📕 목차
1. Introduction
2. UUID
3. ULID
4. TSID
5. KSUID
6. Twitter Snowflake
7. Non Cryptographic ID
8. Performance Evaluation
1. Introduction
📌 계기
[Spring Boot] WebSocket + RabbitMQ를 활용하여 채팅 시스템 구축하기 (with. STOMP)
🫠 포스팅 길이가 길어지면 임시 저장 데이터가 자꾸 날아가버려서, 점진적으로 내용 추가 중입니다.수정 일자내용`24.09.15• System Design• Message pub/sub• Proxy Server Routing`24.09.19• Authenticate (작성
jaeseo0519.tistory.com
엄청나게 길어지고 있는 채팅 시스템 개발 포스팅을 하다가, 드디어 유일 ID 생성 전략 파트로 넘어왔다.
처음엔 단순하게 ULID 쓰면 되니까 짧게 치고 끝낼 생각이었는데, 내 예상보다 엄청나게 많고 다양한 방법들이 존재했다.
[대규모 시스템 설계] 7장. 분산 시스템을 위한 유일 ID 생성기 설계
📕 목차1. 유일 ID 생성기2. 개략적 설계3. 상세 설계1. 유일 ID 생성기 📌 auto_increment는 답이 될 수 있을까?DB가 단일 서버라면 auto_increment가 답이 될 수 있다.하지만 사용자 트래픽이 높은 곳이라
jaeseo0519.tistory.com
계기는 대규모 시스템 설계 책을 읽다가 알게되긴 했는데, 개인적으로 추가적인 성능 비교와 각 전략들의 장/단점들을 분석해보고 싶어져서 작성하게 되었다.
그리고 추가적인 조건들이 더해졌는데, 매번 테스트를 위해 spring 프로젝트를 만드는 게 옳은지 의문이 들었었다.
의존성 주입과 다양한 기능들을 제공해주니 사용하긴 했는데, 너무 프레임 워크 의존적인 개발만 하다보니 개발자로서 역량이 너무 저하된 느낌이라 항상 불쾌했다.
그래서 이번엔 Java와 Gradle, JUnit을 기반으로 측정하고, Spring Boot는 사용하지 않을 생각이다.
또한 결과는 하나하나 엑셀로 옮겨담는 것이 아니라, 테스트가 끝나면 알아서 표를 그리도록 하는 것까지 목표로 두고 있다.
(그런데 하다가 현타와서 클로드한테 맡겼더니 전부 작성해줌. 인간 시대의 종말까진 안 왔지만, 내 커리어 종말은 눈 앞에 다가왔다.)
📌 Auto Increment PK
역사적으로 sw가 특정 데이터 식별자를 나타내기 위해 증가하는 숫자(numeric)를 사용했다.
이는 많은 DB에서 자동 생성 가능하며, 추론이 쉽고, 저장 및 정렬이 효율적이면서, 자연스럽게 시간 순서가 지정되고, 인간친화적이기 때문이다.
이러한 데이터의 고유 ID를 생성하는 방법 중, RDB에서도 MySQL을 사용하면 auto_increment 속성을 제공하는 방법이 가장 널리 알려져있다.
작은 규모의 서비스를 개발하면서 놀 때는 아무런 문제가 되지 않지만, 개발을 하면서 점점 의문이 생기는 점들이 나타나게 된다.
1️⃣ 데이터가 방대한 테이블이라면?
| Type | Byte | Signed Value | Unsigned Value |
| INT | 4 | -2,147,483,647 ~ 2,147,483,647 | 0 ~ 4,294,967,295 |
| BITINT | 8 | -2^63 ~ 2^63-1 | 0 ~ 2^64-1 |
id에 음수를 사용하는 경우는 거의 없기 때문에, 테이블에 42억 개의 데이터가 들어갈 일이 전혀 없다면 BIGINT를 사용할 일이 없다.
설령 그보다 많아진다 하더라도, unsigned bigint 타입을 사용하면 이 값을 넘길 일은 극히 드물어질 것이다.
하지만 이건 내 얘기일 뿐이고, 구글이나 마이크로소프트, 아마존 같이 글로벌 시장에서 막대한 영향력을 끼치는 기업들은 어떨까?
사용자 정보가 2^64-1을 넘어갈 일은 없을 것이다.
한 명이 4~5개의 계정을 만드는 것을 허용한다 해도, 세계은행 자료 조사에 의한 2022년 기준 지구 인구 수는 79.51억 명.
그 사이 사람이 새로 죽고 태어남을 고려해도, 현재로썬 18경에 달하는 표현 범위를 넘어서진 못 할 것이기 때문이다.
하지만 사용자의 행동 데이터라면 어떠한가?
사용자가 작성한 포스트 데이터, 댓글, 포스트와 댓글에 누적된 좋아요 데이터, 혹은 매우 방대한 양의 채팅 수를 고려한다면, 어쩌면 가능하지 않을까? (내가 18경이라는 수를 너무 만만하게 본 걸 수도)
그러나 하나의 데이터베이스에 18경 개의 데이터를 모두 담으려면, 상당한 up-scaling 비용이 들 텐데 이렇게 하진 않을 듯.
2️⃣ RDBMS를 사용하기 적합하지 않은 조건이라면?

auto_increment를 사용한다고 하면, 반드시 RDBMS를 사용함을 전제로 두어야 한다.
그러나 채팅 시스템을 생각해보면, 이게 과연 적절할까? (아래에서도 계속 채팅 시스템을 예시로 들 것)
DAU가 극히 적은 서비스라면 문제가 없을 수도 있겠지만,
채팅 시스템은 기본적으로 real-time 서비스로 제공되고, 소수의 사용자가 방대한 양의 데이터를 순식간에 만들어 낼 수 있다는 특수성이 존재한다.
여기서 메시지 전달이 딜레이되면, 사용자 경험이 저하되면서 사용자 이탈율 증가라는 결과를 낳을 수도 있다.
문제는 이런 방대한 양의 데이터를 매번 RDBMS에 때려넣으려고 하면, 두 가지 관점에서 문제가 발생한다.
- RDBMS에 너무 많은 트래픽이 몰리게 되어, DB가 죽을 수도 있다.
- 심지어 DB가 하나밖에 없다면, SPoF로 작용하여 전체 서비스가 마비된다.
- RDBMS까지 요청이 오고 가는 것은 너무 느리다. 문제는 트래픽이 몰리면서, 이런 현상이 더 심해질 수 있다.
따라서 NoSQL을 사용하여 채팅 데이터를 저장하는 것이 합리적이라고 볼 수 있지만, 그렇게 되면 auto_increment를 사용할 수 없다.
3️⃣ 분산 시스템 환경이라면?

가장 심각한 문제는 auto_increment가 언제나 고유한 ID를 만들어내지 못 하는 경우가 존재할 수 있다는 점이다.
왼쪽의 경우, 샤딩된 DB가 하나 존재하고, N개의 서버가 채팅 데이터를 저장하는 경우다.
master가 하나라면 문제가 되지 않겠지만, 다중 마스터 복제(mult-master replication)라면 중복 ID가 생길 우려가 있다.
여기서 이야기한 내용이므로 pass
오른쪽의 경우엔 Region마다 데이터 센터를 아예 따로 배치한 경우다.
미국에도 서비스할 건데, 한국의 서버를 사용하게 하면 사용자 경험이 너무 저하될 수 있으니, 데이터 센터를 물리적으로 가까운 곳에 위치하게 만든 셈이다.
그런데 이렇게하면 무슨 수로 auto_increment로 생성한 ID의 고유성을 보장할 것인가?
데이터 센터마다 사용 가능한 ID의 범위를 할당하는 등의 방식을 사용하면 해결은 가능하겠지만, 확장성에 상당한 제약이 생길 수 있다.
그렇다고 모든 데이터 센터의 채팅 이력 ID를 동기화하는 전략 또한 상당히 어렵고 복잡한 해결책이 될 수 있다.
