🙇♂️ 과거에 RepositoryItemReader가 최악의 성능을 보인다는 분석은 엄연히 제 실수였습니다.
RepositoryItemReader가 최악의 성능을 보인다는 수치를 보인 이후, 당시 작업이 너무 많아 원인을 제대로 분석할 여유가 없어서 추측만 하고 넘겼었습니다.
그러나 반 년이 지난 지금까지도 개인적인 의문이 풀리지가 않았고, 그 와중에 조회수는 계속 오르고, 제 말이 사실인 것처럼 받아들이신 분들까지 나타나는 상황을 보았습니다.
찝찝한 기분이 들어 급하게 다시 분석해본 결과, RepositoryItemReader의 성능 저하는 제가 만든 Repository 구현체에서 비롯했으며, 잘못된 정보를 장기간 전달드리게 되어 사죄의 말씀드립니다.
처음엔 Hibernate의 동작을 알아보는 방향으로 포스팅을 작성하려 했지만, 도중에 문제가 전혀 다른 곳에서 발견되어 틀을 전체적으로 수정하게 되어 맥락이 이상하게 느껴질 수 있습니다.
해당 포스트의 목적을 한 줄로 요약하면, "기존의 커스텀 ItemReader 구현 없이, RepositoryItemReader를 사용하여 비슷한 수준의 성능을 구현"하는 것입니다.
새로운 도구를 만드는 건 분명히 즐거운 일이지만, 실무적인 관점에서 봤을 때 이런 해결책은 별로 선호되지 않기 때문입니다.
1. Introduction
📌 Question
[Spring Boot] Batch 성능 개선기 (+`24.07.25 추가 개선 및 테스트)
📕 목차1. Introduction2. Reader3. Page offset4. Writer5. Improved Performance6. Additional Improvement1. Introduction 📌 Goal [Spring Boot] 정기 푸시 알림(Push Notification) 전송 배치(Batch) 프로세스💡 문제가 되는 부분이 많
jaeseo0519.tistory.com
예전에 작성했던 Spring Batch에서 RepositoryItemReader가 최악의 성능을 보이는 것을 확인했었다.
그리고 그 원인에 대한 추측으로 다음 두 가지를 제시했었다.
- Hibernate 기반의 Jpa Repository으로 인한 지연
- 리플렉션으로 인한 지연
당시에는 어떻게든 빨리 개선을 해내는 것이 목표였기 때문에 구체적인 이유를 알아보지 못 했지만, 8개월이나 지난 지금까지도 여전히 근본적인 이유에 대해 궁금증이 가시질 않았다.
왜냐하면, 다음 두 가지 질문에 대한 해답을 끝내 얻지 못했기 때문이다.
- Hibernate 구축 비용만으로도 이 정도의 지연이 생길 수 있는가?
- 애초에 Join을 하는데다, SELECT 절로 필요한 데이터만 가져오는데 2차 캐시로 인한 지연이 발생할 수가 있긴 한가?
- 설령 그렇다 하더라도, Reader에서는 데이터 조회만 수행하는데 dirty checking 오버헤드도 일어나지 않을 텐데?
- 같은 repository를 리플렉션으로 여러번 호출하는 것이 이 정도로 심각한 성능 저하를 유발할 수 있는가?
- Java 튜토리얼 Reflection API에서 reflection은 특정 JVM에서 최적화 수행이 불가하므로, 성능에 민감한 애플리케이션에서 자주 호출되는 코드에서 사용하는 것을 삼가라고 한다.
- 그러나, ORACLE - The Java HotSpot Performance Engine Architecture: Chapter 4 - Performance를 읽어보면 자주 사용되는 리플렉션 객체에 bytecode stubs을 생성함으로써, 리플렉션 호출과 관련된 오버헤드를 완전히 제거한다고 명시되어 있다. (HotSpot JVM만 해당되고, 다른 JVM은 확인 안 해봤다.)
하지만 다른 공부할 거리들에 치이는 상황에서 자칫 Hibernate 내부 동작까지 열어봐야 할 수도 있는 작업을 쉽사리 건드린다는 건 현명하지 못한 생각이었다. (대충 하고 싶은 걸 하는 게 아니라, 해야 할 걸 해야 한다는 말)
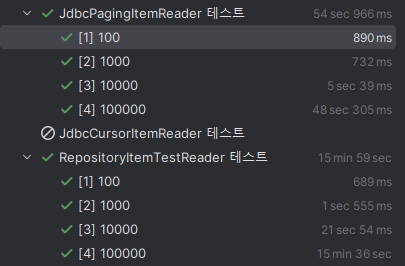
그래서 한 동안 애써 머릿속에서 지우고 살고 있었는데, 오랜만에 그 때 성능을 측정했던 그래프를 구경하다 이상한 점을 발견했다.

정말 하이버네이트 혹은 리플렉션에 의한 지연이라면, 데이터 수가 적어도 이보다는 더 높은 수치가 나와야 하지 않았을까?
그런데 그래프를 보면, 데이터 수의 증가에 따른 수행 시간이 기하 급수적으로 증가하고 있다.
JVM이 reflection으로 호출한 클래스 정보를 컴파인단에서 최적화 해주지 않는다 하더라도, 데이터 1,000개에서 근소한 성능 차이를 보이던 것이 10,000개에서 20배 가까운 차이를 보일 수 있다는 것이 합리적인가?
리플렉션이나 하이버네이트로 인한 문제였다면, 선형적으로 증가하거나 그와 비슷했어야 맞다.
그러나 지금 이건 누가 봐도 쿼리 문제다.
그러다 불현듯 no-offset의 차이 때문은 아니었을까라는 생각이 스쳐지나갔다.
물론, 이는 똑같이 no-offset을 적용하지 않은 JdbcPagingItemReader와의 성능 차이만 봐도 말이 안 되지만, 점점 미궁으로 빠져드는 의문을 다시 없애버리기는 힘들었다.
📌 Strategy for Analysis
spring-batch/spring-batch-infrastructure/src/main/java/org/springframework/batch/item/data/RepositoryItemReader.java at main ·
Spring Batch is a framework for writing batch applications using Java and Spring - spring-projects/spring-batch
github.com
Hibernate의 영향을 평가하는 건 상당히 어려울 것 같으므로, 우선 RepositoryItemReader의 내부 동작을 분석해서 성능 병목 지점으로 작용할 만한 부분을 확인해보았다.
- 생성자 + setter로 초기화
- doRead()에서 locking
- doRead()에서 다음 페이지 이동 필요성 확인
- 다음 페이징 조회가 필요한 경우 doPageRead() 호출
- doPageRead()에서 Pageable 객체 생성
- doPageRead()에서 createMethodInvoker()로 메서드 탐색 후 파라미터 바인딩
- doInvoke()로 메서드 호출
그나마 의심이 가는 부분은 doRead()를 호출할 때마다 Lock을 거는 것과, doPageRead()마다 리플렉션이 실행되는 것.
하지만 Locking은 JdbcPagingItemReader에서도 동일하게 사용하고 있으므로, 성능 차이의 원인이 될 수는 없다고 판단했다.
그럼 정말 reflection이 문제였을까?
2. Evaluate RepositoryItemReader's Performance
📌 Evaluation
측정 방법은 간단하다.
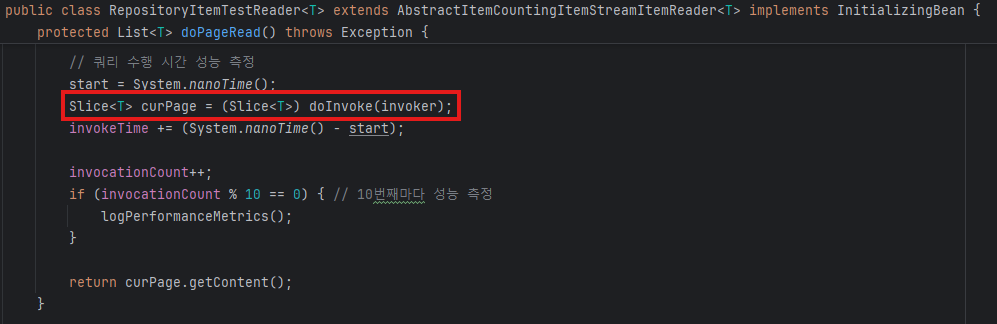
RepositoryItemReader 코드를 통채로 복사해서 수행 시간을 측정하고 싶은 부분에만 성능 측정 코드를 추가해주었다.
그리고 아래 메서드 하나를 추가해주었다.
private void logPerformanceMetrics() {
log.info("--- RepositoryItemReader 성능 측정 (호출 횟수: {}) ---", invocationCount);
log.info("메서드 Invoker 생성 평균 시간: {}ms", methodInvokerCreationTime / (invocationCount * 1_000_000.0));
log.info("메서드 prepare() 평균 시간: {}ms", prepareTime / (invocationCount * 1_000_000.0));
log.info("메서드 invoke() 평균 시간: {}ms", invokeTime / (invocationCount * 1_000_000.0));
log.info("총 리플렉션 관련 평균 시간: {}ms",
(methodInvokerCreationTime + prepareTime + invokeTime) / (invocationCount * 1_000_000.0));
}invoke()는 따지고 보면 쿼리 호출이 되므로 리플렉션 평균 시간도 아닐 뿐더러, 쿼리 수행 시간이 속도를 지배하게 될 것이다.
