Internet에서 Transport Layer protocol은 TCP와 UDP가 있다.
📌 TCP vs UDP
이제부터 신나게 TCP에 대해 알아보겠지만, 대략적으로 어떤 친구인지 알아보자.
TCP
신뢰할 수 있고, 데이터의 in-order 전송을 보장한다.
혼잡 제어(Congestion control), 흐름 제어(Flow control), 연결 설정(Connection Setup) 지원
정확도가 중요한 전송에서 쓰이는데, 실제로는 최근 케이블 성능이 좋아서 대부분 TCP를 사용한다.
UDP
신뢰할 수 없고, 순서를 보장하지 않는 전송 방식이다. (데이터 받는 대로 application으로 올린다.)
"하지만 빨랐죠?"같은 말이나 내뱉고 있는 애라고 보면 된다.
속도가 중요한 전송에서 쓰인다.
참고로 두 가지 방법 모두 지연 보장(delay guarantees)과 대역폭 보장(bandwidth guarantees)는 해주지 않는다.
이유는 이전에 Background에서 설명했던 packet switching 방식이 라우터에서 적용되고 있기 때문이다.
즉, 몇 초 후에 도착하고 대역폭을 얼마나 잡을 지는 transport layer의 역할이 아니라는 소리다.
📌 Transport vs Network Layer
Network Layer : 다른 host들과 논리적 대화
Transport Layer : 다른 host들의 application layer의 process들과 논리적 대화
🧐 뭐가 다른 걸까?
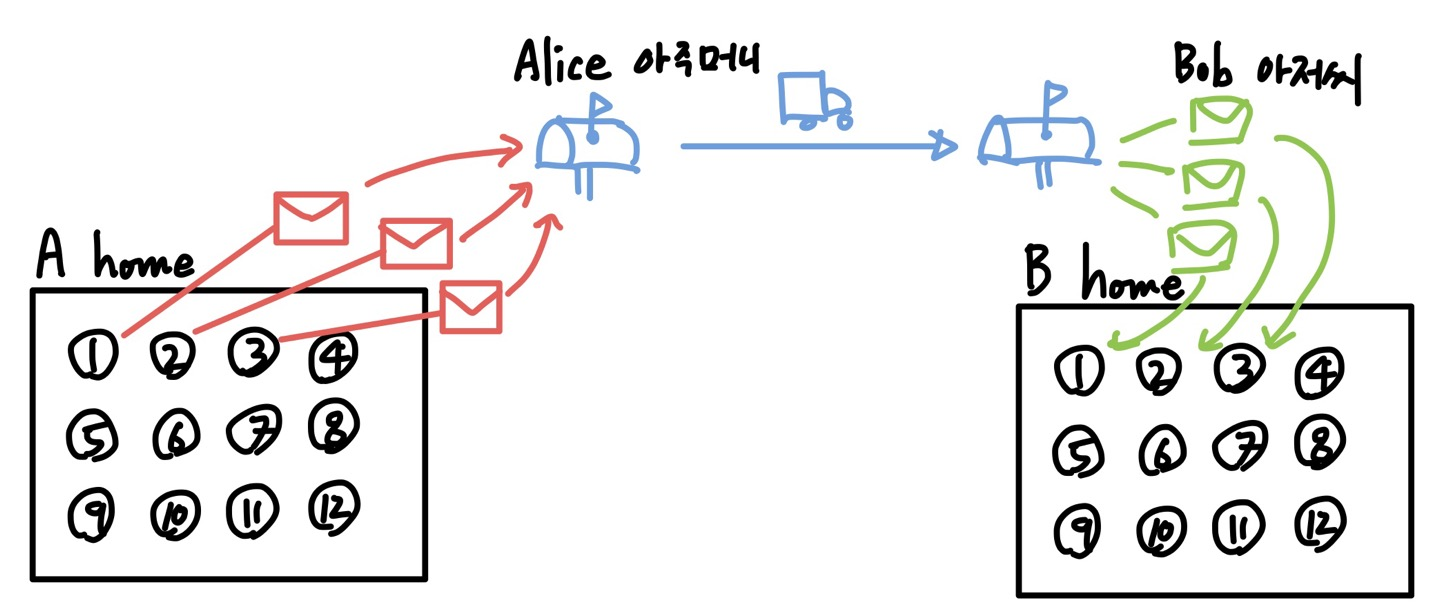
역할극을 통해 알아보자. • Hosts == A, B의 집 • Process == 자식들(숫자) • app messages == 편지 봉투 • Transport protocol == A(Alice)와 B(Bob) • Network-layer protocol == 우체국 서비스 Tranport 계층의 필요성
만약 A와 B의 집에 한 명만 살고 있고, 둘만 영원히 대화한다면 Transport Layer는 필요 없을 지도 모른다. (네트워크 관점에서만 봤을 때의 이야기다.) 하지만 A와 B의 집에는 수많은 자녀들이 살고 있고, A의 자녀들과 B의 자녀들이 서로 대화를 하고 싶다고 가정하면 문제가 복잡해지기 시작한다. A와 B가 없는 상황(Transport Layer가 없을 때)을 가정해보자. A-1과 B-3이 서로 편지를 주고 받고 싶다면, 어떻게 하는 것이 좋을까? 애석하게도 우체국 서비스(Network Layer)에서는 B의 집까지 전달해주기만 할 뿐 어떤 자녀에게 전달해주어야 하는지는 수행해주지 않는다. 따라서 B의 집까지 도달한 편지를 "누가" "누구에게" 보냈는 지를 관리하고, B-3가 A-1에게 답장을 보낼 때 도와주어야 하는 제어자가 필요하다는 것을 알 수 있게 된다.
