목차
1. Flow Control
2. Congestion Control (1)
3. Congestion Control (2)
4. TCP Fairness
1. Flow Control
💡 Overflow를 방지하기 위해 receiver's buffer를 sender에게 알림으로써 전송량을 통제한다.
💡 Sender-side window = min(cwnd, rwnd)
📌 Connection Management
TCP는 통신이 시작하기 전에 접속을 초기화하는 과정이 있다. 왜 이런 과정이 필요할까?
- seq # 초기값은 보안적인 이유로 난수로 지정한다.
- receiver의 window size를 sender에게 통지하여 OverFlow를 방지한다. (불필요한 재전송 방지)
이 두 가지 정보를 교환해야 하는데, 굳이 따로 보내지 않고 묶어서 보내다보니 3번의 교환이 일어난다.
이것을 바로 3-way handshake라고 부른다.
📌 3-way Handshake
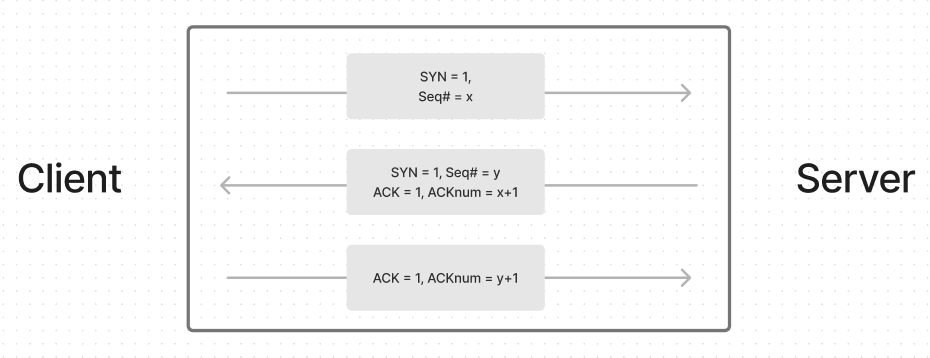
- Client가 Server에게 TCP SYN Segment를 전송한다.
- SYN=1이므로 Server는 접속 과정임을 인식하고 승인한다.
- 이 때, Client 측의 Seq# 초기값과 window size을 갱신한다.
- Server는 SYC ACK을 Client 측에 전송한다.
- Client는 Server 측의 Seq#와 window size를 갱신한다.
- Client는 ACK을 전송하여 접속 단계를 마친다.
- ACK에 데이터를 담을 수도 있다.
📌 Closing a connection
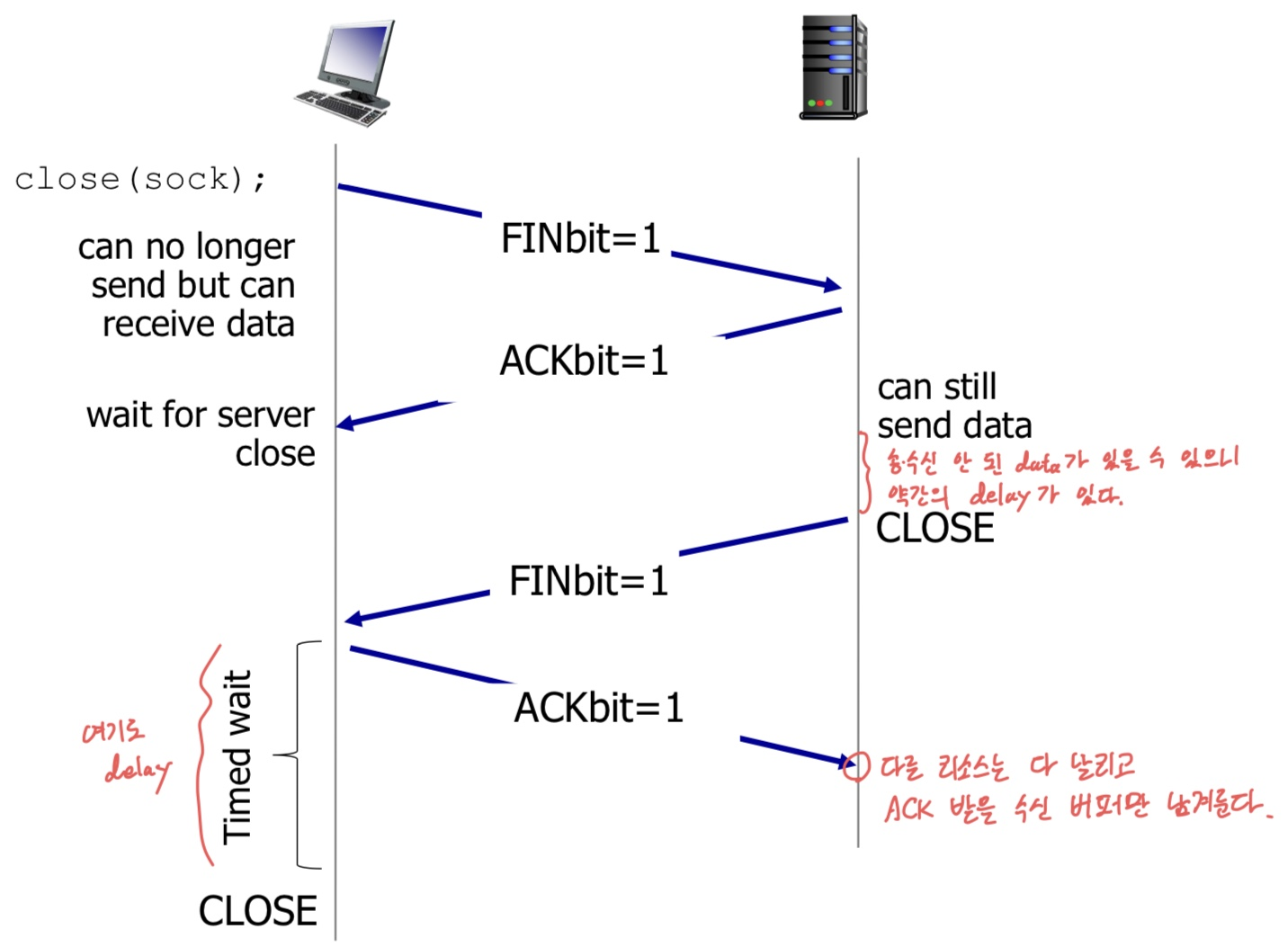
- Client 혹은 Server 중에 접속을 종료하고자 하는 측에서 FIN bit가 1인 Segment를 보낸다.
- FIN을 수신한 측은 ACK을 보내고, (서로 잠시 대기) connection 종료했음을 알리는 FIN=1 Segment를 보낸다.
- 처음 송신한 측은 FIN을 받고, 다시 ACK을 응답한 후 (또 일정 시간 대기) 완전히 종료한다.
- 처음 수신한 측은 ACK을 수신하면 완전히 종료한다. (ACK 받을 만큼의 약간의 리소스 남겨둬서 가능)
엄청 조심히 끊고 있음을 알고 있으면 된다.
📌 Issue
receiver가 sender에게 수용 가능한 buffer size를 알려줌으로써 흐름을 통제할 수 있는 건 알겠는데,
아래의 상황에선 어떻게 될까?
