin은 친절하게 하나하나 설명하는 개발자일 수도 있다.
위와 같이 스타일과 전문성, 품질 기준 등을 특정 도메인에 특화되도록 모델을 훈련시키는 것이 fine-tuning이다.
현실적인 것만 말하자면 fine-tuning은 어렵다.
RAG도 쉬운 건 아닌지만, 체감 상 fine-tuning과 조금 다른 측면으로 어렵고 조금만 연구해도 개선되는 것이 눈에 확확 들어온다.
반면 fine-tuning은 모델 내부의 가중치 자체를 변화시키면서 학습을 시켜야 하는데, 애초에 그걸 할 줄 아는 사람이면 이 포스팅 안 읽었겠지.
(혹시나 읽고 있다면, 제 설명에서 틀린 부분 대차게 지적해주십쇼. 제발.)
📌 행동하는 신체, AI Agent
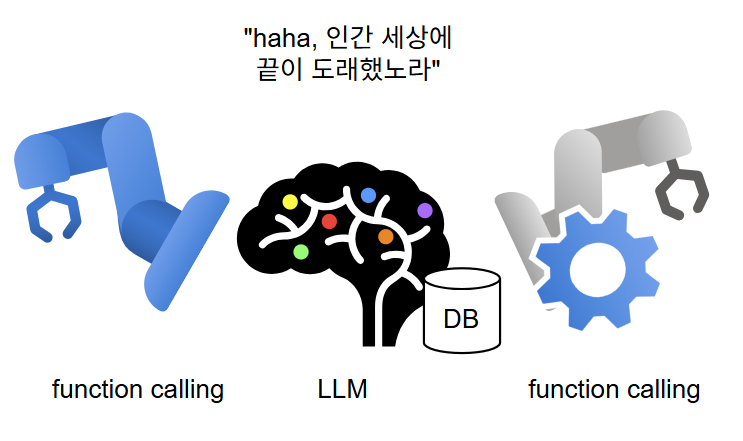
LLM은 어떻게 웹 서칭을 수행했을까?
크롤링 API를 열어놓고 해당 API를 호출할 수 있는 tool를 제작해 LLM에게 넘겨준 후, "이 내용을 웹에서 검색해주세요"라고 명령하면 LLM이 판단하고, tool을 사용한다.
function calling을 지원하는 모델에게 적절한 tools만 넘겨준다면, LLM은 이제 의도, 계획, 행동, 관찰, 피드백 루프를 실행하는 자율적 시스템으로 진화할 수 있게 된다.
예를 들어, 당신이 메일 사진을 찍어 LLM에게 요약을 요청했다고 하자.
LLM이 요약을 다 끝낸 후 "일정을 캘린더에 등록해드릴까요?"라는 질문을 던졌고, 거기에 "네"라고 답했더니 당신의 캘린더에 진짜로 일정이 생기는 것이다.
어쩌면 그 일정 이후에 할 만한 일을 추천해줄 수도 있고, 당신의 기존 스케줄과 겹치지 않도록 메일 상대에게 양해의 메일을 대신 전송할 수도 있을 것이다.
🤔 MCP와 RAG, MCP와 function calling이 뭐가 다르죠?
예전에 작성했던 "MCP(Model Context Protocol)는 혁신이라 할 수 있는가?"에서 말했듯, MCP를 통해 Context가 무한대로 확장되었다는 표현은 다소 과장된 마케팅일 뿐이다.
그럼에도 MCP로 정보를 얻는 것과 RAG로 정보를 얻는 것의 차이, function calling과 MCP 사용의 차이에 대해 혼란이 조금 있었다.
우선 RAG는 주체가 LLM이 아니라 LLM을 사용하는 시스템에 있다. (단, Agentic RAG에선 LLM이 RAG 프로세스까지 제어한다.)
사용자 질문에 미리 저장해둔 연관된 정보들을 조회하여 context를 추가로 전달해주며, 만약 Vector DB의 최신화가 이루어지지 않으면 LLM은 다시 고립된 천재로 회귀한다.
또한 RAG는 특화된 지식들을 저장하고 기억 저장 장치의 목적으로 사용될 뿐, LLM에게 행위를 할 수 있는 기능을 제공해주지는 않는다. (web의 모든 정보를 vector DB에 담을 수 없고, vector DB만 있으면 LLM은 여전히 챗봇에 불과하다.)
따라서 RAG와 MCP는 대립 관계가 아니라, 보완 관계, 즉 완전히 다른 목적으로 사용된다.
그리고 function calling만으로 모든 것을 구현할 수 있는 것은 사실이다.
하지만 위 사진에서 보듯, function calling을 하기 위해 다른 LLM Provider와 통신해야 한다면 어떨까.
캘린더 조회, 등록을 위해 해당 API 스펙에 맞춰 구현하고, 메일 전송을 위해 Google API 스펙에 맞춰 구현해야 한다면, LLM에게 행위를 부여하기 위한 노력이 너무나도 많이 들어가게 된다.
이를 방지하고자 통신 프로토콜을 표준화한 것이 MCP고, MCP Server만 잘 만들어두면 여러 LLM 클라이언트에서 하드 코딩없이 재사용할 수 있는 것이다.
📌 Conclusion

AI Agent를 만들다보면 결국 위 개념들은 모두 접하게 되어있다. (안 하면 도저히 써먹을 만한 게 나오질 않는다)
LLM만 집중하면 최신 정보 수집과 목적을 수행할 수 없고,
RAG만 집중하면 추론이 불가능하며,
Agent만 집중하면 생각과 지식 없이 무작위로 도구를 휘둘러대는 미치광이가 탄생할 뿐이다.
그래서 AI 시스템을 만들려거든, 적어도 위 세 가지에 대해서 조금씩 알아가보길 바란다.
일단 나부터. 🫡