그런데 그냥 네이밍 어떻게 할 지 생각하기 귀찮아서 대충 적어놨다.
자, 이제 어떤 결과가 나올까?
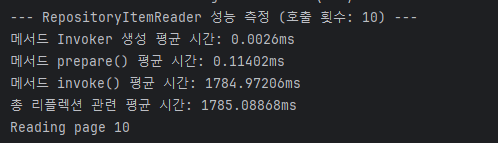
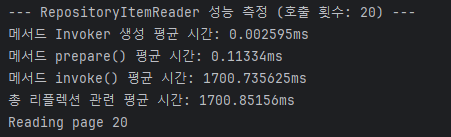
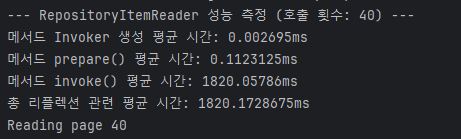
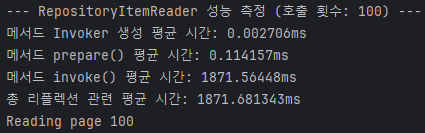
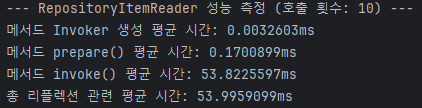
당연하게도 reflection의 속도는 그렇게 느리지 않다.
물론 prepare에 매번 0.1ms나 포함되는 게 흠이긴 하지만, (0.1 * (dataset_sz / page_sz)) ms 정도의 성능 지연만 발생해야 정상이다.
즉, 성능에 미치는 평가가 비례적이지 기하급수적이지 않다는 이야기다.
반면, 쿼리가 수행되고 있는 invoke()를 보면 점점 더 느려지고 있는 게 확연히 드러난다.
그리고 여기서 짐작할 수 있는 건, 이건 1200% 내 잘못으로 인해 성능 저하가 발생하고 있다는 것이다.
3. Repository Implementation
📌 What's the Problem?
만악의 근원이 될 Repository 구현체를 허겁지겁 열었을 때, 얼탱이가 없어서 실성할 뻔 했다.
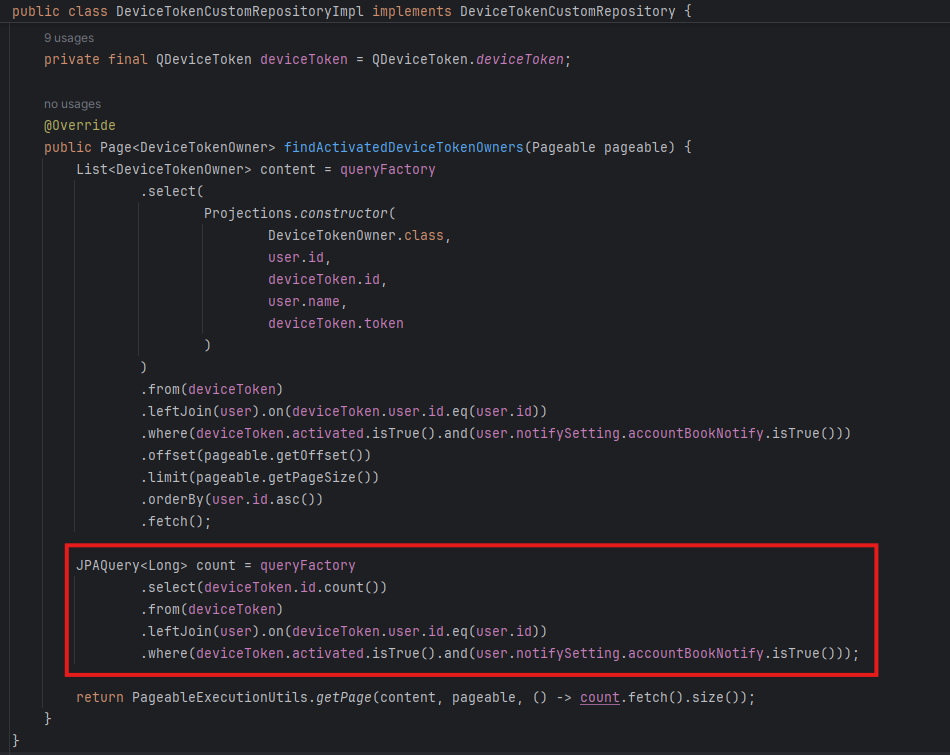
해당 쿼리는 Pagination 방식으로 동작하고 있었고, 때문에 전체 개수를 카운트 해주는 쿼리를 매번 호출하고 있었다.
RepositoryItemReader가 느린 게 아니라, 그냥 내 멍청한 실수로 인해 발생한 성능 저하였던 것이다.
그저 나의 지능에 감탄스러울 뿐이다.
이런 식으로 구현했던 이유를 추측컨데, 아마 이런 사고 흐름이었을 것이다.
- Batch 동작을 잘 모르는 상태에서 Pagination을 적용하려 했음.
- ItemReader의 내부 메커니즘을 전혀 모르므로 평소처럼 count 쿼리가 필요하다 느꼈을 것이고, 습관처럼 쿼리를 삽입함.
- 추후 PagingItemReader 구현체들의 내부 메커니즘을 살펴보면 내부적으로 Slice처럼 동작하는 걸 알게되었지만, 정작 내 repository 구현 방식을 망각함.
진짜 기가 막힌다.
여기서 더 정확하게 측정해보고 싶다면 count 쿼리 수행 속도라도 확인해보고 싶지만, 차마 쪽팔려서 확인할 엄두가 나질 않는다.
빨리 내 흑역사를 없애버리자...
📌 Remove Count Query
사실 Count 쿼리는 존재 자체가 의미가 없다.
ItemReader에서도 반환값을 Slice 클래스로 형변환해서 사용하는데, 이들은 페이지의 마지막을 판단하기 위해 count를 사용하지 않는다.
그럼 어떻게 하느냐?
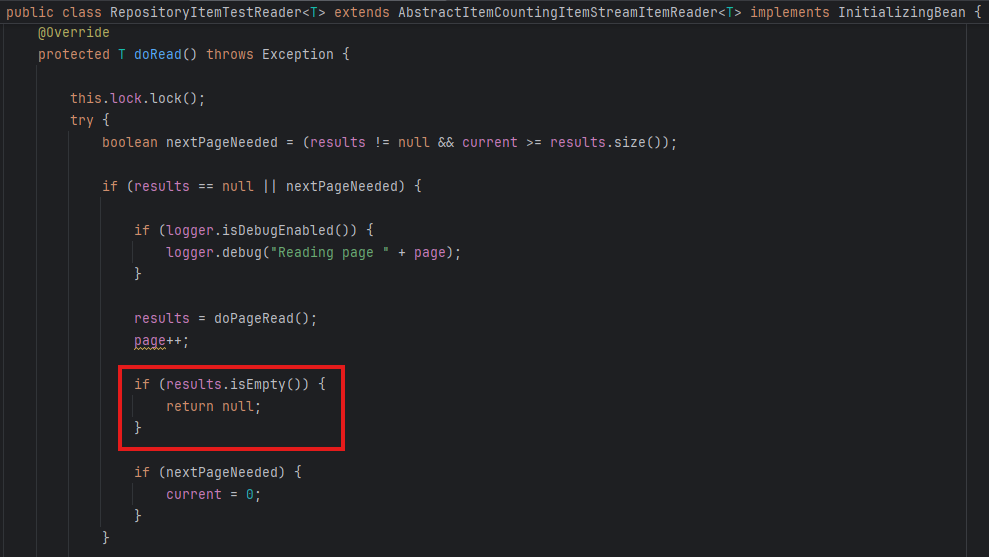
정말 단순하다.
- page size만큼 data를 가져온다.
- data를 차례대로 읽는다.
- 만약 (1)에서 가져온 데이터가 더 이상 없으면, 더 이상 읽을 데이터가 없다는 의미이므로 종료.
JpaPagingItemReader같은 이상한 놈들을 제외하고 모두 같은 방식으로 동작한다.
따라서, 이 문제의 해결 방법은 매우 심플하고도 단순하다.
반환값을 Slice로 바꾸고, count 쿼리를 제거해버리면 끝난다.
