💡 제가 iOS 개발자는 아닌지라, 동작은 하지만 완벽한 코드는 아닙니다.
📕 목차
1. Introduction
2. 어디서 state를 관리할 것인가?
3. Refresh Request Throttling
4. 소감
1. Introduction
📌 RTR(Refesh Token Refresh)
JWT를 적용하기 위한 여러 가지 고려 사항들
📕 목차 1. Authentication & Authorization 2. How to control Access Token & Refresh Token 3. RTR(Refresh Token Rotation) 4. How to store Refresh Token in redis? (advanced RTR) 5. Auto Refresh Strategy 1. Authentication & Authorization JWT가 뭔지는
jaeseo0519.tistory.com
현재 우리 서비스는 jwt 인증 방식을 채택하고 있고, 긴 유효 시간을 갖는 RT가 보안 위협을 갖는다고 판단하여 RTR 방식을 채택하고 있다.
RTR(Refresh Token Refresh) 방식이란, 유효한 RT로 AT를 재발급할 때 RT 또한 재발급 대상으로 취급하는 전략이다.
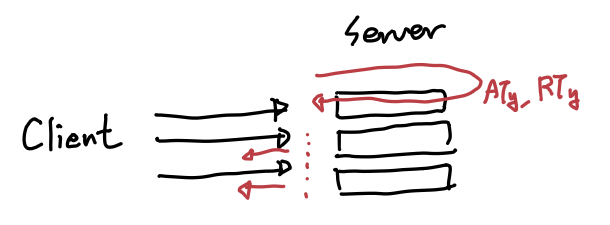
이렇게 되면 유효한 RT가 2개가 생기기 때문에, 서버에서는 현재 사용자가 가지고 있는 RT 상태 정보를 캐싱하여 상태를 관리해야 한다.
예를 들어, 1번 사용자가 RTx로 refresh 요청을 해서 성공했다면, 서버는 새로운 토큰인 ATy, RTy를 발급하고 {1번 사용자: RTy}라는 키-값을 저장한다.
만약 RTx를 탈취해간 공격자가 refresh 요청을 하면, 토큰이 탈취되었다고 판단하여 캐시 정보를 제거하여 강제 로그아웃 처리한다.
이번 포스팅하고는 관련 없지만 여러 플랫폼을 지원할 거라면 RT를 저장할 때, 기기 정보도 함께 담아두어야 한다.
1번 사용자가 여러 기기로 로그인 시도를 하면 죄다 로그아웃 처리 당한다 🤗...
📌 Problem
iOS 팀에서 401 예외가 발생하면 refresh 요청을 보내는 Interceptor 로직을 분명히 구현해두었는데, 간헐적으로 refresh 요청에 실패하는 경우가 발생했다.
func retry(_ request: Request, for _: Session, dueTo _: Error, completion: @escaping (RetryResult) -> Void) {
Log.info("BaseInterceptor - retry()")
if let response = request.task?.response as? HTTPURLResponse {
Log.debug(response.statusCode)
}
// 응답이 401 에러라면
if let response = request.task?.response as? HTTPURLResponse, response.statusCode == 401 {
AuthAlamofire.shared.refresh { result in // refresh 요청
switch result {
case let .success(data): // 요청에 성공했다면
if let responseData = data {
do {
let response = try JSONDecoder().decode(AuthResponseDto.self, from: responseData)
Log.debug(response)
completion(.retry) // 기존 요청 재시도
} catch {
Log.fault("Error parsing response JSON: \(error)")
completion(.doNotRetry)
}
}
case let .failure(error):
if let statusSpecificError = error as? StatusSpecificError {
Log.info("StatusSpecificError occurred: \(statusSpecificError)")
} else {
Log.error("Network request failed: \(error)")
}
completion(.doNotRetry)
}
}
} else {
completion(.doNotRetry)
}
}로직에 큰 문제는 없어보였고, 당연히 iOS팀에서 AT, RT 상태 관리를 잘못했겠거니 싶어서 문제 원인 파악해서 수정해두라고만 이야기를 해두었었다.
그동안 GA4 로그 수집을 위해 서포트를 해주고 있었는데, 뭔가 이상했다.

로그인 뷰에서 refresh 요청 이벤트가 두 번이나 실행되고 있었는데, refresh 자체를 재시도하는 로직은 없었기 때문에 refresh 요청은 단 한 번만 발생했어야만 했다.
그럼에도 두 번이나 발생한 이유는 단순하기 그지없는 이유였는데, 앱을 실행할 때 API가 비동기적으로 2번 호출되고 있었기 때문이다.
