소켓의 존재를 올해 처음 네트워크 스터디를 통해 처음 알아보긴 했었는데, 여전히 알 것 같다가도 종종 헷갈릴 때가 많다.
그래도 이론을 모두 공부해두고 프로그래밍 단계로 넘어가니 나름 할만하고 재밌긴 하다.
아직 실습에서 모든 내용을 안 나간 관계로 차근차근 수정해둘 예정~
목차 1. What is Socket? 1) Communication between Server & Client 2) Socket 2. Base Concept 1) Low Level I/O 2) File descriptor 3) Typical Socket Communication Flow 4) Protocol Family 5) Port Number 6) Structure for IPv4 Address 7) Host Byte Order VS Network Byte Order 8) Converting Dotted-Decimal Notation IP Addr to Integer 3. Client Side 1) gethostbyname : DNS Server로부터 IP 주소 조회 2) socket : 소켓 작성 3) connect : 소켓 연결 4) write : 송신 단계 5) read : 수신 단계 6) close : 파이프 분리 및 소켓 말소 4. Server Side 1) socket : 소켓 작성 2) bind : 소켓 정보 기입 3) listen : 접속 대기 4) accept : 접속 접수 5) read : 수신 단계 6) write : 송신 단계 7) close : 파이프 분리 및 소켓 말소
1. What is Socket?
소켓의 정의를 이야기 하는 것은 그리 어렵지 않다.
Transport Layer와 Application Layer 사이에서 매개체 역할을 해주는 하나의 파일이라고 보면 된다.
그런데 '소켓이 왜 필요하냐?'는 질문에 답하고자 한다면 아주 많은 기본 지식들을 필요로 한다.
학교 수업에서는 다루지 않았지만, 방학 때 미리 공부해놓아서 시험 기간에 생각보다 시간이 널널해진 관계로 가능한 만큼 작성해보려고 한다.
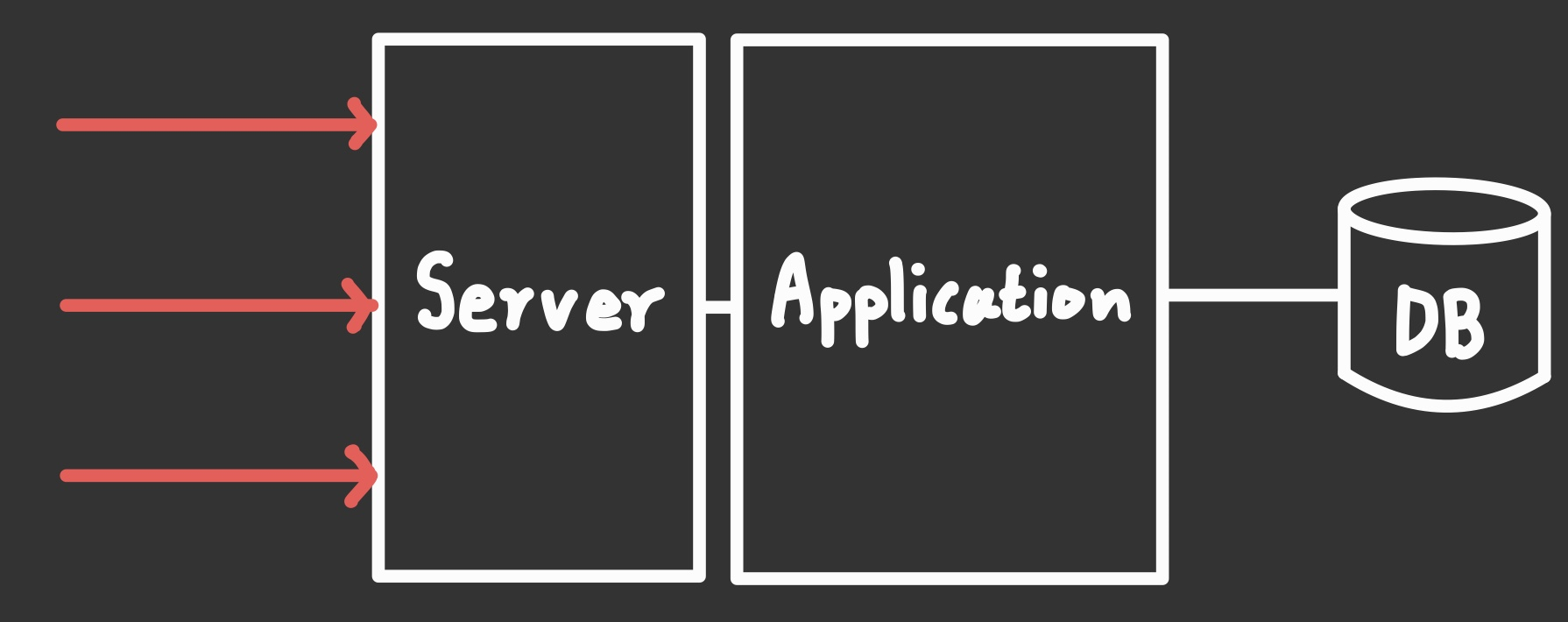
📌 Communication between Server & Client
클라이언트 입장에서는 1:1 통신이지만, 서버 입장에서는 1:N 통신을 수행해야 한다.