@Override
public Slice<DeviceTokenOwner> findActivatedDeviceTokenOwners(Pageable pageable) {
List<DeviceTokenOwner> content = queryFactory
.select(
Projections.constructor(
DeviceTokenOwner.class,
user.id,
deviceToken.id,
user.name,
deviceToken.token
)
)
.from(deviceToken)
.leftJoin(user).on(deviceToken.user.id.eq(user.id))
.where(deviceToken.activated.isTrue().and(user.notifySetting.accountBookNotify.isTrue()))
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.orderBy(user.id.asc())
.fetch();
// 제거
// JPAQuery<Long> count = queryFactory
// .select(deviceToken.id.count())
// .from(deviceToken)
// .leftJoin(user).on(deviceToken.user.id.eq(user.id))
// .where(deviceToken.activated.isTrue().and(user.notifySetting.accountBookNotify.isTrue()));
return toSlice(content, pageable);
}
public static <T> Slice<T> toSlice(List<T> contents, Pageable pageable) {
boolean hasNext = isContentSizeGreaterThanPageSize(contents, pageable);
return new SliceImpl<>(hasNext ? subListLastContent(contents, pageable) : contents, pageable, hasNext);
}
private static <T> boolean isContentSizeGreaterThanPageSize(List<T> content, Pageable pageable) {
return pageable.isPaged() && content.size() > pageable.getPageSize();
}
private static <T> List<T> subListLastContent(List<T> content, Pageable pageable) {
return content.subList(0, pageable.getPageSize());
}
ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
진심으로 숨 쉬는 것조차 부끄러워졌다. 🫠
📌 Has Everything Been Resolved?
다행히(?) COUNT 쿼리 하나 없앤다고 성능이 획기적으로 올라...가긴 했는데, 여전히 써먹을 수 있는 레벨은 아니다. (만약 그랬다면, 새로운 포스팅을 작성하고 있지 않고 이전 포스팅을 삭제해버렸을 것이다.)
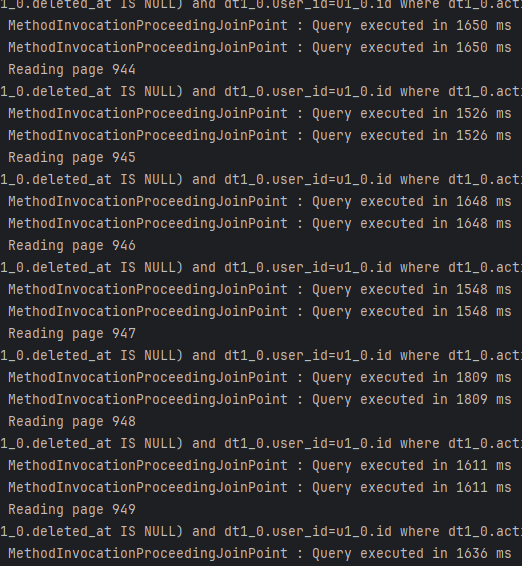
왜냐하면, 현재 Repository에 no-offset이 적용되어 있지 않기 때문에, 페이지가 증가할 수록 쿼리 속도가 매우 느려지기 때문이다.
엥, JdbcPagingItemReader는 그럼 왜 그렇게 빨라요?
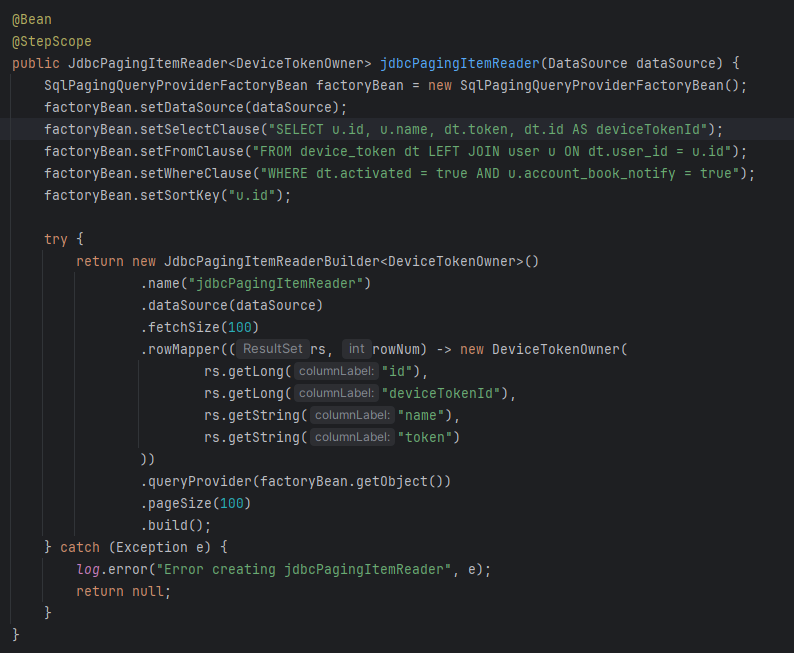
나도 그게 궁금해서 쿼리를 확인해봤는데, 난 정의한 적도 없는 no-offset sql을 은근슬쩍 끼워넣고 있었다.
이게 당췌 무슨 일인지 확인해보려고 소스 코드를 다시 읽어봤는데, JdbcPagingItemReader의 queryProvider 속성을 보면 그 이유를 알 수 있다.
📌 JdbcPagingItemReader queryProvider
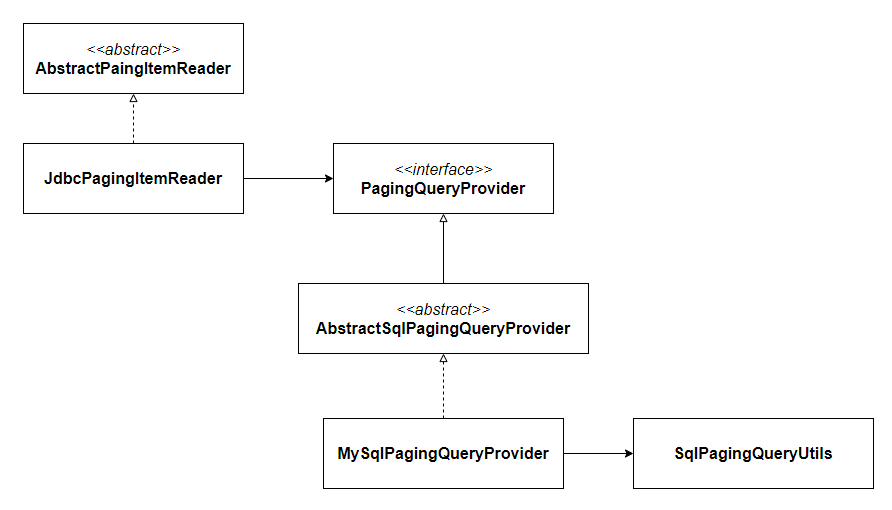
몇 가지 생략하긴 했는데, 개략적인 구조는 위와 같이 생겼다.
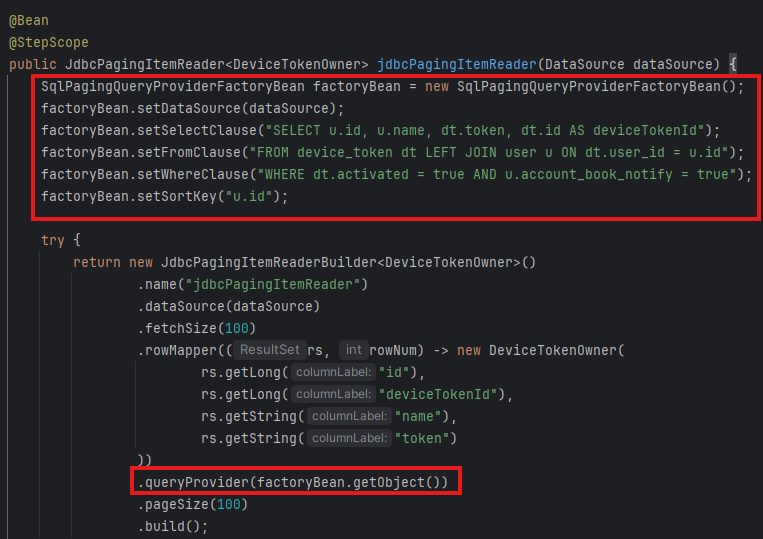
나는 JdbcPagingItemReader를 위와 같이 정의했는데, 쿼리를 SqlPagingQueryProvider에게 정의해준 후에 JdbcPagingItemReader에게 전달해주었다.
그렇다면 아마 no-offset 방식의 쿼리를 생성하는 로직은 PagingQueryProvider 구현체에서 담당하고 있을 확률이 높았고, 아마 이게 가능한 이유는 setSortKey()일 것이라 추측했다.
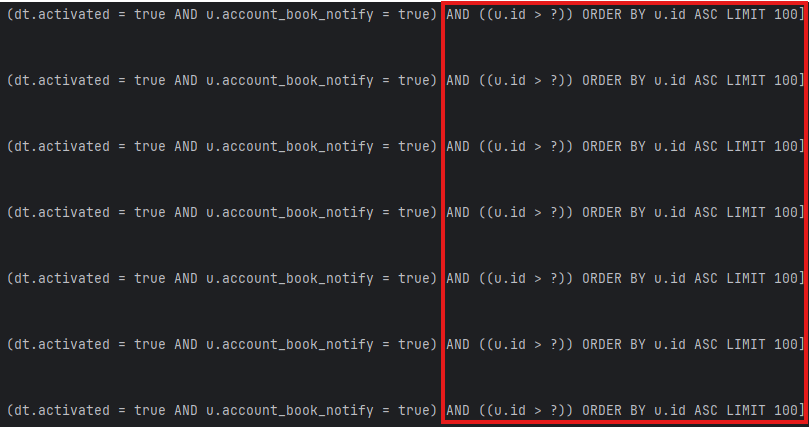
- Limit 사이즈는 JdbcPagingItemReader의 pageSize로 결정되고 있다.
