💡 해당 포스팅의 내용은 정확하지 않습니다!
궁금한 점이나 의문점, 틀린점 등에 대한 댓글은 언제나 환영합니다.
또한 내용이 상당히 어려우니, 멀티 모듈과 도메인 규칙에 대한 기본적인 이해 지식을 필요로 합니다.
이전 내용을 다시 자세히 다루기엔 글이 너무 길어지고 번잡스러워지므로 양해 부탁드립니다. 🙇♂️
(작성 순서대로 정렬)
• 프로젝트 멀티 모듈화 고찰
• 도메인 비즈니스 규칙과 멀티 모듈 아키텍처 설계
• 다중 인프라스트럭처 도메인 모듈 분리를 위한 리팩토링
📕 목차
1. Introduction
2. How to Structure Domain Services
3. Implementing Domain Repositories: Query vs. Application Logic
4. Designing Domain Relationship
5. Conclusion
1. Introduction
📌 Topic

멀티 모듈 구성도 했고, 지긋지긋한 domain 영역을 구조적으로 개선하여 도메인 서비스가 위치할 영역도 구분을 끝마쳤다.
핵심 비즈니스 규칙은 domain-service 모듈에 모두 감추고, 안정적인 처리를 위한 기술적 요구사항만을 application 영역의 모듈이 수행하면 된다.
그러나 본질적인 몇 가지 문제들이 남아있다.
- 도메인 서비스를 어떻게 분리할 것인가?
- 채팅방 가입으로의 상태 이전을 위해, "상태 검사"와 "상태 이전"을 하나로 묶어야 하는가? 분리해야 하는가?
- 애플리케이션과 DB 중 어디서 로직을 처리할 것인가?
- 애플리케이션 혹은 DB 양쪽에서 모두 처리할 수 있는 로직이라면, 어디서 수행하는 것이 맞을까?
- Entity를 어떤 기준으로 분리할 것인가?
- User를 참조하는 테이블은 JPA를 사용하기 때문에, 언제나 ORM 기반의 연관 관계 매핑을 해야할까?
- Entity는 어떻게 정의해야 하는 걸까?
위 문제들을 순서대로 chapter 2, 3, 4에서 자세한 상황과 고민 과정들을 적어보려 한다.
굳이 순서대로 읽을 필요가 없으므로, 궁금한 부분만 찾아서 읽어보셔도 무방합니다. 🤗
2. How to Structure Domain Services
📌 As-is
도메인 서비스를 구조화하는 것은 매우 까다로운 의사 결정 중 하나이다.
하나의 비즈니스 규칙을 통합할 지, 혹은 나눌 것인지에 대한 고민이 필요하다.
이번 챕터에서는 실제로 겪었던 채팅방 가입 시나리오를 통해 이 문제를 살펴보려 한다.
채팅방 가입 시나리오를 떠올려보자.
이전 포스트의 chapter1: current architecture에서 핵심 비즈니스 로직과 서비스 비즈니스 로직을 구분할 때 사용한 예시를 사용할 것이다.
📝 채팅방 가입 도메인 규칙
1. 상태 확인: 채팅방에 가입이 가능한 지 검증한다. (ex. 비밀번호 확인, 인원 수 확인, 차단 여부 확인 등)
2. 상태 이전: 채팅방에 가입한다. (ex. 멤버 추가, 관련 이벤트 발행 등)
여기서 드는 의문은 "상태 확인"과 "상태 이전"이라는 두 행위를 구분할 것인지, 혹은 합칠 것인지에 대한 것이었다.
📍 한 가지 전제
현재는 분산락을 위한 AOP를 Redis를 사용하여 구현하였고, 이 기능 또한 domain-redis 내에 존재한다.
그러나 이전 포스트에서 이는 기술적인 관심사이기에 infra 모듈로 분류하는 것이 옳다고 생각했고,
이에 As-is 파트에서는 분산 락 코드가 infra 모듈 내에 위치해 있음을 가정한다.
쉽게 설명하자면, domain 영역의 모든 모듈은 분산 락 처리를 수행할 수 없는 상태가 된다.
1️⃣ 두 규칙을 합치는 경우
@DomainService
public class ChatRoomDomainService {
@Transactional
public void joinChatRoom(Member member, ChatRoom chatRoom, Password password) {
// 접근 가능 여부 확인
if (!chatRoom.isAccessibleWith(password)) {
throw new InvalidPasswordException();
}
// 상태 변경
chatRoom.addMember(member);
}
}- 하위 서비스에서 "상태 검사 → 채팅방 가입"이 아닌, "채팅방 가입"을 호출하기만 하면 끝난다.
- 하지만 "상태 검사"와 "채팅방 가입" 사이에 약간의 시간차로 인해, 검사 시점과 상태 전이 시점에 오차가 발생할 수 있다.
- 원자성(Atomic)을 지키기 위해 특수한 처리(ex. 분산락)를 수행해야 하지만, 현재 상황에서 domain-service 모듈에서 이를 처리하기 어렵다.
- 도메인 규칙의 원자성 보장을 위해 domain-rdb에서 낙관적 락(Optimistic Lock)과 같은 추가 작업을 요구한다.
- 그러나 낙관적 락은 분산 환경에서 동시성 제어가 불가능하므로, 현재 서비스가 단일 애플리케이션 환경이 아니라면 이를 제어하기 상당히 까다로워진다.
2️⃣ 두 규칙을 분리하는 경우
public class ChatRoomDomainService {
public boolean canJoin(ChatRoom chatRoom, Password password) {
return chatRoom.isAccessibleWith(password);
}
public void addMember(ChatRoom chatRoom, Member member) {
// 이미 검증된 상태라고 가정하고 상태만 변경
chatRoom.addMember(member);
}
}- 하위 서비스의 기술적 처리와 함께 잘 통합될 수 있는 구조를 가진다.
- 하지만 application 개발자가 똑똑해져야만 하는 상황이 발생한다.
- 개발자가 addMember() 이전에 canJoin()을 호출해야 하는 것을 인지하지 못한 상황
- 개발자가 두 연산의 원자성 보장을 위해 기술적 조치를 잊은 상황
- 두 개의 규칙이 원자적으로 이루어지기 위해, application 개발자가 도메인 규칙과 현재 구현된 기능에 대해 보다 상세히 알아야 하는 문제가 발생한다.
- 이는 Law of Demeter에 어긋난다.
위 내용을 정리하면 다음과 같다.
[도메인 서비스의 두 가지 설계 방식]
┌────────────────────────────────┐ ┌────────────────────────────────┐
│ 통합된 방식 │ │ 분리된 방식 │
├────────────────────────────────┤ ├────────────────────────────────┤
│ join(member, password) { │ │ canJoin(password) -> boolean │
│ validate() │ │ addMember(member) │
│ addMember() │ │ │
│ } │ │ │
└────────────────────────────────┘ └────────────────────────────────┘
⬇️ ⬇️
원자성 보장 필요 기술 계층과의 통합 용이
but 기술적 제약 but 도메인 규칙 파편화
그렇다면 차악을 선택할 수밖에 없는 것일까?
이 문제에 대한 해답을 얻기 위해, 다음과 같은 순서로 내용을 다룰 것이다.
- 두 규칙을 분리했을 때의 문제점
- (2)의 방식의 부적절성 검증 (하나의 행위를 "확인"과 "실행"으로 분리해도 괜찮은가?)
- 비즈니스 규칙 원자성 보장의 중요성
- 분산락이 infrastrucutre 모듈로 가는 것이 본질적으로 옳은가에 대한 고민
- 만약, 이게 아니라고 판단할 수 있다면, 두 규칙을 합치는 방향으로 전개할 수 있게 된다.
- 도메인 관점에서 바라보았을 때의 옳은 방법
Bounded Context 관점으로만 분석해도 되겠지만, 그렇게 하면 나같은 초짜들은 당췌 받아들이기가 힘들다.
그래서 우선 기술적 관점으로 반박하고, 도메인 관점으로 다시 바라보는 방법으로 분석하길 택했다.
📌 Drawbacks of Separating Two Rules
🤔 두 규칙을 분리하고, 하위 서비스에서 기술과 통합하도록 설계할 것인가?

public class ChatRoomService {
/**
* 채팅방 참여 가능 여부를 확인합니다.
* 이 메서드는 "검증"만을 책임집니다.
**/
public boolean canJoin(ChatRoom chatRoom, Password password) {
}
/**
* 채팅방에 멤버 정보를 추가합니다.
* 채팅방 가입 시나리오라면, 반드시 {@link ChatRoomService#canJoin}으로 상태를 검사해야 하며,
* 두 연산은 원자적인 연산을 보장해야 합니다.
**/
public void addMember(ChatRoom chatRoom, Member member) {
}
}이 방법은 "상태 확인"과 "상태 전이" 메서드를 분리하여, 하위 서비스에서 분산락과 같은 기술적 인프라와 통합하는 방식이다.
처음엔 이 방법으로 접근하려 했으나, 뭔가 알 수 없는 찝찝함이 계속해서 맴돌았다.
"채팅방 입장"이라는 하나의 도메인 행위를 "확인"와 "실행"으로 분리하는 것은 정말 코드의 재활용성을 높였다고 볼 수 있을까?
1️⃣ canJoin 신뢰성과 예외 처리의 책임
public class ChatRoomJoinService {
@DistributedLock
public void joinChatRoom(JoinChatRoomRequest request) {
boolean canJoin = chatRoomService.canJoin(chatRoom, request.getPassword());
if (canJoin) { // 무엇이 '가능'하다고 판단한 것인지? 어떤 조건들을 확인했길래?
chatRoomService.addMember(chatRoom, member);
}
}
}- ChatRoomService은 canJoin 내부적으로 어떠한 규칙에 의해 결과를 도출하는 지 알 수 없다.
- 물론, 이건 원칙 상 비즈니스 규칙을 외부에 노출시키지 않은 좋은 예시다.
- 문제는 비즈니스 규칙의 세부적인 처리를 호출자 측에 위임해버렸기 때문에, ChatRoomJoinService가 "어떤 기준으로 검사하는지"에 대한 관심이 많아졌다.
- canJoin이 false라는 값을 반환했다면, 이는 비밀번호 오류인가, 채팅방에 사용자가 가득찼기 때문인가, 혹은 그 외의 규칙 때문인가?
