📕 목차
1. What is Clean Architecture?
2. 3-Layer Architecure
3. Presentation Layer
4. Domain Layer
5. Data Repostiroy Layer
6. Advantage
7. MVC? MVVM?
1. What is Clean Architecture?
📌 Introduction
[Android] Project : DRF API와 MVVM Clean Architecture & Kotlin JWT 토큰 인증
안드로이드 공부를 하고 있는데, 어디서부터 이론 공부를 해야할지 도저히 감이 안 와서 닥치는 대로 기능 구현을 하고 있다. DRF는 이전에 개발해놨던 프로젝트를 앱으로 구현 중인 거라 그대로
jaeseo0519.tistory.com
옛날 옛적(벌써 1년 반이나 지났네..)에 취미로 안드로이드를 공부하던 때 무턱대고 MVVM Clean Architecture를 코드에 반영해본 적이 있었다.
물론 뭔 소린지 하나도 이해하지 못 했고, 겨우 구현한 코드 또한 "깔끔하긴 한데, 그래서 이게 무슨 이점이 있다는 건데?"라는 의문이 들었었다.
단순히 보기 좋으라고 이런 개념까지 도입하면서 사람을 괴롭히려는 걸까?
당연히 그렇지 않다.
하지만 여타 블로그 포스트들을 보면 하나같이 이해할 수가 없는 말로 모르는 개념을 설명해주고 있다.
물론 지금의 나는 충분히 이해할 수 있기에, Clean Architecture의 진정한 의미에 대해서 알기 쉽게 정리해두려 한다.
너무 기초 지식이 부족하면 이해할 수 없겠지만, 그래도 최대한 상세하게..
+ 참고로 난 iOS 개발자가 아니다. 그래서 아래 깃헙을 많이 참고했다.
GitHub - kudoleh/iOS-Clean-Architecture-MVVM: Template iOS app using Clean Architecture and MVVM. Includes DIContainer, FlowCoor
Template iOS app using Clean Architecture and MVVM. Includes DIContainer, FlowCoordinator, DTO, Response Caching and one of the views in SwiftUI - GitHub - kudoleh/iOS-Clean-Architecture-MVVM: Tem...
github.com
📌 Clean Architecture
💡 아키텍처의 목적은 모두 관심사 분리라는 동일한 목표를 갖는다.
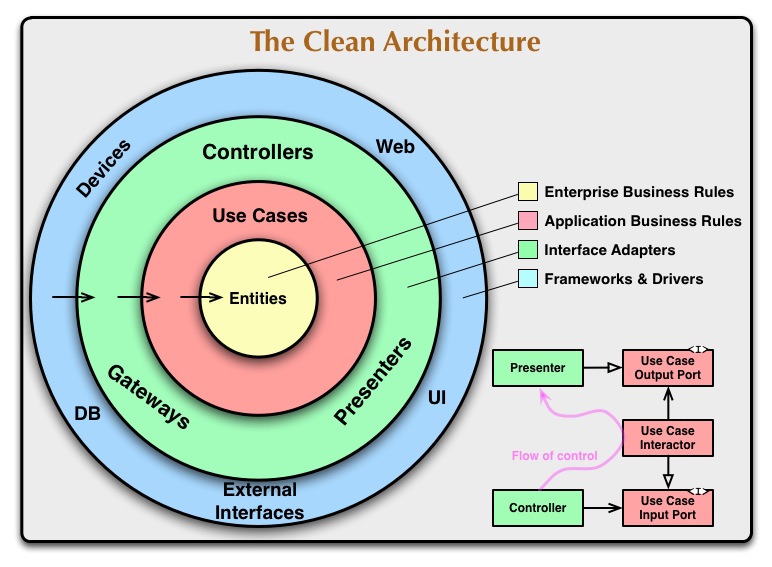
시스템 아키텍처에는 여러 종류가 있다. (위 그림을 보고 황급하게 뒤로가기로 마우스를 옮기는 그대, 진정)
- Hexagonal Architecture (a.k.a Ports and Adapters)
- Onion Architectrue
- Screaming Architecture
- DCI
- BCE
그리고 또 다른 아키텍처 중 하나가 바로 Clean Architecture인데, 서로 차이점이 존재하지만 결국 목적은 한 가지다.
바로 스파게티 코드들을 관심사 별로 분리해 계층 구조를 형성하고, 의존성의 흐름을 제어하여 관심사를 분리하는 것이다.
쉽게 설명한다더니, 바로 씹덕 용어 튀어나왔죠?
✒️ 스파게티 코드, 관심사, 계층 구조, 의존성
아키텍처, 디자인 패턴, 클린 코드와 같은 기본 지식이 없거나, 알더라도 잘못된 이해를 기반으로 작성 혹은, 너무 많은 시간동안 개발되었거나, 다수의 개발자가 참여한 제품은 필연적으로 코드가 지저분해지기 마련이다.
A 클래스에 이미 정의된 변수가 B 클래스에도 정의되어 있다던가, 그 와중에 A가 B를 멤버 변수로 가지고 있는다던가 이런 대환장 파티가 발생하기 시작하면 소스 코드가 복잡하게 얽히기 시작하는데,
각 클래스가 어디에 의존(참조)하는지 화살표를 그려보면 자신만의 스파게티가 완성됨을 확인할 수 있을 것이다.
(혹은 하나의 클래스에서 api 호출부터, 뷰를 그리는 역할까지 모두 그리는 미친 코드가 나온다던가)
이런 스파게티 코드를 다시 정리한다는 것은 매우 힘든 일이다.
설령 하나하나 꼬인 면들을 풀어냈다고 해도, 적절한 기준이 없다면 금새 다시 꼬일 텐데 이걸 어쩐다?
이걸 위해 우린 각 소스 코드의 관심사(역할)를 우선 분리할 필요가 있다.
애플리케이션의 상태를 관리하기 위한 코드인지, 데이터베이스와 연결을 위한 코드인지, 데이터들을 기반으로 View를 그리기 위한 코드들인지 구분을 해야만 한다.
그다음 한 가지 규칙을 걸어둔 것이다.
"View 역할을 하는 코드들은 Controller 역할을 하는 코드들을 의존(참조)할 수 있지만, 역은 허용하지 않는다."
프로그램상으로 불가능한 게 아니라, 그렇게 해야만 한다는 것이다.
이러면 자연스레 View 계층과 Controller 계층이 생기면서, 의존성의 흐름이 생기게 된다.
이해가 안 된다면 정상입니다.
밑에서 이야기 할 내용들을 간략하게 정리해둔 것 뿐이니까..🤗
📌 의존성 규칙

그림이 설명하고자 하는 바는 밑에서 이해하도록 하고, 클린 아키텍처에서 반드시 모든 의존성은 안쪽 원을 향해야 한다는 규칙만이라도 기억하자.
그렇게 해서 얻는 이점이 뭐고, 의존성을 안쪽 원으로 향하게 한다는 건 또 뭔데?
그것도 밑에서 설명. 자질 구레한 설명을 덧붙이지 않은 이유는 저 원칙을 가슴 속에 새기길 바라는 의미다.
📌 장점
- 아키텍처는 소프트웨어 라이브러리에 의존하지 않으므로 프레임 워크 독립적이다.
- 관심사를 분리하면 테스트에 용이하다.
- UI를 변경하기 위해 다른 컴포넌트가 수정될 필요가 없으므로, UI가 독립적이다.
- 데이터베이스를 변경하기 위해 다른 컴포넌트가 수정될 필요가 없으므로, DB 독립적이다.
- 외부 기능으로부터 독립적이다.
사실 여기서 말 하는 장점들은 모두 같은 내용이다.
과연 이게 사실인지는 아래에서 검증해보자.
2. 3-Layer Architecure
📌 변경의 연쇄 효과 (Cascading Changes)
[Clean Architecture] 설계 원칙
📕 목차 1. SOLID 원칙 2. SRP: 단일 책임 원칙 3. OCP: 개방-폐쇄 원칙 4. LSP: 리스코프 치환 원칙 5. ISP: 인터페이스 분리 원칙 6. DIP: 의존성 역전 원칙 1. SOLID 원칙 📌 개요 좋은 SW 시스템은 Clean Code로
jaeseo0519.tistory.com
우선, 의존 관계라는 것은 임의의 클래스가 다른 임의의 클래스를 참조한다고 이해하면 된다.
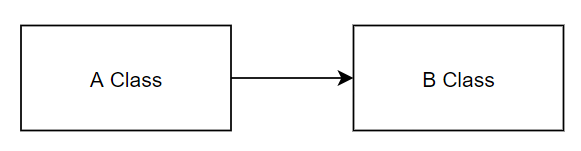
class A {
let b: B
}
class B {
}위와 같이 B 클래스를 참조하는 A 클래스는 "A가 B에 의존하고 있다"라고 말하며,
다이어그램 상으로 의존하는 방향으로 화살표를 이어준다.
(여기서 약한 참조니, 강한 참조니 하는 것은 B를 함수 매개변수로만 받느냐, 멤버 변수로 받느냐 차이)
이러한 의존성 주입은 A가 B의 함수들을 사용하기 쉽게 만들지만, 반대로 말하면 A가 B에 종속된다고 이야기한다.
