💡 Spring Boot에서 로그 파일을 관리하는 방법이 주된 내용이고, 이와 관련한 다양한 정책들은 이론적으로 구상만 해봤습니다.
왜냐면, 프리티어 서버에게 로그 관리란 사치일 뿐이니까..😏
1. Introduction
📌 Problem
로그 관리의 중요성은 알고 있었다.
다만, 혼자서 API 개발부터, 프로젝트 관리에 온갖 회의는 물론이고, 개인적으로도 영어, OS, JVM 공부까지 하다가, 또 틈만 나면 Spring 프레임워크 소스 코드 분석하는데 로그 관리에 투자할 시간이 없었을 뿐.
애초에 런칭도 못 하고 있는데다, 어떤 로그가 중요한 지도 모르는 주제에
로그 시스템에 시간을 투자하는 것 자체가 의미가 없다고 생각했다.
그런데 엊그제 iOS 팀에서 서버에서 에러가 났다고 확인을 요청했었다.
하필 그 때 운동 중이었으니까, 약 2시간 쯤 뒤에 로그를 확인해보려고 했는데,

내가 확인하려 할 쯤엔 이미 너무 많은 로그가 쌓여있었다.
head와 tail 명령어를 잘 섞어서 위치를 추적할 수는 있었으나,
아기자기한 프리티어 서버에서 로그를 1,000줄씩 띄워버릴 수도 없는 노릇이라 문제 지점 파악하는 데만 30분을 쏟아버렸다.
(30분이면 JVM 한 파트는 더 읽고도 남았겠다.)
그리고 지금까지 있었던 수많은 로그들을 컨테이너 다시 올릴 때마다 전부 날려버렸는데,
덕분에 재밌는 오류들이 발생했었는데 전부 기록이 날아가버려서 공부해볼 기회를 놓쳐버린 점도 아쉽긴 하다.
여튼 버그 찾는데 자꾸 낭비되는 내 시간이 아깝다는 이유로 로그를 보다 체계적으로 관리하기로 결정했다.
빠르게 내 공부할 시간을 확보해보도록 하자.
📌 Necessity of Logging
우리는 왜 로그를 필요로 하는가?

살인 사건(서버가 죽음)이 일어났다고 생각해보자.
참고로 사망자는 새벽마다 죽어버리는 우리들의 서버다.
우리(개발자)는 사건(에러)의 진상을 파악(디버깅)해야 하는데,
사망자(서버)가 다잉 메시지(로그)를 남겨두지 않았다면 수사(디버깅)에 난항(야근)을 겪을 것이다.
(하지만 걱정하지말라, 범인은 언제나 당신이다.)
쓰고 보니 비유 살벌하네.
서버는 다시 살릴 수 있으니까 너무 애틋해하지 말도록 하자.
정말 애틋한 건 새벽에 일어나서 저거 고치고 있는 개발자다.
일주일 동안 30시간도 못 잔 거 같다.
헛소리 그만하고, 이유들을 정리해보았다.
- 가시성 (Visibility)
- 실시간 시스템 상태 모니터링 가능
- 성능 metrics(ex. response time, throughput) 추적 용이성
- 에러 로그를 통해 빠르게 장애 지점을 식별하고, 예외 상세 정보를 확인 가능
- 보안 (Security)
- 비정상적인 접근 시도나, 무단 접근, 해킹 시도 등을 관찰 가능
- 실시간으로 처리하지 못 했더라도, 후속 조치를 위한 보안 감사를 추적할 수 있는 정보를 제공
- 비즈니스 (Business)
- 사용자의 사용 패턴, 활동 시간, 인기/저조 기능 등을 식별 가능
- 추후 사용자 경험의 문제점을 파악하고 개선할 수 있는 비즈니스적 가치 창출
- 컴플라이언스 (Compliance)
- 개인정보처리보호법과 같은 법적 요구 사항을 잘 준수하는 지 감사용으로 쓰일 수 있음.
- 성능 최적화 (Performance Optimization)
- 병목 지점, 성능 감지, 리소스 사용량 등을 모니터링하여 최적화 필요한 부분을 식별 가능
로그는 단순히 에러 처리를 위한 기록 그 이상의 비즈니스 가치를 창출하기 위한 도구가 될 수 있음을 기억하자.
📌 (Tip) Where Should We Focus?
우리는 로그를 언제, 어디에 남겨야 할까?
난 예전부터 이에 대한 고민을 끊임없이 하지만, 여전히 잘 모르겠다.
아마 로그의 중요도를 평가하는 것은 직책마다 다를 수 있다. (추측일 뿐이다.)
