💡 해당 내용은 "가상 면접 사례로 배우는 대규모 시스템 설계 기초"를 참조하여 작성하였습니다.
1. Introduction
📌 Key-Value Store
서버 개발자라면, 키-값 저장소의 대표격인 Redis 정도는 사용해봤을 것이다.
이번 파트는 이러한 키-값 저장소들을 분산 환경으로 설계하는 내용을 다룬다.
그 전에 기초 개념 정도로 책에 나온 내용을 슬쩍 다루고 넘어가야겠다.
💡 키는 짧을 수록 좋다.
키-값 저장소의 키는 유일해야 한다.
그리고 성능상의 이유로 짧을 수록 좋은데, 그래서 일반 텍스트보다 해시 값을 적용하는 경우가 많다.
RDB도 마찬가지 아니냐고 할 수 있겠지만, RDB와 KV Store의 목적이 다름에 주의하자.
1️⃣ 메모리 사용량 감소
• Redis같은 in-memory 저장소는 모든 데이터를 RAM에 저장한다.
• 키-값의 크기가 커질 수록, 그만큼 불필요한 메모리를 차지하기 때문에 담을 수 있는 데이터 수가 적어진다.
• Redis의 경우 RDB(스냅샷) 혹은 AOF(로그 기반 지속성)을 이용해 데이터를 디스크를 저장하는데, 이 때도 더 많은 공간과 I/O 비용을 요구하게 된다.
가끔 이걸 해결한답시고, "user:profile:1234"를 "u:p:1234"처럼 수정하는 경우가 있던데, 이러면 유지 보수성이 떨어지므로 별로 좋은 대안책은 아니다.
2️⃣ 네트워크 전송 비용 절감
• 키, 값이 커지면 요청(Request)과 응답(Respons) 크기가 커져, 네트워크 트래픽이 증가한다.
• 대량의 데이터를 주고받는 환경에서 네트워크 I/O가 병목 지점으로 작용할 수도 있다.
3️⃣ 데이터 조회 속도 향상
• 키가 짧을 수록, 해싱 및 비교 연산의 CPU 부담이 줄어든다.
∘ SHA-1로 해싱을 한다고 쳤을 때, 키가 커질 수록 블록 단위가 늘어나서 연산 비용이 증가한다.
• 특히, CPU cache에 적재되는 데이터 크기가 줄면서, 캐시 히트율(cache hit rate)이 높아질 수 있다.
🤔 키-값 저장소 분리할 거면 RDB보다 나은 게 뭔데?
그냥 예전에 생각했던 내용인데, 갑자기 생각나서 추가해놓은 내용.
redis같은 in-memory db의 가장 큰 이점은 물리적인 위치가 가깝다는 점이라고만 배웠었다.
그런데 분산 서버 환경에서 이런 키-값 저장소가 하나의 서버 내에 존재하거나, 혹은 서버 마다 다른 redis를 사용할 수는 없는 노릇이니 결국 분리를 해줄 수밖에 없는 때가 존재한다.
이러면 결국 RDB랑 동등하게 Network overhead가 발생할 텐데, 뭐하러 키-값 저장소를 쓰는지에 대한 의문이었다.
그러나, 조금만 생각해보면 in-memory의 장점이 반드시 같은 서버 내에서 동작해야만 드러나는 것은 아니었다.
Redis를 생각해보자.
데이터를 모두 메모리에 저장하므로 Disk I/O가 없으며(메모리 접근 속도 ns~µs, 디스크 접근 속도 ms),
클러스터링 및 샤딩을 통한 수평 확장에 있어서는 RDB보다 훨씬 수월하다. (수직 확장은 RDB가 낫다.)
그 외에도 키-값 저장소들만이 제공하는 다양한 기능들이 있긴 하지만,
여기선 단순히 Network 오버헤드가 동일한 조건에서 in-memory DB라는 특징이 갖는 이점이 무엇인지만 고민해보았다.
📌 Usecase
- 키-값 쌍의 크기는 10KB 이하
- 큰 데이터를 저장 가능
- 높은 가용성: 장애가 있어도 시스템은 빨리 응답해야 한다.
- 높은 규모 확장성: 트래픽 양에 따라 자동적으로 서버 증설/삭제가 이루어져야 한다.
- 데이터 일관성 수준 조정 가능
- 짧은 응답 지연시간(latency)
🤔 응답 지연시간을 정하는 기준은 뭔데?
응답 지연시간이 짧아야 한다는데, 뭐 얼마나 짧아야 할까.
당연하겠지만, 이것도 정답이 없다.
이를 위해 SLA(Service Level Agreement)와 SLO(Service Level Objective), SLI(Service Level Indicator) 따위를 정해야 한다.
자세한 내용은 Atlassian 페이지에 너무 잘 나와있어서 생략하고, 간략하게 정리하면 이렇다.
(틀렸을 가능성이 높으니, 주의)
• SLA: 서비스 제공자와 클라이언트 간에 맺는 공식적인 계약 또는 합의
• SLO: 서비스 제공자가 달성하고자 하는 구체적인 성능 목표
• SLI: 서비스 성능을 측정하는 구체적인 지표 또는 메트릭
이 중 SLO, SLI는 SRE(Site Reliability Engineering) 엔지니어들이 담당하는 것 같다. (IBM에 따르면)
2. Architecture
📌 단일 서버 키-값 저장소

단일 서버라면 설계가 어렵지는 않다.
다만, 모든 데이터를 메모리에 저장하는 것은 물리적으로 불가능할 수도 있다.
따라서 아래 방법들로 개선의 여지가 존재한다.
- 데이터 압축(compression)
- 자주 쓰이는 데이터만 메모리에 두고 나머지는 디스크에 저장
하지만 이렇게 해도 한 대의 서버로는 부족한 경우가 올 것이고, up-scale 혹은 out-scale을 해야만 하는 상황이 온다.
우리는 out-scale을 통한 수평 확장을 알아볼 예정.
📌 분산 키-값 저장소
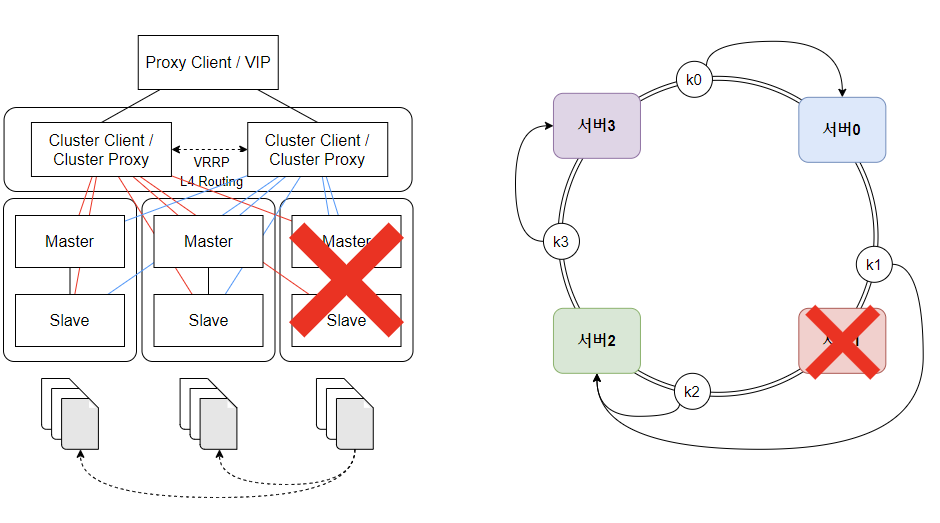
분산 환경에서는 위와 같은 구조를 가진다.