✒️ DB를 활용한 데이터 식별자 생성 방법의 문제
• 데이터의 순차적 특성으로 인해 식별자를 동시에 생성할 수 없다.
• 각 생성기에 대해 다른 시작점, 혹은 다른 증가값을 적용하는 기술을 사용할 수는 있지만 확장에 폐쇄적이다.
• ID 생성기를 다른 시스템으로 분리하면, 해당 시스템이 SPoF가 된다.
• ID 생성기를 다른 시스템으로 분리하면, 요청 애플리케이션과 ID 생성 시스템 간의 왕복 오버 헤드가 발생한다.
• ID를 증가시키면, 악의적인 공격에 노출되기 쉬우며, data set 크기가 노출된다. (계정을 새로 생성했는데 ID가 10이면, 서비스에 10개의 계정이 있다고 유추할 수 있다.)
📌 전역 고유 식별자 (GUID; Globally Unique Identifier)
전역 고유 식별자 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 전역 고유 식별자(全域固有識別子, 영어: Globally Unique Identifier, GUID)는 응용 소프트웨어에서 사용되는 유사난수이다. GUID는 생성할 때 항상 유일한 값이 만들어
ko.wikipedia.org
auto_increment를 사용하지 않고, 별도의 ID 동기화를 위한 추가 작업 없이, 모든 데이터 센터의 서버가 고유 ID(GUID)를 생성하는 방법은 생각보다 단순하다.
유일성을 보장하진 않지만, ID가 생성될 수 있는 경우의 수를 매우 크게 만듦으로써, 사실상 중복이 없다고 가정하는 접근법을 갖는다.
이전 포스팅에서 언급했 듯, "최소한 한 번의 충돌 확률이 50%가 되도록 생성해야 하는 4UUID의 수는 2.71조 개로, 약 86년 동안 초당 10억 개의 UUID를 86년 동안 생성해야 한다. 따라서 103조 개의 4UUID 버전에서 중복을 찾을 확률은 10억 분의 1이다."
그럼 GUID의 아이디어를 차용하여, 적절한 전역 고유 ID 생성기를 만들 수만 있다면, 문제를 쉽게 해결할 수 있지 않을까?
그러나 나는 단순히 고유성을 만족함에 그치지 못 하고, 추가로 몇 가지 요구사항을 충족하는 최적의 ID 생성 전략을 모색해볼 예정이다.
📌 Purpose
- ID는 유일성을 보장해야 한다.
- ID는 숫자로만 구성되어 있어야 한다.
- ID는 64bit로 표현 가능해야 한다. (주의해야 하는 사실은 UUID는 128-bit 난수를 생성한다는 점이다.)
- ID는 발급 날짜에 따라 전력 가능해야 한다.
- 초당 10,000개의 ID를 만들 수 있어야 한다. (사실 이렇게까지 필요없어서, 절충할 수 있는 부분)
✒️ PK는 왜 숫자(Numeric)여야 할까?
정말 다양한 이유가 존재하는데, 가장 눈에 띄는 차이는 문자열과 정수라는 점.
문자열의 비교는 상당히 느리고, 별도의 인코딩, 공백, 대소문자 구분 등의 문제가 발생할 수 있다.
비교 연산이 느리니, 인덱스를 사전 순으로 정렬하고자 했을 때 삽입이 느려지고, 탐색 또한 느려진다.
이번 내용과 다소 관련 없는 이야기를 덧붙이자면, 거의 대부분의 PK는 숫자 타입을 사용한다.
series, sequence, auto_increment, identity 또는 DB Engine의 기본 메서드가 값을 생성하는 방식을 많이 사용하는데, 이렇게 생성한 대리키(surrogate key)의 장점은 PK에 아무런 비지니스적 의미가 담겨있지 않다는 것이다.
비지니스는 시간에 따라 바뀔 수 있다. 아무런 의미가 없는, 그저 고유한 키를 사용해야 PK가 불변함을 보장할 수 있다.
🤔 크기가 64-bit 이내여야 할까? 아니면 64-bit fix여야 할까?
key가 "64-bit 값에서 표현 가능해야 한다"라는 조건이라면, 1이라는 값이 들어가도 무방하다.
그러나 key가 반드시 64-bit 크기를 차지해야 한다면 어떻게 될까?
이에 대해, 2010년에 Kimberly Tripp가 게시한 "More considerations for the clustering key"를 참고했다.
결론만 이야기하자면, clustering key는 고유하고, 좁고, 정적이며, 끊임없이 증가하고, null이 허용되지 않고, 고정 너비일 때 가장 좋은 성능을 보인다고 이야기하고 있다. (물론 고작 자료 하나 찾아본 게 다라 정답이라고는 못 하겠음.)
채팅 이력은 양이 방대하기 때문에, 서비스가 조금만 커져도 shard가 사실상 필수불가결한 부분이다.
이를 고려한다면 64-bit 고정 크기를 할당하는 게 나을 수도 있을 듯하다.
문제는 데이터 크기가 너무 커진다는 점이다.
나같은 그지는 돈으로 부딪혀야 하는 상황에선 한없이 소심해져야 한다.
따라서, 64-bit 내에서 표현 가능하면 ok하는 걸로 하자.
📌 무작위 난수 PK와 DB 연관 계
이 부분은 포스팅 다 쓰고 추가로 찾아본 내용이라, 순서가 조금 꼬였다고 보일 수도 있다.
MySQL UUIDs - Bad For Performance
MySQL UUIDs are still very popular despite a majority of posts warning against their usage. Learn what UUIDs are and why they are very bad for MySQL performance.
www.percona.com
UUID or GUID as Primary Keys? Be Careful!
You can use of UUIDs as the primary key to avoid database scale problems. But should you? I propose an alternative.
tomharrisonjr.com
1️⃣ 공간 비효율
여튼, 기본적으로 UUID와 이를 기반으로 둔 다양한 ID 생성기들은 대체로 16-byte 난수를 생성해낸다.
일단 공간적으로 상당히 비효율적인데, ID 하나만을 속성으로 갖는 테이블에 데이터 1억개를 넣으면 1.6GB가 나온다.
여기에 채팅 정보를 위한 속성이 추가되면, 수많은 데이터가 생길 수 있는 채팅 이력은 금새 엄청나게 용량을 잡아먹을 것이다.
문제는 채팅 이력 하나로 끝이 아니라, 관련된 모든 외래키 열에도 16-byte가 추가된다는 게 더 심각한 문제로 작용한다.
2️⃣ B+Tree 인덱싱 비효율
PK 열은 기본적으로 B+Tree Index가 생성된다.
그리고 Index는 데이터를 정렬된 상태로 유지하려고 하는 특성이 있다.
그런데 여기에 난수를 집어넣으면 온갖 부작용이 발생하기 시작하다.
- B+Tree는 데이터를 페이지 단위로 저장하는데, 랜덤값은 순서가 없어서 페이지를 효율적으로 채우기 어렵기 때문에 한 페이지에 적은 수의 요소만 저장되어 공간을 낭비한다.
- B+Tree가 균형을 유지하기 위해 필요할 때 페이지를 분할하거나 병합하는데, 정렬된 데이터라면 예측 가능한 방식으로 Tree를 채운다. 그러나 랜덤값은 예측이 불가능하므로, 더 많은 페이지 분할과 병합이 발생하고, 이는 성능 저하와 추가적인 Disk I/O를 요구한다.
