💡 해당 내용은 "가상 면접 사례로 배우는 대규모 시스템 설계 기초"를 참조하여 작성하였습니다.
📕 목차
1. 단일 서버
2. 데이터베이스
3. 수직적 규모 확장 vs 수평적 규모 확장
4. 캐시
5. 콘텐츠 전송 네트워크(CDN)
6. 무상태(stateless) 웹 계층
7. 데이터 센터
8. 메시지 큐
9. 로그, 매트릭 그리고 자동화
10. 데이터베이스의 규모 확장
11. 백만 사용자, 그리고 그 이상
✒️ 요약
아래 내용은 요약일 뿐, 절대 정답이 아니다!
• 웹 계층은 무상태 계층으로
• 모든 계층에 다중화 도입
• 가능한 한 많은 데이터를 캐시할 것
• 여러 데이터 센터를 지원할 것
• 정적 콘텐츠는 CDN을 통해 서비스할 것
• 데이터 계층은 샤딩을 통해 그 규모를 확장할 것
• 각 계층은 독립적 서비스로 분할할 것
• 시스템을 지속적으로 모니터링하고, 자동화 도구들을 활용할 것
1. 단일 서버
📌 가장 단순한 설계

- 웹, 앱, 데이터베이스, 캐시 모든 컴포넌트가 단 하나의 서버에서 동작하는 아키텍처
- 구축하기 가장 단순하고 쉽다.
시스템 규모를 확장하는 것은 지속적이고 반복적(iterative)인 과정이다.
이건 책에는 안 나오는 내용인데, 내가 정리하려고 써놓은 포스팅을 읽는 분들이 제법 계시길래 적어두자면..
아래 나오는 내용들은 제목 그대로 "대규모 트래픽을 제어"하기 위한 설계를 위한 구상들이다.
아직 런칭도 안 한 프로젝트나 사용자 수가 10명 정도밖에 안 되는 서비스에서 사용하기엔 너무 과한 것들이 많다.
따라서 "이런 방법도 있구나" 정도로만 봐두는 게 좋다.
2. 데이터베이스
📌 데이터베이스 선택
🟡 관계형 데이터베이스(RDBMS)
- MySQL, Oracle, Oracle Database, PostgreSQL 등
- data를 table, row, column으로 표현
- SQL을 사용해 Join이 가능
🟡 비-관계형 데이터베이스(NoSQL)
- CouchDB, Neo4j, Cassandra, HBase, Amazon DynamoDB, MongoDB, Redis
- 4가지 분류
- 키-값 저장소(key-value store)
- 그래프 저장소(graph store)
- 컬럼 저장소(column store)
- 문서 저장소(document store)
- 일반적으로 Join을 지원하지 않음
✅ NoSQL이 바람직할 수 있는 경우
- 아주 낮은 응답 지연시간(latency)이 요구 → 속도가 중요
- 다루는 데이터가 비정형(unstructured) 데이터 → 관계형 데이터가 아니라면 굳이 RDBMS로 다룰 이유가 없음
- 데이터를 직렬화(serialize)하거나 역직렬화(deserialize) 할 수 있기만 하면 되는 경우
- 아주 많은 양의 데이터를 저장해야 하는 경우 → 매번 DB에 저장하려면 DB 부담 + 속도 지연
📌 아키텍처 개선
- 트래픽을 처리하기 위한 서버와 데이터베이스용 서버로 분리
- 독립적 확장 가능
🤔 궁금한 점
- NoSQL도 종류가 다양한데, 어느 시점에 어떤 NoSQL 선택하는 게 바람직?
- S3보다 NoSQL에 캐싱했을 때 이점을 얻는 경우?
- 로그를 굳이 S3가 아닌 캐싱하기로 하면, Redis? MongoDB?
3. 수직적 규모 확장 vs 수평적 규모 확장
📌 수직적 규모 확장(scale-up)
- 서버 자원을 고사양으로 전환
- 트래픽 양이 적다면 나쁘지 않으며, 단순하고 쉽다.
- 단점
- 확장에 한계가 존재 → 현존하는 HW 스펙 or 클라우드 제공해주는 스펙 이상으로 늘릴 수 없음
- 비용 → AWS에서 업 스케일을 해본 적 있는가? 회사 돈으로 할 거 아니면 엄청난 부담이다.
- 자동복구(failover) 방안 없음 → 단일 장애 지점. 서버 죽으면 모든 서비스 중단
- 다중화(redundancy) 방안 없음 → 트래픽 몰리면 대책이 없다. docker-compose 같은 거 쓰면, 어느정도 핸들링 가능하긴 함
📌 수평적 규모 확장(scale-out)
- 스펙은 그대로 혹은 저가로 맞추고, 개수 자체를 늘리는 방법
- 장점
- 이론 상 확장은 무한대에 가까우며, 확장 개수를 잘 조절하면 up-scaling보다 값쌀 수도 있음
- 트래픽 분산 가능
- 가용성(availability) 증가 및 자동 복구 가능
- 단점
- 추가적인 과제들이 우후죽순 쏟아지기 시작함. (특히 동시성 문제)
📌 로드밸런서
- 클라이언트가 서버로 다이렉트로 접근하지 않고, 로드 밸런서를 경유하게 하는 방법
- 요청을 처리할 서버를 로드 밸런서가 선택
- 로드 밸런서는 public ip 주소, 서버는 private ip 주소를 갖는다.