엥, 이게 뭔 소리임?
class A {
let b: B
func getBValue() -> Int {
b.getValue()
}
}
class B {
private let value = 10
func getValue() { value }
}이번에는 A에서 B의 값을 가져오는 함수인 getBValue()가 추가되었다고 가정하자.
그러다 문득 B 클래스의 이름이 변경될 필요가 있다고 판단하여, B+ 클래스라고 수정해버렸다.
class A {
let b: B+ // 수정이 전파된다!
func getBValue() -> Int {
b.getValue()
}
}
class B+ { // 수정
private let value = 10
func getValue() { value }
}문제는 수정은 B에서 발생했는데, 갑자기 변경이 A에게도 전파되었다.
만약 B를 참조하고 있는 클래스가 많다면, 더욱 많은 파일에 변경이 전파되었을 것이고 git status 명령어를 사용해보면 이름 하나 수정했다고 수십 개의 파일이 수정되었다고 뜰 수도 있다.
물론, 이름 수정이 어렵지 않다는 것은 알고 있다.
여기서 중요한 건 수정이 쉽고 어렵고의 문제가 아니라, 변경 타겟 외의 파일에서도 변경이 발생했다는 점이다.
이번에는 B의 value 만으로는 부족해서 C 클래스의 값을 가져오기로 했다고 치자.
하지만 B, C라고 표현해버리면 아무래도 와닿지 않을 테니, iOS 개발자에게 조금 더 친숙한 ViewModel과 Repository를 사용해봤다.
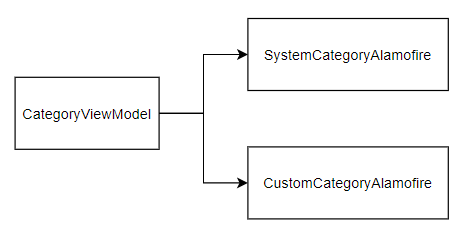
class CategoryViewModel: Obserable {
@Published var category: Category
private let systemCategoryAlamofire: SystemCategoryAlamofire
private let customCategoryAlamofire: CustomCategoryAlamofire
init(...) {...}
/// API로부터 시스템 카테고리 정보를 가져온다.
func getSystemCategory(id: Int) -> Category {
systemCategoryAlamofire.shared.getData(id: Int) { response in
switch resposne {
case .success(data):
if let json = try? JSONSerialization.jsonObject(with: data, options: []) as? [String: Any],
let id = json["id"] as? Int,
let categoryName = json["categoryName"] as? String,
let icon = json["icon"] as? String {
DispatchQueue.main.async {
self?.category = Category(id: id, name: categoryName, icon: icon)
}
}
category.update(id: id, name: categoryName, icon: icon)
case .failure(error):
throw NetworkError.connectionError
}
}
}
/// API로부터 사용자 정의 카테고리 정보를 받아온다.
func getCustomCategory(id: Int) -> Category {
customCategoryAlamofire.shared.getData(id: Int) { response in
switch resposne {
case .success(data):
if let json = try? JSONSerialization.jsonObject(with: data, options: []) as? [String: Any],
let id = json["id"] as? Int,
let categoryName = json["categoryName"] as? String,
let icon = json["icon"] as? String {
DispatchQueue.main.async {
self?.category = Category(id: id, name: categoryName, icon: icon)
}
}
category.update(id: id, name: categoryName, icon: icon)
case .failure(data):
throw NetworkError.connectionError
}
}
}
}카테고리에는 시스템에서 제공해주는 카테고리와 사용자가 정의한 카테고리가 존재함을 가정한다.
따라서 CategoryViewModel은 데이터를 가져올 때, 시스템 카테고리 데이터를 받아올 지, 사용자 정의 카테고리를 받아올 지를 각각 별도의 함수를 정의해야 한다. (DTO는 문제의 심각성을 알려주기 위해, 일부로 적용하지 않았다. DTO 얘기도 밑에서 다룬다.)
아키텍처를 잘 모르는 사람은 아마 위 코드의 문제점을 찾아보라고 하면 "코드의 중복"을 이야기할 수도 있다.
하지만 위 코드는 중복이 아니다.
그저 아주 우연히 중복되었을 뿐인 우발적 중복에 해당한다.
사용자 정의 카테고리는 시스템에서 제공해주는 데이터와는 달리 추가적인 정보(예를 들어, 데이터가 생성된 날짜)들이 포함되어 있을 수 있으며, 현재는 그렇지 않더라도 언제든지 수정될 수 있으므로 합쳐서는 안 된다.
(예를 들어, 시스템 카테고리와 달리 사용자 정의 카테고리 응답은 별도의 데이터가 더 포함되어 있으므로, 둘을 합치면 다른 한 쪽에서는 반드시 에러가 발생한다.)
🤔 CategoryAlamofire 하나만 만들고, 안에서 처리하면 안 되나?
이건 그저 로직을 어디서 처리할 지 위치를 수정했을 뿐 근본적인 해결책을 제시하지 않는다.
CategoryViewModel은 어찌됐든 두 개의 메서드를 제공해주거나, 내부에서 조건문 등을 활용하여 핸들링해야 한다.
아마 이게 대체 왜 문제인지 이해를 못 할 수도 있다.
위의 SystemCategoryAlamofire, CustomCategoryAlamofire처럼 내부 로직을 담고 있는 클래스를 구체 클래스(Concrete class)라고 말한다.
그리고 구체 클래스들을 의존하는 CategoryViewModel과 같은 클래스를 구체 클래스에 의존하는 클래스라고 이야기한다.
이처럼 구체 클래스에 의존하기 시작하면, 종속된 클래스(여기선 CategoryViewModel)들은 구체 클래스들의 변경에 함께 바뀌게 된다.
이는 단순히 이름이 바뀌는 것을 이야기하는 것이 아니다.
- 위에서 언급한 것처럼 추가 데이터가 발생했을 경우 CategoryViewModel 내부의 파싱 로직도 수정되어야 한다.
- 만약, 런칭한 앱이 업데이트 전과 후의 요청해야 하는 API 경로가 다르다면 마찬가지로 조건문을 추가해야 한다.
대체 변경이 어디까지 전파되는지 감이 오나?
서버의 API 스펙의 변경이 클라이언트 앱의 View까지 전파되고 있다. 😂
위 내용이 당췌 뭔 소린지 이해가 안 간다면, 여기서도 하나만 기억하고 가자.
💡 구체적인 클래스에 의존하는 클래스는 구체적인 클래스의 변경에 의해 함께 수정될 수도 있다.
📌 의존성 역전 (Dependency Inversion)
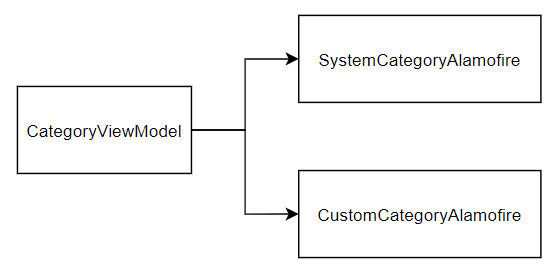
모든 문제의 원흉은 CategoryViewModel이 구체적인 클래스를 의존하고 있기 때문이라고 했는데, 이 문제를 해결하려면 단 하나밖에 없다.
의존성 흐름의 방향을 뒤집어야만 한다. (약 파는 소리 같겠지만, 좀 더 인내심을 가져보세요)
의존성을 뒤집는다는 말은 즉, SystemCategoryAlamofire가 CategoryViewModel을 참조하라는 말이 될 텐데 이게 어떻게 가능하단 말이지?
당연히 그건 불가능하다.
이럴 때 사용하는 것이 바로 인터페이스(swift에서는 protocl)다.
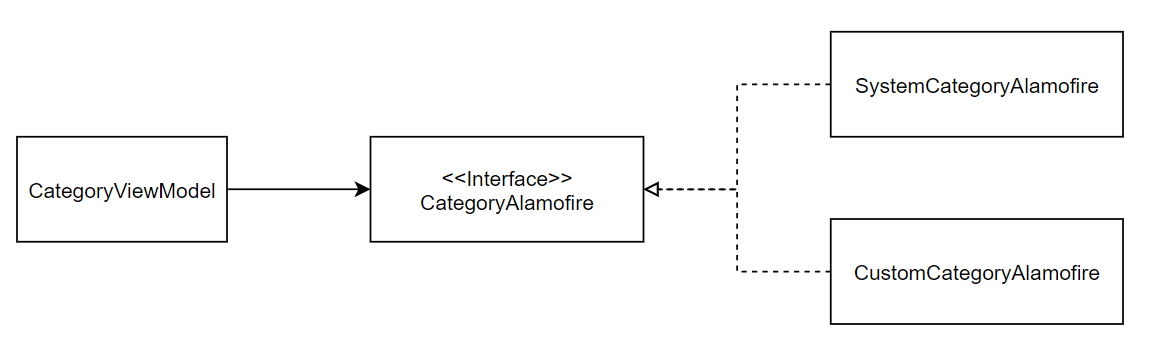
protocol CategoryRepository {
/// API로부터 카테고리 정보를 가져온다.
func getCategory(id: Int) -> Category
}
class SystemCategoryAlamofire: CategoryRepository {
func getCategory(id: Int) -> Category {
...
}
}
class CustomCategoryAlamofire: CategoryRepository {
func getCategory(id: Int) -> Category {
...
