Git은 솔직히 이론 공부보다는 실전 사용이 훨씬 중요하다.
공부를 목적으로 팀 프로젝트 해보면서 커밋 내역도 날려먹었다가 욕도 먹어보고, 충돌나서 뇌가 정지하는 경험을 반복하다 보면 능숙해진다. (난 42Seoul에서 리눅스 명령어와 함께 뇌에 강제 주입시켰었다.)
[Git] What is Git?
올해 동아리 대표로 활동하게 되면서 어디서부터 일반 부원들을 가르쳐야 할까 고민하다가, 생각보다 많은 학생들이 모르던 Git에 대해 다루게 되었다. (전공자라도 별도로 프로젝트나 웹에 대
jaeseo0519.tistory.com
이전 포스팅에서 git의 기초를 다뤘고 이번에는 branch에 대해 설명할 것이다.
개인 프로젝트에서도 중요하긴 하지만 팀 프로젝트에서 branch에 대한 개념을 모른다면..여러모로 피곤해진다.
git 전략에 대한 내용은 일단 다른 강의 자료를 우선 만들고 작성할지 말지 고민 좀 해봐야겠다.
목차
1. What is git remote?
2. What is HEAD & branch?
3. git branch : 브랜치를 확인하고 생성하자
4. git checkout : 헤더를 이동하자
5. git merge : branch를 합치자
6. git rebase : branch의 base를 조정하자
7. git log : 커밋 내역을 확인하고 관리하자
8. git 커밋 내역을 관리하는 이유
1. What is git remote?
처음 git을 연동하면 다음과 같은 명령어를 사용하는 것을 본 적이 있을 것이다.
git remote add origin [본인 github repository url]정확히 따지자면 origin은 별칭이라서 본인이 원하는 네이밍을 지으면 된다. (하지만 굳이?)
remote는 [repository url]을 기억하기 위해 [별명(origin)]을 alias로 다룰 수 있도록 한 것이다.
local에서만 commit을 할 것이라면 몰라도 외부 저장소를 사용한다면, git에게 외부 저장소 '어디에' 저장하는지 알려준다고 생각하며 된다.

git remote 명령어에 v 옵션을 주면 등록된 별명과 매칭되는 url을 보여준다.
git push를 통해서 다음과 같이 명령어를 작성해보자
git push origin main이 명령어의 의미는 origin(외부 저장소 url)의 main 브랜치에 현재 브랜치의 변경사항을 올리겠다는 의미가 된다.
2. What is HEAD & branch
branch는 나뭇 가지를 의미하는 단어다.
그렇다면 git branch는 어떤 의미에서 이런 단어를 사용하는 것일까?
이전 포스팅에서 git은 commit 내역의 스냅샷을 찍어 저장한다고 했었다.
하지만 이 스냅샷들이 아무런 규칙도 없이 중구난방 어질러져 있으면 저장해두는 의미가 없을 것이다.
그래서 git은 이 스냅샷들을 저장하고 각각의 id을 설정한 다음 "현재 내가 보고 있는 위치"를 포인터로 가리키고 있는데 이걸 HEAD라고 생각하면 된다.
즉, 현재 위치를 HEAD는 현재 위치를 가리킨다.
🤔 HEAD 브랜치가 아니라 커밋을 가리킨다구요?
하지만 처음 git log로 확인을 해보면 헷갈릴 수도 있다.
"현재 HEAD는 develop이라는 브랜치를 가리키는 것이고 특정 commit을 가리키는 것 같지는 않은데요?"라고 생각할 수 있지만, 아무거나 commit을 해보고 push하기 직전에 다시 log를 띄워보자.
HEAD -> main의 위치는 옮겨졌으나, origin/main의 위치는 여전히 이전 커밋을 참조하고 있는데,
HEAD는 현재 위치를 참조해야 하므로 당연히 commit을 하면 자동적으로 현재 브랜치의 가장 최근 커밋을 가리키게 되지만 push를 함으로써 원격 저장소에 넣지 않았으니 origin은 이전 커밋 내역의 존재밖에 몰라서 차이가 발생하는 것이다.
