강민철님의 "혼자 공부하는 컴퓨터 구조+운영체제"을 기반으로 학습한 게시물입니다.
📕 목차
1. Overall
2. Scheduling Algorithm
1. Overall
📌 CPU Scheduling

- Process들에게 공정하고 합리적으로 CPU 자원을 배분할 지 정책을 만드는 것 (우선순위)
- CPU 이용률을 증가시키고, overhead, 응답 시간(Response time / Turnaount time), 대기 시간을 최소화하는 것이 목적
- 선점형 스케줄링과 비선점형 스케줄링으로 나뉜다.
- Memory에 여러 Process를 올려놓고(다중 프로그래밍), CPU 가동 시간을 적절히 나누어(시분할) 각각의 Process에게 분배하여 실행한다.
| 종류 | 특징 |
| 장기 스케줄러 (Long-term Scheduler) |
• 어떤 Process가 System resource를 차지할 것인가를 결정해 READY 상태 Queue로 보내는 작업 • 수행 빈도가 적고 느림 |
| 중기 스케줄러 (Mid-term Scheduler) |
• 어떤 Process들이 CPU를 할당 받을 것인지 결정하는 작업 • CPU를 할당받으려는 Process가 많은 경우, Process를 Waiting 시킨 후 활성화해서 부하 조절 • 메모리 부족 시 swap out, 남으면 swap in 결정 |
| 단기 스케줄러 (Short-term Scheduler) |
• Process가 실행되기 위해 CPU를 할당받는 시기와 특정 Process를 지정하는 작업 • 자주 수행되고 빠름 |
📌 Process Priority
- Process마다 우선순위(priority)가 존재한다.
- 입출력 집중 프로세스(I/O bound process)
- 비디오 재생, 디스크 백업 작업 같은 입출력 작업이 많은 Process
- I/O Device에 작업을 요청하고 Waiting 상태에 더 많이 머무른다.
- CPU 집중 프로세스(CPU bound process)
- 수학 연산, 컴파일, 그래픽 처리 같은 CPU 작업이 많은 Process
- 실제 CPU를 사용하는 Running 상태에 더 많이 머무른다.
- 입출력 집중 프로세스(I/O bound process)
- 두 Process가 동시에 CPU resource를 요구한 경우, I/O 집중 Process를 가능한 빨리 실행하여 I/O Device를 작동시키고, CPU 집중 Process에 집중적으로 CPU를 할당하는 것이 합리적이다.
- 모든 Process가 차례를 기다리는 것보다 중요도에 맞게 우선순위를 부여하는 것이 효율적이다.
✒️ CPU burst 와 I/O burst• 버스트(burst) : 특정 기준에 따라 한 단위로 취급되는 연속된 신호 혹은 데이터 모임
• CPU burst : CPU를 이요하는 작업
• I/O burst : 입출력 장치를 기다리는 작업
기본적으로 Process는 CPU burst와 I/O busrt를 반복하며 실행한다.
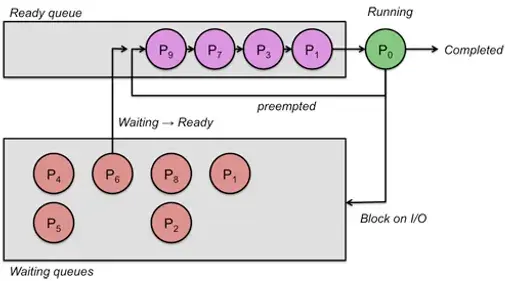
📌 Scheduling Queue
🤔 As-is
- CPU가 모든 Process의 PCB를 조회하는 것은 비효율적이다.
- CPU resource 뿐만 아니라 memory 적재, 특정 I/O Device를 사용하는 Process도 여러 개 있을 수 있다.
✨ To-be
- "줄 서서 기다려라"
- 스케줄링 큐(Scheduling Queue)
- Ready Queue : CPU를 이용하고 싶은 Process들
- Waiting Queue : I/O Device를 이용하기 위해 Ready 상태에 접어든 Process
- 우선 순위가 높은 Process는 CPU resource 요청 순서와 상관없이 먼저 처리될 수 있다.
- 같은 Device를 요구한 Process들은 같은 Ready Queue에서 기다린다.