}
}
class CategoryViewModel: Obserable {
@Published var category: Category
private let categoryRepository: CategoryRepository
init(...) {...}
func getCategory(id: Int) -> Category {
categoryRepository.getData(id: Int) { response in
switch resposne {
case .success(data):
category.updateFrom(category: category)
case .failure(error):
throw NetworkError.connectionError
}
}
}
}CategoryViewModel은 더 이상 구체 클래스에 의존하지 않는다.
그저 명세서인 protocol만을 의존하며, "getCategory()를 호출하면 카테고리 데이터를 받아온다"는 것만을 알면 된다.
SystemCategoryAlamofire에서 추가 데이터를 파싱하게 되어 수정이 발생해도, 응답을 Category라는 DTO에 담았으므로 수정이 전파되지 않으며, 앱 버전 별로 호출하는 API 경로를 다르게 해도, 심지어 이름을 수정해도(protocol 이름을 변경하지 않는 이상) 더 이상 CategoryViewModel을 수정할 일은 없어진다.
이게 바로 인터페이스를 활용한 다형성의 힘이자, 의존성을 역전시키는 근본적인 이유다.
📌 다시 클린 아키텍처로 돌아와서...
위에서 의존성 역전 얘기를 주구장창한 이유는 이 개념이 베이스로 잡혀있어야 하기 때문이다.
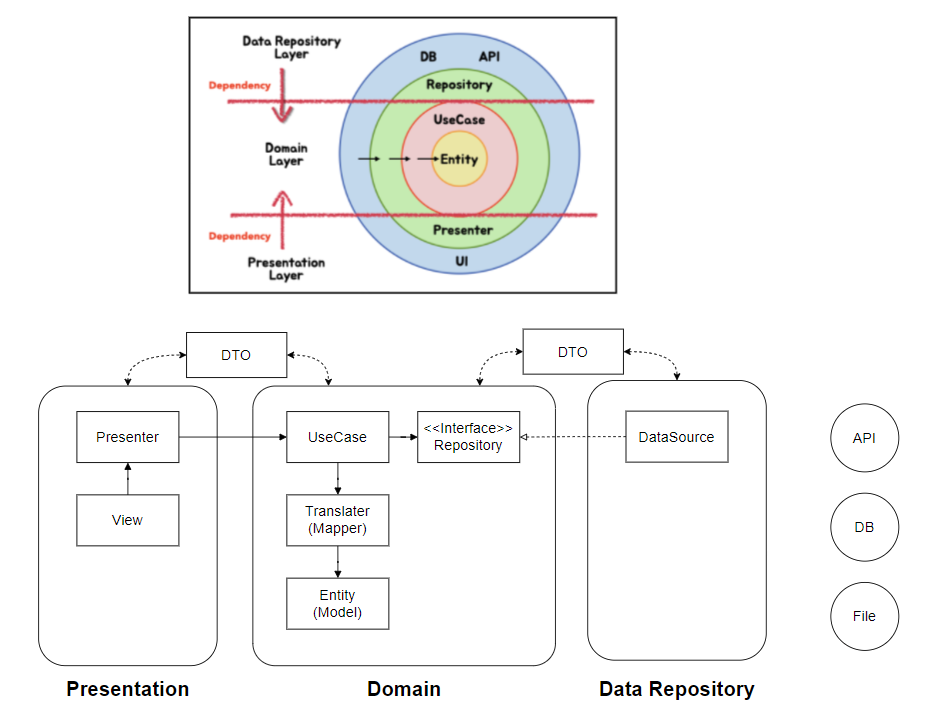
3-Layers
• Presentation Layer (MVVM) = Views + ViewModels
• Domain Layer = Entities + Use Cases + Repository Interfaces
• Data Repository Layer = Repository Implementation + API (Network) + Persistence DB
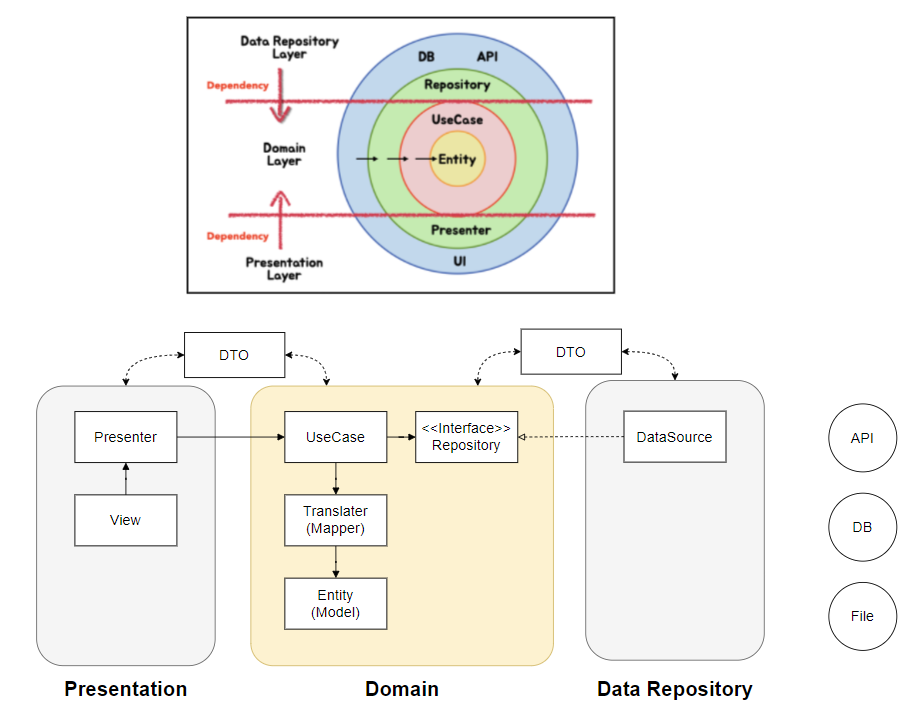
이제는 위 그림을 얼핏 이해할 수 있다.
그림에서 Entity, UseCase, Presenter, UI 등과 같은 개별적인 요소들은 각 관심사 별로 분리한 코드라고 볼 수 있다.
이렇게 분리한 코드들은 다시 비슷한 관심사 별(View와 ViewModel은 다른 역할을 갖지만, 결국 사용자에게 어떤 화면을 보여줄지라는 같은 관심사를 갖는다.)로 묶을 수 있는데,
이렇게 묶은 가장 상위 개념에 해당하는 Layer들은 다음과 같은 규칙을 갖는다.
💡 Present 계층과 Data 계층은 Domain 방향으로 의존성 방향이 지켜져야 한다.
Presentation, Domain, Data Repository 내부를 손으로 살짝 가리면 어떤 그림이 남을까?
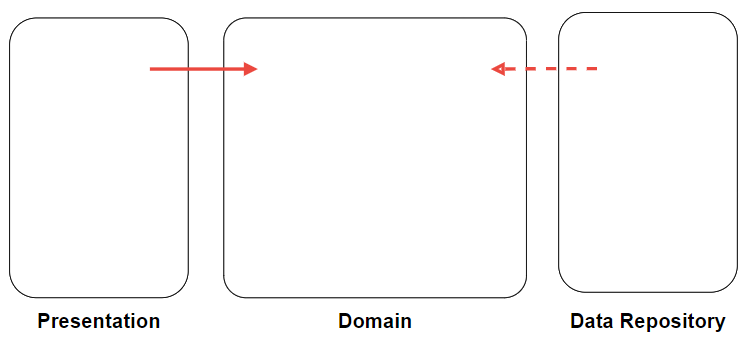
짜잔, Presentation 계층과 Data Repository 계층의 모든 소스 코드는 Domain 방향으로 의존성 흐름이 향한다.
따라서 Domain은 Presentation과 Data Repository 계층의 코드를 알 수 없어야 한다.
Presentation이 Data Repository 계층의 코드를 직접적으로 참조할 수도 없어야 한다.
자자, 여기까지 오면 멘탈이 많이 나갔을 텐데 쉽게 설명해서 이런 의미다. (Entity가 뭔데요? 이런 건 밑에서 이야기 할 예정)
Entity는 UseCase를 몰라야 한다.
그 말은 즉, UseCase를 처리하는 클래스가 Entity에 나타나서는 안 된다는 말이다.
반면, Repository는 UseCase를 의존한다.
따라서 Repository에는 UseCase라는 클래스가 등장한다.
class Entity { ... }
class UseCase {
private var entity: Entity
...
}
class Repository {
private var repository: Repository
...
}뭐, 대충 말만 들으면 이렇게 된다는 건데 갑자기 엄청 쉬워보이지 않나?
하지만 막상 코드를 짜보면 이게 말이 되는 소린가 싶을 것이다.
Entity는 Repository를 호출해서 데이터를 가져와야 하는데, Entity는 Repository의 존재를 몰라야 한다고?
이게 뭔 소리여?
여기선 위에서 알려준 의존성 역전을 위해 protocol을 사용하라는 말이 된다.
이걸 이해했다면 드디어 3-Layer에 대해 공부할 준비 운동을 끝마친 것이다.
