📕 목차
1. Archiving의 목적
2. Archiving의 대상
3. Archiving의 위치
4. tar : 파일과 파일 시스템 archiving
5. dd : 파티션 archiving
6. rsync : archive 동기화
7. 백업 계획 시 고려 사항
🌱 명령 복습
# 현재 활성화된 파티션을 사람이 읽기 쉬운 형식으로 보여준다.
df -h
# 특정 디렉토리에 있는 비디오 파일들의 압축된 아카이브를 생성한다.
tar czvf (아카이브명).tar.gz (디렉토리 경로)/*.mp4
# 큰 파일을 지정한 크기의 작은 파일 여러 개로 분할한다.
split -b 1G (아카이브명).tar.gz (아카이브명).tar.gz.part
# 지정한 기준에 맞는 파일들을 찾아 tar 명령에 전달해 아카이브에 추가한다.
find (패턴) -iname (문자) -exec tar -rvf videos.tar {} \;
# 나머지 사용자의 읽기 권한을 제거한다.
chmod o-r /bin/zcat
# sda2 파티션의 Image를 생성해 홈 디렉토리에 저장한다.
dd if=/dev/sda2 of=/home/username/partition2.img
# 파티션을 무작위 글자로 덮어써 이전 데이터를 알아볼 수 없게 한다.
dd if=/dev/urandom of=/dev/sda11. Archiving의 목적
📌 What is archiving?

- 아카이브(archive) : 여러 파일과 디렉토리를 담고 있는 하나의 파일
- 파일과 디렉토리에 따로 존재할 때보다 이동, 공유, 저장하는 게 훨씬 쉬워진다.
- archive의 종류
- tar : 쉽게 공유하거나 백업하기 위해 파일들의 사본을 만드는 경우
- dd : 파티션이나 심지어 HDD를 통째로 복사해야 하는 경우
- rsync : 주기적으로 시스템을 백업해야 하는 경우
📌 압축(Compression)
- 압축과 아카이빙이 함께 쓰이는 경우가 많지만, 둘을 혼동해서는 안 된다.
- 압축은 file이나 archive가 disk에서 차지하는 공간을 줄여주는 알고리즘을 적용하는 소프트웨어 도구다.
- Network를 통해 큰 archive 파일을 전달할 계획이라면 압축하는 것이 전송 시간을 상당히 줄일 수 있다.
📌 고려 사항
1️⃣ 이미지(image)
- 새로운 곳에 원본 파일 시스템을 다시 생성하는 데 필요한 디렉토리와 파일을 담은 아카이브다.
- VM에 Linux를 설치하기 위해 사용한 ISO 파일이 하나의 예시다.
- OS를 담은 이미지로서, 대상 컴퓨터에 복사하기 쉽게 특별히 구성한 파일
- 실행 중인 OS 전체 혹은 일부분으로부터 생성해 다른 PC에 내용을 쉽게 복사할 수도 있다.
- 대상 PC의 현재 상태를 원본 PC의 완전한 복제본으로 만들 수 있다.
- Image를 생성하고 시스템을 복구하는 데 사용하는 도구는 백업 도구와 거의 비슷하다.
- Window registry architecture는 어떤 방법으로도 설치된 OS를 원래 HW에서 분리할 수 없게 되어 있어서 사용할 수 없다.
2️⃣ 데이터 백업
- 백업은 시스템 관리자 업무의 상당 부분을 차지하며, 굉장히 중요한 과정이다.
- 검증되지 않은 데이터 백업은 제대로 작동하지 않을 수 있다.
- 제대로 백업이 되었는지 확신할 방법은 원래 HW와 똑같은 HW에 복구 테스트를 해보는 방법 뿐이다.
2. Archiving의 대상
💡 특정 Disk를 백업할 때는 어느 파티션을 백업하고, 하지 않을지 정보를 충분히 입수하고 나서 결정하라.
