목차
1. Layering
1) Why Layering?
2) Network Layer
2. Interplay Between Routing and Forwarding
1) Two Key Network Layer Function
2) fowarding table
3) Longest Prefix Matching
4) Per-router Control Plane VS SDN(Software-Defined Networking) Control Plane
3. IP Protocol
1) IP datagram format
2) IP Adress (IPv4)
3) IP Addressing
4. Subnets
1) Concept
2) IP Fragmentation & Reassembly
3) IPv6
5. NAT (Network Address Translation)
1) NAT (Network Address Translation)
2) PAT (Port Address Translation)
3) PF (Port Forwarding)
1. Layering
📌 Why Layering?
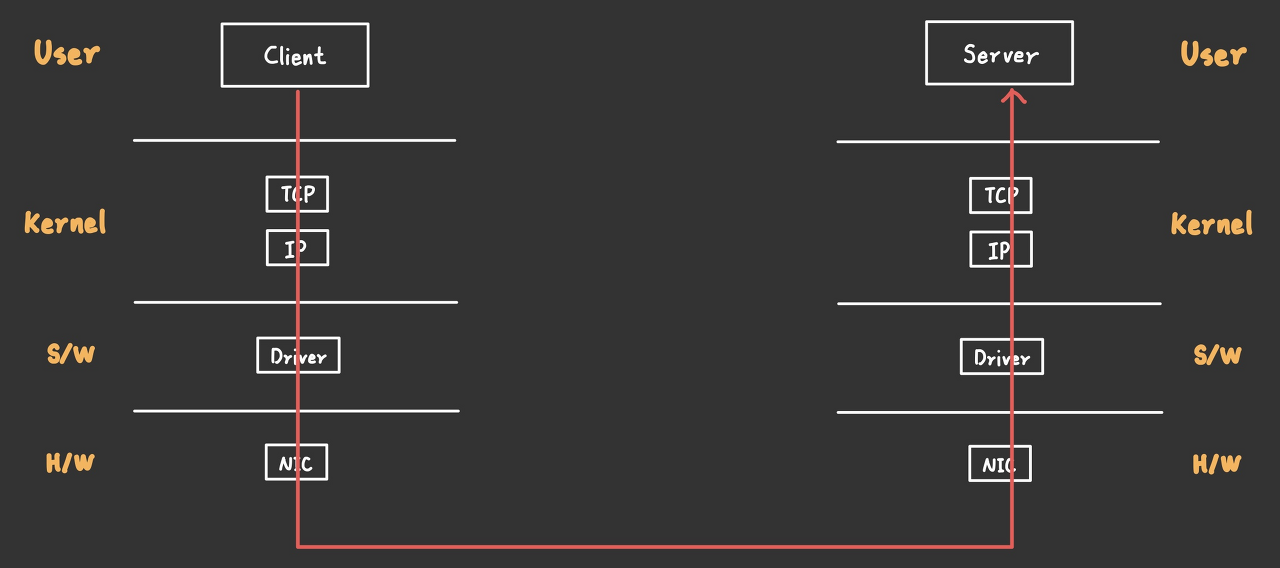
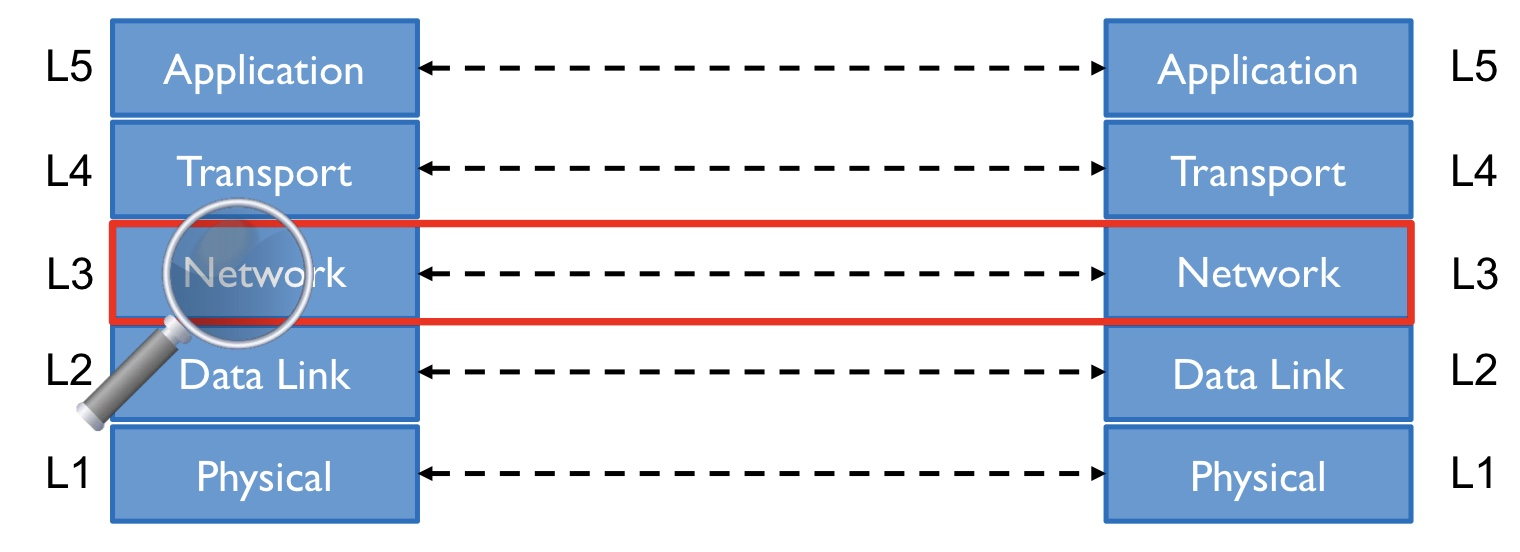
계층 분리를 통해 얻을 수 있는 가장 큰 장점은 "역할 분담"이다.
각 계층마다 역할이 나누어져 있기 때문에 인터페이스 정의가 명확하고, 성능을 개선시킬 때도 다른 레이어들을 신경쓰지 않고 해당 레이어만 수정하면 된다.
SOLID 원칙에서 단일 책임 원칙을 떠올려보면 된다. 개발자들은 언제나 모든 역할을 수행하는 하나의 완전한 존재보다, 각자의 일을 잘 수행하는 여러 함수나 객체들의 상호작용을 통해 SW를 구현하는 것을 선호한다.
- 복잡도가 제거된다
- 유연성이 증가한다
다만, 이 방식에도 단점이 존재하기는 하는데 서로의 역할이 정해져 있기 때문에 성능 최적화에 한계가 존재한다는 점이다.
예를 들어, Transport에서 가지고 있으면 훨씬 유용한 정보들을 Network 레이어에서 가지고 있다면, 다른 레이어 정보를 알 수 없다는 한계로 인해서 함수를 호출해야 한다는 오버헤드가 발생한다.
혹은 라우터가 Transport layer 정보를 읽어 이메일보다 영상 트래픽을 우선시 하도록 만들 수도 있겠지만, 라우터는 L3 장비이므로 Transport layer 정보를 읽을 수 없기 이런 방법이 막히는 경우도 존재한다.
이런 단점들을 보완하기 위해 레이어를 위배(layer violations)하는 Cross-layer information이 종종 사용된다.
즉, 기능을 완전히 분리하기 보다, 다른 레이어 정보를 읽는 게 때론 유용하기에 고의적으로 규칙을 깨는 것이다.