- 서버 개발자
- 주요 관심사: 시스템 성능과 안정성, 에러와 예외 사항, 서비스 가용성 등
- 필요한 로그: 에러 스택 트레이스, API 응답 시간, DB 쿼리 실행 시간, 메모리 사용량 등
- 클라이언트 개발자
- 주요 관심사: API 응답 상태, 사용자 인터페이스 오류
- 필요한 로그: API 요청/응답, 클라이언트 사이드 에러, 브라우저/기기 정보 등
- DevOps/Infra 엔지니어
- 주요 관심사: 시스템 전반적인 안정도와 인프라 리소스 상태
- 필요한 로그: 서버 리소스 사용률, 네트워크 트래픽, 배포 상태, 보안 관련 이벤트 등
- 보안 담당자
- 주요 관심사: 보안 위협 탐지, 컴플라이언스
- 필요한 로그: 접근 로그, 인증/인가 이벤트, 프록시 및 방화벽의 비정상 접근 행위 등
- 데이터 분석가
- 주요 관심사: 데이터 패턴, 사용자 행동
- 필요한 로그: 상세 사용자 행동 로그, 이벤트 트래킹 데이터, A/B 테스트 수치 등
- 기획자/PM
- 주요 관심사: 기능 사용 현황, 사용자 행동 패턴
- 필요한 로그: 기능별 사용 통계치, 사용자 플로우, 에러 발생 빈도 등
- 마케팅 담당자:
- 주요 관심사: 사용자 유입 경로, 페이지 전환율, 체류 시간
- 필요한 로그: 사용자 세션 정보, 사용자 플로우, 에러 발생 빈도 등
- CTO
- 주요 관심사: 시스템 안정성, 기술 부채
- 필요한 로그: 주요 시스템 메트릭, 장애 발생 통계, 성능 지표 등
- CEO
- 주요 관심사: 비즈니스 성과, 사용자 만족도
- 필요한 로그: 핵심 비즈니스 지표, 사용자 증가율 등
그래도 지금까지 개발을 진행하면서, 반드시 이런 부분은 로그를 남겨야 할 필요성을 느낀 부분들이 존재한다.
- Entity 상태 변경 시점: 주요 비즈니스 로직 실행 결과, 그리고 영속화 상태의 Entity 상태 변경 등에 대한 로그는 남겨두는 것이 추후 편리하다.
- Presentation Layer: 프론트엔드와의 싸움에서 이기고 싶다면, 정보력에서 뒤쳐져선 안 된다. 어떤 요청을 받았고, 어떤 응답을 보냈는 지 로그로 남겨두면, 잘못을 인정할 땐 누구보다 쿨하게 하면서, 클라이언트 잘못이라면 한 마리의 물고기를 낚은 낚시꾼의 기분을 만끽할 수 있다. (농담이고, 대화로 잘 해결하길 바란다. 문제를 빨리 조치하기 위해 서로 협력하는 관계라는 걸 잊지 말자.)
- I/O 작업: presentation layer와 마찬가지로, 외부 컴포넌트와 상호작용하는 부분은 모두 로그로 남겨두는 것이 용이하다.
- 예외 발생: 일반적으로 정상적으로 동작할 때의 로그보다, 에러가 발생했을 때 로그를 확인하는 경우가 더 많다. 이 때, 로그를 소중히 여기지 않았다면, 과거의 자신을 책망해봐야 늦었다.
- 인증/인가: 보안은 더 말할 것도 없다. 보안에 대해서는 어느 정도의 성능 저하를 감수하더라도, 완벽해야 한다는 게 내 소견이다.
- 성능 평가: 모든 서비스에 할 필요는 없을 지도 모르지만, 기능 만들고 보니 뭔가 싸한 녀석들이 종종 있을 것이다. 무슨 일이 벌어지는 지 추적해두는 것이 이롭다.
2. How Does Spring Manage Log Files
📌 System.out.println() - Why It's Not Enough
보통 개발을 처음 하는 사람조차도, 디버깅을 위해 정보를 남겨놔야 한다는 중요성은 모두 알고 있다.
하지만 차이가 있다면, 표준 입출력 라이브러리를 사용해버린다는 점이다.
나도 처음 백엔드 개발할 때는 로그라는 단어도 몰라서, System.out.println()으로 로그를 남긴적이 있다.
이는 별로 추천하고 싶지 않은 방법이다.
1️⃣ 성능 저하
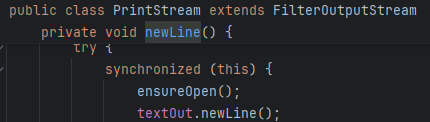
println() 메서드 내부를 살펴보면, synchonized 키워드가 걸려있다.