- 별다른 no-offset 힌트를 제공해주지 않았음에도 `u.id > ?` 조건절이 붙는다면, setSortKey("u.id")를 사용하고 있을 것이다.
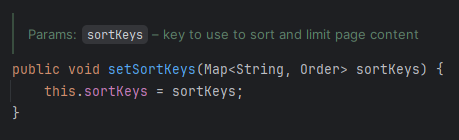
아니나 다를까, 주석을 보면 sort와 페이지 limit을 위해 사용할 키를 정의하는 메서드라고 적혀있다.
그럼 쿼리는 언제 만드느냐?
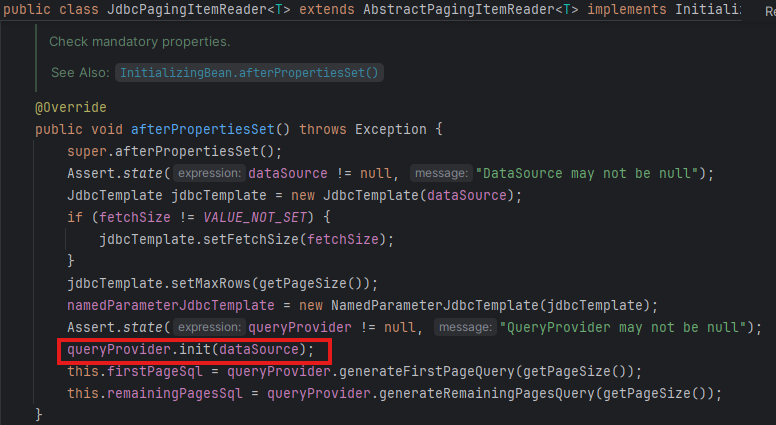
afterPropertiesSet() 메서드에서 queryProvider를 초기화한 후, firstPageSql와 remainingPagesSql으로 쿼리를 생성하는 것을 확인할 수 있다.
(어쩐지 Jdbc 관련 ItemReader 테스트할 때, 해당 함수 호출을 안 해주면 에러가 나더라.)
init()은 그냥 내가 정의한 쿼리들과 dataSource 유효성 검사 후에, 쿼리들을 SELECT, FROM, WHERE, GROUP BY 절로 잘 나눈 후에, namedParameters 사용 여부를 판단하는 게 끝이다.
(MySqlPagingQueryProvider의 경우엔 AbstractSqlPagingQueryProvider에 정의된 init 함수를 그대로 사용한다.)
본격적인 쿼리는 아래 두 메서드에서 실행되는데,
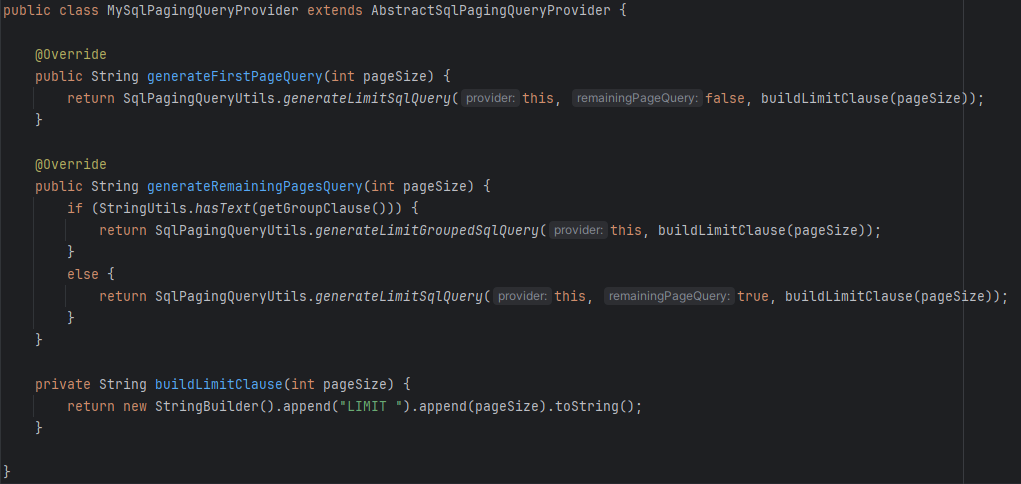
LIMIT 조건은 직접 만들어서 전달해주고, 나머지는 SqlPagingQueryUtils에게 넘겨버린다.
- firstPageQuery는 offset 없이 Limit만 정의되어 있다.
- remainingPageQuery부터 no-offset이 적용되어 나온다.
그렇다면, SqlPagingQueryUtils 내부의 Where 절 쿼리를 생성하는 메서드에서 remainingPageQuery가 true인 조건의 영역에서 찾으려는 로직을 확인할 수 있을 것이다.
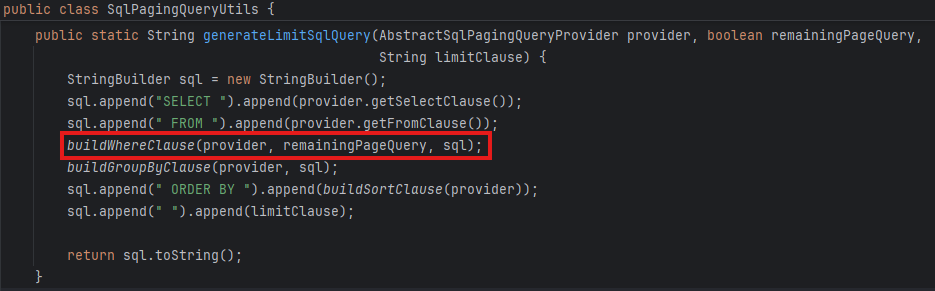
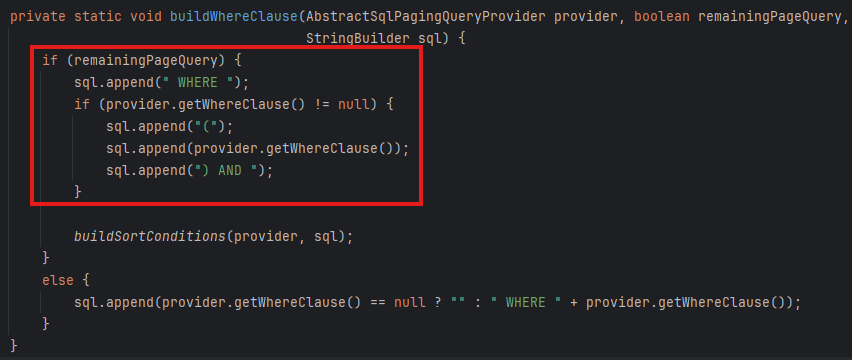
그런데 막상 확인해보니 sortKey는 온데간데 없고, 그저 provider.getWhereClause()가 호출되고 끝이었다.
내가 뭘 놓친 건가 싶어서 아차 싶었는데, no-offset()은 buildSortConditions()에서 적용하고 있었다.
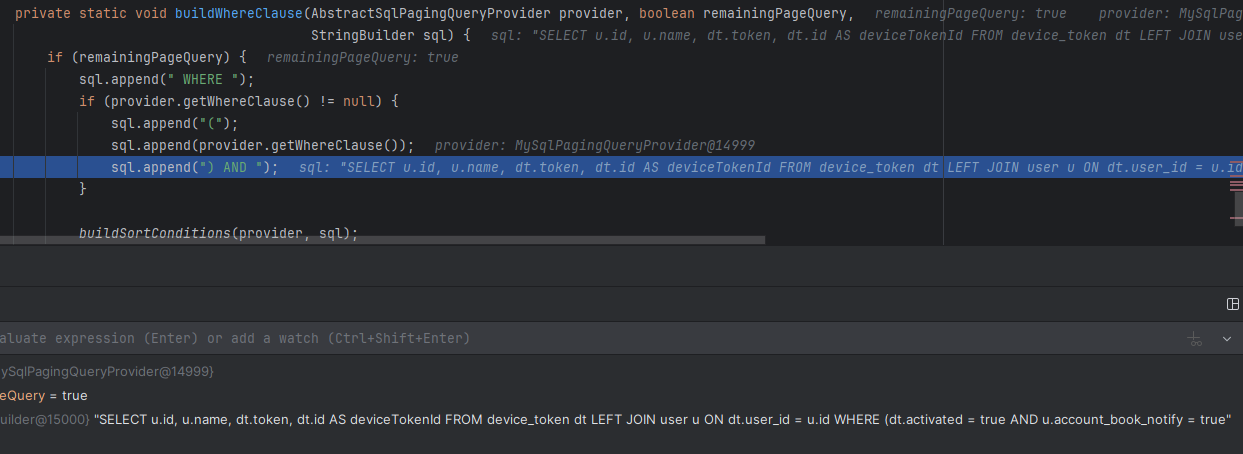
혹시나 또 실수할까 봐, 디버깅까지 하면서 확인해봤다.