우선 여기까지 도착한 스스로에게 박수 👏
📌 DTO(Data Transfer Object, 데이터 전송 객체)
DTO라는 말이 계속 나오는데, 쉽게 말해서 다른 클래스 혹은 계층으로 데이터를 전달할 때 도메인 모델 대신 사용되는 객체를 말한다.
Api로부터 데이터를 받아온 것을 하나하나 파라미터 까주면서 전달하는 건 너무 번거로우니, 보통 여기서 DTO를 직렬/역직렬화 가능하게 만들고 응답 데이터를 DTO로 한 번에 받게 만든다.
/// DTO를 사용하지 않고, API로부터 응답을 받아온다.
func fetchCategories() {
AF.request("https://api.example.com/categories").responseJSON { response in
switch response.result {
case .success(let value):
if let jsonArray = value as? [[String: Any]] {
self.categories = jsonArray.compactMap { json in
guard let id = json["id"] as? Int,
let name = json["name"] as? String,
let icon = json["icon"] as? String else {
return nil
}
return (id, name, icon)
}
}
case .failure(let error):
print("Error: \(error.localizedDescription)")
}
}
}
/// DTO를 사용해, API로부터 응답을 받아온다.
struct CategoryDTO: Codable {
let id: Int
let name: String
let icon: String
}
func fetchCategories(completion: @escaping (Result<[Category], Error>) -> Void) {
AF.request("https://api.example.com/categories").responseDecodable(of: [CategoryDTO].self) { response in
switch response.result {
case .success(let categoryDTO):
completion(.success(categoryDTO))
case .failure(let error):
completion(.failure(error))
}
}
}코드가 깔끔해지기도 하지만, api 응답 스펙이 변경되어도 DTO만 수정하면 되므로 외부 변경이 더 이상 전파되지 않는다.
Entity 얘기를 아직 안 해서 좀 그렇긴 한데, 간단하게 정리하면 상태 관리를 위한 Entity를 DTO 겸으로 쓰게 되면 절대 안 된다.
그러면 DTO는 API의 응답에 딱 맞춘 형태이므로, API에 종속된 상태기 때문이다.
만약 서버 개발자가 두 가지 버전의 API를 내놓거나, 기존 API를 수정하면 Entity로 데이터를 받던 클라이언트는 멘탈이 으스러질 수도 있다.
참고로 DTO에는 한 가지 매우 중요한 원칙이 있는데, 바로 불변성의 원칙이다.
한 번 생성된 객체 DTO는 내부의 값이 절대로 바뀌어서는 안 된다.
절대. 절대. 절대.
따라서 setter 메서드같은 상태 변경 메서드도 존재해선 안 되며, 모든 필드는 let 키워드가 붙어야 한다.
🤔 DTO는 API의 응답을 받아오기 위한 객체다?
클라이언트 측 프레임 워크를 공부하는 사람들의 포스트를 보면 잘못 알려진 DTO의 속성 중 하나가, 마치 DTO는 API의 응답을 받아올 때만 사용한다고 오해하는 것 같다.
클라이언트 개발 짬밥이 적어서 잘 모르겠지만, 일반적으로 API의 응답을 받아올 때만 주로 사용하기 때문이 아닐까 싶은데 이는 정확히 따지자면 틀린 설명이다.
DTO는 애플리케이션의 Domain을 보호하기 위한 Layer다.
(어려운 말로 DTO는 영속 계층(Persistence Layer)까지 도달하는 것을 공통적으로 지양한다.)
Entity의 모든 정보가 Presentation Layer에 노출되면 위험하기 때문에, 정의를 완벽하게 준수한다면 계층 이동 시엔 언제나 DTO를 사용해야 한다.
UseCase는 Domain 영역에 포함되므로, Presentation 계층인 ViewModel로 Entity 정보를 반환할 때는 DTO에 담아서 보내야 한다는 의미다.
근데 이게 또 백엔드랑 클라이언트는 환경이 달라서 이 원칙을 철저하게 준수하게 지키는 게 맞는지는 잘 모르겠다.
3. Presentation Layer
📁 Presentation
⊢ 📁 Ledger // 도메인(인증, 피드, 채팅같은 의미에서) 단위
| ⊢ 📁 Behavior // 도메인 내 재사용 가능한 UI. ex. 인터랙션 패턴(스크롤, 새로고침, 애니메이션 등)
| ⊢ 📁 CategoryList // 하나의 화면을 구성하는 단위
| | ⊢ 📁 View
| | ⨽ 📁 ViewModel
| | ⊢ 🗒️ CategoriesListItemViewModel.swift
| | ⨽ 🗒️ CategoriesListViewModel.swift
| ⊢ 📁 CategoryDetail // 하나의 화면을 구성하는 단위
| | ⊢ 📁 View
| | ⨽ 📁 ViewModel
| ⨽ 📁 Flow // 네비게이션, 화면 전환 로직을 담은 클래스들
⨽ 📁 ...
위에서 다룬 Category 예제를 커스텀 해보도록 하자.
SystemCategory와 CustomCategory를 나누면 필요 이상으로 예제가 복잡해지므로, 이젠 그냥 Category라는 정보만 존재한다고 가정한다.
그래도 무한 스크롤을 적용하는 것까지는 해보자.
📌 View
import SwiftUI
struct CategoriesListView<Model>: View where Model: CategoriesListViewModel {
@StateObject private var viewModel: CategoriesListViewModel
init(viewModel: CategoriesListViewModel) {
_viewModel = StateObject(wrappedValue: viewModel)
}
var body: some View {
NavigationView {
VStack {
if viewModel.items.isEmpty && !viewModel.isLoading {
emptyStateView
} else {
categoryList
}
}
.navigationTitle(viewModel.viewTitle)
.alert(isPresented: .constant(!viewModel.errorMessage.isEmpty)) {
Alert(title: Text(viewModel.errorTitle), message: Text(viewModel.errorMessage))
}
}
}
private var emptyStateView: some View {
Text(viewModel.emptyDataTitle)
.foregroundColor(.gray)
}
private var categoryList: some View {
List {
ForEach(viewModel.items, id: \.name) { item in
CategoryItemView(item: item)
.onAppear {
viewModel.loadNextPageIfNeeded(currentItem: item)
}
}
if viewModel.isLoading {
// 로딩 처리
}
}
}
}
struct CategoryItemView: View {
let item: CategoryListItemViewModel
var body: some View {
HStack {
Image(systemName: item.icon)
.foregroundColor(item.type == .system ? .blue : .green)
Text(item.name)
Spacer()
Text(item.type.rawValue)
.font(.caption)
.foregroundColor(.gray)
}
}
}View의 역할은 사용자에게 정보를 표시하고 사용자 입력을 받는 것이다.
그 어떤 비지니스 로직이나, viewModel의 분기 처리를 해서는 안 된다.
(예를 들어, ViewModel의 상태에 따라 조건문을 수행하여, API를 호출하는 등의 로직을 View에서 해선 안 된다는 말이다.)
물론 어겨도 굴러는 가지만, 테스트를 할 때 문제가 굉장히 복잡해진다.
반드시 각 컴포넌트는 자신의 역할만을 수행하도록 만들어야 한다.
📌 Presenter
import Foundation
import SwiftUI
import Combine
/// View가 VM의 상태 변경을 수행할 수 있는 유일한 함수
protocol CategoryListViewModelInput {
func didLoadNextPage()
func didSelectItem(at index: Int)
}
/// View가 알 수 있는 VM 변수
/// get만 허용하여, 읽기 전용으로 제한
protocol CategoryListViewModelOutput: ObservableObject {
// published
var items: [CategoryListItemViewModel] { get }
var isLoading: Bool { get }
var errorMessage: String { get }
var isEmpty: Bool { get }
// constant
var viewTitle: String { get }
var emptyDataTitle: String { get }
var errorTitle: String { get }
}
// 실제 View가 의존할 ViewModel 타입.
typealias CategoriesListViewModel = CategoryListViewModelInput & CategoryListViewModelOutput
class DefaultCategoriesListViewModel: CategoriesListViewModel {
@Published var items: [CategoryListItemViewModel] = []
@Published var isLoading: Bool = false
@Published var query: String = ""
@Published var errorMessage: String = ""
let viewTitle = NSLocalizedString("Categories", comment: "")
let errorTitle = NSLocalizedString("Error", comment: "")
private let searchCategoriesUseCase: SearchCategoriesUseCase
/// 무한 스크롤 상태
private var currentPageNumber: Int = 0
private var pageSize: Int = 30 // 기본값, 필요에 따라 조정
private var numberOfElements = 0
privaet var hasNext: Bool = true
private var slices: [CategorySlice] = []
private var cancellables: Set<AnyCancellable> = []
init(searchCategoriesUseCase: SearchCategoriesUseCase) {
self.searchCategoriesUseCase = searchCategoriesUseCase // UseCase 의존성 주입
}
/// View가 다음 페이지가 필요하여 호출할 때 실행한다.
/// 단, VM이 가지고 있는 마지막 item과 View가 전달한 현재 item 정보가 일치해야 하며,
/// hasNext가 true고 로딩 상태가 아닌 경우(이미 요청을 보내고 있을 수도 있으므로) 실행된다.