📌 선점형(Pre-emption)과 비선점형(Nonpre-emption) Scheduling
🟡 선점형 스케줄링(pre-emption scheduling)
- Process가 CPU를 비롯한 resource를 사용하고 있어도 OS가 강제로 빼앗(interrupt)을 수 있다.
- 하나의 Process가 CPU를 점유할 수 없다.
- Timer Interrupt가 발생하면 OS가 다음 Process에게 resource를 할당한다.
- Process 간에 데이터 공유 시, 일관성 유지에 따른 비용이 발생한다.
- Context Switch 과정에서 overhead가 발생한다.
🟡 비선점형 스케줄링(nonpre-emption scheduling)
- 일단 Process가 CPU resource를 할당받으면, 해당 Process가 스스로 resource 자원을 놓을 때까지 독점한다.
- 모든 Process가 Resource를 골고루 사용할 수 없다.
📌 디스패처(Dispatcher)
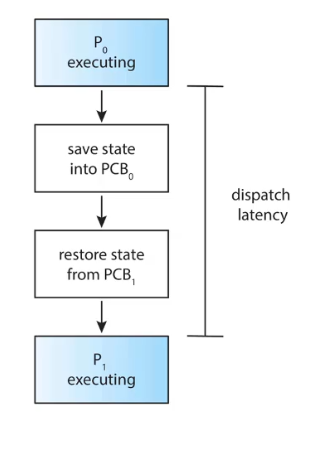
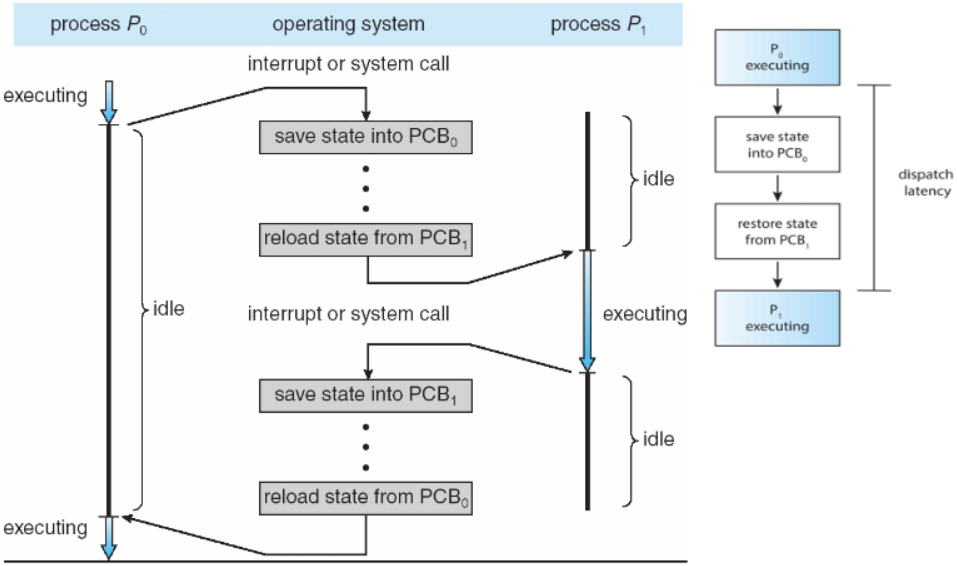
- CPU 코어의 제어를 CPU Scheduler(short-term scheduler)가 선택한 Process에 주는 모듈
- Context Swtching과 User mode로의 전환, Jump 등의 역할을 수행한다.
