⚠️ AOP와 Spring Aspect를 어느정도 이해하고 다뤄보신 분이 아니라면 이해하기 어렵습니다.
1. Introduction
📌 Reason
GitHub - CollaBu/pennyway-was: 🪙 Pennyway Spring Boot Web Application Server
🪙 Pennyway Spring Boot Web Application Server. Contribute to CollaBu/pennyway-was development by creating an account on GitHub.
github.com
위 프로젝트에서 채팅 서버를 점진적으로 Java에서 Kotlin으로 마이그레이션을 하고 있다.
이유를 묻는다면 정석적이고 모범적인 답안을 제시할 수는 있지만, 실상은 그냥 코틀린을 써보고 싶었다.
안 그래도 팀에 맞춘다고 스프링 부트 + 자바를 벗어나지 못 하고 있다가, 어차피 다들 바쁘다고 뿔뿔이 흩어진 마당에 이런 식으로라도 실리를 얻어야 하지 않겠는가.
여튼 그렇게 작업을 하다가, 소켓 서버를 최대한 가볍게 만들겠답시고 Spring Security를 주입하지 않고, @PreAuthorize를 직접 만든 적이 있었다.

"대체 왜?"라는 질문을 받았었는데, 그야 그게 간지였으니까.
농담이고 비록 Node.js + socket.io 조합은 포기했더라도, 최대한 애플리케이션을 경량으로 만들 필요가 있었기 때문이다.
Java에선 Spring AOP를 사용하지 않기 위한 방법이 거기서 거기긴 하다만, Kotlin이라면 이야기가 조금 달라진다.
비록 안드로이드 개발할 때 깔짝 다뤄본 게 끝이지만, 내가 아는 Kotlin은 찐따같은 Java랑은 뭔가..뭔가 다르다고 믿었다.
(Java가 찐따같다는 말에 부디 상처받는 사람이 없길 바란다. 하지만 굳이 죄목을 따지자면 사실 적시 명예훼손이 아닐까)
여튼 이번 목표는 커스텀하게 만들었던 @PreAuthrize를 보다 type-safe하게 만들면서, 성능을 얼마나 끌어올릴 수 있는 지 알아보고자 한다.
📌 Reference
Kotlin으로 Spring AOP 극복하기! | 카카오페이 기술 블로그
Kotlin의 문법적 기능을 사용해서 Spring AOP 아쉬운 점을 극복한 경험을 공유합니다.
tech.kakaopay.com
이 글을 쓸 수 있게 된 직접적인 인사이트는 카카오 기술 블로그에서 얻었다.
Spring AOP가 구리다는 점은 이미 알고 있었지만, Tx 자원까지 고민한 건 놀라웠다.
원래는 코틀린 Trailing Lambda로 해결해볼 수 있지 않을까 싶어서 찾은 글이었지만, 원하는 것 이상으로 많은 걸 배울 수 있었다.
2. Spring AOP Disadvantage
📌 Spring AOP Feels Clumsy
Spring AOP는 기본적으로 구리다.
우선 AOP라는 녀석은 반복되는 공통 로직들을 재사용해야 하는데,
이런 로직들을 중간 중간 끼워넣기 위해서 다음과 같은 방법들을 사용할 수 있다.
1️⃣ 패키지 경로 명시
@Slf4j
@Aspect
@Component
public class ExternalApiLogAspect {
/**
* kr.co.pennyway.api.apis 패키지 하위의 모든 Controller 클래스의 모든 메서드를 대상으로 한다. <br/>
* 단, 클래스명의 접미사가 Controller로 끝나는 클래스만 대상으로 한다.
*/
@Pointcut("execution(* kr.co.pennyway.api.apis.*.controller.*Controller.*(..))")
private void cut() {
}
...
}
2️⃣ 어노테이션 경로 명시
/**
* WebSocket Controller에 대한 인증 및 인가를 지정하는 어노테이션.
* 이 어노테이션이 붙은 메서드는 {@link PreAuthorizeAspect}에 의해 처리됩니다.
*/
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface PreAuthorize {
String value();
}@Aspect
@Component
class PreAuthorizeAspect(private val applicationContext: ApplicationContext) {
@Around("@annotation(kr.co.pennyway.socket.common.annotation.PreAuthorize)")
fun execute(joinPoint: ProceedingJoinPoint): Any? { ... }
...
}이런 식으로 설정을 하면, 해당 패키지의 클래스(혹은 메서드)가 실행되기 전/후에 공통 로직들을 끼워넣을 수 있다.
뭐가 더 낫다고 말할 것도 없이, 둘 다 좀스러운 방식일 뿐이다.
📌 Implementation Complexity
관련 자료가 워낙 방대하다보니 러닝 커브가 크다고 생각은 하진 않지만, 그렇다고 배우기 쉽거나 테스트를 하기 용이하냐고 묻는다면 그런 거 같진 않다.
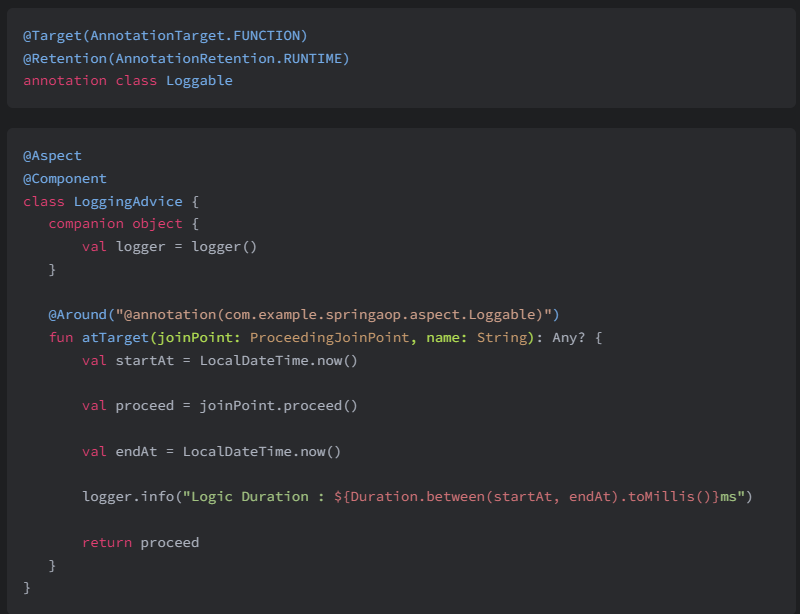
우선 단순한 Annotation을 활용한 단순한 로깅 AOP 기능을 하나 만들기 위해서도, 두 개의 클래스 파일을 만들어야 한다.