Outstream은 모든 스레드가 공유하는 공유 자원이므로, 안전성을 위해 동기화를 해야하기 때문.
그러나 lock은 언제나 느리다.
특히 로그처럼 무차별로 쏟아지는 데이터에 대해 매번 lock을 거는 것은 좋지 않은 생각이다.
2️⃣ 휘발성
println()은 그저 개발자가 명시한 정보를 콘솔에 쏟아부을 뿐이다.
버퍼가 비워지면 그 정보는 콘솔창에만 잔재하며, 이 마저도 프로그램을 종료하면 영구적으로 삭제된다.
물론 FileStream을 쓰면 되긴 하지만, 그럼 로그가 생길 때마다 println()로 인한 lock과 File 쓰기를 위한 작업이 함께 발생해야 한다.
3️⃣ 로그 레벨
로그는 기본적으로 육하원칙이 다 지켜져야 한다.
그 중에서도 "누가(thread)", "언제(timestamps)", "어디서(class/method)"가 없으면, 로그 추적이 매우 힘들어진다.
그리고 로그의 중요도를 구분하기 위해, 로그 레벨이라는 것을 도입하기도 어렵다.
- Error: 시스템 장애, 복구가 필요한 상황, 더 이상의 진행이 불가능
- Warn: 잠재적 문제 상황, 성능 저하
- Info: 일반적인 비즈니스 이벤트, 시스템 상태 변경
- Debug: 상세한 처리 정보, 개발 시 문제 해결용
- Trace: 가장 상세한 정보, 특정 문제 추적 시
만약 println()을 사용하면, 정작 필요한 정보는 상당 수 놓치고, 중요도가 낮은 정보들은 레벨 구분없이 무차별로 파일에 저장될 수 있다.
이는 디버깅을 힘들게 만들고, 서버 물리 공간을 불필요할 정도로 사용하게 될 수 있다.
📌 Logback
Logback Home
Logback Project Logback is intended as a successor to the popular log4j project, picking up where log4j 1.x leaves off. Logback's architecture is quite generic so as to apply under different circumstances. At present time, logback is divided into three mod
logback.qos.ch
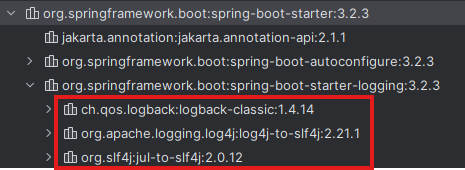
spring-boot-starter-web를 의존하면, 알아서 같이 주입된다.
SLF4J의 3가지 모듈을 가져오는데, 우리는 log4j를 개선한 버전인 logback을 사용할 예정이다.
yml 설정으로도 어느정도 커스텀하게 만들 수는 있으나, 보다 상세하게 구성하기 위해서는 xml로 구성하는 것이 좋다.
xml이 등장했다고 너무 쫄지말자. 나도 처음 써봤다.
공식 문서가 워낙 친절해서, 영어 울렁증이 있는 것만 아니라면 어렵지도 않다.
참고로 로그 작성 Pattern에 대해서 별도의 설명을 하지 않을 예정이니, 공식 문서 참고하면서 해석해보길 기원.
📌 src/main/resources/logback-spring.xml
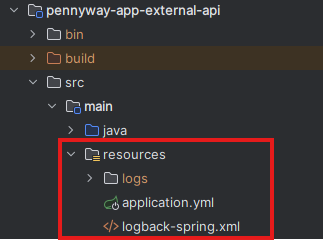
경로에 맞춰서 lobback-spring.xml 파일을 하나 만들어주자.
xml을 설정하기 앞서, 두 가지 주요 컴포넌트를 반드시 이해하고 넘어가자.
- appender: logger를 어디(ex. 콘솔, 파일, DB 등)에, 어떻 출력할 건지?
- logger: 로그를 생성하는 주체
가장 단순한 형태로 만들어보면, 다음과 같다.
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 콘솔 출력 설정 -->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<Pattern>[%d{yyyy-MM-dd HH:mm:ss}:%-3relative] %clr(%-5level) %clr(${PID:-}){magenta} %clr(---){faint} %clr([%15.15thread]){faint} %clr(%-40.40logger{36}){cyan} %clr(:){faint} %msg%n</Pattern>
</layout>
</appender>
<root level="info">
<appender-ref ref="CONSOLE"/>
</root>
<logger name="com.example.service" level="DEBUG" additivity="false">
<appender-ref ref="CONSOLE"/>
</logger>
</configuration>- CONSOLE이라는 이름의 appender를 정의
- ch.qos.logback.core.ConsoleAppender 클래스를 사용하여, 로그로 출력하도록 구성
- PatternLayout 클래스를 사용해, "[2024-01-15 19:20:45:123] {로그 레벨} {프로세스ID} [{스레드명}] ..."처럼 보이도록 패턴 지정 (이후 부터 패턴에 대한 이야기는 생략)
- root logger 설정
- 별도로 지정하지 않은 모든 log에 대한 설정으로, CONSOLE appender를 사용하여 INFO 레벨 이상만 출력
- com.example.service 패키지에 대한 logger 설정
- com.example.service 및 하위 패키지만 별도의 설정
- DEBUG 레벨 이상만 출력
- additivity = "false" : 상위(root)의 logger 설정을 상속하지 않기 위함.