이 문제를 해소하려면, 결국 하위 서비스에 더 많은 정보를 노출하는 방법밖에는 없다.
public class ChatRoomJoinService {
@DistributedLock
public void joinChatRoom(JoinChatRoomRequest request) {
JoinToken token = chatRoomDomainService.validateJoin(chatRoom, password);
// - 비밀번호가 맞았다
// - 검증 당시 방의 수용 인원이 얼마였다
// - 이 검증은 언제까지 유효하다
chatRoomDomainService.addMember(chatRoom, member, token); // addMember의 token 인자를 위해, 반드시 validateJoin을 수행해야 함
}
}
public class JoinToken {
private final Long chatRoomId;
private final int currentMemberCount;
private final LocalDateTime validUntil;
public boolean isValid(ChatRoom chatRoom) {
return chatRoom.getId().equals(chatRoomId)
&& LocalDateTime.now().isBefore(validUntil)
&& chatRoom.getCurrentMemberCount() == currentMemberCount;
}
}- 혹은 여기서 받은 token을 addMember의 파라미터로 전달하여, 두 규칙을 명시적으로 통합할 수도 있다.
- 검증 시점 상태를 보존하고, 두 메서드간의 순서 의존성을 강제적으로 준수하도록 만듦으로써 안전성을 확보했다.
- 그러나 "채팅방 가입"이라는 자연스러운 행위를 인위적으로 둘로 나누었다는 점은 여전하다. (여기서 유즈케이스는 그저 "채팅방 가입"일 뿐인데도!)
- "이 방에 가입할 수 있나요?" (validateJoin)
- "네, 여기 가입 가능한 토큰입니다." (JoinToken)
- "이 토큰으로 가입하겠습니다." (addMember)
2️⃣ 도메인 규칙 원자성 훼손
하지만 이는 이상하게 들릴 수 있는데, 예외 처리 시스템을 잘 구축해둔 상태라면 별 문제가 없을 것이라는 점이다.
또한 "행위"를 관점으로 비즈니스 규칙을 통합한다고 해도, 예외 추상화를 높이기 위한 처리는 마찬가지로 수행해줘야 하는 것 아닌가?
이 방법의 진짜 문제는 "채팅방 가입 가능 여부 확인"이 독립적인 의미를 가지지 않는다는 점이다.
- canJoin은 오직 "채팅방 가입"이라는 행위의 맥락에서만 의미가 있다.
- 확인 시점과 실행 시점 사이에 상태가 변경될 수 있는데, boolean 값은 단순히 그 순간의 상태만을 표현하므로, 실행 시점에는 무의미한 정보가 될 수 있다.
- 마치, 레스토랑에 가서 "자리가 있나요?"라고 물어보고 "네"라는 대답을 듣고 갔는데, 이미 테이블에 누가 앉아 있는 상황과 동일하다.
- 반면, "채팅방 가입"이라는 하나의 행위 구현했을 때는 예외가 발생하는 시점이 곧 행위가 실패하는 지점이다. 따라서 상태 불일치 문제를 하위 규칙에서 고려할 이유가 없다.
😟 이거 중복아닌가요?
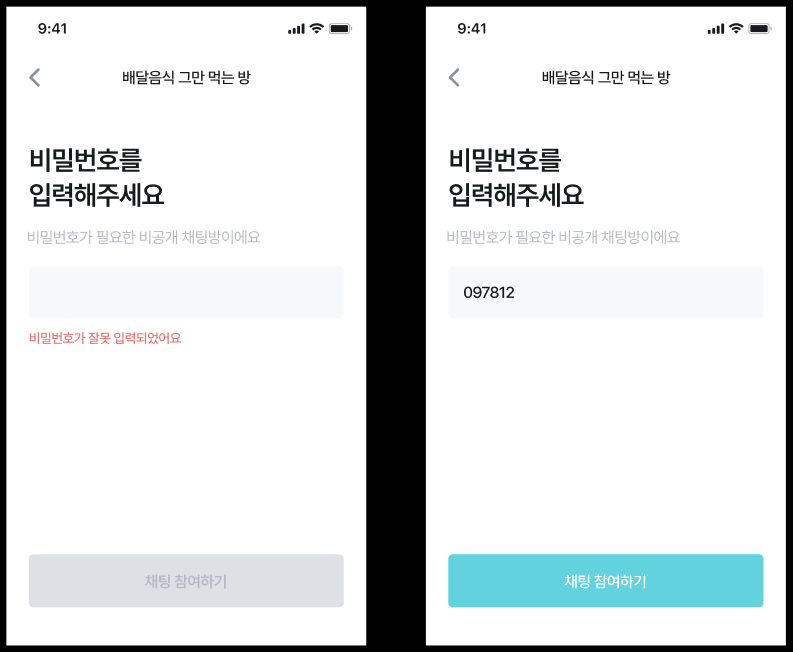
- 채팅방 가입이 아닌, 검증 뷰가 따로 존재하기 때문에 canJoin() 메서드를 분리하는 것이 옳다고 주장할 수도 있다.
- 그러나 비밀 번호 검증을 위한 "상태 확인"과, 채팅방 가입을 위한 "상태 확인"은 도메인 규칙이 다르다.
- 위 View를 위한 API에서는 오직 비밀번호 검증만을 수행한다.
- 채팅방 가입을 위한 상태 검사에서는 비밀번호 검증, 채팅방 가득참 정보, 사용자 밴 여부 등 독립적으로 발전할 수 있는 기능이다.
- 설령 두 규칙이 당장은 동일하더라도, 사용되는 맥락에 따라 다른 방식으로 구현될 수 있다. 누누히 말하지만, 이는 중복이 아니라 우발적 중복이다.
- 따라서 canJoin() 이라는 행위를 두 도메인 규칙에서 공유하려는 생각은 부적절하다.
3️⃣ 기술적 제약 주도 개발?
💡 "동시성 제어"라는 기술적 문제를 해결하기 위해, 도메인 규칙을 분리하는 것은 바람직하지 않다.
위 설계의 가장 큰 문제점은 하나의 행위를 둘로 나누려한 동기가 도메인 관점이 아닌, 분산 락의 위치(기술적 제약) 때문이었다는 것이다.
[처음에 생각한 내용]
- 채팅방 가입을 위한 "확인"과 "실행"은 원자적으로 이루어져야 한다.
- 원자적 연산을 보장하기 위한 분산 락이 infrastructure 모듈에 위치하므로, domain-service 모듈에서 호출할 수 없다.
- 따라서 하위 서비스에서 세부 규칙을 완성해야 한다.
그러나 도메인 관점으로 바라봤을 때, 하나의 행위를 다수의 행위로 분리하는 것은 적절하지 않다는 것을 위에서 확인했다.
따라서 원자성 보장을 domain-service 내에서 지켜줄 필요가 있다.
그렇다면, 이를 위해 가장 먼저 "분산 락을 순수하게 기술적 관심사라고 봐야할 것인가?"를 생각해야 한다.
📌 Is It Correct to View a Distributed Lock as a Purely Technical Requirement?
📍 현재 상황
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
• 분산 락을 infrastructure 영역에 두어야 한다고 생각
• @DistributedLock 어노테이션으로 구현
💡 핵심 질문
"분산 락은 정말 순수한 기술적 관심사일까?"
[Spring Boot] 동시성 제어와 분산 락(Distributed Lock)
📕 목차1. 동시성 문제2. 낙관적 락과 비관적 락3. 분산락1. 동시성 문제 📌 Single Process & Single Thread모든 요청을 하나의 애플리케이션, 그리고 하나의 Thread가 처리한다면 동시성 문제는 발생하지
jaeseo0519.tistory.com
@DistributedLock(key = "'chat-room-join-' + #chatRoomId")
public void execute(Long userId, Long chatRoomId, Integer password) {
...
}우리 서비스에서는 위와 같이 @DistributedLock 어노테이션을 선언해두면, 분산 락이 동작하도록 AOP를 만들어두었다.
분산 락을 구현하기 위해 redis라는 특정 기술과 밀접하게 관련이 있기 때문에,
추후 해당 어노테이션을 domain-redis 모듈에서 infrastructure 모듈로 이전하는 것이 적절할 것이라 생각했으나 과연 그럴까?
우리는 종종 특정한 기술이 인프라스트럭처의 영역이라고 단정 짓게 되지만, 해당 기술의 구현과 그 필요성을 혼동하기 때문인 것 같다.
트랜잭션을 예시로 들어보자.
// 도메인 서비스
@Transactional // JPA, JDBC는 인프라 계층의 기술이지만, 트랜잭션의 필요성은 도메인 규칙에서 비롯됩니다
public void transfer(Account from, Account to, Money amount) {
from.withdraw(amount); // 출금과
to.deposit(amount); // 입금은 하나의 원자적 단위로 실행되어야 합니다
}- 트랜잭션의 구현은 인프라 계층의 책임
- 원자성을 어떻게 보장할 것인가?
- 트랜잭션의 필요성은 도메인 규칙에서 비롯한다.
- 이 규칙은 원자적으로 이루어져야 한다!
- 만약, 기존의 논리대로 분산락은 기술적 관심사이므로 도메인 서비스에서 사용할 수 없다면, @Transactional 또한 사용해서는 안 된다.
- 즉, 분산 락은 단순한 기술적 구현이 아니라 도메인 규칙의 무결성을 보장하기 위한 필수적인 요소라고 보는 것이 보다 적절하다고 생각한다.
🟡 DistributedLock이라는 용어가 기술적인 의미를 내포하고 있지 않은가?
@MySQLTransaction // 특정 데이터베이스에 종속적인 어노테이션
public void transfer(Account from, Account to, Money amount) {
// 계좌 이체 로직
}- DistributedLock이라는 용어는 원자성을 지키기 위한 규칙보다는, 특정 기술명에 가깝다.
- 위 코드처럼 마치 @Transactional을 @MySQLTransactional이라고 사용하는 것과 비슷하다.
- 따라서 여전히 분산 락이 domain-service에서 사용되는 것이 부적절하다고 볼 수 있지만, 이는 적절한 추상화가 지켜지지 않은 문제라고 생각한다.