따라서 HEAD->main은 현재 커밋의 브랜치를 알려주는 것 뿐이고, 저 표시가 커밋 내역 옆에 있다는 것은 해당 커밋이 현재 내가 참조하고 있는 내역이라는 의미를 갖는다.
🧐 그러면 브랜치는 대체 뭔가요?
git commit을 main 브랜치 한 곳에서만 다룬다고 가정해보자.
아직 개발 단계의 서비스에서도 작업이 귀찮아지지만, 배포 중인 서비스라면 중대한 문제가 발생한다.
v1.0 단계에서 배포를 진행중이던 서비스를 개선한 이후 v1.1을 커밋했을 때, 한 번에 성공하면 다행이지만 merge 과정이나 실제 동작 과정에서 에러가 발생할 수 있다.
그러면 버그 픽스 버전을 커밋하기 전까지 HEAD를 옮겨놓는다 하더라도 일정 시간 동안 서비스 제공에 차질이 생기게 되는데, 이건 개발자나 사용자 입장에서나 유쾌한 상황이 아니다.
또한 팀플을 할 때에도 내가 login 기능을 만드는 작업을 하고 중간 중간 push를 하려고 할 때, 다른 기능을 작업하던 팀원들의 commit 내역이 있으면 매번 병합을 해야하는 번거로운 작업까지 수반될 수 있다.
이렇게 개발 속도를 더디게 만들거나 심각한 오류를 발생하는 경우를 없애기 위해 git tree를 나누어 서로 다른 branch에서 작업하고 가장 마지막에 병합을 하는 것이다.
예를 들어, 위의 상황을 방지하기 위해서 보통은 main 브랜치에서 개발을 하지않고 develop 브랜치를 생성하여 작업을 수행한 후, main에 merge한다.
📌 git branch 전략
브랜치 또한 마구잡이로 만들면 혼란을 야기할 수 있다.
어떤 목적을 가지고 있고 어떤 커밋에서 분기되었는지 등을 모른다면 사용하는 것만 못한 상황이 벌어진다.
해당 내용은 나중에 더 심도있게 다룰 것이지만 branch의 목적을 이해하는데 이만한 것이 없어서 가장 정석적인 방법만 설명해두려고 한다.
프로젝트 이전에 어떤 서비스를 개발하느냐에 따라 branch 전략은 상이하다.
정답이 있는 것도 아니고, 본인의 프로젝트에 효율적인 워크 플로우를 팀에서 선택해서 사용하면 된다.
Git Flow는 Main, Develop으로 분기하여 Feature, Release, Hotfix 브랜치가 존재한다.
Main 브랜치는 언제나 출시 가능한 코드를 모아두어야 하기 때문에 안전성 체크가 끝났을 때만 병합시킨다.
Develop 브랜치는 지속적으로 유지되면서 다음 버전 개발을 위한 작업 공간이라고 생각하면 된다.
Release 브랜치는 배포 전 단계에 사소한 버그를 해결한 이후 main, develop 브랜치 모두에 병합한다.
Hotfix 브랜치는 배포는 했는데 문제가 발생한 경우 빠르게 해결해야 하기 때문에 따로 운용한다.
Feature 브랜치는 각자 담당하는 기능을 개발하고 develop에 merge한다.
이 방법이 가장 정석적으로 사용되고 있었지만 웹 어플리케이션에서는 적합하지 않다는 평가가 올라오면서 현재는 별의 별 전략이 다 나오고 있다.
중요한 건 이 내용을 알기 위함이 아니라, 브랜치를 나눔으로써 분업의 효율을 끌어올릴 수 있게 되었다는 점이다.
3. git branch : 브랜치를 확인하고 생성하자
git branch는 매우 간단하게 생성하고 삭제할 수 있다.
git branch (브랜치명)
git branch -d (브랜치명)위의 커맨드로 생성하고, 아래 커맨드로 삭제하면 된다.
그냥 git branch만 입력하면 현재 repository의 branch list를 보여준다.