- 가용성 확보: 서버1이 다운(offline)되어도 서버2가 트래픽을 받았다가, 서버1을 복구하거나 추가 증설
📌 데이터베이스 다중화
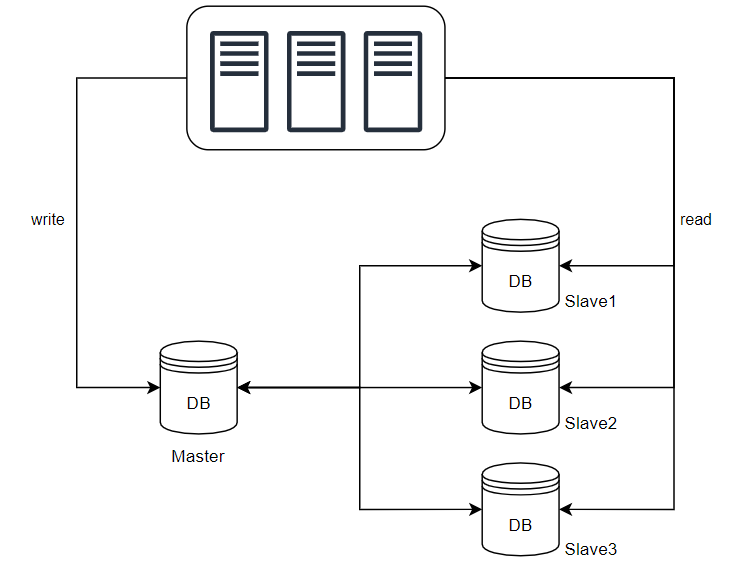
- 주(master)-부(slave) 관계로 분리
- master: 쓰기 연산 대상
- slave: 읽기 연산 대상
- 장점
- 병렬 처리 가능한 query가 증가하여 성능 개선
- 서버 일부가 파괴되어도 데이터가 보존 → ACID의 영속성(Durability) 보장
⚔️ 가용성 확보
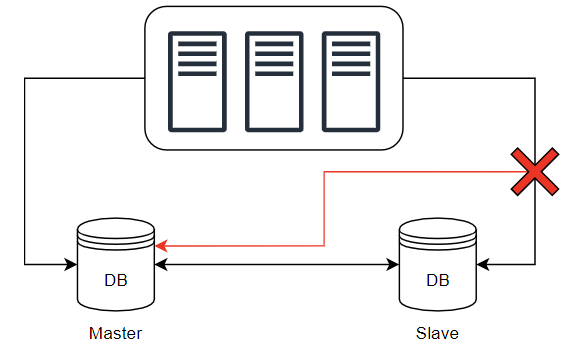
- 한 대 뿐인 부 서버가 다운되면 읽기 연산을 한시적으로 주 서버로 전달한다.
- 부 서버가 여러 대라면 다른 부 서버가 읽기 연산을 처리할 것이므로, 가용성이 확보된다.
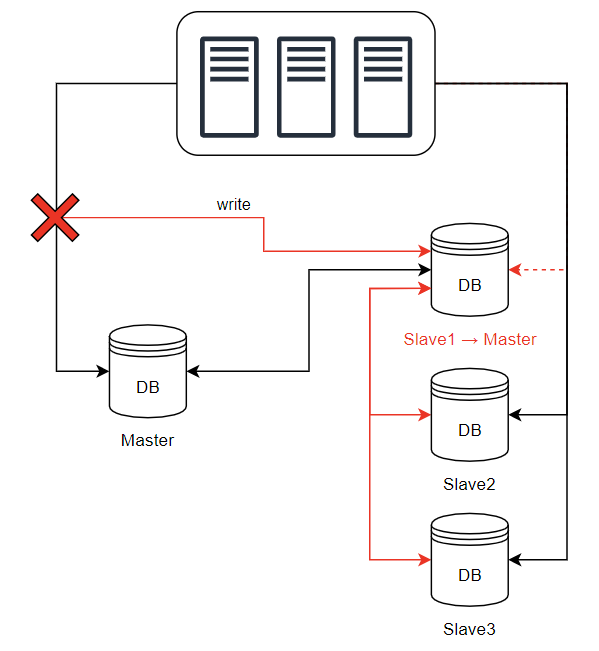
- 주 서버가 죽으면, 임의의 부 서버가 주 서버가 된다.
- 만약, 부 서버가 하나라면 부 서버를 주 서버로 전환한 후, 부 서버를 추가
- 실제 프로덕션 환경에선 더 복잡한 상황이 연출
- 주 서버로 전환된 부 서버의 데이터가 최신 상태가 아닐 수 있다.
- 복구 스크립트, 다중 마스터, 원형 다중화 방식 같은 걸 도입해서 없는 데이터를 복구해야 하는데, 구성이 매우 복잡해진다.
📌 아키텍처 개선
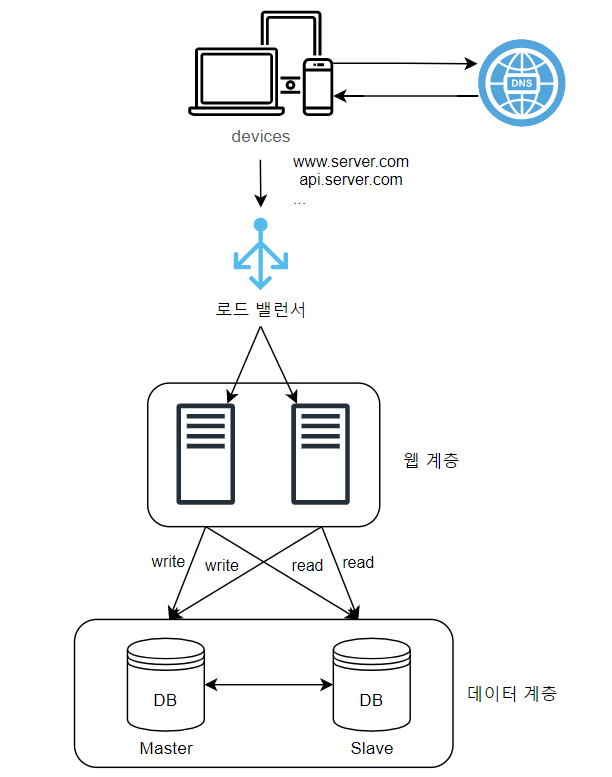
🤔 궁금한 점
- 단일 서버 내에서 docker-compose로 scale-out하면, 단일 서버 scale-up으로 어느정도 해결 가능하긴 할 듯.
