📕 목차
1. 개요
2. 저장
3. 조회
4. 리사이징
5. 기타
6. 결론
1. 개요
📌 계기
[NCP] Cloud Function으로 Object Storage presigned url 발급
📕 목차 1. 개요 2. Sub Account API Key 발급 3. Cloud Function & API Gateway 4. 실행 1. 개요 📌 presigned url Object Storage(= AWS S3)는 일반적으로 누구나 접근해서 수정 가능하면 안 된다. 그렇다면 권한 인증을 받
jaeseo0519.tistory.com
이전에 Naver Cloud에서 제공하는 Object Storage를 사용하면서 presigned url을 사용한 적이 있었다.
해당 방식을 통해 사진을 저장하고 조회하는 기능을 구현할 수는 있었지만 여러가지 문제점 또한 존재했었다.
- presigned url 발급 주체를 Lambda에서 처리해서 인증된 사용자 뿐 아니라, 해당 Api 경로를 알면 누구나 PUT 권한을 받을 수 있다.
- 원본 이미지가 그대로 저장되므로 악의를 가진 누군가가 대용량 이미지를 삽입하면 비용이 과다하게 청구될 우려가 있다.
- 이미지 리사이징을 하지 않고 있으므로, 클라이언트가 이미지를 조회할 때 언제나 원본 사진을 받는 불필요한 과정이 필요하다.
- 사진 경로만 알고 있으면 누구나 언제 어디서든 조회할 수 있다.
새로운 프로젝트에서는 팀원이 Naver Cloud 말고 AWS 좀 써보고 싶다고 해서 S3를 사용하게 되었다.
그리고 인프라를 담당하는 팀원이 S3 정책을 어떻게 할 것인지 PM인 내가 결정해주어야 할 목록들의 리스트를 건네주었는데, 정말 고려할 것들이 생각 이상으로 많았었다.
처음에는 사진 규격을 어떻게 정할지에 대해서 서칭을 시도하다가 이미지 리사이징에 대해 알아보게 되었고,
이미지 리사이징을 위한 여러가지 전략들을 보다보니 가성비의 람다의 메모리와 시간 제한을 정하는 내용들을 찾아보다가
presigned url 뿐 아니라 signed url의 존재 등등
그래서 이 방대한 자료들을 집약한 포스팅을 작성해보고 싶었다.
물론 나는 이론적인 내용들에 보다 치중할 예정이고, 내가 참고했던 링크들을 중간중간 덧붙일 생각이다.
📌 최선의 방법이란

이 글에서 가장 찔렸던 부분은 "본인 호기심을 대입하거나 과도한 모듈화를 핑계료 일을 크게 벌이게 된다면"이었다.
PM의 자아는 업무의 효율과 생산성을 고려한 최선의 방식을 택해야 했지만,
개발자로서의 자아는 새로운 방법론들을 내 서비스에 적용해보고 싶은 순수 재미가 우선이었다.
하지만 이는 개인 프로젝트가 아닌 협업이고, 인프라에서 사용한 모든 자원은 비용이 청구된다.
그리고 경험이 없는 개발자라면 새로운 학습을 해야 하는 비용과 구현하기 위한 비용까지 고려해야만 한다.
비단 나만의 이야기가 아닐 것이다.
따라서 아래에서 나오는 내용 중 어떤 전략을 사용할 지는 "정답"이 아니라, 해당 서비스에 맞는 "최선"의 방법을 고르는 것이 마땅하다.
💡 세부적인 사항을 모두 다루지는 않고, 전체 아키텍처 관점에서 이야기할 예정입니다.
2. 저장
📌 이미지를 어디에 저장할 것인가?
1️⃣ Server
Server에 저장하면 Application이 동작하는 서버에 저장하게 된다.
이 방식은 많은 문제가 존재하는데, 우선 큰 용량을 갖는 이미지를 WAS에 계속 저장해야 하며, 사진을 저장하기 위한 대역폭 또한 제공해야 하므로 부하가 심해질 우려가 있다.
