Routing table을 생성, 유지, 업데이트, 전달하는 프로토콜을 말한다. (라우팅 알고리즘을 위해 주기적으로 정보 교환하기 위한 목적도 포함한다)
목적은 sender host부터 receiver host까지의 최적 경로를 찾는 것이다.
여기서 최적 경로란 "minimum hop count", "fastest", "least congested" 등을 고려해야 한다.
거치는 라우터 수가 적다고 꼭 빠르다는 보장은 없다. 따라서 가중치(트래픽)도 고려해주어야 한다.
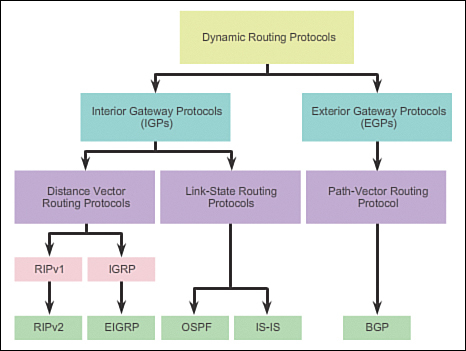
Routing Protocol에는 사람이 하나하나 경로를 입력해주어야 하는 Static Routing Protocol과 Dynamic Routing Protocol이 존재한다. (전자는 말이 안 되므로 패스)
Dynamic Routing Protocol은 AS(Autonomous System, 일정 규모의 같은 관리자 하에 있는 라우터 집합) 내/외부에서 각각 사용되는 라우팅 프로토콜이 있다.
그리고 내부 라우팅 프로토콜까지 오면, 드디어 이번 포스팅에서 다룰 Distance Vector Routing Protocol과 Link-State Routing Protocol이 나온다.
참고로 Protocol과 Algorithm은 엄연히 다른 개념이다.
2. Routing Algorithms
📌 LS Algorithm (Link-State Algorithm)
dijkstra's algorithm 기반
Assum. 인접 router의 Topology를 모두 알고 있다.
Router들이 주기적으로 서로의 정보를 Broadcast하여 공유하기 때문 (모든 노드는 같은 정보를 갖는다.)
Bandwidth와 Delay 같은 링크 세부정보도 변수로 고려할 수 있다.
Router가 목적지까지 가는 경로의 가장 짧은 경로(Shortest Path)를 라우팅 테이블에 기록한다.
최단 경로를 찾을 때는 가중치를 모두 1로 잡으면 됨.
최소 시간을 찾을 때는 가중치를 고려해야 함.
EIGRP, OSPF(EIGRP보다 대규모 네트워크 안정되게 운용)
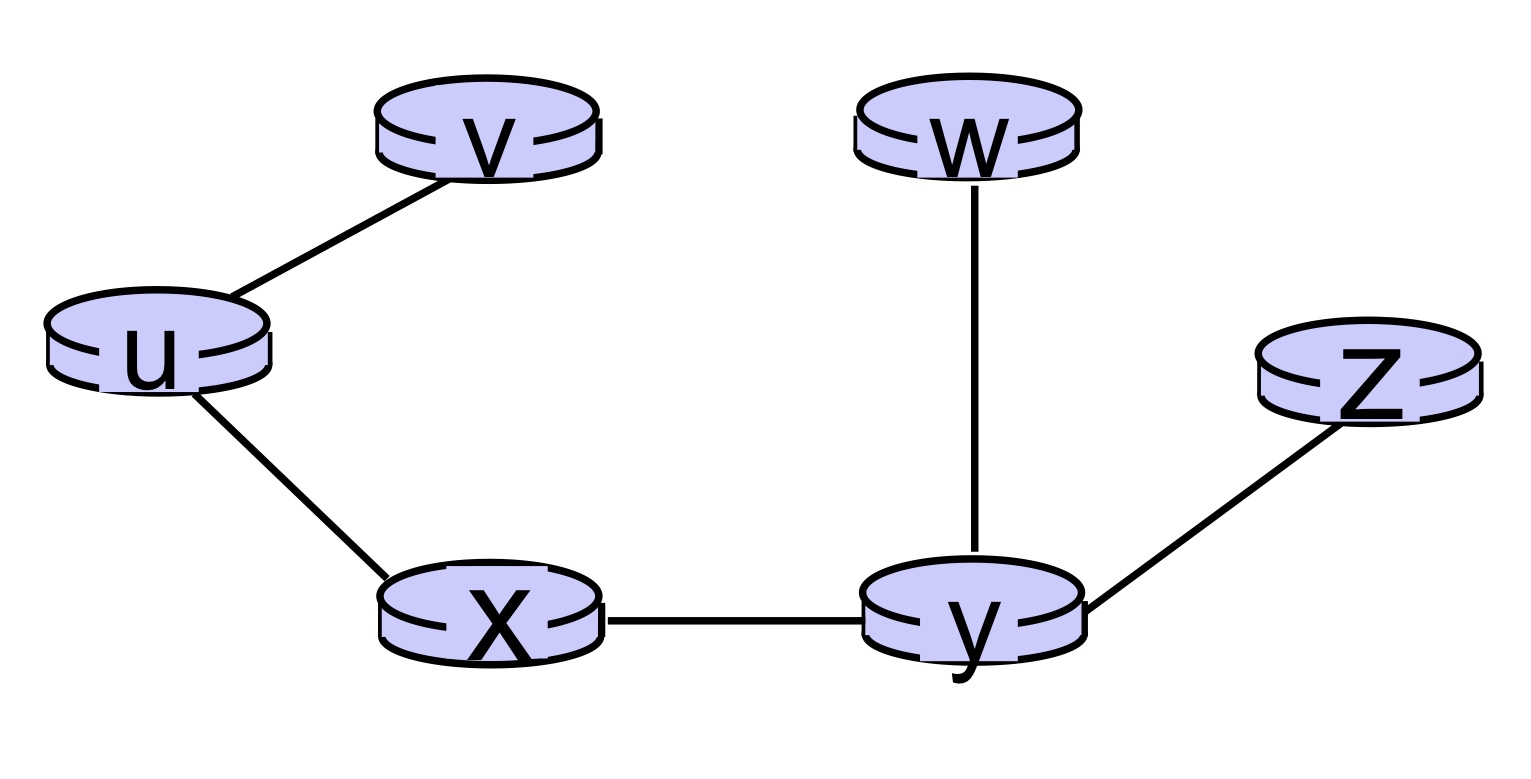
✒️ Graph Abstraction: Link Costs
c_(a, b)를 a에서 b로 가는 비용(cost)이라고 하자. (ex. c_(w,z) = 5, c_(u,z) = ∞) 가중치는 bandwidth, congestion 등을 변수로 선택할 수 있다. 만약 최단 경로만을 찾고자 한다면, 모든 가중치를 1로 계산하면 된다.
graph: G = (N, E) N: set of routers(정점) = { u, v, w, x, y, z } E: set of links(간선) = { (u,v), (u,x), (v,x), (v,w), (x,w), (x,y), (w,y), (w,z), (y,z) }
일단 용어를 조금 정리하고 넘어가자.
c_(x,y): 물리적으로 직접 연결된 link의 cost. 만약 직접 연결된 이웃이 없다면 ∞
D(v): 현재 측정된 source에서 sink(v)까지 가중치가 가장 작은 경로
p(v): 임의의 노드(v)에서 선행노드 (ex. u→x→y가 최단 경로면 p(y)=x)
N': 최단 경로가 찾아진 노드들의 집합
LS Algorithm의 최종 목표는 source인 하나의 노드에서 다른 노드로 향하는 최소 비용을 계산하는 것이다.