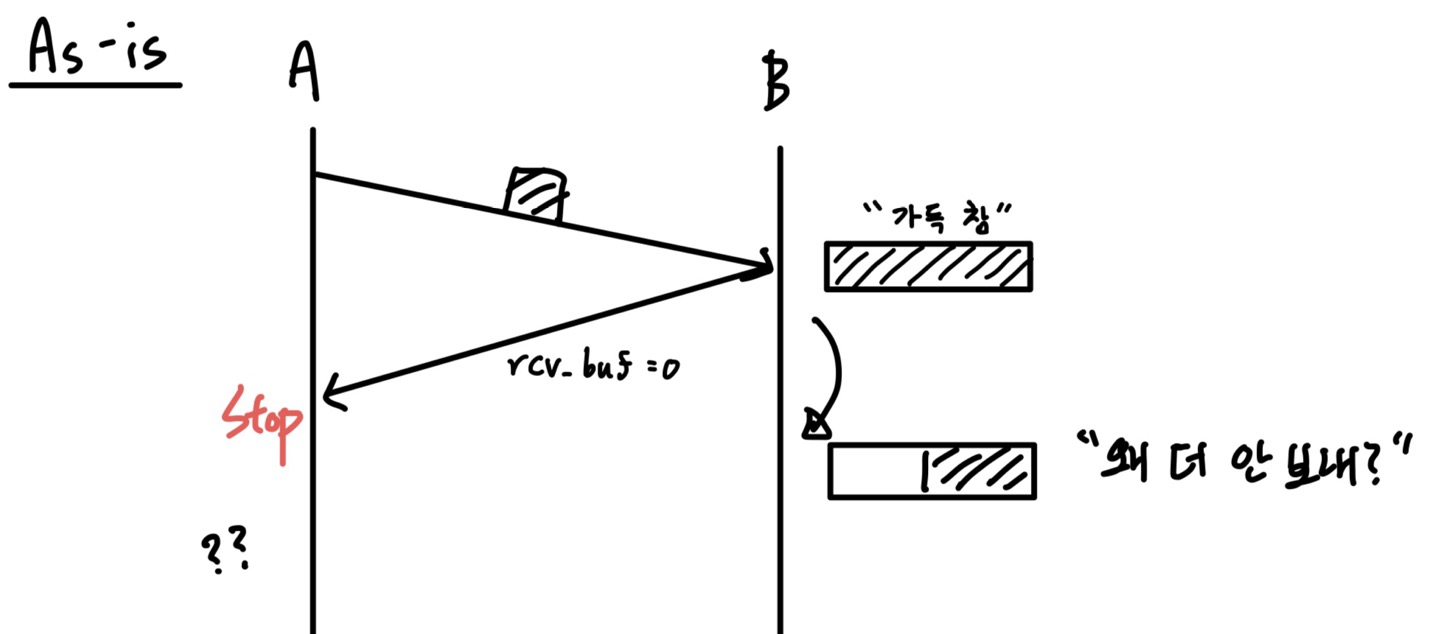
A가 보내야 할 데이터 양은 엄청나게 많은데, B의 Application Layer에서 데이터를 가져가는 속도가 느려서 Buffer가 가득 차버렸다고 가정하자.
그러면 B는 A에게 rcv_buffer=0이라는 ACK을 보낼 것이고, A는 더 보내봐야 Overflow가 발생할 테니 데이터를 보내지 않을 것이다.
하지만 시간이 지나면 B의 buffer는 점점 비어서 데이터를 받을 수 있게 될 텐데, 누가 먼저 대화를 다시 시작해야 할까?
2가지 방법이 있는데, 이건 구현 방식의 차이라서 둘 다 알아두면 좋다.
1️⃣ Receiver가 window size를 송신한다.
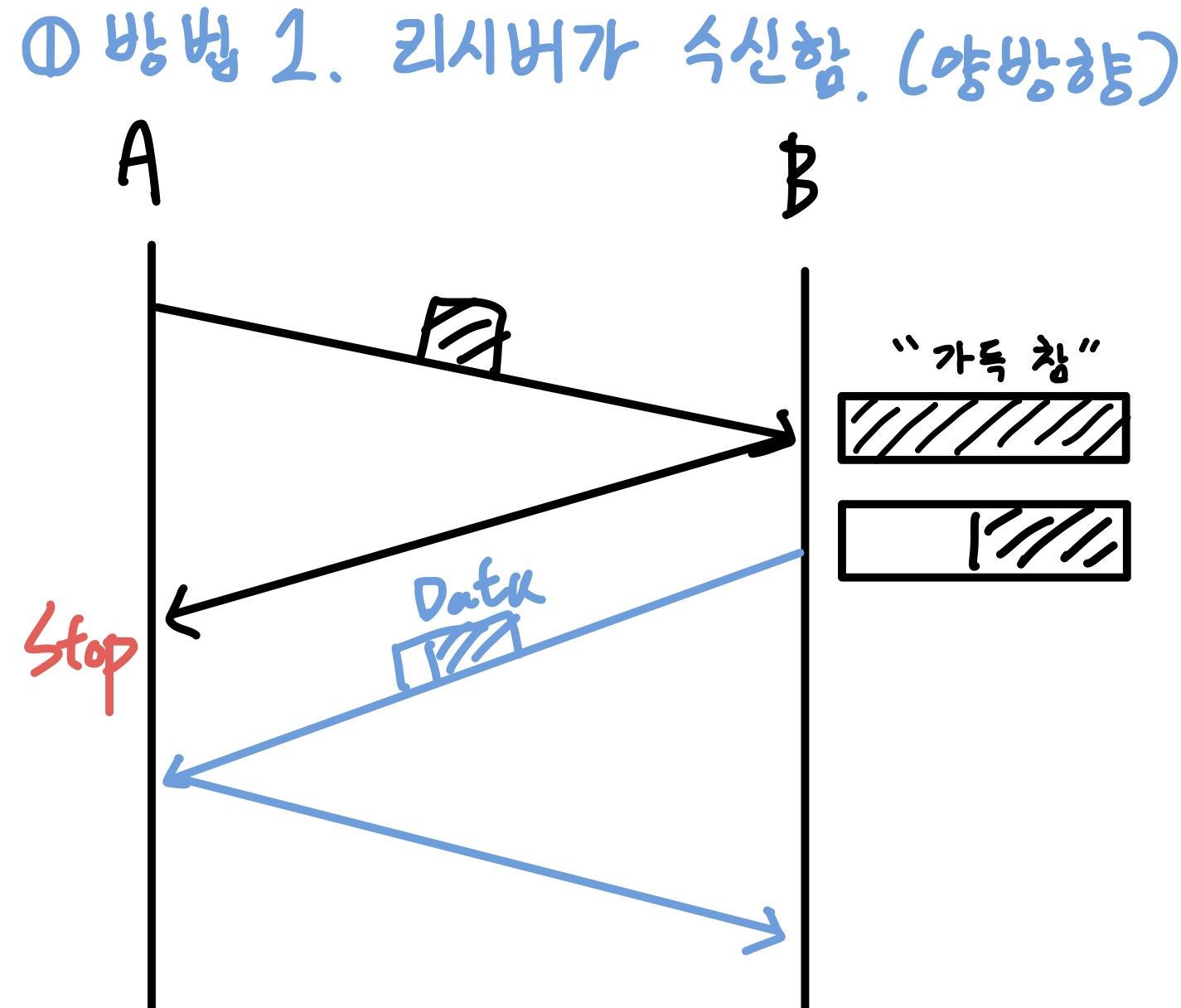
TCP는 1:1 Full duplex 통신이므로 Receiver가 Sender가 되는 게 가능하다.
rcv_buffer를 꼭 ACK이랑 보낼 이유도 없으니, buffer가 비면 A에게 송신해주면 해결할 수 있다.
2️⃣ Sender가 probe packet을 보낸다.
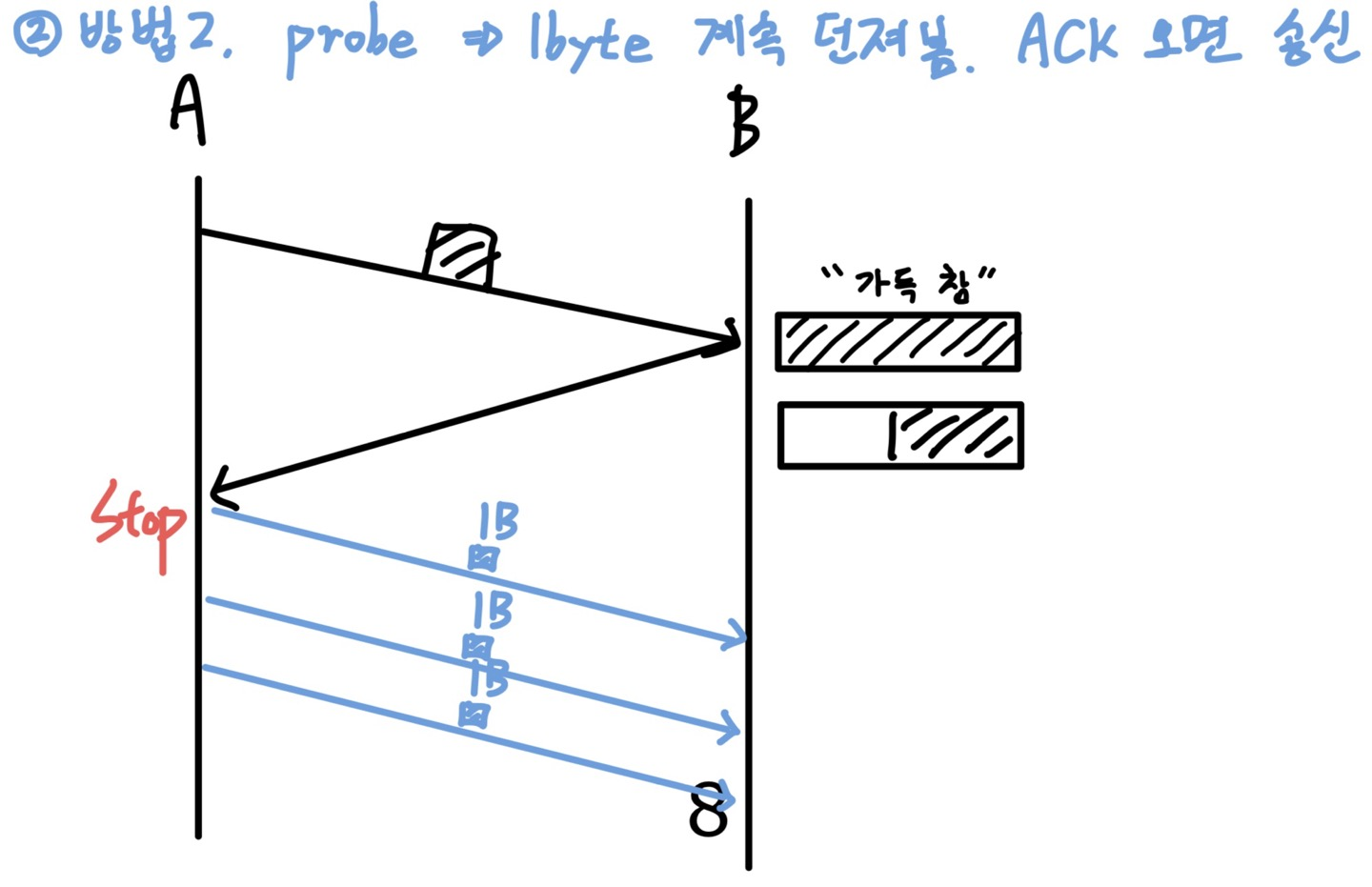
Sender가 1Byte 크기의 probe packet을 지속적으로 흘려보고, ACK이 돌아오면 다시 전송을 재개할 수도 있다.