- 단, 이것도 한계가 존재. 그만큼 단일 서버가 감당해야 할 부하가 심해지고, 트래픽이 한 곳으로 몰리는 것은 여전하므로...
- 어느 시점에 서버 scale-out을 고려하는 것이 적절할까?
- 데이터베이스 다중화 필요성은 언제쯤? 처음부터 주-부 관계 설정까지 하는 건 오버 엔지니어링이 아닐까?
- 데이터베이스 다중화 복구 스크립트, 다중 마스터, 원형 다중화 방식?
4. 캐시
📌 목표
- 값비싼 연산 결과, 자주 참조되는 데이터를 메모리에 임시 보관
- 연이은 요청 시 캐싱된 결과를 반환하여 부하 감소와 응답시간(latency) 감소
📌 캐시 계층
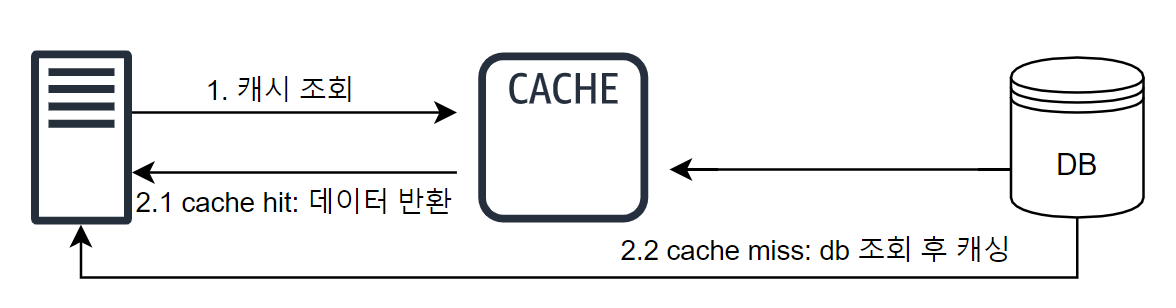
- 가장 일반적인 형태로 사용하는 게 주도형 캐시 전략(read-through caching strategy)
- 컴퓨터 구조에서 배웠던 캐시 전략 이야기가 아닐까 싶다.
- 언제 cache를 업데이트 할 것인지(read or write), cache miss가 발생했을 때 어떻게 할 것인지에 따라 경우의 수가 4개가 나온다. (조합 중 1가지 방법은 불가능함.)
- 캐시할 데이터 종류, 크기, 액세스 패턴에 맞는 전략을 선택하면 된다.
📌 유의할 점
1️⃣ 어떤 상황에 캐싱?
- CUD가 적고, Read가 잦은 데이터
2️⃣ 어떤 데이터를 캐싱
- 어쨌든 캐시는 휘발성 메모리. 영속적인 데이터 저장 시엔 부적합
3️⃣ 만료(expire) 정책
- 만료 기한이 너무 짧으면 DB 조회가 빈번해져서 성능 저하
- 만료 기한이 너무 길면 원본과 차이가 발생 (신선도 저하)
4️⃣ 일관성(consistency) 유지
- 연산이 단일 트랜잭션 내에서 처리되지 않으면 일관성이 깨질 수 있음
- 여러 지역에 걸쳐 시스템 확장 시, 문제가 많이 어려워짐
5️⃣ 장애 발생 시
- 캐시 서버를 하나 두면 단일 장애 지점(SPOF; Single Point of Failure)이 될 수 있다.
- SOF: 특정 지점의 장애가 전체 시스템을 마비시킬 수 있는 곳
- 캐시 서버를 분산시킬 필요가 있다.
6️⃣ 캐시 메모리 크기는 얼마나 크게?
- 캐시 메모리가 너무 작으면, 액세스 패턴에 따라 데이터가 캐시에서 너무 자주 밀려난다.
- 캐시 메모리를 과할당(overprovision)하면, 보관될 데이터가 갑자기 늘어나도 방지할 수 있다.
7️⃣ 데이터 방출(eviction)
- 캐시가 꽉 차면 새로 추가되어야 할 캐시가 기존 캐시를 밀어내야 한다.
- LRU(Least Recently Used) -
- LFU(Least Frequently Used)
- FIFO(First In First Out)
🤔 궁금한 점
- 캐싱을 과하게 많이 할 수록 메모리 부하가 심해져서 서버가 터질 수도..언제 캐싱을 하는 게 좋을까?
- 다중화 서버에서 공유해야 하는 캐시가 있다면, 읽기 & 쓰기 정책을 세우는 게 맞을까? 아니면 과한 설계?
- 캐시 메모리를 과할당하는 기준은? 너무 크거나, 작으면 안 됨.
5. 콘텐츠 전송 네트워크(CDN)
📌 CDN 개요
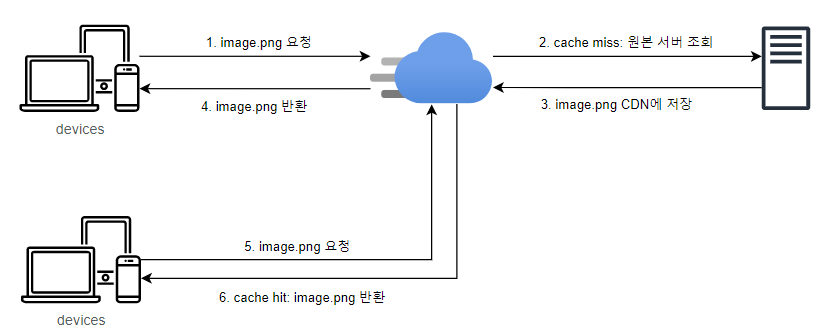
- 정적 컨텐츠(이미지, 비디오, css, javascript 등) 전송용
- 요청 경로(request path), 질의 문자열(query string), 쿠키(cookie), 요청 헤더(request heder) 등의 정보에 기반해 HTML 페이지 캐
- 지리적(물리적)으로 분산된 서버 네트워크
- 사용자와 물리적으로 인접하므로 빠르게 로드할 수 있다.