해당 알고리즘을 이해하기 위한 세 가지 핵심을 기억하자.
Knowledge about the neighborhood: Routing table을 보내는 대신 직접 연결된 link의 id와 cost를 broadcast하여 다른 라우터에 전달한다. (즉, 테이블 전체가 아니라 link state만 공유하는 것이다.)
Flooding: 각 Router는 이웃을 제외한 internet의 다른 모든 라우터에 정보를 보낸다. 이 프로세스를 Flooding이라고 하며, 패킷을 수신하는 모든 라우터는 이웃에게 복사본을 보낸다. 따라서 모든 라우터는 동일한 정보를 가지게 된다.
Information sharing: 라우터는 정보가 변경된 경우에만 다른 모든 라우터에게 정보를 보낸다.
따라서 다익스트라 알고리즘을 수행하기 전과 후의 정보 차이는 다음과 같다.
초기 상태: 각 노드는 이웃 노드의 비용을 모두 알고 있다.
최종 상태: 각 노드는 전체 그래프를 알고 있다.
다익스트라 알고리즘이란 특정 노드에서 다른 노드로 가는 각각의 모든 최단 경로를 갱신하는 알고리즘이므로
k번 반복하면 k개의 대상 노드에 대한 최소 비용 경로를 알 수 있을 것이다.
Initialization
N' = {u} // u is a root node.
for all nodes v
if v adjacent to u
then D(v) = c(u,v)
else D(v) = INF
Loop
find w not in N' such that D(w) is a minimum.
add w to N'
Update D(v) for all v adjacent to w and not in N':
D(v) = min(D(v) , D(w) + c(w,v))
Until all nodes in N
루프가 실행되는 횟수는 네트워크에서 사용 가능한 총 노드 수, 즉 라우터 수와 동일하다.
예시를 통해 step by step으로 이해해보자.
1️⃣ Step 1:
가장 처음은 초기화 단계로 시작한다.
Initialization
N' = {u} // u is a root node.
for all nodes v
if v adjacent to u
then D(v) = c(u,v)
else D(v) = INF
정점 u를 기준으로 테이블을 갱신한다.
Step
N'
D(v) / p(v)
D(w) / p(w)
D(x) / p(x)
D(y) / p(y)
D(z) / p(z)
1
u
2 / u
5 / u
1 / u
INF
INF
이 테이블 정보로만 판단했을 때, x로 가는 것이 가장 최적 경로라고 판단할 수 있다.
사실 알 수 없는 거지만 그리디 알고리즘을 생각해보면 된다.
현재 상황만 따지고 봤을 때 가장 최선의 경우를 선택해서 넘어가는 것이다.
2️⃣ Step 2:
위의 테이블을 이용해서 아래 반복문을 돌려주면 된다.
위에서 x노드로 가는 것이 가장 적합할 것이라 판단했으니 u→x→? 의 경로를 추적한다.
Loop
find w not in N' such that D(w) is a minimum.
add w to N'
Update D(v) for all v adjacent to w and not in N': // 모든 D값을 업데이트해라
D(v) = min(D(v) , D(w) + c(w,v))
Until all nodes in N
참고로 로직을 이해하고 싶다면 철저하게 위에서 제공된 표와 문제에서 제공하는 가중치 정보로만 판단해야 헷갈리지 않는다.
이렇게 완성된 테이블은 Vertex u 관점에서 다른 모든 정점으로 향하는 최소 경로를 파악할 수 있게 해준다.
u가 z로 데이터를 송신해야 한다면? x에게 보내주면 되겠구나! 라고 판단하는 것이다.
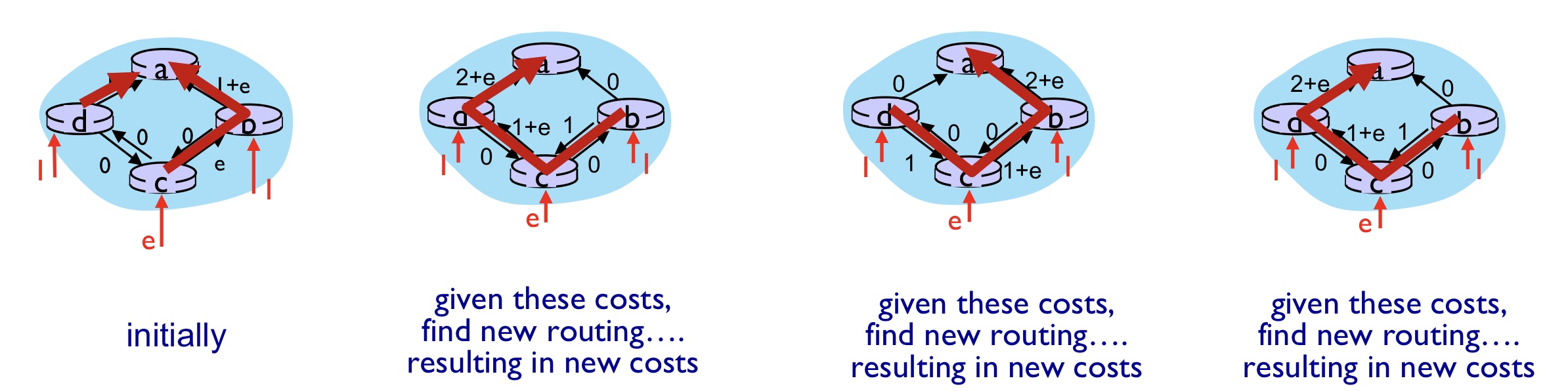
✒️ Issue. oscillations possible
예를 들어서 목적지가 a인 경우, c_(d,a)=1, c_(b,a)=1, c_(c,a)=1+e 인 최적 경로를 발견했다고 치자. 문제는 다음에 LS Algorithm을 수행하면, c router 입장에서는 c_(c,d)가 0이니까 최적 경로라고 판단되어 길을 바꿀 것이고, b router 입장에서도 c_(c,d)가 현재 0이므로 1+e의 가중치인 현재 경로를 버리고 엉뚱한 경로를 택한다. 그리고 다음에는 또 d router까지 합세해서 반대로 되돌아가는 등. 이 문제의 원인은 모든 라우터가 동시에 알고리즘을 수행하려 하기 때문이다.
따라서 몇 가지 Solution이 존재하는데, 1. 모든 Router가 알고리즘을 동시에 수행하지 말고, 업데이트 인터벌을 랜덤으로 정해라 2. 트래픽 볼륨에만 의존하지 말고, hop-count 같은 다른 정보를 써보자. 3. 아예 다른 변수들도 섞어쓰자. (마, 우리가 남이가!)
📌 Distance-Vector Algorithm
bellman-ford 방정식 기반
Assum. 물리적으로 연결된 인접 노드 정보밖에 알지 못한다.
대신, Distance-Vector 전체 주기적으로 공유
각 노드는 Local link cost의 비용이 변경되거나 Distance Vector 업데이트 메시지를 이웃에게 받은 경우에 테이블을 갱신하고 물리적으로 연결된 인접 노드에 알린다.
라우팅 테이블에 목적지까지 가는데 필요한 거리와 방향만을 기록한다.
RIP(소규모 네트워크에서), IGRP(시스코 전용, 중·대규모 네트워크 적용)
공식 하나를 머리에 때려넣어 두면 편하다.