- 디스패치 지연(Dispatch Latency) : Dispatcher가 Running 상태의 Process를 정지하고 다른 Process의 수행을 시작하는 데 걸리는 시간 (overhead)
2. Scheduling Alogithm
📌 알고리즘 성능 평가 기준
| 항목 | 설명 | 목표 |
| CPU 사용률 (CPU Utilization) |
• 시간당 CPU를 사용한 시간의 비율 • Processor를 실행 상태로 항상 유지하여 유휴 상태 방지 (쉬지 말고 일해라!) • 가능하면 I/O 중심 작업보다 Processor 중심 작업을 택해야 한다 |
최대화 ⇧ |
| 처리량 (Throughput) |
• 시간당 처리한 작업의 비율 • 단위 시간당 완료되는 작업이 많도록 짧은 작업을 우선 처리하거나 Interrupt 없이 작업 실행 |
최대화 ⇧ |
| 반환 시간 (Turnaround Time) |
• CPU burst time (쓰고 나갈 때까지 시간, 누적되지 않는다) • 작업이 System에 맡겨져서 완료되는 순간까지의 소요시간을 최소화해야 한다 • main memory에 들어가는 시간 + ready queue에 머무는 시간 + 실행 시간 + 입출력 시간 + ⋯ |
최소화 ⇩ |
| 대기 시간 (Wating Time) |
• 대기열에 들어와 CPU를 할당 받기까지 기다린 시간 • 작업 실행 시간이나 입출력 시간에 실질적 영향을 미치진 못한다 • ready queu에서 기다리는 시간이 최소화되도록 사용자 수 제한 |
최소화 ⇩ |
| 응답 시간 (Response Tiem) |
• ready queue에서 처음으로 CPU를 얻을 때까지 걸리는 시간 • 반응 시간 : 의뢰한 시간부터 반응이 시작되는 시간까지의 간격 • 대화형 시스템에서 중요하다. • 대화식 작업을 우선 처리하고 일괄 처리 작업을 후순위로 둔다 |
최소화 ⇩ |
- System 입장에서 중요한 요소 : CPU Utilization + Throughput
- User 입장에서 중요한 요소 : Turnaround Time + Waiting Time + Response Time
- 평균 대기시간(Average waiting time)으로 주로 비교한다.
📌 Nonpre-emption Scheduling Alogithm
1️⃣ 선입 선처리 스케줄링(FCFS; First Come First Served Scheduling)

- Ready Queue에 삽입된 순서대로 Process 처리
- 가장 간단한 CPU Scheduling Algorithm
- FIFO Queue로 구현하면 된다.
- 호위 효과(Convoy Effect) 현상이 발생할 수 있다
- Short process behind long process
- 하나의 Processor 중심 process가 다른 Process가 떠나기를 기다리는 현상
- Ready Queue 상의 Process 순서에 따라 Waiting time이 크게 바뀐다. (최적화 가능성 존재)
2️⃣ 최단 작업 우선 스케줄링(SJF; Shortest Job First Scheduling)
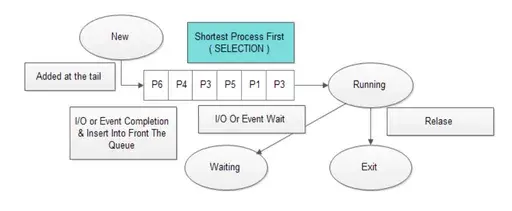
- Queue 삽입된 Process들 중 CPU 이용 시간(작업 시간)의 길이가 가장 짧은 Process부터 실행
- 두 개 이상의 Process 점유 시간이 같다면 FCFS 방식으로 처리
- 평균 Waiting time이 가장 짧다
- CPU burst 길이를 Ready 상태에서 알기 어렵다
- 과거 CPU burst 길이를 가중 평균하여 다음 CPU burst 길이를 예측하기도 한다.
- 구현 방식에 따라 선점형으로도 가능하다. (선점형 최단 작업 우선 스케줄링)
3️⃣ 우선순위 스케줄링(Priority Scheduling)
- Process들에게 Priority를 부여 → highest priority = smallest inteager
- Priority가 같은 Process들은 FCFS 방식으로 처리
- SJF, SRT는 Priority Scheduling의 일종이라 볼 수 있다.
- 기아 상태(Starvation) 또는 무한 봉쇄(Indefinite Blocking)
- Priority Scheduling의 근본적 문제
- Priority가 낮은 Process는 CPU를 무한히 대기하게 될 수도 있다.
- 에이징(Aging)
- 기아 상태를 방지하기 위한 대표적 기법
- Process가 대기하는 시간이 길어질 수록 Process의 Priority를 높인다.
