N 플리마켓이 그랜드 오픈했습니다. 🤗
1. Introduction
📌 Planning

한 달 전쯤, 맡은 기능을 어찌저찌 모두 쳐내고 잉여롭게 공부하며 이틀정도 시간을 보내다가 문득 '내가 이렇게 돈을 받아도 되는 건가?'라는 생각이 머릿 속을 스쳐지나갔었다.
팀원 분들은 런칭이 얼마 남지 않아 동분서주하고 계시는데, 혼자 책펴고 공부하고 있으려니 권태감이 들어, 일이 너무 하고 싶다고 간청하여 업무를 받았었다.

사실 신입인 내가 사고나 치지 않으면 다행이지 않을까 싶어서 기능 태스크는 기대도 안 했었고, 체크 스타일 맞추거나 버그 찾기 같은 업무나 처리할 생각이었다.
적어도 내가 그런 자잘한 작업이라도 처리하면 팀원 분들께서 핵심 기능에 보다 집중할 수 있지 않을까 싶었다.
그런데 웬걸? 각자 자신이 맡은 기능에 엑셀 다운로드 기능 태스크가 할당되어 있던 것들이 통채로 나에게 굴러들어오는 행운이 찾아왔다.
핵심 기능은 아닐지언정, 이렇게 되면 내가 취할 수 있는 액션이 훨씬 많아진다.
이전에 작성했던 "코드에 기교를 부리지 마세요"에서 썼던 것처럼, 국소적인 영역만 보고 설계를 하는 것과 기능 전체를 통합하여 보고 설계하는 것에는 큰 관점의 차이가 존재하기 때문이다.

그래도 학생 때처럼 "일단 질러보고, 안 되면 고치자~"라는 접근법에 엄청나게 관대할 순 없으니, 최대한 실용적인 솔루션을 고려해볼 필요가 있었다.
기능을 다 만들어 놓고 피드백을 받으러 들고 가면, 개선을 바라는 팀원이 의견을 제시하는데 난처하게 만들 우려가 있으니 프로토타입 개발 전략으로 진행하기로 했다. (개선했으면 좋겠는데 이미 완성된 걸 들고 가버리면 고치라고 하기 어렵다.)
그래서 다음 방법으로 개발을 진행했었다.
- 단 여러 방법들을 모색해본다.
- 제 AI로 후보 전략들을 빠르게 프로토타입으로 만든다.
- 피드백
- 최종 선정한 아이디어를 기반으로 시스템 아키텍처를 설계한다.
- 피드백
- 구현
2. Ideas
📌 Apache POI

Java 진영에서 .xlsx 파일을 생성하는데 있어 사실상 Apache POI를 능가할 수 있는 건 없다.
Apache License 2.0에 따르면 사내 서비스/상용 서비스에서도 자유롭게 사용 가능하고, 서버사이드(SaaS)로만 사용 시엔 소스 공개 의무까지도 없다.
가장 전통적이고 잘 알려진 방법이긴 하나, 몇 가지 문제점이 있었다.