다만 Application이 자원을 관리하는데 있어서는 정말 쉬워지기 때문에 서비스에 필요한 작은 용량의 이미지 정도를 관리하고 싶다면 나쁘지 않을 수도 있다.
물론 난 사용하지 않는다.
2️⃣ Cloud Storage (ex. S3, Object Storage)
클라우드에서 제공하는 정적 스토리지를 사용하는 방법.
일반적으로 이 방식을 많이 채택한다.
📌 누가 S3에 저장(접근)할 것인가?
1️⃣ Client
가장 간단한 방법은 S3 자원에 접근 가능한 IAM 계정을 클라이언트 소스 코드에 넣어버리고, 직접 S3에 정적 파일을 저장하는 방식이다.
당연히 보안에 상당히 취약하다.
2️⃣ Server
권한을 갖는 계정을 Server가 관리하고, Client가 자원을 저장하고 싶다고 요청을 하면 처리하는 방법이다.
WAS를 거쳐서 S3에 저장을 하거나, presigned url을 발급해서 일정 시간 동안 S3 자원에 PUT 요청을 허용해주는 방법이 있다.
✒️ presigned url과 signed url
presigned url은 미리 서명된 url을 클라이언트에게 제공하여, 클라이언트가 url에서 식별된 객체에 액세스할 수 있도록 만들고 싶을 때 사용한다. 예를 들어, S3의 특정 key(url)에 대한 서명을 하고 인증된 사용자에게 반환하면, 서버의 대역폭을 사용하지 않고도 클라이언트가 S3와 직접 통신하여 파일을 업로드할 수 있다.
signed url에는 만료 날짜, 시간과 같은 정보를 추가적으로 기입한다. 서명된 쿠키 방식으로도 사용한다고 하는데, 일반적으로 컨텐츠를 조회하기 위한 경로를 제한하는데 사용한다. 예를 들어, S3의 url로 직접적인 조회를 막고 CloudFront의 서명된 url로만 접근하도록 하는 방식이다.
해당 블로그에 보다 자세히 적혀있다.
📌 S3에 어떻게 이미지를 전송할 것인가?
Spring Boot에서 S3에 파일을 업로드하는 세 가지 방법 | 우아한형제들 기술블로그
Spring Boot에서 S3에 파일을 업로드하는 세 가지 방법 | 안녕하세요. 세일즈서비스팀에서 전자계약서 시스템을 개발하고 있는 박민규입니다. 최근 저는 Spring Boot + Kotlin을 활용한 프로젝트에서
techblog.woowahan.com
(우아한 기술 블로그에 정리가 너무 친절히 되어 있어서 내가 쓸 게 없다..)
1️⃣ Stream 업로드
- 업로드할 binary data를 Spring Boot 애플리케이션을 실행 중인 서버의 디스크나 힙 메모리에 저장하지 않고 전송하는 방식 (약간의 메모리를 사용하긴 한다.)
- 애플리케이션을 경유하기만 하기 때문에 전처리가 불가능하다.
- 1회 API 호출에 1개 파일만을 업로드 가능하다. (바이너리에서 여러 개 파일 데이터를 구분할 기준이 없음)
- 대용량 파일 업로드에 유용해보이지만, 실제로 그렇지 않으며 클라이언트에게 업로드 현황을 제공해줄 수 없다.
2️⃣ MultipartFile 업로드
- Spring에서 제공하는 MultipartFile 인터페이스를 이용하는 방법
- 클라이언트가 WAS로 파일을 업로드 하면, 임시 디렉터리에 저장한다.
- 힙 메모리가 아닌 Sevelet Container Disk에 저장된다.
- 요청 처리가 끝나면 임시 저장된 파일이 삭제된다.
- Spring은 임시 디렉토리에 저장된 파일을 MultipartFile 변수에 매핑하여, 업로드된 파일의 바이너리를 힙 메모리에 할당하지 않고도 해당 컨텐츠 metadata에 접근할 수 있다.
- Thead가 작업을 수행하는 동안 부담이 될 수 있다.