3️⃣ 클러스터형 인덱스 문제
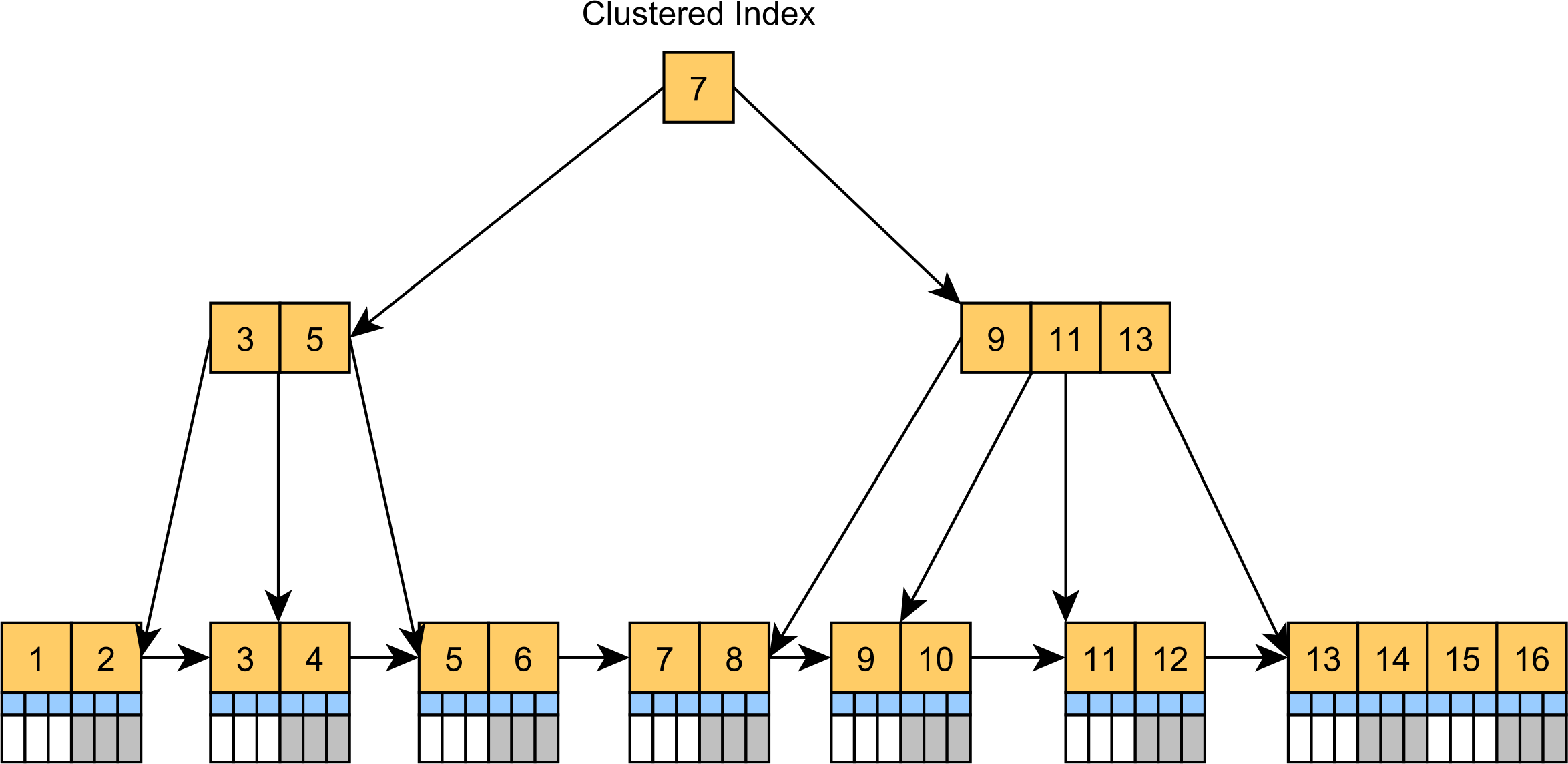
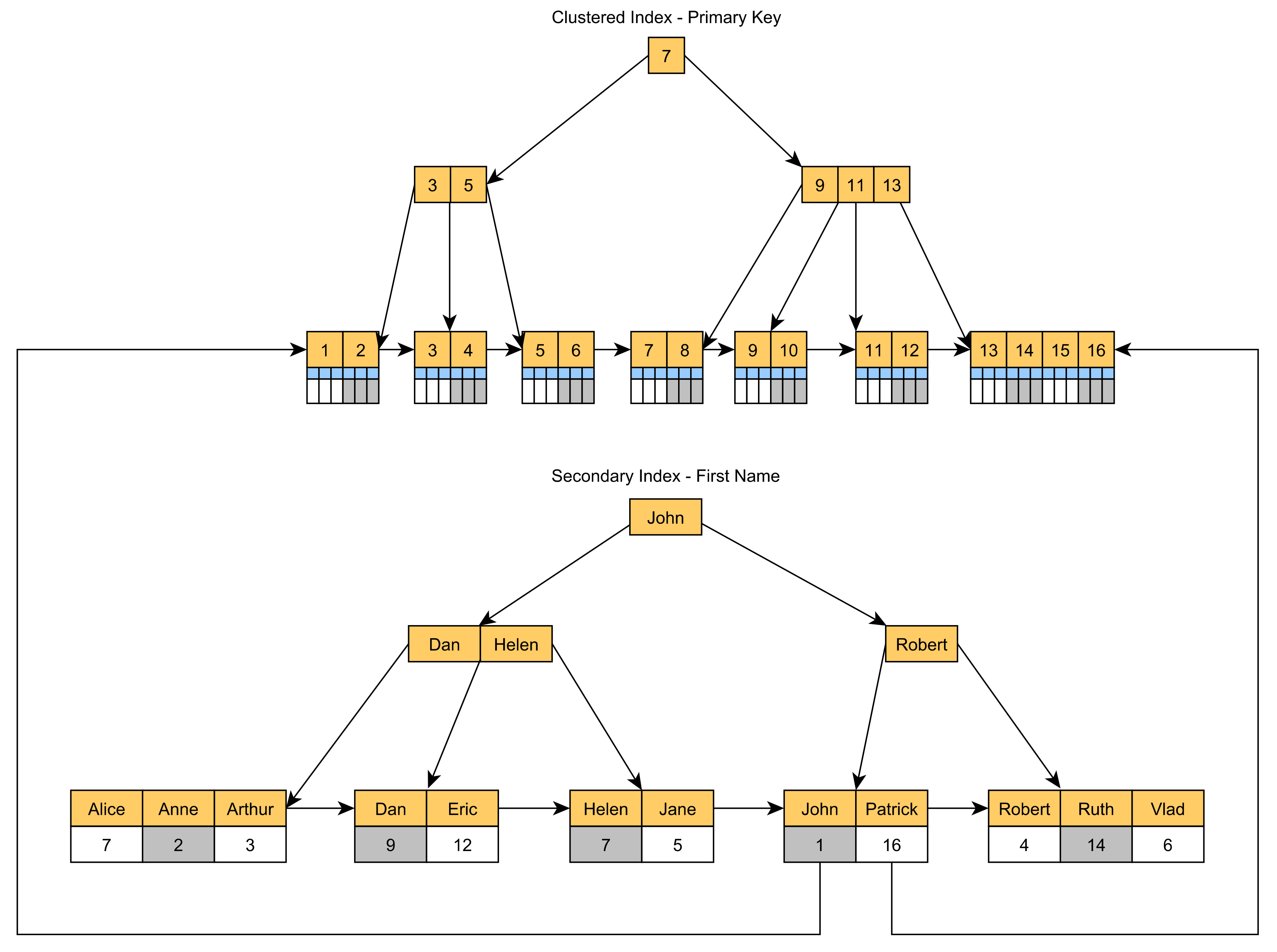
MySQL 혹은 SQL Server는 대체로 PK에 대해 Clustered Index를 사용한다.
이는 테이블의 실제 데이터를 인덱스 구조에 따라 물리적으로 정렬하는 방식을 갖는데, 이상적으로는 위와 같은 구조를 가지게 된다.
또한 보조 인덱스의 리프 노드는 실제 데이터 대신 PK값을 저장함으로써 효율을 극대하는 구조를 갖는다.