@Target(AnnotationTarget.FUNCTION)
@Retention(AnnotationRetention.RUNTIME)
annotation class Loggable@Aspect
@Component
class LoggingAdvice {
companion object {
val logger = logger()
}
@Around("@annotation(com.example.springaop.aspect.Loggable)")
fun atTarget(joinPoint: ProceedingJoinPoint, name: String): Any? {
val startAt = LocalDateTime.now()
val proceed = joinPoint.proceed()
val endAt = LocalDateTime.now()
logger.info("Logic Duration : ${Duration.between(startAt, endAt).toMillis()}ms")
return proceed
}
}
그리고 위 AOP를 적용할 메서드에 어노테이션을 선언해주면 된다.
@Component
class ExampleComponent {
@Loggable
fun execute() { ... }
}
여기서 Spring AOP를 처음 다뤄보는 사람에겐 이런 의문이 뒤따라 올 수 있다.
ProceedingJointPoint는 뭐고, @Around는 대체 뭐지?
굳이 이런 단순한 AOP 기능 하나를 만들기 위해서
개발자가 익숙치도 않은 표현을 이해해야 하고,
추가로 늘어나는 클래스 파일들을 관리하고,
덕지덕지 붙기 시작하는 더러운 어노테이션들을 용인해주어야만 한다.
그리고 이런 AOP가 실제로 잘 적용되는 지 확인을 해야 한다.
LoggingAdvice 만을 테스트하는 건 그리 어려운 일이 아니지만, 만약 해당 어노테이션이 통합 테스트 환경이 아니어도 실행이 되어야 하는 경우엔 문제가 귀찮아 질 수 있다.
예를 들어, 별다른 설정 없이 단위 테스트 환경에서 ExampleComponent의 execute를 실행하면, LoggingAdvice는 동작하지 않는다.
@Loggable을 관찰하는 LoggingAdvice가 Spring Application Context 내에서 초기화되지 않은 상태이므로, 실행조차 되지 않고 그냥 지나치게 되기 때문이다.
📌 String Dependency (Potential Runtime Errors)
@Pointcut("execution(* kr.co.pennyway.api.apis.*.controller.*Controller.*(..))")Spring AOP의 가장 큰 문제는 문자열 의존 한 마디로 정리할 수 있다.
클린 코드든, 이펙티브 자바든 기본적인 프로그래밍 원칙을 다루는 책에서도 단골 소재로 나오는 이야기다.
- 문자열은 번거롭고, 덜 유연하고, 느리고, 오류 가능성이 크다.
- 타입 안전성 보장이 어렵다.
- 타입 추론 목적의 문자열은 컴파일 타임에 문제를 확인할 수가 없다.
- 입력받을 데이터가 진짜 문자열일 때만 사용하고, 타입을 표시하고 싶으면 차라리 새로 만들어라.
대체 이게 무슨 소린가 싶겠지만, 구체적인 예시를 보면 납득하기 어려운 내용이 아니다.
1️⃣ 문자열 타입 경로 지정 방법은 런타임에 깨질 수 있다.
@Pointcut("execution(* kr.co.pennyway.api.apis.*.controller.*Controller.*(..))")@Around("@annotation(com.example.springaop.aspect.Loggable)")위 표현식은 관찰할 클래스 혹은 메서드 경로를 직접 결정하는 방법이고,
아래는 특정 어노테이션을 관찰하도록 결정하는 방법이다.
문제는 이런 패키지 경로를 문자열로 지정하는 방법은 여러 잠재적 문제를 품고 있다.
- 직접 실행해보기 전까지는 패키지 경로 표현식의 오류를 찾아낼 수가 없다. (컴파일 시점 추론이 불가능)
- 변경에 유연하지 않다.
- 관찰 대상의 모든 컨트롤러는 AOP에 의해 패키지 경로가 강제되는 이상한 논리에 빠지게 되었다.
- Loggable 어노테이션의 이름이 마음에 들지 않아서 수정해도, Advice 내의 문자열 표현식은 함께 수정되지 않는다. 만약 이를 놓친다면 런타임에서 에러가 우리를 반겨준다.
2️⃣ 어노테이션의 값은 컴파일 타임에 결정되어야 한다.
@Cacheable(value = "GoogleOauth", cacheManager = "oidcCacheManager")@PreAuthorize("isAuthenticated() and @chatRoomManager.hasPermission(principal.userId, #chatRoomId)")Spring의 @Cacheable이 됐건, Spring Security의 @PreAuthorize가 됐건 Spring을 제법 다뤄본 개발자라면,
굳이 이런 어노테이션이 아니더라도 수많은 어노테이션들을 접해봤을 것이다.
그리고 이런 어노테이션들이 툭하면 문자열로 값을 받고 있는다는 것을 알고 있을 텐데, 이는 Spring 개발자들이 멍청해서가 아니다. (나같은 건 감히 비빌 수 없을 정도로 대단하신 분들이다.)
Java에선 annotation의 모든 값들이 컴파일 타임에 결정되어야 한다.
(Annotation Processing Tool이 컴파일 타임에 동작하여 코드 생성과 검증을 수행하는데, 런타임 과정에서 바뀌면 의미가 없어지기 때문이다.)
엥, 이러면 컴파일 타임에 값을 강제해서 type-safe 해진 거 아닌가요?
애석하게도 AOP 기능을 실행할 때, 컴파일 타임에 값을 알 수 없는 경우가 있다.