✒️ 보다 구체적인 KV Store Cluster 구조
아래는 구체적인 설계 방식이 궁금해서, 좀 더 조사해서 정리해봤다.
- 최상위 계층: Proxy Client / VIP(Virtual IP)
- 애플리케이션이 KV Store Cluster에 접속하기 위한 단일 접근점
- 실제 Redis 클러스터 복잡성을 추상화
- 중간 계층: Cluster Client / Cluster Proxy
- 클라이언트 요청을 적절한 Redis 노드로 라우팅 (ex: hash 기반으로 쓰기 연산은 mater&slave, 읽기 연산은 slave)
- 이중화된 두 개의 Proxy 서버로 하나의 Proxy에서 장애가 발생해도, 다른 Proxy가 작업 지속
- VRRP(Virtual Router Redundancy Protocol): 자동 장애 조치를 위한 프로토콜
- L4 Routing: 트래픽 부하 분산을 위한 전송 계층(TCP/UDP) 라우팅
- 하위 계층: Redis 서버 (Master-Slave 구조)
- 위 그림에선 3개의 샤드(데이터 파티션)와 각 샤드는 Master-Slave 1:1 쌍으로 구성 (Master 장애 시 Slave 승격이 되도록 만들 수도 있다.)
- 각 노드는 특정 해시 슬롯 범위를 담당하고, 전체 데이터가 여러 노드에 분산 저장됨.
- 노드 간 gossip 프로토콜을 통해 클러스터 상태 정보 공유
뭐, 이런 식으로 만든다면 된다는데...엥, 근데 이러면 해시 링을 어떻게 적용한다는 거야?
🤔 해시 링을 적용시키는 게 가능한가? (쓰고 보니 뻘글)
내가 이해한 게 맞다면, 하나의 서버가 죽어도 데이터는 온전히 다른 곳으로 저장되어야 한다.
문제는 서버가 죽었는데, Slave Node 아무리 늘려놓는다고 무슨 의미가 있다는 건가 싶었다. (유실된 데이터 어디감?)
그런데 이건 그냥 프리티어에 찌들어버린 탓인 거 같은데, Master-Slave가 한 서버에 돌아간다고 믿고 있던 이유가 뭐였을까 ㅋㅋㅋ
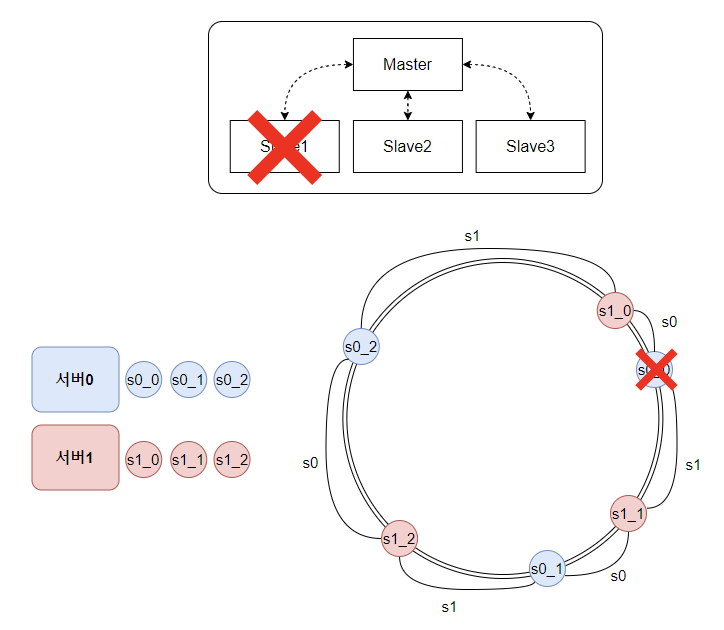
- Master - Slave 노드가 모두 별도의 물리적인 서버에서 동작하면 가능하다.
- Master가 죽으면 Slave 하나를 승격시키고, Slave 하나가 죽으면 다른 Slave가 처리하면 된다.
- 데이터는 주기적으로 동기화되어야 한다.
- Master와 Slave 간의 데이터가 주기적으로 공유되면, 해시 링을 적용할 수 있다.
그리고 이번 책에서는 위 내용을 다루고 있는 거였다.
난 지금 이걸 책 다 읽고 정리하는 중인데 이제 알았네. ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
📌 CAP 정리(Consistency-Availability-Partition Tolerance theorem)
💡 데이터 일관성, 가용성, 파티션 감내 세 가지 요구사항을 동시에 만족하는 분산 시스템 설계는 불가능하다.
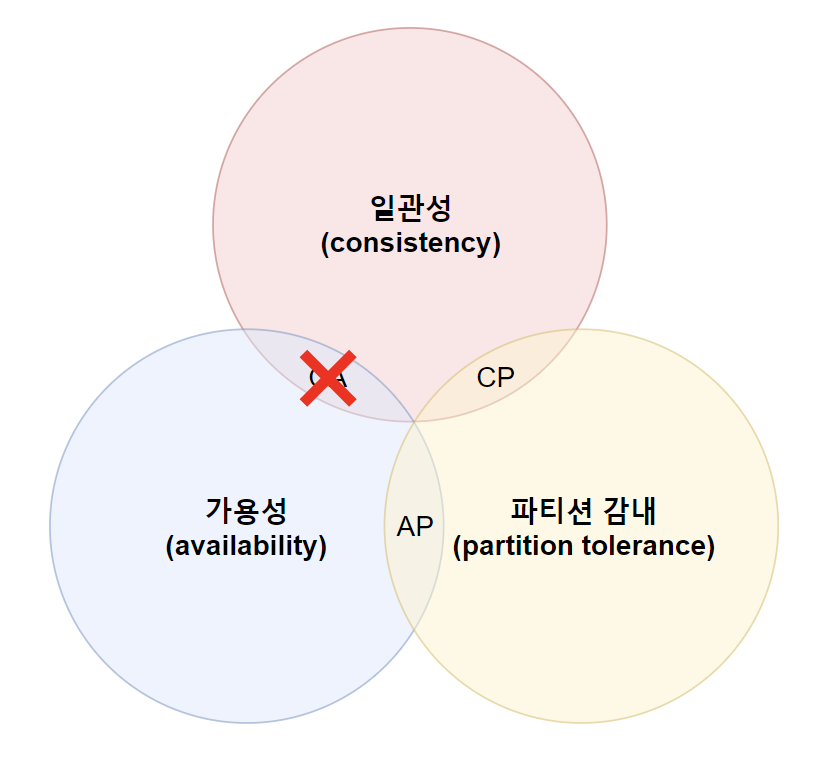
- 데이터 일관성: 모든 클라이언트는 분산 시스템의 어떤 노드에 접속했는지 상관없이, 언제나 같은 데이터를 볼 수 있어야 한다.