📌 Pre-emption Scheduling Algorithm
1️⃣ 라운드 로빈 스케줄링(Round Robin Scheduling)
✒️ 시분할 시스템 : CPU Scheduling과 다중 프로그래밍을 이용해 각 사용자들에게 Computer resource를 시간적으로 분할하여 사용할 수 있게 해주는 대화식 System
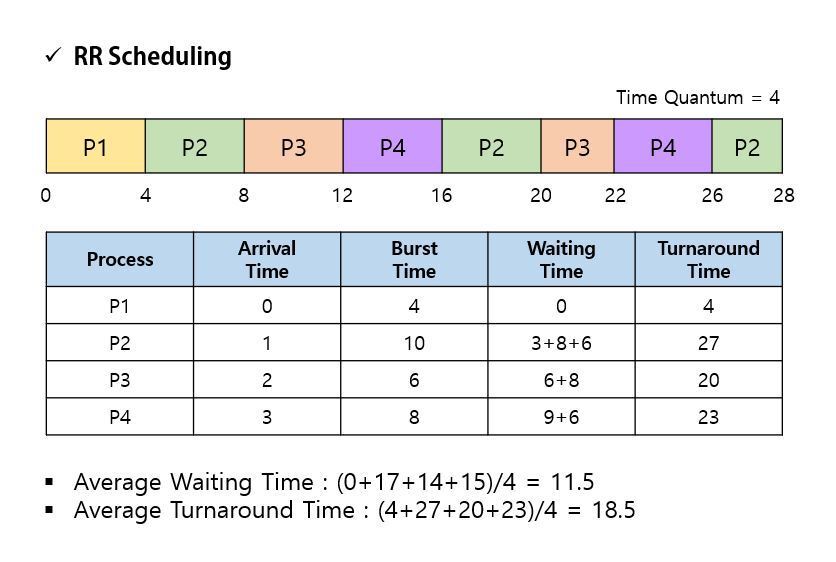
- FCFS 방식에 시간 할당량(time quantum), 또는 타임 슬라이스(time slice) 개념 적용
- time slice : 각 Process가 CPU를 사용할 수 있는 정해진 시간
- 두 가지 경우
- Process의 CPU burst가 한 번의 시간 할당량보다 작은 경우
- Process 스스로 CPU resource를 방출한다.
- Scheduler가 ready queue에 있는 다음 Process에게 resource를 할당한다.
- 실행 중인 Process의 CPU burst가 한 번의 시간 할당량보다 긴 경우
- 시간 할당량 이후 time interrupt가 발생한다.
- 실행 중이던 Process는 다시 ready queue에 삽입된다.
- Process의 CPU burst가 한 번의 시간 할당량보다 작은 경우
- RR 성능
- Time quantum 크기에 매우 많은 영향을 받는다.
- 시간 할당량이 매우 크면 FCFS랑 다를 게 없다.
- 시간 할당량이 매우 작으면 Context Switching으로 인한 overhead가 커진다.
- Time quantum은 Context Switch time보다 커야 한다.
- Context Switch time이 Time quantum의 10%라면, CPU 시간의 약 10%가 낭비되는 것이다.
- Time quantum 크기에 매우 많은 영향을 받는다.
- 어떠한 시간도 q time unit 이상 기다리지 않으므로 공정하다.
- Average Wating Time은 다소 길어질 수 있으나, Response는 짧아진다.
2️⃣ 최소 잔여 시간 우선 스케줄링(SRT; Shortest Remaining Time)
- SJF + RR 형태의 algorithm
- 남은 시간이 짧은 Process에 높은 priority를 부여한다
- SJF로 ready queue 관리하고, RR로 cpu 점유 시간 관리한다고 보면 편하다.
- 정해진 time slice만큼 CPU를 사용하되, ready queue는 남아있는 작업 시간이 가장 적은 process를 택한다.