3️⃣ AWS Multipart 업로드
- AWS S3에서 제공하는 파일 업로드 방식으로, 파일 바이너리가 Spring Boot를 거치지 않는다. (서버 부하를 고려하지 않아도 됨)
- 이것도 Multipart upload기 때문에 업로드 현황을 클라이언트가 확인 가능하다.
- 처음에 보면 이해가 잘 안 될 텐데, 플로우가 대충 다음과 같다.
- Multipart 시작을 위해서 Upload Id와 PartNumber, 그리고 presigned Url을 발급받는다.
- S3에 파트를 분할하여 전송한다. 각 분할된 데이터마다 PartNumber와 ETag 값이 오는데 이 값들을 저장한다.
- Upload ID와 (2)에서 저장한 PartNumber, Etag 배열을 S3로 보내서 업로드를 완료 처리한다.
📌 presigned url은 누가 발급할 것인가?
예전에 나는 Lambda를 사용해서 presigned url을 발급받게 만들었는데, 문제는 이렇게 하면 인증된 유저가 아닌 사용자도 S3에 PUT 권한을 얻을 수 있게 된다.
이걸 별도로 처리하기 귀찮다면, 개인적으로 presigned url은 WAS에게 요청해서 받는 게 경험적으로 편했다.
📌 .webP 확장자 변환
서버 비용을 70%나 줄인 온디맨드 리사이징 이야기
비트윈에서는 사용자들이 올린 사진들을 빠르고 비용 효율적으로 처리하기 위해서 많은 노력을 하였습니다. 이번 포스팅에서는 비트윈에서 더 나은 사진 처리를 위해서 어떠한 아키텍쳐를 구
blog-tech.tadatada.com
이건 처음 알았는데, 단순히 리사이징이나 이미지 압축으로 끝내는 것이 아니라 .webP 파일로 확장자를 변환하면 용량을 더 절약할 수도 있다.
다만 이렇게 하려면 중간에 확장자를 변환해주는 서버를 구현하거나, Lambda를 구현할 필요가 있다.
그리고 가장 중요한 건 조회할 때는 다시 원본 확장자로 변환해주어야 하는 건데, On demand 리사이징 방식이 아니면 좀 힘들지 않을까....싶다.
3. 조회
📌 누가 조회할 수 있는가? (feat. Public Access)
S3에는 url만 알면 누구나 정적 자원을 조회할 수 있도록 옵션을 제공해줄 수 있지만, 보안 상 취약하기 때문에 일반적으로 권장하지 않는다.
그렇다면 제한된 경로로만 S3 자원에 접근 가능하도록 만들어야 하는데 어떻게 할 수 있을까?
📌 presigned url
PUT 요청처럼 GET 요청 또한 미리 서명된 url을 WAS에서 제공해주는 방법이 존재한다.
만약 해당 자원이 서비스의 보안 기능을 사용하여 강력한 보안 정책을 필요로 한다면 사용해볼 수도 있을 것 같다.
하지만 일반적인 자원 접근 요청에 대해 이러한 방식으로 처리하는 건, 불필요하게 WAS의 트래픽을 증가시키는 꼴이 된다.
또한 해당 로직에 대한 구현을 처리해주어야 하고, 제한된 시간 동안 누구나 S3 자원의 직접적인 접근을 허용해주므로 보안 상 위험할 수 있다.
따라서 모든 요청을 presigned url로 처리하는 것은 고려해볼 필요가 있다.