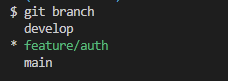
별표 처리된 곳이 현재 내 HEAD가 존재하는 branch라는 것을 보여준다.

v 옵션을 넣어주면 각 브랜치의 상세한 정보까지 보여준다.
작업 도중 브랜치 명을 변경하고 싶다면 아래 코드를 사용하면 된다.
git branch -m (현재 브랜치명) (변경할 브랜치명)
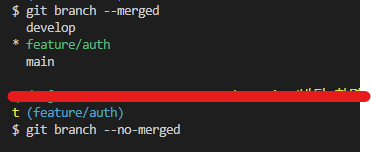
--merged나 --no-merged 옵션을 걸어주면 현재 위치한 브랜치 기준으로 Merge된 브랜치인지 아닌지 확인이 가능하다.
위의 경우에선 --merged 옵션을 걸었을 때, 모든 브랜치가 나타났으므로 feature/auth 브랜치는 제거해도 무방한 상태다.
만약 merge가 완수되지 않은 브랜치를 삭제하려고 하면 강제 옵션을 걸어야 한다.
4. git checkout : 헤더를 이동하자
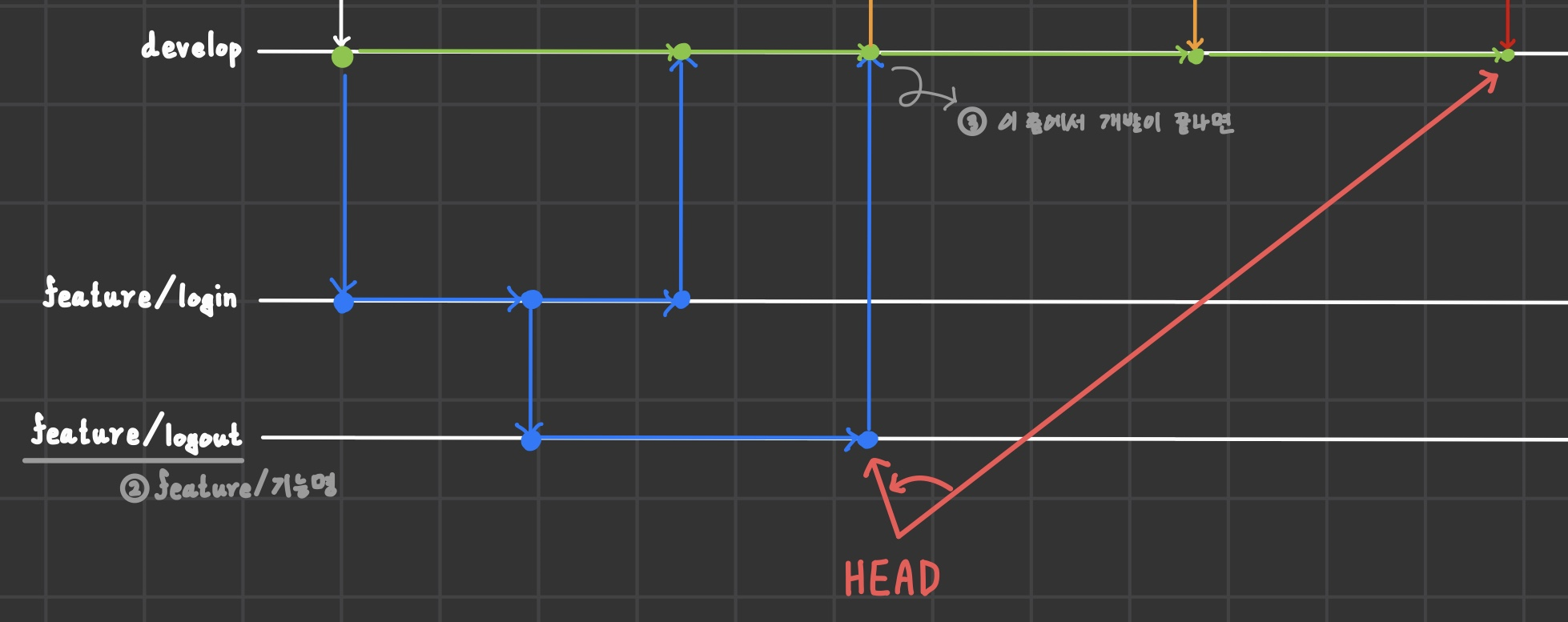
헤더는 현재 위치랑 동일시하면 된다고 했다.
develop 브랜치의 작업에서 이전 커밋 내역을 확인하려면 헤더를 옮기면 된다.