그러면 이런 식으로 로그가 나온다.
📌 Property
위에서 패턴 정규식이 너무 길어서 가독성을 해치는 것 같으면, property 블럭으로 따로 빼줄 수 있다.
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 로그 패턴 설정 -->
<property name="CONSOLE_LOG_PATTERN"
value="[%d{yyyy-MM-dd HH:mm:ss}:%-3relative] %clr(%-5level) %clr(${PID:-}){magenta} %clr(---){faint} %clr([%15.15thread]){faint} %clr(%-40.40logger{36}){cyan} %clr(:){faint} %msg%n"/>
<!-- 콘솔 출력 설정 -->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<Pattern>${CONSOLE_LOG_PATTERN}</Pattern>
</layout>
</appender>
</configuration>사용할 때는 ${} 블럭 안에 property name을 넣어주면, 동일하게 사용해줄 수 있다.
📌 Color
<!-- 로그 패턴에 색상 적용 -->
<conversionRule conversionWord="clr" converterClass="org.springframework.boot.logging.logback.ColorConverter"/>로그가 흑백으로 나와서 칙칙하다면, 위 블럭을 중간에 추가해주면 된다.
📌 File Appender
DEBUG 레벨 로그를 콘솔에 모두 뿌린다면 어떻게 될까.
빠르게 콘솔로 로그를 확인하고 치우고 싶어도, 로그가 너무 많아서 도저히 파악이 안 되는 불상사가 발생할 것이다.
그렇다고 DEBUG 레벨 로그를 날려버리면, 나중에 디버깅 난이도가 급격하게 상승한다.
그래서 우리는 INFO 레벨 이상은 Console로 남기고, DEBUG 레벨 이상은 File에 남길 것이다.
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 로그 패턴에 색상 적용 -->
<conversionRule conversionWord="clr" converterClass="org.springframework.boot.logging.logback.ColorConverter"/>
<!-- 로그 설정 프로퍼티 -->
<property name="LOG_PATH" value="./pennyway-app-external-api/src/main/resources/logs"/>
<!-- 로그 패턴 설정 -->
<property name="CONSOLE_LOG_PATTERN"
value="[%d{yyyy-MM-dd HH:mm:ss}:%-3relative] %clr(%-5level) %clr(${PID:-}){magenta} %clr(---){faint} %clr([%15.15thread]){faint} %clr(%-40.40logger{36}){cyan} %clr(:){faint} %msg%n"/>
<property name="FILE_LOG_PATTERN"
value="[%d{yyyy-MM-dd HH:mm:ss}:%-3relative] %-5level ${PID:-} --- [%15.15thread] %-40.40logger{36} : %msg%n"/>
<!-- 콘솔 출력 설정 -->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<Pattern>${CONSOLE_LOG_PATTERN}</Pattern>
</layout>
</appender>
<!-- 파일 출력 설정 -->
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_PATH}/was.log</file>
<encoder>
<pattern>${FILE_LOG_PATTERN}</pattern>
</encoder>
<!-- 에러 발생시 무시하도록 설정 -->
<prudent>true</prudent>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!-- 롤링된 파일 명명 규칙 -->
<fileNamePattern>${LOG_PATH}/%d{yyyy-MM-dd}/was.%i.log</fileNamePattern>
<timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP">
<!-- 파일당 최대 크기: 10MB -->
<maxFileSize>10MB</maxFileSize>
</timeBasedFileNamingAndTriggeringPolicy>
<!-- 보관 주기: 7일 -->
<maxHistory>7</maxHistory>
<!-- 총 파일 크기 제한: 500MB -->
<totalSizeCap>500MB</totalSizeCap>
</rollingPolicy>
</appender>
<root level="info">
<appender-ref ref="CONSOLE"/>
</root>
<logger name="org.springframework.web" level="debug" additivity="false">
<appender-ref ref="FILE"/>
</logger>
</configuration>- RollingFileAppender
- rollover: 다음 파일로 이동 (다양한 규칙을 적용하여, 로그 파일을 자동으로 분리하는 행위)
- RollingPolicy: 어떻게 rollover을 할 것인가?