📌 Cloud Front (CDN)
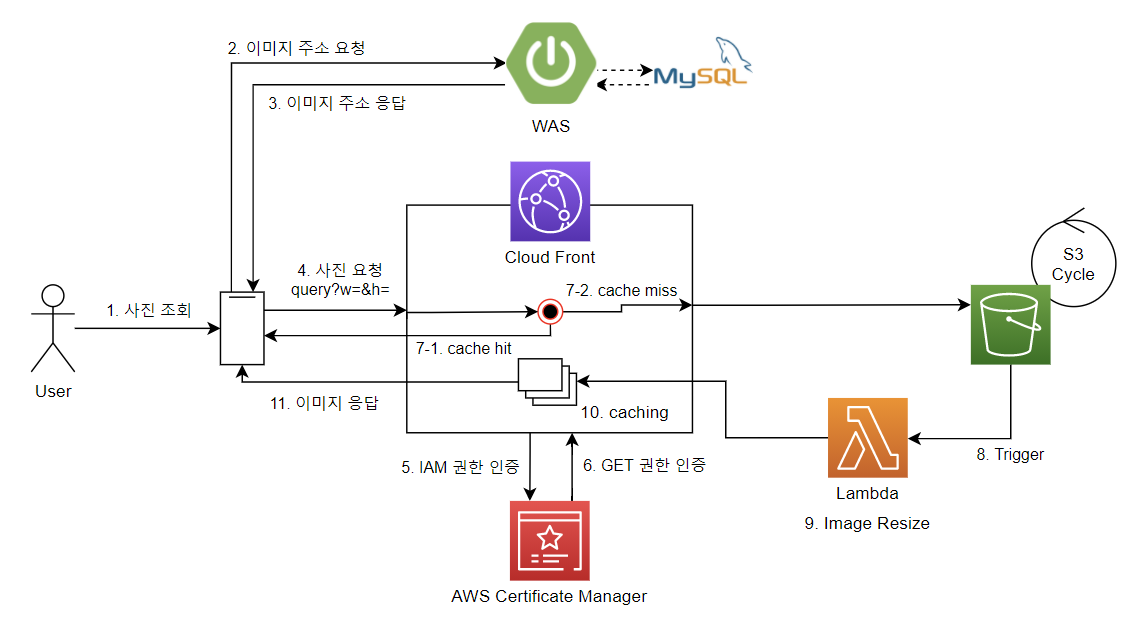
CDN(Cloud Front)는 콘텐츠 전송 네트워크로, 사용자와 가까운 서버에 콘텐츠를 캐시하여 전송 속도를 높이고 원본 속도의 부하를 줄여줄 수 있다.
물리적으로 가까운 곳에서 응답을 받기에 전송 속도 향상과 트래픽 부하 분산에 용이하며, SSL/TLS 암호화를 통해 데이터 전송 보안을 강화할 수 있다. (몰랐는데, Web Application Firewall와 통합하여 보안 위협을 방어할 수도 있다.)
특히 저 캐시 기능이 워낙 강력하다보니 이미지 조회 시엔 CDN을 정말 많이 사용한다.
4. 리사이징
📌 저장할 때 리사이징
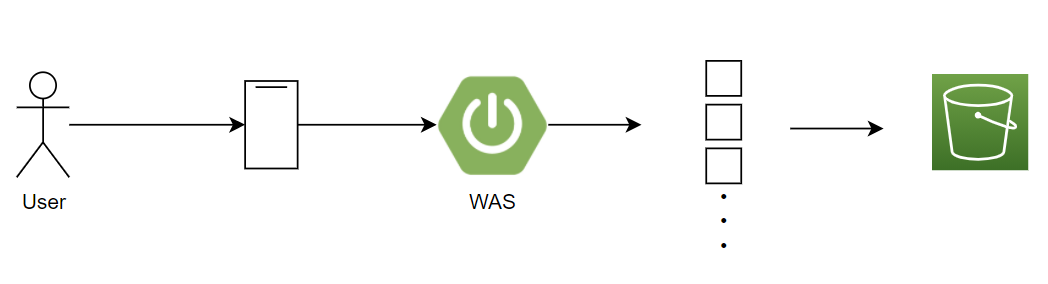
가장 단순하게 생각해볼 수 있는 아이디어로써, 저장하는 시점에 원본 이미지를 리사이징까지 해서 S3에 저장하는 방법이다.
서버가 이미지를 받아서 필요한 크기로 리사이징한 후, 원본 이미지와 함께 리사이징된 이미지를 S3 버킷에 저장하는 방식이다.
- 장점
- 구현이 단순하고, 업로드와 동시에 리사이징을 처리할 수 있다.