현재까지 remainingPageQuery가 true임에도 no-offset은 쿼리에 적용되지 않은 상태임을 확인할 수 있다.
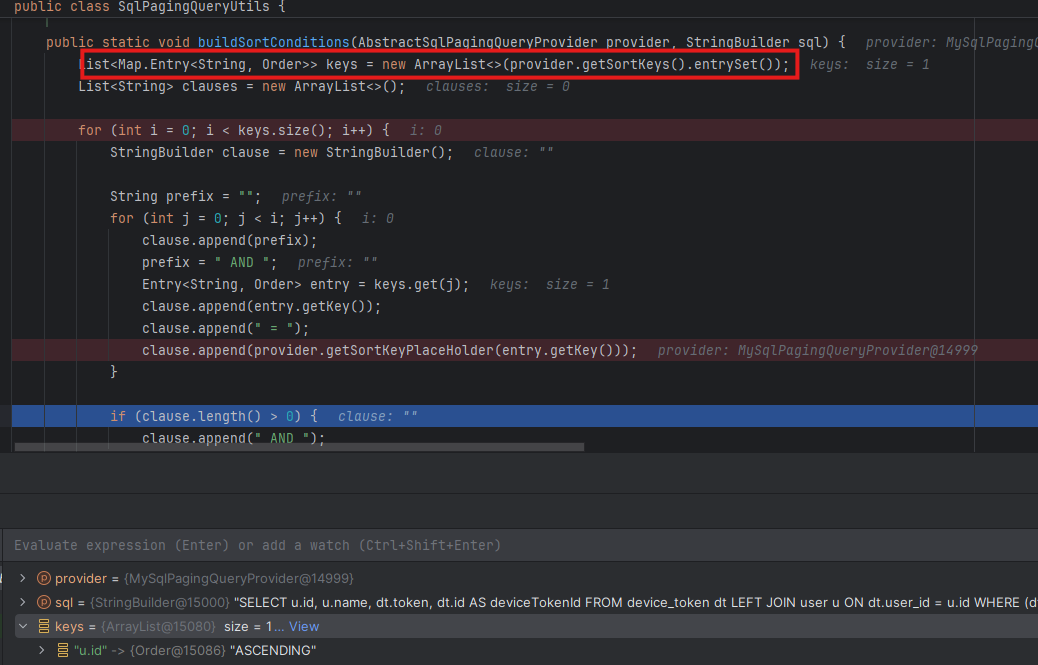
buildSortConditions()에서 provider에 정의된 sortKey들을 모두 불러온 이후
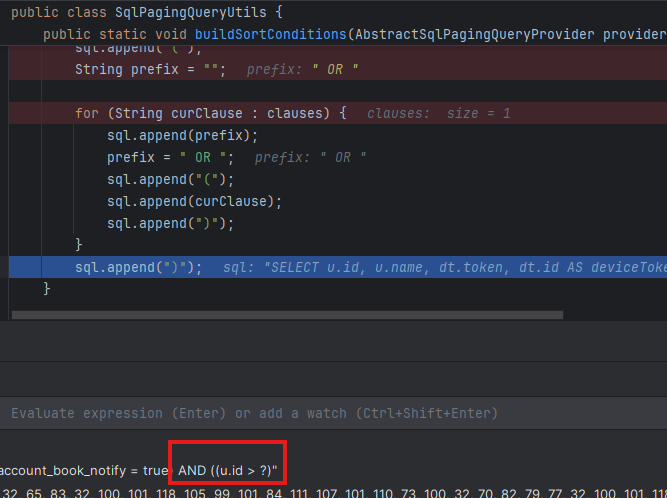
탐색한 sortKey들을 모두 no-offset을 위해 적용해주는 것을 확인해볼 수 있다.
예상한 위치를 찾긴 했는데, 그럼 대체 Order By 절은 어디서 만들고 있는 지가 의문이었다.
그런데 스크롤 조금만 올려보니 buildSortClause()라는 메서드가 따로 있었다. ^^..
4. How to Apply No-Offset to RepositoryItemReader?
📌 Performance
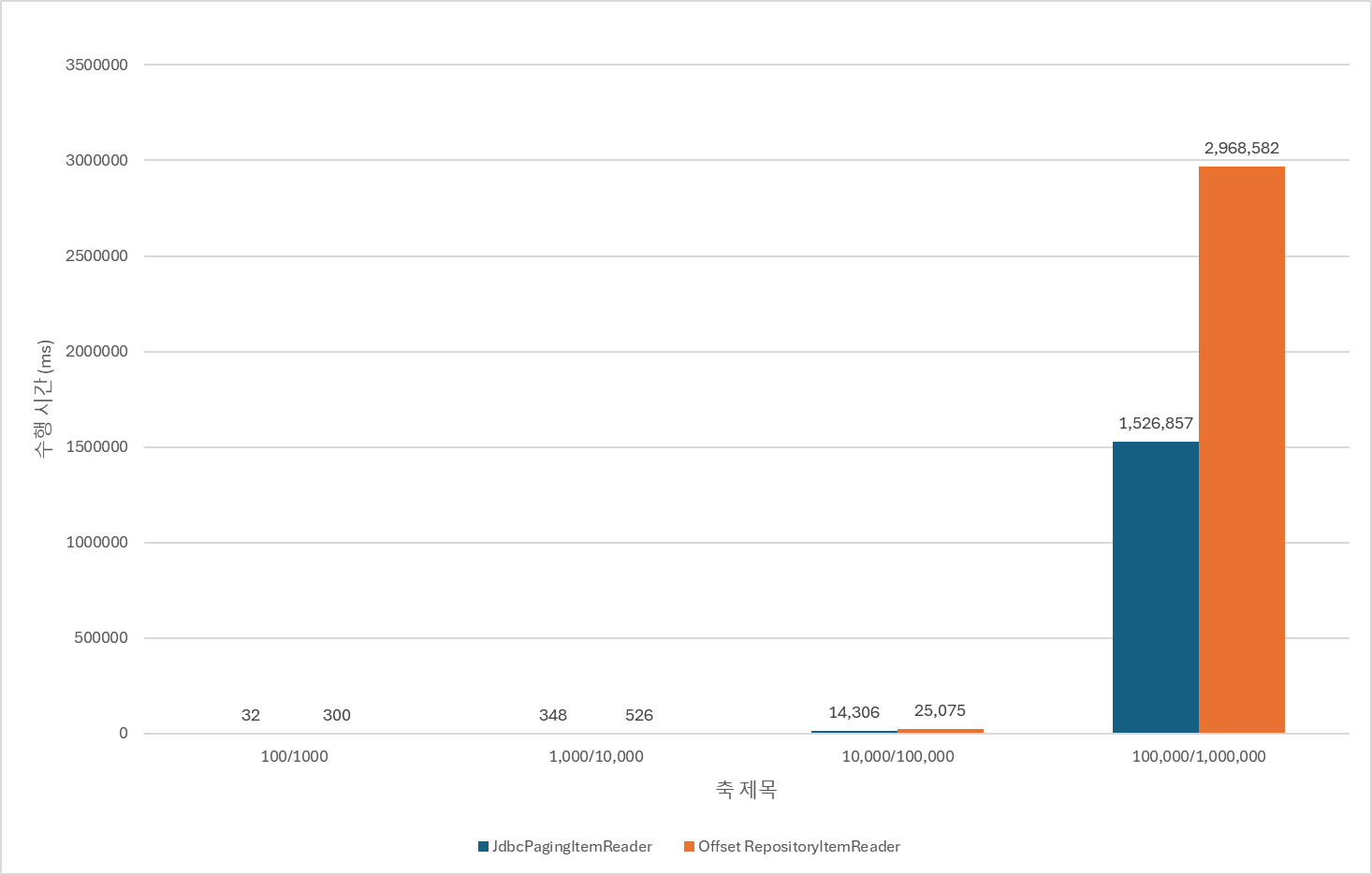
count 쿼리만 제거해줘도 성능이 많이 개선된 것이 보이긴 하지만, 여전히 JdbcPagingItemReader에 비해 많이 느리다. (근데 진짜 COUNT 쿼리 없앤 것만으로도 성능 기가맥히게 좋아진 게 보인다.)
현재 개선해볼 수 있는 것들은 다음과 같다.
- no-offset 적용
- JPA에서 JDBC로 변경
차근차근 개선해보도록 하자.
🤔 왜 굳이 RepositoryItemReader로 다시 성능 개선을 하려 하나요?
이전 포스팅에서 QueryDslZeroOffsetItemReader의 문제점이 있다.
1️⃣ non thread-safe
Spring 배치에서 제공하는 ItemReader들은 내부에 lock을 사용해서 thread-safe를 보장하지만, 커스텀해서 만든 ItemReader는 이에 대한 고려가 되어 있지 않다. (개선하기는 쉬움)•
2️⃣ 새로운 도구 사용을 위한 팀원 전체 이해 공유 어려움
해당 도구를 만들었을 때, ItemReader를 새로 구현한 것보다 팀원에게 필요성과 동작 방식을 설명하는 게 훨씬 어려웠다.