2. Multiplexing & Demultiplexing
📌 As-is
하나의 host에는 여러 개의 process가 동작하고 있다보니, 통신을 위해서 식별자가 필요하다는 것을 깨달았다.
IP 주소를 이용해 host를 알아내고, Port Number로 process를 구분하게 되는데 한 가지 생각해볼 점이 있다.
IP주소가 Internet에서 특정 host를 찾기 위한 정보고, Port 주소가 해당 host에서 process를 구분하기 위한 정보니까 Transport 계층은 Port 정보만 알고 있으면 될까? 그렇지 않다.
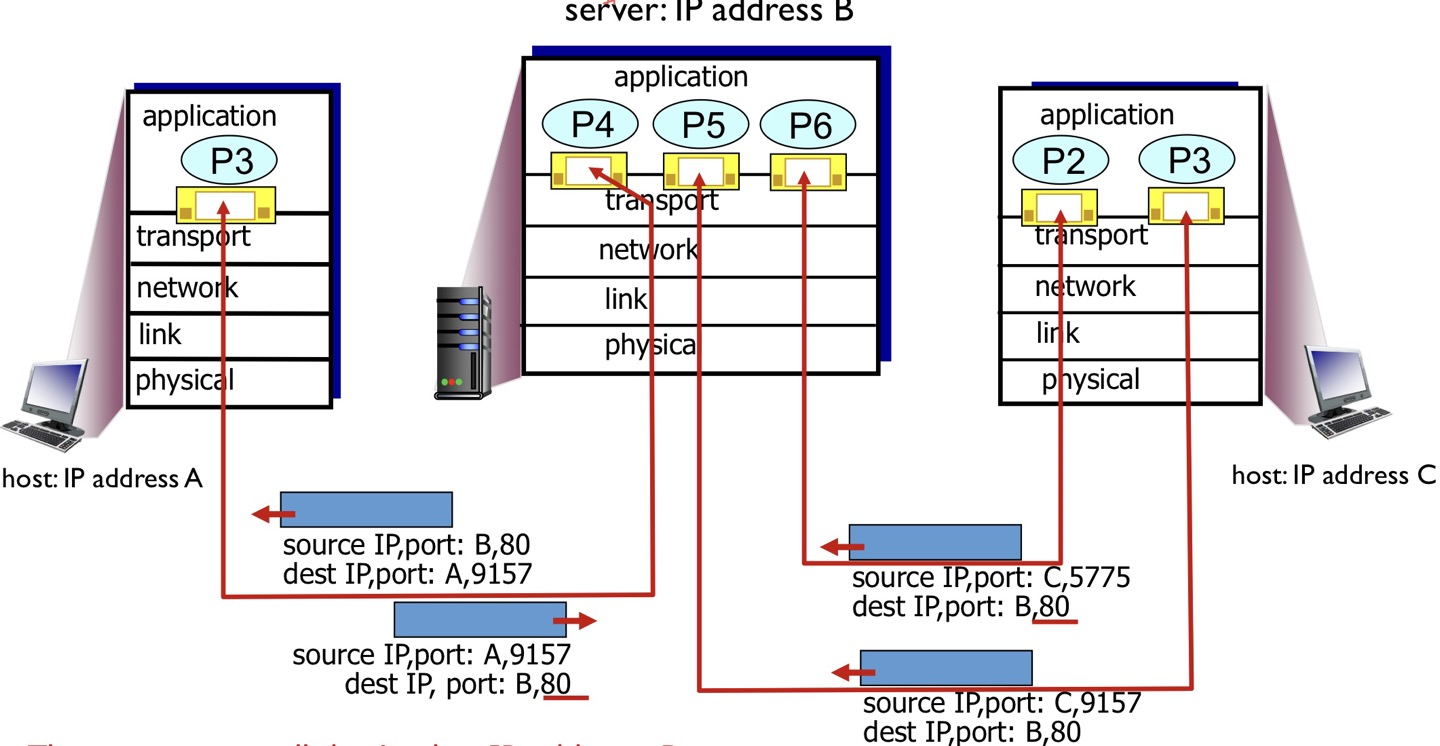
위의 예시로 들었던 A, B의 집에 C라는 이웃이 이사를 왔다고 생각해보자.