1️⃣ 대용량 데이터 처리 시 서버 부하
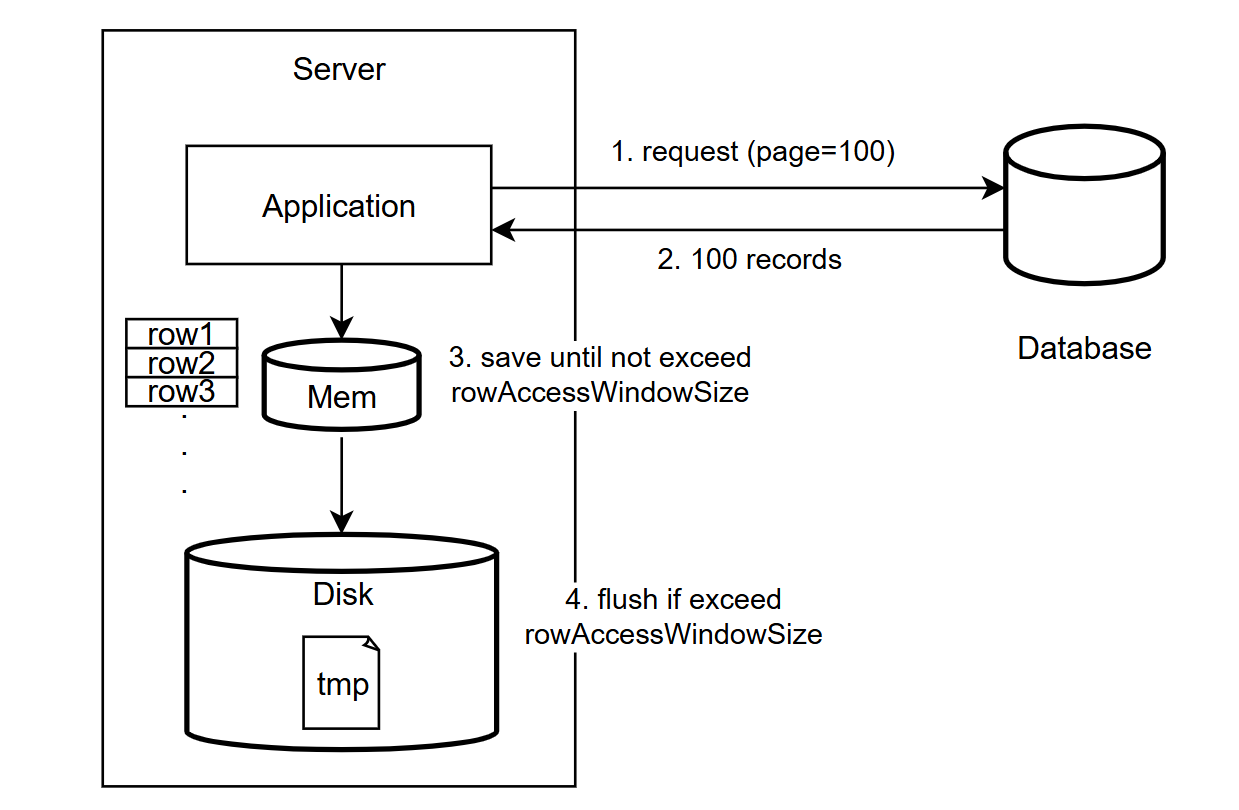
과거 XSSFWorkbook의 문제는 모든 데이터를 메모리에 저장한다는 점이었다.
그렇기 때문에 데이터 양이 메모리 크기를 오버하는 순간 OOM이 발생할 우려가 있었는데, SXSSFWorkbook은 이러한 문제를 해결하기 위해 rowAccessWindowSize를 생성자에서 입력받도록 처리했다.

try (SXSSFWorkbook workbook = new SXSSFWorkbood(ROW_ACCESS_WINDOW_SIZE)) {
...
} catch {
...
}즉, 메모리 공간에 상주시킬 최대 window size를 설정해두면, row가 임계치를 초과할 때마다 disk에 임시 파일을 생성해 flush하면서 주기적으로 메모리를 비워주는 방식으로 진화했다.
사실 위 방식은 xlsx를 만드는 아이디어 중에서 가장 성능이 좋다.
데이터가 많아지면 많아질 수록 성능의 우월함은 다른 방법에들 비해 두드러지고, disk 공간에 임시 파일이 커지는 것도 엑셀 다운로드용 개별 pod을 띄워놓았기에 큰 문제가 되진 않았다.
해당 기능을 클라이언트도 한정적이었기에 트래픽도 예측 가능한 수준이었으므로, 이 방식을 채택한다고 해서 문제가 생길 여지는 크게 없었다.
문제는 데이터가 많아졌을 때, 엉뚱한 이유로 서버에 부하가 발생할 수 있다는 점이었다.
2️⃣ 사용자 경험 저하
두 가지 시스템이 있다.