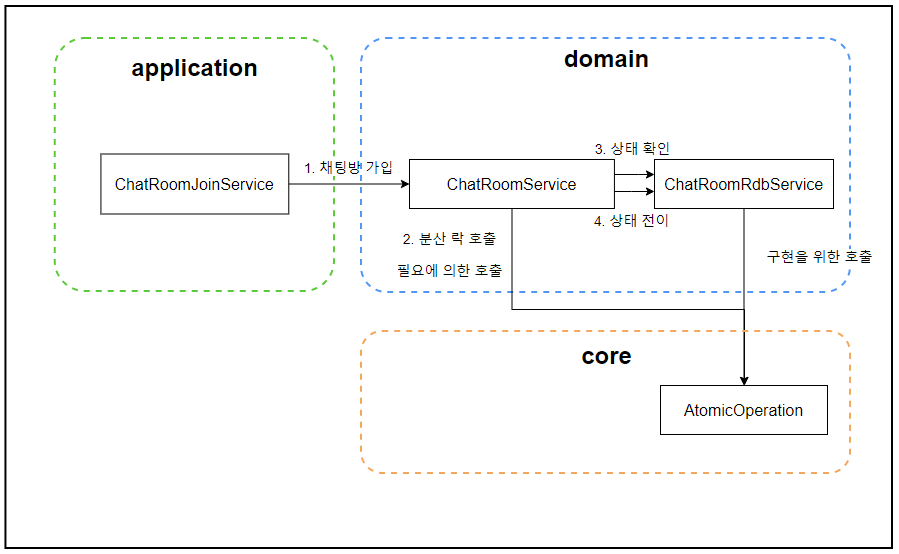
@AtomicOperation(key = "'chat-room-join-' + #chatRoomId")
public void execute(Long userId, Long chatRoomId, Integer password) {
...
}Copy[기술과 도메인 관심사의 구분]
┌─────────────────────┐
│ 도메인 규칙 │
├─────────────────────┤
│ "원자성이 필요함" │
└─────────────────────┘
↓
┌─────────────────────┐
│ 구현 방식 │
├─────────────────────┤
│ • @Transactional │
│ • @AtomicOperation │
└─────────────────────┘- DistributedLock 대신 AtomicOperation이라는 네이밍을 사용하면 어떠한가?
- common 모듈에서 annotation을 정의하고, domain-redis에서 기술적인 구현을 처리한 후, domain-service 모듈에서 필요성을 정의한다면 보다 납득이 되는가?
물론 이렇게 떠들어놓고, 나중에 '생각해보니까 내가 틀렸음 ㅋ'라고 할 수도 있지만
지금 당장은 나름 적절한 해석이라고 생각한다. (제 글은 추론이 80%이므로, 비판적으로 읽어주세용..😅)
여튼 이렇게 되면, domain-service에서 분산 락을 호출하지 못 한다는 제약이 없어지므로 원자성을 보장할 수 있게 된다.
다시 처음으로 돌아가 순수하게 비즈니스 관점에서만 채팅방 가입 시나리오를 다시 살펴보자!
📌 How Do Domain Specialists View This?
💡 설계 결정은 기술적 제약이나 구현의 편의성이 아닌, 도메인 자체의 본질에 기반해야 한다.
이제 두 규칙을 합치는 행위의 정당성을 보이려 한다.
도메인 관점으로 바라본다는 것은 개발자들에게 참 어려운 일이다.
기술에 미치면 미칠 수록, 개발자는 필연적으로 기술 중심으로 모든 일을 해결할 수 있다고 믿게 되기 때문이다.
아주 잠시 기술과 관련된 모든 부분을 잊어버리자.
도메인 전문가에게 "채팅방에 입장하는 것은 '입장 가능한지 확인하기'와 '실제로 입장하기'라는 별개의 행위인가요? 아니면 이는 하나의 통합된 행위인가요?"라고 질문하면 무엇이라 답할까?
난 도메인 전문가가 아니라서 답을 모른다. 😂
그리고 서비스의 세부 규칙이 무엇이냐에 따라 답이 또 달라질 수도 있을 수도 있다.
하지만 (적어도 나는) 이를 하나의 통합된 행위로 볼 것이라 생각한다.
- "입장 가능 여부 확인"이라는 행위는 그 자체로는 아무런 의미가 존재하지 않는다.
- "입장"이라는 행위는 필연적으로 검증을 포함해야 한다.
- 두 행위 사이에 시간 간격이 존재한다는 것이 도메인 관점에서 이상한 상황
- 다시 말하지만, 순수하게 도메인 관점으로 바라보기 때문이다.
여기서 원자성은 결정의 결과이지, 원인이 되어서는 안 된다.
- ❌ "이것이 원자적이어야 하니까, 하나로 합치자"
- ✅ "도메인 관점에서 이는 하나의 행위이므로, 원자적으로 구현해야 한다"
📌 Same Logic, Different Behavior
💡 로직 분리 여부는 "같은 코드가 반복된다"라는 기술적 관점이 아닌, "이 행위가 도메인에서 어떤 의미를 가지는가"라는 비즈니스적 관점이 되어야 한다.
위 내용만으로는 아무래도 설득력이 충분하지 않은 거 같기도 하고 나조차도 받아들이기 쉬운 개념이 아니라서,
아주 약간만 개발자스럽게 접근해보기로 했다.
도메인에서 "입장 가능 여부 확인"이 독립적인 의미를 가질 수 있는 상황이 존재함을 생각해보자.
// 사례 1: 채팅방 목록에서 입장 가능 여부를 표시할 때
public class ChatRoomListView {
private final boolean isAccessible; // 입장 버튼의 활성화 여부를 결정
public static ChatRoomListView from(ChatRoom room, Password password) {
boolean canAccess = room.canAccess(password); // 여기서는 상태 변경 없이 확인만 필요
return new ChatRoomListView(canAccess);
}
}
// 사례 2: 실제 입장 시도할 때
public class ChatRoom {
public void join(Member member, Password password) {
validateAccess(password); // 같은 검증이지만 다른 맥락
addMember(member);
}
}| 📱 UI를 위한 확인 | 🔐 실제 입장을 위한 확인 |
| 단순 조회 목적 | 입장 프로세스의 일부 |
| 상태 변경 없음 | 상태 변경 동반 |
| 실시간 정확성 불필요 | 원자성 필요 |
- 상황
- 두 검증 모두 오직 "비밀번호 확인"만을 수행한다. (이는 중복인가?)
- 차이
- canAccess(): 이는 그저 "읽기" 작업의 일부이며, 상태 변경이 불필요함
- validateAccess(): 입장 시도 시의 검증은 "쓰기" 작업의 일부이며, 무결성 보장을 위한 필수 단계
- CQRS(Command and Query Responsibility Segregation) Pattern과도 밀접한 관련이 있는데, 같은 "검증"이지만 맥락에 따라 다른 방식으로 구현이 가능하다는 점.
설령 "확인"이라는 독립적으로 존재한다고 해서, 반드시 "입장" 행위 내에서 이를 분리할 필요가 없다는 것이다.
public class ChatRoom {
// Query: 독립적인 확인 용도
public boolean canAccess(Password password) {
return this.password.matches(password) && !this.isFull();
}
// Command: 통합된 입장 처리
public void join(Member member, Password password) {
// 비록 같은 검증 로직이 포함되지만,
// 이는 '입장'이라는 하나의 원자적 행위의 일부입니다
if (!this.password.matches(password)) {
throw new InvalidPasswordException();
}
if (this.isFull()) {
throw new RoomFullException();
}
this.members.add(member);
}
}- 독립적인 확인 작업이 필요할 때는 canAccess()를 사용할 수 있다.
- 실제 입장 처리에서는 검증과 상태 변경이 하나의 원자적 단위로 유지된다.
- 같은 규칙임에도 다른 맥락에서 다르게 사용된다.
이것이 바로 DDD에서 말하는 맥락에 따른 모델링이 아닐까?
동일한 비즈니스 규칙이라도 사용되는 맥락에 따라 다른 방식으로 표현될 수 있으며, 이를 함부로 하나로 합치는 작업이 훨씬 리스크가 큰 작업일 수 있다는 것이다.
✒️ Domain-Driven Design 책에서 말하는 서비스의 책임과 역할
Anemic Domain Model 관련 글을 읽다가, Eric Evans의 DDD 내용 일부를 알 수 있었다.
여기서 애플리케이션 계층과 도메인 계층에 대한 내용이 적혀있는데, 내가 분석한 것과 상당히 비슷했다.
[애플리케이션 계층 (서비스 계층의 이름)]
• SW가 수행해야 할 작업을 정의하고, 도메인 객체가 문제를 해결하도록 지시하는 역할.
• 비즈니스에 의미가 있거나, 다른 시스템의 애플리케이션 계층과 상호 작용하는 데 필요하다.
• 이 계층은 얇게 유지되어야 한다.
• 비즈니스 규칙이나 지식을 포함하지 않고, 작업을 조정하고 작업을 다음 계층 도메인 객체로 위임한다.
• 비즈니스 상황을 반영하는 상태는 없지만, 사용자 또는 프로그램에 대한 작업 진행 상황을 반영하는 상태는 가질 수 있다.
[도메인 계층(또는 모델 계층)]
• 비즈니스 SW의 핵심
• 비즈니스 개념, 비즈니스 상황에 대한 정보, 비즈니스 규칙을 표현하는 역할
• 비즈니스 상황을 반영하는 상태는 여기서 제어 및 사용되지만, 이를 저장하는 기술적 세부 사항은 인프라로 위임한다.
3. Implementing Domain Repositories: Query vs. Application Logic
📌 As-is
도메인 레포지토리를 구현할 때 흔히 마주치는 고민은 "어디까지 데이터베이스에서 처리하고, 어디까지 애플리케이션에서 처리할 것인가"이다.
이 문제는 단순히 기술적인 결정이 아닌, 도메인 모델의 순수성과 성능 사이의 균형을 맞추는 아키텍처 관점에서의 결정을 필요로 한다.
만약, "논리적으로 삭제(soft delete)된 디바이스 토큰 정보는 조회하지 않는다"라는 규칙이 있다고 가정하자.
// Application에서 처리하는 방식
@Service
public class DeviceTokenService {
public List<DeviceToken> getActiveTokens(Long userId) {
return deviceTokenRepository.findAllByUserId(userId).stream() // 논리적으로 삭제된 데이터도 모두 조회
.filter(token -> !token.isDeleted()) // 애플리케이션에서 필터링
.collect(toList());
}
}
// Query로 처리하는 방식
@Repository
public interface DeviceTokenRepository {
@Query("SELECT dt FROM DeviceToken dt WHERE dt.userId = :userId AND dt.deletedAt IS NULL")
List<DeviceToken> findActiveTokensByUserId(@Param("userId") Long userId);
}이는 Application에서 필터링해야 할까, 아니면 Query를 사용해 필터링해야 할까?
[현재 상황]
- 딱히 정해놓은 규칙이 없음. 그냥 그때그때 적절하다고 생각하는 방식으로 수행함.
- Application 처리 방식을 택했을 때, 조회할 데이터가 너무 많아질 거 같으면 쿼리로 필터링을 수행함.
- 문제는 external-api에선 삭제된 데이터를 제외해야 하고, admin 페이지에서는 모든 데이터를 필요로 한다면?