- TriggeringPolicy: 언제 rollover가 발생하는가?
- TimeBasedRollingPolicy & SizeAndTimeBasedRollingPolicy
- TimeBasedPolicy: 시간을 기준으로 rollover 설정
- SizeAndTimeBasedRollingPolicy: 시간과 파일 크기를 기준으로 rollover 설정
위 방식은 TimeBasedRollingPolicy을 적용하면서, 내부적으로 Size & Timebased FNATP(File Naming And Triggering Policy)를 사용한 것이다.
대부분의 블로그가 위와 같은 방법으로 설명해놨는데, 이런 조잡한 방식없이 SizeAndTimeBasedRollingPolicy를 바로 사용하면 된다.
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!-- 롤링된 파일 명명 규칙 -->
<fileNamePattern>${LOG_PATH}/%d{yyyy-MM-dd}/${LOG_FILE_NAME}.%i.log</fileNamePattern>
<!-- 파일당 최대 크기 -->
<maxFileSize>${LOG_MAX_FILE_SIZE}</maxFileSize>
<!-- 보관 주기 -->
<maxHistory>${LOG_MAX_HISTORY}</maxHistory>
<!-- 총 파일 크기 제한 -->
<totalSizeCap>${LOG_TOTAL_SIZE_CAP}</totalSizeCap>
</rollingPolicy>%i는 maxFileSize가 넘어갈 때마다 1씩 증가한다.
즉, 지정한 경로에 "${LOG_PATH}/2024-01-15/${LOG_FILE_NAME}.0.log"라는 파일이 생성된다는 의미가 된다.
그런데 직접 실행해보면 알겠지만, 실제로 생성되는 파일은 was.log가 끝이다.
시간 기반, 사이즈 기반 정책이 하나도 적용되지 않고 있을 것이다.
📌 Rolling by Size and Time
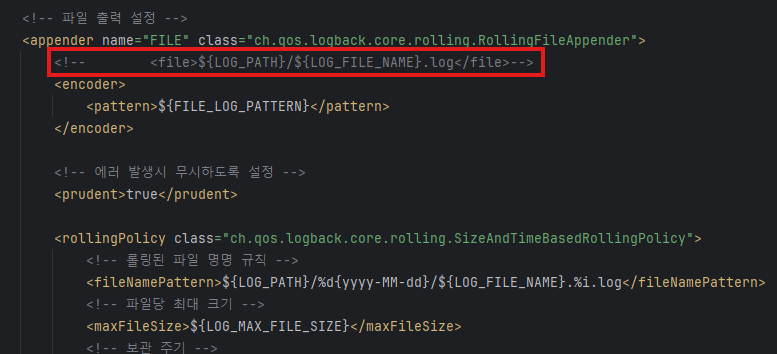
이유가 뭘까 생각해봤는데, 최상단에 파일 이름을 명시해버린 것이 문제가 된다고 판단했다.
fileNamePattern을 정하면 뭐하나? file 이름이 고정 상수로 떡하니 꽂혀있는데.
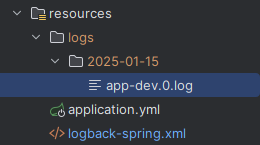
해당 라인을 삭제하면, 위와 같이 로그 파일이 날짜(디렉토리), 번호(사이즈) 별로 구분된다.
📌 Dividing Profiles
local 환경에선 굳이 log 파일을 생성할 이유가 없을 것이다.
반면, dev 환경과 prod 환경에선 필수가 될 텐데, 또 이 둘의 설정이 다르다면 로그 정책을 어떻게 분리할 것인가.
<!-- 프로파일별 설정 파일 로드 -->
<springProfile name="local,dev,prod">
<property resource="application.yml"/>
</springProfile>
<!-- 로그 설정 프로퍼티 -->
<springProperty name="LOG_FILE_NAME" source="log.config.filename"/>
<springProperty name="LOG_MAX_FILE_SIZE" source="log.config.maxFileSize"/>
<springProperty name="LOG_MAX_HISTORY" source="log.config.maxHistory"/>
<springProperty name="LOG_TOTAL_SIZE_CAP" source="log.config.totalSizeCap"/>- springProfile: 환경을 구분하여, 블록을 격리시키는 목적. name은 블럭 이름이 아니라, profile 이름이므로 주의하자.
- springProperty: yml 파일의 정보를 가져와, name으로 변수명을 정한다. 마찬가지로 ${}로 사용할 수 있다.
같은 경로에 yml 파일 정보를 가져오는데, LOG_FILE_NAME 같은 속성 정보도 profile 별로 구분하고 싶다면, 다음과 같이 작성해주면 된다.