이런 값들은 런타임에 값을 받아와야 하는데, @Cacheable의 key, @PreAuthorize의 검증 표현식들이 그 예시다.
문제는 컴파일 타임 결정 조건 때문에 이 값들을 받기가 너무 어렵다는 점이다.
예를 들어, 문자열 상수를 넣기 위해서 `static final String` 보다는 enum 클래스를 사용하는 걸 권장하는 요즘 추세에 어노테이션은 이를 수용하질 못 한다.
enum class AuthType {
PERMIT_ALL("permitAll()"),
AUTHENTICATED("isAuthenticated()");
fun value(): String = spel // 인스턴스 메서드
}
@RequireAuth(AuthType.AUTHENTICATED) // 이건 가능
fun getPublicProfile() { }
@RequireAuth(AuthType.AUTHENTICATED.value()) // 컴파일 에러: 인스턴스 생성(런타임)해야 해서 불가능
fun getPublicProfile() { }enum 상수 자체는 사용할 수 있어도, 상수의 값은 인스턴스 생성이라는 중간 단계 때문에 컴파일 타임에 결정이 되질 않기 때문이다.
패키지 경로나, 어노테이션 경로를 하드 코딩하는 것도 귀찮아 죽겠는데, 동적인 값들을 무슨 수로 처리하겠는가?
그래서 Spring은 일단 값을 문자열로 받으면, 표현식을 추론할 수 있는 Spring Expression Language(SpEL)을 지원한다.
"isAuthenticated() and @chatRoomManager.hasPermission(principal.userId, #chatRoomId)"
// isAuthenticated(): 메서드 실행
// and: && 연산자로 취급
// @chatRoomManager: chatRoomManager라는 Bean을 탐색함
// hasPermission(java.lang.Long, java.lang.Long): chatRoomManager의 (Long, Long) 메서드를 갖는 hasPermission 메서드 탐색
// # : 보통 정적 메서드 호출이나, 매개변수를 받을 때 사용@PreAuthorize의 value 값을 통해 인증/인가 기능을 수행할 수 있는 이유도 이런 이유다.
SpEL을 잘 설정해주고, 표현식을 동적으로 바인딩하면 위와 같이 표현식을 검증한다.
써본 사람 입장에서 이야기 하자면, 이건 AOP 기능을 개발할 때 가장 큰 장벽이다.
학습 비용이 급격하게 증가하면서, 생성 비용이 비싼 EvaluationContext의 정적 관리, 그로 인해 뒤따라오는 동시성 문제까지 고민해야 할 게 한 두가지가 아니다.
✒️ 매개변수 이름과 SpEL
카카오 기술 블로그에서는 다른 관점에서 생산성 저하 원인을 꼽았는데, 매개변수 이름과 표현식의 이름이 동일해야 한다는 문제를 지적했다.
이건 나도 커스텀한 @PreAuthorize를 만들다가 경험해본 일인다.
annotation에 "#userId"를 지정해놓고, 매개변수를 (Long id)로 정하면 두 값이 매칭이 안 되어 userId는 null이 되는 참사가 발생한다.
이런 사소한 실수에도 컴파일 타임에 문제를 잡아내질 못하니, 자꾸 세세한 요소들을 조정하는 코드들을 작성해야 하고, 더 많은 테스트를 요구하게 된다.
이로 인해, "이렇게 할 거면...뭐하러 Spring AOP를 쓰는데?" 라는 원론적인 질문으로 회귀하게 된다는 것이다.
3️⃣ JointPoint의 파라미터 순서 의존성
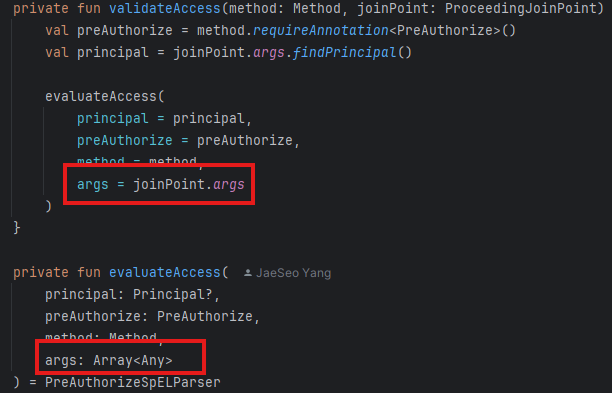
Advice에서 JointPoint의 인자(AOP를 호출한 게 메서드라면, 메서드의 파라미터 정보들)를 필요로 하는 경우가 존재할 수 있다.
예를 들어, 다음과 같이 파라미터 정보를 이용하는 경우를 생각해보자.
@Loggable
fun processUser(userId: Long, name: String, age: Int) {
// 비즈니스 로직
}
@Around("@annotation(com.example.Loggable)")
fun aroundTarget(joinPoint: ProceedingJoinPoint): Any? {
// joinPoint.args는 [Long, String, Int] 타입의 배열
val arguments = joinPoint.args
// 인자의 순서에 의존하는 위험한 코드
val userId = arguments[0] as Long // processUser의 첫 번째 파라미터가 변경되면 실패
val name = arguments[1] as String // 두 번째 파라미터가 변경되면 실패
return joinPoint.proceed()
}만약 processUser()의 userId와 name 파라미터 순서가 바뀌면, runtime에 arguments[0] as Long이 ClassCastException을 반환한다.
// 파라미터 이름에 의존
val userIdIndex = parameterNames.indexOf("userId")
val userId = joinPoint.args[userIdIndex] as Long그렇다고 위와 같이 파라미터 이름을 정하면, @Loggable을 선언한 호출자 측에서 userId에 해당하는 필드 이름을 id로 정해도 런타임 에러가 발생한다.
애초에 AOP라는 게 공통 로직을 추상화시켜서 클라이언트가 세부사항을 신경쓰지 않게 하기 위함인데,
이렇게 되면 파라미터 정렬 순서부터 어떻게 할 지 많은 시간 고민을 해야 하는 이상한 과정을 수반하게 된다.