그 기능이 바로 checkout이다.
git checkout (브랜치명) // 해당 branch로 이동
git checkout -b (새로운 브랜치명) // 해당 branch 생성 후 이동
git checkout -b (새로운 브랜치명) (base 브랜치명) // 해당 branch에서 파생되는 branch 생성 후 이동
git checkout . // 모든 변경사항(add, commit 안 한 경우) 취소
git checkout (commit hash) // 해당 커밋 버전으로 이동checkout은 보통 branch를 이동할 때 많이 쓰지만, 사실 HEAD를 옮기는 명령어다.
기본적으로 branch의 가장 최근 커밋 내역을 가리키기 때문에 굳이 commit hash를 입력하지 않을 뿐,
만약 최신 버전이 아닌 commit으로 이동하고 싶다면 특정 커밋의 hash code를 넣어주면 된다.
📌 Hash Code


노란색 글씨로 적혀있는 긴 문자열이 commit hash 값이고, 너무 길기 때문에 보통 github에서 보여주듯이 'adc6c8c'로 간단히 표기한다.
굳이 정수형 번호가 아니라 token처럼 문자열로 된 아이디를 지급하는 이유는 local DB만 사용한다면 몰라도 클라우드와 자원을 공유하기 때문에 생기는 문제가 있다.
1, 2, 3, ...으로 저장한다면 branch를 합치는 과정에서 이전 commit id를 탐색하고 갱신하는 번거로운 과정이 필요한데, 이를 그냥 랜덤한 문자열로 생성해버린 것이다.
이러면 굳이 id의 중복 검사를 하지 않고, 그냥 생성 시간 순서대로 나열하면 그만이다.
💡 Hash Code는 중복이 없을까?
난 한 번 HashCode가 겹치는 것을 본 적이 있다. (나는 아니고 다른 사람이 겪었다.)
그 때는 git을 처음 써보던 때라 몰랐는데, 지금 그걸 봤다면 바로 로또를 사러 갔을 것이다.
git의 Hash 값 중복이 발생할 확률은 무려 2의 80제곱 분의 일이다.
공대에서 이 정도 수치가 나오면 그냥 0으로 친다.
나는 천문학적인 확률을 뚫고 그 광경을 목격했던 것이다. 🤣
5. git merge : branch를 합치자
branch를 나누고 개발이 끝났으면 언젠가는 다시 병합을 해야한다.
여기서 방법이 2가지로 나뉘는데,
1. Merge만 한다.
2. Rebase와 Merge를 한다. (commit tree를 깔끔하게 유지하고자 할 때)
이실직고 하자면 난 rebase는 이론만 알고 써먹어 본 적이 없다.