📌 고려 사항
- 비용
- 직접 사용자와 물리적으로 가까운 곳에 서버를 구축할 게 아니라면, 보통 제 3 사업자에 운영되는 것을 사용할 것이다.
- 이 때, 트래픽 양에 따라 요금을 내게 될 테니, 자주 사용되지 않은 컨텐츠는 캐싱하지 않는 것을 고려
- 만료
- 시의성이 중요한(time-sensitive) 컨텐츠의 경우 마찬가지로 캐싱 신선도 문제가 발생할 수 있다. 너무 짧지도, 너무 길지도 않아야 한다.
- CDN 장애 대처
- CDN 자체가 죽으면, 임시로라도 원본 서버로부터 컨텐츠를 가져가도록 클라이언트를 구성할 필요가 있을 수도 있다.
- 컨텐츠 무효화
- API: CDN 서비스 사업자가 제공하는 API로 무력화
- Object Versioning: `image.png?v=2`와 같은 식으로 컨텐츠의 버전을 관리
📌 아키텍처 개선
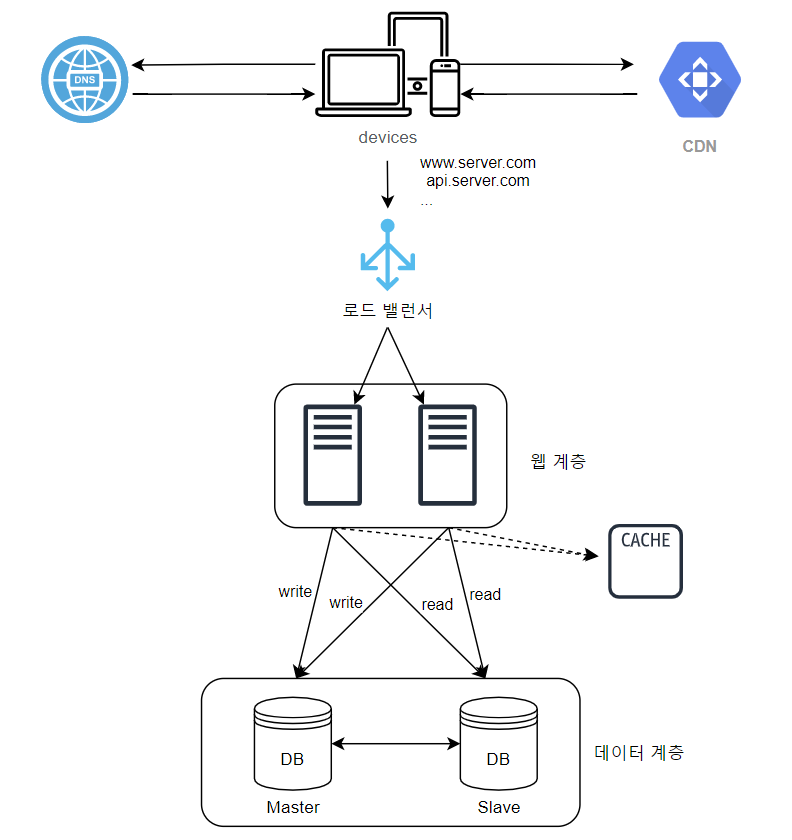
- 정적 컨텐츠는 웹 서버가 아닌 CDN을 통해 제공하며, 부하 분산은 물론 사용자에게도 더 나은 성능 보장
- 캐시가 DB 부하 줄여줌
🤔 궁금한 점
- CDN 장애 대처 시, 서버 측에서 핸들링할 수는 없을까?
6. 무상태(stateless) 웹 계층
📌 상태 정보 의존적인 경우
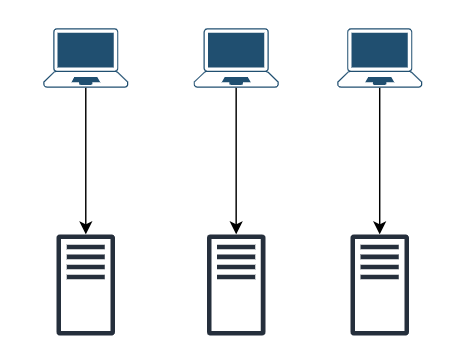
- 서버가 각각 상태 정보를 보관하면, 서로 간에 정보 동기화가 되지 않는다.
- 사용자A의 요청을 서버1이 처음 수행했다면, 사용자A의 모든 요청은 앞으로도 서버1이 담당해야만 한다.
- 만약 사용자A의 요청이 서버2로 가면 인증 정보가 없으므로 실패할 수도 있다.
- 로드밸런서의 고정 세션(sticky session) 기능을 사용하여 구현할 수 있지만, 로드밸런서 부담이 높아진다.
📌 무상태 아키텍처
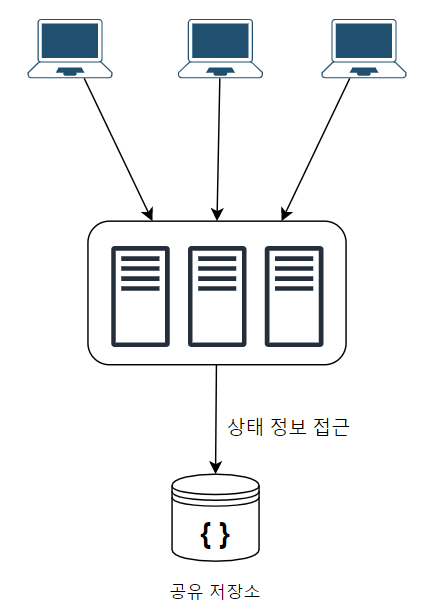
- 웹 계층의 상태 정보를 DB나 NoSQL 같은 지속적 저장소에 저장한다.