📌 Unable to Call Internal Functions
예전에 작성했던 글에서 예시 코드를 일부로 틀리게 적은 게 있다.
@Service
public class OrderPaymentService {
public Payment execute(...) {
// 1. 각 Entity의 도메인 서비스 호출
Payment payment = executeInTransaction(() -> {
...
});
}
@Transactional // AOP 기반 동작에서 내부 메서드 호출은 선언적 Tx가 동작하지 않는다. 이건 그저 예시일 뿐이다.
private <T> T executeInTransaction(Supplier<T> operation) {
return operation.get();
}
}@Transaction이 선언된 함수를 호출하기 때문에 정상적으로 Tx가 동작할 거라 생각할 수 있지만,
Spring을 공부해본 사람은 모두 알 듯이 이렇게 동작하질 않는다.
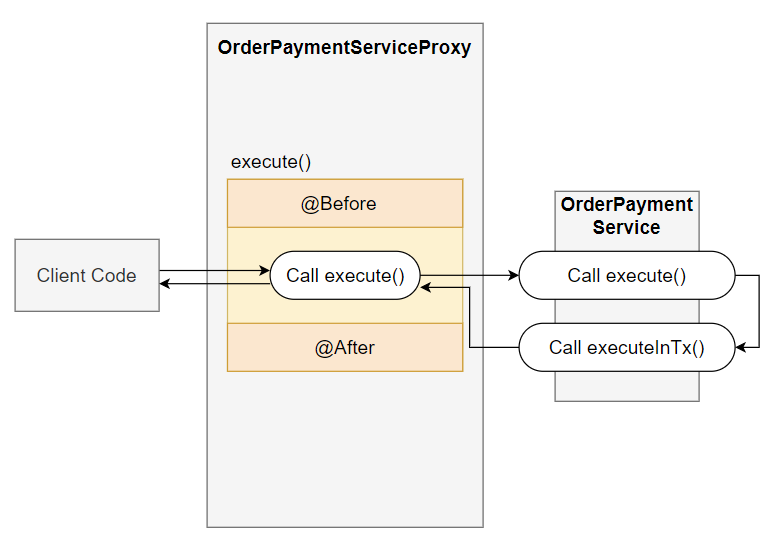
Spring은 @Component 어노테이션이 붙은 클래스들을 Proxy 모드로 수행하기 때문이다.
- Spring은 AOP가 적용될 클래스들의 Proxy 객체를 생성한다.
- 이 Proxy는 원본 클래스를 상속하거나 인터페이스를 구현한다.
- 클라이언트의 호출을 가로채서 AOP 로직을 실행한 후 원본 객체의 메서드를 호출한다.
여기서 중요한 점은, Proxy는 오직 외부에서 들어오는 메서드 호출만을 가로챌 수 있다는 점이다.
즉, execute() 내부에서 executeInTransational()을 호출하면, @Transactional이 수행되지 않는다.
- this는 현재 실행 중인 객체를 가리킨다.
- AOP가 적용된 메서드 내부에서도 this는 프록시가 아닌 실제 대상 객체를 가리킨다.
- 따라서 this.executeInTransactional()은 프록시를 거치지 않고 직접 원본 객체의 메서드를 호출한다.
이걸 해결하는 가장 쉬운 방법은 Tx가 실행될 서비스를 원자적인 연산 단위로 쪼개고, 오케스트레이션 역할의 서비스가 다른 서비스들을 차례로 호출하면 된다.
(그냥 execute()에 Tx를 선언해도 되겠지만, 불필요한 작업에 Tx 자원이 계속 점유되는 상황이 발생하는 병목지점으로 작용할 수 있다.)
이는 아이러니하게도 편의를 위해 사용하는 AOP 때문에 서비스 레이어 단계가 더욱 깊어지게 되어, 코드 복잡도 증가로 이어지는 결과를 낳는다.
📌 Summary
Spring AOP의 단점을 정리하면 다음과 같다.
- 구현이 복잡하다.
- 문자열 종속을 회피할 마땅한 대안이 없기 때문에, 잠재적인 런타임 예외를 가지고 있다.
- 내부 함수 호출 시 적용되지 않는다.
그렇다면 우리는 어떻게 이를 극복할 수 있을까?
3. Simple Solution
📌 Use the Utility or Helper Class
위의 문제들을 해결하기 위한 가장 단순한 방법은 가장 기본적인 형태의 AOP로 회귀하는 것이다.
Java로 표현하면 다음과 같이 사용하게 될 것이다.
class final TxAdvice {
public static <T> T executeInTransaction(Operation<T> function) {
return funtion.execute();
}
@FunctionalInterface
public interface Operation<T> {
T execute();
}
}@Service
public class OrderPaymentService {
public Payment execute(...) {
Payment payment = TxAdvice.executeInTransaction(() -> { // 중간에 끼워넣기
return paymentRepository.save(new Payment(...));
});
// ...
}
}하지만 Transaction을 적용하는 건 static 메서드에서 적용할 수 없으므로, Tx 클래스를 Spring Bean으로 등록시켜야 한다.
(PlatfromTransactionalManager을 사용한다 하더라도 해당 인터페이스 자체가 Spring 실행 이후에 초기화되기 때문에 사용할 수 없는 것으로 알고 있다. 애초에 직접 쓰는 걸 권장하질 않아서 모르겠다.)
@Compnent
class TxAdvice {
@Transactional
public <T> T executeInTransaction(Operation<T> function) {
return function.execute();
}
@FunctionalInterface
public interface Operation<T> {
T execute();
}
}Java에서는 이 정도가 한계다.
모든 클래스에서 TxAdvice 빈을 주입받아서 사용해야 한다는 문제가 발생한다.
약간 찝찝한 점이 있다면, 현재 OrderPaymentService.execute()의 파라미터를 람다 표현식에서 사용하고 있는데,
이렇게 되면 Closure로 작용하게 되면서 effectively final 조건에도 신경을 많이 써주어야 한다.
4. Trailing Lambdas
📌 What's the trailing lambda?