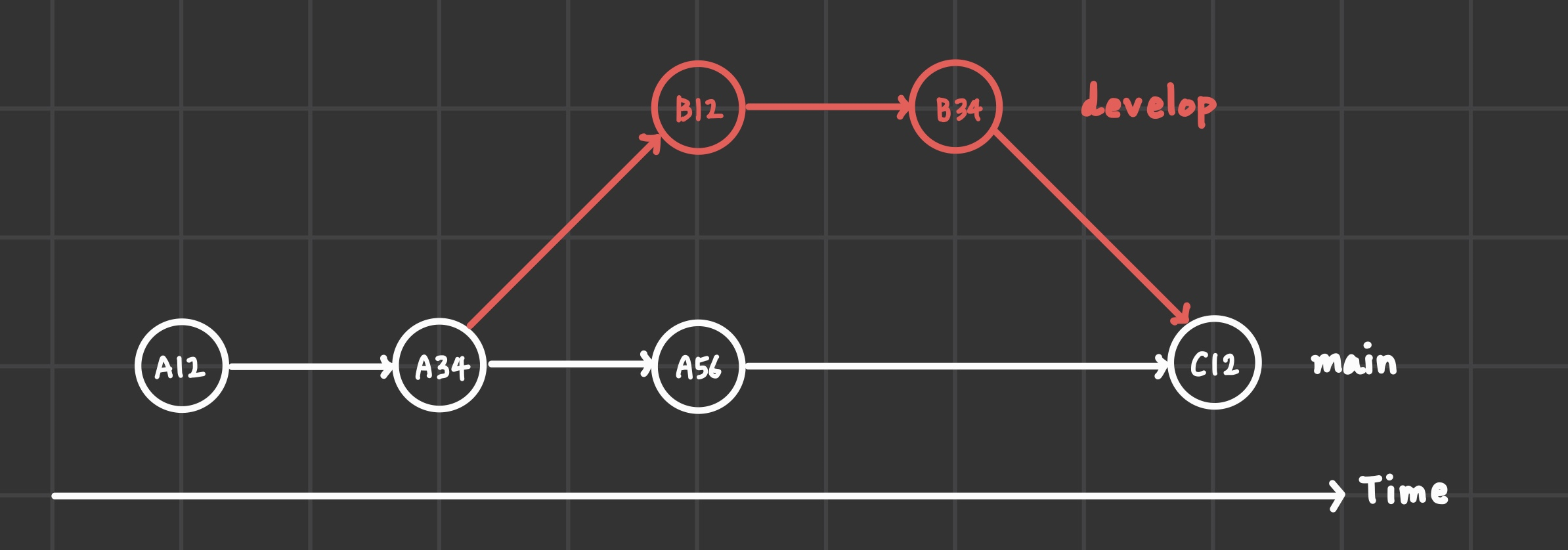
이런 식으로 git history가 작성되어 있다고 쳤을 때,
develop의 작업을 main에 병합하고 싶다면 다음과 같이 명령어를 작성하면 된다.
git branch main
git merget develop문제는 develop의 분기점 base는 A34인데, 그 이후에 Main branch에서도 A56이라는 커밋이 발생했으므로 병합 과정에서 충돌(conflict)이 발생할 수도 있다.
이 때는 충돌이 난 코드를 직접 수정을 해서 다시 add-commit을 해주거나, 'git merge --abort' 명령어로 병합을 취소할 수도 있다.
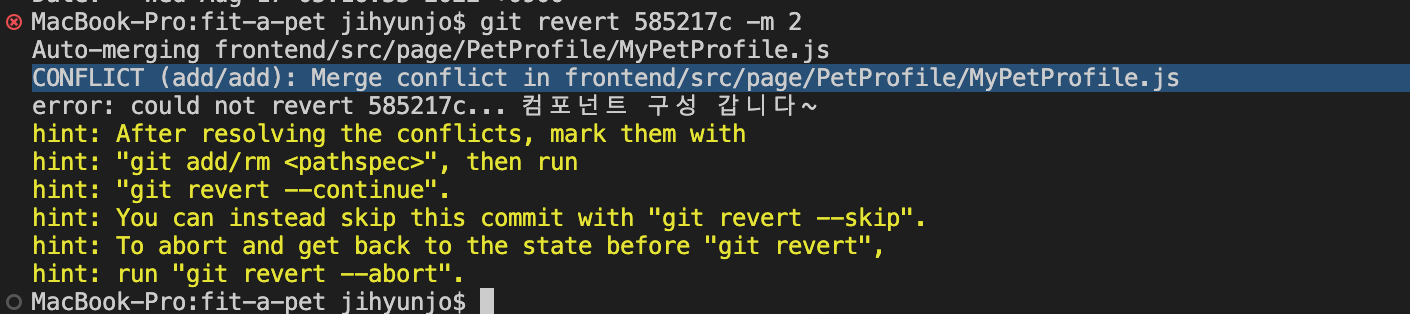
충돌을 컨트롤해야 할 파일은 git이 diff 결과를 소스에 띄워놓기 때문에 비교하여 적절히 수정해주면 된다.