- 혹은 하나의 application 모듈에서 두 가지 기능을 모두 필요로 한다면?
- 컬럼 수는 많지 않으나 속성 값이 너무 많은 경우, 필요한 정보만 불러오기 위해 DTO로 데이터를 조회함
아무런 생각없이 코드를 작성하다보니, 다음과 같은 케이스가 종종 발생하곤 한다.
1️⃣ 하나의 애플리케이션에서 서로 다른 요구 사항
// 푸시 알림 발송 - 활성 토큰만 필요
List<DeviceToken> activeTokens = deviceTokenRepository.findActiveTokensByUserId(userId);
// 관리자 페이지 - 모든 토큰 이력 필요
List<DeviceToken> allTokens = deviceTokenRepository.findAllByUserId(userId);
2️⃣ 데이터 규모에 따른 임시 방편적 결정
// "데이터가 많으니까" Query로 처리
@Query("SELECT new com.example.TokenDto(dt.token, dt.deviceType) " +
"FROM DeviceToken dt WHERE dt.deletedAt IS NULL")
List<TokenDto> findActiveTokensWithProjection();
// "데이터가 얼마 없으니까" Application에서 처리
List<DeviceToken> tokens = repository.findAll();
return tokens.stream()
.filter(token -> !token.isDeleted())
.collect(toList());
😡 아름답지...않아!!!
- 위 방식으로 device token 관리 로직을 구현했더니, 유지/보수성이 매우 떨어지게 되었다.
- soft delete 방식을 처음 사용해보기도 했고, 한창 아키텍처 과도기 때 작성했었던 코드라지만, 최근에 수정할 일이 생겼는데 기능 하나를 수정하기 위해 controller부터 repository까지 모든 코드를 확인해야 했다.
- 근본적인 질문들이 우후죽순 생겨나기 시작했다.
- soft delete 필터링은 비즈니스 규칙인가, 단순한 데이터 필터링인가?
- 성능과 비즈니스 로직 명확성 중 무엇을 우선시 해야 하는가?
- 같은 필터링 로직이 다른 맥락에서 사용될 때, 이를 어떻게 일관성 있게 처리할 것인가?
쿼리로 어느정도의 연산 레벨까지 허용 하는게 맞을까요? - 인프런 | 커뮤니티 질문&답변
누구나 함께하는 인프런 커뮤니티. 모르면 묻고, 해답을 찾아보세요.
www.inflearn.com
(인프런에 올라온 질문에 대한 김영한님의 친절한 답변)
지금부터 다룰 내용은 위 설명을 좀 더 자세히 분석하고, 내가 겪은 케이스에서 해결책을 강구해볼 예정이다.
그래서 이번 챕터 글의 순서도 답변의 순서와 비슷하게 흘러간다.
- 데이터베이스의 역할은 무엇인가?
- DTO를 결정하는 요소
- 비즈니스 로직과 쿼리의 분리란?
- Soft Delete 정책은 비즈니스 규칙인가?
- 프레젠테이션 로직의 Query 침투 문제점
📌 Roles of Database
데이터베이스에서 조회 시 역할은 크게 3가지로 나눌 수 있다.
- Filter (where)
- Projection (select)
- Aggregation (group by)
기술적으로 이 3가지는 데이터베이스에서 수행해주어야, 애플리케이션과 DB 간에 전송되는 데이터가 최적화 된다.
// 예시: 채팅방 목록 조회 API
public List<ChatRoomDto> getChatRooms(SearchCriteria criteria) {
// 1. Filter (WHERE)
List<ChatRoom> rooms = chatRoomRepository.findAll(); // ❌ 모든 데이터 조회
List<ChatRoom> filtered = rooms.stream()
.filter(room -> room.getType() == criteria.getType())
.collect(toList());
// 2. Projection (SELECT)
List<ChatRoomDto> projected = filtered.stream() // ❌ 불필요한 데이터 전송
.map(room -> new ChatRoomDto(room.getName()))
.collect(toList());
// 3. Aggregation (GROUP BY)
Map<ChatType, Long> countByType = rooms.stream() // ❌ 메모리에서 집계
.collect(groupingBy(ChatRoom::getType, counting()));
}- 불필요한 데이터가 네트워크를 통해 전송된다.
- 애플리케이션 메모리를 과도하게 사용한다.
- 데이터베이스가 자신의 책임을 방임하고 있는 상태.
따라서 위와 같은 조건은 DB가 수행해야 할 역할이 맞다.
@Query("""
SELECT new com.example.ChatRoomDto(
cr.name,
COUNT(m),
cr.type
)
FROM ChatRoom cr
LEFT JOIN cr.members m
WHERE cr.type = :type
GROUP BY cr.id
""")
List<ChatRoomDto> findRoomsByType(@Param("type") ChatType type);- 인덱스를 통한 빠른 필터링
- 필요한 컬럼만 선택적으로 조회
- 데이터베이스 엔진의 최적화된 집계 처리
- 비즈니스 로직은 필요한 데이터를 수신하기만 하면 되므로, RDB 규칙에서 자유로워짐.
📌 How to Determine a DTO?
지금까진 그저 "데이터 많으면, DTO로 분리하자" 정도로 사용했었다.
그러나 DTO를 사용했을 때 발생하는 가장 큰 문제는 영속성을 포기해야 한다는 점이다.
1️⃣ 우리는 왜 영속화를 하는가?
[DDD] Entity 에 대한 여러 이야기
목차 서론 entity 란 무엇인가 도메인 세상 이야기 vo 와 entity 가 있다 무엇이 entity 를 결정하는가? entity 의 속성 invariant immutable entity 의 행위 object autonomy self encapsulation 서론 DDD 에서는 유비쿼터스
wonit.tistory.com
이 내용을 어떻게 분석하고 연구해야 할까 고민하다가, 아래 블로그에서 인사이트를 얻을 수 있었다.
(내용 진짜 굿. 제가 전부 다룰 수 없으므로, 관심 있으면 읽어보시는 걸 추천합니다.)
- 영속화의 본질은 연속성에 있다.
- 어떤 객체가 가져야 하는 책임을 연속적으로 추적하고 관찰
- 임의의 시점에 핵심 객체에게 상태를 변경하라는 명령(command)을 했을 때, 그 행위는 가능한 영원히 연속적이어야만 한다.
- 이런 연속성을 위해선 수많은 객체들을 식별할 수 있어야 한다.
- 따라서 핵심 객체들에게 식별자를 할당하는 것이다.
- 이렇게 식별자를 할당받은 객체를 Entity라고 부른다.
- 현실적으로 영원히 Entity가 실행될 수 없는 상황을 안전하게 유지하기 위해, DB로 영속화라는 과정을 수행하는 것이다.
- 반면 이러한 역할을 수행하지 못하는, 그저 데이터 운송책의 역할을 수행하는 것이 DTO.
- 영속성은 "데이터를 저장한다"라는 의미를 넘어선다. 이는 객체의 생명주기와 정체성을 보장하는 행위다.
- Entity로서의 계좌는 거래 내역, 잔액 변동을 포함한 전체 생애주기를 추적한다.
- DTO로서의 계좌 정보는 특정 시점의 잔액이나 상태만을 나타낸다.
2️⃣ DTO의 특징
💡 DTO는 특정 순간의 "스냅샷"과 같다.
- 일시성(Transient Nature)
- DTO는 특정 시점의 데이터를 전달하는 것이 목적
- 스냅샷 자체는 보관할 필요가 없다. 필요할 때마다 새로 찍으면 그만.
- 문맥 의존성(Contextual Nature)
- DTO는 사용되는 맥락에 따라 다른 형태를 갖는다.
- 예를 들어, 목록에선 {이름, 이메일} 정보만 포함하고, 상세 페이지에서는 모든 정보가 필요할 수도 있다.
- 변환의 자유로움(Freedom of Transformation)
- Entity는 일관된 규칙에 따라 변경되어야 하지만, DTO는 필요에 따라 자유롭게 변형될 수 있다.
- 이는 Entity의 진실된 상태를 해치지 않으면서도, 다양한 표현을 가능하게 한다.
3️⃣ DTO를 결정하는 요소
💡 핵심 질문: "이 데이터는 단순히 현재 상태를 보여주기만 하면 되는가, 아니면 시간에 따른 연속성과 일관성이 필요한가?"
- DTO 사용을 결정할 때는 데이터 양이 아닌, 데이터의 성격을 보아야 한다.
- 단순히 조회가 목적인 Context에선, DTO를 사용하는 것이 효율적일 수 있다. (ex. 채팅방의 마지막 메시지 읽음 여부)
- 사용자가 언제 마지막으로 채팅방을 읽었는지를 보여주기만 하면 된다.
- 시간에 따른 변화를 추적할 필요가 존재하지 않는다.
- 다른 상태와의 일관성을 유지할 필요가 없다.
- 상태의 변경이 발생하는 경우, Domain을 사용해야 한다. (ex. 사용자가 채팅방에 새로운 메시지를 전송)
- 채팅방의 상태가 변경된다.
- 이 변경은 시간에 따라 추적이 되어야 한다.
- 다른 상태(참여자 목록, 메시지 순서 등)와 일관성이 유지되어야 한다.
📌 Business Logic
💡 데이터베이스는 단순한 데이터 저장소가 아닌, 도메인 모델의 영속성을 책임지는 인프라스트럭처다.
데이터베이스의 진정한 역할은 다음과 같다.
- 도메인 객체의 상태 보존
- 효율적인 데이터 접근 제공
- 데이터 무결성 보장
이는 단순히 기술적인 분리를 의미하는 것이 아닌, 도메인 개념의 순수성을 지키기 위한 원칙에 해당한다.
예를 들어, "활동 중인 사용자 정보를 조회한다"라는 비즈니스 규칙은 어떻게 구현해야 할까?
// 잘못된 접근: 비즈니스 로직이 쿼리에 포함됨
@Query("""
SELECT m FROM Member m
WHERE m.lastLoginAt > :threshold
AND m.status != 'BANNED'
""")
List<Member> findActiveMembers();
// 올바른 접근: 비즈니스 로직은 도메인 모델에
public class Member {
public boolean isActive() {
return !isBanned() &&
isRecentlyLoggedIn();
}
}- Query: "활동 중"이라는 비즈니스 규칙이 Query에 포함되어 있다.
- Application: 비즈니스 규칙을 도메인 영역에서 명시적으로 표현하고 있다.
- 원칙에 따르면 두 번째 방법이 올바르다.
- 필터링이 DB의 역할인 것은 맞지만, 단순히 "Id를 조건으로 필터링"과 같은 필터링이 아닌, "유효한 사용자 규칙"이라는 도메인 규칙에 따른 필터링이기 때문에 부적절하다.