- 가용성: 일부 노드에 장애가 발생하더라도 클라이언트는 항상 응답을 받을 수 있어야 한다.
- 파티션 감내: 네트워크에 파티션이 생기더라도 시스템은 계속 동작하여야 한다.
- 파티션: 두 노드 사이에 통신 장애가 발생한 것
위 세 가지 요구 사항 중, 어느 두 가지를 선택할 지에 따라 3가지로 나눌 수 있다.
💡 실세계에서 CA 시스템은 존재하지 않는다.
- CP 시스템
- 일관성과 파티션 감내를 지원하고, 가용성을 희생
- AP 시스템
- 가용성과 파티션 감내를 지원하고, 일관성을 희생
- CA 시스템
- 일관성과 가용성을 지원하고, 파티션 감내를 희생
- 통상 네트워크 장애는 피할 수 없으므로 파티션 감내는 반드시 필요하다. 따라서 CA 시스템은 존재하지 않는다.
📌 Why can't we sacrifice partion tolerance?
난 처음에 CA 시스템이 존재할 수 없다는 이유를 납득하기 어려웠다.
네트워크 장애는 피할 수 없으므로 파티션 감내는 필수적이다? 그렇게 치면, 일관성과 가용성도 마찬가지 아닌가?
이를 이해하기 위해선 CAP 이론이 지켜질 수 없는 근본적인 원인을 이해해야 한다.
💡 CAP 이론의 근본적 딜레마는 네트워크 파티션에서 비롯한다.
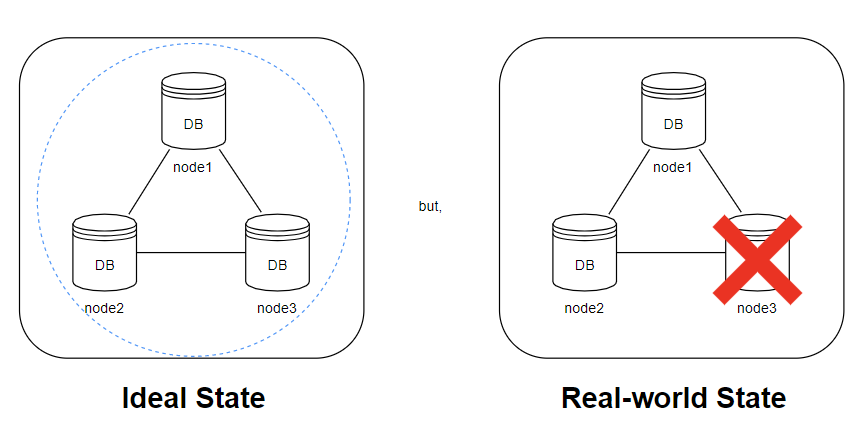
- 이상적인 상태(파티션이 발생하지 않는 상황)에선 CAP 모두 지킬 수 있다.
- 애초에 파티션이 발생하지 않으므로, CA 시스템을 선택해도 파티션 감내를 고려할 이유 자체가 없다.
- n1에 기록된 데이터는 n2, n3에 자동으로 복제될 것이고, 가용성 또한 만족할 수 있다.
- 하지만 네트워크 파티션은 피할 수 없는 문제이므로, 일관성과 가용성 중 하나를 택해야 한다.
- n3에 장애가 발생했고 n3의 최신 데이터가 n1, n2로 복제되지 않은 상태라면?
- 가용성을 희생(CP): 데이터 불일치 문제 회피를 최우선하여, n1, n2에 쓰기/읽기 연산을 중단한다.
- 일관성을 희생(AP): stale data를 반환할 위험이 있더라도, n1, n2에 쓰기/읽기 연산을 허용한다.
- 안정성과 신뢰성을 최우선으로 여기는 서비스(ex: 뱅킹 서비스)일 수록, 일관성을 양보하지 못한다.
- n3에 장애가 발생했고 n3의 최신 데이터가 n1, n2로 복제되지 않은 상태라면?
3. System Component
📌 Overview
이번 절에서는 키-값 저장소 구현에 사용될 핵심 컴포넌트들에 대해 알아본다.
- 데이터 파티션(data partition): 데이터 어떻게 분할할 건지?
- 데이터 다중화(data replication): 데이터를 분산 서버에 어떻게 복제할 건지?
- 일관성(consistency): 다중화된 데이터를 어떻게 동기화할 것인지?
- 일관성 불일치 해소(inconsistency resolution): 일관성이 깨졌을 때, 어떻게 복구할 것인지?
- 장애 조치(failover): 장애 발생하면 어떻게 대응할 것인지?
- 시스템 아키텍처 다이어그램(system architecture diagram)
- 쓰기 경로(write path)
- 읽기 경로(read path)
📌 Data Partition
💡 대규모 데이터는 여러 서버에 분산 저장
대규모 애플리케이션의 전체 데이터를 한 대 서버에 저장하는 것은 불가능하다.
가장 쉬운 해결 방법은 데이터들을 작은 파티션들로 분할한 다음 분산 배치하는 것.
단, 데이터를 파티션 단위로 나눌 때는 다음 두 가지 문제를 중요하게 따져야 한다.
- 여러 서버에 고르게 분산 가능한가?
- 노드 추가/삭제 시, 데이터 이동을 최소화할 수 있는가?
아, 물론 우리는 일관성 있는 해시(consistent hash)를 통해 해결할 수 있다.
consistent hash를 통한 데이터 파티셔닝의 이점은 다음과 같다.
- 규모 확장 자동화(automatic scaling)
- 시스템 부하에 따라 서버 자동 추가/삭제 구성에 용이하다.
- 다양성(heterogeneity)
- 각 서버 용량에 맞게 가상 노드 수를 조정 가능하다. (고성능 서버일 수록 더 많은 가상 노드를 가질 수 있다)
🤔 파티셔닝은 언제 해야 하는가?
Oracle에서 권장하는 table 파티션 시점은 다음과 같다.
• 테이블이 2GB보다 커졌을 때
• 시간(기간) 단위로 데이터를 관리하는 테이블 (최신 데이터는 계속 추가되지만, 과거 데이터는 거의 조회만 되므로 분리하면 성능 개선 가능)
• 테이블 내용을 여러 유형 저장 장치에 분산해야 하는 경우
🤔 파티셔닝과 샤딩은 대체 뭐가 다른 걸까?