코틀린에서 보다 우아하게 해결하는 방법을 알기 전에, Trailing Lambda라는 문법을 이해해야 한다.
난 Swift 할 때, Trailing Closure를 다뤄본 적이 있어서 어렵진 않았다.
일반적인 람다 호출은 다음과 같이 생겼다.
// 일반적인 람다 호출
someFunction(arg1, arg2, { x -> x * 2 })
Trailing Lambda는 함수의 마지막 매개변수가 람다일 때, 이를 괄호 밖으로 뺄 수 있는 문법이다.
// Trailing Lambda 사용
someFunction(arg1, arg2) { x -> x * 2 }
예를 들어, 파일을 읽는 코드를 작성한다고 하면, 두 가지 방법 모두 사용 가능하다.
// 일반적인 방식
file.use({ reader ->
val content = reader.readText()
println(content)
})
// Trailing Lambda 사용
file.use { reader ->
val content = reader.readText()
println(content)
}여기서 주목할만한 점은 람다가 함수의 유일 매개변수인 경우에는 빈 괄호마저 생략 가능하다는 것이다.
둘은 별 차이가 없어보이지만, 이를 잘 활용하면 DSL(Domain Specific Languate)를 만들 때 효과적이다.
// HTML 구조 처럼 kotlin 코드를 작성할 수도 있다.
html {
head {
title { +"페이지 제목" }
}
body {
div {
+"Hello World"
}
}
}
📌 LoggingAdvice with Trailing Lambda
가장 단순한 로그 AOP 부터 개선해보자.
fun <T> loggingStopWatch(function: () -> T): T {
val startAt = LocalDateTime.now() // 함수 실행 전 시작 시간 체크
val result = function.invoke() // 로직 실행
val endAt = LocalDateTime.now() // 함수 실행 후 종료 시간 체크
logger.info("Logic Duration : ${Duration.between(startAt, endAt).toMillis()}ms")
return result
}@Component
class ExampleComponent(private val ...) {
fun execute() = logging {
this.executeInternal()
}
fun executeInternal() = logging { // 내부 함수 호출도 동작
...
}
}짜잔, 끝나버렸다.
- 일반 함수이므로 특별한 설정이 필요 없으며, 스프링 컨텍스트 초기화 여부와 상관없이 바로 사용할 수 있다.
- 로깅이 발생하는 시점이 코드상 명확히 보이며, IDE에서 코드 네비게이션에 훨씬 용이하다.
- 명시적인 함수 호출이므로 내부 메서드 호출에서도 정상 동작한다.
- 조건에 따라 로깅을 적용할지 결정할 수 있으며, 필요에 따라 type-safe한 매개변수를 전달할 수도 있다.
- 일반 함수이므로 단위 테스트가 가능하다.
이러니 Kotlin 한 번 맛보면 Java로 못 돌아간다는 얘기가 나오는 구나 싶다.
📌 TxAdvice with Trailing Lambda
다음은 Tx인데, 이번에는 Advice가 런타임에 초기화 되는 내부 의존성을 가져야 하기 때문에 문제가 다소 까다로워진다.
(개인적으로 이 파트는 카카오 기술 블로그를 읽는 게 훨씬 나을 것이라 생각한다. 내가 쓴 건 분석에 가까운 글이 될 듯 하다.)
@Component
class TxAdvice {
@Transactional
fun <T> run(function: () -> T): T {
contract {
callsInPlace(function, kotlin.contracts.InvocationKind.EXACTLY_ONCE)
}
return function.run()
}
}Java로 예시를 들었던 TxAdvice를 코틀린으로 치환하면 위와 같이 표현할 수 있다.
- contract: 컴파일러에게 함수 동작 방식 추가 정보를 제공하는 방법 (최적화)
- classInPlace: 이 람다가 호출될 특정 방식을 명시
- InvocationKine.EXACTLY_ONCE: 람다가 정확히 한 번 호출됨. (default는 UNKNOWN이고, AT_MOST_ONCE(최대 한 번), AT_LEAST_ONCE(적어도 한 번)도 있다.)
@Service
class OrderPaymentService(
private val txAdvice: Tx.TxAdvice
) {
fun execute(...): Payment {
Payment payment = savePayment(Payment(...))
// ...
}
private fun savePayment(payment: Payment) = txAdvice.execute {
return paymentRepository.save(payment)
};
}호출은 위와 같이 하는데, 사실 여기까진 Java에 비해서 뭐가 특별한 게 있는 지 모르겠다.
하지만 놀라운 건 이 다음이다.
@Component
class Tx(
_txAdvice: TxAdvice,
) {
init {
txAdvice = _txAdvice
}
companion object {
private lateinit var txAdvice: TxAdvice
fun <T> run(function: () -> T): T { // 전역적으로 쓸 함수
return txAdvice.run(function)
}
}
@Component
class TxAdvice {
@Transactional
fun <T> run(function: () -> T): T { // 실제 Tx가 적용되는 시점
return function.run()
}
}
}- Tx의 run() 함수를 전역적으로 사용하기 위해 companion object 블럭에 삽입
- 하지만 Java 코드 예시를 들던 때와 동일하게, @Transactional은 정적 공간에서 사용할 수 없음
- @Transactional이 선언된 run() 함수를 같은 TxAdvice를 컴포넌트로 등록 (둘은 강한 연관 관계이므로 내부 클래스로 넣어버린 듯)
- txAdvice는 ApplicationContext에 등록이 된 후에나 주입받을 수 있으므로, companion object 내부의 txAdvice는 지연 초기화로 변수 할당. (의존 관계가 Tx → TxAdvice면, Spring이 알아서 TxAdvice 먼저 Bean 등록을 하기 때문에 여긴 별도의 조치가 필요 없다.)
(처음에 코드를 잘못 이해해서 완전히 잘못 썼다가, 다 지우고 다시 썼다. 허허)
초기화 설정 단계에만 초점을 맞추면,
- Spring이 Application Context 초기화 하면서 TxAdvice 빈 등록
- Tx 클래스를 빈으로 등록하고 TxAdvice 주입
- init 블록으로 주입받은 TxAdvice를 companion object의 txAdvice에 할당
- 어디서든 Tx.run { ... }으로 트랜잭션 실행 가능
@Service
class OrderPaymentService(
...