6. git rebase : branch의 base를 조정하자
rebase는 단어 의미 그대로 base를 조정할 수 있다.
위의 git history의 문제는 develop 작업의 분기점 이후에 main에서 수행된 커밋 이력 때문에 충돌이 발생했을 때의 가정이다.
이럴 때 rebase를 하면 좀 더 깔끔하게 해결할 수 있는 방법이 있다.
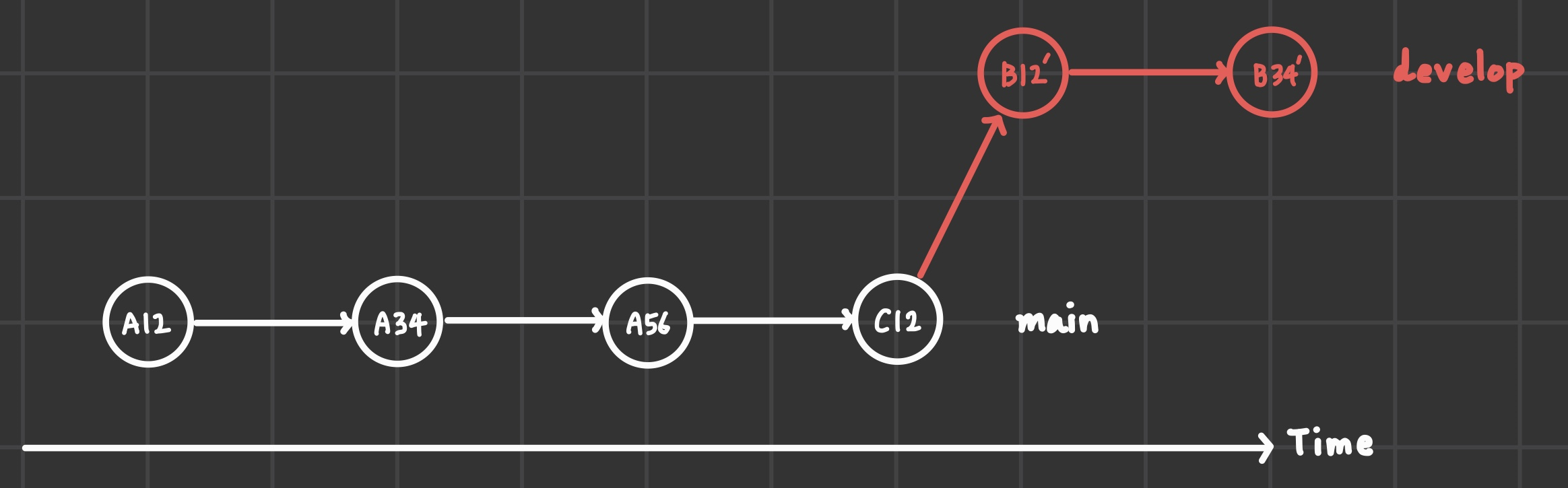
B12의 base를 C12로 옮기면 B12', B34'으로 커밋 이력이 갱신된다.
즉, main 브랜치를 기준으로 다른 브랜치를 재정렬시켰기 때문에 커밋 이력이 정렬됨에 따라 merge를 수행해도 conflict 없이 feat fast-forward merge가 가능해진다.
위 과정을 순서대로 명령어로 작성하면 다음과 같다.
git checkout develop
git rebase main // main을 기준으로 rebase
git checkout main
git merge develop단순히 merge만 하고 끝낼 것이 아니라 더 효율적이고 깔끔한 git history를 만들고 싶다면 git rebase에 대해 더 공부해보는 것을 권장한다.
💡 rebase할 때 주의 사항
rebase를 하면 커밋 이력이 갱신된다.
그런데 main은 실제 배포 중인 버전일 수 있기 때문에 함부로 건들여서는 안 된다.
rebase를 할 때, main이나 develop 브랜치 중 하나를 기준으로 삼아야 하는데
일반적으로 main에서 rebase를 하는 방식은 지양한다.