지금까지 수평적 파티셔닝의 한 종류가 샤딩이라고 생각했는데, 작년 쯤에 CS 테스트에서 수직적/수평적 샤딩의 차이를 물어보는 문제가 있었다.
아니, 샤딩이면 샤딩이지 수직적 샤딩은 또 뭔데?
처음엔 그냥 관용적인 표현이겠거니 했었다. (마치 frame을 packet이라고 부르는 것처럼)
하지만 샤딩과 파티셔닝의 차이를 정리해둔 글을 보고 다름의 차이를 정리해보았다.
(틀렸을 수도 있습니다..)
✒️ 파티셔닝(partitioning) vs 샤딩(sharding)
• 보통 샤딩이라고 하면, 수평적 파티셔닝(HP)의 특수한 사례 중 하나를 의미한다. (파티셔닝이 더 넓은 개념)
• 파티셔닝과 샤딩의 공통점은 데이터를 나누는 것이고, 가장 큰 차이는 서버 분할 강제성이다.
∘ 파티셔닝: 데이터베이스를 더 작은 논리적 단위로 나누지만, 동일한 서버 또는 단일 DB 내 위치 가능
∘ 샤딩: 여러 서버에 분산된 더 작고 자율적인 단위(shard)로 나누는 것이 필수
• 즉, 파티셔닝은 샤딩을 포함하는 더 넓은 범주의 개념이다.
위 내용을 이해하면 수직/수평 파티셔닝과 수직/수평 샤딩의 차이가 보다 명료해진다.
데이터를 더 작은 논리적 단위로 나누는 것은 동일하되, 샤딩은 데이터들을 물리적으로 분리된 서버 또는 DB에 분산시키는 것이 필수적이다.
물론, 깊게 파고 들면 다른 게 더 많긴 하겠지만, 지금 이 얘기를 하는 파트는 아니므로 스탑~
📌 Data Replication
💡 높은 가용성과 안정성 보장을 위해서 데이터를 여러 서버에 비동기적으로 복제
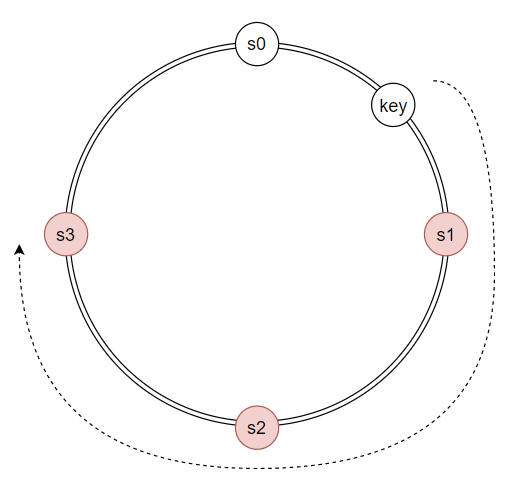
N(튜닝 가능한 값)개 서버를 선정하는 방법은 해시 링의 key 위치에서 시계 방향으로 순회하면서 만나는 N개 서버들에 사본들을 저장하는 것이다.
단, 가상 노드를 사용하다보면 대응될 실제 물리 서버 개수가 N보다 작을 수도 있다.
(N=3이어서 3개를 선택했는데, s0_0, s0_1, s0_2를 선택해버린 경우, 실제 저장되는 물리 서버는 s0 하나가 된다.)
따라서, 물리 서버를 중복 선택하지 않도록 해야 한다.
여기서 안정성을 더 확보하고 싶다면, 분산된 데이터들을 여러 데이터 센터에 나누면 된다. (하나의 데이터 센터에서 서버를 분산 처리해도, 데이터 센터 전체가 마비되면 서비스는 중단되기 때문)
그리고 센터들은 고속 네트워크로 연결하면 속도도 개선할 수 있다.
📌 Consistency
💡 여러 노드에 다중화된 데이터는 적절한 동기화가 이루어져야 한다.
정족수 합의 프로토콜(Quorum Consensus Protocol)을 사용하면 읽기/쓰기 연산에 일관성을 보장할 수 있다.
(*정족수: 합의체가 의사를 진행하고 의결하는 데 필요한 최소의 구성원 출석수)
- N: 사본 개수
- W: 쓰기 연산 정족수 (쓰기 연산이 성공했다고 간주하려면 적어도 W개 서버로부터 성공 응답을 받아야 한다.)
- R: 읽기 연산 정족수 (읽기 연산이 성공했다고 간주하려면 적어도 R개 서버로부터 성공 응답을 받아야 한다.)
여기서 오해하지 말아야 할 건, W=1이 "오직 하나의 서버에만 데이터를 기록한다"가 아닌, "적어도 한 대의 서버에 기록되면 성공"했다고 간주한다는 것이다.
N, W, R을 정하는 기준은 결국 가용성과 일관성 사이에서 타협점을 찾는 과정이다.
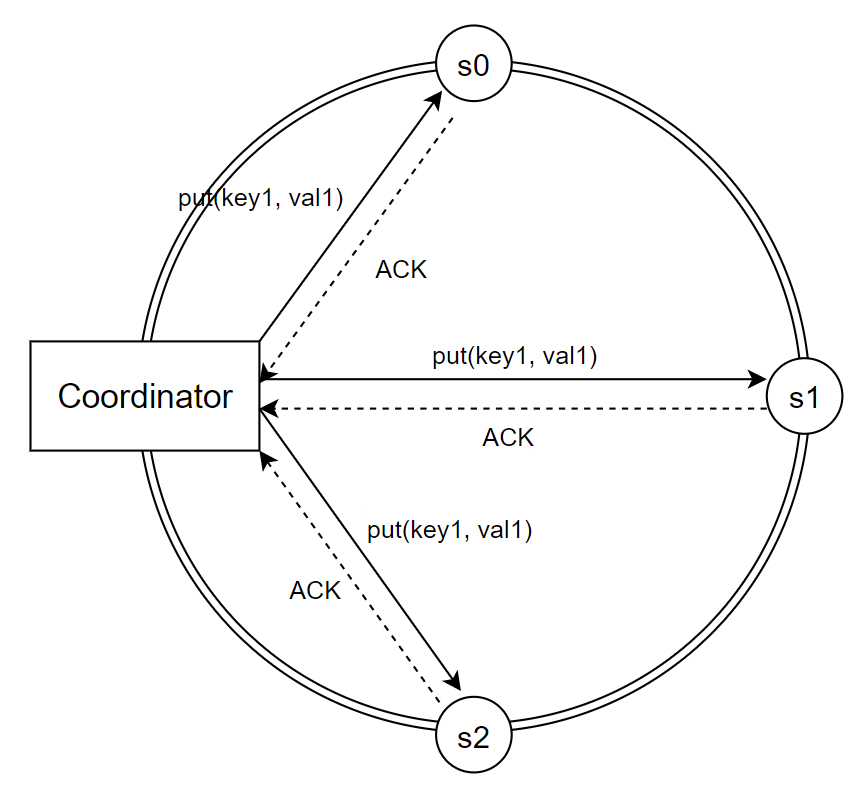
- W=1 혹은 R=1: 응답 속도는 증가, 일관성 수준 감소
- W > 1 혹은 R > 1: 일관성 수준 증가, 응답 속도 감소
✒️ N, W, R을 정하는 구성
- R=1, W=N: 빠른 읽기 최적화 (가용성 희생)
- W=1, R=N: 빠른 쓰기 최적화 (일관성 희생)
- W+R > N: 강한 일관성 보장 (ex: N=3, W=R=2; 일관성을 보증할 최신 데이터를 가진 노드가 최소한 하나는 겹침)
- W+R <= N: 약한 일관성
🟡 일관성 모델(consistency model)
- 강한 일관성(strong consistency): W+R > N
- 모든 읽기 연산은 가장 최근에 갱신된 결과를 반환하도록 보장 (가장 단순한 방법은 모든 사본에 현재 쓰기 연산 결과 반영이 될 때까지 해당 데이터에 대한 읽기/쓰기를 금지하는 것)
- 클라이언트가 절대로 낡은(out-of-date) 데이터를 보지 못한다.