📌 Network Layer
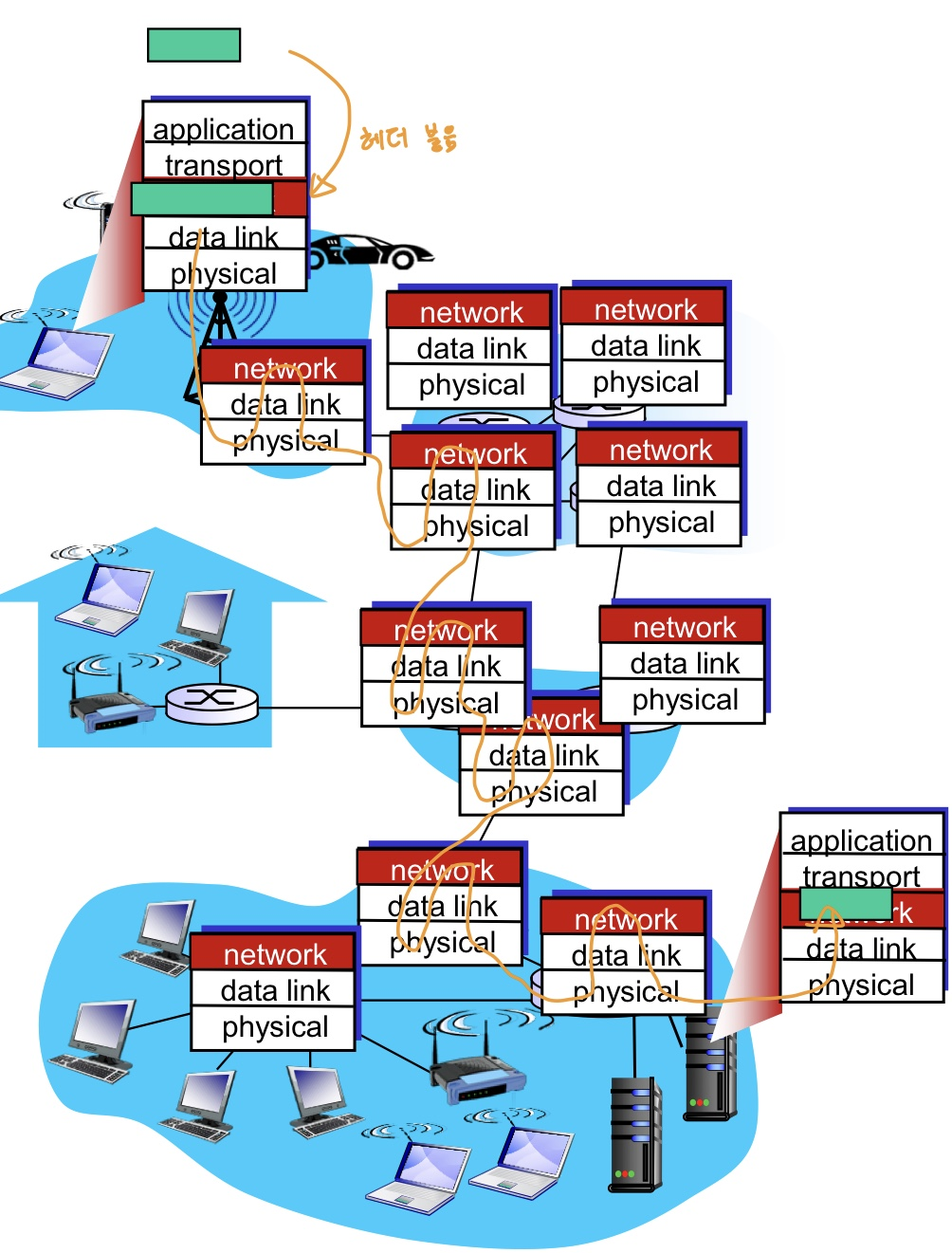
Network Layer Protocol은 모든 host와 router이 지켜야하는 약속이다.
Client가 TCP/IP 통신으로 Request를 보냈을 때, segment(message + TCP header)에 IP Header 등을 붙여서 one-hop 이동하여 라우터에 보내진다.
Router의 역할은 Server까지 잘 전달하는 역할만 수행하면 되므로 Segment 정보는 관심이 없다. (이를 segment가 datagrams에 캡슐화 되었다고 한다.)
Router의 관심 정보는 Network layer의 IP 주소이므로 해당 데이터를 읽고, 다음 라우터로 전송하는 과정을 반복하여 최종적으로 Server까지 Segment를 전달해줄 수 있다.
2. Interplay Between Routing and Forwarding
📌 Two Key Network Layer Function
Router의 두 가지 기능이라도 무방한데, 포워딩과 라우팅이 있다.
- Forwarding: 수신한 패킷을 적합(최적경로)한 라우터에게 보낸다.
- Routing: 출발점(source)부터 도착점(sink)까지의 최적 경로를 routing algorithms으로 판단한다.
정리하면 Routing Algorithm을 수행하여 갱신한 Router table에 기반하여, 수신한 packet을 다음 router에게 전달해주는 것이 Router가 하는 일이다.
📌 Fowarding table
강의 자료에 Fowarding table이라고 되어 있던데, Routing table과 둘은 엄연히 다르다고 한다.
(수정된 내용) 처음엔 Routing table이 맞다고 생각했는데, 라우팅 테이블은 최적 경로 알고리즘을 수행해서 얻어낸 경로표 같은 개념이고, 라우팅 테이블을 기반으로 출력 포트를 정해놓은게 Forwarding table이라 포워딩 테이블로 칭하는 게 맞는 거 같다. (아니, 근데 잘 모르겠다. 교수님께 여쭤봐야될 듯...)
→ 결론은 구분이 의미가 없다고 하셨다. 마치 segment, packet, frame을 엄격하게 구분하지 않는 것처럼, 실무에서도 포워딩 테이블이니 라우팅 테이블이니 섞어써도 다 알아 듣기 때문에 스트레스 받을 필요는 없다고 하셨다!

실제로 cmd 창에서 "route print"를 치면 라우터 테이블을 확인해볼 수 있다.
- Network Destination
- 수신처 정보를 담고 있다. (패킷의 최종 목적지)
- IPv4(32-bit)주소는 서브넷(네트워크 주소) + Host(호스트 주소)로 할당되어 있다.
- 2^32개 IP 주소를 모두 담을 수는 없으니 여러 개의 서브넷을 하나의 서브넷으로 간주하는 주소 집약을 사용한다.
- 141.223.84.1 ~ 141.223.84.128는 모두 1번 링크로 가면 도착할 수 있게 된다.
- 단, 해당 물리적으로 연결된 길은 반드시 그 길로 간다는 그 길로 간다는 가정이 필요하다.
- 즉, 근처의 기기는 모두 비슷한 IP 주소를 가진다는 전제가 깔려있어야 하고, 실제로 그렇다.
- host 번호가 0이면 subnet을 가리키고, 255면 subnet 전체 host에 broadcast한다.
- 0.0.0.0/0.0.0.0은 매칭되는 주소가 없으면 "일단 인터넷으로 나가는" 기본 라우터(Default Gateway)를 설정한 값이다. (다만, 이 정보는 다소 특수한 케이스로써, Router의 경우엔 일치 정보가 없으면 ICMP를 송신처에 unicast하여 에러를 알린다.)
- Nemask
- 서브넷과 호스트 주소는 고정되어 있지 않기 때문에, netmask로 구분한다.
- 마찬가지로 32bit주소이며, IP 주소와 1:1 매칭시켰을 때, 1이면 서브넷 주소, 0이면 호스트 주소라고 판단한다.
- Gateway
- 패킷을 전송할 다음 IP 주소를 의미한다.
- 라우터 주소라면 "나한테 보내주면 Destination으로 보내줄게!"라는 의미가 된다.