처음에는 이게 뭐지? 싶은데 하다보면 LS-Algorithm에 비해 훨씬 간단하고 직관적이다. (노가다를 할 거기 때문)
$$ d_{x}(y) = min_{v}( c(x,v) + d_{v}(y) ) $$
(\( d_{x}(y): x에서 y로 가는 최소 비용, min_{v}: x이웃에 대해 취해진 모든 방정식, c(x,v): x에서 v로 가는 비용 \))
벨만 포드 알고리즘은 단순하다. 더이상 업데이트가 발생하지 않으면, 최적 경로가 갱신되었다고 판단한다.
즉, 변화가 없을 때까지 위의 공식을 사용해서 테이블을 갱신하면 된다! (겁나 귀찮다)
At each node x,
Initialization
for all destinations y in N:
Dx(y) = c(x,y) // If y is not a neighbor then c(x,y) = ∞
for each neighbor w
Dw(y) = ? for all destination y in N.
for each neighbor w
send distance vector Dx = [ Dx(y) : y in N ] to w
Loop
wait(until I receive any distance vector from some neighbor w)
for each y in N:
Dx(y) = minv{c(x,v)+Dv(y)}
If Dx(y) is changed for any destination y
Send distance vector Dx = [ Dx(y) : y in N ] to all neighbors
forever
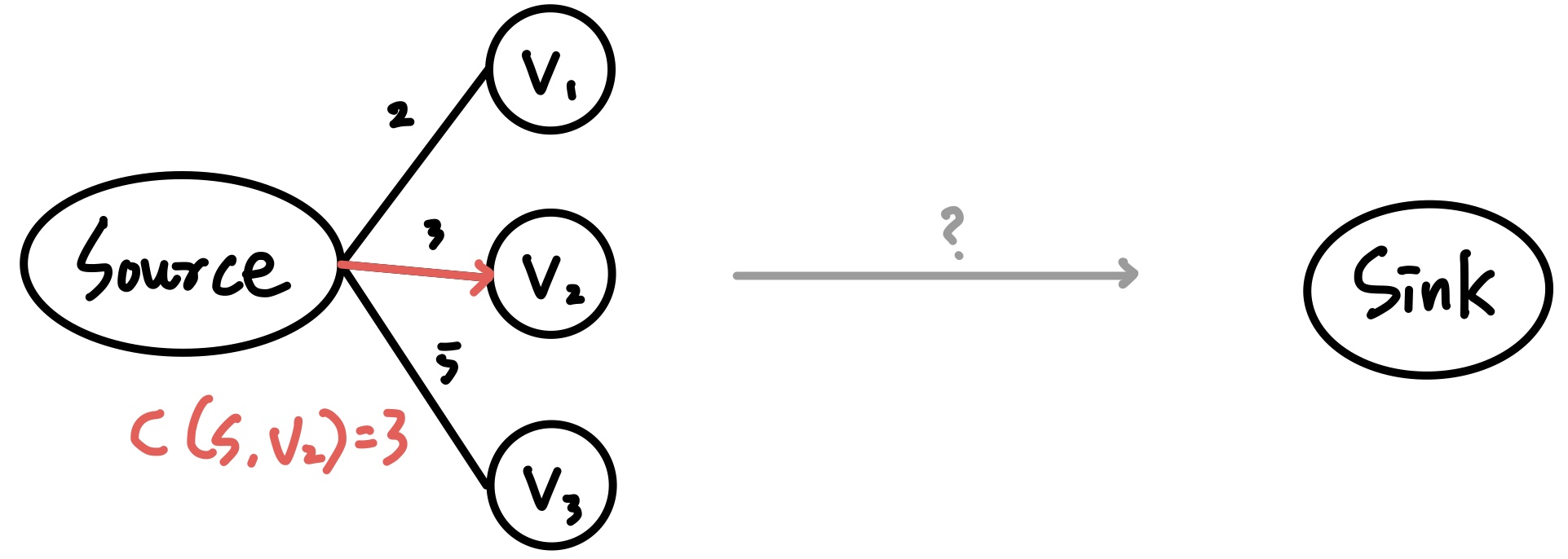
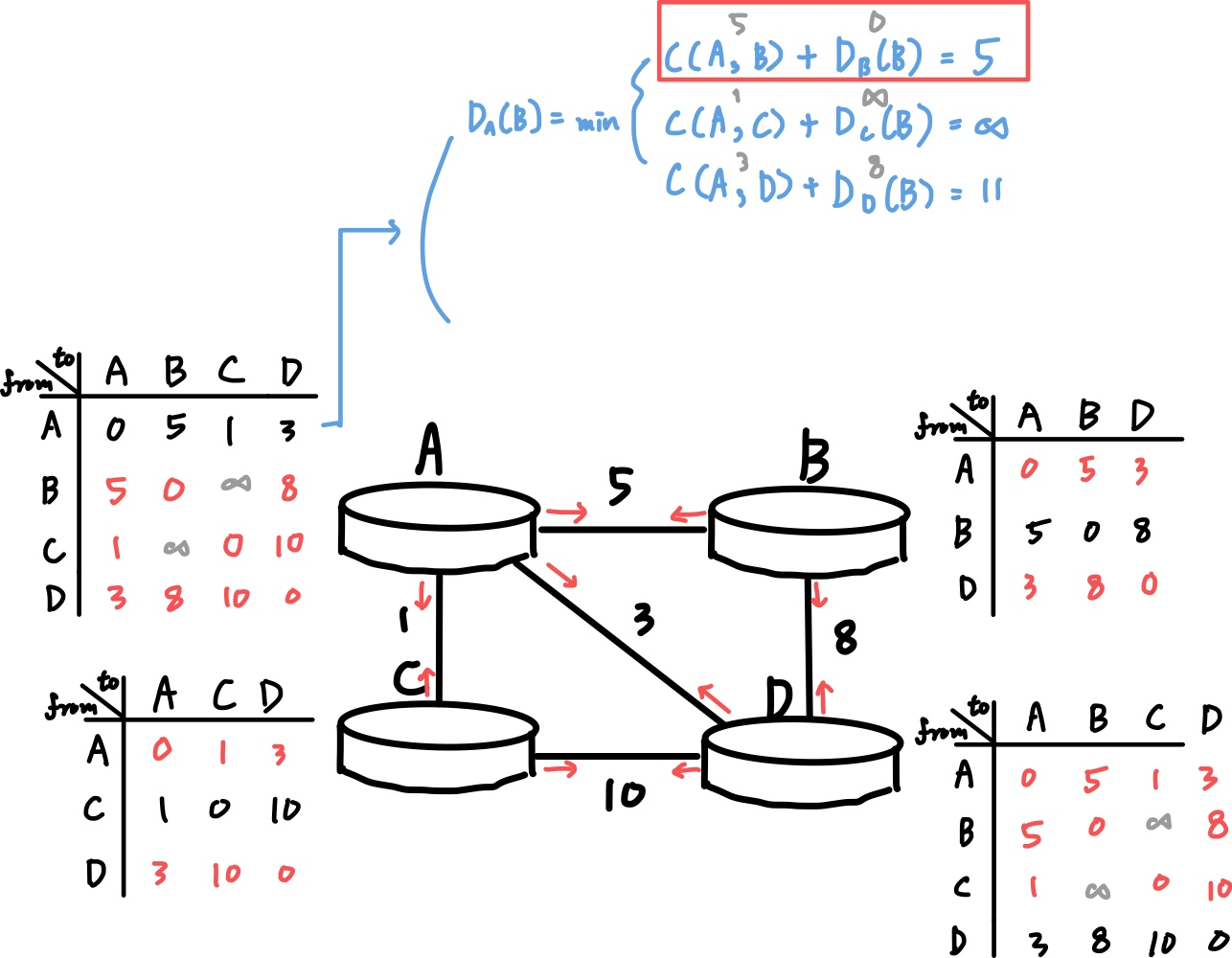
Source에서 Sink까지 최적 경로를 계산하고 싶어도, Distance Vector Algorithm은 물리적으로 연결된 인접 노드간의 정보 교환만이 일어나므로 LS Algorithm 같은 접근법은 사용할 수 없다.