- 고가용성 시스템에는 적합하지 않은 모델
- 약한 일관성(weak consistency): W+R <= N
- 읽기 연산이 가장 최근에 갱신된 결과를 반환하는 것을 보장하지 못한다.
- 일관성이 중요한 시스템에는 적합하지 않은 모델
- 결과적 일관성(eventual consistency)
- 약한 일관성 모델의 특수한 형태, 결국에는 갱신 결과가 모든 사본에 동기화되는 모델 (클라이언트는 여전히 낡은 데이터를 보게될 수도 있다!!)
- 쓰기 연산이 병렬적으로 발생 시, 시스템에 저장된 값의 일관성이 깨질 수 있음 → 클라이언트가 버전 정보를 활용해 해결해야 한다. (데이터 버저닝)
- 다이나모, 카산드라 같은 저장소가 택하고 있는 모델
📌 Inconsistency Resolution : Data Versioning & Vector Clock
💡 결과적 일관성 모델에서 일관성이 깨졌을 때, 클라이언트 측의 처리 기법
시작하기 앞서, 내용을 요약하면 이렇다.
- 문제 발생 원인: 병렬 쓰기 연산으로 인해, 같은 데이터가 다른 값을 가지게 된 경우
- 버저닝: 데이터를 변경할 때마다, 해당 데이터의 불변(immutable)한 버전을 함께 기록
- 벡터 시계: 데이터 충돌을 감지했을 때 해결 방법
🐛 문제 발생 케이스
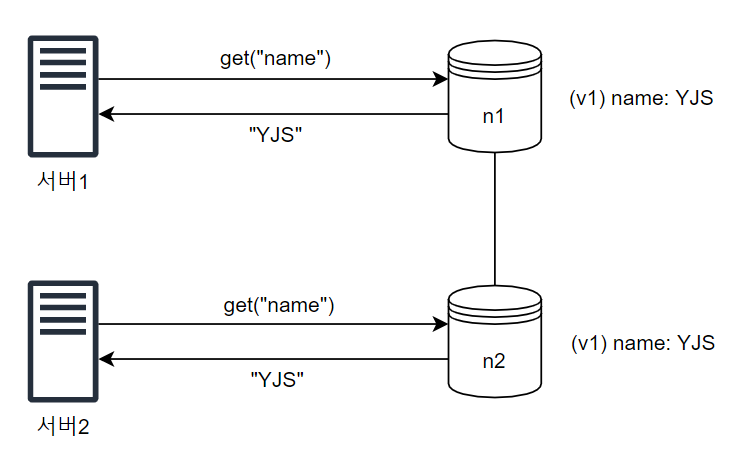
데이터 사본이 n1, n2 노드에 보관되어 있을 때, 서버1, 서버2 모두 같은 값을 결과로 받을 수 있다.
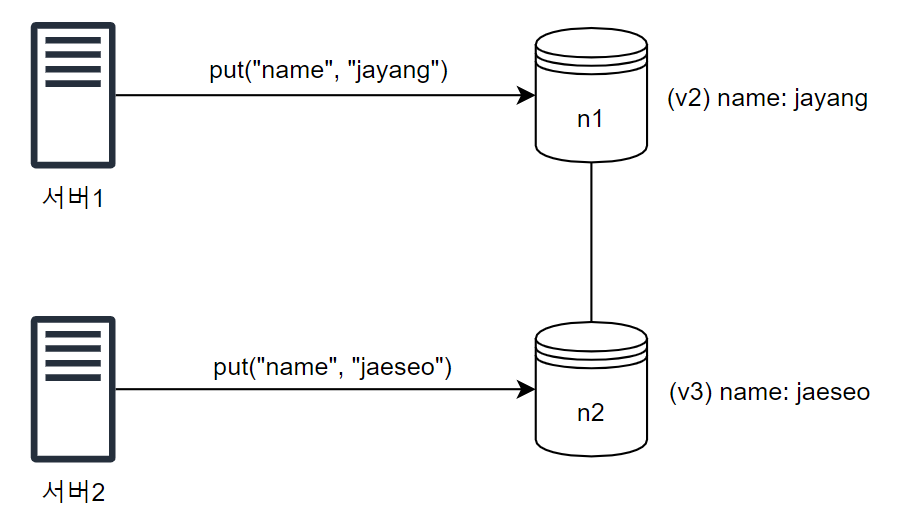
문제는 병렬 쓰기를 허용하면, 위와 같이 같인 데이터에 대해 서로 다른 값을 쓰게 되는 경우가 발생할 수 있다.
또 하필 두 연산이 동시에 이루어졌다면, n1과 n2는 충돌(conflict)하는 값을 가지게 된다.
⏲️ 벡터 시계(Vector Clock)
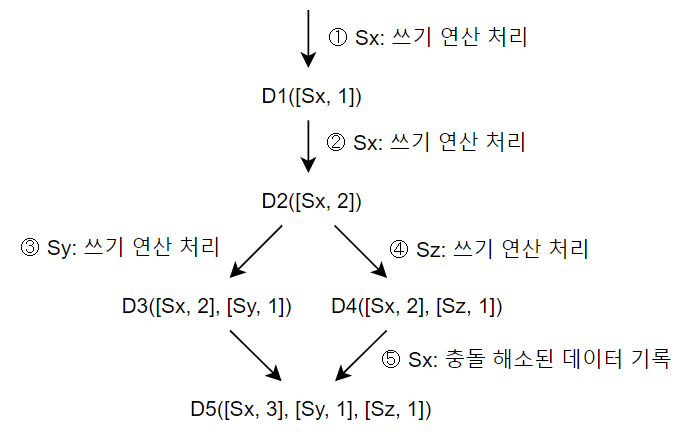
- 모든 데이터는 [서버, 버전] 순서쌍을 갖는다.