RepositoryItemReader를 사용해서 비슷한 성능을 낼 수 있다면, 그렇게 하지 않을 이유가 없다고 생각했다.
3️⃣ 신규 도구 제작의 근본적인 문제점
실무에서 새로운 도구를 직접 제작하는 것은 별로 좋아하질 않는다. (회사 분위기 따라 정도가 다르긴 하다)
어느정도 검증된 라이브러리들과는 달리, 직접 제작한 도구들은 자칫 테스트를 놓친 부분에서 장애를 일으킬 수 있으며, 이는 자칫 비즈니스 손실로 다가올 수 있기 때문에 조심스럽기 때문인 듯하다.
📌 Design
커스텀 ItemReader를 구현하지 않으면서 no-offset을 적용하기란 생각보다 까다로운데, 마지막으로 읽은 id 상태(= lastId)를 어디서 관리할 것인지 고민이 필요하다.
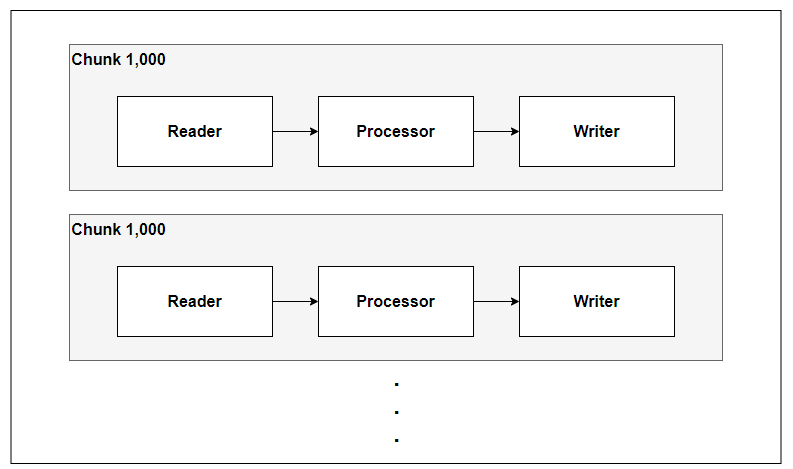
RepositoryItemReader 내부에는 배치 라이프사이클 전체를 관통하는 상태가 존재하지 않고,
chunk 단위로 데이터를 처리하거나 repository로 값을 전달해주기 위한 속성 정도만 존재한다.
1️⃣ Idea1. Batch 애플리케이션 시작할 때, Job에서 초기화
- 플로우
- Job에서 lastId 변수를 jobParameter에 정의
- Reader에서 읽은 후, Processor 혹은 Writer에서 pageSize만큼 lastId 증가
- Reader만 단독 테스트가 어렵고, Batch 자체에 전역 상태가 생김.
2️⃣ Idea2. Repository를 감싸는 Holder 클래스 사용
- 플로우
- RepositoryItemReader에 Repository를 바로 넘기지 않고, lastId 상태를 관리하는 Holder 클래스 전달
- chunk 호출될 때마다 page size만큼 증가시키면서 repository로 param 전달
- RepositoryItemReader 스펙에 의하면, repository 클래스 인자는 PagingAndSortRepository 인터페이스를 구현해야 하므로 실현할 수 없다.
3️⃣ Idea3. Batch 전용 Repository 클래스 사용
- 상태를 갖는 Batch 전용 Repository를 구현
- pros
- ItemReader를 직접 구현하는 것에 비해 구현 난이도, 코드 유지/보수성을 획기적으로 낮출 수 있다.
- Query를 QueryDsl로 관리하면서, Jdbc를 적용하는 것도 쉽다.
- cons
- 일반적으로 Repository가 상태를 갖는 것은 어불성설
난 여기서 일단 3번 째 아이디어를 채택하기로 했다.
📌 A Repository Exclusively for Batch
Repository는 Stateless를 따르는 컴포넌트라는 것은 나 또한 알고 있다.
그럼에도 ItemReader를 직접 구현하지 않는 이상, thread-safe하면서 Batch 라이프사이클 동안 lastId 상태를 관리할 만한 곳을 정의해주기가 마땅치 않다.
위에서 언급했 듯, Job에서 state를 정의하고 jobParameter를 넘기는 게 하나의 방법이 될 수는 있겠지만,
- Repository 무상태 원칙을 준수하기 위해 Batch에 상태를 추가하는 것은 옳은가?
- Reader만 독립적으로 테스트를 어떻게 할 수 있는가?
반면, Repository에서 상태를 관리하면 다음 이점을 얻을 수 있다.
- 이미 RepositoryItemReader에서 Repository 호출 전에 Lock을 수행하므로, Repository 상태를 관리하기 훨씬 수월해진다.
- 기존의 QueryDsl로 Query를 배치에서 관리할 수 있다는 이점을 클래스 하나 더 구현함으로써 동일하게 구현할 수 있다. (ItemReader를 직접 구현하는 것보다 훨씬 쉽고 유지보수도 편하다. 단, 클래스 수가 증가한다.)
- Pageable 인자에 대한 검증은 RepositoryItemReader 생성할 때 수행해주므로 별도의 null-safe 쿼리를 고려하지 않아도 된다.
위 아이디어를 기반으로 코드를 작성하는 것은 어렵지 않다.
@Slf4j
@Repository
@RequiredArgsConstructor
public class DeviceTokenCustomRepositoryImpl implements DeviceTokenCustomRepository {
private final JPAQueryFactory queryFactory;
// 멀티 스레딩을 고려하여 volatile 타입 정도로만 고려해도 충분하긴 할 듯.
private final AtomicLong lastProcessedId = new AtomicLong(0);
@Override
public Slice<DeviceTokenOwner> findActivatedDeviceTokenOwners(Pageable pageable) {
ConstructorExpression<DeviceTokenOwner> constructorExpression = Projections.constructor(
DeviceTokenOwner.class,
user.id,
deviceToken.id,
user.name,
deviceToken.token
);
BooleanExpression whereCondition = deviceToken.activated.isTrue()
.and(user.notifySetting.accountBookNotify.isTrue());
// 굳이 이렇게 하지 않아도 됨. 다만 JdbcPagingItemReader와 동일하게 동작하도록 만듦.
if (lastProcessedId.get() > 0) {
log.info("lastProcessedId: {}", lastProcessedId.get());
whereCondition = whereCondition.and(deviceToken.id.gt(lastProcessedId.get()));
}
// offset 절 제거
List<DeviceTokenOwner> content = queryFactory
.select(constructorExpression)
.from(deviceToken)
.innerJoin(user).on(deviceToken.user.id.eq(user.id))
.where(whereCondition)
.limit(pageable.getPageSize())
.orderBy(deviceToken.id.asc())
.fetch();
if (!content.isEmpty()) { // query 실행 후 로그 확인용. 실제 코드엔 필요 없음.
lastProcessedId.set(content.get(content.size() - 1).deviceTokenId());
log.info("updated lastProcessedId: {}", lastProcessedId.get());
}
return toSlice(content, pageable);
}
// cron으로 배치 실행하면 lastProcessedId는 언제나 초기화되므로 필요 없음.
// 하지만 스프링 내부 스케쥴링이나, ParameterlizedTest 할 때는 수동 초기화가 필요하다.
public void resetLastProcessedId() {
log.info("Resetting last processed ID from {} to 0", lastProcessedId);
lastProcessedId.set(0);
}
}
좀 더 보기 편했으면 해서 constructor와 where 표현식을 분리해봤다. 허허
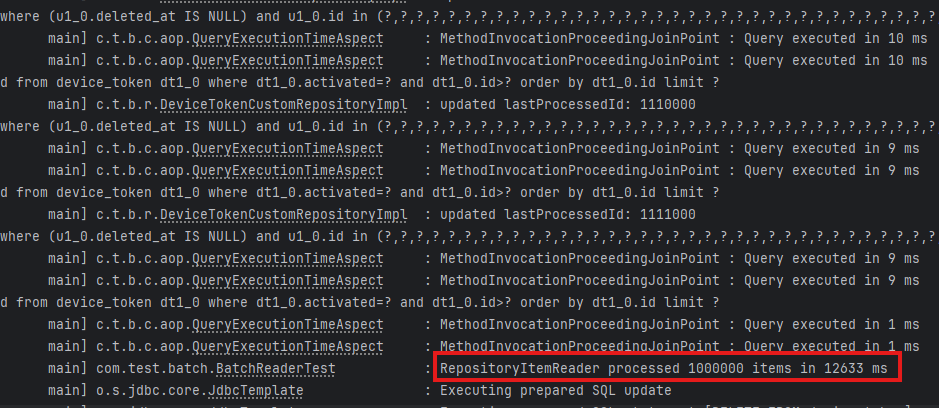
첫 번째 쿼리 이후 제대로 no-offset이 적용되는 것 또한 확인했고, 전체 읽은 item 수까지도 꼼꼼하게 체크해서 정상적으로 동작함을 확인했다.