7. git log : 커밋 내역을 확인하고 관리하자
git log는 지금까지 커밋 내역을 조회할 수 있는 명령어다.
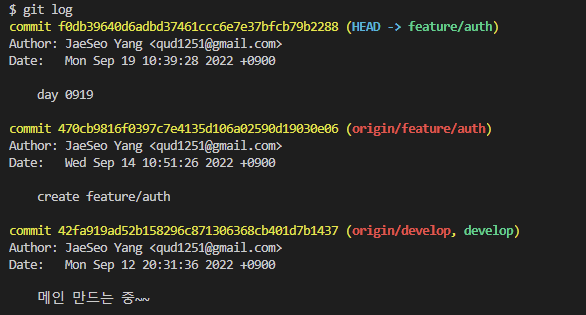
옵션을 걸지 않으면 commit Hash값, 작성자, commit 날짜, commit 메세지, HEAD의 위치, git hash 값 정보가 뜬다.
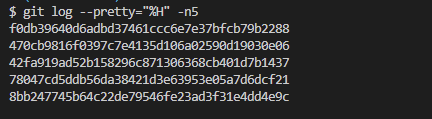
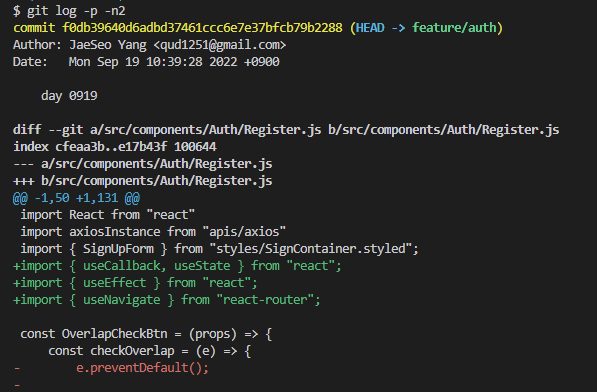
명령어에 능숙해지면 가공을 통해 원하는 정보를 쏙쏙 확인할 수 있긴 한데, 나도 자주 쓰는 몇 가지 커맨드 말고는 잘 모른다.
Git - 커밋 히스토리 조회하기
머지 커밋 표시하지 않기 저장소를 사용하는 워크플로우에 따라 머지 커밋이 차지하는 비중이 클 수도 있다. --no-merges 옵션을 사용하면 검색 결과에서 머지 커밋을 표시하지 않도록 할 수 있다.
git-scm.com
혹시 궁금하면 이 사이트를 참조하면 된다.
8. git 커밋 내역을 관리하는 이유
처음에 언급했듯 git은 모든 소스코드를 한줄한줄 담아 저장소에 보관한다.
아무리 강력한 압축 메커니즘을 사용한다고 한들, 누군가 바보같이 가상환경을 gitignore에 설정하지 않는다던가(그게 나야~), 무분별한 commit을 남발하면 용량이 생각보다 커진다.
이것은 git이 버전 관리를 할 수 있는 힘이지만, 강력한 힘에는 언제나 부작용(side-effect)이 따르기 마련.
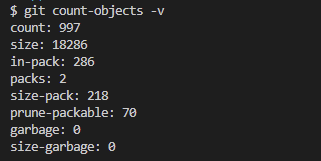
git count-objects -v이 명령어는 현재 git 저장소의 저장소 사이즈를 확인할 수 있다.
해당 repository는 997개의 커밋 이력과 18,727kb의 용량을 가진다.
github 무료 버전은 한 저장소에 2GB까지 할당해주므로 이 용량을 벗어나면 limit에 걸리게 된다.
또한, 무분별한 커밋과 트리 사용은 협업에 있어 작업의 흐름을 파악하기 힘들게 만들기 때문에 여러모로 관리가 필요하다.
관리하는 방법을 설명하는 내용은 너무 길어질 것 같으므로 포스팅을 분리하도록 하고,
지금 단계에서는 이 정도만 알고 넘어가면 된다.
제발 의미있는 내역에 대해서만 commit 하자.