🤔 정말 사소한 if문 조차 모두 애플리케이션에서 관리해야 하는 걸까?
💡 좋은 설계가 우선이며, 성능은 그 다음이다.
다시 언급하지만, 데이터베이스는 크게 두 가지 핵심적임 책임을 갖는다.
- 도메인 모델 상태를 안전하게 보관하고 복원
- 효율적인 데이터 접근 방법을 제공하는 것
문제는 위 두 책임은 시시때때로 충돌할 수 있다는 점이다.

바로 위에서 설명했던 "활동 중인 사용자 정보 조회"를 관리자 페이지에서 적용하기로 했는데, (활동 중인) 사용자 수가 1억 명이라고 가정하자.
(적절하지 않은 예시임에 동의한다. 일반적으로 관리자 페이지 기능을 핵심 비즈니스 영역이라 보긴 어렵기 때문이다.)
일반적으로 User 테이블은 상당히 많은 데이터를 가지고 있으며, 이 데이터를 1억 개 가져온다면 서버가 "난죽택"을 선언할 것이다.
따라서 도메인 규칙을 준수하기 위해, 여러 조건을 추가했음에도 많은 데이터를 불러와야 한다면 불합리하다고 느낄 수 있다.
여기선 선택을 해야만 한다.
- 성능을 위해 비즈니스 규칙을 SQL에 숨길 것인가?
- 아니면 도메인 규칙의 명확성을 위해 성능을 일부 희생할 것인가?
DDD 관점에선, 언제나 후자가 전자보다 우선 순위가 앞선다.
- 성능 문제는 추후 다른 방법(캐싱, 인덱싱, 배치 등)으로 해결할 수 있다.
- 숨겨진 비즈니스 규칙은 시스템이 커질 수록 유지보수를 어렵게 만든다.
- 하지만 애플리케이션에 모든 도메인 규칙이 포함되어 있다면, "이 사용자는 현재 시스템에서 활성화된 상태"라는 것이 코드에 명확하게 표현된다.
하지만 원칙과 이론의 가장 큰 문제는 현실과 동떨어져 있는 경우가 많다는 점이다.
그럴 땐, 아래의 trade-off를 고려해보면 좋을 거 같다.
| 데이터베이스 필터링 | 애플리케이션 필터링 | |
| 성능과 도메인 규칙 명확성 | 성능은 좋지만, 비즈니스 규칙이 쿼리에 침투함 | 규칙은 명확하지만, 불필요한 데이터가 전송될 우려가 있음 |
| 유지 보수성 | 조건이 복잡해질 수록 쿼리 복잡도 중가 | 도메인 객체의 상태와 규칙이 한 곳에서 관리 |
| 확장성 | 새로운 필터링 조건마다 쿼리 수정 필요 | 도메인 모델 수정으로 새로운 규칙 추가 가능 |
내가 실무 환경을 모르니 함부로 말은 할 수 없지만, 이런저런 곳에서 스타트업 이야기를 듣다보면 타협이 필요한 일은 반드시 존재할 것이라 생각한다.
내가 확언할 수 있다는 것은 도메인 규칙을 데이터베이스로 필터링하는 순간 유지/보수는 포기해야 할 정도로 복잡해진다는 점이다.
📊 예외적인 경우
여기서 예외적인 경우가 있는데, batch 서비스처럼 비즈니스 규칙에 얽매이지 않는 성격의 애플리케이션들이 존재한다.
이런 시스템의 본질은 "효율성"과 "성능"에 가장 큰 중요성을 두고 있으며, 애초에 domain-service 모듈을 의존하기 보다는 인프라 계층에 직접적으로 의존하는 방향으로 구현하는 경우가 많다.
이런 시스템은 어차피 핵심 비즈니스 로직에 영향을 주지 않기 때문에, SQL을 잘 활용하는 쪽으로 생각을 하는 게 더 나을 수도 있다.
📌 Is This Different Context?
같은 필터링 로직이라도, 사용되는 맥락에 따라 다르게 구현될 필요가 있으면 어떻게 해야 할까?
지금까지는 완전 무식하게 다음과 같이 구현했었다.
class DeviceTokenService {
// 활성화된 토큰만 조회
public List<DeviceToken> readActiveTokens() {...};
// 비활성화된 토큰 포함 모든 데이터 조회
public List<DeviceToken> readAllTokens() {...};
}그러나 Domain Model을 올바르게 이해한 개발자라면, 다음과 같이 처리했을 것이다.
난 왜 지금까지 Service에서만 디자인 패턴을 적용할 생각을 했을까..^^
Service처럼 Repository나 Domain Logic을 분리하는 방법을 취하는 것만으로도, 이번 고민은 아주 쉽게 해결할 수 있었다.
📌 Presentation Logic
-- ❌ 잘못된 예: 데이터베이스에서 표현 로직 처리
SELECT
CASE
WHEN deleted_at IS NULL THEN '활성'
ELSE CONCAT('삭제됨 (', FORMAT(deleted_at, '%Y-%m-%d'), ')')
END as status
FROM device_tokens;-- ✅ 올바른 예: 원시 데이터만 조회
SELECT token, deleted_at
FROM device_tokens;
// 표현 로직은 애플리케이션에서 처리
public String getFormattedStatus() {
if (deletedAt == null) {
return "활성";
}
return String.format("삭제됨 (%s)",
deletedAt.format(DateTimeFormatter.ISO_DATE));
}이건 간단한 내용이니까, 간단하게 설명하고 생략
- 표현 요구사항은 자주 변경된다.
- 국제화 처리가 어려워지고, 불필요한 연산을 DB가 수행해야 한다.
- 비즈니스 로직과 표현 로직이 섞이게 된다.
4. Designing Domain Relationship
📌 As-is
도메인 주도 설계에서 Entity 설계는 단순한 데이터 모델링을 넘어서는 핵심적인 결정 사안이다.
그러나 많은 스프링 개발자들이 JPA의 편리한 기능에 매료되어 Entity 관계 매핑에만 집중하곤 하지만, 이는 도메인 설계의 본질을 놓치는 것일 수도 있다.
이 글에선 내가 겪은 경험을 통해 올바른 관점에서 Entity를 설계하는 것은 무엇일지 살펴보려 한다.
💡 핵심 인사이트
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
• Entity 간 관계는 단순히 기술적 편의성이 아닌 도메인 규칙에 기반해야 한다.
• 같은 생명주기(lifecycle)를 가진 Entity들은 하나의 Aggregate로 묶어야 한다.
• 조회 패턴은 생명주기와 별개로 성능과 사용성을 고려해 결정할 수도 있다.
Spring Boot를 처음 배울 때, ORM의 개념을 배움과 동시에 객체를 통해 연관 관계를 쉽게 표현할 수 있다는 내용을 배운다.
그래서 나를 포함한 대부분의 사람들이 다음과 같이 연관 관계를 표현하고 있다.
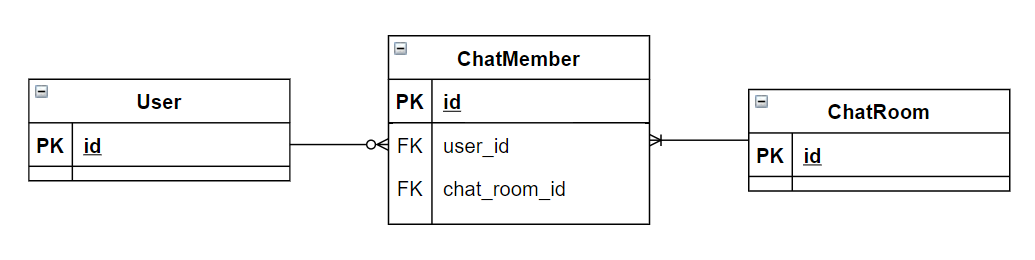
public ChatRoom {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
}
public ChatMember {
@Id
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id")
private User user;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "chat_room_id")
private ChatRoom chatRoom;
}그러나 언제나 이렇게 정의하는 것이 최선일까?
- MSA에선 아예 Aggregate별로 서비스를 분리해버려서 특정 Entity 참조 자체가 안 되는 경우가 있을 거 같은데, 이런 경우엔 어쩔 수 없이 기본 타입으로 참조할 것인가?
- JPA에서 @ManyToOne으로 참조가 가능한 것과 DDD는 관련이 없다. 그렇다면 올바른 접근 방법은 무엇일까?
물론, 객체 참조의 방식이 좋은 이유는 다음과 같은 객체 지향 방식의 프로그래밍을 사용할 수 있기 때문이다.
// 객체 참조를 사용하면 자연스러운 객체 탐색이 가능
chatMember.getUser().getName(); // 객체 지향적인 접근
// ID 참조는 추가 쿼리나 명시적인 조회가 필요
User user = userRepository.findById(chatMember.getUserId());
String name = user.getName(); // 절차적인 접근하지만 막상 이렇게 작성하는 경우가 드물다는 점이다.
- 실무에선 가급적 Lazy Loading 전략만을 사용한다는 이야기 때문에 언제나 추가 쿼리를 염두에 두어야 한다.
- 언제 Eager Loading 전략이 적절한 것인지 알 수 없으므로, N+1 문제가 날 것 같은 경우엔 항상 절차적 접근을 택할 수밖에 없게 되었다.
- N+1 문제를 우려하지 않아도 되는 건 `자식 → 부모` 패턴의 조회가 발생하는 경운데, 경험 상 대부분의 경우 `부모 → 자식` 순으로 조회가 발생해야 해서 의미가 없었다.
최근에 "User의 Device마다 ChatRoom별 마지막으로 읽은 메시지 아이디 정보"를 저장해야 할 필요가 생겼다.
이 데이터는 write-back & write-allocate 캐싱 전략을 통해 주기적으로 rdb에 저장되고 조회되는데, entity를 정의하다 보니 의문이 생겼다.
@Entity
@Getter
@Table(name = "chat_message_status",
uniqueConstraints = {
@UniqueConstraint(
name = "uk_chat_message_status",
columnNames = {"user_id", "chat_room_id"}
)
})
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class ChatMessageStatus {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Long userId;
private Long chatRoomId;
private Long lastReadMessageId;
private LocalDateTime updatedAt;
...
}- 위 도메인은 어떠한 경우에도 참조 대상인 user와 chatroom에 대한 join이 발생하지 않는다.
- 객체보단 Long으로 부모 테이블을 참조했을 때, 애플리케이션 관리가 훨씬 유용했다.