📌 N번 비동기 API 호출, N번 refresh 요청
하나의 View를 구성하기 위한 모든 데이터를 단 하나의 응답에 담게 된다면,
Server 입장에선 API가 View에 종속되며, API가 상당히 무거워지므로 요청을 세분화해야 한다.
그럼 Client는 하나의 View를 구성하기 위해 N개의 요청을 호출해야만 하는데, 이 요청들을 동기적으로 처리하면 상당히 비효율적이므로 당연히 비동기적으로 호출하는 것이 일반적이다.
그런데 N개의 요청을 보낼 때, ATx가 만료되어 모두 401 에러를 반환했음을 가정하자.
각 요청은 모두 Interceptor에 의해 RTx로 refresh 요청을 보내게 된다. 무려 N개의 refresh 요청을.
이 요청 중 무엇이 먼저 도달하든 상관없이 결과적으로 강제 로그아웃 처리된다.
a, b, c 요청이 존재한다고 가정하자.
- c 요청이 먼저 도달해서 RTx로 refresh를 하여 ATy, RTy를 재발급 받는다.
- Server는 1번 사용자에게 마지막으로 발급한 RT 값으로 RTy를 캐싱해둔다.
- 띠옹. 그런데 갑자기 a 요청이 RTx refresh를 하려고 했더니, Server가 탈취된 토큰이라 간주하고 1번 사용자를 강제 로그아웃 시켜버린다.
- b 요청은 애초에 존재하지도 않는 RT를 들고 간 꼴이 되므로 더 억울한 상황
이후의 동작이 더 골 때리는데, Server에선 RT의 상태만을 관리하므로 c 응답이 받아간 RTy는 무력화 되었지만 ATy는 그렇지 않다.
c 응답은 Client에게 되돌아가서 성공했음을 알리고 ATy를 저장한 후, 다시 원래 요청을 retry한다.
a와 b 요청은 실패했으므로, 본래 요청을 수행하지 않는다.
그럼 Client는 엉뚱한 현상을 맞이할 수 있는데, c 요청은 성공하고 a, b 요청은 실패하게 된다.
더 기이한 상황은 새로고침을 하면, 다시 정상적으로 a, b, c 요청에 성공하게 될 것이다.
왜냐하면, ATy는 유효한 상태기 때문..
하지만 이 AT는 만료기간이 매우 짧으므로, 사실상 시한부 운명이다.
여기서 심각한 문제는 오류가 뒤늦게 나타나게 되므로, 문제 원인을 파악하기가 매우 까다로워진다는 점이다.
(실제로 서비스에 원인을 알 수 없는 이상 증상이 몇 가지 더 있었는데, Refresh 문제를 해결하니 덩달아 해결된 게 더 있다.)
📌 어떻게 처리해야 하지?
문제 원인은 동일 Client가 전달한 N개의 refresh 요청을 독립적으로 취급하기 때문에 발생한다.
이를 처리하려면 N개의 요청을 하나로 다루기 위한 상태를 어디선가 관리해주어야 하는데, 이론 상 서버와 클라이언트 모두 핸들링할 수 있(긴 하)다.
2. 어디서 state를 관리할 것인가?
📌 Server: Refresh의 멱등성 보장
짧은 시간에 동일한 RT로 refresh 요청이 들어오면, 모두 같은 RT로 반환하는 방법이 있다.
예를 들어, a, b, c 요청(순서대로 서버에 도착했다고 가정)이 RTx로 refresh를 시도하는 경우, a 요청이 accept되어 ATy, RTy를 발급했다고 가정하자.
해당 응답을 캐싱해두었다가, b, c의 refresh 요청이 서버에 도달하면 캐싱해둔 ATy, RTy를 그대로 돌려주면 문제를 해결할 수 있다.
하지만 서버에서 처리하게 되면, 동시성 문제라는 추가 상황을 고려하며, 보안 구멍이 발생하는 리스크를 감수해야 한다.
🟡 동시성 문제
Spring Boot에서 캐싱된 데이터를 바로 응답으로 돌려줄 땐, Controller에 @Cachable를 붙여두면 편하게 처리할 수 있다.
하지만 그러기 위해서는 b, c 요청이 도달하기 전에, 언제나 a 요청에 대한 응답이 캐싱되어 있어야 함을 성립해야 한다.
Controller Layer에서 이걸 다룬다는 건 상당히 버거우므로, Service Layer로 로직을 옮겨야만 한다.
RTx를 기준으로 a, b, c 요청을 동기화 시켜주면 되지 않을까?