3️⃣ 다단계 큐 스케줄링(Multilevel Queue Scheduling)
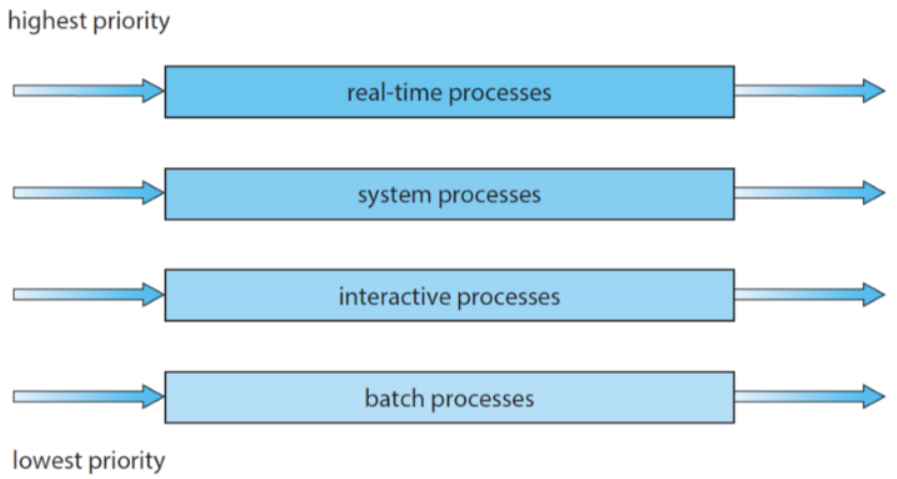
- Ready Queue를 여러 개 사용해서, Queue끼리도 Priority를 부여하는 방식
- Priority가 높은 Queue 판단 → Ready Queue 내에서 Priority 가장 높은 Process 선택
- Queue 별로 다른 Time slice를 적용할 수 있다. (각 queue별 독자적 scheduling)
- Priority Alogithm과 마찬가지로 기아 문제 발생
4️⃣ 다단계 피드백 큐 스케줄링(Multilevel Feedback Queue Scheduling)
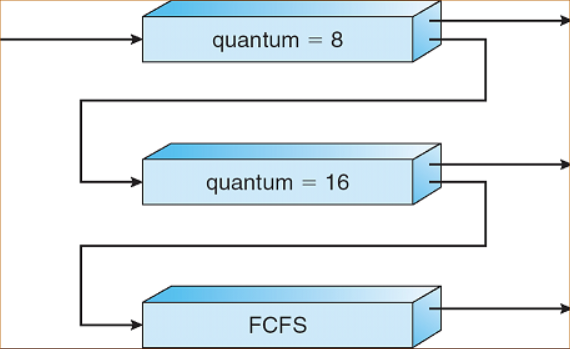
- MLQ를 보완한 형태
- Ready Queue 간 승격/강등의 개념 적용 → Process들이 Queue 사이 이동 가능
- 새로운 Ready Process를 가장 높은 Priority Queue에 삽입
- 해당 Queue에서 작업이 끝나지 않으면, 다음 Priority Queue로 강등
- 작업이 끝날 때까지 반복
- CPU를 오래 사용해야 하는 CPU 집중 Process의 Priority가 자연스레 낮아지게 된다.
- 낮은 Priority ready queue에서 너무 오래 기다리고 있는 Process에 aging을 적용하여 기아 현상을 예방할 수 있다.
📌 Thread Scheduling
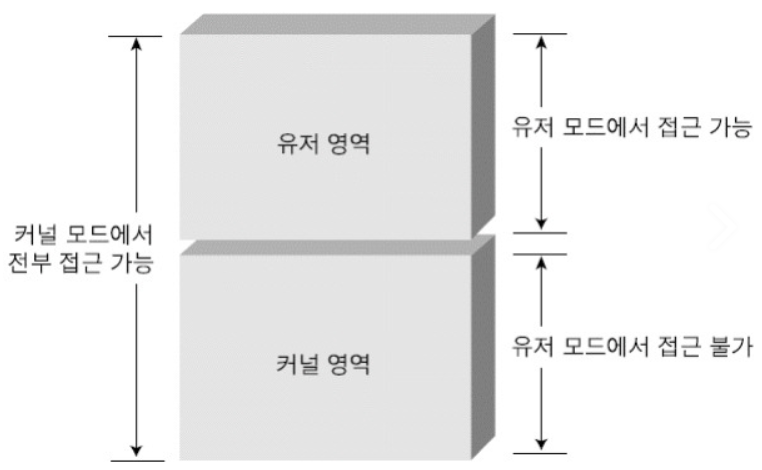
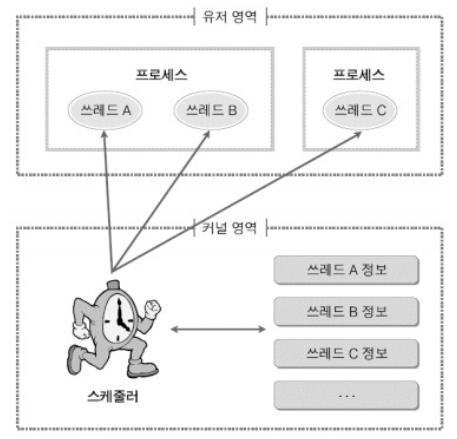
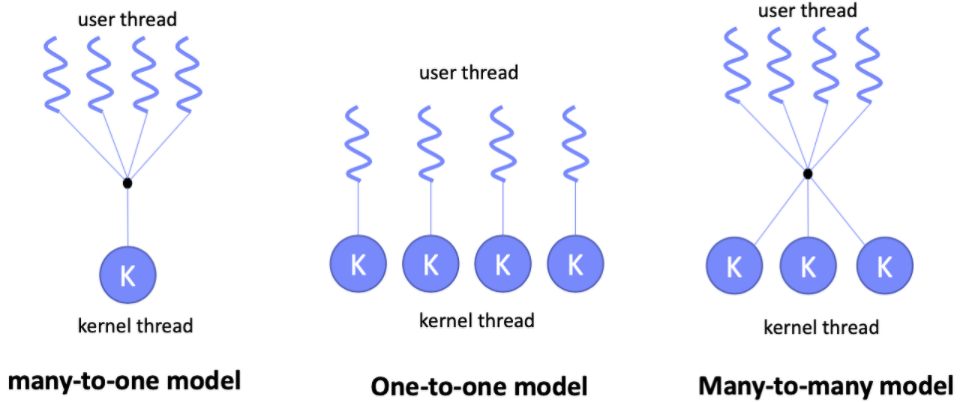
책에는 안 나오지만 궁금해서 찾아봤다.
최신 OS에서 Scheduling 되는 것은 보통 Process가 아니라 Kernel Thread라고 한다.
참고로 최근에는 one to one model이 가장 많이 쓰인다고 하더라. (독학이라 팩트 검증해줄 곳이...ㅠ)
- User Level Thread
- 일반적으로 User level의 library를 통해 구현된다.