- Interface(포트)
- 좀 어려울 수 있는데, 단일 네트워크 포트는 여러 IP 주소를 가질 수 있다. (이해 안 되면 패스)
- 다음 라우터로 전송을 할 때, 어느 인터페이스를 통해서 전송할 지를 판단할 수 있다.
- 내 경우엔 위에 Interface 리스트를 보여주고 있는데, 이 중 어디로 보낼건지 정하는 것이다.
- Metric
- 해당 경로의 비용을 나타낸다. Metric이 작을 수록 빠른 경로다.
📌 Longest Prefix Matching

Forwarding table은 "해당 목적지로 가는 경로"를 파악하고 있는 것이기 때문에, 수신한 패킷이 전달되어야 하는 IP 주소 정보는 패킷 안의 IP Header에 담겨있다.
헤더 안의 IP 주소는 마찬가지로 Dest 주소와 Netmask 정보가 담겨져 있는데, 라우터는 포워 테이블과 대조하여 일치하는 주소가 복수 개라면 앞쪽부터 가장 많이 일치하는 방향으로 경로를 선택한다.
왜냐하면, 네트워크 번호 길이가 길 수록 연결 가능한 호스트 수는 적어지고 서브넷 규모 또한 작다는 뜻이기 때문에, 보다 구체적인 위치를 파악할 수 있게 된다.
✒️ Router가 궁금한 것은 Host 주소가 아니라 Network 주소다.
내가 전송하고자 하는 목적지 네트워크의 게이트 웨이까지만 잘 도착한다면 된다.
해당 게이트 웨이는 수신측 네트워크의 입구 역할을 수행하고 있으므로, 그 다음은 Internet이 아니라 Ethernet의 방식을 따라 ARP 테이블로 수신측에 전달한다.
Longest Prefix Matching에서 알 수 있듯이, Prefix(Network 주소)만을 매칭해서 비교해보는 것은 라우터의 목적이 네트워크와 네트워크 간 교류를 위함이지, 네트워크 내부에서의 통신을 위해서가 아님을 상기하자.
📌 Per-router Control Plane VS SDN(Software-Defined Networking) Control Plane
여기서는 Router의 작동 방식에 대한 설명이다.
위에서는 간략하게 Router의 기능은 라우터 테이블 갱신과 패킷 중계 동작 2가지가 있다는 설명으로 그쳤지만,
Hub와는 달리 Router는 갱신 동작과 중계 동작이 분리되어 있다는 중요한 특징이 있다.
그리고 이 작업을 수행하는 2가지 방법이 존재한다.
✒️ Per-router Control Plan
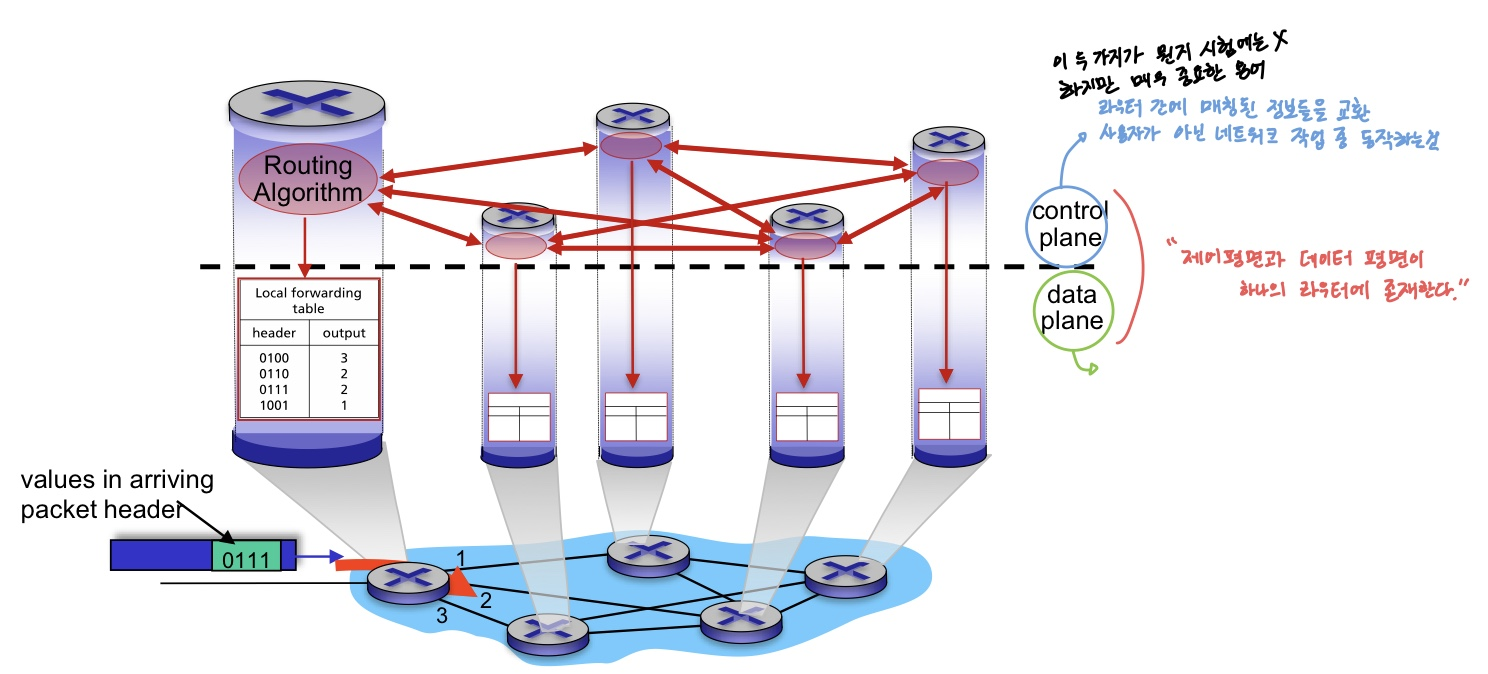
전통적이면서 일반적인 방식이다. (그런데 찾아보니 Management/Policy plane이란 게 또 존재한다)
라우터는 테이블을 갱신하기 위해서 Routing Algorithm을 수행해야 하는데, 해당 알고리즘을 수행하기 위해서 라우터들은 인접 노드 간에 주기적인 테이블 정보 교류가 이루어져야 한다.
- 제어 영역(Control plane)은 이웃하는 라우터와 전체 네트워크 Topology를 탐색하고, 라우터 테이블을 작성하는 영역이다.
- 데이터 영역(Data plane)은 라우터의 제어 영역 Protocol 정보를 RIP(Routing Information Base)와 FIB(Forwarding Information Base)에 넣고, 데이터 단계에서 SW또는 ASIC이 트래픽을 전송한다.
라우터 내에 영역이 분리되어 있긴 하나, 최적 경로인 라우터 테이블을 갱신하기 위해서는 각 노드가 서로의 정보를 지속적으로 교환해야 하는 것이 지금까지의 방식이었다.
✒️ SDN Control Plane

이 내용은 대학원 내용이라서 참고만 하라고 교수님께서 말씀하셨지만 그래도 포스팅 해놓으려 한다. (작년에 FFT 알고리즘도 이러다가 공부했던 거 같은데..)
처음에 해당 기술이 발표되고 별 주목을 못 받다가, 2012년 구글에서 "개쩌는데?"하면서 성과 선보였다가 최근 10년 중 네트워크 분야에서 매우 중요한 내용이 되었다고 한다.
SDN은 심플한 아이디어를 가진다.
라우터는 이제 진짜로 "패킷 전달"만 하고, 라우터 테이블을 채우는것조차 중앙 서버에서 컨트롤 하여 최적화를 하는 방식이다.