- 함수형 프로그래밍처럼 가변적인 영역과 불변적인 영역을 분리한다고 생각하면 쉽다.
- 웹 계층은 더 이상 개별적으로 상태 정보를 보관하지 않으므로 무상태(stateless)가 되고, 확장에 용이해진다.
📌 아키텍처 개선
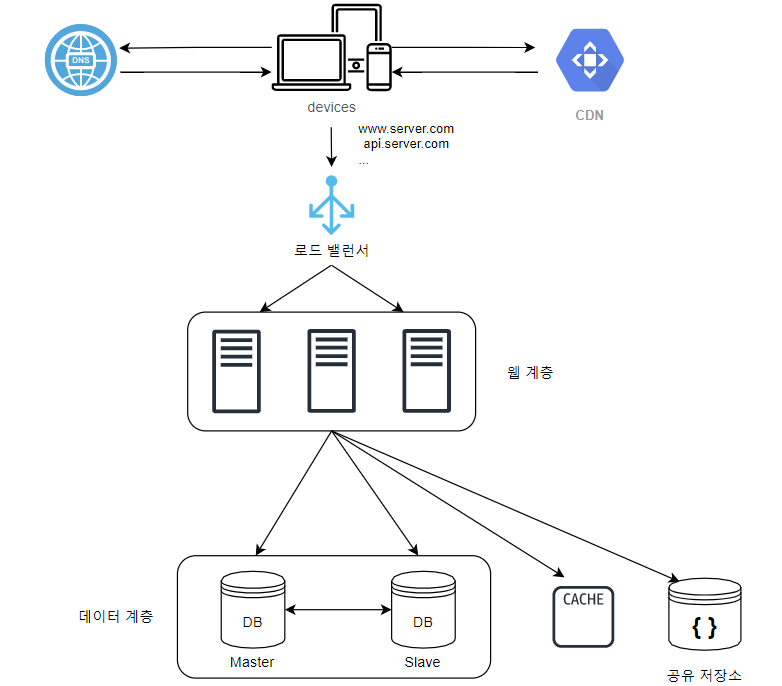
- 웹 계층은 유연하게 오토 스케일링(autoscaling)이 가능해졌다.
🤔 궁금한 점
- 세션 정보를 RDB로 다룰지? NoSQL로 다룰지? 데이터의 성격에 따라 달라지는 건지, 그저 속도가 중요한 건지?
- 이론적으론 매우 우아한 방법이지만, 동시성 문제가 발생할 수 있다.
- 이를 제어하기 위한 비용은 고려하지 않는지?
- 세션 클러스터링, 분산락 등을 사용해야 한다면 이로 인한 오버헤드가 발생함. 무조건 위 아키텍처를 구성하는 게 좋은 거라 볼 수 있을지?
7. 데이터 센터
📌 다중 데이터센터 아키텍처 개요
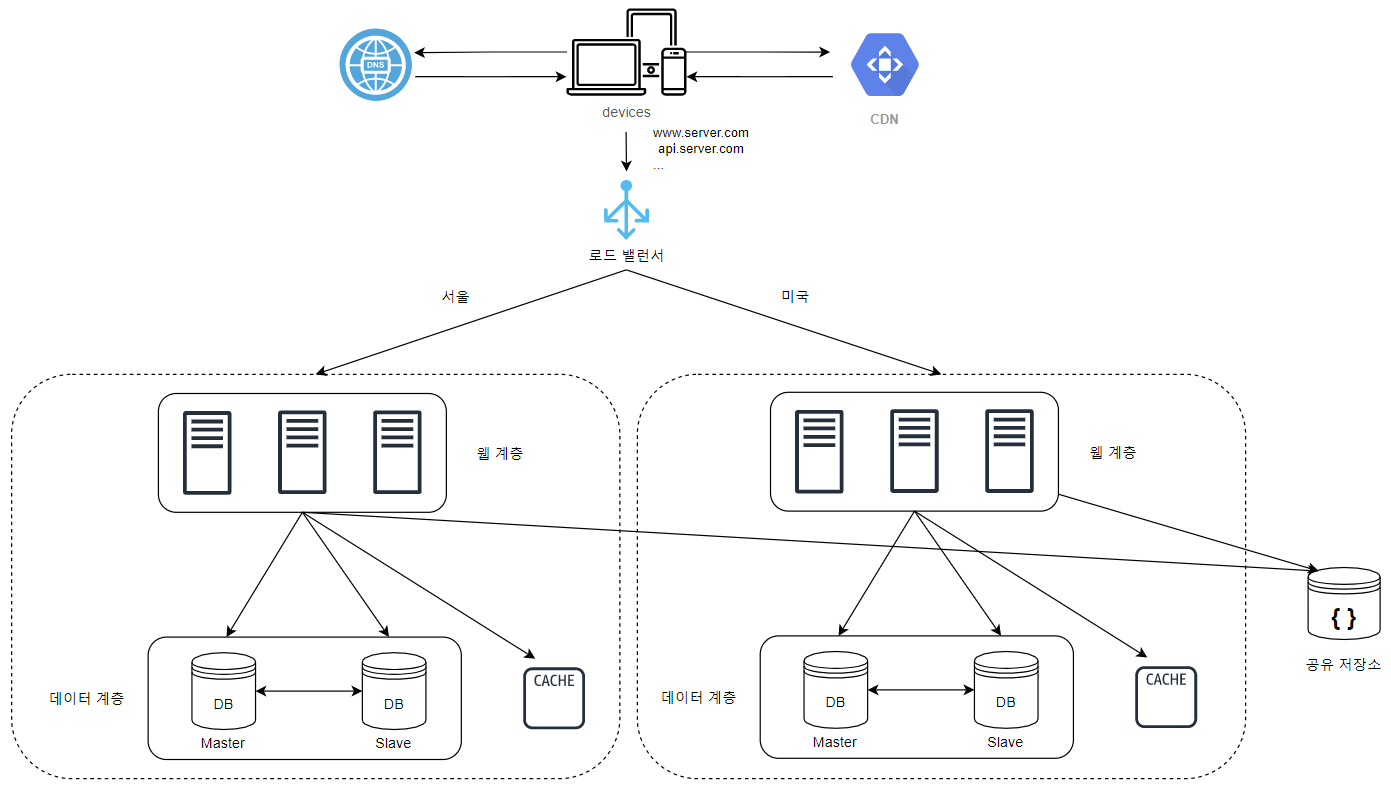
- CDN처럼 데이터 센터도 사용자와 물리적으로 가까운 곳에 배치하는 전략
- 장애가 없다면, 사용자는 가장 가까운 데이터 센터로 요청이 전달됨
- 지리적 라우팅(geoDNS-routing 또는 geo-routing)으로 사용자 위치에 따라 도메인 이름을 치환할 IP 주소 결정해주는 DNS 서비스
- 하나의 데이터 센터에 장애가 생기면, 다른 데이터 센터로 요청 전달
📌 기술적 난제
- 트래픽 우회
- 올바른 데이터 센터로 트래픽을 보내는 효과적인 방법 필요
- 데이터 동기화(synchronization)
- 각 데이터 센터가 독자적인 데이터베이스를 사용하고 있다면, 문제가 발생할 수 있음
- 장애가 자동으로 복구되어 트래픽이 다른 곳으로 옮겨진다고 해도, 해당 데이터 센터에는 찾는 데이터가 없을 수도?? → 서울 리전 서비스 사용하던 사용자 정보가 미국 리전 서비스에도 존재하는가?
- 보편적 전략은 데이터를 여러 데이터 센터에 걸쳐 다중화하는 방법 → 어케 했는데..
- 테스트
- 애플리케이션을 여러 위치에서 테스트해봐야 함