서버는 트래픽이 증폭해도 이를 견딜 수 있는 견고한 시스템을 구축해야 하는데, 이걸 가능하게 해주는 것이 소켓이다.
(실시간 양방향 통신을 가능하게 해주는 WebSocket과는 개념이 엄연히 다르다.)
우선 N명의 Client로부터 Request가 들어올 때, 동시에 요청을 처리할 수 있는 방법에는 무엇이 있을까?
가장 쉽게 생각해볼 수 있는 것은 Thread를 N개 생성하면 된다. (Process를 N개 준비하는 건 미친 발상이다.)
하지만 Thread를 사용해서 다수의 클라이언트 요청을 처리하는 것은 위험하다.
쓰레드 간 공유자원 관리: 쓰레드 간의 공유 자원을 관리하기 위해 복잡한 동기화 문제를 발생시킬 수 있으며, 쓰레드 간 경합 조건(race condition) 등의 문제점이 발생할 수 있다.
오버헤드: 쓰레드를 생성하고 관리하는 건 굉장히 큰 비용을 지불해야 한다. 쓰레드를 사용할 거라면 Pooling과 같은 방법들을 사용해야 하는데, 굉장히 까다롭다.
확장성 제한: 쓰레드는 CPU 코어 수에 제한을 받는다. 공간 복잡도 측면에서 바라보았을 때, N개의 Thread를 만든다는 것은 제한적이며, 리소스를 많이 잡아먹는다.
소켓이라는 건 서버와 클라이언트의 IP 주소, 포트 번호, 연결 상태 등을 기록해놓은 하나의 파일이다.
연결 정보들을 소켓들이 관리해줌으로써, 클라이언트의 요청마다 매번 새로운 프로세스 혹슨 쓰레드를 생성하지 않아도 된다.
만약, 병렬적으로 작업을 처리하고 싶어진다면 멀티플렉싱(Multiplexing) 구현을 위해 소켓 별도 쓰레드를 생성해주면 된다.
📌 Socket
Linux는 모든 것을 파일로 다루며, Socket도 일종의 파일이다.
(上) Linux, (下) Window
소켓이라는 건 결국 Protocol Stack이 참조하는 제어 정보들을 담고 있는 것이다.
통신하는 상대와 자신의 IP 주소, Port 번호, 통신 동장 진행 상태 등의 정보를 저장하고 관리한다.
Socket 라이브러리는 소켓을 구현하는 함수들을 모두 제공하고 있기에, 개발자는 별도의 구현없이 소켓을 사용할 수 있다.
OS 내부의 Protocol Stack에게 송신을 의뢰하면, Socket Library 내의 도구들이 '결정된 순번'대로 호출된다.
그리고 논리적인 파이프 라인이 모두 연결되고 나면, 상대에게 데이터를 쏟아 붓는 것이다.
2. Base Concept
📌 Low Level I/O
ANSI 표준 함수가 아니라, Linux 운영체제가 제공하는 함수 기반의 파일 입출력.
표준이 아니므로 다른 OS에 대한 호환성이 없다.
리눅스는 소켓도 파일로 간주한다. 따라서 저수준 I/O 함수를 기반으로 소켓 기반 데이터 송·수신 가능.
ex. open(), close(), write(), read(), ...