///
/// - Parameter: item: View에서 마지막으로 표시한 Category 정보
private func loadNextPageIfNeeded(currentItem item: CategoryListItemViewModel) {
guard let lastItem = items.last, lastItem == item, hasNext, !isLoading else { return }
load(categoryQuery: CategoryQuery(query: query), .fullScreen)
}
/// UseCase를 실행하여 데이터 요청
private func load(categoryQuery: CategoryQuery, loading: CategoryListViewModelLoading) {
isLoading = true // 데이터 불러오는 동안, 로딩 상태 ON
searchCategoriesUseCase.execute(
requestValue: .init(query: categoryQuery, page: currentPageNumber + 1)
cached: { [weak self] page in // 성공 응답을 캐싱할 거라면 필요.
self?.mainQueue.async {
self?.appendPage(page)
}
},
completion: { [weak self] result in
self?.mainQueue.async {
switch result {
case .success(let page):
self?.appendPage(page) // 성공하면 페이지 정보 갱신
case .failure(let error):
self?.handle(error: error) // 실패하면 Toast, Alter 등으로 실패 알림
}
self?.loading.value = .none // 성공/실패 여부 상관 없이, 끝나면 로딩 종료
}
})
}
/// 수신한 데이터를 VM 상태정보에 갱신하는 함수
private func appendPage(_ categorySlice: CategorySlice) {
// 무한 스크롤 응답 상태 갱신
currentPageNumber = response.currentPageNumber
pageSize = response.pageSize
numberOfElements = response.numberOfElements
hasNext = response.hasNext
// VM 내부 Slice 상태 정보 갱신
slices = slices.filter { $0.page != categorySlice.page } + [categorySlice]
items = slices.categories.map(CategoryListItemViewModel.init)
}
/// 에러 핸들링
private func handle(error: Error) {
errorMessage = error.isInternetConnectionError ?
NSLocalizedString("No internet connection", comment: "") :
NSLocalizedString("Failed loading categories", comment: "")
}
/// 페이지를 다시 그림 (여기선 필요 없는데, 만약 검색 기능 만들 거라면 필요함.)
private func update(movieQuery: MovieQuery) {
resetPages()
load(categoryQuery: CategoryQuery(query: ""))
}
/// 무한 스크롤 정보 초기화
private func resetPages() {
currentPageNumber = 0
numberOfElements =0
slices.removeAll()
items.removeAll()
}
}
extension DefaultCategoriesListViewModel {
func didLoadNextPage() {
guard hasNext, !isLoading else { return }
load(categoryQuery: CategoryQuery(query: query))
}
// 여기서 선택된 카테고리에 대한 처리를 수행
// 상세 화면으로 이동하는 로직을 여기서 구현할 수 있음.
// 혹은 뷰 이동을 하지 않고, update 함수를 실행할 수도 있음.
func didSelectItem(at index: Int) {
guard index < items.count else { return }
let selectedCategory = items[index]
print("Selected category: \(selectedCategory.name)")
// update(...)
}
}
// Category에서 필요한 정보만을 선택적으로 저장.
// 오직 Category Entity에서 추출한 정보만을 관리한다.
struct CategoryListItemViewModel: Equatable {
let name: String
let icon: String
let type: Type
}
extension CategoryListItemViewModel {
init(category: Category) {
self.name = category.name ?? ""
self.icon = category.icon ?? ""
self.type = category.type ?? Type.system
}
}ViewModel은 View와 Domain Layer 사이에서 중재자 역할을 수행한다.
UseCase로부터 데이터를 받아서 View에 적합한 형태로 가공한다.
만약 서버로부터 "2024-08-27T09:00:00"이라는 날짜 정보를 받아왔다고 하자.
이걸 View에서 파싱하는 게 아니고, ViewModel 내에서 파싱해야 한다.
다시 이야기하지만, View는 그저 state를 참조하여 그림을 그릴 뿐이다.
✒️ 데이터 가공 ≠ 비지니스 로직
ViewModel에서 비지니스 로직을 처리해선 안 된다고 이야기를 해도, 어디까지가 비지니스 로직 처리고, 어디까지가 데이터 가공인지부터 모호하다.
쇼핑 앱의 상품 목록 기능을 구현한다고 생각해보자.
비지니스 로직은 "무엇을 할 것인가"를 다룬다. (데이터 처리, 계산, 필터링 등)
즉, 앱의 핵심 기능과 규칙을 정의하고 제어하는 로직을 정의한다.
사용자의 선호도에 따라 상품을 정렬하거나, 할인율을 꼐산하고, 재고가 있는 상품만 필터링하는 등의 작업이 수행될 수 있다.
데이터 가공은 "어떻게 보여줄 것인가"에 더 관심이 많다. (표시 형식 변환, 필요한 정보만 선택)
비지니스 로직을 통해서 받은 데이터가 달러 단위일 때, 이를 현지 통화 형식으로 변환하거나
날짜를 사용자 친화적인 형식으로 수정한다거나, 화면에 표시할 정보만 선택적으로 객체를 생성하는 로직이 포함된다.
진짜 뭔 소린지 모르겠다면, 일단 개발을 계속 진행해보면 된다.
이건 테스트 케이스 작성해보고, 머리도 몇 번 깨져보기 전까진 절대 이해할 수 없다.
4. Domain Layer
📁 Domain
⊢ 📁 Entities
| ⊢ 🗒️ Category.swift
| ⨽ 🗒️ CategoryPage.swift
⊢ 📁 Interfaces/Repositories
| ⊢ 🗒️ CategoriesQueriesRepository.swift
| ⨽ 🗒️ CategoriesRepository.swift
⨽ 📁 UseCase
⊢ 🗒️ CategoriesFetchRecentQueriesUseCase.swift
⨽ 🗒️ CategoriesSearchUseCase.swift
여기서 폴더 구조를 참 많이 고민했는데, 백엔드에선 보통 Domains 하위 폴더에 바로 Category 같은 폴더를 만들고
각 도메인 별로 또 Domain, Service 같은 폴더를 적는 걸 선호한다.
왜냐면 서버 측 애플리케이션에선 도메인 계층을 데이터 관점으로 바라보기 때문에, 이렇게 함으로써 훨씬 관리가 용이해지기 때문이다.
하지만 클라이언트 측 애플리케이션에선 위의 구조를 많이 채택하던데, 서버랑 달리 도메인에 강하게 종속되는 게 올바르지 않기 때문일지도 모르겠다.
📌 UseCase
/// API로부터 데이터를 호출한다.
/// 응답이 성공하면, 데이터를 캐싱한다.
protocol CategoriesSearchUseCase {
func execute(
requestValue: CategoriesSearchUseCaseRequestValue,
cached: @escaping (CategoryPage) -> Void,
completion: @escaping (Result<CategoryPage, Error>) -> Void
) -> Cancellable?
}
class DefaultCategoriesSearchUseCase: CategoriesSearchUseCase {
private let categoryRepository: CategoryRepository
private let categoryQueriesRepository: CategoryQueriesRepository
init(
categoryRepository: CategoryRepository
categoryQueriesRepository: CategoryQueriesRepository
) {
self.categoryRepository = categoryRepository
self.categoryQueriesRepository = categoryQueriesRepository
}
func execute(
requestValue: CategoriesSearchUseCaseRequestValue,
cached: @escaping (CategoryPage) -> Void, // 이미 API 응답 정보가 있으면, 캐싱 정보를 가져오기 위함.
completion: @escaping (Result<CategoryPage, Error>) -> Void
) -> Cancellable? {
return categoryRepository.fetchCategoryList(
query: requestValue.query,
page: reuqestValue.page,
cached: cached,
completion: { result in
if case .success = result { // 성공적인 검색 후 쿼리 저장 (캐싱)
self.categoryQueriesRepository.saveRecentQuery(query: requestValue.query) {_ in}
}
completion(result)
}
)
}
}
struct CategoriesSearchUseCaseRequestValue {
let query: CategoryQuery
let page: Int
}/// 데이터를 Core 혹은 UserDefauls에서 불러온다.
protocol FetchRecentQueriesUseCase {
@discardableResult
func execute() -> Cancellable?
}
final class CategoryFetchRecentQueriesUseCase: FetchRecentQueriesUseCase {
struct RequestValue {
let maxCount: Int
}
typealias ResultValue = (Result<[CategoryQuery], Error>)
private let requestValue: RequestValue
private let completion: (ResultValue) -> Void
private let categoriesQueriesRepository: CategoriesQueriesRepository
init(
requestValue: RequestValue,
completion: @escaping (ResultValue) -> Void,
categoriesQueriesRepository: CategoriesQueriesRepository
) {
self.requestValue = requestValue
self.completion = completion
self.categoriesQueriesRepository = moviesQueriesRepository
}
func execute() -> Cancellable? {
categoriesQueriesRepository.fetchRecentsQueries(
maxCount: requestValue.maxCount,
completion: completion
)
return nil
}
}(여기서 CategoryRepository는 Domain 영역 내의 protocol이며, Repository Data Layer에서 구현한다.)
비지니스 로직과 규칙을 포함하는 핵심 계층으로 Repository로 데이터를 가져온 후, 데이터 처리, 계산 등을 수행하는 역할을 갖는다.
비지니스 로직이 단순하면 진짜 하는 일이 없다.
그렇다고 생략하진 말자.
보통 하나의 뷰를 그리기 위해 데이터를 API로부터 이미 불러왔다면, 해당 데이터는 캐싱을 해둔다.