그러나 무작위 난수를 PK로 사용하게 되면, Clustered Index가 왼쪽 이미지처럼 효율적으로 구성되질 앟는다.
페이지 분할이 자주 발생하고, 공간 활용도가 떨어지는데 문제는 이게 보조 인덱스의 Leaf Node에도 영향을 미치게 된다.
📌 추가적인 비지니스 문제
우리 서비스는 1:1 채팅이라는 개념이 없다.
언제나 반드시 채팅방을 개설하고, 채팅방에 들어간다는 전제를 둔다.
그렇다면 유일성은 chat_id와 chat_room_id 복합키가 가지면 된다.
굳이 chat_id가 전역적으로 고유할 이유가 없으며, 채팅방 내에서만 고유하면 그만이다.
그 말은 즉슨, 안 그래도 중복 가능성이 극악이었던 GUID가 더더욱 겹치기 힘들어짐을 의미한다.
또한, 밑에서 다룰 SnowFlake와 같은 개념을 도입하지 않아도, simple하게 구현 가능함을 의미하기도 한다.
📌 범용 고유 식별자 종류
RFC 9562: Universally Unique IDentifiers (UUIDs)
The authors gratefully acknowledge the contributions of Rich Salz, Michael Mealling, Ben Campbell, Ben Ramsey, Fabio Lima, Gonzalo Salgueiro, Martin Thomson, Murray S. Kucherawy, Rick van Rein, Rob Wilton, Sean Leonard, Theodore Y. Ts'o, Robert Kieffer, Se
www.rfc-editor.org
RFC-9562 문서에서 추적한 범용 고유 식별자 종류는 다음과 같다.
- ULID
- LexicalUUID
- Snowflake (더 이상 서비스 안 됨)
- ShardingID
- KSUID
- Elasticflake
- Flake (더 이상 존재하지 않음. Snowflake의 영감을 받아 생성됨)
- Sonyflake
- orderedUuid
- COMBGUID
- SID
- pushID
- XID
- ObjectID
- CUID
모든 내용을 다루지는 않을 것이다.
기존에 라이브러리가 제공되거나, 참고할 소스 코드가 존재하는 케이스만 선별하여 포스팅을 작성했다.
그리고 Snowflake, Elasticflake, ShardingID 같은 것들은 zookeeper, elasticsearch, shrding된 db 등의 추가 학습 비용을 요구하는데, 공부야 할 수 있는데 문제는 우리 서비스에 적용할 범주를 아득히 넘어섰기 때문에 과감하게 버렸다.
(읽으면 또 공부해보고 싶어질 거 같아서, 찾아보지도 않음..)
하다보니 내용이 너무 많기도 하고, 단순히 적합한 ID 생성 전략을 서칭하는 것이 주 목적이라 생각보다 포스팅이 빈약해졌다. 🫠
2. UUID
📌 Definition
[대규모 시스템 설계] 7장. 분산 시스템을 위한 유일 ID 생성기 설계
📕 목차1. 유일 ID 생성기2. 개략적 설계3. 상세 설계1. 유일 ID 생성기 📌 auto_increment는 답이 될 수 있을까?DB가 단일 서버라면 auto_increment가 답이 될 수 있다.하지만 사용자 트래픽이 높은 곳이라
jaeseo0519.tistory.com
UUID 개념은 질리도록 설명했으므로, 여기선 다른 이야기를 해보자.
📌 GUID vs UUID
Is there any difference between a GUID and a UUID?
I see these two acronyms being thrown around and I was wondering if there are any differences between a GUID and a UUID?
stackoverflow.com
GUID와 UUID는 다른 의미인지가 조금 궁금해져서 찾아봤다.
🙆♂️ 간단하게 보면 차이가 없다.
- Microsoft-speak에서는 GUID, 이를 사용하지 않으면 UUID라고 부른다.
- UUID 사양 작성자와 MS조차 이걸 동의어라고 이야기한다.
- GUID, UUID는 둘 다 16-byte(128-bit)의 고유 식별자를 의미한다.
🙅♂️ 그러나 상황에 따라 다른 게 정답이다.
- RFC-4122에 따르면 UUID에는 4가지 변형(varient)이 존재한다.
- 모든 GUID는 이 4가지 변형 중 하나에 속하므로, RFC-4122 기준으로는 모든 GUID가 UUID라고 말할 수 있다.
- 그러나 일부 사람들은 UUID를 variant2만을 의미할 수도 있기 때문에, 다르다고 볼 수 있다. 즉, 'UUID'가 모든 변형을 포함하는지, 일부만을 포함하는지, 그리고 어떤 표준을 기준으로 삼는지에 따라 답변은 달라질 수 있다.
- IETF RFC-4122: 모든 GUID를 UUID로 인정한다.
- ITU-T X.667 ISO/IEC 9834-8:2004: variant 2만을 적합한 UUID로 인정한다.
📌 UUID는 시간 순 정렬이 불가능하다?
이전에 공부했던 바에 의하면, UUID를 사용할 수 없는 이유는 시간 순 정렬이 불가능하며, 128-bit의 크기를 갖는 ID를 생성하기 때문이었다.
따라서 테스트를 해볼 가치조차 없는 경우였기에, 안 되는 이유만 짚고 넘어갈 심산이었다.
그런데 웬걸? UUID 라이브러리 스펙을 보다가 이상한 문구를 발견했다.

내가 아는 UUID version은 4가 마지막이었는데, 무려 7까지 있던 것이었다.
심지어 라이브러리에서 구현한 게 version 7까지인 거고, 실제로는 version 8까지 존재한다.
(다만, version 8은 이전 버전과의 호환성을 유지하는 것만이 요구 사항인 자유 형식이라 구현을 안 한 듯하다.)
여기서 눈 여겨 봐야할 건, version 6와 7의 time-based 항목이다.
무작위 난수가 아닌, 시간을 기반으로 한다는 것은 UUID 스펙에 시간 정렬을 고려하는 버전을 내놓았을 가능성이 높았고, 실제로 그랬다.
- UUIDv1: 생성 호스트의 MAC 주소와 Timestamp 기반으로 ID를 생성한다. 동시 생성에 적합하지만, 낮은 추측성 스펙트럼에서 실패한다.
- 이 버전의 가장 큰 문제는 MAC 주소와 생성 시간 유추가 가능해서, UUID 역시 유추 가능하다는 보안 문제가 있다.
- UUIDv2: RFC에 공식적인 정의가 없으나, 호스트의 MAC 주소, Timestamp, 로컬 도메인 번호, 지정된 로컬 도메인 내에서 의미있는 정수 식별자를 사용한다.
- UUIDv3: 제공된 입력 데이터의 MD5 해시를 통해 생성한다. 이를 통해 동일 입력을 기반으로, 동일 UUI를 제공할 수 있다.
- UUIDv4: UUID의 변경 부분 bit를 생성하기 위해 완전히 무작위 데이터가 사용된다.
- UUIDv5: version3와 마찬가지로 입력 값을 기반으로 생성하지만, SHA-1 해싱 알고리즘을 사용하기 때문에, 이유가 없으면 v3보다는 v5를 사용한다,.
- UUIDv6: UUIDv1 내의 bit를 간단히 재정렬하여 불투명한 byte sequence로 정렬할 수 있게 한다.
- UUIDv7: Unix Epoch Timestamp를 기반으로 한 새로운 시간 기반 UUID bit layout
- 1582년 10월 15일 00:000:00.00부터 100 나노초 간격의 카운트 대신, Unix epoch를 소스로 사용하여 1970년 1월 1일 UTCC 자정부터 밀리초를 카운트한다.
- UUIDv1과 호환성을 제공해야 하는 것이 아니라면, UUIDv7을 사용하는 것이 좋다.
✒️ 단조성(Monotonicity)
그렇다면 무조건 UUIDv7을 사용하는 것이 좋을까 싶지만, v6가 나노초 단위로 생성을 하지만, v7은 밀리초 단위로 생성한다는 것을 주의해야 한다.