- 단일 서버 환경이면 synchronize, 다중 서버 환경이면 분산락으로 Lock
- a 요청이 Redis RTx refresh 이력을 조회 → 없으므로 ATy, RTy 재발급 후 이력 갱신 (timestamp 포함)
- b 요청이 Redis RTx refresh 이력을 조회 → 존재하며, t초 이내의 요청이므로 캐싱 데이터를 응답으로 반환
- c 요청 또한 (3)과 같은 흐름
보안을 위해서라면 어느정도 오버 헤드를 감수하는 것에 동의하는 편이지만, 이건 너무 과하다.
심지어 위 방식은 재생 공격에 취약해지는데, 공격자가 RT를 탈취해서 공격했을 때 어물쩡 같이 통과될 수도 있다.
그렇다고 ttl을 너무 짧게 잡으면, 정상적인 Client의 요청이 거부될 우려 또한 존재한다.
📌 Client: N개의 Refresh 요청을 하나로 묶기
Server에선 이미 사용자별로 유효한 RT 상태를 관리하는 것만으로도 충분히 부담이 된다고 생각한다.
그렇다면 이 문제는 Client 단에서 처리하는 것이 훨씬 우아하지 않을까?
Server는 불특정 다수의 Client를 상대해야 하지만, Client는 오로지 자기 자신과 Server만을 고려하면 된다.
Server는 N개의 요청 중 하나의 Client로 부터 발생함을 알아내기 위해 상당히 번거로운 로직을 처리해야 하지만, Client는 자기 자신의 요청만을 잘 관리하면 그만이다.
여러 개의 refresh 요청이 나가야 하는 경우, 하나의 refresh 요청만을 내보낸다면 위 문제를 아주 쉽게 해결할 수 있다.
3. Refresh Request Throttling
📌 Idea
Refresh Request Throttling이란 용어따윈 없다.
그저 내가 Throttling 기법에서 착안한 방법이라 그렇게 작명을 했을 뿐이고, 엄밀히 따지고 보면 Throttling하고도 동작 방식이 다르다.
핵심 아이디어는 누군가 refresh 요청을 처리하는 중이라면, 나머지 요청은 대기하는 것이다.
이번에도 a, b, c 요청이 모두 401 에러가 발생했고, 모든 요청은 refresh를 호출해야 한다.
하지만 a, b, c 중 하나라도 refresh 요청을 실제로 호출했다면, 나머지 요청은 대기해야 한다.
그리고 refresh 성공 응답이 돌아오면, 대기하던 모든 요청은 key chain에 갱신된 AT, RT가 존재하므로 더 이상 refresh를 호출할 필요없이 모두 성공 처리하면 된다.
이를 위해서 retry 로직은 아래 스텝을 따라야 한다.
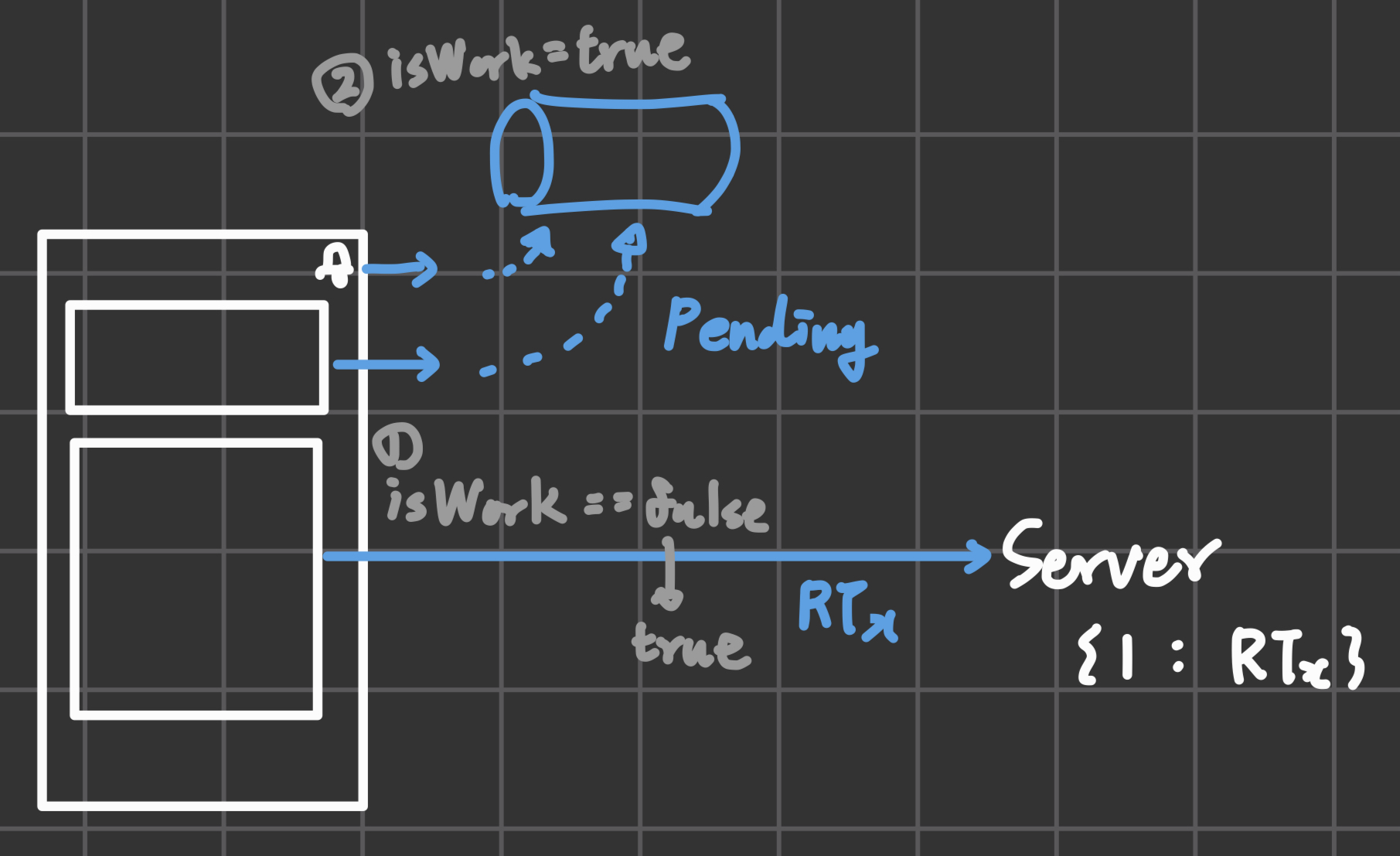