📌 File descriptor
Linux, Unix 계열 시스템의 프로세스가 파일에 접근하기 위해 구분해놓은 0이 아닌 정수값
fd 0 : 표준입력 (Standard Input)
fd 1 : 표준출력 (Standard Output)
fd 2 : 표준에러 (Standard Error)
파일 식별자로써 application이 받고 메모리에 저장해둔다.
Low Level I/O 함수는 인자로 파일 디스크립터를 받는다.
Low Level I/O 함수에게 소켓의 파일 디스크립터를 전달하면, 소켓을 대상으로 입출력을 진행한다.
📌 Typical Socket Communication Flow
소켓의 생성부터 소멸까지 일련의 순서를 따라야만 한다.
지금 보고 이해가 안 간다면, 밑에서 공부하다가 다시 찾아와서 흐름을 파악하는 것이 좋다.
왼쪽이 Client, 오른쪽이 Server
Client와 Server의 소켓 동작이 미묘하게 다른 것에 주의하자.
왜냐하면, 서버는 소켓을 만들고 기다리고 있다가 Client가 연결 요청을 함으로써 통신이 진행되기 때문이다.
📌 Protocol Family
이후에 소켓을 작성하기 위해, socket 함수에 몇 가지 정보들을 넘겨주어야 한다.
#include <sys/socket.h>
// <디스크립터1> = socket(<IPv4>, <TCP>, ...);
int socket(int domain, int type, int protocol); // 성공 시 fd, 실패 시 -1
domain: 소켓이 사용할 프로토콜 체계(Protocol Family) 정보 전달. (PF_INET 고정하면 됨)
PF_INET: IPv4 인터넷 프로토콜 체계
PF_INET6: IPv6 인터넷 프로토콜 체계
PF_LOCAL: Local 통신을 위한 UNIX 프로토콜 체계
PF_PACKET: Low Level 소켓을 위한 프로토콜 체계
PF_IPX: IPX 노벨 프로토콜 체계
type: 소켓의 데이터 전송방식에 대한 정보 전달. (TCP / UDP)
SOCK_STREAM: 연결지향형 데이터 전송 소켓, TCP
SOCK_DGRAM: 비연결지향형 데이터 전송 소켓, UDP
protocol: 두 컴퓨터간 통신에 사용되는 프로토콜 정보 전달.
두 번째 인자로 소켓 프로토콜이 정해지므로, 세 번째는 0을 전달해도 된다.
📌 Port Number
소켓 정보를 채우기 위해서 알아야 하는 Port 번호와 sockaddr 구조체에 대해 알아보자
#include <sys/socket.h>
// bind(<디스크립터1>, <포트 번호>, ...);
int bind(int sockfd, struct sockaddr *myaddr, socklen_t addrlen); // 성공 시 0, 실패 시 -1
sockfd: 주소 정보(IP와 PORT)를 할당할 소켓의 파일 디스크립터
myaddr: 할당하고자 하는 주소 정보를 지니는 구조체 변수의 주소값
addrlen: 두 번째 인자로 전달된 구조체 변수의 길이정보
IP 주소로 목적지까지 잘 도착했다 하더라도, Host에는 여러 프로세스가 동작하고 있을 것이다.
이 중에서 실제로 데이터를 받아야 하는 프로세스까지 전달하기 위해서 Port라는 개념이 도입되었다.
즉, Port란 네트워크를 통해서 데이터를 주고받는 프로세스를 식별하기 위해서 호스트 내부적으로 프로세스가 할당받는 고유한 값이 된다.
포트와 소켓은 1:N 관계이기에 하나의 포트에는 여러 소켓이 연결될 수 있다.
하나의 프로세스는 같은 프로토콜, 같은 IP 주소, 같은 포트 넘버를 가지는 여러 소켓을 만들 수 있다. (파일을 만들 수 있는만큼 가능하다.)
그러나 같은 정보를 담고 있는 소켓이어도 fd로 application이 모두 구분할 수 있는 것이다.
Port 번호는 16비트(0 ~ 65535)로 표현하는데, Well-known Port(0 ~ 1023)은 용도가 결정되어 있다.