항상 증가하는 속성은 time based UUID 생성의 핵심이며, v6, v7의 시간 기반 특성은 "시간은 계속 흐른다"라는 전제로 인해 단조성의 일반 속성을 제공한다.
그러나 특정 timestamp에 두 개 이상의 UUID를 생성해야하는 경우, UUID가 계속 증가하도록 하기 위한 추가 논리를 도입해야 한다.
이를 위해 고정 길이 카운터, 모노토닉 랜덤, 카운터 롤오버 처리, 단조성 검증 등을 수행할 수 있지만, 추가적인 학습 및 개발 비용이 요구된다는 트레이드 오프가 수반된다.
[참고] 새로운 고유 식별자 형식(UUIDv6, UUIDv7 및 UUIDv8) 분석
📌 한계점
여전히 UUID가 128-bit 공간을 차지하는 문제를 해결하지 못 한다. (심지어 얘네 표현식 중간에 '-'가 들어가서 실제로는 32자가 아닌 36자가 나온다.)
또한, UUID는 문자열로 생성되기 때문에 이로 인해 발생될 side-effect 또한 여전히 존재한다.
보안 문제도 여전히 남아있다는 게 결정적.
만약, 이를 정말 UUID를 사용해서 해결하고 싶다면 UUIDv8을 활용해야 한다.
나에게는 현재 여기에 투자할 시간은 존재하지 않기 때문에, UUIDv8을 이용하는 방법은 추후 고려해볼 예정.
3. ULID
📌 Definition
GitHub - ulid/spec: The canonical spec for ulid
The canonical spec for ulid. Contribute to ulid/spec development by creating an account on GitHub.
github.com
ULID(Unique Lexicographically IDentifiers)는 UUID의 한계를 해결하기 위한 시도 중 하나다.
Unix 밀리초 수준 timestamp(48-bit)와 무작위 난수(80-bit)의 조합으로 이루어진 128-bit 난수다.
- UUID와 128-bit 호환성
- 밀리초 당 1.21e+24개의 고유 ULID
- 사전 순 정렬 가능
- 36자 UUID와 달리 26자 문자열 정식 인코딩 가능
- 더 나은 효율성과 가독성을 위해 base32 사용 (문자 당 5bit)
- 대소문자 구분 없음
- 특수문자 사용 불가 (URL 안전)
- 단조 정렬 순서(동일한 밀리초를 올바르게 감지하고 처리)
📌 한계점
- 대소문자를 구분하지 않고 비교해야 하는 것을 개발자가 지속적으로 알고 있어야 한다.
- 여전히 128-bit이므로 UUID보다 작지 않다.
4. TSID
📌 Definition
GitHub - f4b6a3/tsid-creator: A Java library for generating Time-Sorted Unique Identifiers (TSID).
A Java library for generating Time-Sorted Unique Identifiers (TSID). - f4b6a3/tsid-creator
github.com
TSID(Time-Sorted Unique IDentifier)는 Twitter snowflake와 ULID를 합쳐서 만든 자바 라이브러리다.
timestamp(42-bit) + 무작위 난수(22-bit)의 조합으로 이루어진 64-bit 난수
여기서 무작위 구성 요소로는 Node ID(0~20 bit)와 Counter(2~22 bit) 하위 부분이 존재한다. (즉, Node ID bit 크기에 따라 Counter 가용 공간이 줄어들어 밀리초당 생성 가능한 숫자가 줄어든다.)
Nod Id는 device나 인스턴스 ID 값을 나타내어 근본적인 중복 방지를 위해 존재한다.
예를 들어, 2개의 인스턴스에서 생성되는 TSID 값이 완전히 중복되지 않음을 검증없이 보장하고 싶다면, 이 값을 2bit로 제공할 수 있다.
단, 그만큼 counter bit가 줄어들기 때문에, 각 node에서의 단조성이 깨지기 쉬워진다.
- 시간 정렬 기반으로 정렬 가능
- 64-bit 정수로 저장 (표준 문자열로 18자, base encoding한 문자열은 13자의 길이)
- Base32로 문자열 표현 가능 (URL safe하며, 대소문자를 구분하지 않고, 하이픈도 없다. 표준 문자열로 13자)
✒️ TSID의 Timestamp
TSID는 Snowflakes와 같이 timestamp bit를 42-bit로 설정한다.
ULID와 비교해 6 bit를 절약했지만, 그만큼 ULID의 수명이 줄어든다는 것을 의미한다.
이를 보완하기 위해서 TSID는 1970-01-01 00:00:00.000이 아닌, 2020-01-01 00:00:00.000을 시작점으로 하는 밀리세컨드 값이 된다.
📌 한계점
- 시스템 시계에 의존하기 때문에 시간 동기화가 매우 중요
- 42-bit timestamp 제한으로 인해, 약 139년 동안만 사용 가능 (현재로썬 단점으로 보기 매우 어려우나, unsigned interger를 사용한다는 가정하에 성립한다.)
- 적은 bit 수로 인해, UUID보다 충돌 저항성이 낮음.
📌 TSID Factory
뭔가 이것만 봐도 TSID를 사용하게 될 거 같아서, 추가적인 내용을 조사해본 내용.
How to not use TSID factories
TSID is a monotonically incremented, node and time dependent universal identifier of only 8 bytes (against the 16 bytes of a standard UUID). Universal means that, under specific conditions, it can …
fillumina.wordpress.com
TSID는 고유하지 않은 ID를 여러 개 생성할 수 있는데, 이를 방지하기 위해 두 가지 환경을 고민해야 한다.
- 동일 Node 내 다른 Thread
- 다른 Node
내가 사용할 라이브러리 기준에서 기본 TSID 구조는 다음과 같았다.
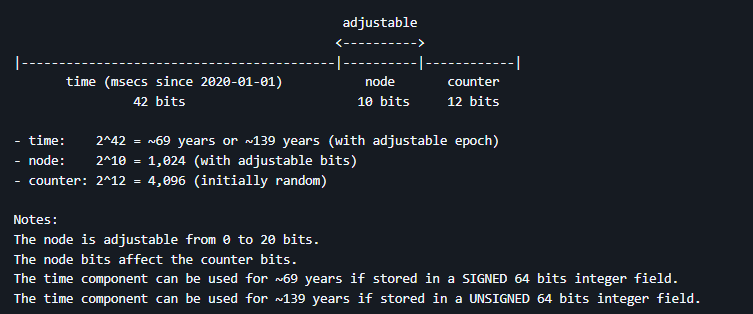
기본 node bit는 10-bit가 할당되어 있으므로, 최대 카운터 값은 2^12 -1 = 4,095.
즉, 밀리초당 생성할 수 있는 최대 TSID는 4,096개가 된다.
여기서 충돌을 회피하기 위해 고민해야 하는 값은 Node라는 값인다.
이는 물리적 머신, 가상 머신, 컨테이너, k8s 포드, 실행 중인 프로세스, 데이터베이스 인스턴스 번호 등이 될 수 있다.
시스템 속성이나 환경 변수를 TsidFactory로 정의하지 않으면, Node 식별자가 무작위로 선택된다고 한다.
GitHub - fillumina/tsid-factory-test: Test various ways to use TSID-generator factories
Test various ways to use TSID-generator factories. Contribute to fillumina/tsid-factory-test development by creating an account on GitHub.
github.com

여기서 결론은 하나였는데, 동일한 Node 내에서 모든 Thread는 동일한 공유 팩토리를 사용해야 한다는 것.
다중 노드 시스템의 경우엔 TsidFactory.newInstance1024(nodeId)와 같은 메서드를 사용하여, 동일 Node 내에서 모든 Thread가 동일 Node ID를 가진 공유 팩토리를 사용하도록 만들어야 한다.