하나는 요청을 보냈을 때 2초간 아무런 반응이 없다가 2초만에 완료되고, 다른 하나는 1ms만에 반응은 오지만 작업이 5초 동안 진행된다.
아이러니하게도, 사용자 관점에서는 후자가 좋다.
어쨌든 빠른 피드백이 돌아오기 때문이다.
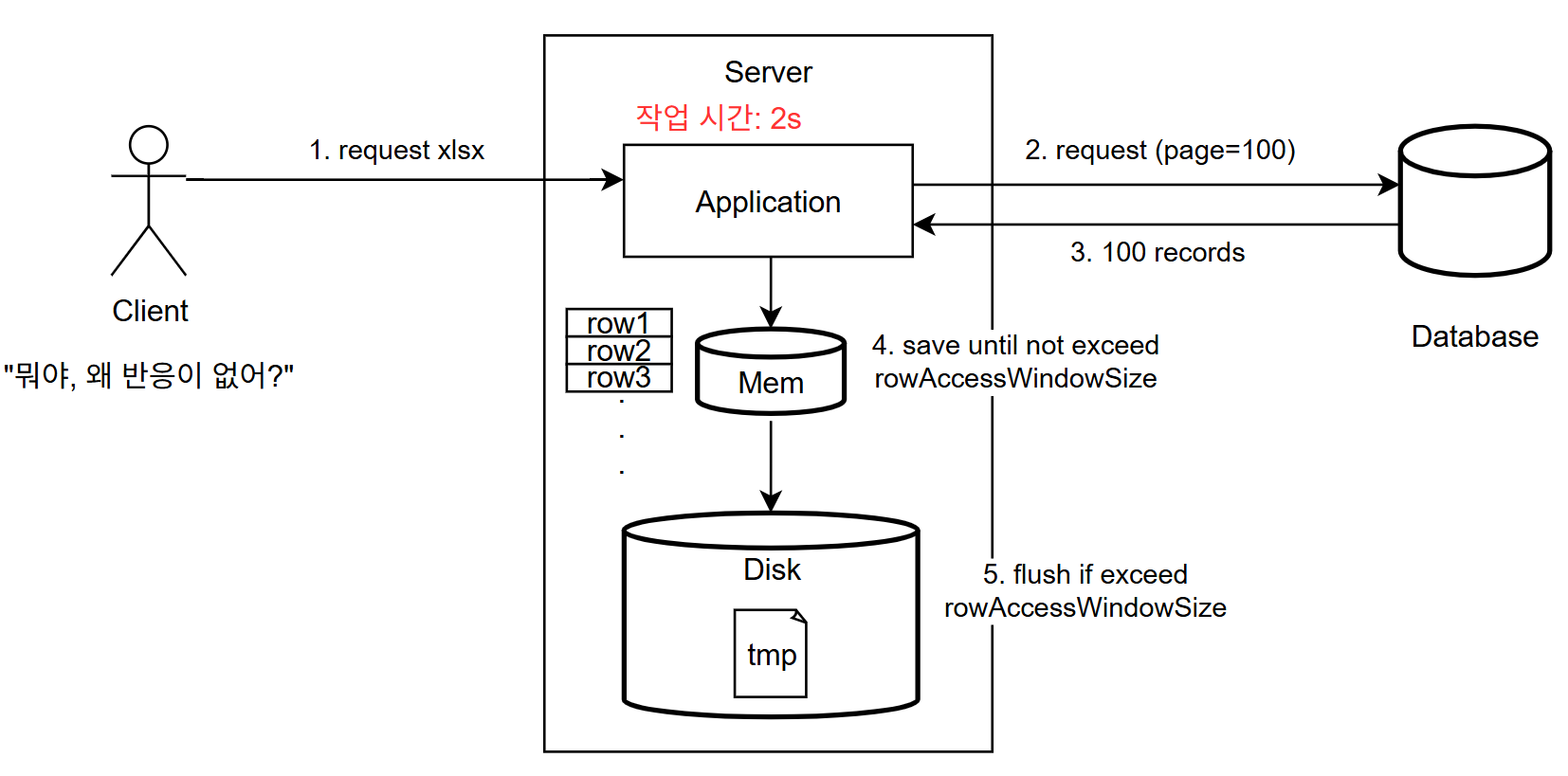
방금 전 그림을 클라이언트까지 확장해서 바라보자.
