강민철님의 "혼자 공부하는 컴퓨터 구조+운영체제"을 기반으로 학습한 게시물입니다.
📕 목차
1. 다양한 보조기억장치
2. RAID(Redundant Array of Independent Disks)
1. 다양한 보조기억장치
📌 하드 디스크(HDD; Hard Disk Driver)

- 자기적인 방식으로 데이터를 저장하는 장치 → 자기 디스크(magnetic disk)라고도 부른다.
- 플래터(Platter)
- 실질적으로 데이터가 저장되는 곳
- 자기 물질로 덮여 있어 수많은 N극과 S극(0과 1)을 저장한다.
- CD나 LP와 비슷하지만 더 많은 양의 데이터를 저장하기 위해 일반적으로 여러 겹의 플래터로 이루어져 있고, 양면을 모두 사용할 수 있다.
- 스핀들(Spindle)
- 플래터를 회전시키는 구성 요소
- RPM(Revolution Per Minute) : 스핀들이 플래터를 돌리는 분달 회전수
- 플래터가 돌아가면서 헤드가 읽는 물리적 방식이라서 전자식 보다는 느리고, 파일 연속 작업시 속도가 점점 감소한다.
- 헤드(Head)
- 플래터를 대상으로 데이터를 읽고 쓰는 구성 요소
- 플래터 위에서 미세하게 떠 있는 채로 데이터를 읽고 쓴다.
- 양면 플래터 사용 시에는 플래터당 두 개의 헤드가 사용된다.
- 액츄에이터 암(Actuator arm)
- 디스크 암이라고도 하며, 제어신호를 받아 헤드를 원하는 위치로 이동시킨다.
- 일반적으로 모든 헤드는 액츄에이터에 부착되어 다같이 이동한다.
🟡 플래터는 트랙(track)과 섹터(sector) 단위로 데이터를 저장한다.

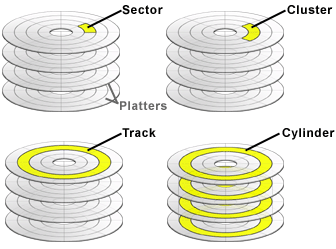

- 트랙(Track)
- 플래터를 여러 동심원으로 나누었을 때, 그중 하나의 원을 뜻한다.
- 섹터(Sector)
- 트랙을 여러 조각으로 나누었을 때, 그중 한 조각을 뜻한다.
- HDD의 최소 전송 단위 (약 512 Byte지만 4,096 Byte에 이르는 경우도 있다.)
- 실린더(Cylinder)
- 여러 겹의 플래터 상에서 같은 트랙이 위치한 곳을 모아 연결한 논리적 단위
- 연속된 정보는 보통 한 실린더에 기록된다. (액츄에이터를 움직이지 않고 바로 데이터 접근 가능)
- 클러스터(Cluster)
- 섹터의 그룹이며 도스에 의해 인식되는 최소 기억 단위
- 작게는 16개부터 많게는 128개 이상의 섹터를 하나의 Cluster로 사용한다.
- 보통은 클러스터의 2^(n)개의 섹터를 가지고 있다.
🟡 하드 디스크가 저장된 데이터에 접근하는 시간


- 탐색 시간(Seek Time)
- 접근하려는 데이터가 저장된 track까지 head를 이동시키는 시간
- 데이터 지역성이 높으면 head의 이동 거리가 짧아져 평균 탐색 시간이 크게 줄어든다.
- 디스크 부품을 더 작고 가볍게 만들 수록 개선할 수 있지만, 용량이 작어진다. (trade-off)
- 회전 지연 시간(Rotational Latency)
- head가 있는 곳으로 platter를 회전시키는 시간
- 전송 지연 시간(Transfer Time)
- HDD와 PC 간에 데이터를 전송하는 시간
🤔 프로그래머가 꼭 알아야 할 컴퓨터 시간들
| 연산명 | 시간 |
| L1 캐시 참조 | 0.5ns |
| 분기 예측 오류(branch mispredict) | 5ns |
| L2 캐시 참조 | 7ns |
| 뮤텍스(mutex) 락/언락 | 100ns |
| 주 메모리 참조 | 100ns |
| Zippy로 1 KB 압축 | 10,000ns = 10us |
| 1 Gbps 네트워크로 2 KB 전송 | 20,000ns = 10us |
| 메모리에서 1 MB 순차적으로 read | 250,000ns = 250us |
| 같은 데이터 센터 내에서 메시지 왕복 지연시간 | 500,000ns = 500us |
| 디스크 탐색(seek) | 10,000,000ns = 10ms |
| 네트워크에서 1 MB 순차적으로 read | 10,000,000ns = 10ms |
| 디스크에서 1 MB 순차적으로 read | 30,000,000ns = 30ms |
| 한 패킷의 CA(캘리포니아)로부터 네덜란드까지의 왕복 지연 시간 | 150,000,000ns = 150ms |