여기서 의미하는 256, 1024, 4096은 2^8, 2^10, 2^12로, 지수는 곧 수용 가능한 node 개수를 의미한다.
나는 어차피 현재 하나의 노드만 운영일 생각이므로, 전혀 고려하지 않아도 된다.
그럼 같은 Node내 Multi-Thread 에서의 충돌 환경만 고려하면 되는데, 이미 TSID Factory에서는 TSID를 만들 때 동기화가 되어있으므로 신경쓰지 않아도 된다고 한다.
다만 흥미로운 부분이 하나 있었는데, ThreadLocalDate을 사용하는 것처럼 합당한 이유가 있다면 마련하는 것도 좋다는 것이었다.
"엥, 이게 뭔 소리야?" 싶었는데, 요지는 이러했다.
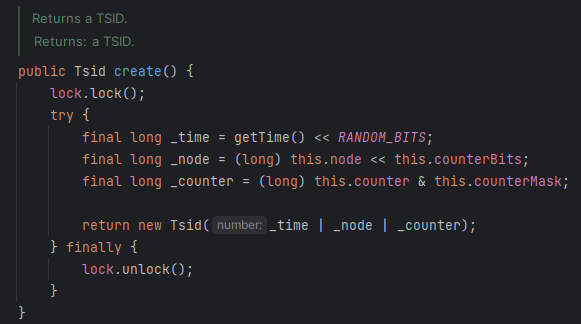
라이브러리 내에서 Tsid를 생성하는 함수는 위와 같이 정의되어 있는데, 동기화를 위해 Lock을 사용하고 있다.
Lock은 멀티 스레드 환경의 성능 저하를 유발하므로, 이를 최적화하고 싶다면 멀티 스레딩 환경에서 각 Thread마다 독립적인 난수를 생성하는 ThreadLocalRandom을 사용할 수 있다는 의미다.
public static TsidFactory getTsidFactory(int nodeCount) {
int nodeBits = (int) (Math.log(nodeCount) / Math.log(2));
return TsidFactory.builder()
.withRandomFunction(
() -> ThreadLocalRandom.current().nextInt() // 랜덤 생성 인수 전달
)
.withNodeBits(nodeBits)
.build();
}이런 식으로 만들면, 각 Thread가 독립적으로 난수를 생성할 수 있으므로 병렬 처리 성능이 향상될 수 있음을 이야기 한다.
근데 지금은 이렇게까지 할 이유가 없어서, Factory를 재정의하진 않았다.
5. KSUID
📌 Definition
GitHub - segmentio/ksuid: K-Sortable Globally Unique IDs
K-Sortable Globally Unique IDs. Contribute to segmentio/ksuid development by creating an account on GitHub.
github.com
KSUID(K-Sortable Unique IDentifier)는 K가 붙어 있어서, 한국에서 개발했나 싶었지만 아니었다. (농담 아니고 진지함)
timestamp(32-bit) + 무작위 난수(128-bit) 조합의 160-bit 난수
- 시간 순 정렬 보장
- 충돌, 조정, 의존성 없음
- 160-bit 난수 (표준 문자열 표현으로는 27자)
📌 한계점
- UUID보다 긴 무려 160-bit (20-byte)를 자랑하는 크기. (더 알아볼 이유도 없이 여기서 컷)
6. Twitter Snowflake
📌 Definition
GitHub - twitter-archive/snowflake: Snowflake is a network service for generating unique ID numbers at high scale with some simp
Snowflake is a network service for generating unique ID numbers at high scale with some simple guarantees. - twitter-archive/snowflake
github.com
찾아봤으나 더 이상 지원되지 않는 서비스라고 한다.
자세한 설명이 필요하면 이전 포스팅을 참고하면 된다. (혹은 이전의 깃헙도 도움이 된다.)
- 식별자가 64-bit로 구성되어 있기 때문에 효율적인 저장이 가능하다. (조인 성능도 향상)
- 시간 기반으로 생성되기 때문에 정렬 보장 (auto_increment도 보장)
- Node가 갑자기 사라져도, 복구가 가능한 방식으로 분산 처리된다.
- 비서술적(Non-Descriptive) 구조이므로 아무 의미 없는 기본키 생성 가능
- 정수로만 이루어져 있기에 문자열 키에서 발생하는 문제 제거
📌 한계점
- Zookeeper 클러스터를 모니터링하고 유지 관리해야 한다. (이게 결정적인 게, 내 서비스는 Zookeeper까지 돌리는 건 너무나도 오버 엔지니어링인 상황인데, Zookeeper가 없으면 서버 ID 할당이 너무 어려워진다.)
- 식별자 생성 서비스 클러스터(Snowflake 서버)를 유지 관리해야 한다.
- timestamp가 차지하는 공간이 41-bit. 41-bit의 수로 표현 가능한 수를 고려했을 때, 현재 시각을 기원 시각으로 잡았을 때 69.7년 동안 겹치지 않도록 하는 것이 한계. (분명한 건 67년 뒤의 일은 내가 상관할 바가 아니다.)
7. Non-Cryptographic ID
📌 MurmurHash
MurmurHash - Wikipedia
From Wikipedia, the free encyclopedia Computer function MurmurHash is a non-cryptographic hash function suitable for general hash-based lookup.[1][2][3] It was created by Austin Appleby in 2008[4] and, as of 8 January 2016,[5] is hosted on GitHub along wit
en.wikipedia.org
정식으로 뭔가 사용되는 것 같지는 않고, 그냥 이렇게도 해볼 수 있지 않을까란 생각에 개인적으로 알아봤다.
MurmurHash2를 사용하면 32-bit 또는 64-bit 값을 생성할 수 있으면서, 정렬된 버전을 보장하는 버전 또한 별도로 존재한다.
암호화를 하면 느려질 우려가 있기에, 비암호화 키를 사용한다면 대안책으로 쓰일 수도 있지 않을까 싶었으나
이내 터무니 없는 생각이라는 걸 깨달았다.
- 기본적으로 같은 입력에 대해 항상 같은 출력을 생성하므로, 입력값 선택이 다시 문제가 된다.
- 입력값으로 Timestamp를 넣으면 되지 않을까 싶지만, 이것만으로는 단조성을 지키기 힘드므로 결국 추가 인자가 필요하며, 이는 Node Id와 같은 입력 정보를 필요로 한다.
- 시간 정보를 포함하지 않기 때문에, 시간 기반 정렬이 어렵다.
- 암호화 해시 함수가 아니므로, 입력값으로 ID를 예측 가능하기 때문에 보안성이 떨어진다.
- 여러 노드에서 고유 ID 생성을 위한 추가적인 조정 메커니즘을 필요로 한다.
- PK에 "의미있는 정보"가 포함될 여지가 있다.
8. Performance Evaluation
📌 Target
우선 처음의 목표를 상기시켜보자.
- ID는 유일성을 보장해야 한다.
- ID는 숫자로만 구성되어 있어야 한다.
- ID는 64bit로 표현 가능해야 한다. (주의해야 하는 사실은 UUID는 128-bit 난수를 생성한다는 점이다.)
- ID는 발급 날짜에 따라 전력 가능해야 한다.
- 초당 10,000개의 ID를 만들 수 있어야 한다. (사실 이렇게까지 필요없어서, 절충할 수 있는 부분)
이를 만족하는 지 확인해야 하는 수집해야 하는 정보는 다음과 같다.
- ID 생성 시간
- ID 정렬 여부
- 충돌 비율
- DB Join 시간
GitHub - psychology50/high-concurrency-unique-id-generator-test: 🔍 SPoF 문제를 없애고, 동시성을 보장하면서,
🔍 SPoF 문제를 없애고, 동시성을 보장하면서, 고유한 ID 생성 전략 탐색을 위한 Repository - psychology50/high-concurrency-unique-id-generator-test
github.com
모든 코드와 프로젝트 실행 방법은 위 깃헙에서 확인 가능합니다.