데이터가 방대해지더라도 pod의 가용공간이 충분하며, auto scale로 트래픽 스파이크를 잡을 수 있기에 SXSSFWorkbook을 사용해서 처리해도 서버 입장에선 큰 무리가 없다.
하지만, 그렇다고 DB I/O 시간이 빨라진다는 의미는 아니다. 이는 Apache POI와 독립적인 문제다.
하루 평균 10만 건 이상의 데이터가 축적되고 사용자가 최근 1개월 이내 데이터만 확인할 수 있다는 제약을 걸어도, 최소 31만 건을 DB에서 조회해와야 한다.
더 넓은 기간을 선택할 수 있거나, 데이터가 많아질 수록 DB에서 데이터를 가져오는 시간은 더 오래 걸릴 수밖에 없다.
사용자가 기대했던 것은 아마 다운로드 버튼을 눌렀기에, 브라우저 다운로드 진행 현황이 반응하는 것을 기대했을 것이다.
그러나 실상은 서버가 대용량 데이터를 처리하느라 응답을 제때 하지 못하고 있기에, 브라우저는 아무런 반응조차 하지 않고 있다.
그 다음 사용자의 행동을 예측하는 것은 어렵지 않다.
다시 한 번 엑셀 다운로드 버튼을 클릭할 것이다. 어쩌면 연타할 수도 있다.
서버의 불필요한 자원 낭비와 부하는 여기서 비롯하게 되는 것이다.
위 문제를 해결하기 위해서 몇 가지 아이디어를 떠올려볼 수 있다.
- 데이터를 불러오는 대로 클라이언트에게 streaming으로 응답
- 쓰로틀링이나 디바운스, 혹은 Rate Limit으로 사용자 연타 방지
- 동일 사용자 요청을 식별하여, 진행 중인 요청에 대한 중복 요청 방지
- DB에서 데이터를 가져오는 속도를 더 빠르게 만들기
- 사용자가 엑셀 다운로드 요청을 보내면 Batch로 작업을 하고, 다운로드 가능한 링크를 알려주기
등등.
2번은 사용자의 경험을 떨어트린 채로 서버의 안위만 걱정하는 것이므로 근본적인 해결책이라 볼 수 없다.
3번은 동일 사용자 식별을 위해 기술적으로 해결하는 비용이 높아질 우려가 있고, 4번은 pagination cursor같은 방법을 고려해볼 수도 있긴 하나 팀원들을 설득하기 위한 시간이 필요한 것과 더불어, 안정성이 우선시되는 시스템 특성과 빠듯한 데드라인이 잡힌 현상황을 고려했을 때 꺼내볼 수 있는 이야기는 아니었다. (인덱싱은 많은 데이터에서 적은 양을 빠르게 식별하기 위함이지, 결과 집합이 큰 경우에는 큰 의미가 없으니 고려 대상이 아니다.)
5번은 세 가지 방법으로 구현해볼 수 있다.
- 요청 -> 다운로드 가능한 경로를 클라이언트에게 응답
- 토스트로 작업이 진행 중임을 띄워줄 수 있고, 문제가 발생했을 때 즉각적인 피드백도 가능
- 처리하는 동안 불필요하게 커넥션을 계속 물고 있음
- 요청 -> 배치 처리 -> 메일로 다운로드 경로 알림
- 굳이 또 배치 애플리케이션 만들거나, 기존 시스템에 배치 처리 서비스를 만들어야 함.
- 기존 컴포넌트 재사용하기도 어렵고, 3번만큼 비용이 높아지진 않겠지만 번거로움.