A-1이 B-3에게 편지를 보냈는데, C-1도 B-3에게 편지를 전송했을 경우 B-3는 A-1과 C-1 모두에게 답장을 주고 싶을 것이다. 문제는 IP 주소에 해당하는 A,C 정보가 없을 경우 1,1이라는 정보만으로 답장해야 할 상대를 판단해야 하는데 불가능한 일이다.
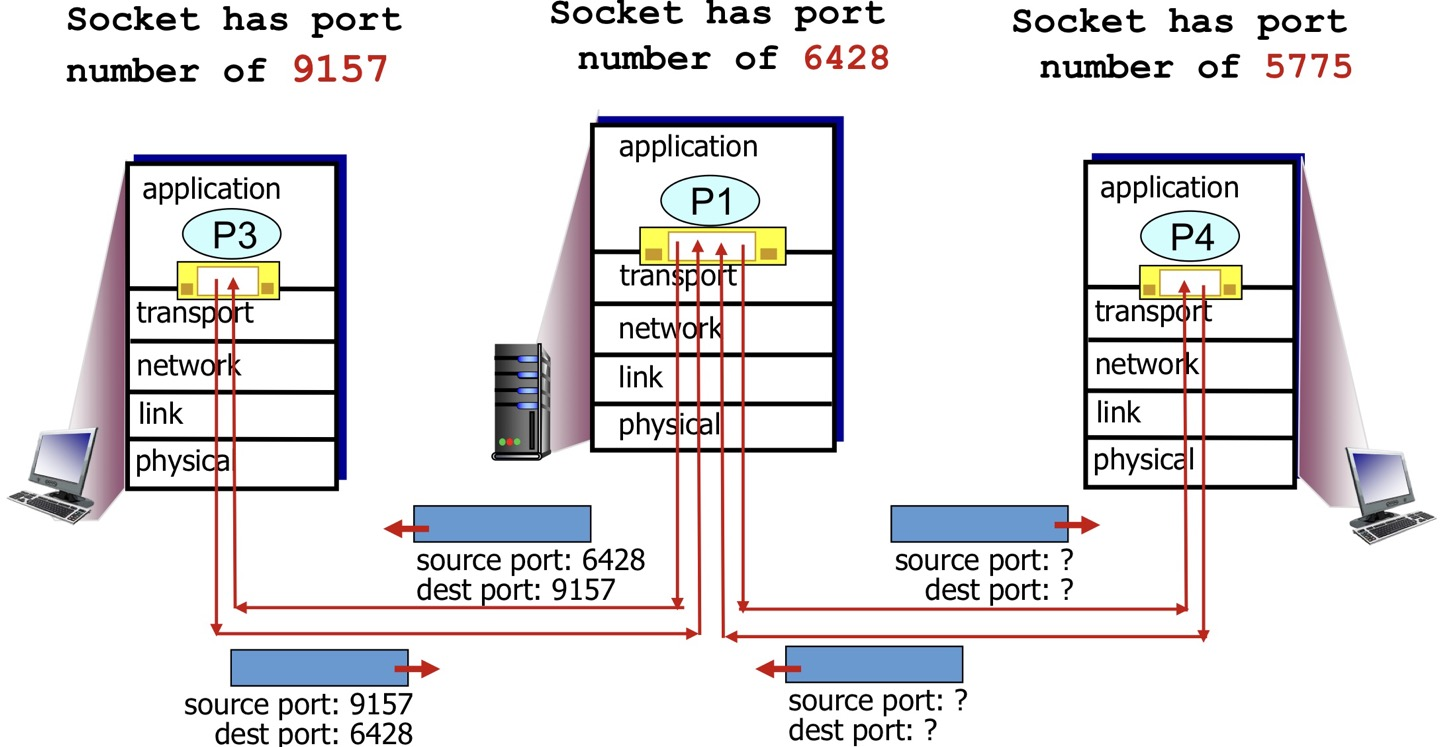
따라서 TCP Protocol은 계층 구조를 위배해서 Port 정보와 IP 주소 모두 알고 있어야 한다는 뜻이 된다!