1byte 정도면 부담이 되는 크기도 아니고, 설령 B의 buffer가 아직 가득 차서 받지 못 하더라도 그냥 discard 해버리면 그만.
probe interval 시간을 정하는 건 딱히 정해져 있지는 않다.
2. Congestion Control (1)
📌 Flow Control vs Congestion Control
둘 다 Overflow를 막기 위함이고, Network 상태에 결정적인 영향을 미친다.
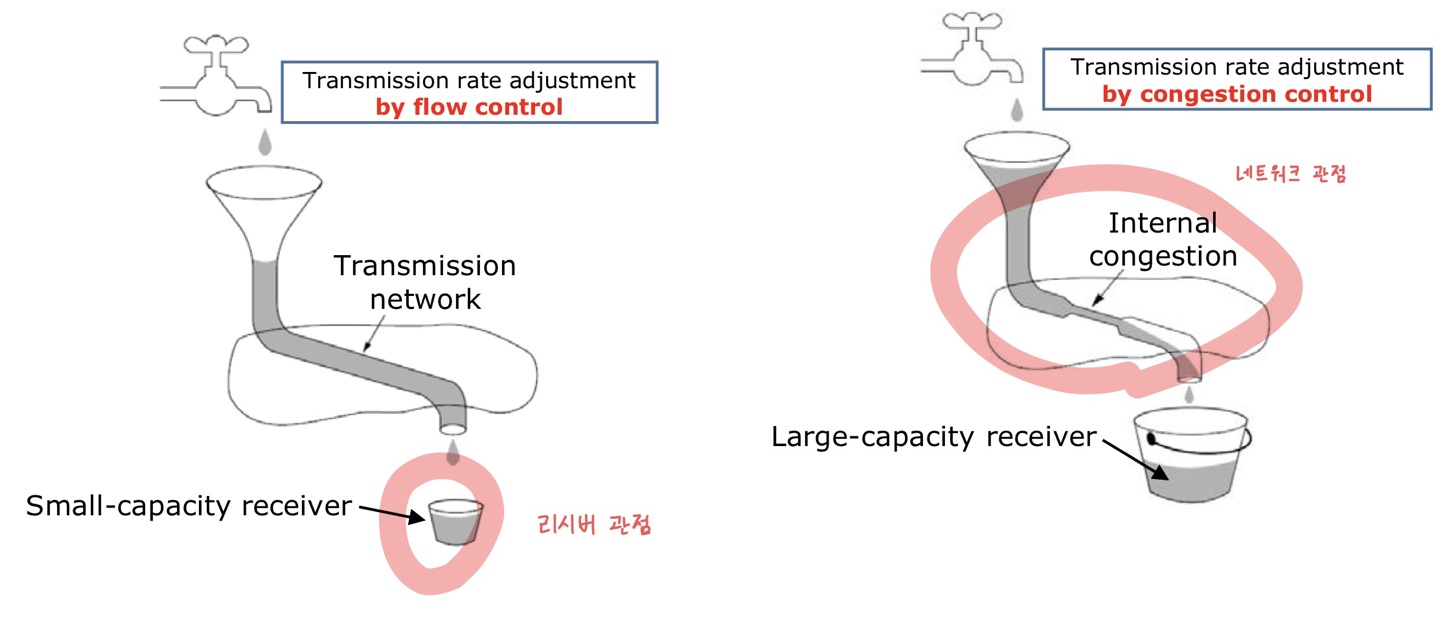
- Flow Control (흐름 제어) : Receiver 관점에서 Sender의 전송량을 통제하는 것
- Congestion Control (혼잡 제어) : Sender 관점에서 Network 상태를 보고 전송량을 조절하는 것
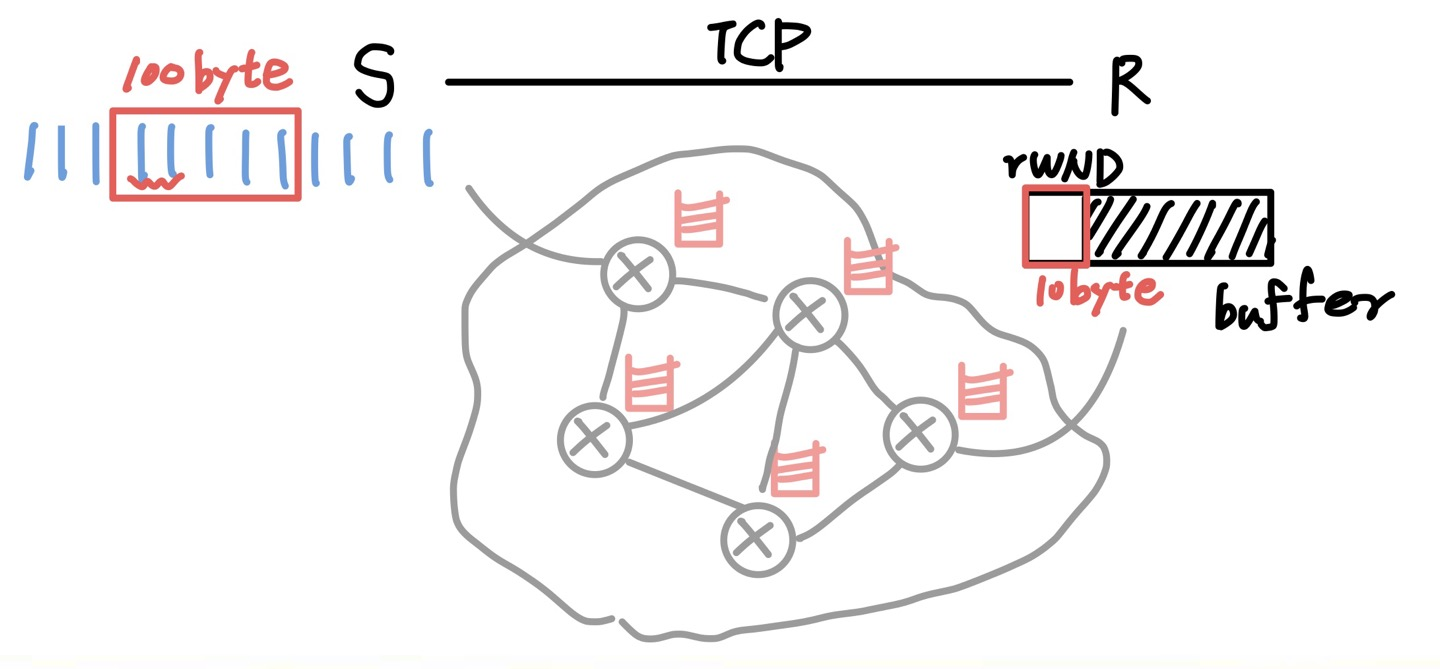
- Reciver가 10byte 받을 수 있어도 Router가 5byte밖에 못 받으면 5byte만 보내야 한다.