) {
fun execute(...): Payment {
Payment payment = savePayment(Payment(...))
// ...
}
private fun savePayment(payment: Payment) = Tx.execute {
return paymentRepository.save(payment)
};
}이렇게하면, TxAdvice 빈을 주입받지 않고도 전역적으로 사용할 수 있다.
👇 사실 이렇게까지 할 거면 Java로도 흉내를 낼 수 있는 거 아닌가?
@Component
public class Tx {
// 정적 필드로 TxAdvice 참조 저장
private static TxAdvice txAdvice;
// 생성자를 통한 의존성 주입
public Tx(TxAdvice txAdvice) {
Tx.txAdvice = txAdvice;
}
// 전역적으로 접근 가능한 정적 메서드
public static <T> T run(Operation<T> operation) {
return txAdvice.run(operation);
}
// 함수형 인터페이스 정의
@FunctionalInterface
public interface Operation<T> {
T execute();
}
// 내부 클래스로 TxAdvice 정의
@Component
public static class TxAdvice {
@Transactional
public <T> T run(Operation<T> operation) {
return operation.execute();
}
}
}코틀린 코드를 다시 Java로 변환해보았는데, 몇 가지 문제가 있다.
- trailing lambda 문법의 부재로 사용자 측의 코드가 조금 더 장황해진다.
- Java는 Generic과 void를 함께 사용할 수 없기 때문에, void 대신 Void를 반환하고 null을 반환해야 한다.
- Kotlin의 lateinit이나 init 블록같은 초기화 의도를 명확하게 표현할 수가 없다.
- 다만 그렇게 치면, 지연 초기화하는 kotlin 방식도 제작과 사용 관심사 분리가 제대로 이루어지지 않은 좀스런 방법이긴 하다.
계속 이야기하지만 위 내용은 카카오 기술 블로그를 보는 게 훨씬 낫다.
그러면 함수명으로 Tx 모드를 구분하는 아이디어와, @Cacheable을 개선한 방법도 다루고 있다.
4. Improving in Practice
📌 PreAuthorizeAspect
pennyway-was/pennyway-socket/src/main/java/kr/co/pennyway/socket/common/aop/PreAuthorizer.kt at dev · CollaBu/pennyway-was
🪙 Pennyway Spring Boot Web Application Server. Contribute to CollaBu/pennyway-was development by creating an account on GitHub.
github.com
(해당 챕터에서 작성할 모든 코드는 위 링크에서 확인 가능합니다.)
이걸 실전으로 개선해보자.
Introduce에서 언급했듯, 소켓 서버를 최대한 경량화하기 위해 Spring Security 의존성을 주입하지 않았고, 이에 Controller 계층의 인증/인가 AOP 기능을 직접 구현했었다.
이를 위해 AOP 로직을 담은 PreAuthorizeAspect와 표현식 검증을 위한 PreAuthorizeSpELParser 유틸 클래스를 사용했다.
(코드를 모두 첨부하기엔 너무 길기 때문에 github 링크로 대체)
이 코드는 기존 PreAuthorize보다 기능은 부족하지만, 적어도 인증과 빈을 이용한 검증 과정은 완벽히 동작한다.
하지만 평가식 검증을 위해 사용 중인 StandardExpressionContext가 매우 비효율적으로 동작하고 있다고 우려했었다.

- StandardExpressionContext는 생성 비용이 비싸고, 내부 캐싱 기능을 이용하려면 static으로 상태를 관리하는 것이 합리적이다.
- 하지만 동시에 여러 사용자가 평가를 검증하려는 경우, 인증되지 않은 사용자가 통과되거나, 인증되어야 할 사용자가 통과되지 않을 수도 있다.
- 평가식을 통해 principal 객체나 bean 매개변수를 할당하는 과정에서, 다른 thread에서 값을 덮어쓸 수 있기 때문이다.
- 따라서, PreAuthorizeSpELParser는 평가 전에 메서드를 lock하거나, CAS 알고리즘을 아주 잘 활용하여 동시성 문제를 제어해야만 한다.
이런 조치가 필요했던 초기 원인은 StandardExpressionContext 생성 비용때문이긴 하지만,
거슬러 올라가보면 StandardExpressionContext를 만들 수밖에 없던 이유는 Spring AOP 때문이었고,
근본적인 원인은 Java의 annotation과 깊숙하게 연결되어 있다.
위 문제를 kotlin의 tailing lambda를 사용해서 개선해보자.
📌 Authentiate
서버의 인증 로직에 따라 처리 방법이 갈리겠지만, 적어도 내가 구현한 소켓 서버에서는 인증 로직만큼 단순한게 없다.
그 어떠한 외부 의존성도 필요없으며, 순수하게 principal 객체만으로 검증을 할 수 있게 규칙을 설계해두었기 때문이다.
fun <T> authenticate(
principal: Principal,
function: () -> T
): T {
when (isAuthenticated(principal) {
true -> return function.invoke()
false -> throw PreAuthorizeErrorException(PreAuthorizeErrorCode.UNAUTHENTICATED)
}
}
fun isAuthenticated(principal: Principal?): Boolean = ...그래서 위와 같은 함수를 정의하기만 해도, 기존 인증 로직과 완전히 호환되는 로직을 구현할 수 있다.
@Test
fun `인증된 사용자는 정상적으로 진행된다`() {
// given
val (user, userPrincipal) = createValidFixture()
// when
val result = authenticate(principal = userPrincipal) {
"some result"
}
// then
assertEquals("some result", result)
}
@Test
fun `인증되지 않은 사용자는 UNAUTHENTICATED 예외가 발생한다`() {
// given
val (user, userPrincipal) = createExpiredFixture()
// when & then
assertThrows<PreAuthorizeErrorException> {
authenticate(principal = userPrincipal) {}
}.also { e ->
assertEquals(PreAuthorizeErrorCode.UNAUTHENTICATED, e.errorCode)
}
}사용은 위와 같이 할 수 있다.
github에는 반영하는 걸 깜빡했는데, 여기서 더 개선할 수 있는 점이 있다.
isAuthenticated 매개변수가 Principal? 타입으로 null을 허용해놓은 상탠데, 처음에는 authenticate() 함수 하나만을 제공하려 했기 때문이다.