모든 라우터가 정보를 중앙 서버(SDN Controller)로 전송하면, 중앙 서버에서 한 번에 알고리즘을 수행해 각 노드에 최적화된 라우팅 테이블을 제공해주는 식이다.
이후 언급할 라우터가 라우팅 테이블을 갱신하기 위한 방법들을 살펴보면, 상당히 합리적이라고 생각한다.
그런데 이렇게 되면 중앙 서버 터지면, 모든 라우터가 마비되는 건가요..? 모르겠네. 이것도 교수님께 여쭤봐야겠다.
3. IP Protocol
📌 IP datagram format (IP header)
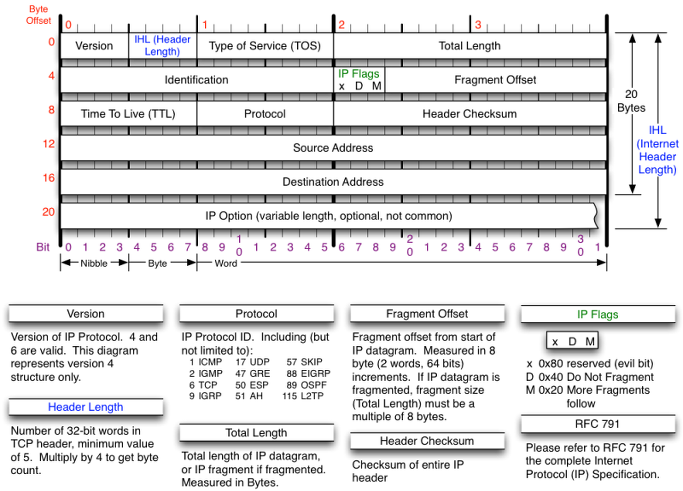
IP 헤더의 모든 정보를 지금 보는 것은 의미가 없고, 뒤에서 헷갈릴 때마다 찾아보는 것이 좋다.
| 필드의 명칭 | 길이(bit) | 설명 | |
| IP 헤더 20 바 이 트 |
버전 | 4 | IP 프로토콜의 버전. 현재는 IPv4 고정 |
| 헤더 길이(IHL) | 4 | IP 헤더의 길이. 프로토콜 옵션 유무에 따라 헤더 길이가 달라지므로 필요 | |
| 서비스 유형 (ToS) |
8 | 패킷을 운반할 때의 우선 순위. (불필요해짐. 모두 이 값을 높게 잡아버려서...) | |
| 전체 길이 | 16 | IP 메시지 전체의 길이를 나타냄 | |
| ID 정보 (Identification) |
16 | 각 패킷을 식별하는 번호. 보통 패킷의 참조 번호가 여기에 기록된다. 단, IP 클라이언트에 따라 분할된 패킷은 모두 값이 같다. |
|
| 플래그 | 3 | 총 3bit인데, 유효한 것은 2bit이다. 하나는 조각 나누기(Fragmentation)이 가능한지 나타내고, 다른 하나는 해당 패킷이 이미 조각으로 나눈 것인지를 알린다. | |
| 프래그먼트 오프셋 |
13 | 이 패킷에 저장되어 있는 부분이 IP 메시지 맨 앞부분부터 몇 번째 바이트에 위치하는지를 기록한다. | |
| 생존 기간(TTL) | 8 | 네트워크 전송 중 순환 경로에 빠진 경우를 대비한 필드. 라우터를 경유할 때마다 이 값이 1씩 줄어들고, 0이 되면 순환 경로에 빠졌다고 판단하여 패킷을 폐기한다. | |
| 프로토콜 번호 | 8 | 프로토콜 번호가 기록된다. • TCP: 06(16진수) • UDP: 11(16진수) • ICMP: 01(16진수) |
|
| 헤더 체크섬 | 16 | 오류 검사용 데이터. (불필요해짐) | |
| 송신처 IP 주소 | 32 | 이 패킷을 발신한 쪽의 IP 주소 | |
| 수신처 IP 주소 | 32 | 이 패킷을 수신할 상대 IP 주소 | |
| 옵션 | 가변 | 위의 헤더 필드 이외 제어 정보 기록. 거의 쓰지 않음 | |
📌 IP Address (IPv4)
- 고유한 32-bit 정수값 (IPv4 기준)
- NIC(Network interface card, LAN Adapter)에 할당된 IP 주소가 송신측 주소가 된다.
- IP 주소는 Network 주소(왼, Prefix)와 Host 주소(우, Suffix)로 계층적 구조를 가진다.
- 141.223.84.70/225.225.225.0
- 141.223.84 : Network 주소 (Prefix)
- 70 : Host 주소 (Suffix)
- IP 주소는 언제나 dotted-decimal(dotted-quad) notation으로 표기한다.
📌 IP Addressing
처음 IP 주소 개념이 만들어졌을 때는 Network와 Host address bit-number가 제한되어 있었다.
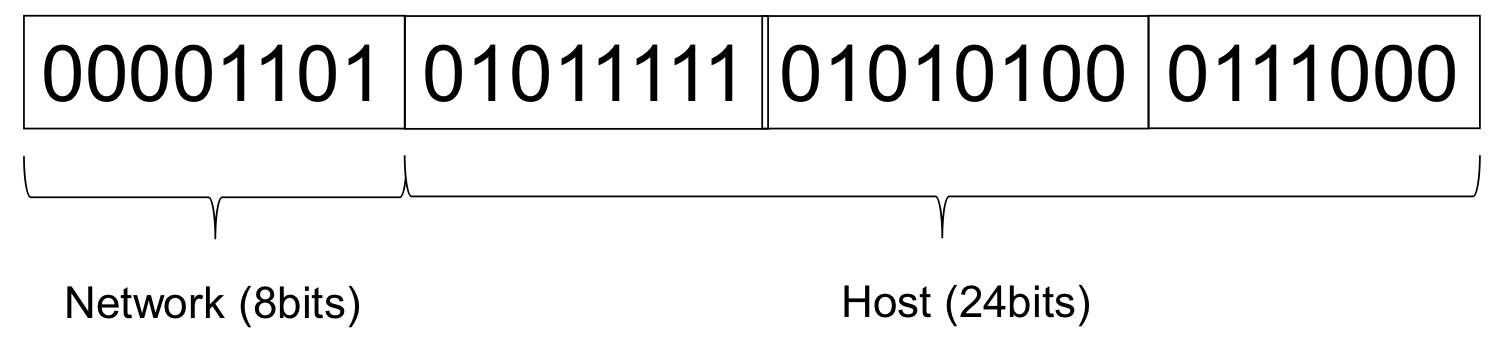
네트워크 개념을 잘 이해했다면, 이게 얼마나 어이없는 경우인지 알 수 있을 것이다.
전 세계에 Network가 고작 256(=2^8)개 할당할 수 있는 게 끝이며, 해당 네트워크마다 Host는 16,772,216(2^24)개나 수용 가능한 비현실적인 수치를 보여주고 있다.