- 문제는 Router는 전달하는 역할만으로도 너무 바빠서 피드백을 해줄 수 없다. → Sender가 측정해야 한다.
- TCP 통신에서 ACK이 오지 않으면 "이건 무조건 Router Overflow다!"라고 판단한다.
- 요즘 시대에 packet loss의 발생 이유 90%이상이 Router QueueOverFlow라서 그렇다.
- Congestion이 발생했다고 판단하고 조치를 취한다.
- window size를 줄이고, 전송 속도도 같이 늦춘다.
- ACK이 잘 오기 시작하면 다시 전송 속도를 단계적으로 높인다.
💡 Network 환경에 따라 전송속도(Tranport Layer → Network Layer)를 동적으로 조절한다.
📌 Overview
1988년에 flow control만 사용하는 것은 효과가 없는 정도가 아니라 상황을 더욱 악화시킬 수도 있다는 연구 결과가 발표됐다.
Router에서 Queueing delay가 발생 → ACK을 못 받은 Sender가 불필요한 packet 재전송 → Congestion 악화
라는 기적의 디플레이션 효과가 발생하는데, 문제는 이게 실제로 loss packet에 대한 재전송이 발생하는 perfect한 상황인 경우에도 네트워크 성능이 상당히 떨어진다는 점이었다.
결국 Receiver가 Sender의 송신량을 결정짓는 것 외에도, Sender가 Network Congestion을 파악하고 스스로 전송량을 조절하기까지 해야한다는 결론에 다다랐다.
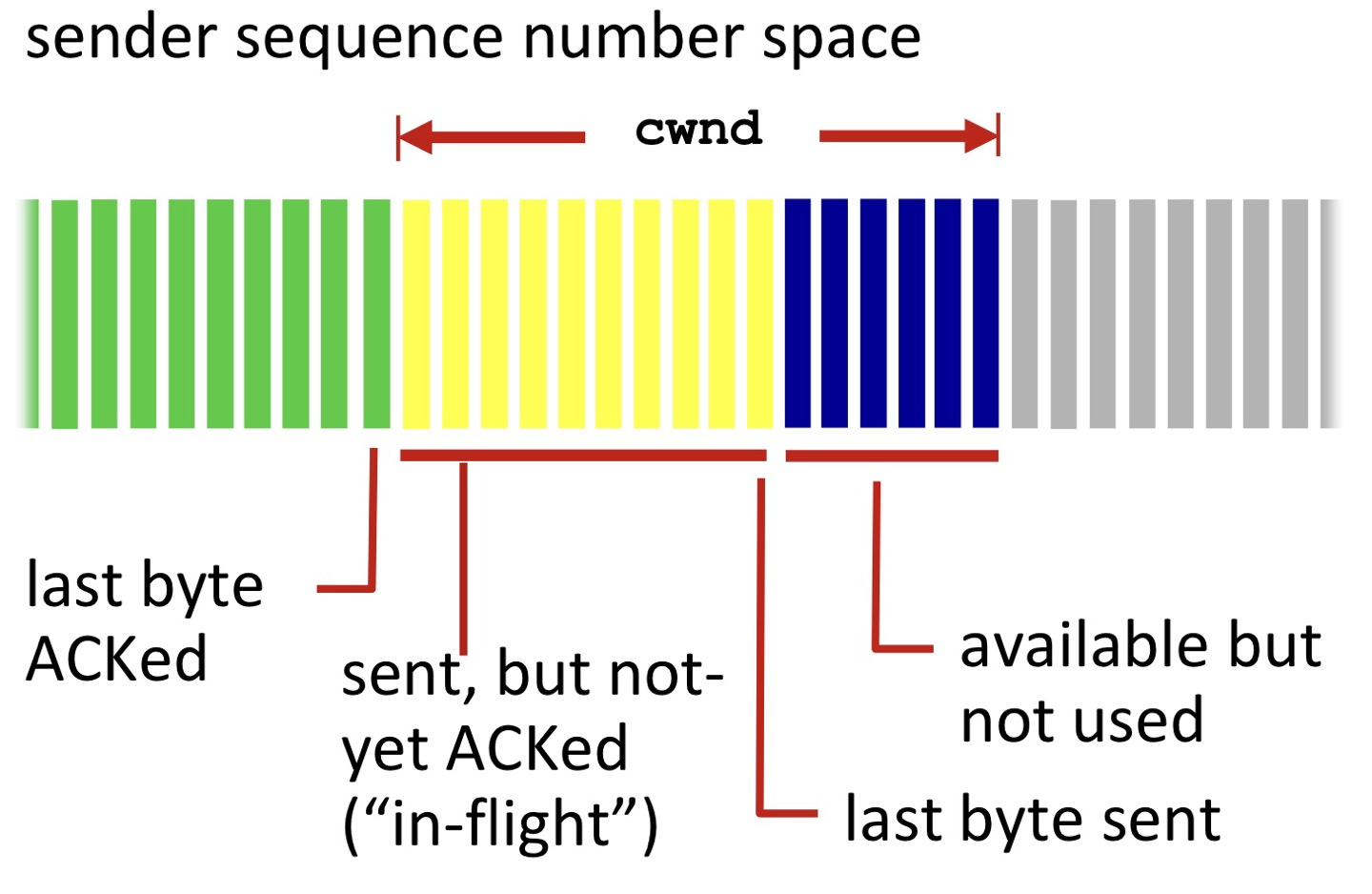
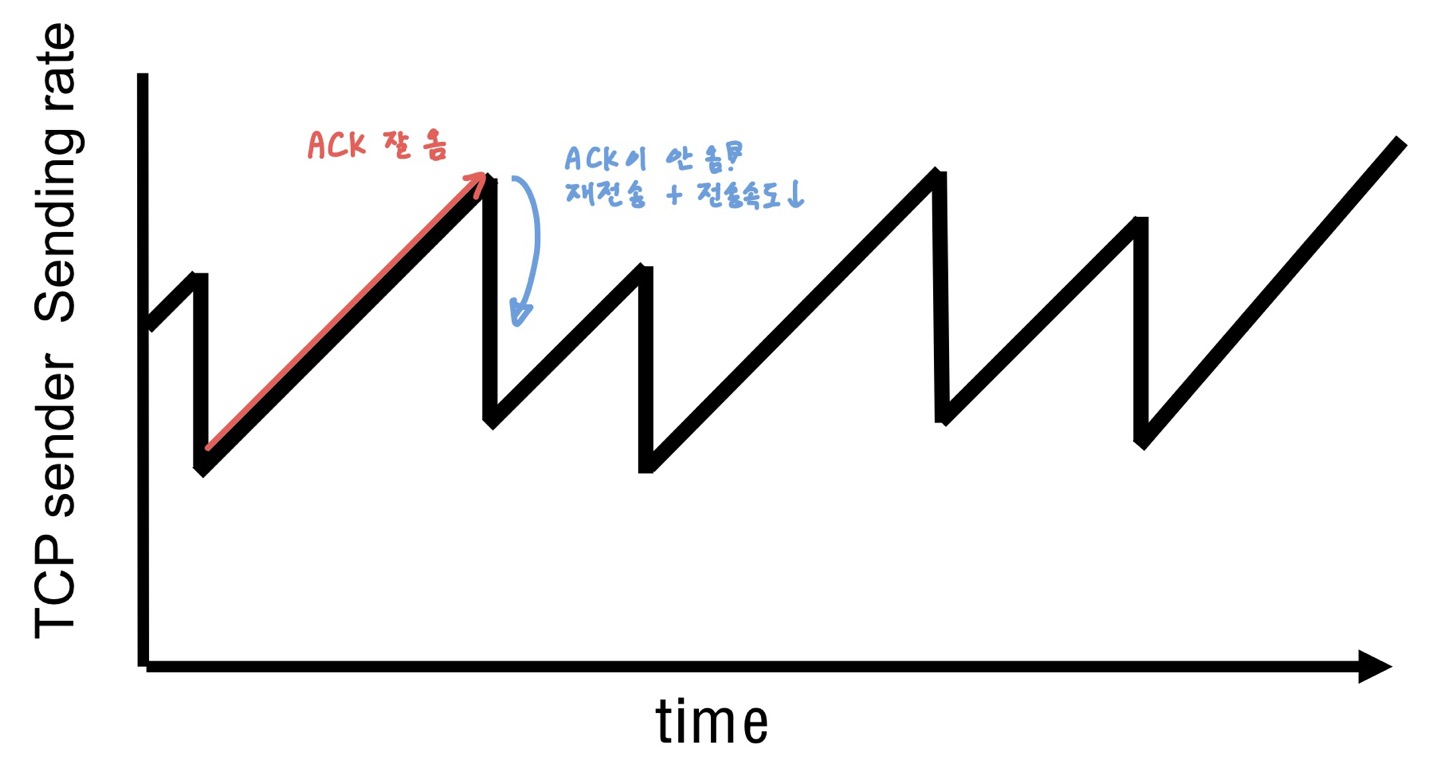
- TCP sendig behavior: \( TCP rate(전송량) ≈ \frac{cwnd}{RTT}bytes/sec \)
- Congestion에서 RTT는 거의 고정값이다. (TCP rate를 cwnd라고 무방)
- RTT도 변동 폭이 크긴한데, 그거랑 별개로 전송 속도에 미치는 크기가 너무 작아서 cwnd가 결과를 지배한다고 보면 된다.