만약, 모든 요청을 허용할 때는 매개변수로 null이 들어올 수 있는 우려가 있었고,
그렇다고 authenticate()를 사용 안 하자니 개발자가 인증 절차를 빼먹은 건지, 혼선을 줄 여지가 있다고 생각했었다.
이럴 때는 그냥 함수 하나를 더 정의해주면 된다.
fun <T> permitAll(function: () -> T): T = function.invoke()그럼 모든 요청을 허용하려는 걸 명시적으로 표현할 수도 있으며, principal 객체가 필요없는 경우도 명확히 할 수 있으므로 null 허용 조건을 없앨 수 있다.
📌 Authorization
인가 과정의 경우엔 문제가 까다로워진다.
- 인가 로직은 동적으로 결정되며, 보통 이를 표현하는 빈을 등록한다.
- 만약 해당 빈이 DB같은 외부 의존성까지 가지고 있다면, 일반적인 Reflection도 아닌 Spring ApplicationContext를 탐색해야 한다.
- AOP는 인가 과정을 수행하기 위해 다음 정보들을 필요로 한다.
- 인가 과정을 수행하기 위한 클래스 정보
- 클래스 내에서 실행할 메서드 정보
- 메서드에 들어갈 파라미터 정보
문제는 저 빈들을 어떻게 동적으로 결정할 거냐는 문제가 골치아프다.
@Controller
class FooController(
private val barService: BarService,
private val authManager: AuthManager // 인가 로직을 수행할 빈을 Controller에 의존성 추가?
) {
@MessageMapping("...")
fun execute(
principal: Principal
) = authorize(principal, authManager.hasPermission(...)) {
...
}
}만약, 위와 같은 형태로 구현하겠다고 한다면 Controller에 온갖 인가 로직을 담은 빈을 주입해주어야 한다.
당연히 이런 행위는 컨트롤러 슬라이스 테스트 코드들이 난데없이 깨지는 결과를 낳는다.
(물론 일반적으로 하나의 Controller에 여러 인가 클래스가 등장할 거 같진 않지만)
이를 해결하려면 결국 순수 함수 형태로 표현하는 것은 불가능하다.
PreAuthorize를 위한 클래스가 필요하며, 해당 클래스는 다음 정보들을 추가로 받아야 한다.
- 빈 탐색을 위한 ApplicationContext를 주입받아야 한다.
- 빈 클래스 정보, 함수 이름, 매개변수 정보를 추가로 받아야 한다.
되도록 Reflection도 사용하고 싶진 않았지만, 내 머리로는 다른 좋은 아이디어가 떠오르질 않았다.
하지만 적어도 위에서 배운 꼼수를 바로 써먹어 볼 수 있는 기회는 생겼다.
@Component
class PreAuthorizer(
_preAuthorizeAdvice: PreAuthorizeAdvice
) {
init {
preAuthorizeAdvice = _preAuthorizeAdvice
}
companion object {
private lateinit var preAuthorizeAdvice: PreAuthorizeAdvice
fun <T, R> authorize(
principal: Principal,
serviceClass: KClass<T>, // 인가 로직을 담은 클래스 정보
methodName: String, // 인가 로직을 수행할 메서드 이름
vararg args: Any?, // 메서드에 전달할 매개변수 정보
function: () -> R
): R where T : Any {
when (isAuthenticated(principal)) {
true -> return preAuthorizeAdvice.run(
serviceClass = serviceClass,
methodName = methodName,
function = function,
args = args
)
false -> throw PreAuthorizeErrorException(PreAuthorizeErrorCode.UNAUTHENTICATED)
}
}
}
@Component
class PreAuthorizeAdvice(
private val applicationContext: ApplicationContext
) {
fun <T, R> run(
serviceClass: KClass<T>,
methodName: String,
vararg args: Any?,
function: () -> R
): R where T : Any {
// 인가 과정
return function.invoke()
}
}
}PreAuthorizeAdvice 안에서 applicationContext를 활용해 빈 정보를 추출하고, 매개변수를 전달하는 로직을 구현하면
기존과 완전히 동일한 기능을 하는 AOP를 구현할 수 있다.
@Test
fun `인가된 사용자는 정상적으로 진행된다`() {
// given
val (user, userPrincipal) = createValidFixture()
// whenb
val result = authorize(MockManager::class, MockManager::execute.name, 1L) {
"some result"
}
// then
assertEquals("some result", result)
}
@Test
fun `인증되었으나, 1번 사용자가 아니라면 FORBIDDEN 예외를 반환한다`() {
// given
val (user, userPrincipal) = createValidFixture()
// when & then
assertThrows<PreAuthorizeErrorException> {
authorize(userPrincipal, MockManager::class, MockManager::hasPermission.name, 2L) {}
}.also { e ->
assertEquals(PreAuthorizeErrorCode.FORBIDDEN, e.errorCode)
}
}사용할 때는 이런 식으로 쓰면 된다.
내부 상세 로직을 설명하는 건 이번 포스트 목적과는 관련이 없는 거 같아서, 고민하다가 빼버렸다.
다만 Any? 타입으로 받은 args에 대해서는 주의해야 할 점이 있어서, 이것만 따로 기록해두고 나머지 상세 로직은 패스.
처음에 ApplicationContext에서 빈을 찾고, 해당 빈에서 메서드 정보를 찾기 위해 다음과 같이 reflection을 수행했었다.
val manager = applicationContext.getBean(serviceClass.java)
val method = serviceClass.java.getDeclaredMethod(
methodName,
*args.map { it?.javaClass ?: Any::class.java }.toTypedArray()
)
그리고 인가 로직을 수행할 가짜 컴포넌트를 추가로 만들어주었는데, kotlin의 Long 타입으로 매개변수를 설정해주었다.