단순한 데이터라면 UserDefaults, 보안이 중요하다면 KeyChain, 보다 상세하게 데이터를 관리하고 싶다면 CoreData를 활용할 것이다.
(네트워크 비용은 상당히 비싸다. 그리고 매번 똑같은 화면 그릴 때마다 데이터 요청하면 서버가 많이 아파한다.)
그래서 View의 LifeCycle 중, 가장 처음 View를 그릴 때는 API를 호출하고, 응답을 캐싱해주기 위한 CategoryRepository가 존재하는 거고, 단순히 똑같은 뷰를 새로고침하는 등의 단계에선 캐싱된 정보를 반환하는 CategoryQueriesRepository가 존재한다.
만약, 이 캐싱 로직이 너무 어렵다면 과감히 버려도 무방하다. 나중에 개선해도 되는 부분이다.
UseCase도 파사드 패턴으로 분리하면 매우 편리한데, 이러면 처음 공부하는 사람들의 뚝배기가 아작이 날 것 같으니까 패스.
궁금하다면 내가 예전에 작성한 포스트를 읽어보면 된다.
[Spring Boot] Service Layer 분리에 대하여
1. As-is. Service 계층의 순환 참조 Spring을 가장 처음 배우면, Web Application 5계층에 대해서 배우게 된다. 그리고 User라는 Domain에 대해 코드를 작성하면 아래 클래스들을 작성하고 시작한다. UserControlle
jaeseo0519.tistory.com
[Spring Boot] Service Layer 분리에 대하여 (2)
📕 목차1. 개요2. 여러 개의 UseCase3. 단일 UseCase4. 파사드 패턴을 더 준수해보기 1. 개요 📌 배경 [Spring Boot] Service Layer 분리에 대하여1. As-is. Service 계층의 순환 참조 Spring을 가장 처음 배우면, Web
jaeseo0519.tistory.com
📌 Repository
/// API로부터 Category 정보를 조회한다.
protocol CategoriesRepository {
@discardableResult
func fetchCategoriesList(
query: CategoryQuery,
page: Int,
cached: @escaping (CategoriesPage) -> Void,
completion: @escaping (Result<CategoriesPage, Error>) -> Void
) -> Cancellable? // 네트워크 요청은 느려서, 도중에 취소할 수도 있음.
}/// UserDefaults 혹은 Core로부터 캐싱된 데이터를 조회한다.
protocol CategoriesQueriesRepository {
/// 최근 조회한 데이터를 가져온다.
func fetchRecentsQueries(
maxCount: Int,
completion: @escaping (Result<[CategoryQuery], Error>) -> Void
)
/// 최근 조회한 데이터를 저장(캐싱)한다.
func saveRecentQuery(
query: MovieQuery,
completion: @escaping (Result<CategoryQuery, Error>) -> Void
) // 로컬 데이터 조회는 빠르므로, 도중에 취소하는 기능이 필요 없음.
}만약 CategorySearchUseCase가 구체 클래스 Repository를 참조하고 있다면, 의존성의 흐름이 Domain → Repository Data로 형성된다.
이는 원칙에 위배되므로, 위에서 배운 의존성 뒤집기 스킬을 시전하면 된다.
참고로 protocol은 Domain 폴더 하위에 위치해야 한다.
Data 폴터 하위에 넣어버리면, 의존성 흐름은 분명 역전시켰지만, Domain → Repository Data로 폴더 단위의 흐름은 유지되어 버린다.
📌 Entity와 Translater
struct Category: Equatable, Identifiable {
typealias Identifier = Int
enum Type {
case system
case custom
}
let id: Identifier
let name: String?
let icon: String?
let type: Type?
func isValid() -> Bool {
return !name.isEmpty && id > 0
}
}
struct CategoryPage: Equatable {
let currentPageNumber: Int
let pageSize: Int
let numberOfElements: Int
let hasNext: Int
let categories: [Category]
}struct CategoryQuery: Equatable {
let query: String
}Entity는 핵심 비지니스 객체를 나타내며, 서버에서 받은 데이터를 앱 애플리케이션 내부에서 일관되게 표현하고 조작하기 위해 사용한다.
isValid 처럼 함수를 포함할 수도 있고, 그저 데이터 구조만을 포함하는 집합일 수도 있다.
뭐든 상관없다. 그저 엔터프라이즈의 여러 애플리케이션에서 사용될 수만 있으면 된다.
혹시나 아직도 이해 못 한 사람들을 위해, 왜 API로부터 받아온 DTO를 그대로 사용하면 안 되는 지 다시 한 번 살펴보자.
DTO는 API 스펙에 따라 언제든지 변경될 수 있다.
따라서, DTO를 그대로 state로 사용하는 것은 클라이언트 입장에선 상당히 곤란해질 수 있다.
DTO가 변경되어도, 클라이언트가 관리하는 state에는 영향을 주어서는 안 된다.
Domain을 애플리케이션 계층 내에서 가장 보호받아야 하고, 외부의 변화에 영향을 받아선 안 되는 성역같은 곳이다.
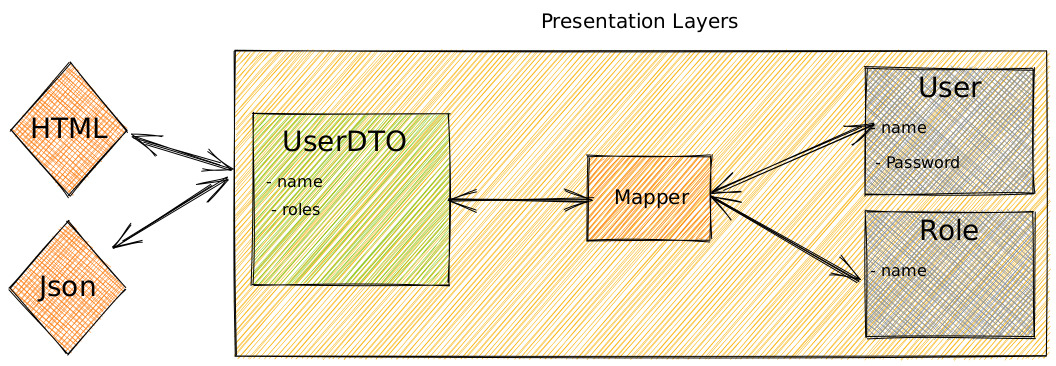
📌 Translator
struct CategoryTranslator {
static func translate(dto: CategoryDTO) -> Category {
return Category(id: dto.id, name: dto.name, icon: dto.icon)
}
}Translator(Mapper)는 DTO를 Entity로 변환하거나, Entity를 DTO로 변환시킬 때 사용한다.
그런데 Mapper가 꼭 필요할까?
struct CategoryDTO: Codable {
let id: Int
let name: String
let price: Double
func toEntity() -> Category {
Category(id: id, name: name, price: price)
}
}DTO를 Entity로 변환시킬 때 자주 사용하는 기법이다.
일반적으로 Translator가 없어도, 위와 같이 간단하게 처리할 수 있는 경우가 대부분이라 굳이 클래스 수만 늘리는 행위를 굳이 할 필요가 있나 싶긴 하지만, Entity로 변환하는 작업이 복잡해질 수록 귀찮아진다.
또한 임의의 Entity로 DTO를 변환시키기 위한 로직은 일반적으로 재사용되는 경우가 많으며, 애초에 Entity로 변환하는 것은 DTO의 책임이 아니므로 Translator라는 클래스에게 책임을 위임하는 것이 깔끔하다.
하지만 나는 정말 단순한 경우엔 그냥 toEntity() 같은 메서드 쓰는 걸 선호하는 편이긴 하다.
✒️ Translator를 왜 Domain 폴더 하위에 넣지 않았을까?
그림에선 Translator가 Domain 영역에 존재한다.
하지만 이렇게 되면 한 가지 문제가 생기는데, Domain 영역이 Api 호출 응답으로부터 받은 DTO의 존재를 알아야 한다. (쉽게 말해, UseCase 로직에 CategoryDTO가 등장한다.)
API 응답 스펙에 맞춘 CategoryDTO를 Domain 폴더에 넣는 것은 외부의 영향이 Domain 영역으로 전파되는 꼴이니, Data 폴더의 하위에 넣을 수 밖에 없다.
하지만 그럼 Data 폴더의 DTO가 UseCase에 등장하므로, 의존성의 방향이 Domain → Data로 향한다.
이를 해결하기 위한, 두 가지 방법이 존재한다.
하나는 Data Layer에서 Domain Layer에서 DTO를 넘길 때, 한 번 더 변환시키는 방법이다.
Domain 영역과 Data 영역 모두 DTO를 정의하고, 넘기기 전에 변환하는 방법이다.
이는 중복 DTO가 너무 많이 생길 수 있다는 문제가 있다.
보다 간단하게 해결하는 방법은 Entity로 변환하는 Translator를 아예 Data 영역에 넣어버리는 것이다.
그럼 UseCase가 받는 것은 언제나 Translator에 의해 변환된 Entity 객체일 것이고, 여전히 Data가 Domain에 의존하기만 하는 상태이므로 원칙을 준수할 수 있다.