대신 Source와 v1, v2, v3가 서로의 Distance Vector를 공유하기 때문에 해당 정보를 활용할 수는 있다.
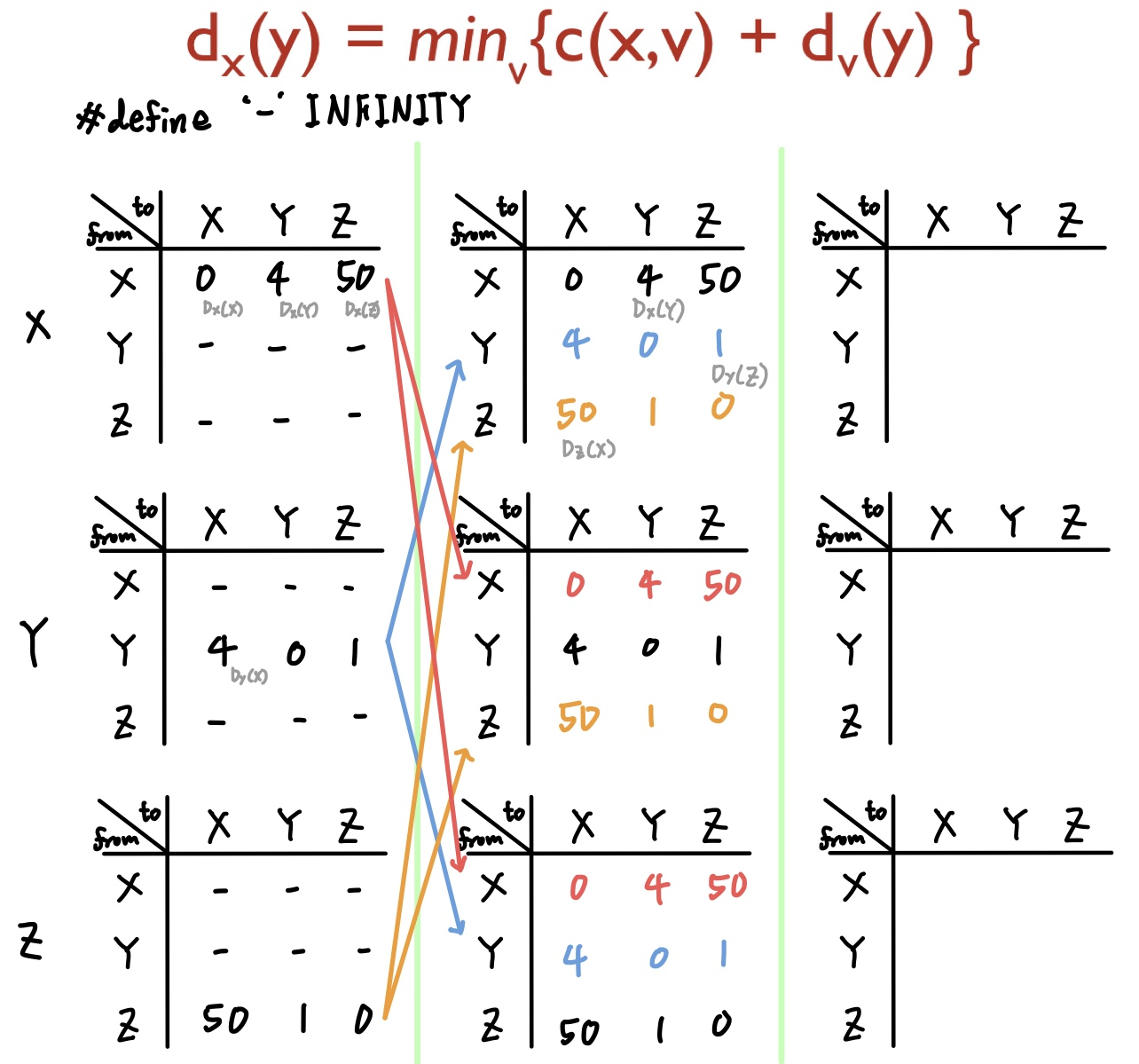
우선 테이블을 전체 초기화를 시켜준다.
그리고 각 노드는 주어진 정보만을 이용해서 자신의 distance를 업데이트한다.
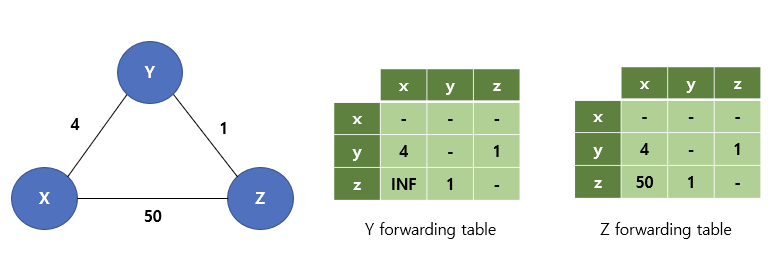
Vertex X, Y, Z는 모두 물리적으로 인접해있으므로 각자의 Distance Vector를 공유한다.
각각의 Vertex는 테이블을 전달받았다는 것은 곧 인근 노드에서 line cost의 변화가 있다고 판단하여 알고리즘을 수행한다.
(반드시 자신의 테이블에 있는 정보로만 판단하자!!!!)
모든 정점에 대해 과정을 서술하면 포스팅이 너무 방대해지므로 하나만 해볼 것이다.