- isWork: 이미 refresh 요청을 처리하고 있는 지 확인한다.
- isWork == true: 요청을 queue에 삽입하고 대기한다.
- isWork == false: isWork를 true로 바꾸고, refresh api를 호출한다.
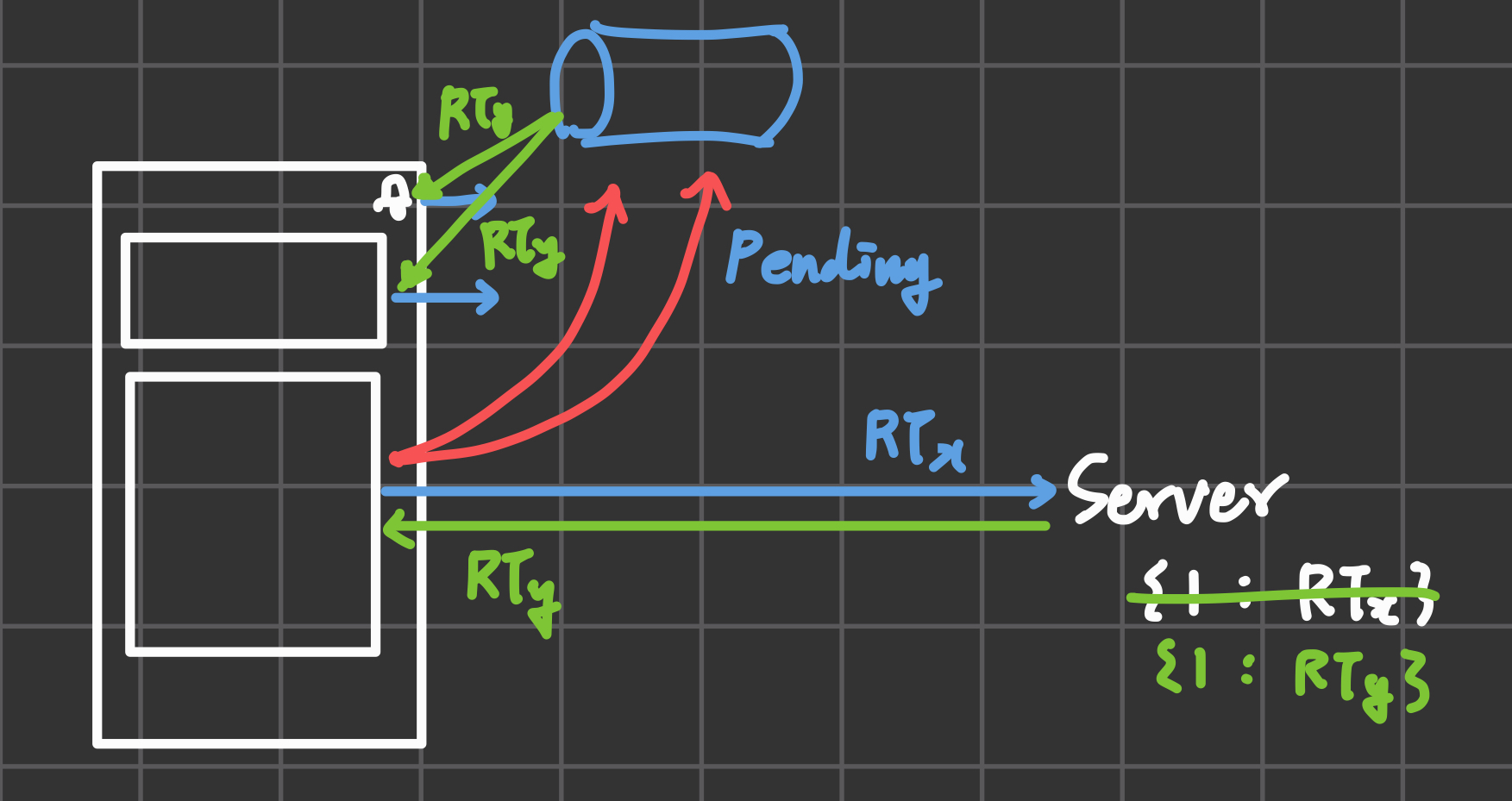
- refresh 응답이 돌아오면 AT/RT를 갱신하고, queue에 있던 모든 요청을 성공 처리한다.
- 깨어난 요청은 refresh 요청을 스킵하고, 기존 요청을 retry한다.
📌 TokenRefreshHandler Specification
우선 비동기적으로 수행되는 Refresh 요청을 하나로 묶어주려면, TokenRefreshHandler는 반드시 static이어야 한다.
이는 Singleton으로 만들어주면 간단하게 해결할 수 있다.
TokenRefreshHandler는 내부적으로 isWork state를 가지고 있어야 하며, 대기 중인 요청을 처리하기 위한 pendingRequest Queue를 가지고 있어야 한다.
그럼 대략적으로 아래와 같은 구조를 가지게 된다.
class TokenRefreshHandler {
static let shared = TokenRefreshHandler() // 싱글턴
private var isRefreshing = false
private var pendingRequests: [(Result<Data?, Error>) -> Void] = [] // refresh 요청을 보내지 않고, 대기할 요청들
private init() {}
func refreshSync(completion: @escaping (Result<Data?, Error>) -> Void) {
if isRefreshing { // 이미 리프레시 중이면 대기열에 추가
pendingRequests.append(completion)
return
}
isWorking = true // refresh 요청을 보내러 가기 전에, 상태를 우선적으로 수정
AuthAlamofire.shared.refresh { [weak self] result in
guard let self = self else { return }
switch result {
case let .success(data): // 성공하면
if let responseData = data {
do {
let response = try JSONDecoder().decode(AuthResponseDto.self, from: responseData)
} catch {
completion(.failure(error))