- 모든 데이터 센터에 동일한 서비스가 설치되어 있어야 함
🤔 궁금한 점
- 데이터 센터가 공유하는 저장소 위치는 어디에?
- 이것도 지리적으로 중간 위치 쯤 여러 개 두어 다중화??? 비용은 둘 째치고 가능하긴 한 건가.
- 모든 데이터에 대해 다중화를 할 필요가 있을까?
- 서비스 성격에 따라 달라지려나..예컨데 한국 사용자에게만 열리는 이벤트 정보를 미국 데이터 센터 DB에 놔둘 필요가 있을까.
- 다만 서울 리전이 다운되면, 미국으로 트래픽이 갈 텐데 이벤트도 중단?? 그럼 진짜 모든 데이터를 동기화해야 하나?
8. 메시지 큐
📌 메시지 큐 개요

- 메시지 무손실(durability)을 보장하는 비동기 통신(asynchronous communication)을 지원하는 컴포넌트
- 메시지 버퍼 역할을 하며, 소비자가 꺼낼 때까지 메시지를 안전하게 보관
이게 처음 보는 사람은 좀 이해가 안 갈 수 있는데, 우선 목적은 "시스템의 컴포넌트를 분리하여, 독립적으로 확장될 수 있도록 하는 것"이다.
메시지 큐가 나오면 이제 MSA 내용이 살짝 감미되는데..조금 알아듣기 쉽게 써놓으면 아래와 같다.
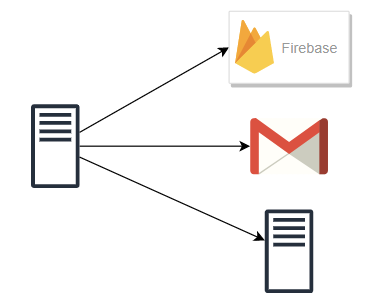
- 이벤트를 발행하는 서버1와 구독을 하는 서비스(FCM, Gmail, 서버2)가 존재한다고 가정
- 서버1은 각 서비스에서 요구하는 요청 스펙에 의존하게 됨.
- FCM, Gmail, 서버2 또한 변경에 유연할 수가 없음 (잘못하면 서버1의 요청을 받지 못 하게 되므로)
- 문제는 서버2가 잠시 다운되어 데이터를 받지 못하면, 서버1은 그동안 대기하거나 실패하게 됨.
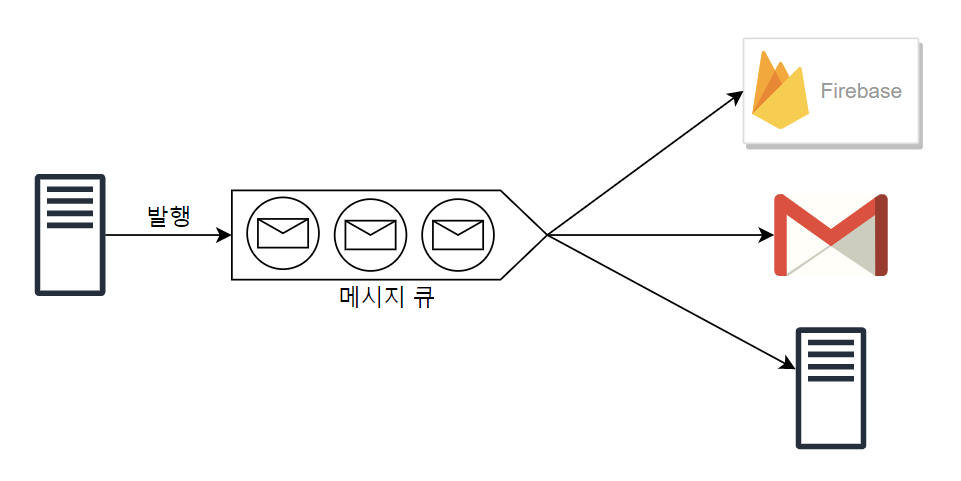
- 서버1은 메시지를 받을 구체적인 서비스의 존재를 모름. 그냥 topic에 대한 메시지를 발행하기만 하면 됨
- FCM, Gmail, 서버2 또한 구독 신청만 해놓으면 정보를 받을 수 있음
- 서버2가 잠시 다운되어도 서버1은 알 필요 없고, 메시지 큐에 저장되어 있음이 보장. 따라서 서버2가 복구되는 대로 쌓여있던 메시지를 꺼내서 처리하면 그만.