📌 archive가 필요 없는 경우
$ scp .ssh/id_rsa.pub (계정명)@(ip):/home/(계정명)/.ssh/authorized_keys- 파일의 양이 적고 크기가 크지 않다면 그대로 목적지로 전송해도 크게 문제되지 않는다.
- 여러 디렉토리에 분산된 많은 파일이나 파티션 곳곳에 분산된 많은 파일을 백업하긴 힘들다.
📌 파티션(Partition)
지능적인 백업 정책을 수립하려면 파티션을 생각해봐야 한다.
회사의 아주 큰 회계 데이터베이스가 들어 있는 파티션을 백업할 때, 파티션이 공간을 얼마나 차지하는지, 어디에 위치하는지를 모르면 제대로 백업하기 힘들다.
- 주 OS 파티션
- /dev/sda3
- 저장 장치 A(sda)의 세 번째 파티션
- 의사 파일 시스템 티렉토리 dev를 통해 시스템 리소스로 표시됨
- 시스템에 연결된 모든 장치는 dev 디렉토리에 있는 파일로 표시된다.
- 회계 데이터베이스가 있는 파티션도 /dev/sda1 등의 이름으로 여기에 속할 것이다.
- /dev/sda3
- 의사 파일 시스템
- 의사 파일 시스템에 있는 파일들은 disk에 저장되지 않고 memory에만 존재한다.
- 시스템이 부팅될 때마다 OS에 의해 자동으로 바뀌고, 종료되면 사라진다.
- 임시로 HW profile을 나타내는 파일들을 백업할 필요는 없다.
- 유형이 tmpfs거나 Use 열이 크기가 0이면 일반 파티션이 아닌 임시 파일 시스템이다.
- UEFI 펌웨어 제어 파티션
- Linux를 설치할 때 시스템 부팅 과정을 UEFI 펌웨어로 제어하기 위해 만든 파티션
- 최근에는 UEFI가 BIOS를 대체하고 있다.
- Linux를 설치할 때 시스템 부팅 과정을 UEFI 펌웨어로 제어하기 위해 만든 파티션
- 별도 파티션
- var, usr 등의 디렉토리
- 민감한 데이터의 무결성과 보안을 유지하기 쉽다.
- "/var/log/" 등의 디렉토리에 생성된 파일들이 시스템을 다 차지하는 것을 막을 수 있다.
- boot 디렉토리
- 별로 좋은 생각은 아니다.
- kernel Image가 boot 디렉토리에 저장되므로, Linux kernel 버전으로 업데이트할 때마다 여기에 저장할 파일들이 많아진다.
- 일반적으로 boot 파티션에 500MB밖에 할당하지 않는데, 6개월 정도 운용하고 업데이트하다보면 공간이 꽉 차서 업데이트에 실패한다.
- boot 디렉토리는 가장 큰 파티션 안에 두는 것이 좋다.
- var, usr 등의 디렉토리
3. Archiving의 위치
📌 어디에 백업해야 할까
백업은 순서에 상관없이 다음 속성을 만족해야 한다.
(OS 관점으로 보면 archive를 어디 저장하든지 상관없지만, 모범 사례를 따르는 것이 좋다.)
- 신뢰성(reliable)
- 백업 중에 무결성을 충분히 보장할 수 있는 storage 매체를 사용하라
- 검증(tested)
- 실운영 환경과 똑같은 환경에서 될 수 있으면 많은 archive로 복구 테스트를 수행하라
- 순환(rotated)
- 현재 백업보다 최소 몇 단계 이전까지의 archive를 모두 보관해 최신 백업으로 복구할 수 없을 때를 대비하라
- 분산(distributed)
- 적어도 일부 archive는 물리적으로 떨어진 곳에 저장하라
- 보안(secure)
- 백업 및 복구 과정 동안 안전하지 않은 Network나 storage에 데이터를 잠시라도 노출하면 안 된다.