그렇다면 Streaming 응답은 어떤가?
모든 row를 처리할 동안 기다리지 않고, window size만큼 클라이언트로 전달하면 되지 않을까?
3️⃣ Streaming 응답 불가
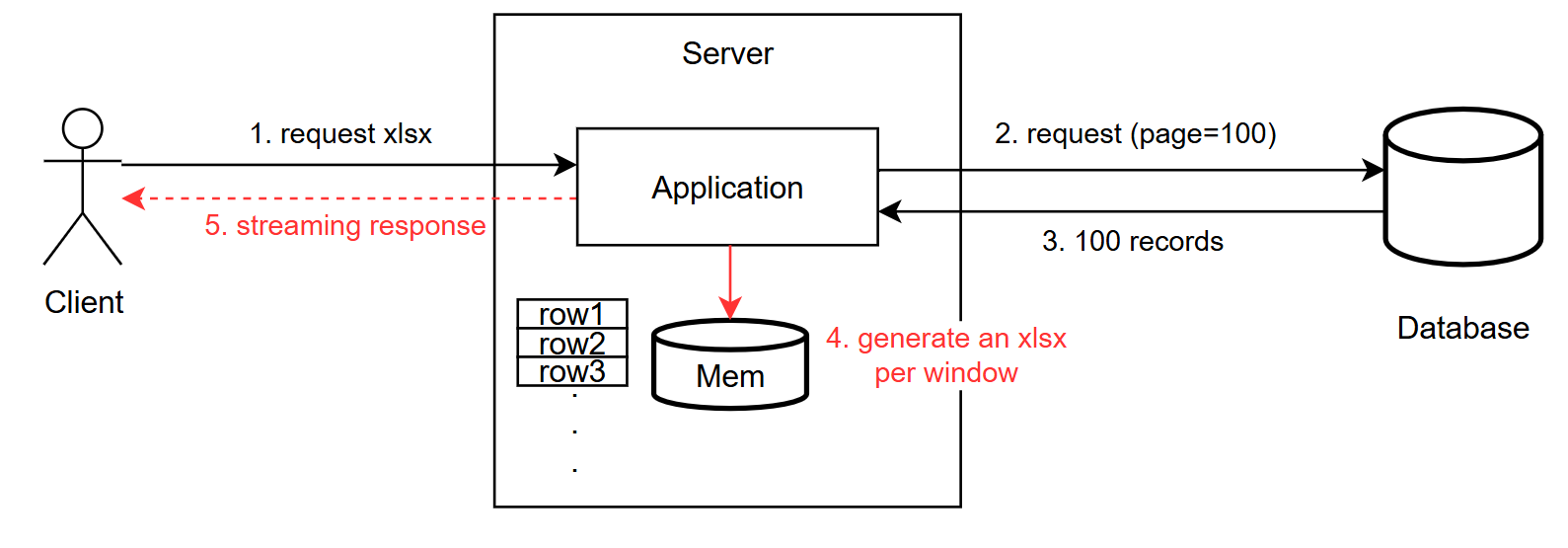
위와 같은 프로세스가 가능하다면 어떨까?
window 사이즈가 넘을 때 disk에 저장하는 게 아니라, 바로 xlsx 파일을 만들어서 client에게 보낸 후 client에서 조합을 하도록 만들면?
위와 같이 처리되면 참 좋겠다고 생각은 했었으나, 그렇다고 큰 기대를 하지는 않았었다.
예전에 PCM을 WAV로 패키징하는 처리를 통해서 data와 데이터를 감싸는 wrapper의 차이가 명확하다는 것을 알고 있었고, 이번에도 당연히 안 될 것이라 예상은 했었다.

스트리밍 응답이 불가능한 것은 아니다.
하지만 SXSSFWorkbook의 outputStreaming에 쓰는 과정은 모든 xlsx를 만든 후, 만들어진 결과를 스트리밍으로 전달할 뿐이다.