✒️ Classful Addressing (1981)
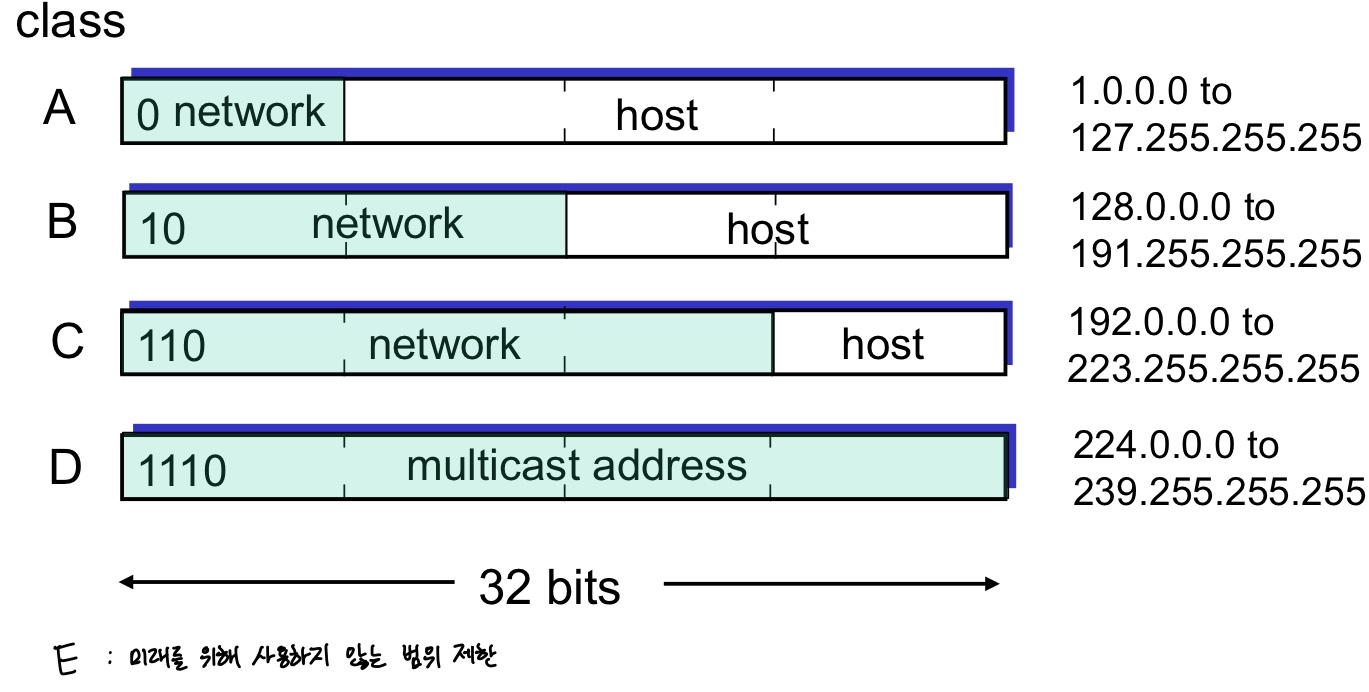
위 문제의 대안책으로 할당받는 기관 규모 별로 다르게 할당하는 의견이 제시되었다. (당연히 쓰이지 않았다.)
A 클래스는 Subnet이 많은 곳, 아래로 내려갈 수록 규모가 작은 기관을 위한 IP Address가 할당되는 개념이다.
이전 방식보다는 유연해졌으나, 여전히 비효율적이고, 힘 있는 기관이 불필요할 정도로 IP를 낭비하고 있다.
✒️ CIDR: Classless Inter-Domain Routing (1993)

- Network part와 Host part를 고정적으로 구분하지 않고, 임의의 길이로 정한다.
- Address format: a.d.c.d/x (x는 1의 개수를 10진수로 표현하며 subnet part를 결정)
- 이 방식을 택하면 낭비되는 최대 수치가 50%로 줄어든다.
4. Subnets
예전에 Subnet의 정의가 무엇이냐로 스터디원끼리 열심히 논쟁을 했었는데, 지금 보니 다 틀렸었다. ㅋㅋ
📌 Concept
"Subnet은 라우터를 거치지 않고, 물리적 통신이 가능한 모든 범위를 일컫는다.
즉, 같은 Network port를 갖는 범위이다."
✒️ 서브네팅(Subnetting)
라우터와 네트워크 장비 없이 통신 가능한 영역을 브로드 캐스트 도메인이라고 한다.
그러나 이런 영역이어도 Host의 IP Address는 반드시 모두 달라야 한다는 조건이 있다.
여튼, 너무 큰 브로드 캐스트 도메인은 네트워크 환경의 트래픽 증가를 야기하므로 성능 저하를 발생시킨다.
따라서 네트워크를 쪼개서 통신 성능을 보장하는 것이다.
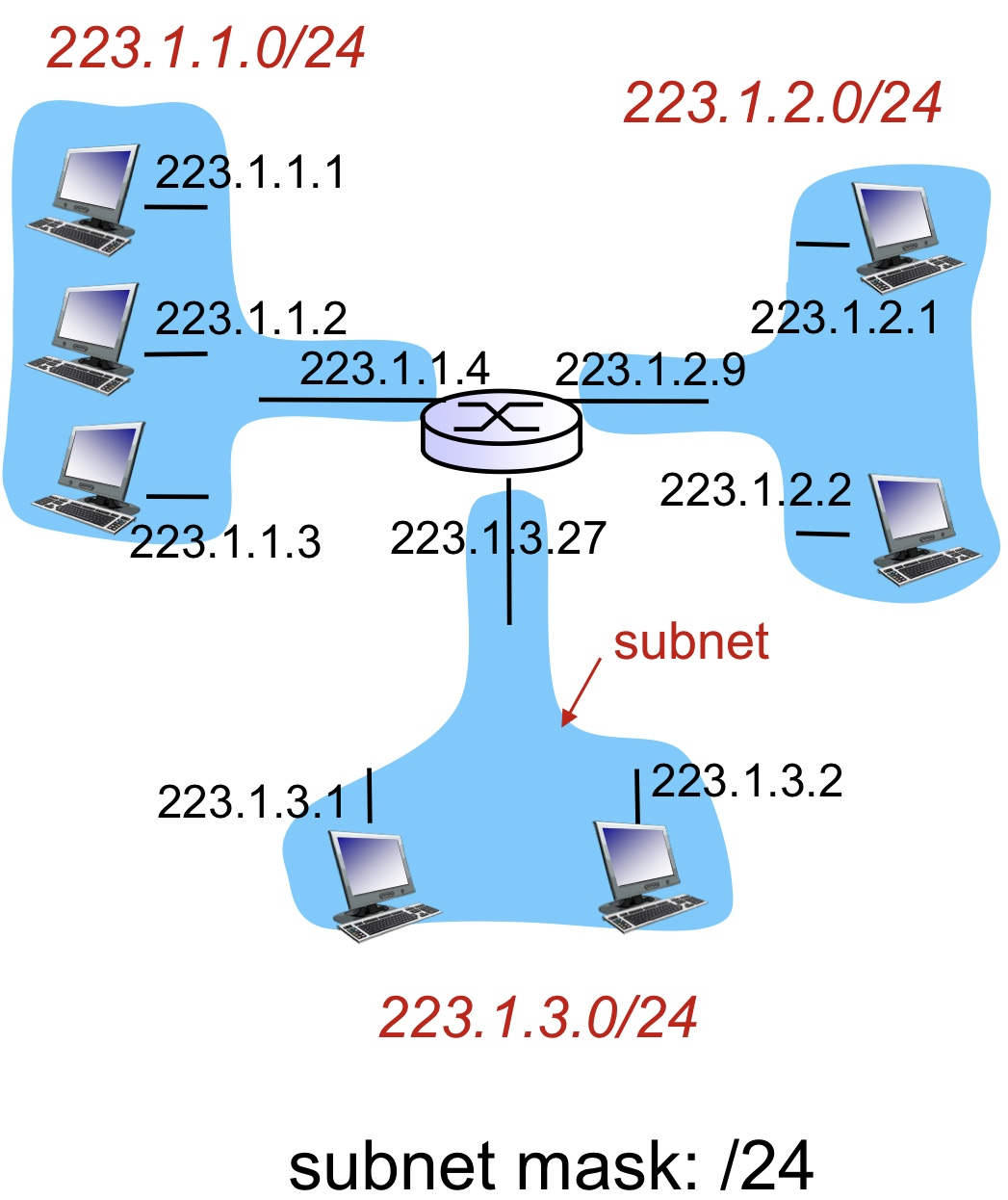
위의 그림은 3개의 Subnet이 있다고 볼 수 있다.