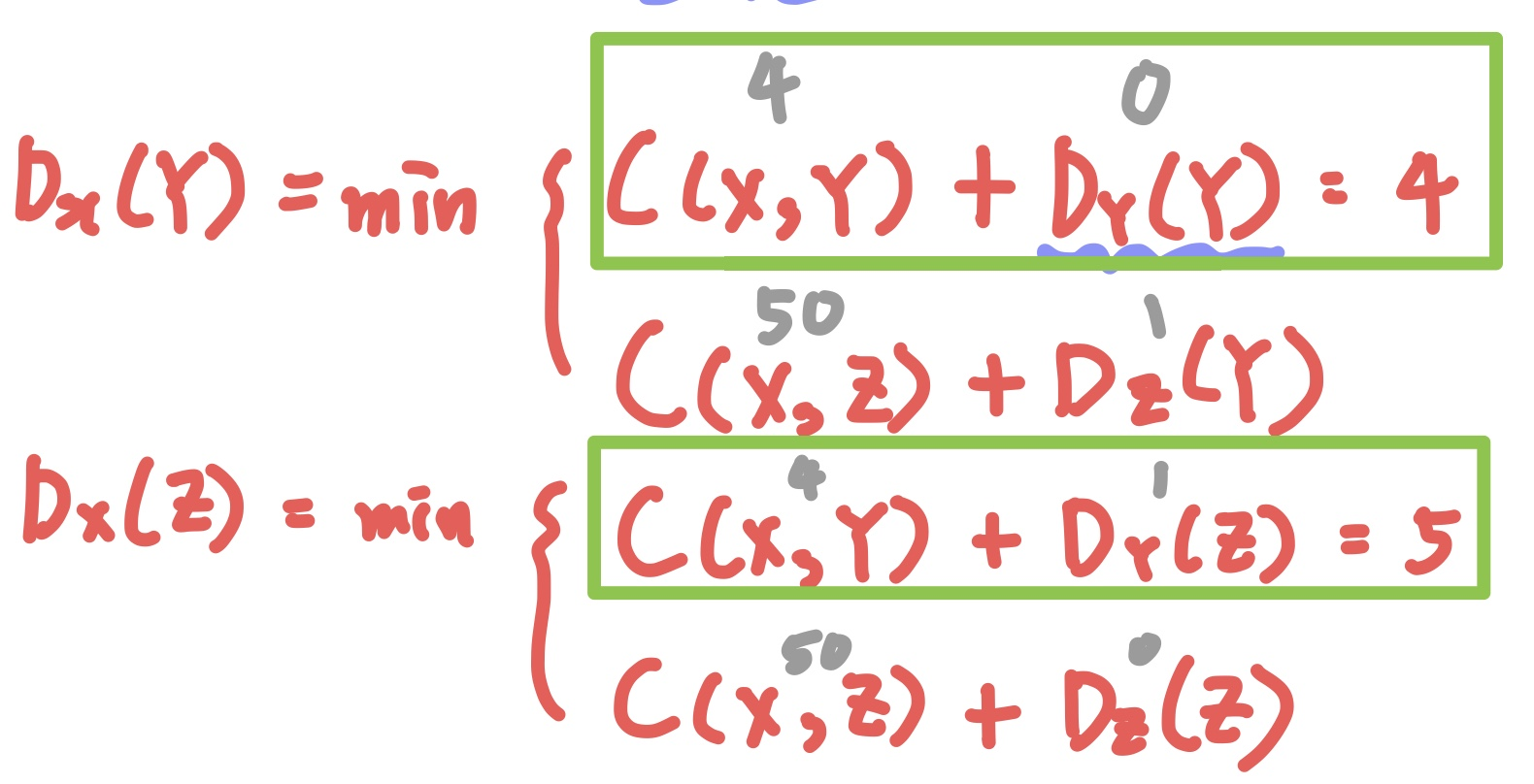
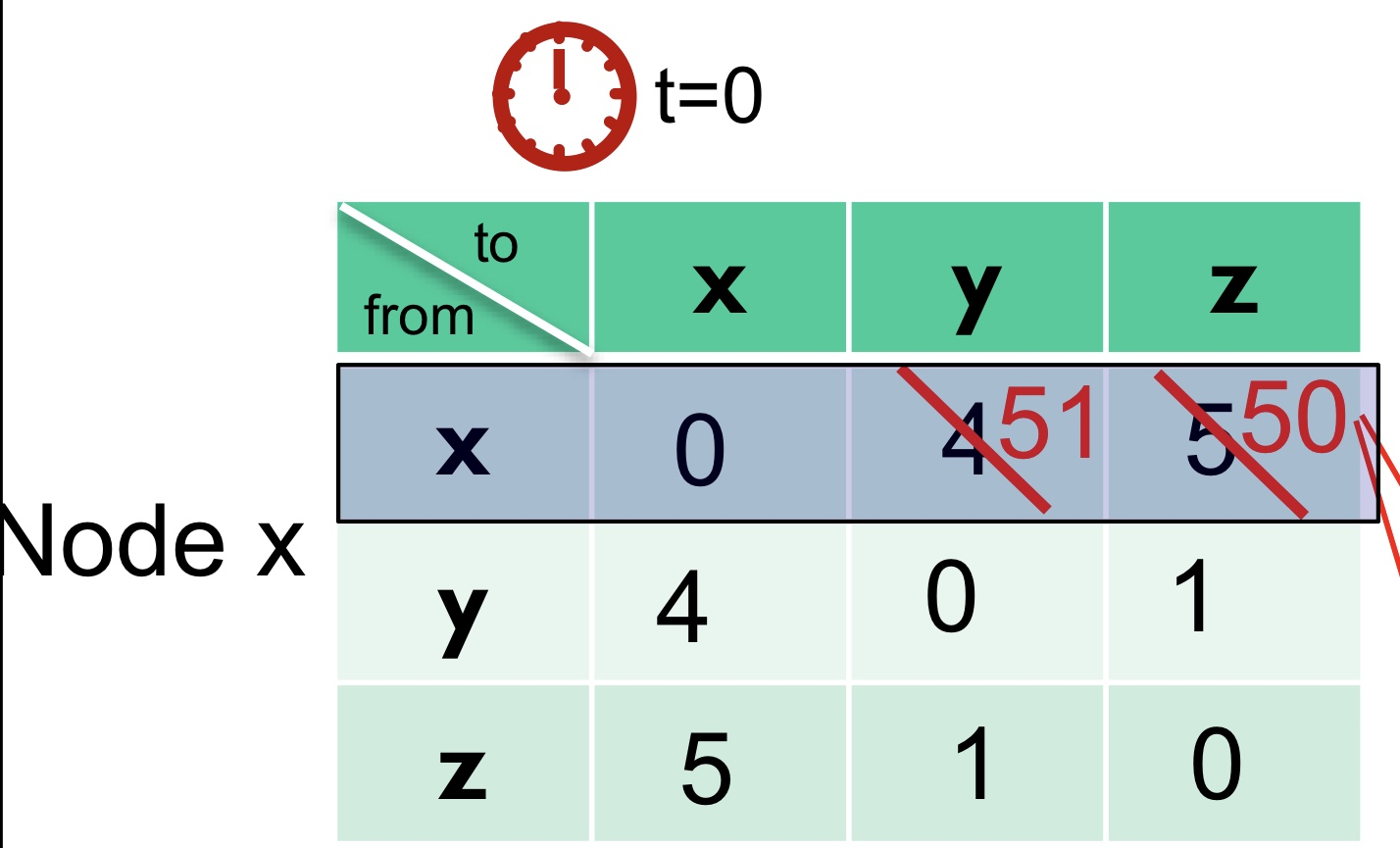
Vertex X의 현재 Distance Vector를 통해서 알고 싶은 정보는 \( D_{X}(Y), D_{X}(Z) \)이다.
\(D_{X}(Y)\)로 가는 경로는 X→Y와 X→Z→Y가 있으므로, 두 경로 중 최소 비용을 탐색한다.
테이블 정보에 따르면 \( C(X,Y)+D_{Y}(Y) = 4+0 = 4 \)이고, \( C(X,Z)+D_{Z}(Y) = 50+1 = 51 \)이므로 최소 비용은 4로 유지된다.
\(D_{X}(Z)\)의 경우에는 X→Z와 X→Y→Z가 있다.
\(D_{X}(Z) = min( C(X,Z)+D_{Z}(Z), C(X,Y)+D_{Y}(Z) )\)를 계산해보면, 처음에 물리적 link 정보로 판단했던 50이라는 값이, YZ Edge를 통해 다 빠른 경로를 탐색하게 되어 Update된다.
위의 과정을 통해 드디어 X 정점의 Distance Vector를 갱신했다!
Y, Z 정점은..이제 위 과정을 반복 수행해주면 된다. (노가다라니까?)
뭐, 어찌 잘 했다 치면 Step2의 최종 결과는 위와 동일하다.
값의 변화가 일어났으므로 Router는 다시 DV를 인접 노드들에 전파한다.
위에서 언급했듯이 이 알고리즘은 더이상 값의 변화가 없는 시점이 곧 종료 시점이라 판단하기 때문에 한 스텝을 더 넘어가야 한다.
Step3에서 위 내용을 반복하면 테이블 값이 어떠한 노드에서도 변경되지 않는 것을 알 수 있다.
이 알고리즘은 깊은 이해를 필요로 하지 않는다. 그냥 아래 절차만 유의하면 된다.