- 업로드 시점에 이미지를 리사이징하므로, 이후 이미지 조회 시 추가 작업이 필요 없다.
- 단점
- 트래픽이 많을 경우 서버 부하가 증가할 수 있으며, 리사이징 속도가 충분히 빠르지 않다면 사용자의 접근 또한 그 시간만큼 제한된다.
- 서버 리소스가 한정되어 있으므로 대규모 서비스에서는 확장성이 떨어진다.
📌 저장하고 리사이징
AWS Lambda를 이용한 이미지 썸네일 생성 개발 후기
당근마켓에서는 2019년 1월부터 Lambda@Edge를 이용해 실시간으로 이미지 변환하는 방법으로 전환했습니다. 새로운 방식에 대해서는 아래 링크 참고해주세요.
medium.com
S3와 Lambda를 활용하는 방식으로써, 사용자가 이미지를 저장하면 이벤트 트리거를 통해 Lambda 함수를 호출해 이미지를 리사이징한다.
그리고 리사이징된 이미지를 다시 S3에 저장하는 방식이다.
- 장점
- 서버를 거치지 않으므로 부하를 분산시킬 수 있다.
- Lambda는 사용한 만큼 비용을 지불하면 되므로 가성비가 좋고, 확장성 또한 좋다.
- 단점
- 이벤트 기반 처리를 위한 설정과 관리가 복잡할 수 있다.
- 리사이징 작업이 비동기로 처리되므로, 리사이징된 이미지를 바로 사용할 수가 없다.
- 만약 리사이징 도중에 클라이언트가 자원을 요청하면, 원본을 반환해주는 식으로 처리해줄 수 있다.
- 클라이언트가 응답 실패가 발생했을 때 예외 처리를 해주거나, 서버가 자체적으로 라우팅해주거나 선택적으로 적용하면 될 것 같다.
📌 조회할 때 리사이징 (온 디맨드 방식)
AWS Lambda@Edge에서 실시간 이미지 리사이즈 & WebP 형식으로 변환
안녕하세요, 당근마켓에서 백엔드 서버 개발 인턴으로 근무하고 있는 Marco입니다. 저는 이번에 당근마켓 서비스의 썸네일 생성 방식을 On-The-Fly 이미지 리사이징으로 새롭게 구현하였습니다. 이
medium.com
CloudFront와 Lambda@Edge를 이용한 방법으로써, S3에는 원본 이미지만 저장하고 사용자가 조회하면 1차로 캐시를 확인하고, cache miss가 발생하면 조회하면서 리사이징을 하는 방법이다.
- 장점
- 리사이징 작업이 필요할 때만 수행되므로, 저장소와 처리 리소스를 효율적으로 사용할 수 있다.
- 캐시를 아주 적절하게 사용하는 사례라고 볼 수 있다.
- 단점
- 리사이징 속도를 충분히 빠르게 개선하지 못 한다면 응답이 상당히 지연될 것이며, 사용자 경험이 떨어지게 된다.
- 설정과 관리가 제법 복잡하다...^^
5. 기타
📌 key path 설계
처음 S3의 key의 설계를 하게 되면 보통 다음과 같이 구상한다.
/users/{userId}/profile
/users/{userId}/something
...
하지만 이런 단순한 경로는 S3 보안 정책을 따로 설정하지 않으면, 누구나 쉽게 파일 위치를 유추할 수 있다.
(대충 아무 값이나 넣어서 다른 사람의 비공개 이미지도 조회할 수 있게 된다는 의미)
[AWS S3] AWS S3 Key path 설계
0. Table Of Contents 0. Table Of Contents 1. 설계 배경 2. 고려해야할 항목 3. AWS S3 Reference 분석 3.1. 문제상황 예시 3.2. 문제상황 해결 4. 실전 적용 5. 결론 및 느낀점 6. Reference 1. 설계 배경 개인 프로젝트를
hello-world.kr
그리고 정말 흥미로웠던 이야기는 S3 Bucket의 파일을 어떻게 분포시키냐에 따라 검색 성능이 떨어질 수도 있다는 점이었다.