- 표현법: D([S1, v1], [S2, v2], ..., [Sn, vn])
- D: 데이터
- Si: 서버 번호
- vi: 버전 카운터
- 데이터 D를 서버 Si에 기록할 때, 두 작업 중 하나를 수행해야 한다.
- [Si, vi]가 있으면 vi 증가
- 그렇지 않으면 [Si, 1]를 추가
- 버전 X가 버전 Y의 이전 버전인지 판단하는 법
- 버전 Y에 포함된 모든 구성 요소 값 >= X에 포함된 모든 구성요소 값
- ex: Dx([s0, 1], [s1, 1])은 Dy([s0, 1], [s1, 2])의 이전 버전
- 버전 X와 버전 Y 사이에 충돌이 있는 지 확인하는 법
- 버전 Y에 포함된 모든 구성 요소 값 중, 하나라도 X가 작은 값을 갖는 경우
- ex: Dx([s0, 1], [s1, 2])와 D([s0, 2], [s1, 1])은 충돌
- 충돌은 클라이언트가 감지하고, 해소한 후 서버에 기록한다.
🤔 결과적으로 일관성이 지켜진다면서요? 이러면 클라이언트가 낡은 데이터를 보게될 수도 있잖아요.
내가 오해한 내용이긴 하지만, 혹시나 나같은 사람이 또 있을까봐 적어놨다.
위 원리를 이해하지 못한 것은 아니지만, 충돌을 감지하여 완화하는 시점에 대한 의문이 생겼다.
결과적 일관성은 약한 일관성의 한 종류이므로, 일관성을 보증할 최신 데이터 노드가 하나 이상 포함되어 있다는 보장이 없다.
그 말은 즉슨, D3, D4로 분기한 시점에 클라이언트가 Sy, Sz 데이터가 아니라, Sx, Sy를 읽어버리면 충돌을 감지하지 못한다는 의미가 된다.
그러나, 벡터 시계의 목적은 일시적 불일치를 허용하되, 일정 시간이 지나면 결국 모든 노드가 동일한 데이터로 수렴할 것을 보장할 뿐이다.
수렴 시간에 대한 엄격한 보장도 없고, 클라이언트는 낡은 데이터를 보게 될 수도 있다. (그야..그게 약한 일관성이니까..)
🫠 벡터 시계의 단점
- 충돌 감지 및 해소 로직을 위한 클라이언트 구현 복잡도 증가
- [서버:버전] 순서쌍 개수가 매우 빠르게 증가
- 방치하면 서버 메모리와 디스크에 부담
- 임계치(threshold)를 설정하여 오래된 순서쌍을 제거하면, 버전 선후 관계 불분명해질 우려 (그런데 Dynamo: Amazon's Highly Available Key-Value Store의 4.4 Data Versioning을 읽어보면, "However, this problem has not surfaced in production and therefore this issue has not been thoroughly investigated."라고 적혀있다. 즉, 운영 환경에서 그런 문제가 발생한 적이 없다는 뜻.)
threshold 정하는 개략적인 가이드도 찾고 싶었는데 도저히 못 찾겠다..
📌 Failover
대규모 시스템에서 장애는 흔하디 흔하다.
이번 파트 구성은 다음과 같이 구성되어 있다.
- 장애 감지 기법
- 멀티 캐스팅
- 가십 프로토콜
- 장애 해소 전략
- 일시적 장애 처리
- 영구적 장애 처리
🚨 장애 감지(failure detection) 기법
분산 시스템에서는 보통 두 대 이상의 서버가 같은 장애를 보고해야 실제로 장애가 발생했다고 간주하게 된다.
1️⃣ 멀티 캐스팅 (multicasting)
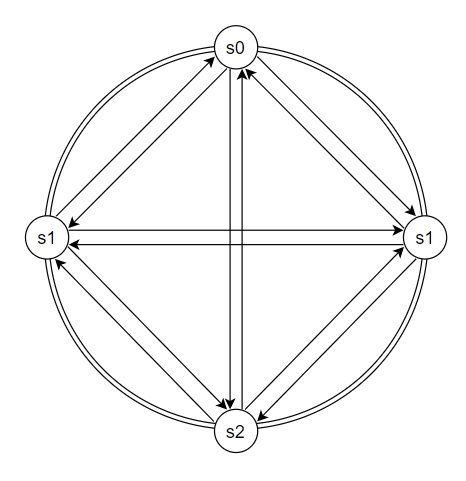
- 모든 노드가 멀티캐스팅 채널을 구축하는 것이 가장 확실하고 손쉬운 방법
- 하지만 서버가 많아질 수록, 유지해야 할 connection이 많아지므로 비효율적이다.
- 프로세스가 죽어서 노드가 crash를 일으킬 우려 존재
- 네트워크 문제로 인해 packet delay 혹은 drop 가능성 존재
- 노드가 빠르게 증가할 수 있음
2️⃣ 가십 프로토콜 (gossip protocol)
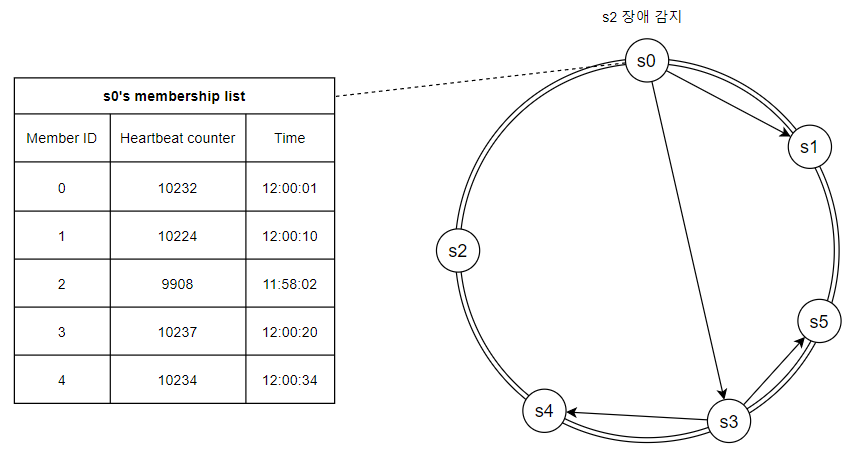
- 각 노드는 멤버십 목록(membership list)를 유지한다.
- 멤버십 목록: 각 멤버 ID와 박동 카운터 쌍의 목록
- 각 노드는 주기적으로 자신의 박동 카운터를 증가시킨다.
- 각 노드는 주기적으로 무작위로 선정된 노드들에게 주기적으로 자신의 박동 카운터 목록(gossip message)을 보낸다.