비록 발단은 기술적인 문제를 처리하다 생기긴 했지만, 모든 연관 관계를 객체로 표현해야 한다는 의문에 조금씩 균열이 가기 시작했다.
그렇다면 우리는 어떤 경우에 객체 참조를 해야 하고, 어떤 경우에 하지 말아야 하는 걸까?
아니 애초에 Entity는 어떻게 설계했어야 하는 걸까?
참고로 이번 챕터는 다음과 같은 흐름으로 진행된다.
- Bounded Context 설계는 전략적 결정이다.
- 라이프사이클
- 조회 패턴
- DDD 방식으로 DB 테이블을 설계했다면?
📌 Bounded Context Is a Strategic Decision
DDD 핵심만 빠르게 이해하기
마이크로서비스의 설계 방법론인 DDD(Domain Driven Design)에 대해 제가 가진 지식과 그간의 경험을 기반으로 정리하였습니다. 이 글을 읽기 전에 먼저 일하는 방식 변화를 이끌고 있는 애자일, 마이
happycloud-lee.tistory.com
(위 포스팅을 정말 많이 참고했습니다. 내용이 너무 좋아서, 꼭 읽어보시는 걸 추천합니다.)
Entity를 설계할 때 가장 어려운 것은 "서비스를 어떻게 나눌 것인가?"에 대한 대답이다.
이는 단순히 기능을 분리하는 것이 아닌, 비즈니스 도메인을 이해하고 그 경계를 명확히 할 줄 알아야 하기 때문이다.
DDD에서 말하는 Bounded Context가 바로 이러한 경계를 말한다.
1️⃣ Bounded Context란?
[인증 Context]
- 사용자 = 보안 주체
- 중요 속성: 이메일, 비밀번호, 권한
[결제 Context]
- 사용자 = 거래 주체
- 중요 속성: 결제수단, 거래내역, 신용등급
[채팅 Context]
- 사용자 = 대화 참여자
- 중요 속성: 온라인상태, 프로필, 차단목록- 특정 도메인 모델이 적용되는 명시적 경계
- 같은 용어라도 Context에 따라 다른 의미를 가질 수 있다.
- 예를 들어, 위 예시처럼 "사용자"는 각 Context에서 서로 다른 의미와 속성을 갖는다. 따라서 동일한 용어라도 다른 모델링을 필요로 한다.
2️⃣ 왜 Context를 나눠야 하는가?
Context를 나누지 않으면, 다음과 같은 문제가 발생할 수 있다.
- 모델의 모호성
- 동일한 용어가 여러 의미로 사용되어 혼란이 발생할 수 있다.
- ex) "상태"가 계정 상태인지, 온라인 상태를 의미하는 건지
- 변경의 어려움
- 한 기능의 변경이 의도치 않게 다른 기능에 영향을 미칠 수 있다.
- ex) 결제 로직 변경이 인증 로직에 영향을 미침
- 확장성 제한
- 새로운 요구사항 추가가 기존 로직을 복잡하게 만들 수 있다.
- ex) 소셜 로그인 추가가 전체 사용자 모델의 변경을 필요
3️⃣ Context 경계를 어떻게 결정하는가?
- 업무적 응집도
- 동일한 비즈니스 규칙을 공유하는가?
- 같은 이해 관계자가 관리하는가?
- 데이터 사용 패턴
- 함께 조회되고 수정되는 데이터는 무엇인가?
- 트랜잭션의 범위는 어디까지인가?
- 변경의 빈도와 영향
- 어떤 기능들이 함께 변경되어야 하는가?
- 변경이 다른 기능에 영향을 주는가?
4️⃣ Context 간 협력 패턴
- Shared Kernel (공유 커널)
- 여러 Context가 공유하는 핵심 모델
- ex) 공통 코드, 기본 규칙
- Customer-Supplier
- 상류(제공자)-하류(사용자) 관계
- ex) 인증 Context → 결제 Context
- Anti-Corruption Layer
- 외부 모델을 내부 모델로 변환하는 계층
- ex) 레거시 시스템 연동 시 사용
하지만 이것만으로는 여전히 Entity를 어떻게 분리해야 할 지 상당히 모호하다.
그럴 때는 Entity들의 생명 주기를 고려해보면 어떨까?
📌 Lifecycle
💡 Entity들의 상태가 항상 동시에 업데이트가 되어야 하는가? 잠시라도 불일치가 허용되는가?
도메인 주도 설계와 MSA: 라이프 사이클을 기준으로 한 도메인 분리
이 글에서는 도메인 주도 설계와 MSA를 라이프 사이클을 기준으로 도메인을 분리하는 방법에 대해 설명합니다. 이를 통해 복잡한 시스템을 효율적으로 관리하고, 유지보수성을 높일 수 있습니다
f-lab.kr
(이번엔 f-lab 기술 블로그를 참조했습니다.)
1️⃣ 서로 다른 두 Entity
JPA로 처음 개발을 시작하면, 대부분 다음과 같이 시작한다.
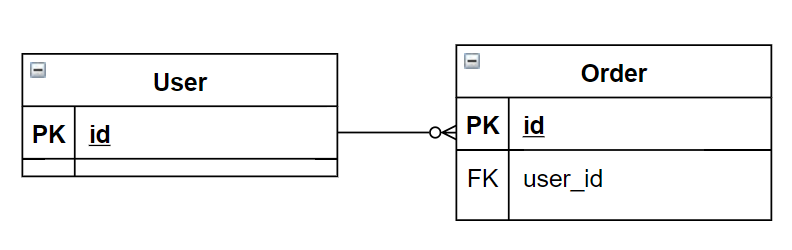
@Entity
public class Order {
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id")
private User user;
// 주문과 관련된 모든 정보가 User와 함께 관리됨
}주문은 사용자와 관련이 있으므로, 위 방식은 전혀 문제가 없어 보인다.
하지만 정말 그럴까?
실은 주문(Order)과 사용자(User)는 서로 다른 생명주기를 가질 수 있다.
- 사용자가 탈퇴하면 주문 내역은 어떻게 되는가?
- 주문 이력을 완전히 삭제?
- "탈퇴한 사용자"로 표시?
- 주문 데이터는 그대로 두고 사용자 정보만 마스킹?
이를 결정하는 요소는 기술이 아닌 서비스를 운영하는 국가의 법과 사내 규칙에 의해 결정된다.
그리고 이러한 규칙에 따라 두 Entity의 생명주기가 다르기 때문에 고민이 생기기 시작한다.
| 👤 User | 📝 Order | |
| 데이터 보존 | 탈퇴 시 삭제 필요 | 장기 보관 필요 |
| 법적 요구사항 | 개인정보보호법 | 전자상거래법 |
| 변경 주기 | 수시 변경 가능 | 생성 후 거의 불변 |
이러한 경우 두 Entity는 서로 다른 Context로 분리하는 것이 옳지 않았을까?
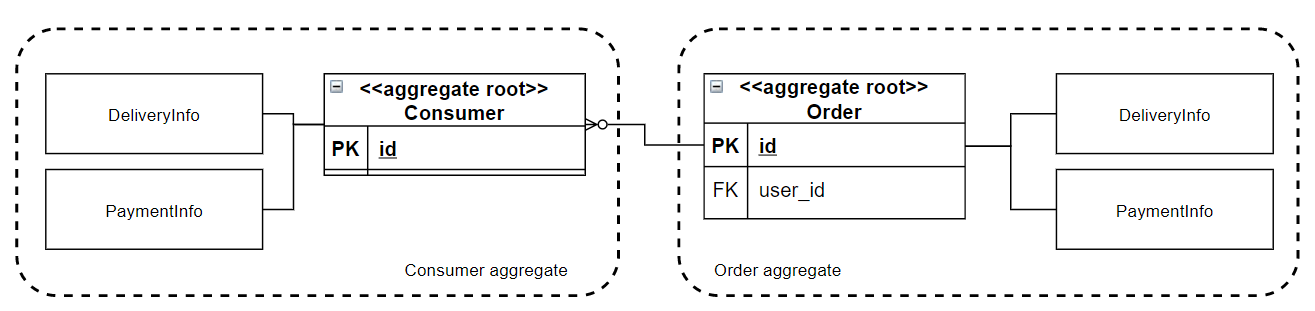
처음에 소개한 포스팅의 `8) Event storming - Step6. Aggregate 정의 - Aggregate 규칙: RPO`를 확인해보면, 이런 내용이 적혀있다.

@Entity
public class Order {
private Long userId; // ID만 참조
}
💡 생명주기 결정 시 고민해보면 좋을 내용 (개인적인 생각)
• 서로 다른 두 Entity가 언제나 함께 생성되는가?
• 하나가 삭제될 때 다른 하나도 삭제되어야 하는가?
• 데이터 보관 기간이 동일한가?
• 트랜잭션이 언제나 함께 일어나야 하는가?
모든 질문에 "Yes"라면 같은 Context에 포함하고, "No"가 하나라도 있다면 느슨한 결합을 고려해봄직 하다.
2️⃣ 단일 Entity
테이블을 설계해보면, 언제나 가장 방대한 양의 컬럼을 가지고 있는 것은 User 테이블이 된다.
아이디, 이메일, 비밀번호부터 계좌, 별명, 온라인 상태, 밴 여부 등 온갖 데이터를 다 가지고 있고,
이로 인해, 거의 모든 테이블이 User 테이블에 얽히게 됨으로써, 도저히 분리가 안 되는 Entity 설계를 가지게 되는 경우가 허다하다.
그럼 이런 User Entity 또한 Context에 따라 분리할 수 있지 않을까?
User 테이블에 다음과 같은 정보들이 담겨 있다고 가정하자
// 인증 도메인의 User
public class AuthUser {
private Long id;
private String email; // 이메일
private String name; // 실명
private String username; // 서비스 전체에서 사용할 닉네임
private String password; // 인증에 필수적인 정보
private String phoneNumber; // 2FA 등에 사용
private BankAccount account; // 지출 관리에 필요한 정보
private MonthlyBudget budget; // 지출 관리에 특화된 정보
private String nickname; // 채팅에서 사용할 닉네임
private OnlineStatus status; // 온라인 상태
private List<BlockedUser> blocks; // 차단 목록
}
나는 평소 이런 테이블을 분리하기 위한 기준을 다음과 같이 책정한다.
(내가 만들고 있는 서비스를 기준으로 작성했다. 사용자는 아이디/패스워드 혹은 OAuth 로그인이 가능하며, 서비스는 지출 관리, 피드, 채팅 기능을 제공한다.)
- 정보 변경 주기
- 사용자 분석에 따르면 비밀번호, 이메일은 거의 변경되지 않으며, Oauth 기능을 제공하는 경우 사용하는 일이 드물다.