S3 UI가 너무 디렉토리처럼 착각하도록 만들어서 그렇지, 사실은 모두 key라는 사실을 잊지 말자.
S3는 내부적으로 트래픽이 몰리는 key에 대해 파티셔닝을 하는데, 이런 오버헤드를 감소시키고 싶다면 하나의 키에 트래픽이 몰리지 않도록 분산시키는 설계를 구상해볼 필요가 있다.
📌 확정되지 않은 이미지에 대한 관리
S3, 이미지 용량 관리를 어떻게 할 수 있을까?
S3의 용량을 조금이라도 관리하고 줄여볼 수 있을까? 에서 시작된 고민의 과정
official.palms.blog
S3를 가장 잘 활용한다고 생각했던 예시.
예를 들어, 사용자가 게시물을 작성하기 위해 이미지를 올렸을 때 임시로 사진을 저장해야 하는 경우가 있다.
(github이 아주 좋은 예다. 이슈에 이미지를 올리면 임시로 사진을 저장하고, 저장된 경로를 반환한다.)
문제는 사용자가 게시물 작성을 취소해버리면 해당 이미지를 삭제할 방법이 필요하다.
단순히 timestamp를 기준으로 오래된 사진을 삭제하기엔 잘 저장되어 있는 다른 사진들에게도 영향을 줄 수 있다.
이러한 해결책으로 위 블로그에선 임시 경로(/delete)에 이미지를 저장하고, 확정이 되면 원본 경로로 옮기는 방식을 채택한다.
6. 결론
📌 내가 결정한 방법
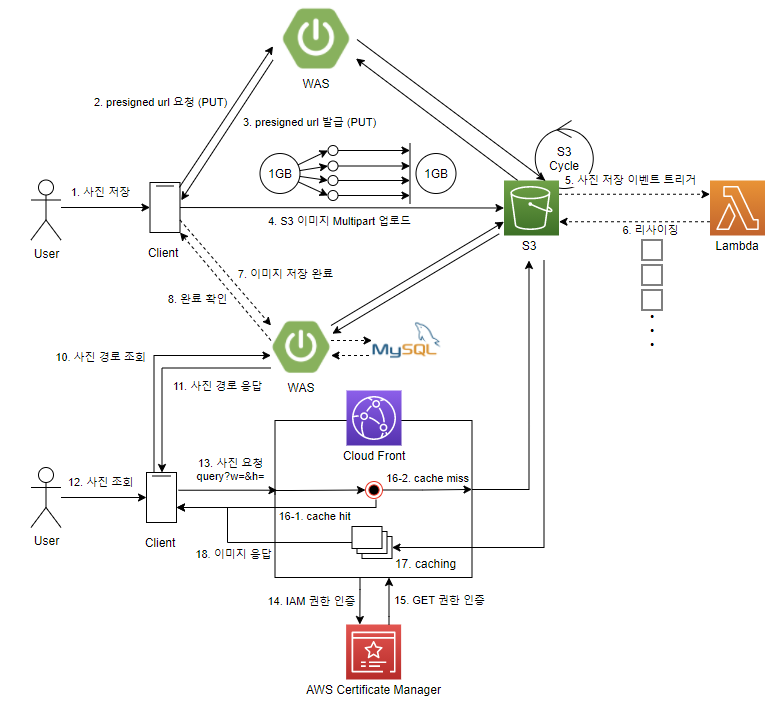
사진을 저장할 때는 presigned url을 발급하고, 이미지 용량이 크다면 multipart 업로드를 통해 S3에 저장한다.
그리고 On demand 방식이 아닌 S3 & Lambda를 사용해 리사이징을 구현했다.
이렇게 한 이유는 현재 진행중인 프로젝트에서 필요로 하는 리사이징 규격이 그렇게 많지 않기도 했으며, 이미지 리사이징 속도를 빠르게 개선하기 위해 시간을 투자할 정도로 여유롭지 않은 상황이었기 때문이었다.
조회를 할 때는 Cloud Front를 사용해 S3에 대한 직접적인 접근을 거부하도록 만들었다.