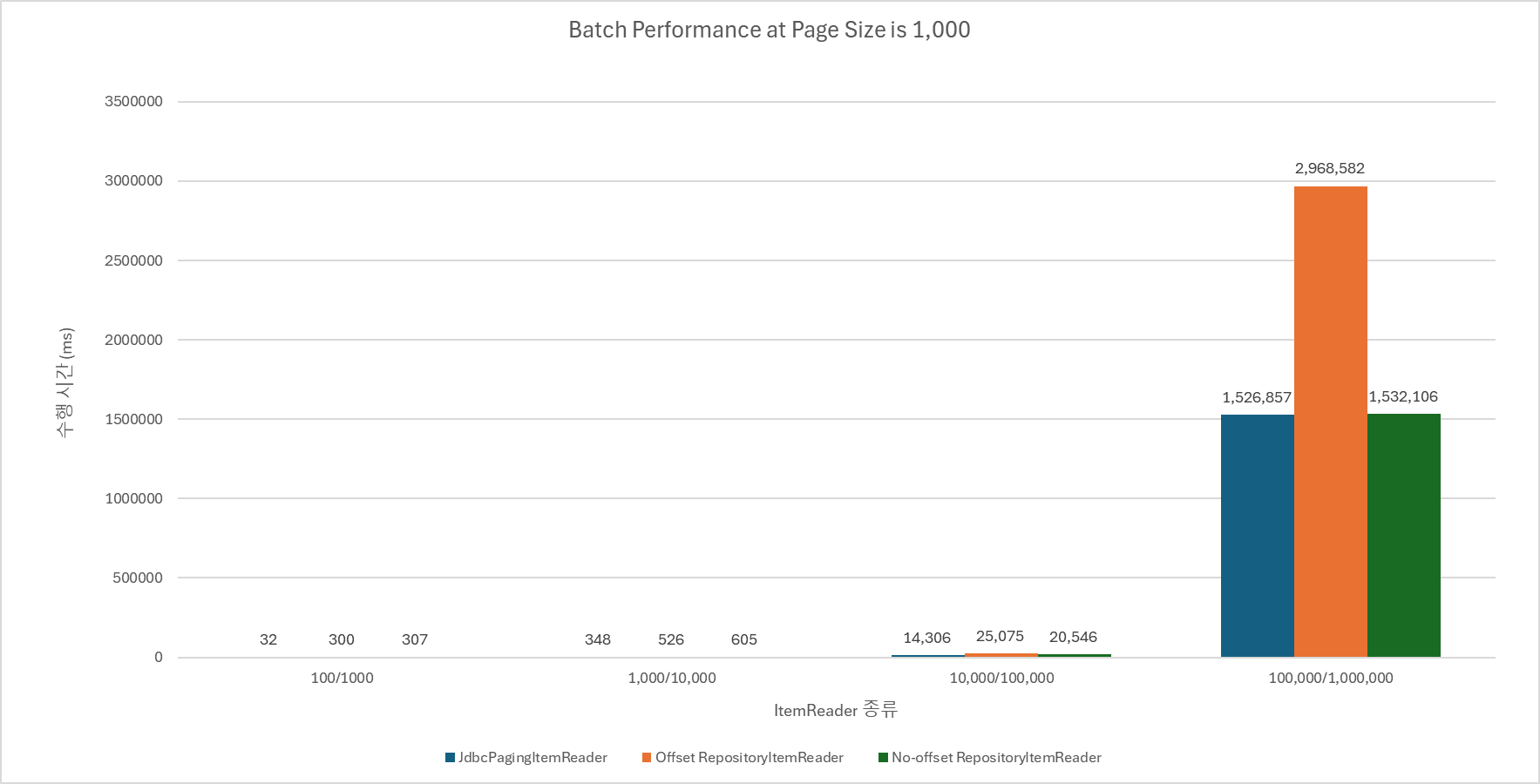
JdbcPagingItemReader와 거의 비슷한 수준까지 퍼포먼스를 끌어올릴 수 있었다. 🎉🎉🎉
다시 말하지만 RepositoryItemReader는 죄가 없었다.
주석에 명시되어 있는 것처럼, repository 구현체에 가장 크게 영향을 받을 뿐이다. 하하..
📌 Remove the State of Repository
Repository에서 상태를 관리하는 게 영 마음에 안 들어서 조금 더 찾아보니, 스택 오버 플로우에서 ExecutionContext를 사용하면 Job 혹은 Step 범위에서 값을 공유할 수 있다고 한다.
이번 포스팅은 성능 개선이 목적이라 코드를 수정하진 않았지만, 이걸 사용하면 Writer에서 context 값을 수정해주면 되지 않을까 싶다.
다만 멀티 스레딩 환경에서 동시성 문제를 제어할 수 있을 지는 좀 더 고민해봐야 한다.
개인적으로는 RepositoryItemReader를 확장해서 no-offset 부분만 적용시켜줘도 좋지 않을까 싶다.
5. Further Improvement
📌 Does Replacing Hibernate with JDBC Make a Difference?
아마 현재 상황에서 JPA를 Jdbc 방식으로 바꾼다고 해서 큰 이점을 얻을 수 있을 것이라 기대하긴 어렵다..
- 영속화 상태 변경에 따른 Dirty Checking하는 비용으로 인해, 대량 배치 작업에서 Hibernate를 사용하면 지연이 발생하는 것은 사실이다.
- 그러나 현재 Projection을 사용하긴 하나, DTO를 사용하기 때문에 영속성 컨텍스트를 사실상 사용하고 있지 않다. (심지어 Reader만 테스트하고 있으므로 영속성 변경 감지 비용 또한 발생하지 않는다.)
실제로 QueryDslNoOffsetPagingItemReader와 성능을 비교해봤는데,
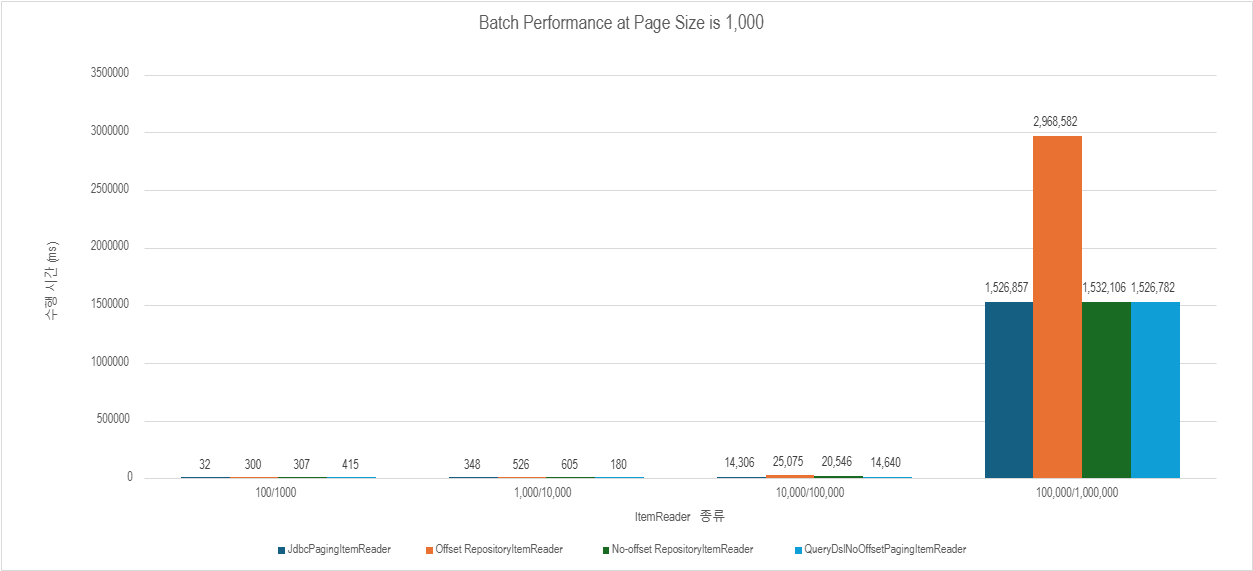
이미 그냥 차이가 없다고 봐도 무방할 정도다.
다만, 역시 커스텀 ItemReader 방식이 JdbcPagingItemReader와 더 유사한 성능을 보이고 있긴 하다.
이 부분을 개선하면 더 좋아질 수 있긴 하겠지만, common case에는 해당한다고 보긴 어려우므로 나는 패스.
📌 Remove the Join Clause
여기까지 오면 더 이상 배치를 개선한다고 해결할 수 없는 한계에 봉착한다.
이전 포스트에서 분석했듯이 Join 절을 풀지 못하기 때문에 발생하는 문젠데, Join을 푸는 방법은 단순하다.
시간 복잡도를 줄이려면, 공간 복잡도를 늘려서 해결할 수 있다. (논리적으로 오류만 아니라면)
문제는 당시 뇌가 redis에 절여져서, 사용자 정보를 모두 캐싱해둔다는 말도 안 되는 발상밖에 안 떠올랐다는 건데, 갑자기 포스팅을 쓰다가 궁금해진 부분.