처음엔 자신이 알 수 있는 정보만을 기입해놓는다.
DV를 이웃끼리 공유하고, 각자 자신의 열의 최적 경로를 탐색한다. (다른 노드 정보는 건들지 말 것)
더이상 테이블 변화가 없거나, 이웃 노드로부터 DV가 넘어오지 않을 때까지 (2)번을 반복한다.
끝! 참 쉽죠?
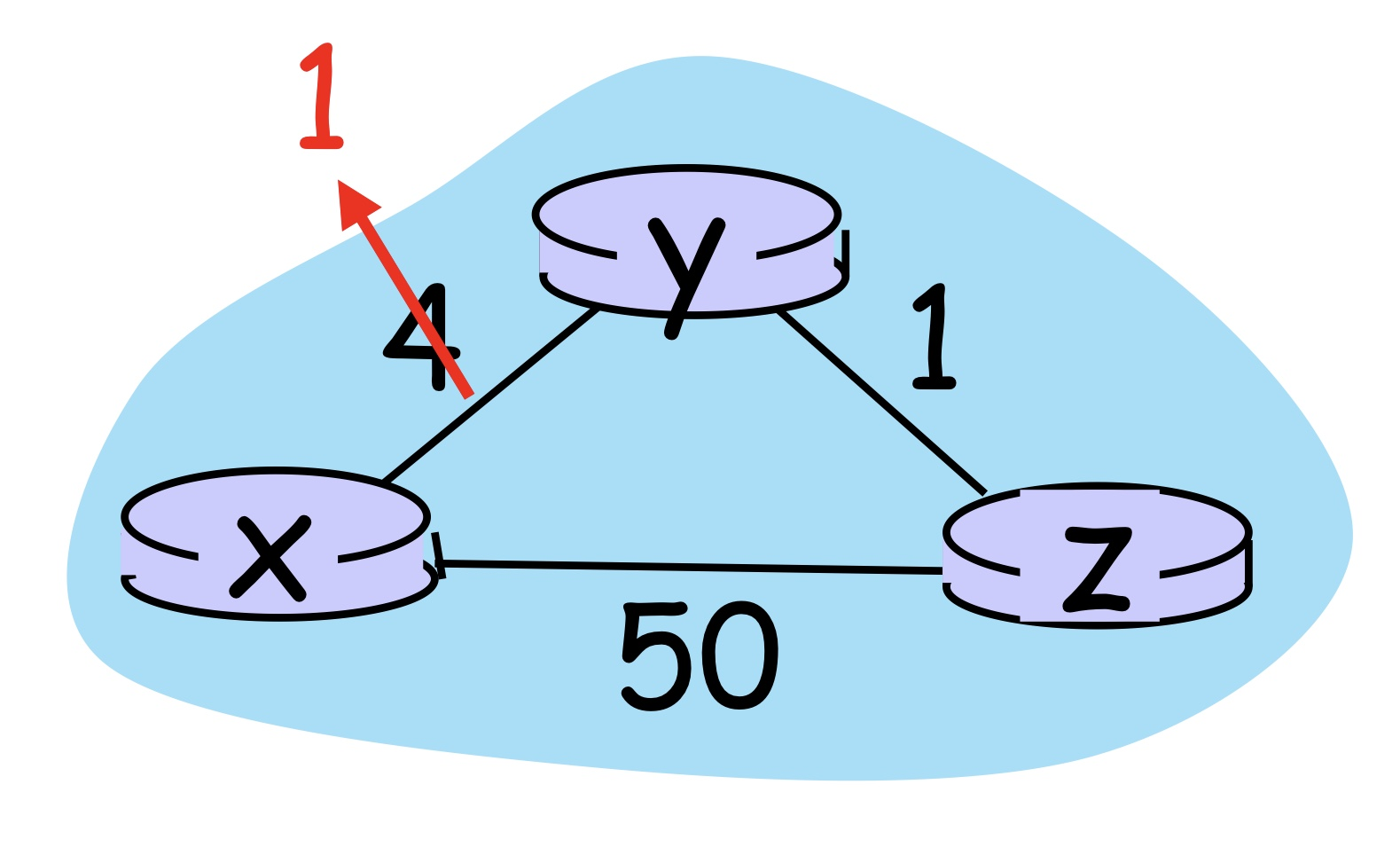
✒️ Issue. link cost changes : Count-to-infinity
좋은 소식과 나쁜 소식이 있다. 좋은 소식은 별 문제가 안 되지만, 언제나 나쁜 소식이 화를 불러 일으킨다. 처음 State에 대한 Distance Vector가 모두 갱신되어 있다는 것을 가정으로 한다.
(1) Good news travels fast