self.notifyPendingRequests(result: .failure(error))
}
}
completion(.success(data)) // 요청 성공 처리
self.notifyPendingRequests(result: .success(data)) // 대기 중인 요청 성공처리
case .failure(let error):
completion(.failure(error)) // 에러 처리
self.notifyPendingRequests(result: .failure(error)) // 대기 중인 요청 모두 에러
}
self.isRefreshing = false // 나갈 땐 반드시 상태를 되돌려놔야 한다.
}
}
}나는 이걸 이해하는데 좀 걸렸지만, 개발 좀 해본 iOS 개발자라면 이 정도는 껌이겠지..
저기서 completion 안 넣었다가, 정작 refresh api 직접 호출한 애는 retry로 안 넘어가는 사소한 이슈도 있었다. ㅎㅎ
📌 Interceptor retry()
retry()는 더 이상 AuthAlamofire를 직접 호출하면 안 되고, TokenRefreshHandler에게 요청을 위임해야 한다.
기존의 로직이 모두 TokenRefreshHandler로 넘어갔으므로, retry() 에서는 success와 failure의 분기처리만 해주면 된다.
func retry(_ request: Request, for _: Session, dueTo _: Error, completion: @escaping (RetryResult) -> Void) {
if let response = request.task?.response as? HTTPURLResponse {
Log.debug(response.statusCode)
}
if let response = request.task?.response as? HTTPURLResponse, response.statusCode == 401 {
TokenRefreshHandler.shared.refreshSync { result in
switch result {
case .success:
completion(.retry)
case .failure:
completion(.doNotRetry)
}
}
} else {
completion(.doNotRetry)
}
}간단~
📌 예외 케이스의 존재 여부
한 가지 우려스러웠던 상황은 refresh 요청 중에 대기 상태가 되지 않고, refresh 성공 이후 뒤늦게 retry를 시도하는 경우 성공을 보장할 수 있을 지 확신이 서지 않았다.