- 박동 카운터 목록을 받은 노드는 멤버십 목록을 최신 값으로 갱신한다.
- 어떤 멤버의 박동 카운터 값이 지정된 시간 동안 갱신되지 않으면, 해당 멤버는 장애(offline) 상태인 것으로 간주한다.
- 위 이미지의 경우, 오랫동안 박동 카운터가 갱신되지 않은 s2 정보를 전달받은 노드들이 s2가 장애 상태라고 판단한다.
gossip을 전달받은 노드를 감염(infected)된 노드라고 부르는데, 여기서 push gossip과 pull gossip 방식으로 나뉜다.
(감염된 노드가 gossip을 퍼트릴 것인지, 비감염 노드가 새로운 gossip을 주변 노드에 물어볼 것인지)
이 성능을 수학적으로 증명해놓은 글이 있어서 참고해보면 좋을 것 같다.
🤔 노드가 너무 많아서 박동 카운터 목록이 우연히 갱신되지 않았을 수도 있지 않나?
노드가 gossip message를 랜덤하게 보낸다는 점, 그리고 그 노드의 수도 엄격하게 정해진 바가 없다.
그 말은 즉, s2가 정말 장애 상태일 수도 있지만, 노드가 매우 많은 경우 우연히 정보를 전달받지 못했을 수도 있지 않냐는 의문이 생겼다. (혹은 시스템이 오랫동안 실행 중이라면, 한 번 정도는 일부 노드가 완전히 고립될 수 있지 않은가?)
그래서 조사를 조금 더 해보니, gossip protocol은 신뢰성을 보장하지는 않는다고 한다.
내가 이야기한대로 잘못된 장애 감지를 할 우려가 있으며, 이를 거짓 양성(false positive; 의역하면 오탐지)이라고 한다.
이를 위한 여러 논의가 있는데, 확실친 않으므로 직접 확인해보시길 바랍니다. 🙏
• Stackoverflow - "How to guarantee that all nodes get infected in gossip-based protocols?" - answer by Ami Tabory
∘ 실제로 일부 노드가 고립되는 상황이 발생할 수는 있으나, 이 경우 어떤 프로토콜도 이를 해결할 수 없다.
∘ 가십 프로토콜은 사실상 존재하지 않는다. 다양한 가십 기반 알고리즘 군(family)이 있을 뿐이다.
∘ 특정 조건 하에서는 모든 노드에 정보가 전파되는 것을 보장할 수 있다.
1. 어떤 노드 그룹(V')에 대해, 항상 이 그룹에서 외부 노드로 연결되는 활성 링크 존재
2. 각 노드가 균일하게 d개의 이웃을 선택
∘ 감염을 마르코프 체인(Markov Chain)처럼 생각했을 경우, 위 조건에선 일부 노드가 고립될 확률은 0에 수렴한다.
• Heartbeat-style Failure Detector using Gossip
∘ 네트워크 장애 등으로 heartbeat counter가 제때 전달되지 않을 수도 있음.
∘ 거짓 양성 확률을 줄이기 위해 의심 상태(suspicious)를 도입하고, 이런 현상이 지속되면 장애 처리
• Membership Protocol
∘ 거짓 양성이 발생하는 이유는 perturbed processes(교란된 프로세스), packet losses 때문
∘ failure가 발견되었을 때, 다른 노드에 바로 알리지 말고 먼저 suspect 단계를 추가하면 거짓 양성 비용 절감 가능
∘ (놀라운 건) 가십 방식의 멤버십은 정확도가 높은 게 장점이라고 한다. ㄷㄷ
참고로 교란된 프로세스는 이론적인 개념과 가십 프로토콜에서의 의미가 조금 다르다.
원래는 기본 프로세스(ex: 이상적인 가십 전파 모델)에 무작위적 또는 비결정적 요소가 추가된 상태를 말하고, 수학적으로는 기본 확률 모델에 노이즈나 변동이 추가된 것을 의미한다.
이게 가십 프로토콜에서 작용하는 의미는 노드 처리 속도 변동, 메시지 전송 지연 변동, 노드가 일시적 과부화 상태에 빠짐, 시스템 클록이 완벽히 동기화되지 않음 등을 의미한다고 한다.
더 적으려다가 내용이 너무 수학적으로 깊어져서 관뒀다.
재밌긴 한데 포스팅이 3배로 길어질 거 같아서 두려워졌다.
🔍 장애 해소(failure resolution) 전략
- gossip 프로토콜로 장애를 감지한 시스템은 가용성을 보장하기 위한 조치를 해야 한다.
- 일시적 장애 처리와 영구적 장애 처리 두 가지가 있다.
(여기서부터 책이 갑자기 급발진하는 느낌이 있다.)
1️⃣ 일시적 장애 처리
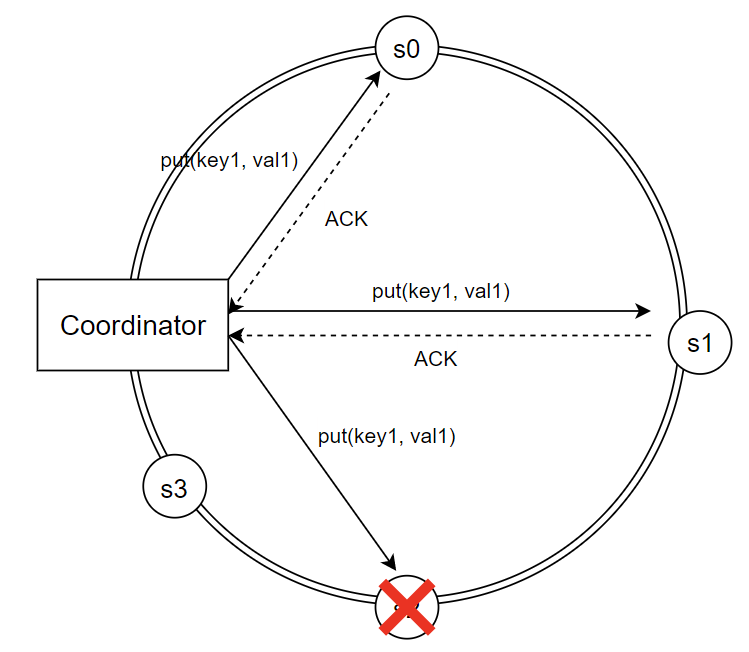
- 엄격한 정족수(strict quorum) 접근법이면, 지정된 서버가 장애 시 읽기와 쓰기 연산을 금지 (실패 처리)
- ex: s0, s1, s2에서 3개의 응답이 필요한데, s2가 다운되면 작업 실패
- 느슨한 정족수(sloppy quorum) 접근법은 가용성을 높이기 위해, 좀 더 유연한 방식을 채택
- 정족수 요구사항은 여전히 강제
- 쓰기 연산을 수행할 W개의 활성화 서버와 읽기 연산을 수행할 R개의 활성화 서버를 해시 링에서 선택 (장애 서버는 무시)
- 단서 후 임시 위탁(hinted handoff) 기법: 장애 서버로 가는 요청은 잠시 다른 서버가 처리하고, 장애 서버가 복구되면 일괄 반영하여 데이터 일관성 보존. (임시로 쓰기 연산을 처리한 서버는 단서(hint)를 남겨둠)
- ex: 위 이미지의 경우 s2에 대한 읽기/쓰기 연산은 일시적으로 s3가 처리하고, s2가 복구되면 s3는 갱신된 데이터를 s2로 인계
이게 뭔 소린가 싶은 부분이 있긴 한데, 여기서 ? 찍는 순간 또 포스팅 작성 시간 3시간 증가할 거 같아서 관뒀다.