- TCP sender limits transmission: LastByteSent - LastByteAcked ≤ cwnd
아이디어는 진짜 단순하기 그지 없다.
Sender는 packet loss가 발생할 때까지 cwnd를 늘리다가, packet loss가 발생하면 다시 cwnd를 떨어트리는 걸 반복한다.
📌 Three phases
Congestion Control 방식에서 시간에 대한 cwnd는 3가지 구간이 존재한다.
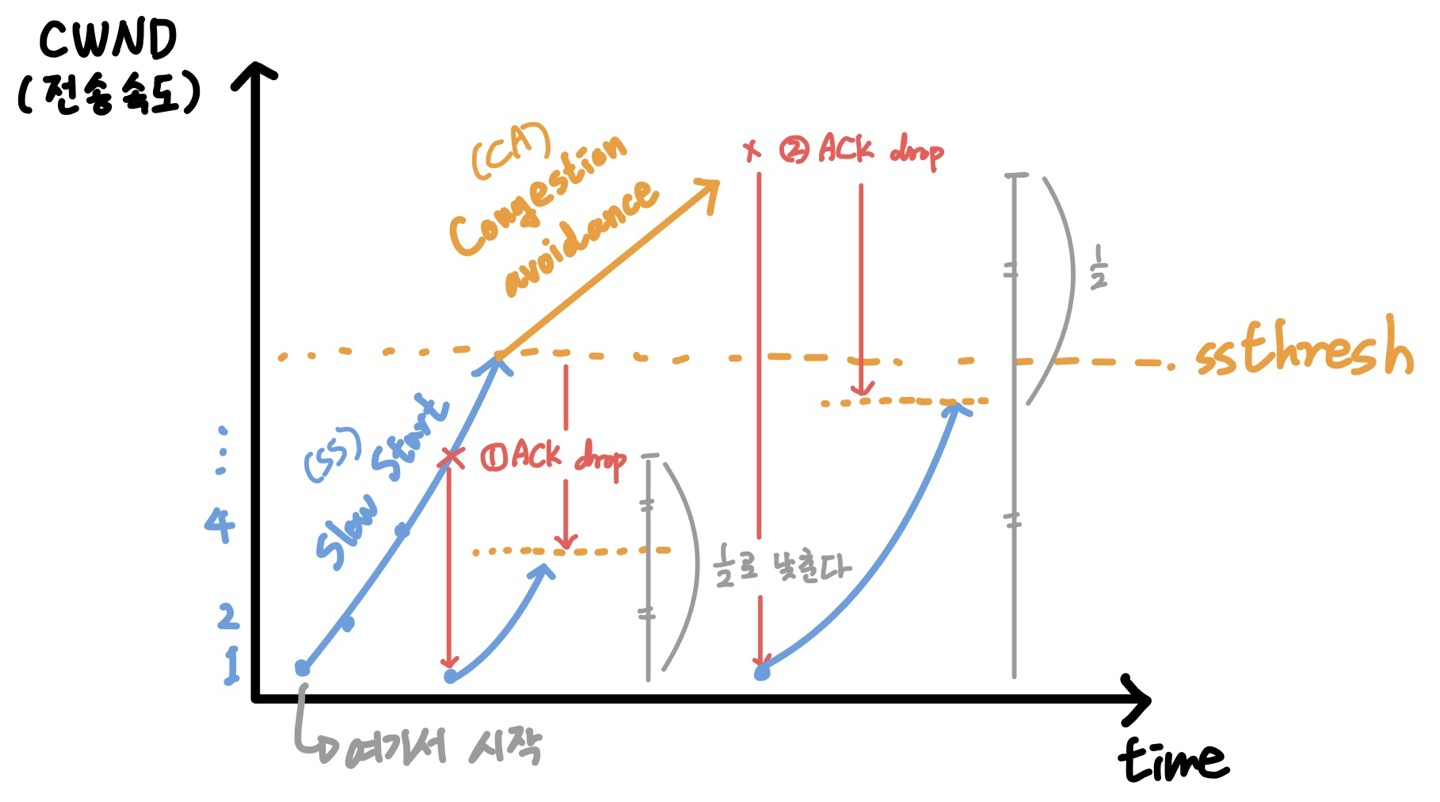
- Slow start : Congestion 발생하면 처음부터 시작하지만, 증가율이 "exponentially" 증가한다.
- Congestion avoidance : ssthresh에 도달하면 전송 속도가 "linearly" 증가한다.
- Fast recovery (optional) : 없어도 되는 부가 기능이지만, 대부분 서비스가 지원하고 있다.
- Congestion 발생 시
- 무조건 시작점부터 시작 (Fast recovery의 경우 조금 다른 경우 있음.)
- ssthresh는 발생시점에서 1/2로 줄인다.
💡 기존 ssthresh에서 1/2가 아니라, Congestion이 발생한 시점에서 1/2로 줄여야 한다.
3. Congestion Control (2)
시작하기 전에 TCP에서 packet loss를 판단하는 방법은 2가지라고 했던 것을 기억하자.
- Time out
- three duplicated ACKs
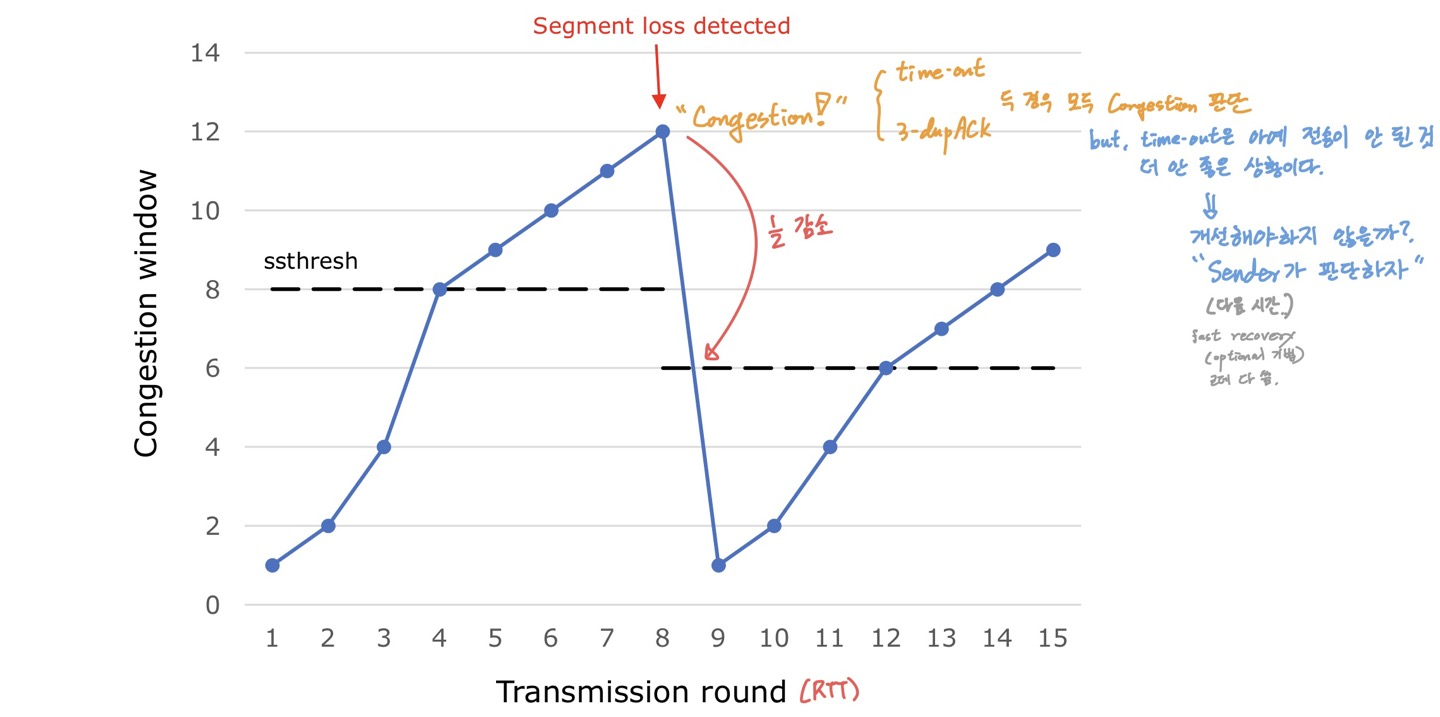
1️⃣ Slow start
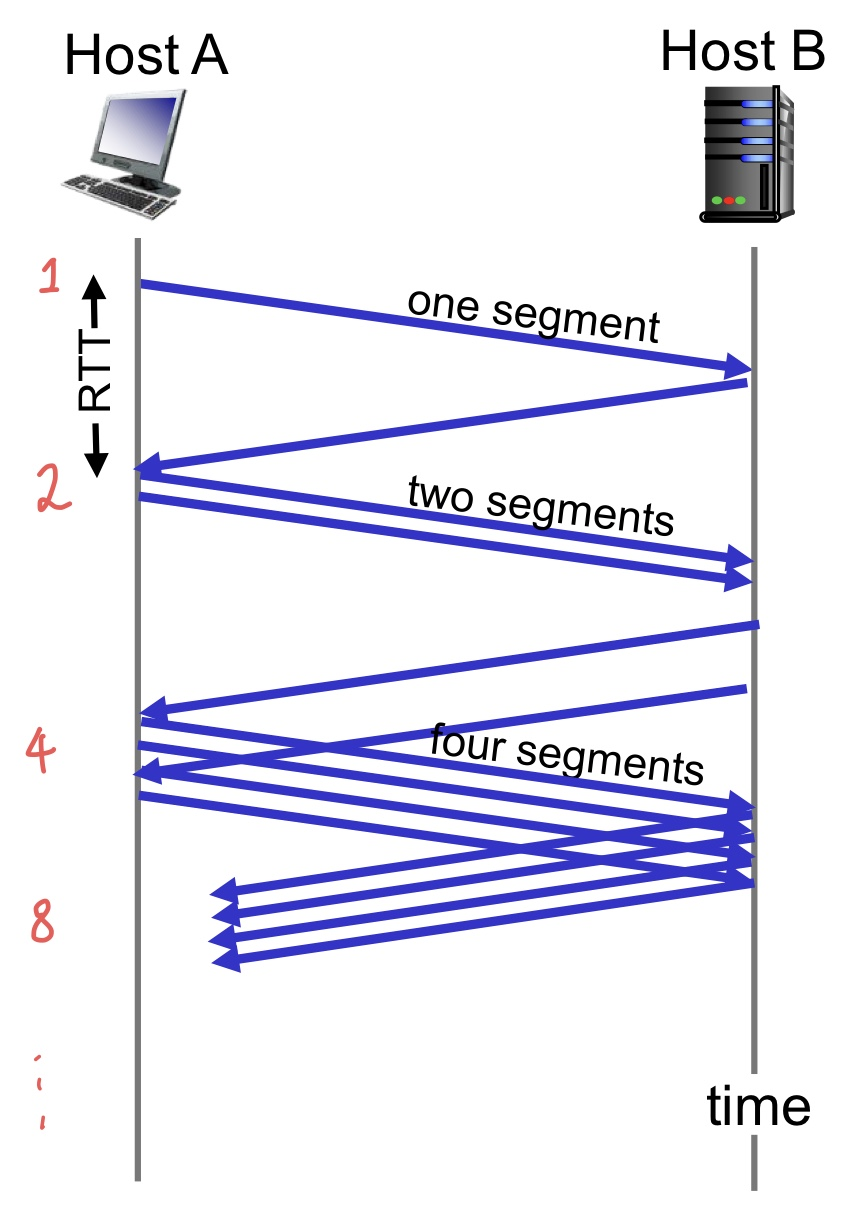
TCP의 window size는 1 MSS가 가장 작은 단위이기 때문에 여기가 시작점이 된다.
- cwnd 시작 = 1 MSS
- RTT마다 2배씩 증가 (1, 2, 4, 8, ...)
- ACK을 받을 때마다 cwnd를 1씩 증가시키면 지수 증가 효과가 있다.