- 준수(compliant)
- 늘 관련 범규와 업계 표준을 준수하라
- 최신(up to date)
- 몇 주 또는 몇 달이 지난 archive를 보관할 필요는 없다
- 스크립트(scripted)
- 수행할 작업을 사람이 모두 기억하고 있을 거라 기대하지 말고, 자동화하라
4. tar : 파일과 파일 시스템 archiving
📌 archive 생성 3단계
- archive에 포함할 파일을 알아둔다.
- archive가 사용할 storage drive 안의 위치를 확인한다.
- file을 archive에 추가하고 archive file을 storage에 저장한다.
이 세 단계를 한 번에 해결하고 싶다면 tar를 사용하면 된다.
📌 단순 archive와 compression의 예
💡 tar 명령은 명시한 원본 디렉터리와 파일들을 절대로 이동하거나 삭제하지 않고 복사한다.
1️⃣ 기본적인 tar 사용법

$ tar cvf archivename.tar *- -c : archive 생성
- -v : 자세한 log를 화면에 출력
- -f : 생성할 archive 파일명 지정
tar 확장자명은 없어도 되지만, 파일의 용도를 명확히 보여주는 편이 좋다.
2️⃣ archive 파일 압축
$ tar czvf archivename.tar.gz *.mp4- -z(zip) : archive를 gzip 프로그램으로 압축한다.
- 관례로 .gz 확장자를 덧붙인다.
3️⃣ 압축 파일 나누기 : split
$ split -b 1G archivename.tar.gz "archivename.tar.gz.part"
$ cat archivename.tar.gz.part* > archivename.tar.gz- archive 파일이 아주 커지는 경우, split 명령어로 여러 개의 작은 파일로 나누어 전송한 뒤 병합할 수도 있다.
📌 file system archive streaming
# tar czvf - --one-file-system / /user /var \
--exclude=/home/andy/ | ssh (계정명)@(ip) \
"cat > /home/(계정명)/workstation-backup-Apr-10.tar.gz"위 명령어는 Linux가 작동되는 A host에서 tar로 archive를 생성하고, ssh로 archive를 remote server에 전송해 저장하는 방식이다.
이 명령어를 이해하기 위해서는 작은 예를 먼저 살펴보는 것이 좋다.
$ tar czvf - importantstuff | ssh (username)@(ip) \
<linearrow /> "cat > /home/username/myFiles.tar.gz"- archive 이름 대신 대시(-)를 사용하면 내용을 표준 출력 장치에 출력한다.
- archive 이름은 명령어 마지막에, data stream을 remote server에서 cat을 실행함으로써 명시할 수 있다.
- 중간 단계에 임시 파일을 local pc에 저장할 필요가 없다.
# tar czvf /dev/sdc1/workstation-backup-Apr-10.tar.gz \
--one-file-system / /usr /var --exclude=/home/andy- 명령어 옵션 구성
- --one-file-system : archive를 만들 때 다른 파티션에 있는 데이터를 모두 제외한다. (sys나 dev같은 의사 파티션)
- / /usr /var : usr과 var 파티션을 명시적으로 참조한다.
- --exclude= : 필요에 따라 선택된 파일 시스템 안에서 특정 디렉토리나 파일을 제외한다.
📌 find로 파일 모으기
archiving 하려는 파일이 모두 단일 디렉토리 구조 안에 모여있지 않고, 포함하고 싶지 않은 파일들도 있을 때, 원본 디렉토리 구조를 변경하지 않고 원하는 파일만 모을 수 있다.
- 주어진 규칙에 맞는 파일들의 이름과 위치를 표준 출력(stdout, standard out)으로 출력한다.
# find /var/www/html/ -iname "*.mp4" -exec tar -rvf videos.tar {} \;- 명령어 옵션
- -iname : 대문자와 소문자를 모두 매칭한다. (-name은 대소문자를 구분한다.)
- {} : find의 표준 출력 결과가 해당 위치로 들어온다.
- find 명령은 sudo로 실해하는 편이 좋다.