(메모: s2가 계속 복구 안 되면 어떡함? s3가 인계받아서 처리하다가 얘도 장애처리되면??)
2️⃣ 영구적 장애 처리
- 반-엔트로피(anti-entropy) 프로토콜로 사본들 동기화 (사본들을 비교하여 최신 버전으로 갱신 과정 포함)
- 머클(Merkle) 트리: 사본 간 일관성 깨진 상태 탐지 및 전송 데이터 양 줄이기 위해 사용
(이 내용을 정리할까 하다가 진짜 뭔 소린지 못 알아 먹겠어서, 나중에 다시 시간내서 볼 예정)
📌 System Architecture Diagram
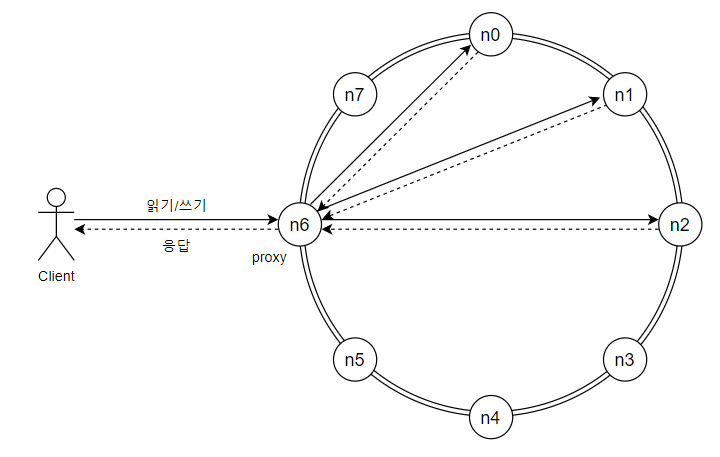
- 클라이언트는 키-값 저장소가 제공하는 두 가지 단순한 API(get, put)로 통신
- 중재자는 클라이언트에게 키-값 저장소에 대한 proxy 역할을 하는 노드
- 노드는 일관성 있는 해시의 해시 링 위에 분포
- 시스템 분산화를 통해, 노드 추가 및 제거 유연성 확보
- 데이터 다중화
- 모든 노드가 같은 책임을 가지므로 SPoF가 없어짐
- 클라이언트 API
- 장애 감지
- 데이터 충돌 해소
- 장애 복구 메커니즘
- 다중화
- 저장소 엔진 등등
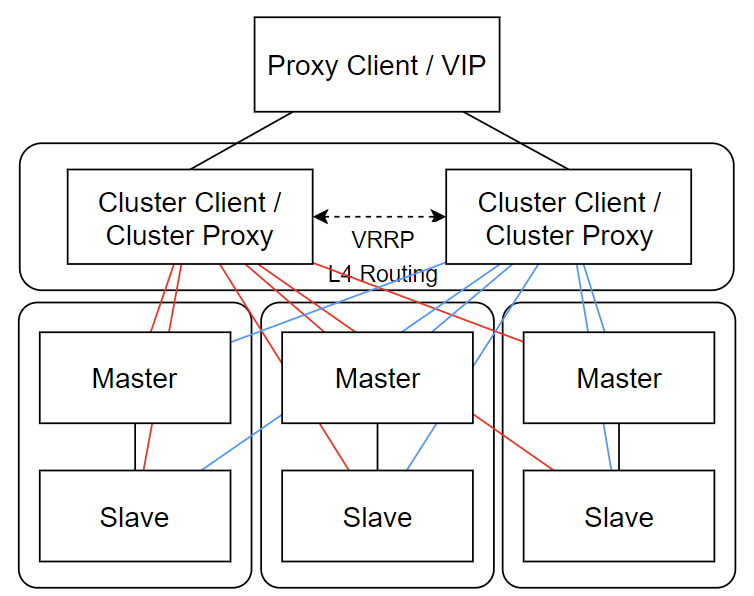
위 그림이 좀 더 이해하기 쉬운 거 같기도 하고...아직 감이 잘 안 오는 부분이 있어서, 직접 구현을 해봐야 알 거 같다.
📌 Write Path
Write Path와 Read Path 모두 카산드라(Cassandra)의 사례를 참고한 내용입니다.
- 쓰기 요청이 커밋 로그(commit log) 파일에 기록 (disk)
- 데이터가 메모리 캐시(mem cache)에 기록 (memory)
- 메모리 캐시가 가득차거나, 특정 임계치에 도달하는 disk의 SSTable에 기록 (disk)
쓰고보니 Redis도 비슷했던 거 같다.
📌 Read Path
- 데이터가 메모리에 있으면 반환 (memory)
- 없으면 블룸 필터(Bloom filter)를 검사 (disk)
- 블룸 필터를 통해 어떤 SSTable에 키가 보관되어 있는 지 탐색
- SSTable에서 데이터 조회 (disk)
- 해당 데이터를 반환
4. Conclusion
📌 Summary
| 목표/문제 | 기술 |
| 대규모 데이터 저장 | consistent hash로 서버 부하 분산 |
| 읽기 연산에 대한 높은 가용성 보장 | 데이터를 여러 데이터 센터에 다중화 |
| 쓰기 연산에 대한 높은 가용성 보장 | versioning & vector clock을 사용한 충돌 해소 |
| 데이터 파티션 | consistent hash |
| 점진적 규모 확장성 | consistent hash |
| 다양성(heterogeneity) | consistent hash |
| 조절 가능한 데이터 일관성 | 정족수 합의 |
| 일시적 장애 처리 | 느슨한 정족수 프로토콜과 단서 후 임시 위탁 |
| 영구적 장애 처리 | 머클 트리 |
| 데이터 센터 장애 대응 | 여러 데이터 센터에 걸친 다중화 |
이 포스팅 며칠 째 작성 중인지 모르겠다.
개인적으로 수학적 증명 내용들도 많아서 공부하다가, 너무 과하게 딥하게 들어가는 거 같아서 호다닥 끝내버렸는데
나중에 직접 구현해보면서 감을 좀 익혀야 할 필요성을 느낀다.