하지만 iOS팀에서 만들어 놓은 로직을 살펴보니, refresh를 위한 RT 토큰을 key chain에서 불러오는 시점은 AuthAlamofire 내부에서 이루어지고 있었다.
즉, RTx 토큰으로 실패해서 retry()가 실행된다 하더라도, refresh 요청을 보낼 시점엔 RTx 토큰을 정상 참조하게 되므로 문제가 발생하지는 않을 것이라 판단했다.
retry() ~ success 사이까진 isRefreshing 상태로 blocking을 걸고 있으므로, 예외 시나리오에 대한 문제는 현재까지 확인할 수 없었다.
🤔 정~~~~말 재수없는 경우?
쓰다보니 약간 우려스러운 점이 isRefreshing 상태를 판단하는 지점과 isRefreshing을 true로 바꾸는 작업이 원자적(atomic)이지 않기 때문에 문제가 될 수도 있지 않을까 싶다.
Singleton 인스턴스라 괜찮을 거 같긴 한데, iOS에서 멀티 스레드로 요게 진행이 되는 걸까..거기까진 생각을 미처 해보지 못해서 살짝 불안하다.
📌 결과 로그 확인
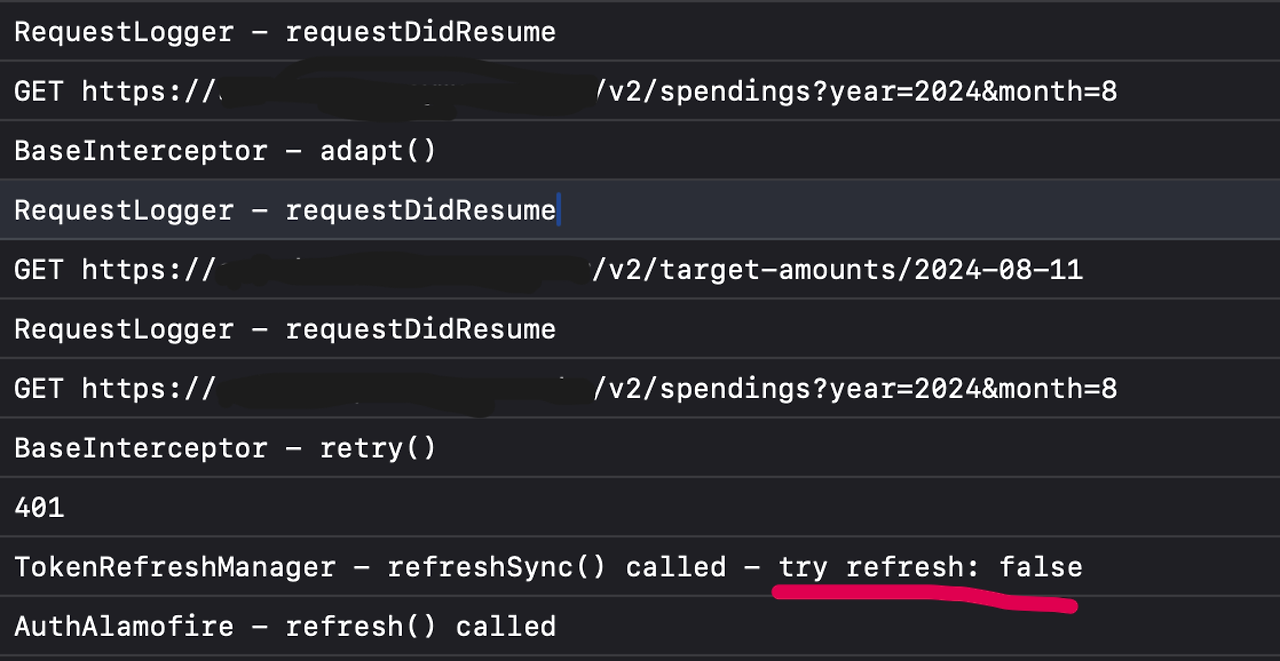
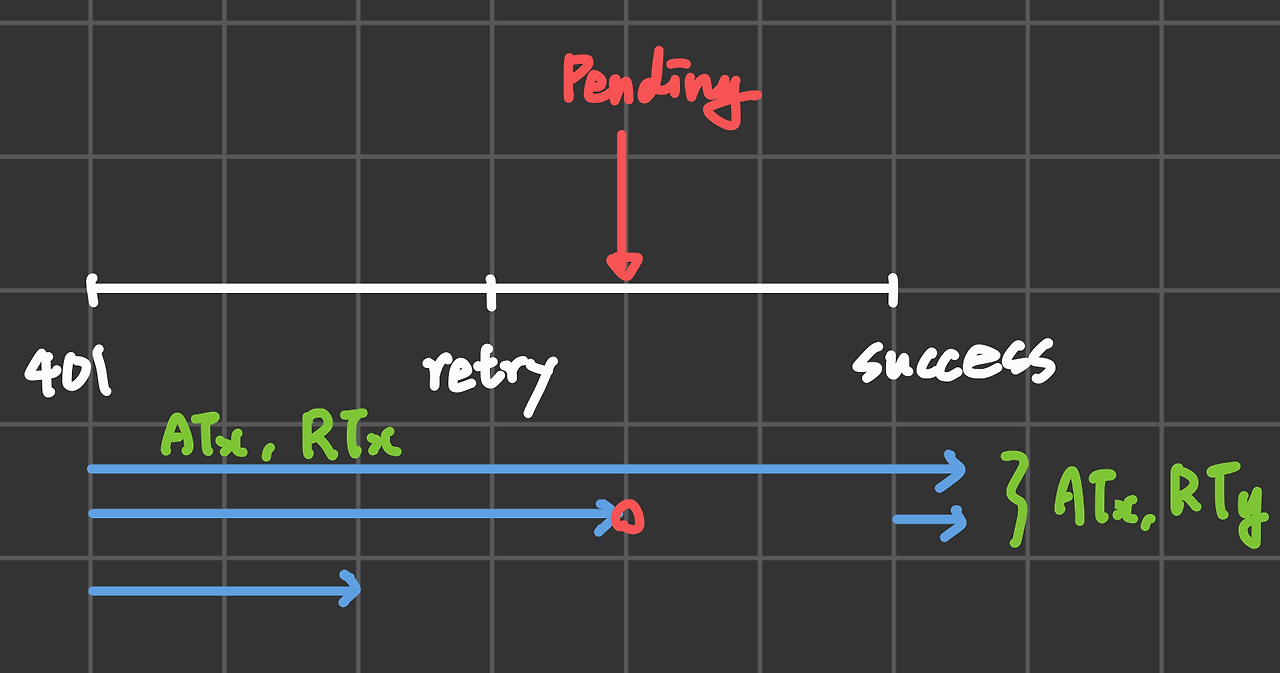
총 4개의 요청이 비동기적으로 호출되는 상황이고, 가장 첫 번째 요청이 실패하여 retry()로 넘어가면,
아직 refresh api를 호출하러 간 요청이 없으므로, isRefreshing의 state는 false 값을 갖는다.
이를 true로 바꾸고 진입.
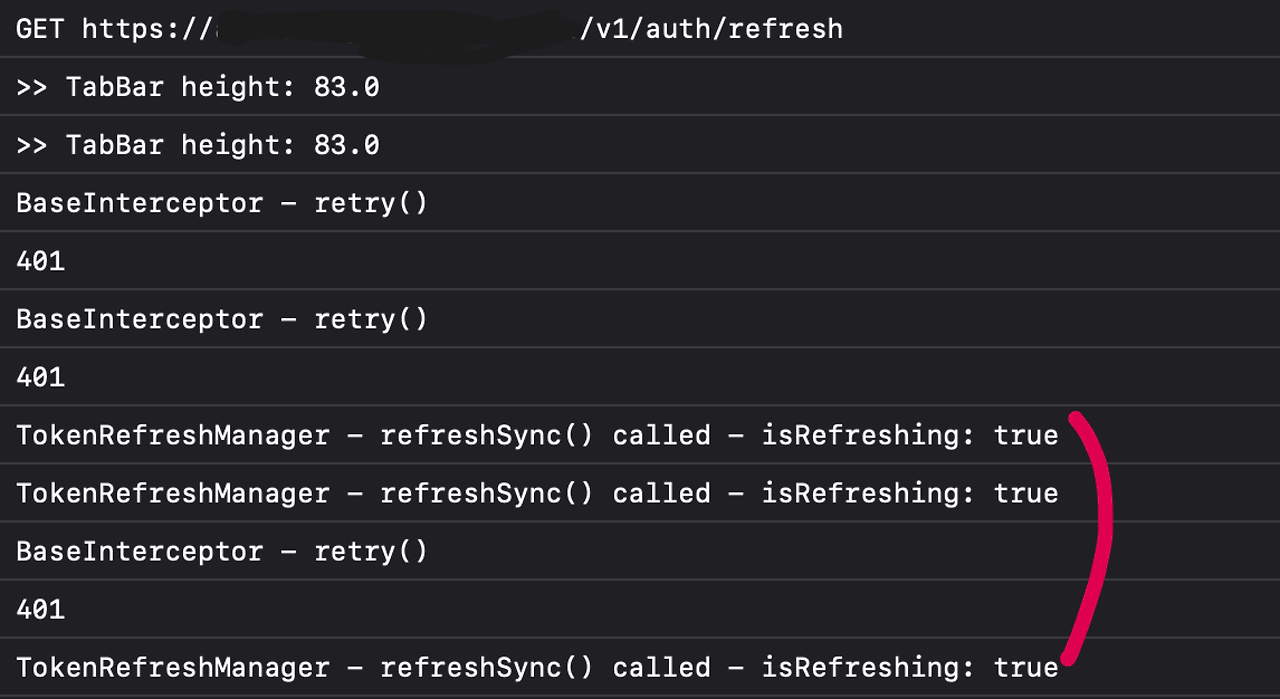
뒤따라 retry()를 호출하는 요청들은 이미 refresh를 하러 간 요청이 있으므로 대기한다.