---
spring:
config:
activate:
on-profile: local
log:
config:
filename: app-local
---
spring:
config:
activate:
on-profile: dev
log:
config:
filename: app-dev
maxHistory: 7
maxFileSize: 10MB
totalSizeCap: 500MB어차피 커스텀으로 정한 속성이기 때문에, 굳이 log.config.* 형태일 이유는 없다.
하지만 yml과 이를 참조하는 xml의 경로는 일치해야 한다.
그리고 Profile 별로, springProfile 블럭을 이용해 로깅 전략을 수립하면 된다.
<!-- 프로파일별 로그 설정 -->
<springProfile name="local">
<root level="info">
<appender-ref ref="CONSOLE"/>
</root>
</springProfile>
<springProfile name="dev">
<root level="info">
<appender-ref ref="CONSOLE"/>
</root>
<logger name="org.springframework.web" level="debug" additivity="false">
<appender-ref ref="FILE"/>
</logger>
</springProfile>
<springProfile name="prod">
<root level="info">
<appender-ref ref="CONSOLE"/>
</root>
<logger name="org.springframework.web" level="debug" additivity="false">
<appender-ref ref="FILE"/>
</logger>
</springProfile>- local: INFO 레벨 이상 콘솔 출력만
- dev, prod: 모든 로그는 INFO 레벨 이상 콘솔 출력, "org.springframwork.web" 패키지 이하 컴포넌트는 모두 DEBUG 이상 FILE 출력
👇 전체 코드
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 프로파일별 설정 파일 로드 -->
<springProfile name="local,dev,prod">
<property resource="application.yml"/>
</springProfile>
<!-- 로그 설정 프로퍼티 -->
<property name="LOG_PATH" value="./pennyway-app-external-api/src/main/resources/logs"/>
<springProperty name="LOG_FILE_NAME" source="log.config.filename"/>
<springProperty name="LOG_MAX_FILE_SIZE" source="log.config.maxFileSize"/>
<springProperty name="LOG_MAX_HISTORY" source="log.config.maxHistory"/>
<springProperty name="LOG_TOTAL_SIZE_CAP" source="log.config.totalSizeCap"/>
<!-- 로그 패턴에 색상 적용 -->
<conversionRule conversionWord="clr" converterClass="org.springframework.boot.logging.logback.ColorConverter"/>
<!-- 로그 패턴 설정 -->
<property name="CONSOLE_LOG_PATTERN"
value="[%d{yyyy-MM-dd HH:mm:ss}:%-3relative] %clr(%-5level) %clr(${PID:-}){magenta} %clr(---){faint} %clr([%15.15thread]){faint} %clr(%-40.40logger{36}){cyan} %clr(:){faint} %msg%n"/>
<property name="FILE_LOG_PATTERN"
value="[%d{yyyy-MM-dd HH:mm:ss}:%-3relative] %-5level ${PID:-} --- [%15.15thread] %-40.40logger{36} : %msg%n"/>
<!-- 콘솔 출력 설정 -->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<Pattern>${CONSOLE_LOG_PATTERN}</Pattern>
</layout>
</appender>
<!-- 파일 출력 설정 -->
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<!-- <file>${LOG_PATH}/${LOG_FILE_NAME}.log</file>-->
<encoder>
<pattern>${FILE_LOG_PATTERN}</pattern>
</encoder>
<!-- 에러 발생시 무시하도록 설정 -->
<prudent>true</prudent>
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!-- 롤링된 파일 명명 규칙 -->
<fileNamePattern>${LOG_PATH}/%d{yyyy-MM-dd}/${LOG_FILE_NAME}.%i.log</fileNamePattern>
<!-- 파일당 최대 크기 -->
<maxFileSize>${LOG_MAX_FILE_SIZE}</maxFileSize>
<!-- 보관 주기 -->
<maxHistory>${LOG_MAX_HISTORY}</maxHistory>
<!-- 총 파일 크기 제한 -->
<totalSizeCap>${LOG_TOTAL_SIZE_CAP}</totalSizeCap>
</rollingPolicy>
</appender>
<!-- 프로파일별 로그 설정 -->
<springProfile name="local">
<root level="info">
<appender-ref ref="CONSOLE"/>
</root>
</springProfile>
<springProfile name="dev">
<root level="info">
<appender-ref ref="CONSOLE"/>
</root>
<logger name="org.springframework.web" level="debug" additivity="false">
<appender-ref ref="FILE"/>
</logger>
</springProfile>
<springProfile name="prod">
<root level="info">
<appender-ref ref="CONSOLE"/>
</root>
<logger name="org.springframework.web" level="debug" additivity="false">
<appender-ref ref="FILE"/>
</logger>
</springProfile>
</configuration>
3. How to Manage Log Files
📌 Log Storage Policy
⚠️ 여기서부터 이어지는 내용들은 모두 뇌피셜입니다.