- 반면 채팅 온라인 상태는 매우 빈번하게 변경이 발생한다.
- 사용자가 계정 탈퇴를 할 시, 민감한 데이터는 모두 마스킹 처리를 해야만 하나, 그러지 않아도 되는 정보 또한 존재한다.
- 변경 주기가 다르다면, 분리를 고려해볼 수 있다.
- 정보 응집도
- 지출 관리에 필요한 은행 계좌 정보는 채팅이나 피드 도메인과 관련이 없다.
- 온라인 상태 또한 지출 관리와는 관련이 없다.
- 함께 변경되는 경향이 있는 데이터들을 분리하여 응집도를 높이는 것이 좋다.
- 도메인 자율성
- 채팅 시스템은 사용자 온라인 상태를 자유롭게 관리해야 한다.
- 만약 이를 중앙화된 User 테이블에서 관리하면 유연성이 저하될 수 있다.
// 인증 도메인의 User
public class User {
private Long id;
private String email;
private Long username; // 서비스 전체에서 사용할 닉네임
private String password; // 인증에 필수적인 정보
private String phoneNumber; // 2FA 등에 사용
}
// 지출 관리 도메인의 User
public class ExpenseUser {
private Long id;
private String name; // 실명
private BankAccount account; // 지출 관리에 필요한 정보
private MonthlyBudget budget; // 지출 관리에 특화된 정보
}
// 채팅 도메인의 User
public class ChatMember {
private Long id;
private String nickname; // 채팅에서 사용할 닉네임
private OnlineStatus status; // 온라인 상태
private List<BlockedUser> blocks; // 차단 목록
}이렇게 설계하면,
- 공통된 사용자 정보는 중앙에서 관리할 수 있다.
- 각 Domain에 특화된 정보는 독립적으로 관리하고 발전시킬 수 있다.
Lifecycle을 기준으로 Bounded Context를 이해하고, 잘 설계했다면 이제 코드에 반영할 일이 남았다.
다른 Aggregate의 Entity를 참조할 때는 객체보단 pk를 참조하면 되겠지만, 여전히 한 가지 의문이 남아 있다.
같은 Context 내의 Entity들은 어떻게 할 것인가?
📌 Retrieval Pattern
🤔 같은 Context 내에서는 Lazy Loading을 할 일이 거의 존재하질 않는다?
어디선가 위의 주장을 하는 내용을 본 적이 있다.
같은 lifecycle을 갖는 Entity를 매핑했다면, 한 가지 의문이 들 수 있을 것이다.
만약, 정말 잘 분리된 상태(각각의 Entity가 명확한 책임과 생명주기를 가지며, 다른 Entity와의 관계가 명확한 경우)라면 Context 내의 Entity들은 높은 확률로 함께 조회되어야 할 일이 많을 것이다.
public class Order {
@OneToMany(fetch = FetchType.LAZY)
private List<OrderItem> orderItems;
@ManyToOne(fetch = FetchType.LAZY)
private DeliveryAddress address;
}- 주문 항목 없이 주문을 처리할 수 있는가?
- 배송 주소 없이 주문을 처리할 수 있는가?
대부분의 경우에 불가능할 것이다.
왜냐하면, 주문, 주문 항목, 배송 주소는 하나의 완결된 개념을 구성하고 있기 때문이다.
- 같은 Aggregate 내의 Entity들은 하나의 트랜잭션 단위로 움직인다.
- 함께 생성되고, 함께 수정되어야 한다.
- 이것이 높은 응집도의 정의이기 때문이다.
하지만 여기서 중요한 점은 규모와 조회 패턴이다.
주문 항목이 2-3개일 때와 수천 개일 때는 상황이 많이 다르다.
그리고 수천 개의 데이터가 반드시 필요한 경우도 드물다.
또한 생명주기 관점에서의 "함께"와 조회 관점에서의 "함께"는 다른 의미를 내포할 수도 있다.
1️⃣ 규모의 관점
예를 들어, 대형 마켓플레이스의 판매자 주문 관리 시스템을 구상해보자.
public class SellerOrder {
@OneToMany(fetch = FetchType.LAZY)
private List<OrderItem> orderItems; // 수천 개일 수 있습니다
@OneToMany(fetch = FetchType.LAZY)
private List<OrderStatusHistory> statusHistory; // 많은 이력이 쌓일 수 있습니다
// 주문 목록 조회시에는 기본 정보만 필요할 수 있다.
public OrderSummaryView toSummary() {
return new OrderSummaryView(
this.id,
this.totalAmount,
this.status
);
}
// 상세 조회시에만 모든 정보가 필요할 수 있습니다
public OrderDetailView toDetail() {
return new OrderDetailView(
this.id,
this.orderItems, // 여기서 lazy loading 발생
this.statusHistory // 여기서 lazy loading 발생
);
}
}이런 경우엔 같은 컨텍스트 안에 있더라도 lazy loading이 필요할 수 있다.
따라서 이 주장은 다음과 같이 수정되는 것이 옳지 않을까?
같은 Bounded Context 내의 Entity들은 대부분 함께 사용되어야 하지만, 데이터의 규모나 성능 요구사항에 따라 예외가 있을 수 있다.
만약 Lazy Loading이 필요한 상황이라면, 그것이 성능 상의 이유 때문인지, 잘못된 경계 설정 때문인지, 혹은 도메인 규칙 때문인지를 고려해봐야 한다.
2️⃣ 조회 패턴의 관점
public class Order {
private List<OrderItem> items;
private DeliveryAddress address;
private PaymentInfo paymentInfo;
}
- 생명주기 관점
- 주문이 생성될 때 주문 항목들도 반드시 함께 생성되어야 한다.
- 주문이 취소되면 주문 항목들도 함께 취소 상태가 되어야 한다.
- 배송지 정보도 주문과 함께 생성되고 관리되어야 한다.
- 조회 관점
- 주문 목록에서는 주문 기본 정보만 필요할 수도 있다.
- 결제 처리를 수행할 때는 결제 정보만 필요할 수도 있다.
- 배송 처리 시에는 배송지 정보만 필요할 수도 있다.
비록 같은 Aggregate 내의 Entity들은 일관된 생명 주기로 관리되어야 하지만, 조회는 상황과 맥락에 따라 유연하게 결정될 수도 있다.
중요한건 "반드시 함께 조회되어야 하는가?"보단 "함께 조회되어도 문제가 없는가?"를 고려하는 것이 낫지 않을까 싶다.
(사실 이런 관점에서 보면, Order의 수정이 발생한다고 반드시 items, address, paymentInfo 모두에 수정이 전파되지도 않을 텐데, 무작정 Eager 전략을 사용하는 게 정말 옳은가 싶다.)
DDD 적용시 JPA 설계에 대해 궁금한 사항 - 인프런 | 커뮤니티 질문&답변
누구나 함께하는 인프런 커뮤니티. 모르면 묻고, 해답을 찾아보세요.
www.inflearn.com
이에 대해 김영한님(또 당신입니까?)의 답변이 있는데, 이것도 참고해보면 좋다.
📌 What If the Database Were Designed Using the DDD Method?
마지막으로 As-is 파트에서 고민했던 내용과 글을 작성하면서 추가로 든 의문을 하나 더 정리해보려 한다.
- "User의 Device마다 ChatRoom별 마지막으로 읽은 메시지 아이디 정보"를 객체가 아닌 pk 방식의 참조가 도메인 관점에서 어떠한지
- 다른 aggregate root를 갖지만 변경이 전파되는 경우는 무엇인지
1️⃣ 현재 구현된 ChatMessageStatus Entity를 DDD 관점에서 바라보기
@Entity
public class ChatMessageStatus {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Long userId;
private Long chatRoomId;
private Long lastReadMessageId;
private LocalDateTime updatedAt;
...
}우선 위와 같이 user를 객체 타입이 아닌 PK를 통한 참조는 잘 했지만, 다른 부분에서 문제가 발생했다.
이를 다이어그램을 통해 알아보자.
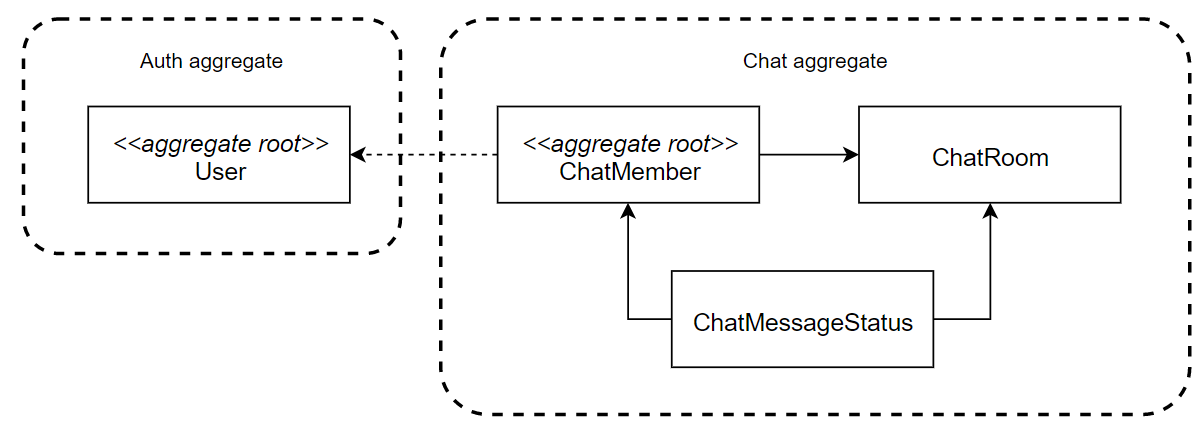
(ChatMember를 aggregate root로 잡는 것이 올바른 건지 모르겠다. "누가 전체 규칙을 관리할 것인가?"라는 관점에서 보면 ChatRoom 되는 것이 올바르다고 생각하지만, 그렇게 되면 aggregate root가 아닌 table(ChatMember)이 다른 aggregate root를 참조하는 이상한 현상이 발생한다.)
- User와 ChatMessageStatus는 별개의 aggregate에 속해있으므로, 객체 타입보다는 pk를 사용하는 것이 올바르다.
- 그러나 애초에 aggregate root가 아닌 ChatMessageStatus가 참조해야 하는 대상은 User가 아닌 ChatMember여야 올바른 Entity 분리라고 볼 수 있다.
- 오히려 User를 객체 타입으로 참조하는 ChatMember를 pk 타입 참조로 수정해야 한다.