- 여기에 대해 의문이 있는데, TCP는 Cumulative ACK으로 응답을 돌려주기 때문에 모든 packet에 대한 ACK이 돌아오지 않으니 이렇게 생각하면 안 되는 거 아닌가..? 아니면 Cumulative ACK의 seq#로 1개의 응답을 받더라도 대충 알아서 계산해서 window size를 늘려버리는 건가? 교수님께 여쭤봐야겠당,,
- (해결) 이 상황은 delay ACK이나 내가 가정한 경우는 모두 무시한 상황에 해당한다. 설령 그렇다 하더라도 내가 말했던 seq#로 판단하던가 해서 처리해줄 수 있다. 중요한 건 cwnd를 1씩 증가시키는 게 아니라, "2배 씩 늘려야 한다"가 중요하다.
Congestion이 감지(packet loss)되면 다음과 같이 반응한다.
- cwnd 1 MSS부터 다시 시작
- ssthresh = cwnd/2
- ssthresh/2가 아니라, packet loss가 발생한 지점에서 cwnd/2가 기준이 된다!
만약, packet loss가 발생하지 않고 ssthresh까지 도달하면 congestion avoidance 단계로 넘어간다.
2️⃣ Congestion avoidance
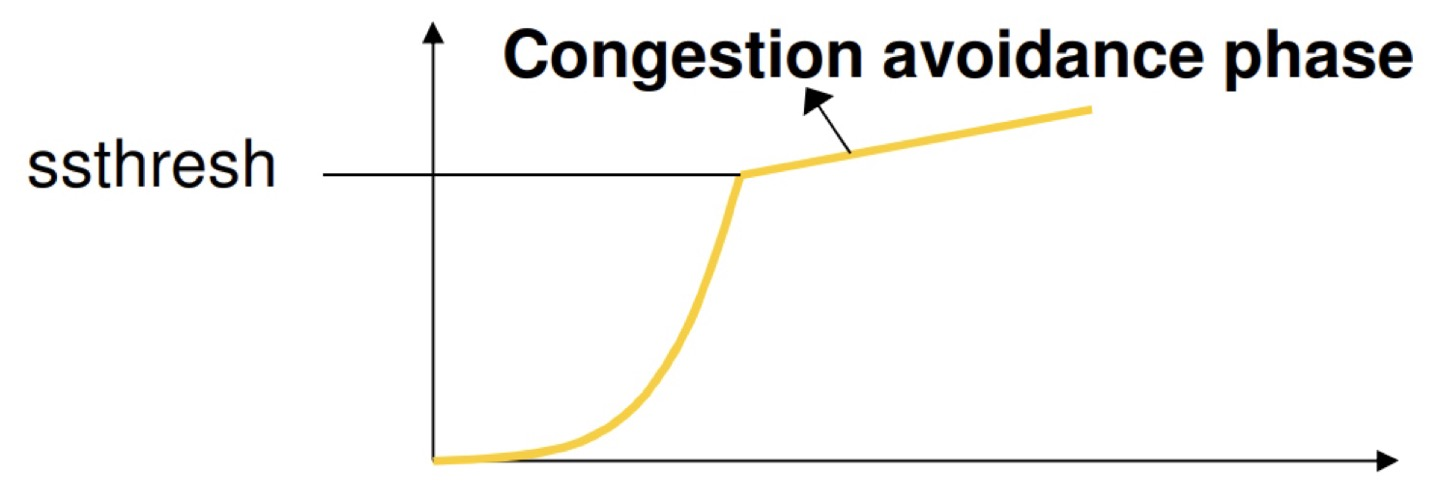
- cwnd = cwnd + 1 MSS every RTT
- ACK을 받을 때마다 1/cwnd MSS만큼 증가시키면 선형 증가 효과가 있다.
- 이게 뭔 소린가 했는데, cwnd가 현재 100 MSS라면 1 MSS짜리 Segment를 100개 날리고, ACK을 100개 받을 것이다. (아까부터 누적 ACKs를 왜 고려 안 하는지 의문) 그럼 1/100씩 100개를 받으면 결과적으로 1 MSS 만큼 증가하는 효과를 가져오고 싶은 걸 말씀하신 거 같은데...여전히 납득은 안 된다.
Congestion이 감지되면 다음과 같이 반응한다.
- cwnd 1 MSS부터 다시 시작 (Slow Start로 돌아간다.)