모든 로그들을 계속 쌓아두기만 한다면 무의미할 뿐 아니라, 그 만큼 물리적인 공간을 차지하게 되므로 서버 입장에선 부담이 될 수 있다.
따라서, 로그 레벨에 따른 보관 기간 정책을 책정하는 것이 좋다.
1️⃣ 로그 레벨
예를 들어, 다음과 같이 구상해볼 수도 있을 것 같다. (예시일 뿐)
- Hot (0~7d): 빠른 검색이 필요한 최신 로그
- Warm (8~30d): 가끔 접근하는 중기 로그
- Cold (31~90d): 거의 접근하지 않는 장기 로그
- Delete (90d~): 자동 삭제
참고로 로그에 어떤 기록을 담냐에 따라 법적 조치가 들어갈 수도 있으므로, 개인정보보호법 등을 꼼꼼하게 확인해보자.
(근데 듣기로는 오히려 대기업은 문제가 없고, 대부분 개인 정보 유출되는 건 어디서 듣도 보도 못한 사이트가 많다고 한다. 개인 정보 보안 관련 쪽으로 상당히 후진국스러운 면모를 엿볼 수 있다.)
2️⃣ 로그 압축 및 아카이빙
로그 레벨을 나누었다면, 어디에 저장해볼 지 생각해볼 필요도 있다.
- Hot
- 최근 로그인 만큼 중요도가 높으며, 빠른 탐색이 핵심
- 오늘 자 로그는 파일, 어제 이전 로그들은 gz로 압축 혹은 NoSQL 같은 곳에 저장해볼 수도 있다.
- Warm
- Hot 로그에 비해 중요도는 낮지만, 여전히 탐색에 용이해야 하며, 데이터 지속성과 적절한 균형이 중요
- NoSQL 혹은 RDB에 저장. (증가하는 로그 볼륨을 효과적으로 처리하려면, 샤딩과 클러스터링으로 수평적 확장이 필요해질 수 있다.)
- Cold
- 중요도가 매우 낮으며, 조회하는 경우가 매우 드물기 때물기 때문에 데이터 지속성이 핵심
- S3 bucket 중에서도 저비용 storage에 저장해둘 수 있다.
3️⃣ 로그 분석 최적화
로그를 (나처럼) 그대로 쌓아두기만 하면, 탐색에 상당한 어려움을 겪는다.
DAU 10명만 되어도 로그가 상당히 많이 쌓일텐데, 컴플레인이라도 걸려서 로그를 뒤져봐야 한다고 생각해보자.
(우리는 iOS 개발자가 2명인데, 고작 둘이서 같이 활동하다가 로그 찾아달라고 해도 죽을 맛이다.)
따라서, 로그들을 어떻게 저장할 지 고민해볼 필요가 있다.
// 로그 인덱싱 전략
{
"template": "app-logs-*",
"mappings": {
"properties": {
"@timestamp": { "type": "date" },
"service": { "type": "keyword" },
"level": { "type": "keyword" }
}
}
}예를 들어, 위와 같이 각 log의 속성으로 timestamp, service 명, log level 등을 기록해두고, content를 추가하는 식으로 로그를 잘 가공한다고 생각해보자.
나중에 스스로가 대견해질 것이다.