- 서비스 또는 서버 간 결합이 느슨해지므로, 규모 확장성이 보장된다.
🤔 궁금한 점
- 메시지 큐를 도입하면 항상 어지러운 게 실패했을 경우의 핸들링..서버1은 메시지 큐에 발행하고 클라이언트에게 성공 응답 보냈는데, 서버2가 뻗어있으면 사용자는 데이터를 받지 못 함.
- 물론 상황마다 다르겠지만, 처리해줄 수 있다면 처리해주는 게 맞는가? 그렇다면 인프라 측면으로 핸들링이 가능한가?
9. 로그, 매트릭 그리고 자동화
"이 정돈 해라!" 이런 느낌 ㅋㅋ
📌 로그
- 에러 로그 모니터링은 중요
- 서버 단위로도 가능. 로그를 단일 서비스로 모아주는 도구를 활용하는 것도 용이
- AWS Cloud Watch 같은 서비스 사용하면 매우 편리
📌 매트릭
- 호스트 단위
- .CPU, Memory, Disk I/O에 대한 정보
- 종합(aggregated) 매트릭.
- 데이터베이스 계층 성능
- 캐시 계층 성능
- 핵심 비지니스 매트릭 → Google Analytics 같은 서비스 사용하면 쉽게 적용 가능
- 일별 능동 사용자(daily active user)
- 수익(revenue)
- 재방문(retention)
📌 자동화
- 개발자가 개발 이외의 곳에서 인적 리소스를 낭비하게 된다면, CI/CD 파이프라인을 도입해 자동화를 고려해야 함
- 빌드, 테스트, 배포 등등.
📌 아키텍처 개선
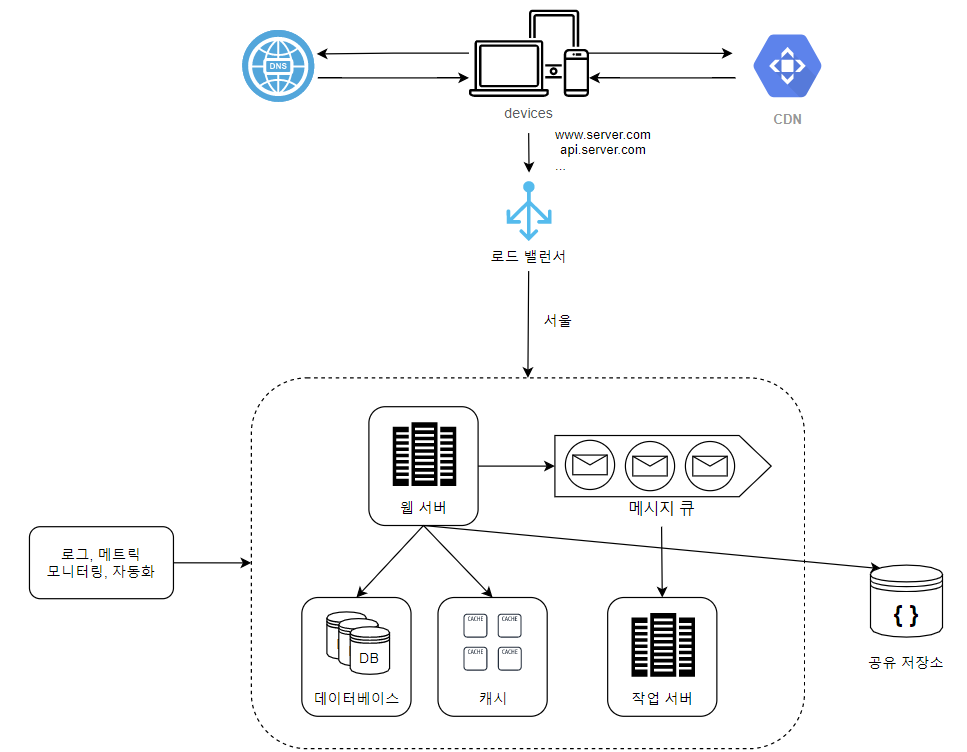
🤔 궁금한 점
10. 데이터베이스의 규모 확장
📌 수직적 확장
- DB를 고성능으로 바꾸는 방법
- 서버 up-scale과 같은 단점을 갖는다
- 특히 비용이...Cloud에서 제공하는 SQL 서비스를 사용해본 적이 있는가? 진짜 돈 엄청 깨진다.