사용자 정보 100,000개와 사용자가 0~N개의 device token을 가질 수 있는 환경에서, 둘 중 무엇이 더 빠를까?
- 디바이스 토큰 1,000개씩 읽으면서 사용자 정보 조인
- 디바이스 토큰 1,000개씩 읽고, 사용자 정보는 IN 절로 별도 쿼리로 조회.
👇 Repository 코드 확인
@Override
public Slice<DeviceTokenOwner> findActivatedDeviceTokenOwners(Pageable pageable) {
// 1. join 없이 deviceToken만 조회
List<Tuple> deviceTokens = queryFactory
.select(deviceToken.id, deviceToken.token, deviceToken.user.id)
.from(deviceToken)
.where(deviceToken.activated.isTrue().and(deviceToken.id.gt(lastProcessedId.get())))
.limit(pageable.getPageSize())
.orderBy(deviceToken.id.asc())
.fetch();
// 2. deviceToken이 없으면 빈 결과 반환
if (deviceTokens.isEmpty()) {
return toSlice(List.of(), pageable);
}
// 3. 마지막 조회된 deviceToken의 ID를 업데이트
lastProcessedId.set(deviceTokens.get(deviceTokens.size() - 1).get(deviceToken.id));
log.info("updated lastProcessedId: {}", lastProcessedId.get());
// 4. deviceToken에 대한 user ID 목록 추출
List<Long> userIds = deviceTokens.stream()
.map(tuple -> tuple.get(deviceToken.user.id))
.distinct()
.collect(Collectors.toList());
// 5. user ID 목록에 해당하는 user 조회
Map<Long, String> users = queryFactory
.select(user.id, user.name)
.from(user)
.where(user.id.in(userIds).and(user.notifySetting.accountBookNotify.isTrue()))
.fetch()
.stream()
.collect(Collectors.toMap(
tuple -> tuple.get(user.id),
tuple -> tuple.get(user.name),
(existing, replacement) -> existing
));
// 6. deviceTokenOwner 목록 생성
List<DeviceTokenOwner> result = deviceTokens.stream()
.filter(token -> users.containsKey(token.get(deviceToken.user.id)))
.map(token -> new DeviceTokenOwner(
token.get(deviceToken.user.id),
token.get(deviceToken.id),
users.get(token.get(deviceToken.user.id)),
token.get(deviceToken.token)
))
.toList();
return toSlice(result, pageable);
}
결과는 가히 충격적이었다.
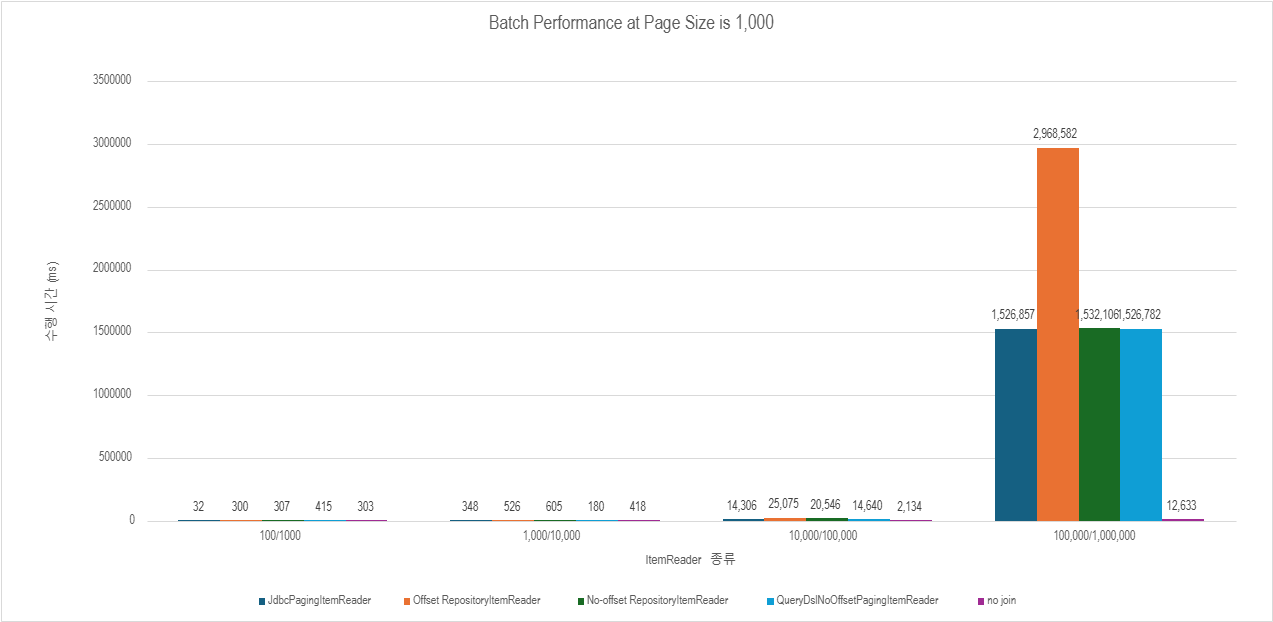
데이터가 클 수록 join이 느려진다는 것은 알고 있었지만, 400ms대에서 20ms 이하로 줄어들 줄은 몰랐다.
진짜 대규모 데이터를 다뤄본 경험 유무 차이가 여기서 갈리는 구나
🧮 메모리 사용량 차이
대량 데이터인 만큼 객체 헤더 비용같은 것도 다 계산해야겠지만, 괜히 정확하지도 않으면서 어중간하게 할 바에 안 하는 게 낫다고 판단했다.
기존 방식 (조인)
• 메모리 사용량 = DeviceTokenOwner 객체 * pageSize
• DeviceTokenOwner ≈ userId(Long, 8 bytes) + deviceTokenId(Long, 8 bytes) + userName(String, avg 15 * 2 bytes/char = 30 bytes) + token(String, avg FCM token len = 150 * 2 bytes/char) = 344 bytes
• 메모리 사용량 = DeviceTokenOwner 객체 * pageSize = 356 * 1,000 = 344 KB
새 방식 (다중 쿼리)
• 중간 튜플 리스트(deviceTokenId, token, userId) * 1,000 ≈ 316 KB
• userIds 리스트 * 300 ≈ 2 KB
• users Map(userId → userName) ≈ 24 KB
• 메모리 사용량 = (중간 튜플 리스트) + (userId 리스트) + (users Map) + (DeviceTokenOwner * 1,000) = 316 + 2 + 24 + 344 = 686 KB
탐색 기준은 device token이며, 여기서 발생 가능한 최악의 경우는 device token마다 모두 다른 user와 매핑되어 있는 경우가 된다.
이 때, 성능을 증가시키기 위해 메모리가 2배 가까이 증가하는데, 약 300 KB의 메모리를 더 사용한다.
300 MB 아니고 고작 300 KB라고 할 수 있겠지만, 당시 프리티어 1GB RAM에 API 서버, RabbitMQ, Redis, 채팅 서버가 모두 올라가 있던 상태에선 이건 도입할 수 없는 방법이었다. (개발 서버라서 돈이 없었다 ㅜ)
→ 다시 생각해보니 pageSize를 1,000이나 잡았으니 당연히 안 됐던 거겠지. 이 정도 성능이면 사용자 수가 적을 땐, 100만 잡아도 충분히 제 기능을 다 했을 거고, 메모리 사용량도 적었을 것이다. 그냥 내 오판이었다.
고작 이 정도의 메모리 희생으로 퍼포먼스를 비약적으로 향상시킬 수 있다는 건 진심으로 놀랐다.
이래서 데이터베이스 수업 시간에 교수님이 Join 하지 좀 말라고 하셨구나.
아아, 이 멍청한 제자가 드디어 깨닫습니다. 🫠
📌 et cetera
- 서버 가용 자원에 따라 page size를 조절하는 것도 도움이 될 수 있다.
- 멀티 스레딩 혹은 파티셔닝을 할 적절한 기준 혹은 키가 있고, 서버 가용 자원이 허락한다면 시도해볼만 하다.
6. Conclusion
📌 후련하질 않다.
결과적으로 어마무시한 성능 개선을 이뤄내긴 했다.
- Count 쿼리 포함 + Join + offset 수행 시간: 43,200,000 ms (약 12시간)
- Count 쿼리 제거 + Join + no-offset 수행 시간: 1,526,782 ms (약 25.4분) → (1) 대비 28.3배 빠름
- Count 쿼리 제거 + 다중 쿼리 + no-offset 수행 시간: 12,633 ms (약 12.6초) → (2) 대비 120.9배 빠름
즉, 전체 3,420배나 빨라졌다.
하지만 이전에는 ItemReader의 문제라고 판단하고 분석한 반면, 이번 건 내 Query를 개선했을 뿐이다.
시작부터 끝까지 내 문제였다는 게 씁쓸할 따름.
내일까지 포트폴리오 제출해야 하는데, 자꾸 이 부분이 스스로 이상하다고 생각되어 분석했다가 포폴 못 내게 생겼다. 🤦♂️
빨리 써봐야지..