(뭔가 유용한 말을 하고 싶었는데, 나도 안 해봐서 급하게 마무리 덜덜)
📌 Overview
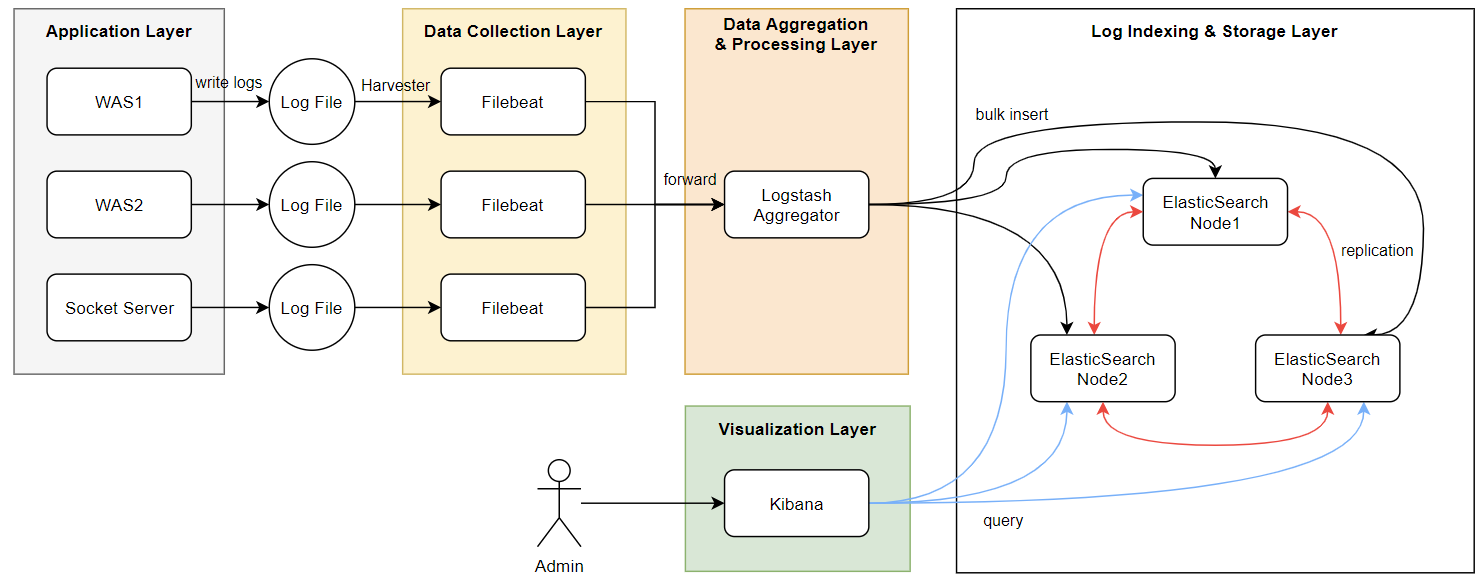
백엔드를 공부하는 사람이라면 한 번쯤은 들어봤을 ELK라는 오픈 소스가 있다.
정확히는 Elasticsearch - Logstash - Kibana를 모두 합쳐서 부르는 준말이다.
예전부터 너무 써보고 싶었는데, 메모리를 너무 많이 잡아먹어서 도저히 프리티어 서버에서 굴릴 수가 없다.
'언젠간 써봐야지'라고 연신 중얼거린지 벌써 2년이 다 되어간다.
빨리 ELK 쓰는 회사로 취업해서 만져보고 싶다. 만지게 해줄 지는 모르겠다.
여튼 ELK를 사용하면 로그 관리가 상당히 용이해지는데, 다음과 같은 식으로 구성해볼 수 있다.
- 애플리케이션 계층
- 여러 애플리케이션이 각각의 독립적인 로그 파일을 생성하여 축적한다.
- 데이터 수집 계층 (Filebeat)
- 해당 로그들을 주기적으로 수집하여, 버퍼에 저장한다.
- 버퍼가 가득차면 데이터 처리 계층으로 전달한다.
- 데이터 통합 및 처리 계층 (Logstash)
- Aggregator는 수집된 로그들을 적절하게 가공하여, 데이터 저장 계층으로 전송한다.
- 데이터 인덱싱 및 저장 계층 (Elasticsearch)
- 로그 데이터들을 인덱싱하여 저장한다.
- 클러스터링으로 고가용성과 확장성을 제공하면서, replica로 데이터 안전성을 보장한다.
- 시각화 계층 (Kibana)
- Elasticsearch의 데이터를 조회하여, 사람이 이해하기 편하도록 시각화한다.
- 대시보드 같은 도구들을 통해, 시스템 상태와 중요 지표들을 실시간 모니터링할 수 있다.
디게 예전에 알아봤던 내용들이라 맞는 진 모르겠는데, 설명이 빈약할 뿐 틀리진 않았을 것이다.
(언젠간 써봐야지)
5. Conclusion
📌 로그는 자산이다.
이거 적용하자마자, 오늘 iOS 팀이랑 디버깅하는 과정에 요긴하게 써먹었다.
개발할 때는 그렇게 로그 중요하게 신경써놓고, 왜 정작 배포 환경은 등한시 했었는지...모르겠다기엔 솔직히 지금 로그 파일 만드는 것도 부담일 정도로 서버 상태가 안 좋긴 하다.
로그는 자산이 맞다.
근데 지금 서버 굴릴 시드도 없는데, 로그 줄 테니까 누가 돈으로 좀 바꿔줬으면 좋겠다.
여튼 이번에 생략한 부분이 상당히 많은데, 체계적인 로그 관리 방법이 궁금해졌다.
고로 다음 포스팅 주제는 대규모 로그 관리 시스템 설계를 다뤄보자.