여담으로...이보다 더 자세히 적고 싶었는데, 어쩌다 보니 그냥 참조한 블로그 모아놓은 포스팅이 됐다.
아무래도 내용이 어렵기도 하고, S3 외에도 신경써야 할 부분이 한 두 가지가 아니다 보니 프로젝트에 몰입하느라 포스팅 시간이 충분하질 않았다 ㅜㅜ
온전히 이해하지 못한 내용도 많아서 조금 아쉽지만, 이런 조잡한 포스팅이라도 누군가에겐 도움이 되지 않을까....싶어서 정리해보았다.
📌 참고자료
Spring Boot에서 S3에 파일을 업로드하는 세 가지 방법 | 우아한형제들 기술블로그
Spring Boot에서 S3에 파일을 업로드하는 세 가지 방법 | 안녕하세요. 세일즈서비스팀에서 전자계약서 시스템을 개발하고 있는 박민규입니다. 최근 저는 Spring Boot + Kotlin을 활용한 프로젝트에서
techblog.woowahan.com
서버 비용을 70%나 줄인 온디맨드 리사이징 이야기
비트윈에서는 사용자들이 올린 사진들을 빠르고 비용 효율적으로 처리하기 위해서 많은 노력을 하였습니다. 이번 포스팅에서는 비트윈에서 더 나은 사진 처리를 위해서 어떠한 아키텍쳐를 구
blog-tech.tadatada.com
[AWS] S3 + CloudFront + ACM으로 이미지 배포환경 구축하기(Route 53 사용 X)
우테코에서 프로젝트를 진행 도중, 원래는 S3 사용 허락을 받지 못한 상황이라 원래는 아래와 같은 이미지...
blog.naver.com
AWS Lambda@Edge에서 실시간 이미지 리사이즈 & WebP 형식으로 변환
안녕하세요, 당근마켓에서 백엔드 서버 개발 인턴으로 근무하고 있는 Marco입니다. 저는 이번에 당근마켓 서비스의 썸네일 생성 방식을 On-The-Fly 이미지 리사이징으로 새롭게 구현하였습니다. 이
medium.com
AWS Lambda를 이용한 이미지 썸네일 생성 개발 후기
당근마켓에서는 2019년 1월부터 Lambda@Edge를 이용해 실시간으로 이미지 변환하는 방법으로 전환했습니다. 새로운 방식에 대해서는 아래 링크 참고해주세요.
medium.com
AWS Lambda@edge로 실시간 이미지 리사이징(updated)
AWS Lambda@edge(CloudFront)로 실시간 이미지 리사이징 기능을 구현합니다. Cloud 9으로 람다 함수를 작성하고 CloudWatch로 로그를 확인합니다.
heropy.blog
Lambda@Edge 예제 함수 - Amazon CloudFront
이러한 예제를 사용하려면 배포의 Lambda 함수 연결에서 본문 포함 옵션을 활성화해야 합니다. 기본적으로 활성화되어 있지 않습니다. CloudFront 콘솔에서 이 설정을 활성화하려면 Lambda 함수 연결(L
docs.aws.amazon.com
Amazon S3 이미지 온디맨드 리사이징을 통한 70% 서버 비용 줄이기 - AWS Summit Seoul 2017
Amazon S3 이미지 온디맨드 리사이징을 통한 70% 서버 비용 줄이기 - AWS Summit Seoul 2017 - Download as a PDF or view online for free
www.slideshare.net
더 나은 사용자 경험을 위한 이미지 리사이징을 해보자
안녕하세요! 크몽의 푸른피, 떠오르는 블루칩 Blue(블루)입니다.
medium.com
AWS Lambda에서 메모리 설정값과 CPU 파워의 관계 by 데이블(Dable)
안녕하세요. 데이블 백엔드 개발팀 최형주입니다.이번에 말씀드릴 내용은 서버 없는 컴퓨팅(Serverless Computing)의 널리 사용되는 AWS(Amazon Web Service)의 Lambda에 대한 내용입니다. AWS Lambda는 메모리 설
www.theteams.kr