5. Data Repostiroy Layer
📁 Data
⊢ 📁 Network // 외부 API 등을 호출하여 데이터 수신
| ⊢ 📁 DataMapping // API 요청/응답을 위한 DTO
| | ⊢ 🗒️ CategoriesRequestDTO+Mapping.swift
| | ⨽ 🗒️ CategoriesReponseDTO+Mapping.swift
| ⨽ 🗒️ CategoryEndpoints.swift // Endpoint 클래스를 반환하는 상세 Endpoint 정보 정의
⊢ 📁 PersistentStorages // UserDefault, Core 등 캐시로부터 데이터 수신
| ⊢ 📁 CoreDataStorage
| | ⨽ 🗒️ CoreDataStorage.swift
| ⊢ 📁 CategoriesQueriesStorage
| | ⊢ 📁 CoreDataStorage
| | ⊢ 📁 UserDefaultsStorage
| | ⨽ 🗒️ CategoriesQueriesStorage.swift
| ⨽ 📁 CategoriesResponseStorage
| ⊢ 📁 EntityMapping
| ⊢ 🗒️ CoreDataCategoriesResponseStorage.swift
| ⨽ 🗒️ CategoriesResponseStorage.swift
⨽ 📁 Repositories // Data stream 로직
⊢ 🗒️ DefaultCategoriesRepository.swift // API 호출로 데이터를 받는 Repository
⨽ 🗒️ DefaultCategoriesQueriesRepository.swift // 캐시에서 데이터를 받는 Repository
📁 Infrastructure/Network
⊢ 🗒️ DataTransferService.swift // NetworkService를 래핑하여 추가 로직 처리(ex. 디코딩, 로)
⊢ 🗒️ Endpoint.swift // 기본적인 API 요청을 위한 로직을 구현해놓은 클래스
⊢ 🗒️ NetworkConfig.swift // baseUrl, header, queryParams 등을 설정할 수 있는 Config
⨽ 🗒️ NetworkService.swift // 네트워크 통신의 기본적인 부분 처리
여기가 엄청 복잡한데, 위 구조는 이상적이지만 입문자에겐 너무 복잡하고 과할 수 있다.
캐싱 안 할 거라면 PersistentStorages 날려버리고, Alamofire 같은 라이브러리를 쓸 거라면 일단 Infrastructure/Network 폴더도 날려버려도 괜찮다. (물론 있는 게 더 좋음.)
현재 가장 중요한 건, Repository와 Network 하위의 DataMapping에 존재하는 코드들이다.
📌 Repository
import Foundation
import Alamofire
class DefaultCategoriesRepository: CategoriesRepository {
private let baseURL: String
private let cache: CategoriesResponseStorage
init(baseURL: String, cache: CategoriesResponseStorage) {
self.baseURL = baseURL
self.cache = cache
}
func fetchCategoriesList(
query: CategoryQuery,
page: Int,
cached: @escaping (CategoriesPage) -> Void,
completion: @escaping (Result<CategoriesPage, Error>) -> Void
) -> Cancellable? {
// 먼저 캐시된 데이터를 확인
if let cachedCategories = cache.getResponse(for: query, page: page) {
cached(cachedCategories) // 있다면, 캐싱된 값을 반환 (API 호출 패스)
}
// API 요청 파라미터 구성
let parameters: [String: Any] = [
"query": query.rawValue,
"page": page
]
// Alamofire를 사용한 네트워크 요청
let request = CategoryAlarmofire.shared.request("\(baseURL)/categories",
method: .get,
parameters: parameters)
.validate()
.responseDecodable(of: CategoriesPage.self) { [weak self] response in
switch response.result {
case .success(let responseDTO):
// 성공 시 캐시에 저장
self?.cache.save(response: responseDTO, for: requestDTO)
completion(.success(responseDTO.toEntity())) // DTO를 Entity로 변환하여 반환
case .failure(let error):
completion(.failure(error))
}
}
// Cancellable 프로토콜을 따르는 래퍼 반환
return CancellableWrapper(request)
}
}엄청 대충 작성한 코드다.
Repository는 세분화하기 시작하면 밑도 끝도 없이 복잡해지고, 내가 Swift를 그렇게 잘 아는 게 아니라서 예시 코드 작성이 어렵다.
그렇다고 엄청 단순하게 하자니, 위처럼 개선할 여지가 넘쳐나는 코드가 탄생했는데, 여튼 이 정도로만 3-Layer 아키텍처를 준수해준다면 나중에 수정하기 매우 수월해진다.
📌 Network vs PersistentStorages
모든 데이터를 매번 API로 부터 받아오지 않고, 로컬 스토리지에 캐싱을 하기 시작한다면 보다 세분화할 필요가 있다.
중요한 것은 어디서 받아오는지는 Domain 영역이 몰라야 한다.
QueriesRepository처럼 대놓고 캐시에서 데이터를 가져오겠다고 작성한 경우에도, Core Data에서 가져오는 지, UserDefaults에서 가져오는 지 알 수 없게 감쳐두었다.
그저 로컬 저장소에서 가져옴을 명시했을 뿐이다.
Domain 입장에서는 그저 데이터를 받아왔다는 것을 알기만 하면 끝난다.
📌 조금 더 깊게 들어가보면...
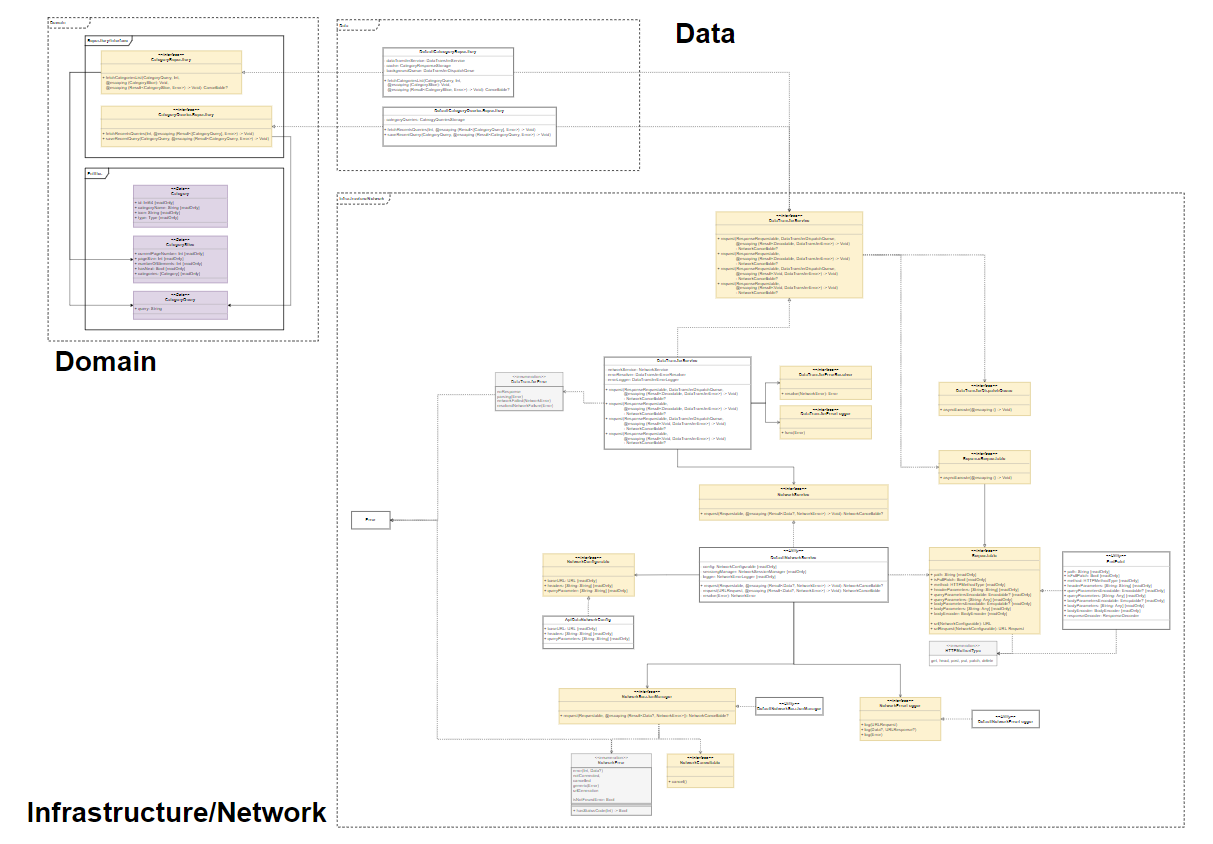
일반적으로 많이들 구성하는 Repository Data 쪽 관계도를 설명하려 했으나, 너무 많아져서 관뒀다.
알아보기 쉽게 큰 글씨로 영역을 구분해두었고, 노란색은 인터페이스(프로토콜), 보라색은 Entity로 표시했다. (enum은 회색)
Infrastructure/Network 영역(폴더)에 있는 프로토콜들은 애플리케이션이 실제 네트워크 요청을 보낼 때, 가장 저수준인 I/O 레벨의 로직을 처리하는 로직들의 모음이다.
무슨 소린지 모를 수 있다. 지금은 아키텍처를 공부하는 시간이니 그런 건 몰라도 된다.
중요한 건 여기서 그 어떤 곳에서도 구체 클래스가 구체 클래스를 직접 참조하는 일이 없으며,
모두 protocol을 참조하고 있다는 점이 중요하다.