xy 가중치가 줄어들면 y가 DV를 업데이트하고 이웃들에게 알릴 것이다. 그럼 노드 z가 테이블을 업데이트하고 x로 향하는 최소 비용 경로를 갱신하고 다시 DV를 이웃에게 알린다. y의 최소 비용은 변하지 않으므로, 더이상 메시지를 보내지 않고 잘 종료될 것이다.
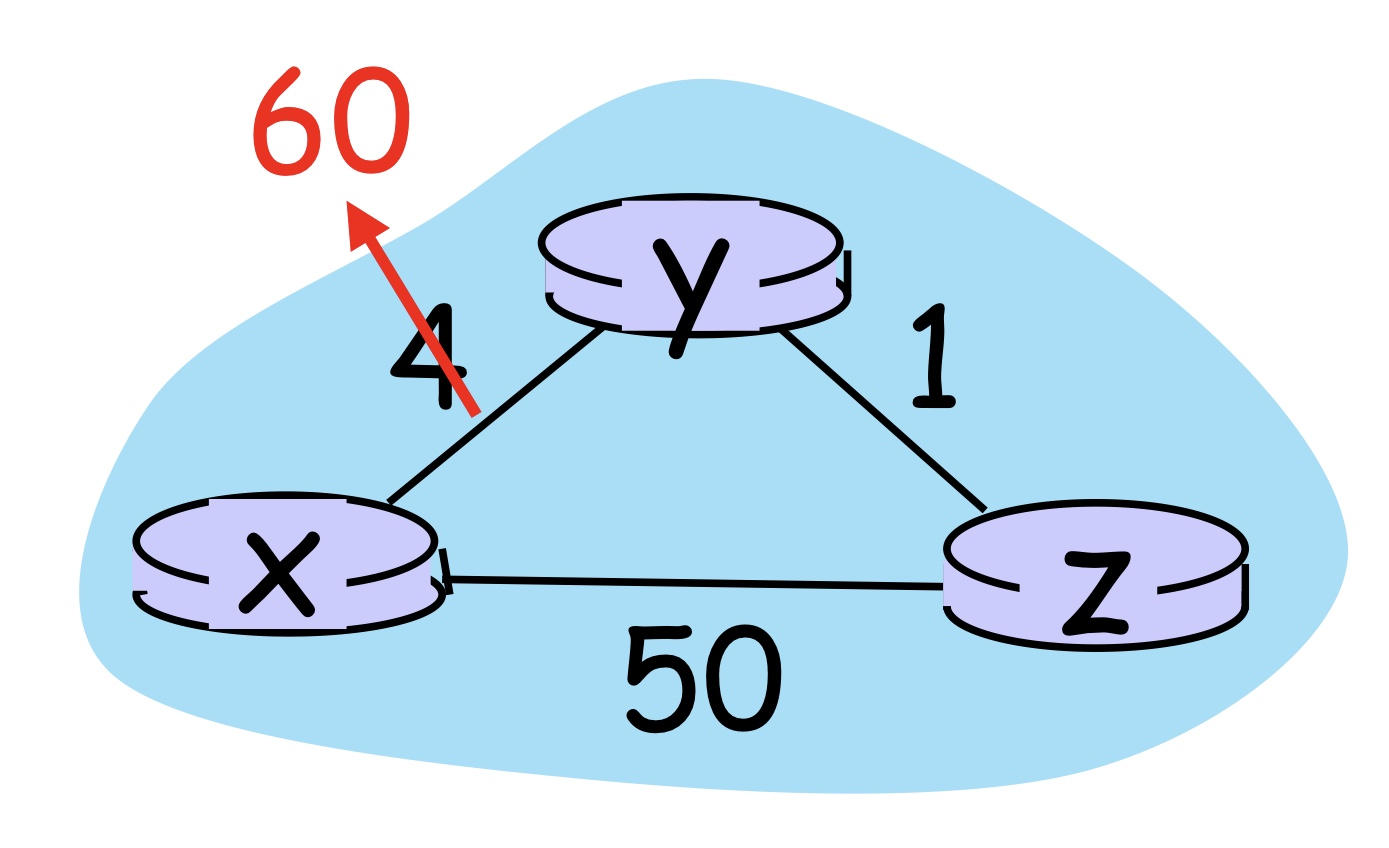
(2) Bad news travels slow : Count-to-infinity Problem
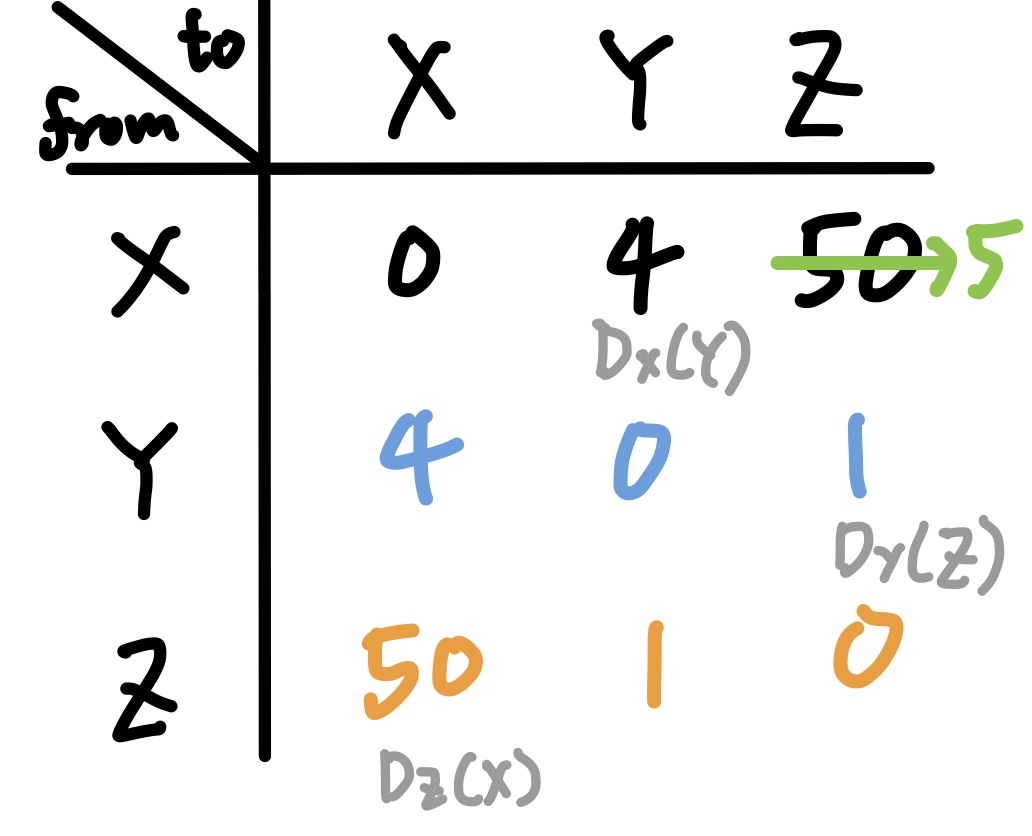
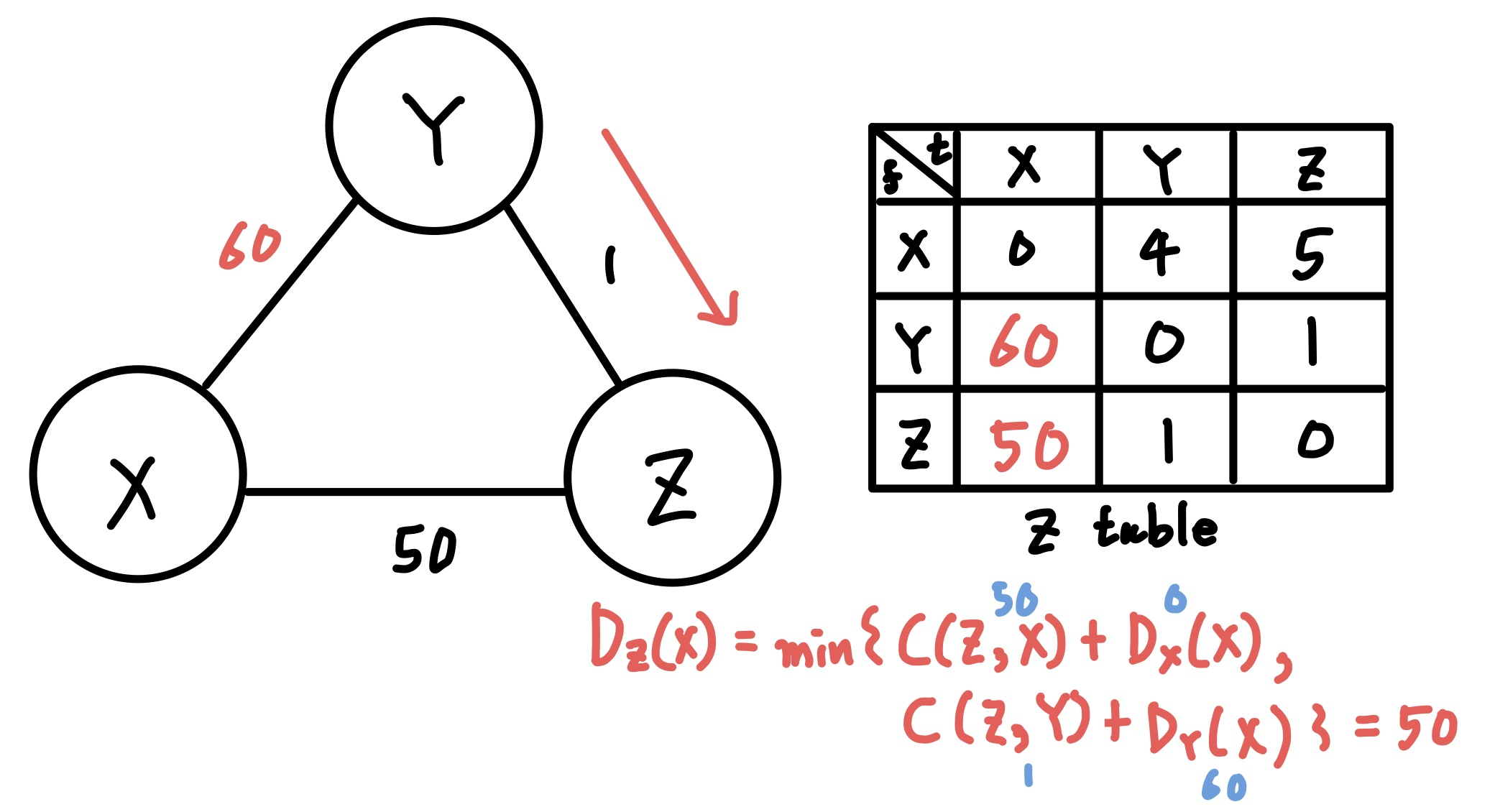
마찬가지로 Edge XY에서 값의 변화가 발생했다. 그러면 해당 간선에 물리적으로 연결된 노드 X와 Y에서 업데이트가 발생할 것이다.