- 시스템 디렉토리를 검색하므로 일반 사용자 권한으로 읽지 못하는 일부 파일을 놓칠 수도 있다.
🟡 locate
$ locate *vedio.mp4- 급할 때 파일을 간단히 찾을 수 있는 명령어
- 전체 시스템을 검색해 지정한 문자열에 매칭되는 파일을 찾는다.
- 대부분 locate가 fine보다 빨리 결과를 찾는다.
- locate는 파일 시스템 자체를 검색하지 않고, 검색 문자열을 기존 인덱스에서 찾는다.
- 인덱스가 오래될 수록 검색 결과의 정확성이 떨어진다.
$ updatedb- 일반적으로 인덱스는 시스템이 부팅될 때마다 업데이트된다.
- 수동으로 업데이트하고 싶다면 위의 명령어를 사용하면 된다.
📌 권한 및 소유권 유지하기와 archive 추출하기
💡 Archiving 작업으로 파일 접근 권한과 소유자 속성이 손상되면 안 된다.
🟡 권한

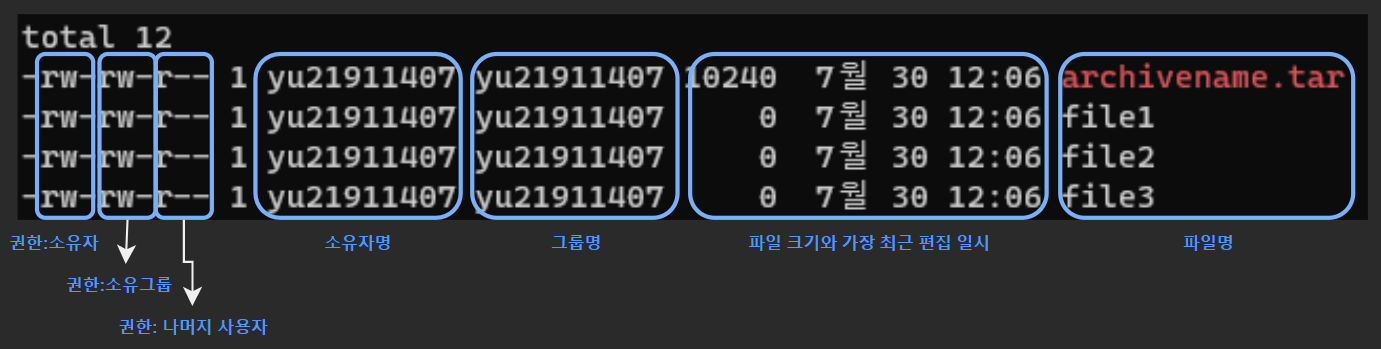

귀찮으니까 예전에 정리한 자료로 대체
🟡 소유권

- 파일이 너무 크거나 민감한 데이터가 있는 경우 이메일을 사용할 수는 없다.
- 같은 server 사용자라면 복사해주면 된다.
- 서로 다른 서버라도 scp로 파일을 전송하고 요청한 사용자 홈 디렉토리로 복사하면 된다.
- 두 방법 모두 다른 사용자의 디렉토리로 복사해야 하므로 sudo를 사용해야 한다.
- 파일 소유자가 root가 되는 문제가 발생한다.
- 마찬가지로 수신자 측에서 sudo 권한의 chown 명령어로 권한을 수정해야 한다.

🟡 추출과 소유권
$ mkdir tempdir && cd tempdir
$ touch file1 file2 file3 && ls -l
$ sudo chown otheruser:otheruser file3
$ tar cvf stuff.tar *
$ tar xvf stuff.tar && ls -l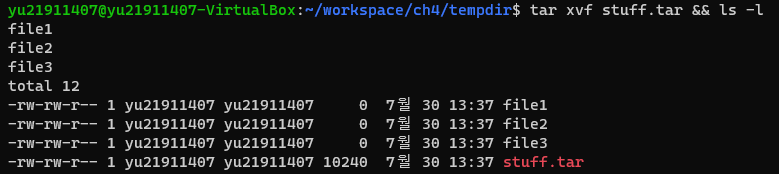
- 일반적으로 관리자 권한이 있는 사용자만 다른 사용자 계정에 있는 리소스를 이용할 수 있다.