@TestComponent
class MockManager {
fun hasPermission(userId: Long): Boolean {
println("userId: $userId")
return userId == 1L
}
}
그리고 다음과 같이 테스트 케이스를 작성하고 실행하면 당연히 통과할 것이라 기대했다.
@Test
fun `인가된 사용자는 정상적으로 진행된다`() {
// given
val (user, userPrincipal) = createValidFixture()
// whenb
val result = authorize(MockManager::class, MockManager::execute.name, 1L) {
"some result"
}
// then
assertEquals("some result", result)
}
그런데 웬걸, "Caused by: java.lang.NoSuchMethodException: ...MockManager.hasPermission(java.lang.Long)" 예외가 발생하면서 테스트가 실패로 돌아갔다.
처음엔 원인을 전혀 알 수가 없었다. (그야 kotlin이 익숙칠 않으니)
그런데 에러 문구를 보다보니 이상했던 점이, Long 타입이 kotlin이 아닌 java.lang.Long으로 들어가고 있었다.
val method = serviceClass.java.getDeclaredMethod(
methodName,
*args.map { it?.javaClass ?: Any::class.java }.toTypedArray()
)Any로 들어온 args의 타입을 추론하는 과정에서, 값을 javaClass 타입으로 수정하는데, 만약 long 타입이면 java.lang.Long이 되는 식이다.
여기서 나는 멍청하게도 'java랑 kotlin은 완벽히 호환될 텐데..?'라고 중얼거리고 있었는데, kotlin의 컴파일 동작에 대한 이해가 전무했기 때문이었다.
fun hasPermission(userId: Long): Boolean { ... }kotlin에는 래퍼 클래스와 기본 타입에 대한 구분이 없다.
정확히는 kotlin이 소스 코드를 컴파일할 때, 최적의 타입을 스스로 결정하기 때문이다.
hasPermission에서 Long 타입인 userId는 null을 허용하지 않는다.
그렇다고 내부적으로 Long의 메서드를 사용하는 것도 아니다.
그러니 kotlin은 이를 기본 타입으로 치환할 가능성이 높으며, 따라서 hasPermission(java.lang.Long) 타입의 메서드를 찾을 수 없게 되어버린 것이다.
val method = serviceClass.memberFunctions.find { it.name == methodName }
?: throw NoSuchMethodException("$methodName not found in ${serviceClass.qualifiedName}")
val parameterTypes = method.parameters.drop(1).map { it.type.javaType }
val javaMethod = serviceClass.java.getDeclaredMethod(
methodName,
*parameterTypes.map {
when (it) {
is Class<*> -> it // 이미 Class 객체라면 그대로 사용
is ParameterizedType -> it.rawType as Class<*> // 제네릭 타입이라면 raw type 사용
else -> throw IllegalStateException("Unsupported type: $it")
}
}.toTypedArray()
)그러다보니..이런 정신이 아찔해지는 코드가 탄생하게 되었다.
만약 설명이 궁금하다면, 코드 복사에서 GPT에게 물어보는 게 빠를 거 같으니 패스.
📌 Performance
😅 그냥 재미로 해본 것에 불과합니다.
여튼 이렇게 개선한 AOP는 몇 가지 눈에 띄는 개선점을 보인다.
- 함수명을 통해 보다 명확하게 인증/인가 수행 목적을 보인다.
- annotation으로 인한 문자열 의존성에서 벗어나, 보다 type-safe한 AOP로 작용한다.
- 안녕, 날 너무도 화나게 만들었던 SpEL 🖐️
그렇다면 실제 성능은 얼마나 차이날까?
아래는 벤치마킹 테스트를 통해 수행한 결과를 적어놨다.
(벤치마킹이라고 해봐야, 그냥 내 기준대로 한 거라 큰 의미는 없다.)
| Test Scenario | Spring AOP (µs) | Trailing Lambda (µs) | Performance Improvement |
| 간단한 인증 (성공) | 16.04 | 0.42 | 38.x faster |
| 간단한 인가 (성공) | 19.90 | 3.74 | 5.3x faster |
| 복잡한 인가 (성공) | 5.51 | 1.00 | 5.5x faster |
| 인증 + 인가 (성공) | 23.42 | 1.86 | 12.6x faster |
| 간단한 인증 (실패) | 23.49 | 6.22 | 3.8x faster |
| 간단한 인가 (실패) | 33.85 | 11.08 | 3.1x faster |
| 복잡한 인가 (실패) | 20.62 | 6.08 | 3.4x faster |
| 인증 + 인가 (실패) | 30.48 | 7.56 | 4.0x faster |
Warm-up 비용에 대해서도 체크해봤는데, 다음과 같은 결과를 얻었다.
| Batch | AOP | Trailing Lambda | Description |
| 1 | 75.84 | 304.09 | 초기 웜업 비용 |
| 2 | 32.00 | 6.00 | Rapid 최적화 단계 |
| 3 | 30.00 | 2.00 | 거의 안정화 단계 |
| 10 | 30.00 | 4.00 | 최종 안정화 단계 |
사실 이건 Trailing이나 Spring AOP 때문에 성능이 결정됐다고 보기 보단, 순전히 synchronize에 의한 결과가 아닌가 싶다.
근데 뭐, Spring AOP 아니었음 결국 lock 걸거나, CAP 알고리즘 때려박았어야 했는데 그보단 낫지 않은가.
📌 Conclusion
Reflection에서 벗어나지 못 한 것도 아쉽고, 아직 kotlin 자체도 익숙해지는 시기라서 내용이 생각보다 두서없어진 것 같다.
그래서 이번 포스팅 자체는 다 쓰고 보니 스스로 별로 마음에 들진 않은 것 같다. 허허
그래도 전부터 Spring AOP를 안 쓰는 방법을 고민하다가, 마침 좋은 글을 읽게 되어 정리해보았고,
나름 유의미한 지식들을 얻어갈 수 있어서 만족.