이해가 안 가면 "라우터를 통과해야만 대화를 할 수 있는가?"를 따지면 된다.
위의 그림에는 "223.1.1", "223.1.2", "223.1.3"의 Network 주소를 갖는 3개의 독립적인 Network가 있다고 판단한다.
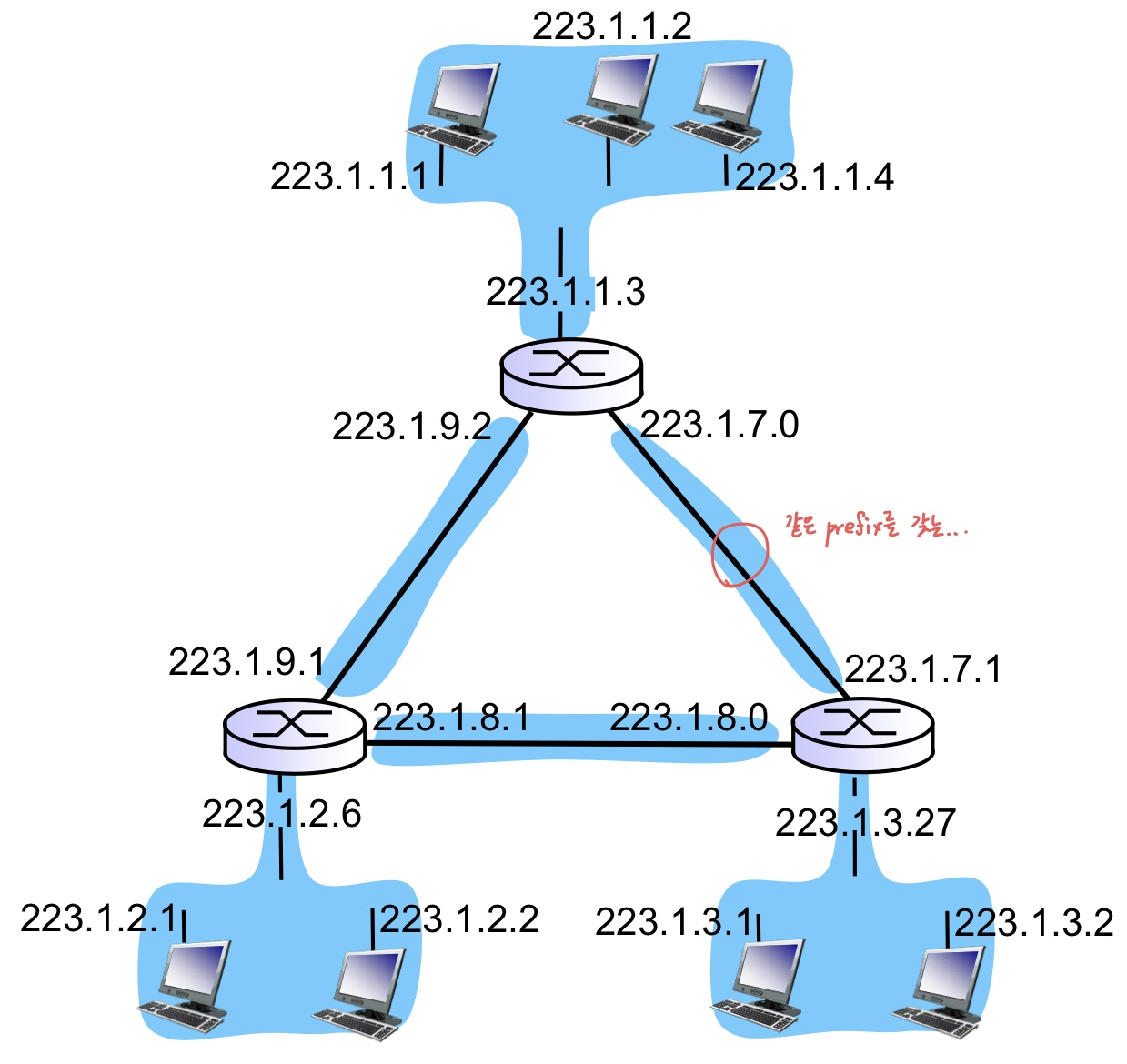
이 그림에서 "Subnet의 개수가 몇 개냐?" 라고 묻는다면, 답은 6개가 된다. ^^..
가장 직관적인 이유는 Router를 거치지 않고 통신이 가능한 경로 선상에 놓여있다는 것이고,
보다 논리적인 이유를 대라고 한다면 같은 prefix를 가지는 구역이기 때문이다.
📌 IP Fragmentation & Reassembly
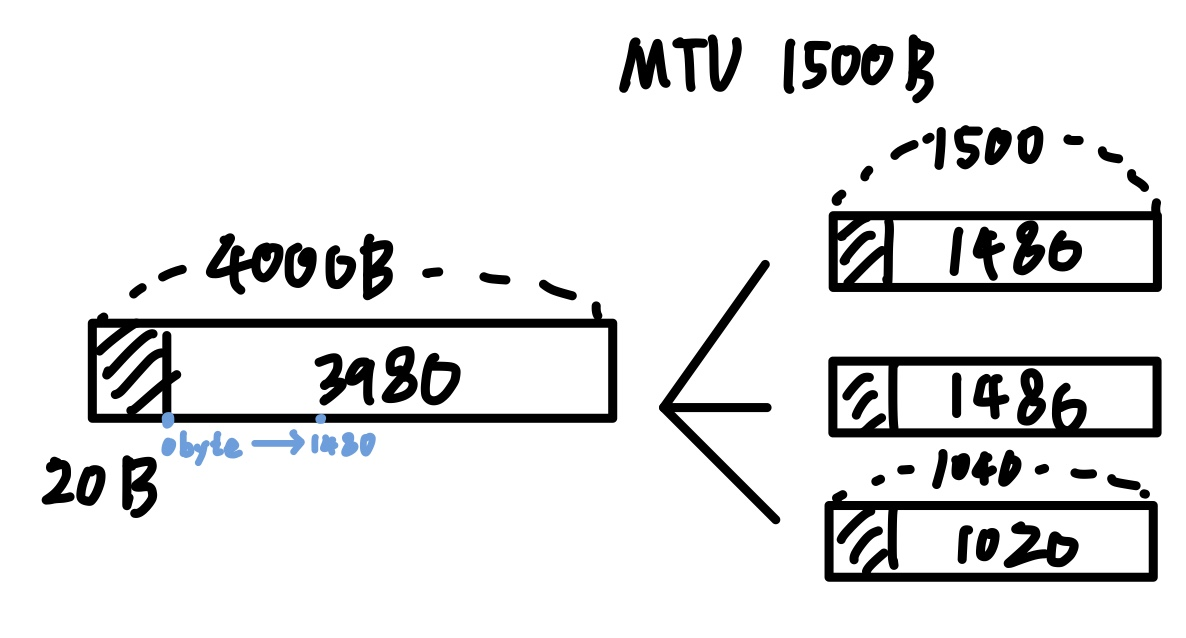
IP Header에는 fragmentation 여부를 알 수 있는 field가 존재한다.