- 내 파일 중 하나의 소유자를 동료로 바꾸는 것은 다른 사용자 계정을 변경하는 작업이다.
- 따라서 archive에서 파일을 추출할 때, 다른 사용자 소유의 파일로 저장하는 것은 불가능하다.
- 원래 권한으로 파일을 추출하는 것도 비슷한 문제가 있다.
- 해결책은 sudo 권한으로 작업을 수행하는 것이다.
5. dd : 파티션 archiving
📌 dd(disk destroyer)
- 파티션과 관련된 작업을 할 때 유용하다.
- 어떤 디지털 매체라도 바이트 하나하나를 완벽히 복사해 완벽한 Image를 만들 수 있다.
- dd는 디스크 파괴자의 약자다. 오타 하나가 disk 데이터를 통째로, 영구적으로 삭제하는 일이 생길 수 있다.
📌 dd 사용하기
'/dev/sda'로 지정된 disk에 있는 데이터 전체의 완벽한 Image를 만들어보자.
우선 '/dev/sda'와 빈 disk를 연결한다.
💡 Archive가 제대로 작동하는지 늘 테스트하라.
1️⃣ 기본적인 사용법
# dd if=/dev/sda of=/dev/sdb- 'if=' : 원본 드라이브
- 'of=' : 데이터를 저장할 파일이나 장치의 이름
2️⃣ .img archive 생성
# dd if=/dev/sda of=/home/username/sdadisk.img- 드라이브 전체의 Image를 생성한다.
- 드라이브에 있는 특정 파티션에도 똑같이 작업할 수 있다.
3️⃣ 한 번에 복사할 바이트 수 지정 : bs 플래그
# dd if=/dev/sda of=/home/username/partition2.img bs=4096- 이상적인 bs 값은 하드웨어와 여러 조건에 따라 나뉜다.
4️⃣ 복원
dd if=sdadisk.img of=/dev/sdb- if와 of의 값을 바꾸면 복원이 된다.
📌 dd로 디스크 소거하기
⚠️ 하드디스크 드라이브를 모두 파괴하는 방법
# dd if=/dev/zero of=/dev/sda1
# dd if=/dev/urandom of=/dev/sda1- 비밀 데이터를 담은 파일을 지우기만 하면, 시간과 동기만 충분할 경우 복구가 가능하다.
- dd를 사용하면 파티션의 구석구석을 수백만 또는 수백억 개의 0으로 덮어씌울 수 있다.
- 두 번째 명령어는 /dev/urandom 파일을 원본으로 사용하여 disk를 무작위 글자들로 덮어버린다.
6. rsync : archive 동기화
아주 큰 Archive를 정기적으로 백업하기 위해 매일매일 전송하면 Network에 상당한 부담을 준다.
파일 시스템을 통째로 전송하는 대신 최신 백업 내역에서 추가 혹은 수정된 파일들만 전송한다.