구글의 전설적인 프로그래머 제프 딘(Jeff Dean)은 2011년에 일반적인 컴퓨터 구조에서 응답지연 값을 공개했었다.
물론 최근에는 기술이 많이 발전되어 몇 가지는 유효하지 않지만, 여전히 이 수치들은 컴퓨터 연산 처리 속도를 짐작할 수 있도록 도와준다.
🟡 고정 헤드 디스크와 이동 헤드 디스크

- 고정 헤드 디스크(fixed-head disk) = 다중 헤드 디스크(multiple-head disk)
- head가 track별로 여러 개 달려 있다.
- 탐색 시간이 들지 않는다. (탐색 시간 = 0)
- 이동 헤드 디스크(movable-head disk) = 단일 헤드 디스크(single-head disk)
- Platter의 한 면당 head가 하나씩 달려있다.
📌 플래시 메모리(Flash Memory)
- USB, SD 카드, SSD가 모두 플래시 메모리 기반 보조 기억 장치에 해당한다.
- ROM이나 일상적으로 접하는 거의 모든 전자 제품 안에 내장되어 있다고 봐도 무방하다.
- 작고 가볍고, 전력을 적게 쓰고, 충격에 강하다.
- 많은 용량을 담을 수는 없으며, 데이터를 영구 보존할 수 없다.
- 크게 NAND 플래스 메모리와 NOR 플래시 메모리가 있다.
- 연산을 수행하는 기반 회로에 따라 결정된다.
- 대용량 저장 장치로 많이 사용되는 플래시 메모리는 보통 NAND 플래시 메모리다.
🟡 셀(Cell)

- 플래시 메모리에서 데이터를 저장하는 가장 작은 단위
- 하나의 셀에 몇 bit 저장 가능한지에 따라 플래시 메모리 종류(SLC, MLC, TLC, QLC)가 나뉜다.
- 셀은 플래시 메모리 수명, 속도, 가격에 큰 영향을 미친다.
1️⃣ SLC(Single Level Cell) 타입
- Physical bit density : 12GB
- Write 동작 비율(SLC 대비) : 1
- Read 횟수 (per 1bit) : 1회
- 가장 빠르고, 읽고 쓰는 횟수가 비교적 적어 수명도 가장 적지만 용량이 적고 가격이 비싸다.
✒️ 집적도(density) : 동일한 면적에 반도체 칩이 얼마나 많은 논리 소자로 구성되어 있는지를 나타내는 척도
2️⃣ MLC(Multiple Level Cell) 타입
- Physical bit density : 6GB
- Write 동작 비율(SLC 대비) : > 1.5
- Read 횟수 (per 1bit) : 1.5회
- SLC보다 대용화하기 유리하고 저렴하지만, Write time, Read time, 신뢰성 같은 성능 품질이 하락한다.
3️⃣ TLC(Triple Level Cell) 타입
- Physical bit density : 4GB
- Write 동작 비율(SLC 대비) : >> 2.33
- Read 횟수 (per 1bit) : 2.33회
🟡 셀보다 더 큰 단위들

- Cell → Page → Block → Plane → Die
- 페이지(Page) : Cell이 모여서 만들어진 단위 (읽기/쓰기 단위)
- Free : 어떠한 데이터도 저장하고 있지 않아서 새로운 데이터를 저장할 수 있는 상태
- Valid : 이미 유효한 데이터를 저장하고 있는 상태 (새 데이터 저장 불가)
- Invalid : 쓰레기 값처럼 유효하지 않은 데이터를 저장하는 상태
- 블록(Block) : Page가 모여 만들어진 단위 (삭제 단위)
- 플레인(Plane) : Block이 모여 만들어진 단위
- 다이(Die) : Plane이 모여 만들어진 단위
- 페이지(Page) : Cell이 모여서 만들어진 단위 (읽기/쓰기 단위)
✒️ 플래시 메모리는 HDD와 달리 덮어쓰기가 불가능하다
🟡 플래시 메모리 동작 원리
FTL Design based on Log Blocks
FTL(Flash Translation Layer)은 RAM공간에 저장되는 Mapping Table Size를 줄이기 위해 Log Block을 사용하는 Hybrid Mapping방법이 고안되었고, 이 Log Block의 활용방법에 따라 여러 Scheme들이 제안되었다. Log Blocks Hybr
ji007.tistory.com