테스트 수행 기기는 4-cores, 8-threads, 16 GB RAM이며, JDK17 환경에서 10-thread pool을 가지고 테스트 했습니다.
📌 Id Generator
public interface IdGenerator<T> {
T execute();
}우선 ID 생성 전략이 너무 다양해서, 인터페이스를 하나 정의해주었다.
제네릭을 사용한 이유는 TSID의 경우 Long 타입 반환이 가능해서, String으로 고정할 수 없었기 때문.
String으로 감싸면 해결할 수 있긴 했으나, 그로 인해 평가의 불이익이 발생하는 것을 방지하고 싶었다.
📌 Benchmark
public class BenchmarkResult {
private String generatorName;
private int sampleSize;
private int byteSize;
private long generationTime;
private boolean sortable;
private double collisionRate;
private long dbJoinTime;
private String exampleId;
BenchmarkResult(String generatorName, int sampleSize) {
this.generatorName = generatorName;
this.sampleSize = sampleSize;
}
// getter, setter ...
}그리고 모든 Test 실행 결과를 담아두고, 테스트가 모두 종료되면 Excel로 출력할 예정이었다.
MS의 xlsx 확장자로 엑셀을 만들기 위해 POI API를 사용했는데, 이게 생각보다 시간이 너무 많이 뺏길 거 같아서 그냥 클로드한테 BenchmarkResult랑 요구 사항 던져주니까 코드를 모두 작성해줬다. 🤣
public class ResultWriter {
public static void exportToExcel(final Map<String, List<BenchmarkResult>> results) throws Exception {
XSSFWorkbook workbook = new XSSFWorkbook();
XSSFSheet sheet = workbook.createSheet("Benchmark Results");
// Write data
writeData(sheet, results);
// Create charts
createGroupedChart(workbook, sheet, "Generation Time (ms)", 2);
createGroupedChart(workbook, sheet, "Collision Rate", 4);
createGroupedChart(workbook, sheet, "DB Join Time (ms)", 5);
// Auto-size columns
for (int i = 0; i < 6; i++) {
sheet.autoSizeColumn(i);
}
// Write to file
try (FileOutputStream outputStream = new FileOutputStream("BenchmarkResults.xlsx")) {
workbook.write(outputStream);
}
}
private static void writeData(Sheet sheet, Map<String, List<BenchmarkResult>> results) {
System.out.println("Writing data to Excel...");
Row headerRow = sheet.createRow(0);
headerRow.createCell(0).setCellValue("Generator Name");
headerRow.createCell(1).setCellValue("Sample Size");
headerRow.createCell(2).setCellValue("Generation Time (ms)");
headerRow.createCell(3).setCellValue("Sortable");
headerRow.createCell(4).setCellValue("Collision Rate");
headerRow.createCell(5).setCellValue("DB Join Time (ms)");
headerRow.createCell(6).setCellValue("Byte Size");
headerRow.createCell(7).setCellValue("Example ID");
int rowNum = 1;
for (Map.Entry<String, List<BenchmarkResult>> entry : results.entrySet()) {
for (BenchmarkResult result : entry.getValue()) {
Row row = sheet.createRow(rowNum++);
row.createCell(0).setCellValue(result.getGeneratorName());
row.createCell(1).setCellValue(result.getSampleSize());
row.createCell(2).setCellValue(result.getGenerationTime());
row.createCell(3).setCellValue(result.isSortable());
row.createCell(4).setCellValue(result.getCollisionRate());
row.createCell(5).setCellValue(result.getDbJoinTime());
row.createCell(6).setCellValue(result.getByteSize());
row.createCell(7).setCellValue(result.getExampleId());
}
}
System.out.println("Data written successfully.");
}
private static void createGroupedChart(XSSFWorkbook workbook, XSSFSheet sheet, String title, int dataColumn) {
System.out.println("Creating chart: " + title);
XSSFDrawing drawing = sheet.createDrawingPatriarch();
XSSFClientAnchor anchor = drawing.createAnchor(0, 0, 0, 0, dataColumn + 4, 1, dataColumn + 15, 20); // 여기서 테이블 크기 조정
XSSFChart chart = drawing.createChart(anchor);
chart.setTitleText(title);
chart.setTitleOverlay(false);
XDDFCategoryAxis bottomAxis = chart.createCategoryAxis(AxisPosition.BOTTOM);
bottomAxis.setTitle("Sample Size");
XDDFValueAxis leftAxis = chart.createValueAxis(AxisPosition.LEFT);
leftAxis.setTitle(title);
XDDFChartData data = chart.createData(ChartTypes.BAR, bottomAxis, leftAxis);
XDDFChartData.Series uuidSeries = data.addSeries(getXDDFDataSource(sheet, "UUID"), getYDDFDataSource(sheet, "UUID", dataColumn));
uuidSeries.setTitle("UUID", null);
XDDFChartData.Series timeOrderedUuidSeries = data.addSeries(getXDDFDataSource(sheet, "TimeOrderedUUID"), getYDDFDataSource(sheet, "TimeOrderedUUID", dataColumn));
timeOrderedUuidSeries.setTitle("TimeOrderedUUID", null);
XDDFChartData.Series timeOrderedEpocUuidSeries = data.addSeries(getXDDFDataSource(sheet, "TimeOrderedEpochUUID"), getYDDFDataSource(sheet, "TimeOrderedEpochUUID", dataColumn));
timeOrderedEpocUuidSeries.setTitle("TimeOrderedEpochUUID", null);
XDDFChartData.Series ulidSeries = data.addSeries(getXDDFDataSource(sheet, "ULID"), getYDDFDataSource(sheet, "ULID", dataColumn));
ulidSeries.setTitle("ULID", null);
XDDFChartData.Series ksuidSeries = data.addSeries(getXDDFDataSource(sheet, "KSUID"), getYDDFDataSource(sheet, "KSUID", dataColumn));
ksuidSeries.setTitle("KSUID", null);
XDDFChartData.Series tsidSeries = data.addSeries(getXDDFDataSource(sheet, "TSID"), getYDDFDataSource(sheet, "TSID", dataColumn));
tsidSeries.setTitle("TSID", null);
XDDFChartData.Series tsidLongSeries = data.addSeries(getXDDFDataSource(sheet, "TSIDLong"), getYDDFDataSource(sheet, "TSIDLong", dataColumn));
tsidLongSeries.setTitle("TSIDLong", null);
chart.plot(data);
XDDFBarChartData bar = (XDDFBarChartData) data;
bar.setBarDirection(BarDirection.COL);
bar.setBarGrouping(BarGrouping.CLUSTERED);
System.out.println("Chart created successfully. about " + title);
}
private static XDDFCategoryDataSource getXDDFDataSource(XSSFSheet sheet, String generatorName) {
System.out.println("Creating XDDFDataSource for " + generatorName);
List<String> categories = new ArrayList<>();
for (int i = 1; i <= sheet.getLastRowNum(); i++) {
Row row = sheet.getRow(i);
if (row.getCell(0).getStringCellValue().equals(generatorName)) {
categories.add(String.valueOf(row.getCell(1).getNumericCellValue()));
}
}
return XDDFDataSourcesFactory.fromArray(categories.toArray(new String[0]));
}
private static XDDFNumericalDataSource<Double> getYDDFDataSource(XSSFSheet sheet, String generatorName, int dataColumn) {
System.out.println("Creating YDDFDataSource for " + generatorName);
List<Double> values = new ArrayList<>();
for (int i = 1; i <= sheet.getLastRowNum(); i++) {
Row row = sheet.getRow(i);
if (row.getCell(0).getStringCellValue().equals(generatorName)) {
values.add(row.getCell(dataColumn).getNumericCellValue());
}
}
return XDDFDataSourcesFactory.fromArray(values.toArray(new Double[0]));
}
}물론 중간 중간 나와 안 맞는 부분이 있어서, 실사용을 위해 일부 수정이 필요하긴 했다만 여튼 꿀빨았다.