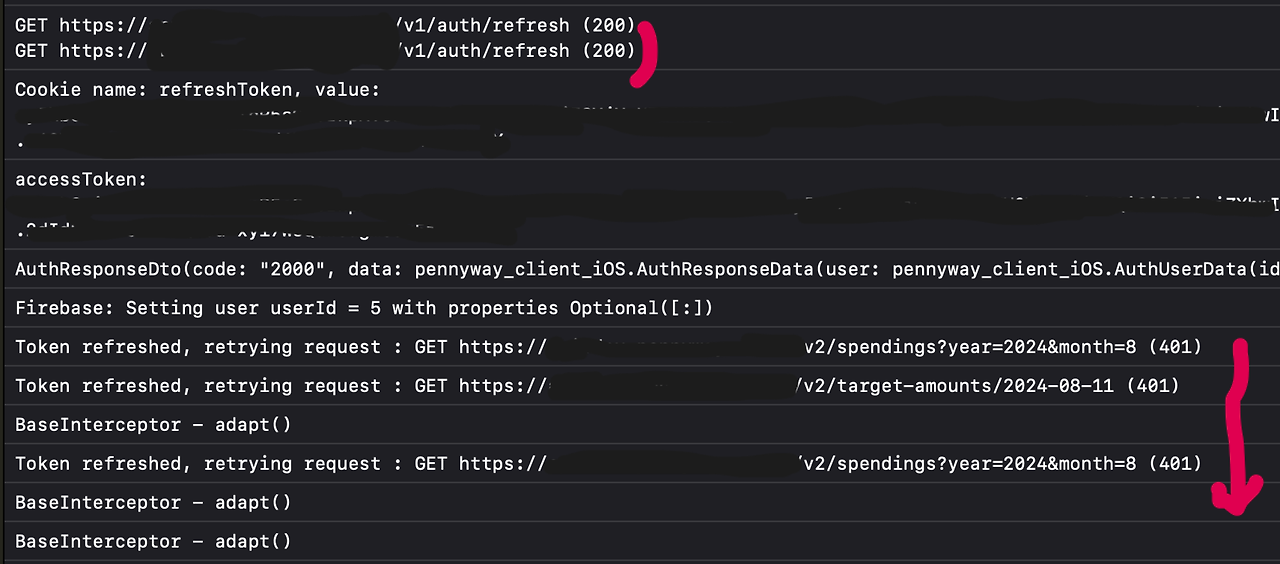
refresh 요청의 응답이 성공으로 돌아오면, key chain의 AT, RT를 갱신하고 모든 요청을 일괄 성공 처리한다.
그러면 정상적으로 모든 요청이 재시도되는 것을 확인할 수 있다.
4. 소감
📌 보안 위협 막으려다가 iOS팀 등이 터져나갔다.
RTR을 적용하면 백엔드만 좀 더 고생하고, 더 높은 보안 수준을 유지할 수 있겠거니 싶었는데 진짜 생각치도 못 한 부분에서 문제가 터졌다.
역시 기술 하나를 도입할 땐 정말 신중해야겠구나...앞으로 API 내부적으로 특수한 로직을 처리했을 때, 되도록 클라이언트에서 알 수 있도록 Swagger 문서를 더 신중하게 작성해야겠구나 싶었다.
근데 적어놨어도 어차피 터질 문제긴 했다만..
예전같았으면 무식하게 서버에서 처리하려고 진땀빼고 있었을 텐데, 우아하고 빠르고 쉽게 client에서 처리하여 해결할 수 있어서 진짜 다행이었다.
역시 지식은 나를 배신하지 않아. 🤟