- X블록에 읽기/쓰기 단위인 Page에 C라는 값을 저장한다.
- A를 A' 수정하고 싶으면 A를 Invalid 처리하고 A'을 Free 상태의 Page에 저장한다.
- 가비지 컬렉션(garbage collection) 기능으로 유효한 Page만을 새로운 블록으로 옮긴다.
- 삭제 단위인 X블록의 데이터를 지워버린다.
2. RAID(Redundant Array of Independent Disks)
📌 RAID의 정의
Raid 데이터 복구 튜토리얼 : Raid 5/0/1/6/1로부터 데이터를 복구하는 법
Raid 데이터 복구는 누군가에겐 쉽겠지만 일반인들에게는 매우 어렵습니다. 여기서는 Raid 5/0/1/6/1로부터 파일을 복구하는 법에 관한 완전한 길라잡이를 설명드리겠습니다. 꼼꼼히 읽어보세요.
4ddig.tenorshare.com

- 저렴한 Disk를 하나로 모아 고성능 Disk처럼 사용하려는 취지에서 시작됐다.
- 이론 상 4TB HDD 하나에 저장하는 것보다 1TB HDD 4개에 저장하는 것이 4배가량 빠르다.
- 데이터를 동시에 읽고 쓸 수 있기 때문이다.
- IT 기업에서 매일같이 쏟아지는 수십, 수백 TB 데이터를 관리하고, 절대 잃어버려서 안 될 민감한 정보들을 복구하기도 용이하다.
- 데이터 안정성 혹은 높은 성능을 위해 여러 개의 물리적 보조 기억 장치를 하나의 논리적 보조 기억 장치처럼 사용하는 기술이다.
- 여러 개의 HDD와 SSD를 사용하여 고성능 혹은 고가용성을 위한 개념이다.
📌 RAID의 종류
- RAID 레벨 : RAID 구성 방법
RAID 종류 및 특징
RAID Redundant Array Inexpensive Disk 혹은 Redundant Array Independent Disk 의 약자 처음 개념이 등장할 때는 여러개의 저렴한 디스크를 하나로 모아 고성능의 디스크처럼 사용하자는 생각에서 출발. 현재는 꼭
dev-mystory.tistory.com
아래 사진은 모두 해당 블로그에서 가져왔습니다! 근데 정리 잘 되어 있어서 참고용으로 게시.
1️⃣ RAID0

- 여러 개의 보조 기억 장치에 데이터를 단순히 나누어 저장하는 구성 방식
- 스트라입(Stripe) : 분산되어 저장된 데이터, 분산하여 저장하는 것은 Striping이라 한다.
- 오류 검출 기능이 없기 때문에 하나의 Disk에 문제가 생기면 전체에 문제가 생긴다.
- 안정성보다는 고성능을 위해 사용된다.
2️⃣ RAID1

- 복사본을 만드는 방식이며, 미러링(mirroring)이라고도 부른다.
- RAID0에서 속도를 절반 가량 희생하여 안정성을 높인 방법이다.
- 복구가 간단하지만, 사용 가능한 용량이 적어진다.
3️⃣ RAID4

- 완전한 복사본을 만드는 대신 오류를 검출하고 복구하기 위한 정보인 패리티 비트(parity bit) 저장한다.
- RAID0 보다 안정성을 높이고, RAID1 보다 성능을 높였다.
- Parity 전용 disk에 부하가 걸릴 경우 전체 성능이 저하되며, 읽기 보다는 쓰기에서 성능 저하가 크다.
- disk에 쓸 때는 parity bit를 연산하여 기록해야 하지만, 읽을 때는 데이터만 있으면 되기 때문이다.
- 새로운 데이터가 저장될 때마다 parity를 저장하는 disk에도 접근하게 되어 병목 현상이 발생한다.
✒️ Parity
원래 parity bit는 오류 검출만 가능하고 복구는 불가능하지만 RAID에서는 가능하다.
예를 들어, BLOCK A-PARITY에는 BLOCK A1~3번 데이터 실제값을 확인하여 1이 홀수갠지 짝수갠지를 기억한다.
만약 Disk 1이 손상되어 BLOCK A2가 사라져도 parity bit를 역산하여 기존 데이터를 복구할 수 있다(고 한다..)
하여튼 RAID4에서는 Parity 정보를 저장한 장치로써 나머지 장치들의 오류를 검출 및 복구한다.
4️⃣ RAID5

- parity를 저장하는 별도의 Disk를 두지 않고 parity bit를 분산하여 저장한다. (병목 현상 해소)
- 구현을 위해 3개 이상의 Disk가 필요하지만, 성능상 이유로 적어도 5개의 Disk를 사용하는 걸 권장한다.
- Disk에 장애가 발생 시 RAID5 Array를 재구성하는데 오랜 시간이 걸릴 수 있다.
- 동시에 2개의 Disk가 손상되면 전체 Disk 데이터를 복구할 수 없게 된다.
5️⃣ RAID6

- RAID5보다 보수적으로 parity bit를 분산하여 disk 당 2개씩 저장한다.
- RAID5에서 속도를 다소 희생하고 안전성을 높인 방식이다.
이외에도 여러 RAID가 있고, RAID를 혼합한 Nested RAID도 존재한다.