쉽게 말해, 데이터를 모두 수집하고 ZIP으로 패키징하는 과정이 끝나야지만 xlsx 파일로 동작을 하기 때문이다.
내가 원한 것은 모든 과정이 streaming이 되길 바랬지만, 이 방식은 단순히 Application to Client 단계에서만 streaming으로 동작할 뿐이었다.
📌 ExcelJS
서버가 됐건, 클라이언트가 됐건 어디선가는 책임을 지고 xlsx를 만들긴 해야 한다.
그러나 서버에서 streaming 응답을 위해 xlsx 생성 책임을 질 수 없다면, 해당 책임만을 클라이언트에게 넘겨버리면 된다.
2021년에 Naver D2에 올라온 글을 읽어보면 이해할 수 있다.
(사내에서만 확인할 수 있는 내용인 줄 알고 글을 써도 되나 한참 고민하고 있었는데, D2에도 공개되어 있길래 안심하고 올림..)
읽어보면 딱히 어려운 글은 아니다.
서버가 outputStreaming으로 데이터를 서빙해주면, 클라이언트 단에서 데이터를 받으면서 xlsx로 만들면 되는 것 뿐이다.
xlsx 생성과 streaming을 동시에 할 수 없으니, xlsx 생성을 클라이언트 단에서 수행하는 것.
이 방식을 고려하긴 했지만, 두 가지 관점에서 사용이 꺼려졌다.
- D2에서는 Node.js 기반 SSR 방식이지만, 우리는 CSR 방식의 프론트 라이브러리를 선택했다. 그 말은 즉, xlsx 생성의 부담을 클라이언트 측으로 전가시켜야 한다. 장애가 발생하더라도 서버에서 발생하는 것이 대응하기 편하지, 클라이언트 환경에 의해 성공 여부가 좌우되는 것은 리스크가 너무 컸다.
- 아무리 풀스택 직군이라지만 우리 팀은 백엔드 기술 스택에 익숙한 상황이다. 그런데 js를 사용해서, 익숙치도 않은 latest releases가 2023년인 라이브러리를 사용하는 것은 아무래도 납득하기 어려웠다.
📌 Streaming Response (return CSV)
streaming으로 응답하는 것을 포기해야 하나 고민하던 찰나, 엑셀 다운로드를 수행하는 주체가 누구인지를 다시 한 번 떠올려봤다.
엑셀을 요구하는 사용자는 불특정 다수가 아니었고, 사용자들은 모두 엑셀을 잘 다루는 사람들이었다.
그말은 즉슨 내가 예쁘게 엑셀을 전달해주는 것보다, 빠르게 데이터만 서빙해주면 알아서 데이터를 능숙하게 처리할 전문가들이었기에 굳이 xlsx여야 할 이유가 없었다.
csv(Comma-Seperated Values) 파일은 데이터를 그저 row마다 개행을 해주고, column마다 콤마를 붙여주면 끝난다.
별도의 패키징 과정도 필요없고, 데이터 포맷 형식을 맞추는 것도 쉽고, streaming 응답을 통해 서버의 메모리 부하 또한 줄일 수 있다.
이건가? 이거다.
바로 사내 챗에 아이디어 리스트를 좔좔 읊었고, csv로 반환해도 좋다는 ok 사인을 받은 후 시스템 설계를 시작했다.
3. Design
📌 Architecture
시행착오가 몇 번 있었다.
완전히 새로운 아키텍처를 세우는 것도 아니고, 그렇다고 내가 개인 프로젝트에서 사용하던 아키텍처 기반으로 설계하는 것도 아니고, 팀 내에서 이미 정한 기본적인 골격에 녹아들게 만들기 위해 고민을 많이 했었다.
처음에는 Spring MVC에서 Streaming 응답을 위해 다음과 같이 작성하는 것도 전부 감추고 싶은 마음이 컸다.