- ssthresh = cwnd/2
여기서 생각해볼 점은 ssthresh가 언제나 줄어들지는 않는다는 점이다.
만약, 혼잡 회피 단계에서 기존 ssthresh 2배 이상까지 cwnd가 올라간다면 slow start부터 시작하더라도 ssthresh는 기존보다 높아진다.
3️⃣ Fast recovery (optional)
Packet loss가 발생할 수 있는 경우는 처음 상기시켜 봤듯이 2가지 경우가 있다.
- Time out
- Three duplicated ACKs
그런데 이 둘의 심각도가 과연 같을까? 매번 Slow Start부터 시작하는 게 합리적인가?
Time out은 ACK이고 뭐고 아무런 상황을 파악할 수 없는 최악의 경우가 된다. 이 때는 무조건 Slow start부터 시작한다.
하지만 Three duplicated ACKs는 적어도 ACK이 오고 갈 정도는 되는 상황이다.
그래서 후자의 경우엔 좀 더 유연하게 대처하는 것이 Fast recovery 방식이다.
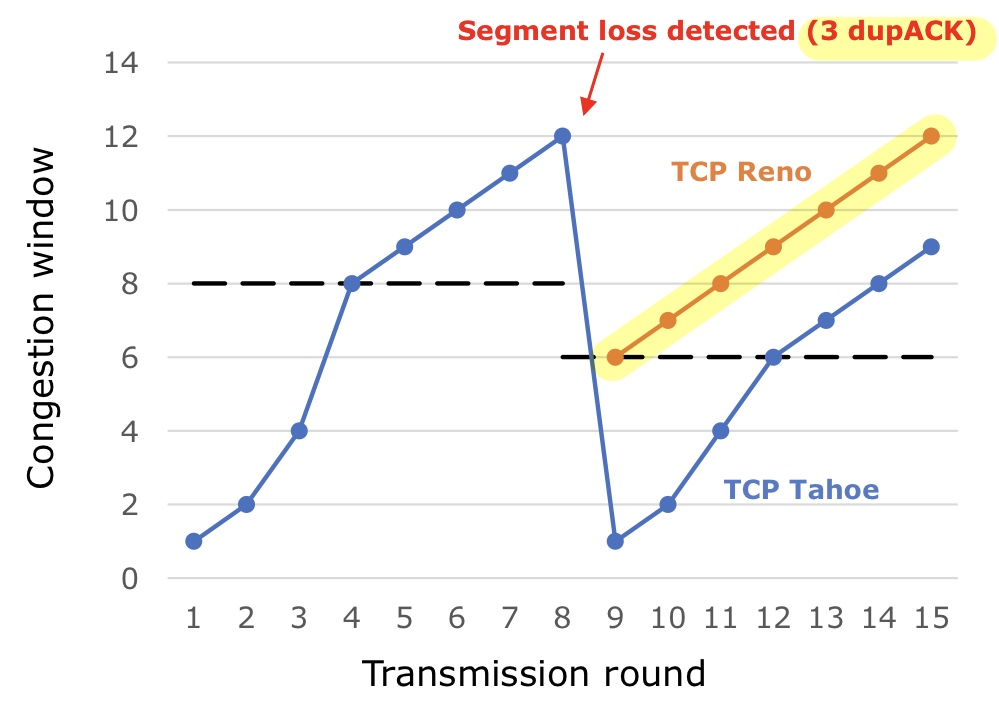
- ssthresh = cwnd/2 (동일)
- cwnd = ssthresh 부터 시작 → congestion avoidance phase부터 시작
💡 Time out은 최악의 경우이므로 무조건 Slow Start부터 다시 시작한다.
✒️ Fast Recovery in Detail
💡 Idea : 각 dupACK마다 Sender에게 일시적으로 "credit"을 부여하여 Segment를 in-flight packet으로 유지한다.
만약, dupACK이 3개라면?
- ssthresh = cwnd/2
- cwnd = ssthresh + 3
- 비록 차례는 어긋낫지만, 그 뒤의 패킷에 대해서는 성공적으로 수신했다는 의미
- 하지만 cwnd를 오른쪽으로 3칸 옮길 수는 없으니, 사이즈를 3칸 늘려서 새로운 패킷 전송 cwnd 공간 확보
- 새로운 ACK을 받으면 cwnd = ssthresh로 돌아온다.
즉, fast recovery 단계에선 dupACK 개수마다 cwnd를 1씩 증가시켜 window size를 넓힌다.
이렇게 하는 이유는 속도 증가를 위함이 아니라, 속도를 유지하는 것이 목적이다.
🧐 이해가 안 가는데?

이론적으로 복잡한 내용은 아니다.
그냥 Network 상에 있던 3개의 ACK은 확실히 받을 수 있었으니 그만큼 window를 늘려서 더 보내보는 건데, 내가 여기서 한참을 고민했었다.
왜냐하면, 이 시나리오를 하나하나 그려보면 논리적으로 맞아 떨어지질 않는다!
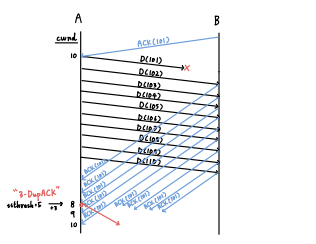

어쨌든 현재 상황에서 dupACK이 3번 발생했으니 Congestion이라 판단했을 것이다.
그런데 ACK이 날아온 것은 이전 상태(혼잡 감지가 안 됐을 때)에서 측정한 전송량의 공백이고, 그 공백만큼 데이터를 더 보낸다? 뭔가 앞뒤가 안 맞지 않나.
여튼 그래서 교수님께 여쭤봤더니, 이 방식은 heuristic한 해결책이라고 하셨다.
나처럼 너무 논리적이고 수학적으로 딱 맞게 떨어트리려고 하면 납득할 수 없고, 경험에 의한 실험값 정도로 생각하면 된다고 말씀해주셨다.
4. TCP Fairness
📌 TCP 환경에서 모든 전송률은 같은(공정한)가?
결과적으로 "이상적인 조건"일 때는 그렇다.
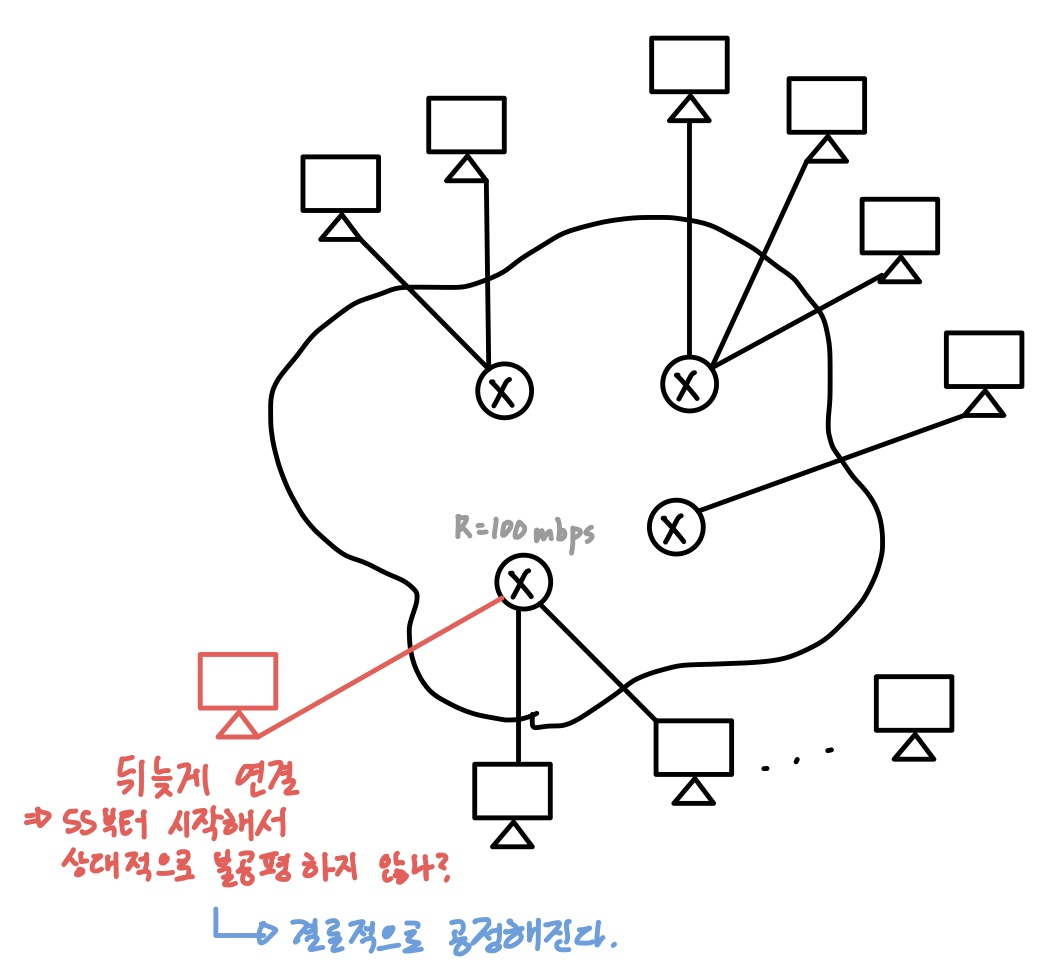
여러 대의 PC가 연결되어 있는 Network 환경에서 기존의 PC들은 모두 환경에 적응하여 비슷한 트래픽양을 쓰고 있을 것이다.