(너무 복잡해져서 생략했지만, Repository 구현체가 참조하고 있는 모든 멤버 변수 또한 protocol이다.)
Infrastructure는 애플리케이션에서 가장 Low Level에 대한 작업을 정의하며,
웬만하면 바뀔 일이 없지만 Alamofire 같은 라이브러리를 사용해서 요청을 보내도록 수정하게 된다 해도 변경이 전파되지 않는다. (다른 폴더에서 변경이 발생하지 않는다.)
그럼 Repository에선 대체 무슨 일을 하는 거지?
데이터를 서버에서 가져올 지, 혹은 로컬 저장소의 캐시값을 가져올지 등을 결정하고, DTO를 Entity 타입으로 변환하여 return을 하는 등의 작업을 수행한다.
Core Data, UserDefaults, Key Chain 같은 것들은 네트워크 요청이 아니므로, Data Repository 폴더 하위에 구현되어 있다.
🤔 같은 영역 내라면, 굳이 protocol을 사용하지 않아도 되지 않나요?
다른 영역, 특히 Domain → Data의 의존성 흐름을 역전하기 위해 protocol을 사용하면 된다고 배웠다.
그런데 왜 굳이 같은 영역 내에서도 protocol을 사용할까?
이는 클린 아키텍처와는 별개의 내용으로, 객체 지향의 SOLID 원칙을 준수하기 위함이다.
6. Adventage
이제 위에서 나왔던 클린 아키텍처의 장점들을 되짚어 볼 건데, 아키텍처를 도입하지 않고 개발하면서 머리 한 번쯤 깨져보지 않으면 이해할 수 없을 것이다.
📌 프레임 워크 독립적이다
예전의 나도 그랬지만, 처음 클린 아키텍처를 보는 사람들이 오해하기 쉬운 것이 Clean Architecture는 MVC 패턴이든, MVVM 패턴이든 상관 없다.
MVVM 패턴은 그저, 기존의 MVC 패턴에서 View와 View Controller 간의 강한 결합을 끊어 내기 위해 도입된 Presentation 계층 차이일 뿐이다.
클린 아키텍처는 특정 프레임워크에 의존하지 않는다.
따라서 UI 프레임워크를 SwiftUI를 사용하다가, UIKit으로 바꾸는 등 변화에 자유롭다.
프레임워크를 바꾼다고 Domain 영역과 Repository Data 영역에 아무런 문제가 발생하지 않기 때문이다.
(위 코드에서 Domain과 Repository Data 영역에 SwiftUI를 import 한 적이 있는가?)
📌 테스트에 용이하다
아키텍처 도입 전 테스트 케이스 작성을 해보지 않은 분은 공감이 안 갈 수 있습니다.
각 계층이 명확히 분리되어 있다면 단위 테스트를 수행하기가 매우매우매우 쉬워진다.
(TDD를 한다면 테스트 코드의 작성이 어려워져서 리팩토링을 하는 역순으로 진행되겠지만, 지금은 BDD라고 가정한다.)
import Alamofire
class UserCreateUseCase {
func execute(name: String, email: String, completion: @escaping (Bool) -> Void) {
guard isValidEmail(email) else {
completion(false)
return
}
let parameters: [String: Any] = ["name": name, "email": email]
AF.request("https://api.example.com/users", method: .post, parameters: parameters)
.validate()
.responseDecodable(of: CreateUserResponse.self) { response in
switch response.result {
case .success(let userResponse):
UserDefaults.standard.set(userResponse.userId, forKey: "userId")
UserDefaults.standard.set(name, forKey: "userName")
UserDefaults.standard.set(email, forKey: "userEmail")
completion(true)
case .failure(_):
completion(false)
}
}
}
private func isValidEmail(_ email: String) -> Bool {
return email.contains("@")
}
}
struct CreateUserResponse: Decodable {
let userId: String
}만약, 위 코드처럼 분리를 하지 않은 상태에서 UseCase, 즉 비지니스 로직을 테스트한다고 가정해보자.
일반적으로 사용자 행동에 대한 테스트는 아래 3단계로 구성한다.
- given: 테스트를 하기 위한 사전 조건 (ex. 필요한 의존성 주입, execute 매개변수 지정)
- when: 실제 테스트를 수행
- then: 테스트 수행의 결과가 예측값과 같은지 판단
현재 테스트의 목적은 "사용자 생성을 위한 비지니스 로직, 규칙이 올바르게 적용되는가"에 중점을 둔다.
그 말은 즉, 유효하지 않은 email에 대한 예외가 발생하는 것을 테스트하는 것은 올바르지만,
데이터베이스 연결이 실패했거나, 다른 요인으로 실패해서 테스트가 fail되는 것은 올바르지 않은 단위 테스트다.
물론, 이런 경우는 예외 처리를 수행해서 해소할 수는 있다.
이번엔 조금 더 나아가서 애초에 UseCase 테스트를 위해 Alamofire 의존성을 주입해주거나, 실제 API 호출이 발생하는 것이 올바른 것일까?
실제 실행 환경을 테스트하는 스모크 테스트같은 통합 테스트가 아니라면, 그럴 이유가 없다.
protocol UserRepository {
func createUser(name: String, email: String, completion: @escaping (Result<String, Error>) -> Void)
}
protocol UserStorage {
func saveUserInfo(userId: String, name: String, email: String)
}
class UserCreateUseCase {
private let userRepository: UserRepository
private let userStorage: UserStorage
init(userRepository: UserRepository, userStorage: UserStorage) {
self.userRepository = userRepository
self.userStorage = userStorage
}
func execute(name: String, email: String, completion: @escaping (Bool) -> Void) {
guard isValidEmail(email) else {
completion(false)
return
}
userRepository.getUser(name: name, email: email) { result in
switch result {
case .success(let userId):
self.userStorage.saveUserInfo(userId: userId, name: name, email: email)
completion(true)
case .failure(_):
completion(false)
}
}
}
private func isValidEmail(_ email: String) -> Bool {
return email.contains("@")
}
}이번엔 계층을 올바르게 분리하고, 의존하는 클래스는 모두 protocol로 수정했다.
UserRepository, UserStorage는 당연히 성공적으로 수행한다는 것이 기본 전제이므로,
테스트를 할 때는 해당 프로토콜을 구현한 Mock 객체를 만들어, 요청에 대한 반환값을 임의로 조작할 수도 있다.
만약 Repository 작업이 실패했을 때, UseCase 동작을 테스트해보고 싶다면 그 또한 Mock 객체를 생성해 테스트 가능하다.
✒️ Mock 객체?
제품 코드에서 사용하기 위해 UserRepository를 구현한 클래스를 테스트에서 사용하면, DB 연결 작업을 실제로 처리해줘야 한다.
하지만 단위 테스트에선 실제 연결을 수행하지 않고, API 호출 후 예상 응답을 미리 정의한 가짜 객체를 생성한다.
그리고 UseCase를 테스트하기 위해 UserCreateUseCase 인스턴스를 생성할 때, 가짜 객체를 주입해주면 된다.
📌 UI 독립적이다
UI 로직이 비지니스 로직과 분리되어 있다는 것은 UI의 변경에 의해 시스템의 다른 곳에서 영향을 주지 않음을 의미한다.
비지니스 로직은 UseCase에 있고, UseCase는 도메인 영역에 위치한다.
View는 Presentation 계층에 존재하며, 모든 의존성 흐름은 Presentation → Domain으로 향하므로 타당하다.
📌 DB 독립적이다
protocol을 정의함으로써 애플리케이션의 의존성 흐름을 App → DB에서, DB → App으로 바꾸었기 때문이다.
위에서 든 예시로는 와닿지 않을 수 있다.
원래라면 Repository가 의존하는 NetworkService protocol을 정의하여, 한 번 더 추상화 시킬 필요가 있다.
실제로 어느 DB에 연결되는지 Configuration을 설정하는 파일만 수정하면, 도중에 Firebase를 사용하다 Mongo DB로 변경해도 아무런 영향을 주지 않는다.
또한 Firebase의 상세 스펙이 바뀐다고, 애플리케이션에 변경 사항이 전파되지 않는다.
📌 외부 기능으로부터 독립적이다
외부 기능으로부터 완전히 자유롭긴 많이 힘들다.
적어도 API 스펙의 변경이 View까지 전파되는 제정신 나간 상황은 방지했으며, Router와 Repository Data 영역의 DTO 정도만 영향을 받는다.
라이브러리를 사용한다면, 직접적으로 사용하지 않고 Adapter 패턴을 적용한다면 보다 안전해진다.
[SwiftUI] MVVM 패턴 구조의 앱에서 Analystics 계층 분리하기 (+ `24.07.31 아키텍처 개선 과정 추가)
📕 목차1. Introduction2. Architecture Design & Implementation3. Firebase Service Implementation1. Introduction 📌 문제 상황 ✨ Analytics Layer 분리 by psychology50 · Pull Request #135 · CollaBu/pennyway-client-ios작업 이유 Google Analy
jaeseo0519.tistory.com
위 포스트는 이전에 Analytics 기능을 도입하기 위해, 어댑터 패턴과 옵저버 패턴을 이용해 분석 계층을 추가한 것이다.
위와 같이 사용하면 외부 기능으로부터 매우 안전해진다.