@GetMapping(value = "/foo/export", produces = "text/csv")
public ResponseEntity<StreamingResponseBody> export(RequestQueryParam param) {
StreamingResponseBody body = outputStream -> fooExportUseCase(param, outputStream);
var filename = URLEncoder.encode("foo.csv", StandardCharsets.UTF_8);
var headers = new HttpHeaders();
headers.setContentDisposition(ContentDisposition.attachment().filename(filename).build());
headers.setContentType(MediaType.parseMediaType("text/csv"));
return ResponseEntity.ok().headers(headers).body(body);
}filename만 다른데, 이걸 중복 선언해주는 게 귀찮아서 다음과 같이 만들 수는 없을까 싶긴 했다.
@ExportExcel(
resource = "FOO",
fileName = "foo_{yyyyMMdd}.csv"
)
@GetMapping(value = "/foo/export", produces = "text/csv")
public ExportQuery<RequestQueryParam, FooView> export(RequestQueryParam param) {
RowMapper<FooView> fooRowMapper = new FooRowMapper(); // 헤더와 매핑 방법 정의
return ExportQuery.of(fooExportUseCase, param, fooRowMapper);
}HandlerMethodReturnValueHandler를 구현한 커스텀 Handler를 구현하면, 위 방식을 구현할 수 있기는 하다.
그런데 useCase를 controller 밖으로 던지질 않나, 기존 방식에 비해 오히려 학습 비용이 증가하는 것 같아서 꼴보기 싫어졌다.
다시 한 번 생각해보자.

기존 시스템 아키텍처를 유지하면서 가능한 기존 조회 메서드를 그대로 활용하고자 한다면, UseCase 레이어에서 csv 파일을 생성해 반환해야만 한다.
아무리 파싱 로직이라지만 UseCase가 기술적 세부 사항을 담는 것은 아니라고 생각했고, 모든 엑셀 다운로드 기능마다 UseCase에 중복 로직을 담고 싶은 마음도 없었다.
어느 날 요구사항에 "csv말고 xlsx로 바꿔주세요"라고 했을 때, 변경 사항을 최소화 하려면 포맷터 처리는 한 곳에서 담당하는 것이 변경에 유연하다.

이번에는 데이터를 포맷팅하는 로직을 담당하는 ExportService를 분리하고, ExportUseCase에서 데이터 응답을 위해 사용할 Service를 전달해주는 방법을 생각해봤다.
하지만 기존 컨벤션에 의해 Service가 다른 Service를 의존하는 것은 원칙적으로 금지되어 있다.
그것이 설령 인터페이스라 할지라도.
일정이 조금 널널했다면 기존 아키텍처 개선안에 대한 아이디어를 말씀드려봤겠지만, 당시는 전혀 그럴 상황이 아니었기에 다른 설계안을 더 고민해보기로 했다.
애초에 ExportService에서 필요로 하는 것은 무엇인가? 그저 데이터 뿐이다.
다만 SearchService의 조회 방식이 어떨지는 알 수가 없다.
Offset 페이지네이션일 수도 있고, No-offset 페이지네이션일 수도 있고, 그것도 아니면 cursor 방식일 수도 있다.
각각의 조회 방식에 따라 유연하게 대응하기 위해서는 ExportService는 SearchService의 조회 방법에 대해 모르게 만들어야 하지만, 그렇다고 해서 SearchService가 그 역할을 위임하게 하는 것도 올바르지 않다.
잠깐. 데이터를 읽어온다고?
이거 완전 Iterator가 떠오르지 않나? (다소 억지 전개)

데이터를 읽어오는 방식을 정의한 Iterator와 csv header, row format을 정하기 위한 메타 데이터를 ExportService로 전달해준다면 SearchService에 대한 ExportService의 직접 의존성을 끊어버릴 수 있다.
이를 위해, 람다식에 SearchService를 넣어서 전달해야 하는 기교가 발생하겠지만, 어차피 Bean은 ApplicationContext 레벨에서 관리되는 Proxy이므로 객체가 복사된다거나 하는 이상 현상이 발생하지도 않는다.