📌 Structure for IPv4 Address
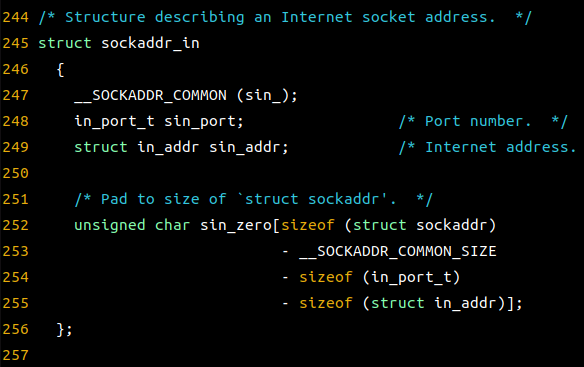
struct sockaddr_in
{
sa_family_t sin_family; // 주소체계: 항상 AF_INET
uint16_t sin_port; // Port num: 16-bit short Type
struct in_addr sin_addr; // 32-bit IP주소: 정수타입 구조체
char sin_zero[8]; // 사용하지 않음 -> 0 유지
}
sin_family
주소 체계 정보를 저장한다.
사실상 무의미한 정보이며, 항상 AF_INET으로 채우면 된다. (IPv4)
예전에는 다양한 체계가 있을 거라 생각해서 유연하게 대응하기 위해 준비했으나 필요가 없게 되었다. 그렇다고 지우면 데이터를 읽는데 문제가 생기므로 padding 값을 채운다고 생각하면 된다.
굳이 이렇게 번거롭게 하는 이유는 역사적인 이야기가 포함되어 있다. 과거 개발 당시에는 "미래에 IPv4 뿐만 아니라 다양한 주소 체계가 나올 것이다!"라고 생각했고, sockaddr을 다양한 주소체계의 주소정보를 담을 수 있도록 정의한 구조체였다. 주소 정보를 개발자가 원하는 Port 번호와 IP 주소를 표현하도록 유도하였으나, 문제는 이게 너무 어렵고 귀찮은 과정이었다. (애초에 불필요하기도 했고) 따라서 개발자들은 보다 실용적인 sockaddr_in 구조체를 다시 만들어 사용하게 되었고, 중간중간 불필요한 과정이라고 생각되는 부분들은 이런 흐름에서 발생한 부산물들이라고 보면 된다.
📌 Host Byte Order VS Network Byte Order
주소를 저장하는 방식은 CPU 제조사 별로 다르다.
4byte 메모리 주소를 나누어 저장하는 방식
Host Byte Order:
CPU별 데이터 저장 방식
빅 엔디안(Big Endian): 상위 바이트의 값을 작은 번지수에 저장. (낮은 번지부터)
리틀 엔디안(Little Endian): 상위 바이트의 값은 큰 번지수에 저장. (큰 번지부터)
Network Byte Order
통일된 데이터 송수신 기준
Big Endian 기준
빅 엔디안 방식을 사용하는 CPU와 리틀 엔디안을 사용하는 CPU가 데이터 통신을 하게 되면 문제가 발생할 수 있기 때문에, 통신을 할 때는 빅 엔디안을 기준으로 통일하게 되었다.
✒️ 바이트 변환함수
unsigned short htons(unsigned short); // host → network (short)
unsigned short ntohs(unsigned short); // network → host (short)
unsigned long htonl(unsigned long); // host → network (long)
unsigned long ntohl(unsigned long); // network → host (long)
📌 Converting Dotted-Decimal Notation IP Addr to Integer
#include <arpa/inet.h>
// 성공 시 빅 엔디안으로 변환된 32-bit 정수값, 실패 시 INADDR_NONE 반환
in_addr_t inet_addr(const char *string);
Dotted-Decimal Notation은 인간 친화적인 표현이므로, 컴퓨터 입장에서는 당연히 달갑지 않을 것이다.
inet_addr()은 Dot을 모두 제거하고, 빅 엔디안 순서의 32-bit 정수값으로 변환시켜준다.
순서까지 모두 내부적으로 바꿔주고 있기 때문에 hton() 함수를 굳이 다시 호출해주지 않다도 된다.