조각 나누기(fragmentation)란 Packet의 data가 송신하려는 케이블의 MTU보다 큰 경우 진행된다.
예를 들어, 4000byte의 packet이 다음으로 넘어가려고 하는데, MTU=1500byte인 경우 최대 송신 가능한 데이터의 크기는 1500byte밖에 안 된다.
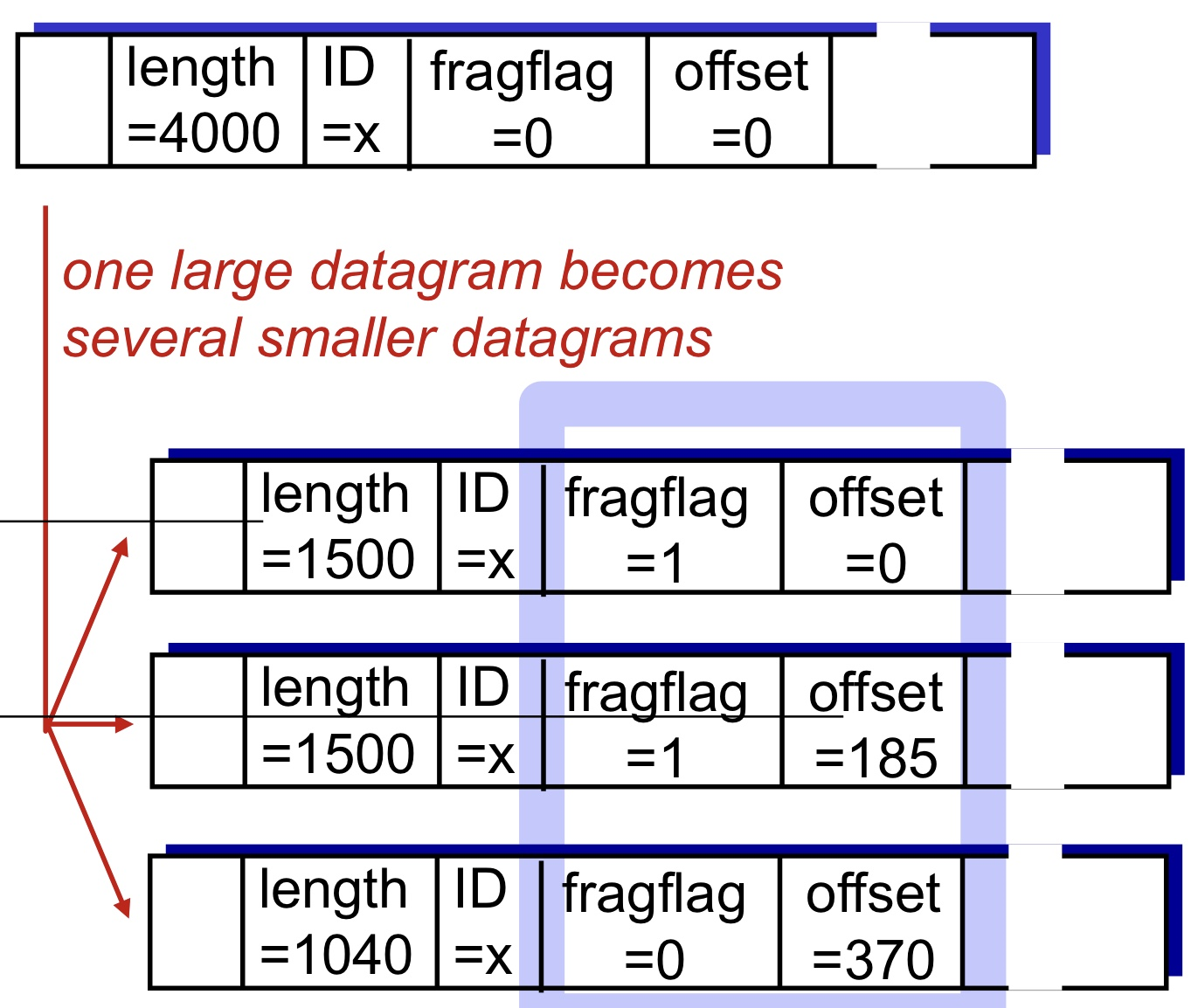
이 경우 Network Layer에서 Segment를 3개로 분할하여 각각에 모두 IP header를 달아준다.
세 개의 IP header는 모두 동일한 정보를 담고 있어야 하는데, 다음 필드를 주의하면 된다.
- ID: 원본과 모두 같은 ID를 가지고 있어야 한다. (원래 하나의 Segment임을 판단)
- offset: 원본 데이터 시작 위치에서 얼마나 떨어져 있는지 기록한다. (8로 나누어 byte 단위로 맞춘다.)
- flag: 분할된 packet이면 flag를 1로 바꾼다. 하지만 마지막 fragment는 0을 주어 마지막 조각임을 명시한다.
📌 IPv6
IPv6는 64bit 주소 체계로 2^64개의 값을 표현 가능하다. 왜 이 주소 체계가 언급되었냐면, IP 주소는 고유해야 한다는 성질 때문이다.
IPv4는 32bit 주소 체계이므로 최대 허용 가능한 수의 범위가 2^32개로써, 대략 4억개가 된다.
하지만 요샌 한 사람이 하나의 네트워크 기기만 사용하지 않기 때문에 이미 이 수치는 진작에 넘어섰다. (50억을 넘는 수치로 알고 있다.)
그런데 왜 우리는 여전히 IPv4를 사용할 수 있는 것일까?
네트워크 분야는 상당히 보수적이라고 한다.
만약 IPv6로 체계가 바뀌면 기존 기기들을 모두 뜯어고쳐야 하는데, 천문학적인 시간과 비용이 소모될 뿐 아니라 그동안 인터넷이 원활하게 돌아갈 수가 없다는 엄청난 리스크를 짊어지고 있다.
그래서 'IPv4로 어떻게든 커버할 수 있는 방법이 없을까?'를 연구하다가 Network Address Translation이라는 기가 막힌 방법이 나오게 되었고, IPv6는 아직까지는 사용되지 않아도 되는 주소 체계가 되었다.
3. NAT (Network Address Translation)
📌 NAT (Network Address Translation)

되게 재밌는 개념이다. 이걸 이해하려면 주소 집약의 원리와 이유부터 알아야 한다.
- 가정에 PC와 모바일 기기 보급 → 할당 가능한 IP 주소 고갈
- 그런데 독립된 Network 끼리는 Internet에 연결되어 있지 않을 때는 서로 중복이 생겨도 된다.
- 단, 같은 Network 내에서는 고유해야 한다.
- 즉, 인터넷에서 사용할 global address와 사내용 주소인 private address를 분리하면 된다.
- 같은 회사 내에선 private address가 중복되면 안 된다.
- 다른 회사와는 private address가 중복되어도 괜찮다.
- 곧장 Internet에서 연결할 수는 없고, 주소 변환(private → global)으로 간접 접근을 시도해야 한다.
이게 주소 집약에 대한 핵심의 끝이다.
즉, 네트워크 내에선 그들만의 IP 주소를 사용하다가 인터넷에 접근하게 될 때는 global IP address를 사용해야 한다는 뜻인데, 이게 당췌 무슨 소리일까?
인터넷에 접근하려면 네트워크 내의 모든 기기는 반드시 출입구 역할을 하는 게이트 웨이 라우터를 거쳐야만 한다.
그렇다면, 모든 기기에 global IP 주소를 할당해 주는 것이 아니라, Router에만 공인 IP 주소(global ip address)를 할당하고 Network는 자신들만의 규칙을 따르는 IP 주소(private ip address)를 할당해줄 수 있지 않을까?