이 구조가 최선이 아님에는 동의하지만, 기존 컨벤션을 최대한 위배하지 않으면서 세부 규칙을 UseCase로부터 감추는 조건을 동시에 달성하려면 기존 아키텍트를 통채로 수정해야 하므로 무리가 있다.
4. Implement
제가 작성했지만 어쨌든 사내 코드이므로 세부 코드는 올릴 수 없음을 미리 말씀드립니다. (저도 제 자식 자랑하고 싶어요.)
📌 ExportService
난 사실 ExportEngine이라고 네이밍을 짓고 싶었다.

하지만 이런 나의 소심한 야망이 더 커지기 전에 스스로 묻어버렸다.
ExportService의 스펙은 다음과 같다.
- Input: export 설정값(e.g. 헤더, row 포맷 등), iterator, outputStream
- Output: outputStream을 통한 row 쓰기
- 역할
- export 설정 메타데이터로 적절한 RowWriter 선택
- iterator를 순회하면서 outputStream에 data 쓰기
- 적절한 예외 처리
실제 코드에선 이런 플로우로 진행될 것이다.
@Service
public class CsvExportService implements ExportService {
public <R> void execute(ExportOption<R> exportOptions, ExportIterator<R> iterator, OutputStream outputStream) {
try (RowWriter writer = getWriter(exportOptions.type())) {
while (iterator.hasNext()) {
R row = iterator.next();
String[] columns = extractColumns(exportOptions.rowMapper(), row);
writer.writeRow(columns);
writer.flush();
}
} catch {
...
}
}
}데이터를 csv 포맷에 맞추는 역할은 CsvRowWriter에게 위임했다.
그것이 원하는 파일 형식 별로 디테일을 맞추기도 편했고, Adapter처럼 쓰기도 용이했기 때문이다.
📌 Other Components...

개인 프로젝트였으면 하나하나 코드 다 올렸을 텐데, 한참 고민해본 결과 이제 갓 면수습을 한 내가 그런 감당 못할 짓은 하면 안 된다고 판단이 들었다.
그래서 이 내용은 다이어그램으로 대체하기로 결정.
RowWriter의 RowMapper의 선언과 생성 위치가 다른 이유는 두 정보의 맥락을 결정하는 위치가 상이하기 때문이다.
말 그대로 ExportService의 쓰기 포맷과 방식에 대해 결정하는 RowWriter와 달리, RowMapper는 도메인 정보를 기반으로 정의되어야 하기 때문에 반드시 사용자에게 입력을 받아야 한다.
4. Conclusion
📌 기존 골격에 나의 설계를 담는다는 건 배로 어렵구나..
이번에 가장 어려웠던 건 기능 구현이나 설계가 아니었다.
이미 정해져 있는 팀의 컨벤션을 따르기 위해 설계적 결함을 수정함과 동시에 요구사항을 충족하기 위해 고민하는 게 가장 머리가 아팠다.
이것도 따지고 보면 설계긴 한데..
최우선 목표가 기존 소스 코드를 최대한 재활용하는 것이었고, 부차적으로 사용하기 쉽고 이식성이 높은 설계를 하는 것이었는데 제법 나쁘지 않았던 거 같기도 하고?
그런데 Csv 말고 뭐 얼마나 다양한 Writer가 생길 거라고 괜히 오버한 측면이 있던 거 같기도 하다.
일단 CsvExportService에다 파싱 로직 전부 넣어버렸어도 되었을 거 같았던 느낌.
우아한 기술 블로그에서는 아예 Apache Poi를 엑조디아마냥 조각조각 나누어서 라이브러리에 가까운 무언가를 만들어버렸던데, 나도 저만큼 많은 엑셀 기능이 시스템에 포함되어 있었다면 진짜 각잡고 해볼 수 있었을 거 같은데 아쉽긴 하다.
그래도 오랜만에 소소하지만 설계다운 설계를 해볼 수 있어서 좋았었다. (한 달 전의 일이라 과거형)