아래의 예시 코드를 분석해보자.
int main(int argc, char *argv[]) {
char *addr1="1.2.3.4"; // Dotted=Decimal Notation
char *addr2="1.2.3.256";
unsigned long conv_addr=inet_addr(addr1); // Big endian, 32bit int type
if (conv_addr == INADDR_NONE)
printf("Error occured! \n");
else
printf("Network ordered integer addr: %#lx \n", conv_addr); // 0x4030201
conv_addr=inet_addr(addr);
if (conv_addr==INADDR_NONE)
printf("Error occured! \n"); // error 걸림
else
printf("Network ordered integer addr: %#lx \n", conv_addr);
return ;
}
addr1은 정상적으로 출력이 되겠지만, addr2의 경우에는 1byte 범위를 초과하는 256이라는 값이 들어갔으므로 예외처리에 걸리게 된다.
#include <sys/socket.h>
// <디스크립터1> = socket(<IPv4>, <TCP>, ...);
int socket(int domain, int type, int protocol); // 성공 시 fd, 실패 시 -1
2️⃣ bind : 소켓 정보 기입
#include <sys/socket.h>
// bind(<디스크립터1>, <포트 번호>, ...);
int bind(int sockfd, struct sockaddr *myaddr, socklen_t addrlen); // 성공 시 0, 실패 시 -1
3️⃣ listen : 접속 대기
#include <sys/socket.h>
// listen(<디스크립터1>, ...);
int listen(int sockfd, int backlog); // 성공 시 0, 실패 시 -1
소켓의 제어정보에 접속 대기 상태를 기록한다.
sockfd
연결요청 대기상태에 두고자 하는 소켓 파일 디스크립터 전달
이 함수의 인자로 전달된 디스크립터의 소켓이 서버 소켓(리스닝 소켓)이 되며, 클라이언트와 연결될 때는 복사본을 만들어 연결시킨다. (원본은 건들지 않음)
backlog
연결요청 대기 Queue의 크기 정보를 전달
5가 전달되면 큐의 크기가 5가 되어서, 클라이언트 연결요청을 5개까지 대기시킬 수 있다.
4️⃣ accept : 접속 접수
#include <sys/socket.h>
// <디스크립터2> = accept(<디스크립터1>, ...);
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen); // 성공 시 fd, 실패 시 -1
서버 Application 기동 후 즉시 이 단계까지 호출되며, 접속 패킷이 오기 전까지 대기한다. (일종의 Blocking 함수)
함수 호출이 완료되면, 인자로 전달된 클라이언트 주소 정보를 기입한 소켓(복사본) 파일 디스크립터를 돌려준다.
sockfd
서버 소켓(원본)의 파일 디스크립터를 전달한다
addr
연결요청을 한 클라이언트 주소정보를 담을 변수의 주소 값을 전달한다.
addrlen
두 번째 매개변수 addr에 전달된 주소의 변수 크기를 Byte 단위로 전달한다.
단, 크기정보를 변수에 저장한 다음에 변수의 주소 값을 전달한다.
함수가 종료되면 클라이언트 주소 정보 길이를 OS가 채워준다.
✒️ 왜 복사본을 돌려주는 건가?
소켓을 작성하는 것은 일련의 순서를 따라야만 한다. 작성(socket) → IP, Port번호 기입(bind) → 리스닝 소켓 지정(listen) → 접수 대기(accept) 이렇게 기껏 만들어 놓은 소켓이 클라이언트 요청이 들어왔다고 원본에 매칭시켜주게 되면, 다음에 요청을 보낸 클라이언트는 접속 대기 소켓이 존재하질 않으므로 연결할 수가 없다. 그렇다고 연결될 때마다 매번 처음부터 소켓 작성 과정을 반복하는 것은 비합리적이다. 따라서, 서버측 IP와 Port번호가 동일한 소켓에 클라이언트 개별의 IP, Port 번호를 기록한 복사본을 만들어주는 것이 좋다.
5️⃣ read : 수신 단계
#include <unistd.h>
// <수신 데이터 길이> = read(<디스크립터2>, <수신 버퍼>, ...)
ssize_t read(int fd, void *buf, size_t nbytes); // 성공 시 수신 바이트 수(파일 끝 0), 실패 시 -1
6️⃣ write : 송신 단계
#include <unistd.h>
// write(<디스크립터2>, <송신 데이터>, <송신 데이터 길이>);
ssize_t write(int fd, const void *buf, size_t nbytes); // 성공 시 전달 바이트 수, 실패 시 -1
7️⃣ close : 파이프 분리 및 소켓 말소
#include <unistd.h>
// close(<디스크립터2>);
int close(int fd); // 성공 시 0, 실패 시 -1