예를 들어서 Network 안에서 어떤 PC가 인터넷에 접근을 하면, 라우터가 요청자를 기억해놓았다가, 해당 요청을 자신의 주소로 대신 보내고 응답을 받은 후에 원래 요청했던 기기에 데이터를 돌려주면 된다.
이 방식을 채용하기 위해선 NAT Router에 다음과 같은 기능들이 구현되어 있어야 한다.
- 주소 치환: 밖으로 나가는 private ip addr을 라우터에 할당된 global ip addr로 치환하여 전송하고, 들어오는 패킷은 기존에 요청한 기기의 private ip addr로 다시 치환하여 돌려줄 수 있어야 한다.
- 주소 기억: 바꿔 쓴 IP를 대응표에 기록하여, 데이터를 돌려받으면 대응표에 기록된 사내 네트워크에 돌려준다. (인터넷 접속 동작이 끝나면 대응표에서 삭제한다.)
그리고 사내용 주소(private addr)의 범위도 정해져 있다. 이는 다른 회사와 중복해도 괜찮다.
- 10.0.0.0 ~ 10.255.255.255
- 172.16.0.0 ~ 172.31.255.255
- 192.168.0.0 ~ 192.168.255.255
📌 PAT (Port Address Translation)
PAT는 Dynamic NAT의 일부이긴 하지만 수업에선 이 용어를 따로 언급하진 않으셨다.
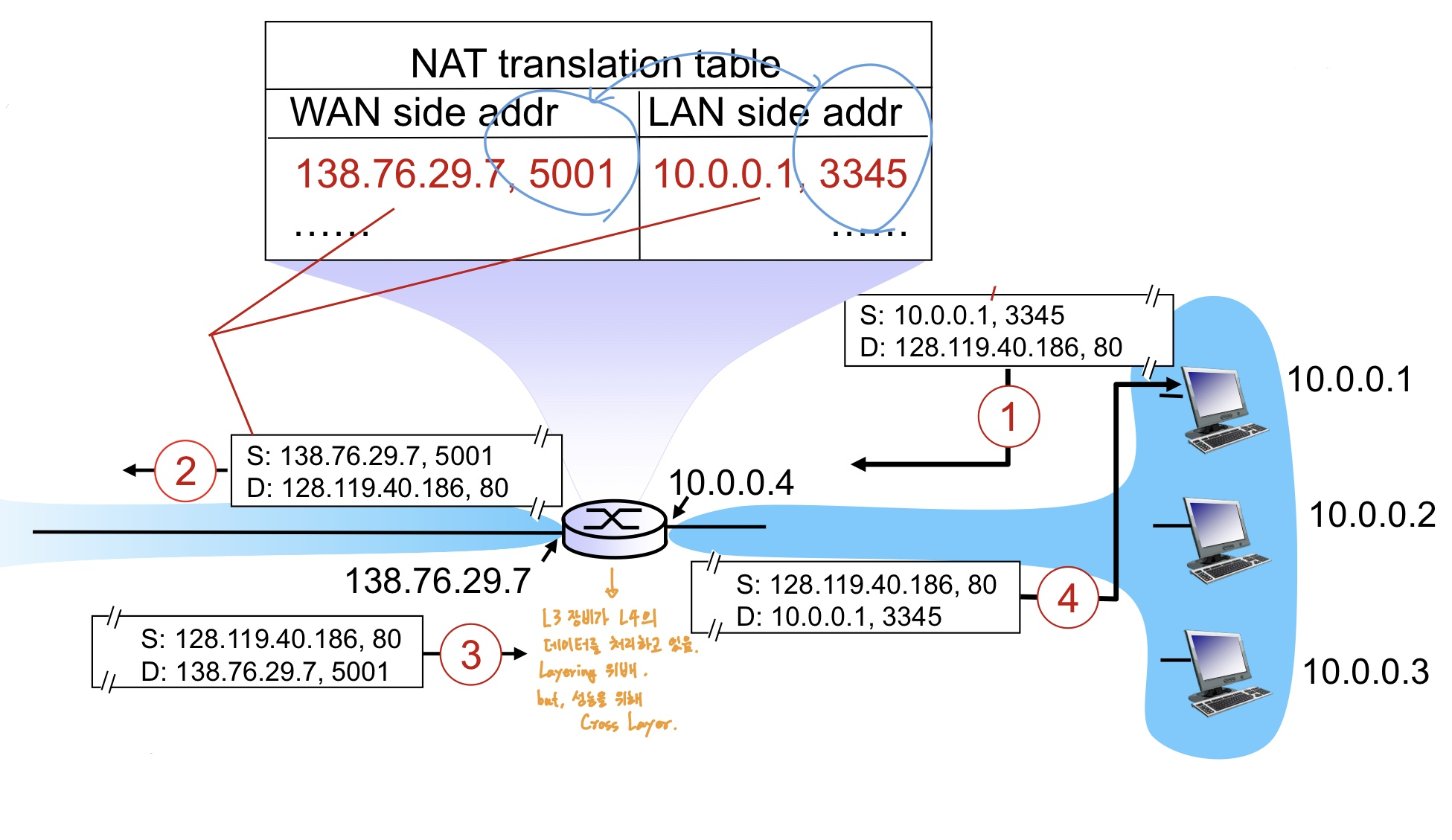
PAT는 대응표를 작성할 때, Host의 private ip addr 뿐만 아니라 port 번호도 같이 기입해둔다.
NAT만으로는 1개의 공인 IP 주소를 가지는 Router가 N개의 Host를 구분할 방도가 없다. (패킷을 보낼 때는 그렇다 쳐도, 받았을 때는 누구한테 돌려줄지 어떻게 판단할 것인가?)
그래서 포트 번호를 동시에 기록할 뿐만 아니라, 주소 변환 동작 과정에서 해당 포트 번호도 랜덤으로 치환한다.
이렇게 되면 공인 IP 주소 하나에 N개의 사설 IP 주소를 대응시킬 수 있다.
✒️ Port Number를 치환하는 이유
랜덤으로 포트 번호가 정해지기 때문에 아주 가끔 이 포트 번호가 겹치는 경우가 발생할 수 있다. 그렇게 되면 같은 공인 주소, 포트 번호를 가지므로 처음 문제로 회귀한다. 돌려줄 PC를 판단할 수 없게 된다.
따라서 Client 측 포트 번호를 받아서 이를 치환하면 되는데, 여기서 주의할 점은 port number는 Transport Layer(L4) 계층의 정보다. 즉, L3 장비인 라우터가 성능을 위해 Cross Layer을 하고 있는 하나의 사례로 볼 수 있다.
📌 PF (Port Forwarding)
한 가지 고려해봐야 할 점이 있다.
만약 서버에 사설 IP 주소가 할당되어 있다고 한다면, 외부에서 사용자가 접근하는 방법은 무엇일까?
게이트 웨이의 대응표는 내부에서 요청이 발생했을 때, 아주 일시적으로 갱신되었다가 요청이 끝나면 곧장 사라져버린다.
(심지어 서버는 요청을 보낼 일도 없다.)
이는 well known port number로 이슈를 해결할 수 있다.
port 번호는 일반적으로 랜덤하지만, http 통신은 80번 포트를 사용하는 등의 약속들이 이미 정해져 있다.
그리고 라우터의 대응표에 수동으로 80번 포트로 정보 요청이 들어오는 경우, 네트워크 내부의 서버로 데이터가 넘어가도록 기록해주면 된다.
NAT이 내부에서 외부로 나가는 과정을 고려한 기술이라면, Port Forwarding은 외부에서 내부로 접근하는 경로를 지정해주는 기술이라고 보면 된다.