- Process의 Thread library에 의해 독자적으로 scheduling 한다.
- TCB는 Process 내에서, PCB는 kernel에서 관리한다.
- Process 하나 당 Kernel Thread 1개가 할당된다.
- 장점
- 동일한 memory 영역에서 thread가 생성 및 관리되므로 속도가 빠르다.
- Scheduling과 synchronization을 위해 System call(kernel 호출)을 하지 않아 overhead가 적다.
- Process 내부에서 Context switching 수행
- 단점
- Kernel이 Process 내부의 thread를 인식하지 못하므로, 전체를 하나의 Thread로 본다.
- 하나의 thread가 system call 썼다가 kernel이 해당 process 전체를 Waiting 상태로 전환시켜버리면, 전체 Thread가 중단된다. (Blocking System Call)
- Scheduling Priority를 지원하지 않으므로 thread 동작 순서를 절대 예측할 수 없다.
- Kernel이 Process 내부의 thread를 인식하지 못하므로, 전체를 하나의 Thread로 본다.
- Kernel Level Thread
- OS가 지원하는 Thread 기능으로 구현된다.
- kernel이 thread 생성 및 scheduling 등을 관리한다.
- User Level Thread에 비해 느리다
- Kernel이 전체 TCB와 PCB를 관리한다.
- 장점
- Kernel이 각 thread를 개별적으로 관리 가능하다
- Thread가 system call 등으로 중단되어도, Kernel은 process 내의 다른 thread를 중단시키지 않는다.
- 단점
- Scheduling과 synchronization을 위해 system call을 하는데 오래 걸린다.
- User mode와 Kernel mode 간 전환이 빈번해 overhead가 발생한다.
이거 말고도 혼합된 Thread model도 존재한다고 한다.
근데, 뭐가 문제가 많다고 하기도 하고 지금 단계에서 너무 깊게 파는 건 별로인 거 같아서..Docker 공부하러 가야겠다!