소켓에 src와 dest ip/port를 모두 기록하고, 연결된 프로세스의 PID 정보가 담겨있다.
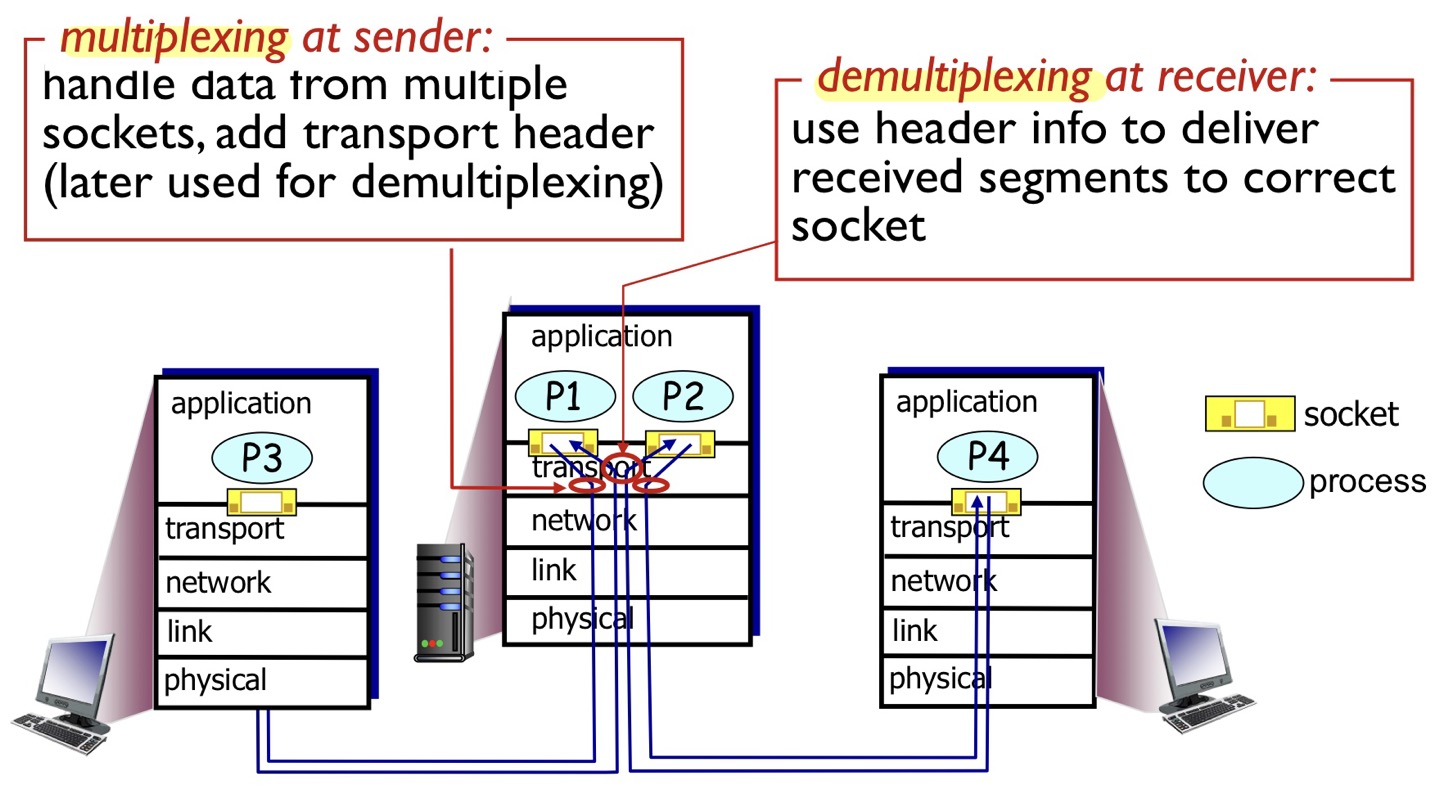
📌 Multiplexing & Demultiplexing
Multiplexing :sender 입장, Transport Layer가 socker으로 각 process들이 보낸 데이터들에 헤더 붙여서 하위 계층으로 내려주는 것
Demultiplexing :receiver 입장, Transport Layer가 하위 계층으로부터 받은 세그먼트의 헤더 정보를 보고 알맞은 socket에 올려주는 것
📌 UDP Demux vs TCP Demux
우선 Tranport Layer에서 Demultiplexing을 하기 위한 요구 사항이 존재한다.