그런데 만약 새로운 PC가 나타난다면 어떻게 될까?
공정하다는 조건이 성립하기 위해서는 100 mbps의 Router에 연결된 N대의 PC가 100/N mbps 만큼의 전송률을 보장받아야 한다는 뜻이 된다.
하지만 뒤늦게 연결한 PC는 Slow Start부터 시작하기 때문에 상대적으로 불공평하지 않은가?
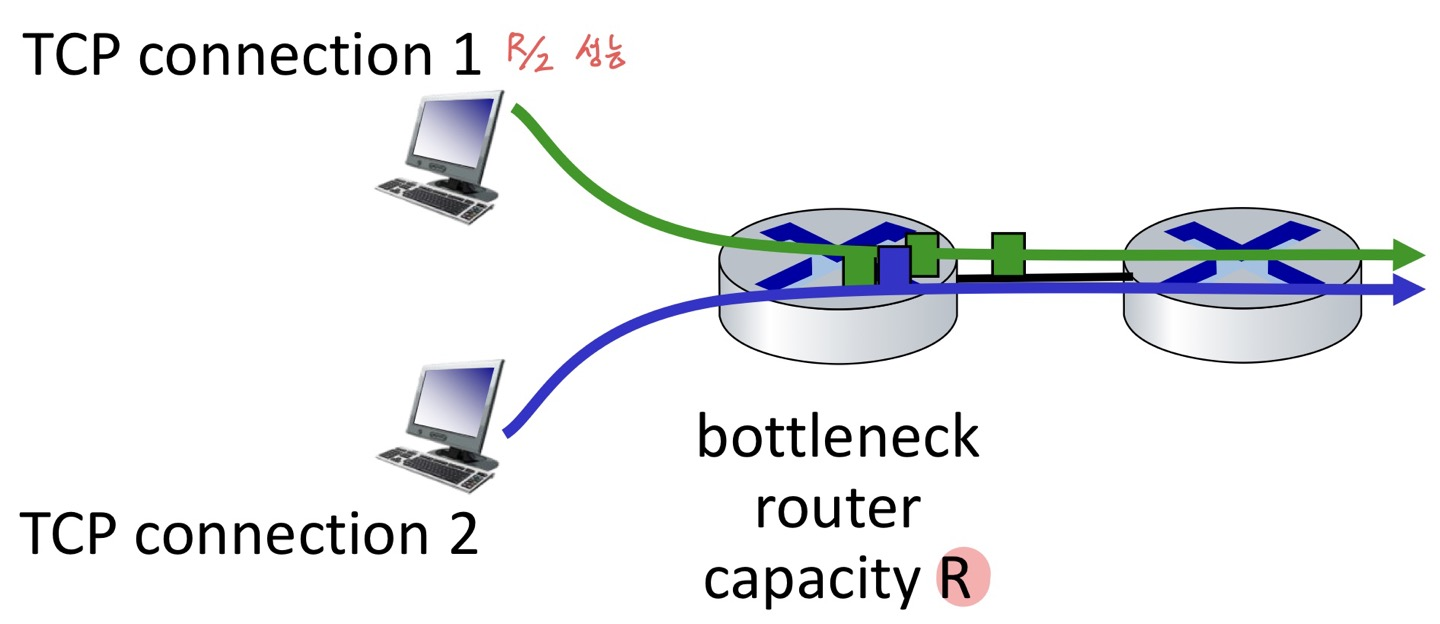
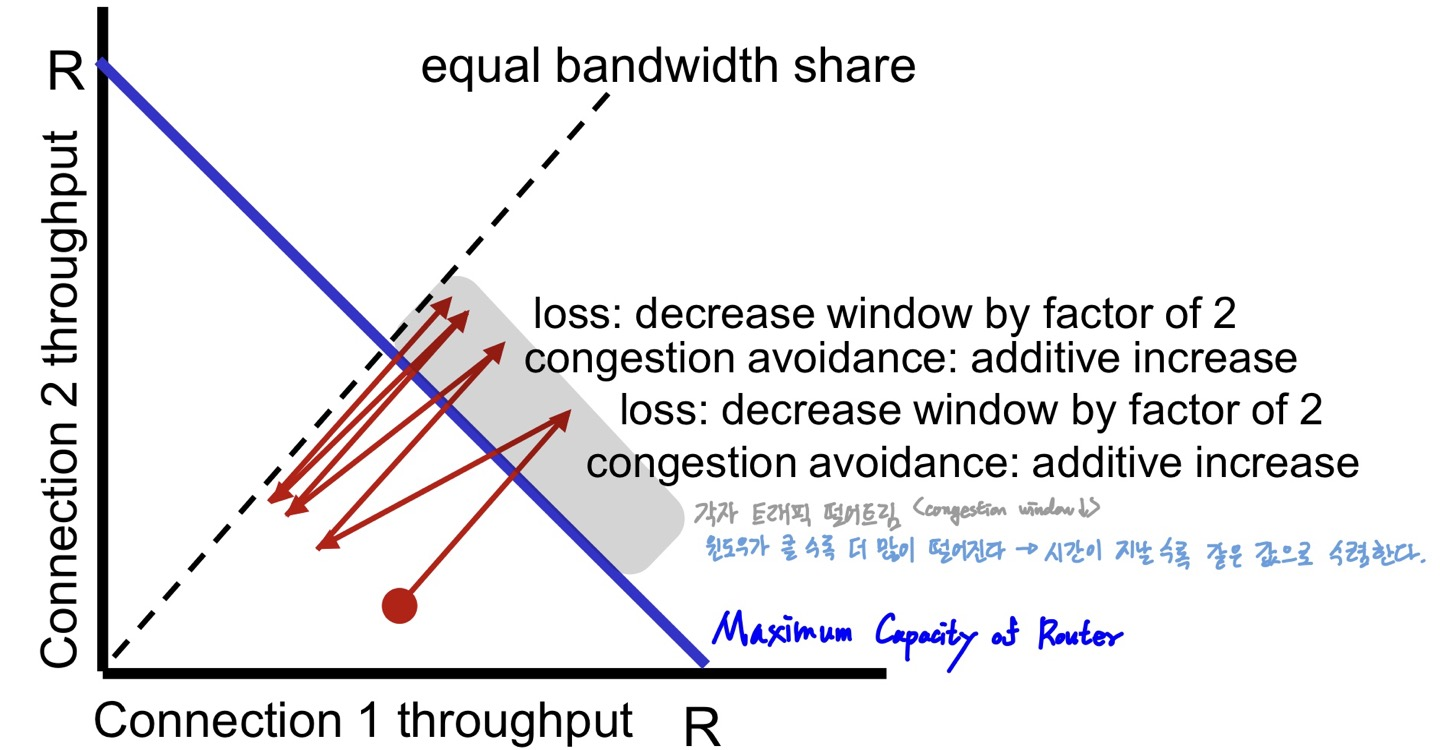
결과적으로 시간이 지나면 공정해진다고 할 수 있다.
Congestion이 발생하면 각각의 PC가 트래픽을 떨어트릴 것이고, window가 클 수록 더 많이 떨어지기 때문에 시간이 지날 수록 같은 값으로 수렴하게 된다.
물론 현실은 다르다.
위의 조건이 성립하기 위해선 몇 가지 가정이 필요하다.
- 모두 같은 RTT 값을 가져야 한다.
- 모두 같은 Connection을 가져야 한다.
- TCP 통신만 존재해야 한다. (UDP는 다소 '이기적'인 통신이라서)
현실에서는 RTT 값이 작은 연결이 link의 대역폭을 더 많이 붙잡을 수 있다.
이것까진 어떻게 TCP끼리 잘 해결한다 치더라도, UDP나 TCP 병렬 연결을 사용하는 application이 불공평한 할당을 얻게 될 수도 있다.