- ChatMessageStatus는 인프라 관점에서 보았을 때 API가 아닌, Socket을 위한 데이터에 가까운데, 어쩌면 이 또한 다른 aggregate root로 분리하는 것이 적절했을 수도 있다.
- 라이프사이클 관점에서 보았을 때, ChatMessageStatus는 ChatMember의 데이터가 삭제되기 전까지만 유효하다. 이런 관점에서 보면 묶는 게 더 적절한데...DDD 어렵다 진짜 😂
여기서 문제가 발생한 지점은 ChatRoom의 aggregate root 여부와 ChatMessageStatus의 Context 위치에 대한 이야기다.
- 해결된 문제
- User와의 관계가 필요할 때는 PK 참조로 충분하다.
- ChatMessageStatus는 User가 아닌 ChatMember를 참조했어야 한다.
- 해결해야 할 과제
- ChatRoom의 일관성을 누가 관리할 것인가?
- ChatMember 간의 상호작용을 어떻게 구현할 것인가?
해결해야 할 과제를 조금만 더 설명해보자면 이런 내용이다.
// 첫째, ChatRoom이 Aggregate Root가 아닐 때 발생하는 문제
public class ChatMember {
private Role role; // 관리자인지 여부
public void promoteToAdmin() {
// 다른 관리자가 있는지 어떻게 확인?
// 채팅방의 정책을 어떻게 검증?
this.role = Role.ADMIN;
}
}
// 둘째, ChatMessageStatus가 Chat aggregate에 속했을 때의 문제
public class ChatMessageStatus {
private Long chatMemberId; // ChatMember를 참조하도록 수정
private Long deviceId;
private Long lastReadMessageId;
// 이렇게 하면 ChatMember가 삭제될 때 자연스럽게 함께 삭제
// 하지만 여전히 ChatRoom의 정보가 필요할 수 있음.
}
초기에 ChatMember를 Aggregate Root로 선택한 이유는 다음과 같다.
- 채팅방에서의 사용자의 모든 상태와 행위를 관리
- 메시지 읽음 상태와 같은 사용자별 데이터의 일관성 책임
- 사용자의 채팅방 내 활동을 캡슐화
하지만 이 과정에서 위의 두 가지 의문들과 충돌이 발생하기 시작했다.
지금은 이 주제에 대해 다룰 짬밥이 없는 터라, 일단 스스로에게 주는 과제라고 생각하고 패스 🏃♂️➡️ (돔황챠~)
2️⃣ 다른 Aggregate에 의해 변경의 영향이 전파되는 경우
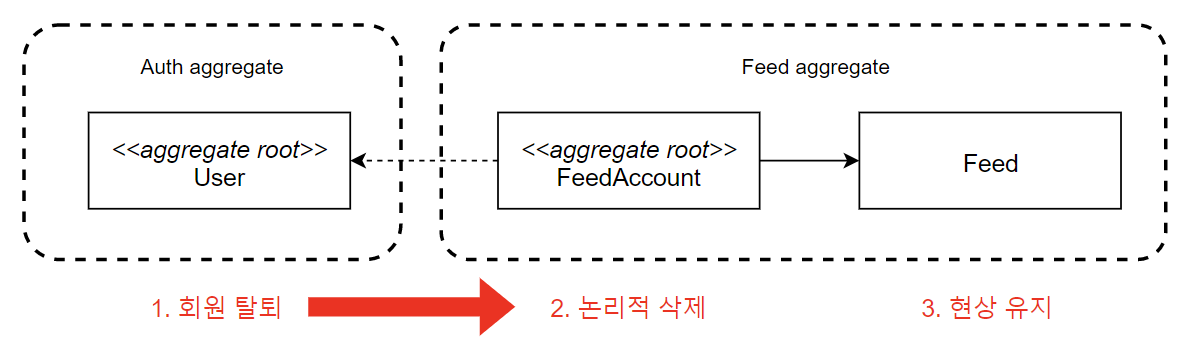
Bounded Context 개념에 따르면, 같은 생명 주기를 갖는 Entity는 같은 Aggregate에 속해야 한다.
그러나 "회원 탈퇴"의 경우는 어떠한가? (여기서 User 데이터는 물리적으로 삭제된다는 전제를 둔다.)
이 파급력이 큰 행위는 거의 모든 Aggregate Root에 영향을 전파한다.
그렇다면 이는 User와 같은 Lifecycle을 공유하는 강한 결합으로 보아야 하지 않은가?
어째서 이를 분리해도 된다고 보는 걸까?
여기엔 중요한 차이점들이 존재한다.
🟡 데이터의 의미 차이
public class User {
private Long id;
private String email; // 개인정보
private String password; // 인증 정보
public void delete() {
// 완전히 삭제되어야 함 (개인정보 보호법)
}
}
public class FeedAccount {
private Long id;
private Long userId;
private LocalDateTime deletedAt; // 논리적 삭제 상태
private String nickname; // 피드에서 사용하는 표시명
public void markAsDeleted() {
this.deletedAt = LocalDateTime.NOW;
// 하지만 데이터는 남아있음
// 예: "탈퇴한 사용자"로 표시
}
}
🟡 상태 변경 의미의 차이
- User의 삭제는 개인정보 보호를 위한 완전한 제거
- FeedAccount의 삭제는 단지 표시 방식의 변경에 불과
🟡 후처리 방식 차이
// Auth Domain
public class AuthService {
public void deleteUser(Long userId) {
User user = userRepository.findById(userId);
userRepository.delete(user); // 물리적 삭제
eventPublisher.publish(new UserDeletedEvent(userId));
}
}
// Feed Domain
public class FeedService {
@EventListener
public void handleUserDeleted(UserDeletedEvent event) {
FeedAccount account = feedAccountRepository.findByUserId(event.getUserId());
account.markAsDeleted(); // 논리적 삭제
// Feed들은 그대로 유지
}
}
이러한 관점에서 봤을 때, 두 Entity가 별개의 Aggregate로 분리되어야 하는 이유는 다음과 같다.
- 자율성
- User: 개인정보 보호법에 따른 삭제 정책
- FeedAccount: 서비스의 데이터 정합성을 위한 보존 정책
- 각자 다른 비즈니스 규칙을 따름.
- 일관성
- User가 삭제되어도 Feed의 맥락은 보존되어야 함.
- FeedAccount는 Feed들과의 관계를 위해 존재
- 즉, FeedAccount는 User보다 Feed와 더 강한 결합을 가짐.
- 진화 가능성
- User와 FeedAccount의 수정은 서로 독립적으로 발생할 수 있으며, 그렇게 되어야 함.
5. Conclusion
📌 도메인 중심 설계로 나아가
지금까지 우리는 도메인 주도 설계 관점(과 기술 관점을 한데 섞어버린)에서 서비스 아키텍처의 여러 측면들을 살펴보았다.
처음에는 단순히 기술적으로 접근했던 방식들을 깊게 파고 들어갈수록, 모든 결정의 중심에는 도메인이 있어야 한다는 것을 깨달았다.
도메인 서비스를 구조화할 때, 우리는 종종 기술적 제약에 얽매여 도메인의 본질을 놓치곤 한다.
"채팅방 입장"이라는 하나의 자연스러운 행위를 "확인"과 "실행"으로 나누려했던 것처럼.
그러나 이럴 때일 수록 개발자가 아닌, 비개발자의 시선에서 바라보아야 한다.
그래야 비로소 이 행위는 하나로 통합된 개념이어야 한다는 것을 알 수 있게 된다.
도메인 레포지토리를 설계할 때도 마찬가지다.
단순히 "어디서 필터링하는 것이 성능상 유리한가"가 아닌,
"이 로직이 도메인의 본질적인 규칙인가, 아니면 단순한 데이터 접근 패턴인가"를 고려해야 한다.
때로는 성능을 일부 희생해서라도, 올바른 설계를 통해 도메인 규칙의 명확성을 선택해야 할 수도 있다.
Entity의 관계를 설계할 때는 더욱 신중해야 한다.
JPA가 제공하는 편리한 관계 매핑 기능들에 매료되어, 모든 연관 관계를 객체 참조로 표현하려는 유혹에 빠지곤 한다.
하지만 진정한 도메인 모델링은 각 Entity의 생명주기와 책임을 고려해야 한다.
예를 들어, 사용자가 탈퇴할 때 주문 내역은 어떻게 될지, 채팅방의 메시지 상태는 어떻게 관리될지와 같은 도메인의 핵심 규칙들이 설계를 주도해야만 한다.
이러한 고민들을 통해 알게된 핵심 원칙들을 정리하자면 다음과 같다.
- 도메인 중심 사고
- 기술적 제약이나 편의성이 아닌, 도메인 규칙과 개념이 설계를 이끌어야 한다.
- "할 수 있는가?"가 아닌 "해야 하는가?"를 먼저 고민하고, 여기에 기술을 접목해야 한다.
- 명확한 경계 설정
- Bounded Context는 단순한 기능 분리가 아닌, 도메인 개념의 명확한 구분에 해당한다.
- 각 Context는 자신만의 규칙과 생명주기를 가져야 한다.
- 일관된 설계 원칙
- 성능과 도메인 규칙 사이에서는 항상 도메인 규칙을 우선시 해야 한다.
- 성능 최적화는 다른 방법으로 달성할 수 있지만, 잃어버린 도메인의 의미는 되찾기가 매우 힘들다.
- 유연한 구현 전략
- 같은 Context 내에서도 데이터의 규모와 사용 패턴에 따라 구현 전략은 달라질 수 있다.
- 하지만 이러한 결정은 항상 도메인 규칙을 해치지 않는 선에서 이루어져야 한다.
마지막으로 가장 중요한 것은, 이 모든 결정에 정답이 없다는 점이다.
우리가 할 수 있는 것은 그저 도메인을 깊이 이해하고, 그 이해를 바탕으로 최선의 판단을 내리는 것 뿐이다.
때로는 현실적인 제약과 타협해야 할 수 있지만, 그러한 상황에서도 우리는 도메인의 본질을 잃지 않도록 주의해야 한다.
도메인 주도 설계는 쉽지 않은 여정이다. (이렇게까지 했는데 여전히 모르는 게 더 많다. 아니 오히려 더 모르겠다. ㅋㅋㅋㅋ)
하지만 이러한 여정이 거듭해서 누적되었을 때, 지금까지 공부했던 다양한 도구와 방법론들이 DDD라는 이름 하나로 연결되는 깨달음이 주어질 것이다.
도메인의 언어로 이야기하고, 도메인 규칙으로 설계하는 것.
이것이 앞으로 내가 그리고 많은 개발자들이 나아가야 할 길이라고 생각한다.