각 socket은 유일한 식별자를 가진다
각 segment는 source와 destination의 IP 주소, Port 넘버 정보를 가지고 있다.
Segment가 host에 도착하면 Tranport Layer는 segment의 dest port number를 확인하고 알맞은 socket에 전송하는 것까진 동일하다.
UDP Demux
UDP는 비연결 지향(Connectionless)이라 소켓 연결 단계가 없다.
소켓 연결 단계가 없는 이유는 애초에 다중 접속이 되도록 디자인 되었기 때문이다. (packet을 추적하지 않는다.)
즉, 두 개 이상의 세그먼트가 출발지 IP, port#이 다르더라도, 동일한 IP, port#를 가진다면 동일한 socket을 통해 process에 전달된다.
UDP socket은 목적지 IP와 port # 두 요소로 구성된 집합에 의해 식별된다.
TCP Demux
TCP는 연결 지향(Connection-oriented)이라 대화하는 프로세스 간 정보를 가지고 있어야 하므로 소켓 연결 단계(3-way handshake) 과정을 선행한다.
1:1 통신을 하도록 디자인되어 있기 때문에 Web server는 각각의 클라이언트 마다 다른 socket을 사용한다.
TCP는 출발지와 목적지 IP, port# 4가지 정보로 소켓으로 구분한다.
✒️ 소켓 연결 단계
오랜만에 보니까 또 헷갈리는 개념이라 정리해두기로 했다. UDP처럼 목적지 IP와 port#만으로 상대 host의 process를 찾을 수 있는데, 왜 TCP는 모든 정보를 필요로 할까? 왜 클라이언트마다 소켓을 다르게 할당할까?
애초에 그렇게 디자인 되었기 때문이다. TCP의 목적은 정확도를 높이기 위함이므로 각각의 통신 상대마다 추적할 필요가 생겼다. 그러기 위해선 단순히 "데이터를 보냈다"가 아니라, 정말 잘 갔는지 등의 여부를 지속적으로 소통하면서 연결을 유지해야 하기 때문에 각각의 socket을 만들어 1:1 통신을 하는 것이다.
3. UDP : User Datagram Protocol
📌 특징
"No frills", "bare bones"
별 기능이 없는 Internet transport protocol
Multiplexing/Demultiplexing 기능만을 제공한다.
Application이 거의 IP와 통신하는 수준
"Best effort" service
UDP 세그먼트는 packet 손실이나 데이터 전송 순서를 보장하지 않는다.
그래놓고 "근데 일단 난 최선의 노력을 다했어!"라고 웃으며 날 쳐다보고 있는 셈이다. (열받네)
application이 신뢰성 있는 통신 기능을 구현한다면 UDP 상에서도 신뢰성을 보장할 수 있기는 하다.
application layer에서 재전송, 확인 응답의 기능을 구현해야 한다.
DNS와 이론 상으로는 속도가 중요한 스트리밍, 라이브 서비스에서 사용된다고 하나 요샌 거의 TCP를 사용한다.
UDP 헤더 구조는 아래와 같다.
필드명
길이(bit)
설명
src port#
16
패킷을 송신한 측의 포트 번호
dest port#
16
패킷을 건네줄 상대의 포트 번호
data length
16
UDP 헤더 + payload 길이
checksum
16
오류 유무 검사
✒️ Connectionless : 소켓 연결 단계인 handshaking이 존재하지 않는다!
📌 Why is there a UDP?
연결을 위한 단계가 없기 때문에 설정에 대한 딜레이가 없다.
연결 상태를 유지할 필요가 없으므로 많은 app을 수용할 수 있다.
헤더 사이즈가 8byte로 작다 (TCP는 20byte)
혼잡 제어를 하지 않으므로 application이 요구하는 전송량을 제한없이 전송한다.
📌 UDP checksum
목적 : 패킷을 받는 순간에 데이터가 깨졌는지 판단하여 "errors"를 검출한다.
sender
Segment의 content는 순서에 따라 16bit씩 끊어서 모두 더한다.
모든 16bit의 합을 가지 1의 보수를 취한다. (오버 플로우를 버리거나 wraparound로 이용한다.)
결과를 UPD segment checksum field에 삽입한다.
receiver
rcv도 똑같이 계산해보고 같으면 에러가 없다고 판단한다.
checksum field 자체가 오류가 있을 수 있긴 하나, 최근 기술력으로 checksum error가 발생하는 경우 자체가 극히 드물다.