\( D_{X}(Y) = min( C(X,Y)+D_{Y}(Y), C(X,Z)+D_{Z}(Y) ) = min(60+0, 50+1) \)이므로 X에서 Y로 가는 값은 무사히 변경되는 것을 확인할 수 있다.
문제는 Y에서 발생한다. C(Y,X)에 대한 정보는 측정한 수치를 가져오면 되니 상관없다. 그러나 \(D_{Z}(X)\)는 테이블에서 가져오는 수치를 이용한다. C와 달리 D라는 것은 결국 이전 가중치들을 기준으로 종합해놓은 최적 경로이므로 알고리즘이 오작동하기 시작한다. (오작동이라고 하기엔, 정상적으로 값을 도출하긴 하나 매우 비효율적으로 동작한다.)
이걸 약 50번 반복하면 정상적인 결과가 나온다.
\( D_{Z}(X) = 5 \)라는 값은 애초에 (Z→Y→X)경로를 통한 최적 경로 결과였다. 그러나 노드 Y 입장에선 그런 정보를 알 수 없다. 그냥 'Z에게 보내면 X에게 가중치 5밖에 안 들어가는 경로가 존재한다'라고 밖에 인지하지 못 하므로 DV를 업데이트 해서 보낸다. 노드 Z입장에서는 ZYX 경로를 사용하고 있었는데, Y에서 업데이트를 하라고 하니 가중치를 수정해서 DV를 보낼 것이다. 그럼 Y는 다시 \( C(Y, Z) + D_{Z}(X) \)에서 업데이트가 일어날 것이고, 위의 과정을 값의 변화가 없는 시점까지 반복한다. 에헤헤..한다..최적화.. 이 문제를 해결하는 방법은 여러 가지가 있다. 그 중에서 수업시간에 배운 방법은 "Poisoned Reverse", DV 정보에 독을 푼다는 방법이다.
✒️ Poisoned Reverse
Z노드가 Y→X 경로를 거치는 것이 최적 경로라면, Z노드가 Y노드에게 X노드로 가는 비용이 INF라고 전해버린다.
이유는 Z노드가 Y를 경유해서 X를 가는 것이 최적 경로라면, \( D_{Y}(X) < D_{Z}(X) \)는 언제나 참이어야 한다. 따라서, Y노드는 애초에 \(D_{Z}(X)\)라는 정보가 필요하지도 않았는데, 괜히 혼란만 야기한 셈인 것이다.
이렇게 하면 비록 처음 한 번은 잘못된 수치를 돌려줄 수는 있으나, 바로 다음 갱신 동작 때 Z가 독을 탄 DV 정보를 이용해 곧바로 최소 비용 경로를 찾아서 다시 전파할 수 있게 된다.
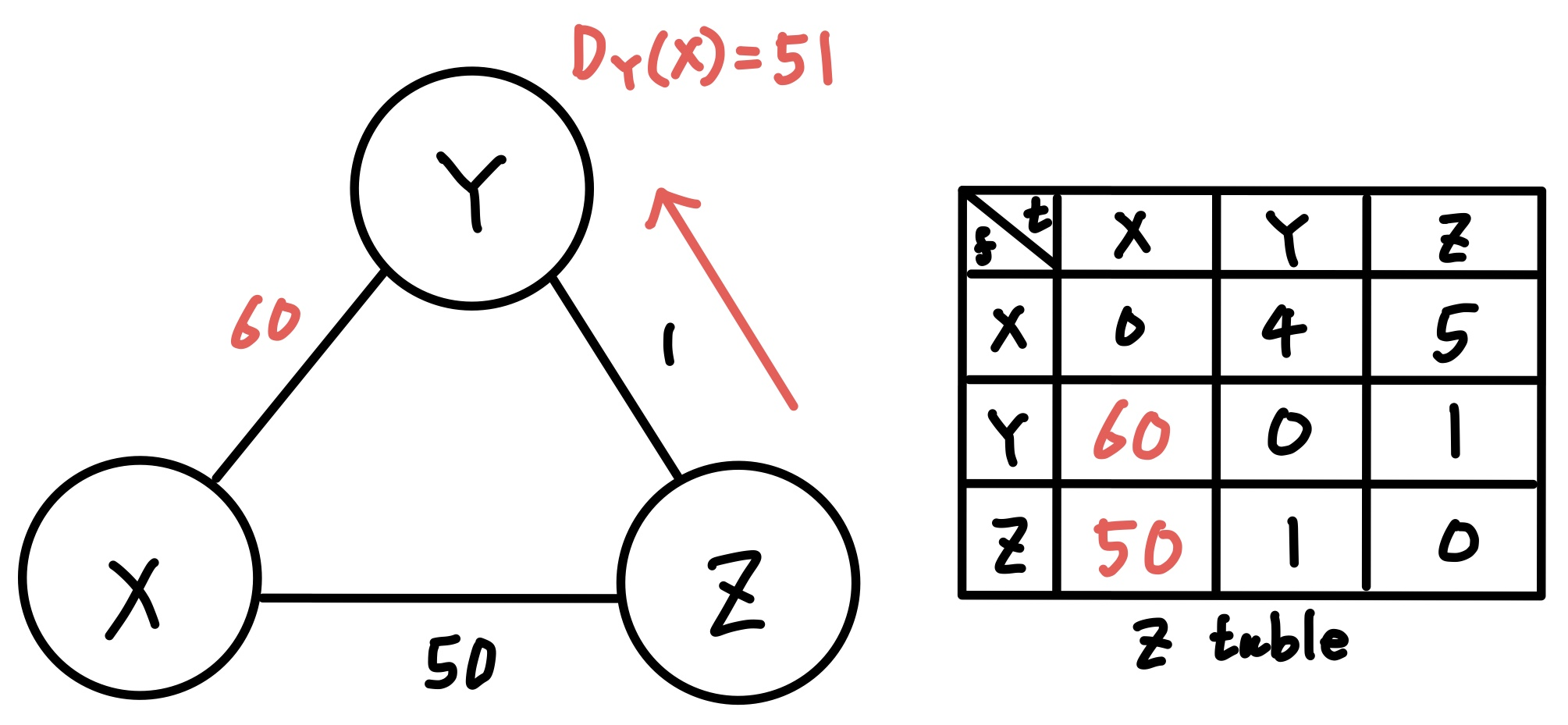
직접 해보면 된다. \(D_{Z}(X)\)에 무한대를 넣고 Y에게 던져주면, Y는 \(D_{Y}(X)\)를 60으로 초기화하여 전파한다.
Z 노드는 정상적인 DV 정보를 그대로 이용해서 갱신해주면 된다. 그럼 \(D_{Z}(X) = 50\)이라는 최적 경로(X→Z)를 찾아서 주위에 전파한다.
그럼 노드 Y는 다시 알고리즘을 돌려서 (Y→Z→X) 경로의 최적 경로를 찾고 \(D_{Y}(X)\)를 51로 수정한 후 다시 전파할 것이다.