📌 수평적 확장 : 샤딩(sharding)
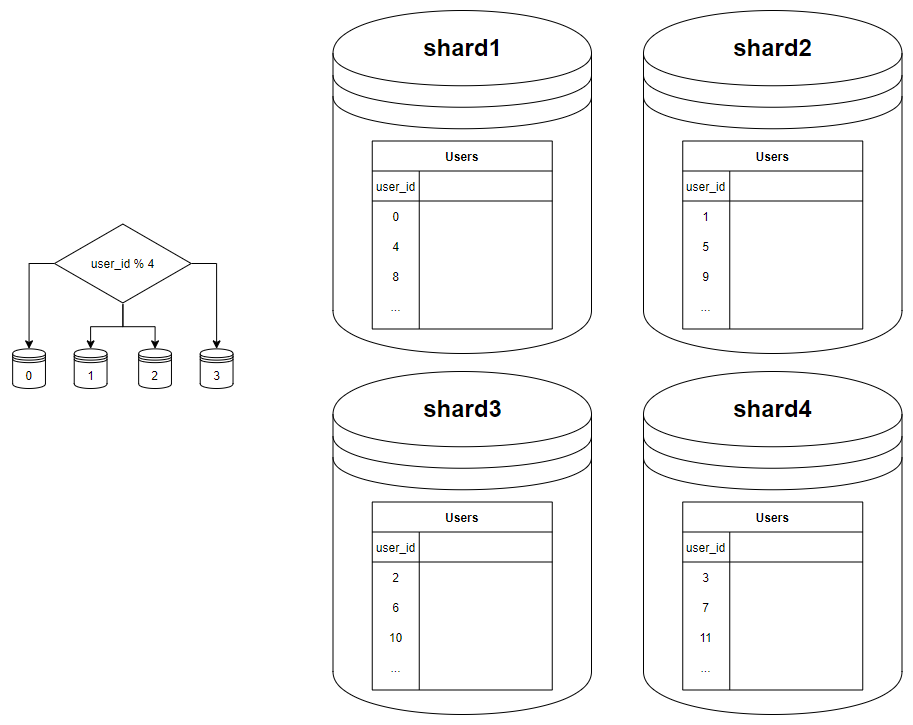
- 샤딩(sharding): 데이터베이스 수평적 확장을 뜻함. NoSQL도 마찬가지
- 모두 같은 스키마를 사용하지만, 샤드에 보관되는 데이터 사이 중복이 없음
그런데 내가 알기론 이 샤드라는 개념이 제대로 자리 잡지 못 한 것으로 알고 있는데, 시스템이 복잡해지고 새로운 문제가 많이 생긴다.
여기에 대한 트러블 슈팅..재밌겠다
📌 샤딩 도입 시 고려 사항
- 샤딩 키(파티션 키)의 기준은 어떻게?
- 하나 이상의 컬럼으로 결정
- 데이터를 고르게 분할할 수 있도록 하는 게 가장 중요
- 데이터 재샤딩
- 데이터가 너무 많아지거나, 샤드 간 데이터 분포가 고르지 못한 경우 필요 → 샤드 소진(shard exhaustion)
- 샤드 키를 계산하는 함수를 변경하고, 데이터 재배치해야 한다. → 이후 배울 안정 해시(consistent hashing) 기법
- 유명인사 문제(핫스팟 키, 핫 키 문제)
- 특정 샤드에 질의가 집중되어 서버 과부화 걸리는 경우
- 유명한 사람들이 하나의 샤드에 저장되어 있다면, read 연산 때문에 과부화 발생
- 유명인사마다 하나의 샤드를 제공하거나, 더 잘게 쪼개야 함
- 조인과 비정규화
- 여러 샤드에 걸친 데이터는 조인이 어려움
- 역정규화해서 조인이 필요 없게 만들어버리는 방법이 있음
📌 아키텍처 개선
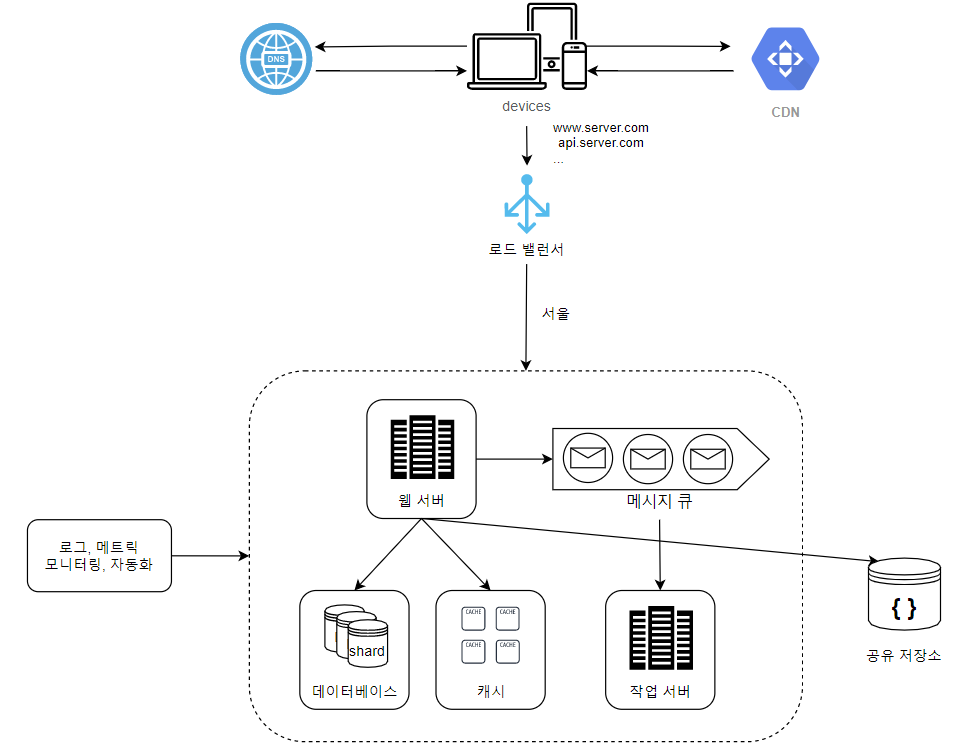
🤔 궁금한 점
샤딩을 도입해야 할 정도의 규모 있는 서비스를 운영해보질 못 해서, 뭐가 궁금한지도 모르겠다.
뒷 내용 읽으면서 생기면 차근차근 처리할 생각