📌 사용법
$ mkdir mynewdir && cd mynewdir
$ touch file{1..10}
$ ssh yu21911407@192.168.56.1 "mkdir syncdirectory"
$ rsync -av * yu21911407@192.168.56.1:syncdirectory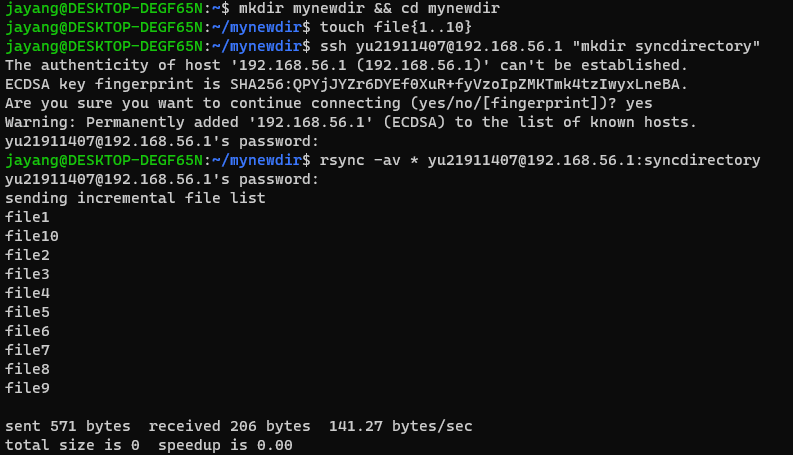

- -a : rsync가 재귀적으로 동기화한다.
- rsync가 재귀적으로 하위 디렉토리와 그 안의 모든 내용을 동기화한다.
- 특수 파일들, 수정 시간, 소유권과 접근 권한을 유지한다.
- -v : 명령이 수행하는 작업을 상세히 출력한다.
$ touch newfile
$ nano file3
$ rsync -av * yu21911407@192.168.56.1:syncdirectory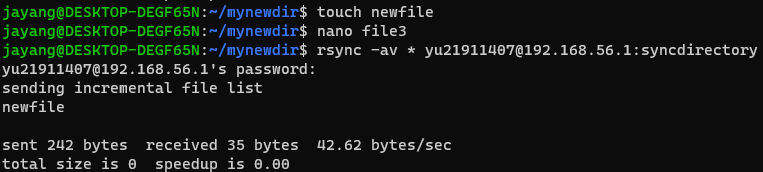

- 똑같이 rsync를 보내면 새로 추가한 newfile만 전송된다. (nano file3치고 아무 내용 입력도 안 해버렸더니 반영이 안 됐다. 😅)
7. 백업 계획 시 고려 사항
📌 데이터 가치 측정
- 새로운 Archive를 얼마나 자주 생성하고, 이전 버전을 얼마나 오래 보관할 것인가?
- 백업 과정에 얼마나 많은 검증 단계를 넣을 것인가?
- 데이터 사본을 동시에 몇 개나 보관할 것인가?
- Archive를 원격지에 보관하는 것은 얼마나 가치있는가?
📌 차등 백업(differential backup)
- 전체 백업을 일주일에 한 번(월요일) 수행하고, 더 작고 빠른 차등 백업을 나머지 6일 동안 매일 수행할 수 있다.
- 화요일 백업은 월요일 백업 이후에 변경된 파일들만 포함한다.
- 수, 목, 금요일 백업도 각각 월요일 백업 이후에 변경된 파일들을 모두 포함한다.
- 복구할 때 마지막 전체 백업과 최신 차등 백업만 있으면 된다.
📌 증분 백업(incremental backup)
- 마찬가지로 전체 백업을 월요일에만 수행하고 화요일에는 변경된 파일만 백업한다.
- 그러나 수요일 백업은 화요일 이후에 추가나 변경된 파일들만 백업한다.
- 목요일 백업은 수요일 이후에 변경이나 추가된 파일만 백업한다.
- 빠르고 효율적이지만, 백업 데이터가 여러 파일에 분산되어 있으므로 복구에 시간이 더 많이 들고 복잡하다.
✒️ 좋은 보안 습관
• 중요한 데이터를 모두 백업 가능하도록 자동화하고 신뢰성 있으며 검증되고 안전하게 반복하는 절차를 만들어라.
• 가능하면 기밀 데이터는 별도의 파티션에 만든 파일 시스템에 저장하고, 시스템 부팅 시 이 파일 시스템을 마운트하라.
• 파일 접근 권한이 정확한지 늘 검사하고, 최소한의 접근 권한만 부여하라.
• 구형 저장 장치에 저장된 데이터가 제대로 삭제되었을 거라 쉽게 넘기면 안 된다.