📌 Test
@TestInstance(TestInstance.Lifecycle.PER_CLASS)
public class IdGeneratorBenchmarkTest {
private static final int THREAD_COUNT = 10;
private static Connection conn;
private static final Map<String, List<BenchmarkResult>> results = new HashMap<>();
@BeforeAll
public void setUp() throws SQLException {
conn = DriverManager.getConnection("jdbc:h2:~/test;DB_CLOSE_DELAY=-1", "sa", "1234");
createTables();
}
@AfterAll
static void teardown() throws Exception {
dropTables();
conn.close();
ResultWriter.exportToExcel(results);
}
@ParameterizedTest(name = "UUID")
@ValueSource(ints = {256, 512, 1_024, 4_096, 8_192, 100_000, 300_000, 500_000})
public void evaluateUUID(int sampleSize) throws Exception {
IdGenerator<String> generator = new UuidGenerator();
runBenchmark(generator, "UUID", sampleSize);
}
@ParameterizedTest(name = "TimeOrderedUUID")
@ValueSource(ints = {256, 512, 1_024, 4_096, 8_192, 100_000, 300_000, 500_000})
public void evaluateTimeOrderedUUID(int sampleSize) throws Exception {
IdGenerator<String> generator = new TimeOrderedUuidGenerator();
runBenchmark(generator, "TimeOrderedUUID", sampleSize);
}
@ParameterizedTest(name = "TimeOrderedEpochUUID")
@ValueSource(ints = {256, 512, 1_024, 4_096, 8_192, 100_000, 300_000, 500_000})
public void evaluateTimeOrderedEpocUUID(int sampleSize) throws Exception {
IdGenerator<String> generator = new TimeOrderedEpochUuidGenerator();
runBenchmark(generator, "TimeOrderedEpochUUID", sampleSize);
}
@ParameterizedTest(name = "KSUID")
@ValueSource(ints = {256, 512, 1_024, 4_096, 8_192, 100_000, 300_000, 500_000})
public void evaluateKSUID(int sampleSize) throws Exception {
IdGenerator<String> generator = new KsuidGenerator();
runBenchmark(generator, "KSUID", sampleSize);
}
@ParameterizedTest(name = "ULID")
@ValueSource(ints = {256, 512, 1_024, 4_096, 8_192, 100_000, 300_000, 500_000})
public void evaluateULID(int sampleSize) throws Exception {
IdGenerator<String> generator = new TsidGenerator();
runBenchmark(generator, "ULID", sampleSize);
}
@ParameterizedTest(name = "TSID")
@ValueSource(ints = {256, 512, 1_024, 4_096, 8_192, 100_000, 300_000, 500_000})
public void evaluateTSID(int sampleSize) throws Exception {
IdGenerator<String> generator = new TsidGenerator();
runBenchmark(generator, "TSID", sampleSize);
}
@ParameterizedTest(name = "TSIDLong")
@ValueSource(ints = {256, 512, 1_024, 4_096, 8_192, 100_000, 300_000, 500_000})
public void evaluateTSIDLong(int sampleSize) throws Exception {
IdGenerator<Long> generator = new TsidLongGenerator();
runBenchmark(generator, "TSIDLong", sampleSize);
}
private <E extends Comparable<? super E>> void runBenchmark(IdGenerator<E> generator, String generatorName, int sampleSize) throws Exception {
BenchmarkResult result = new BenchmarkResult(generatorName, sampleSize);
result.setGenerationTime(testGenerationTime(generator, sampleSize));
result.setSortable(testSortability(generator, sampleSize));
result.setCollisionRate(testCollisionRate(generator, sampleSize));
result.setDbJoinTime(testDbJoinPerformance(generator, generatorName, sampleSize));
// ID의 byte 크기 계산
E sampleId = generator.execute();
String exampleId = sampleId.toString();
result.setExampleId(exampleId);
result.setByteSize(exampleId.getBytes().length);
results.computeIfAbsent(generatorName, k -> new ArrayList<>()).add(result);
}
...
}전반적인 테스트 구조는 위와 같다.
각 ID 생성 전략들의 sample size를 점진적으로 증가시키고, 각각에 대해 성능치를 측정한 후 최종적으로 엑셀로 변환한다.
Spring에 기대지 않고 처음 H2 DB를 써봤는데, 이게 버전 업데이트 되면서 자동으로 DB가 생성 안 되는 가벼운 이슈가 있었다.
1️⃣ ID 생성 시간
// ID 생성 시간 측정
private <E> long testGenerationTime(IdGenerator<E> generator, int sampleSize) throws Exception {
long start = System.nanoTime();
ExecutorService executor = Executors.newFixedThreadPool(THREAD_COUNT);
CountDownLatch latch = new CountDownLatch(sampleSize);
for (int i = 0; i < sampleSize; i++) {
executor.submit(() -> {
try {
generator.execute();
} finally {
latch.countDown();
}
});
}
try {
latch.await(); // 모든 작업이 완료될 때까지 대기
} finally {
executor.shutdown();
}
return (System.nanoTime() - start) / 1_000_000; // 밀리 초로 변환
}아이디 생성 시간은 sampleSize만큼 실행하는 데 걸리는 시간을 측정했다.
단순히 ID 하나 만드는 시간만 확인해보려다가, ID Factory의 lock 등을 감안했을 때, 전체 수행 시간을 측정해보는 게 더 유의미하다고 판단했다.
2️⃣ 정렬 여부
// ID 정렬 가능 여부 테스트
private <E extends Comparable<? super E>> boolean testSortability(IdGenerator<E> generator, int sampleSize) {
List<E> ids = new ArrayList<>();
for (int i = 0; i < sampleSize; i++) {
ids.add(generator.execute());
}
List<E> sortedIds = new ArrayList<>(ids);
Collections.sort(sortedIds);
return ids.equals(sortedIds);
}처음에 정렬 여부를 어떻게 판단하나 싶었는데, timestamp 기반의 ID 생성기로 도출된 값은 반드시 "정렬 가능"해야 한다는 것에 초점을 맞췄다.
즉, ID를 String으로 받는다고 해도 사전 순 정렬이 됨을 보여야 하지 않을까 싶어서, 일단 이렇게 해봤는데 잘만 된다.
참고로 ids가 불변 List가 아니기 때문에, ids.sort(...)를 했어도 됐다.
백엔드 개발하면서 막상 잘 안 쓰게 되다보니, 자꾸 헷갈린단 말이지..
3️⃣ ID 충돌 여부
// ID 충돌율 테스트
private <E> double testCollisionRate(IdGenerator<E> generator, int sampleSize) throws Exception {
Set<E> uniqueIds = Collections.newSetFromMap(new ConcurrentHashMap<>());
ExecutorService executor = Executors.newFixedThreadPool(THREAD_COUNT);
CountDownLatch latch = new CountDownLatch(sampleSize);
for (int i = 0; i < sampleSize; i++) {
executor.submit(() -> {
try {
uniqueIds.add(generator.execute());
} finally {
latch.countDown();
}
});
}
try {
latch.await(); // 모든 작업이 완료될 때까지 대기
} finally {
executor.shutdown();
}
return 1 - ((double) uniqueIds.size() / sampleSize);
}충돌 테스트는 생성된 ID를 Set 자료형에 삽입해서, 최종 Set의 size가 sampleSize와 동일함을 보이면 된다.
문제는 이게 멀티 스레드 환경이라 Concurrent한 자료구조가 필요했는데, concurrent api에 Set은 없었다.
검색해보니 Collections.newSetFromMap()에다가 Concurrent 자료 구조를 넣어주니 됐다.
예전에 ConcurrentSet 없어서 포기한 적 있었는데...ㅎㅎ
4️⃣ DB 조인 테스트
// DB 조인 성능 테스트
private <E> long testDbJoinPerformance(IdGenerator<E> generator, String generatorName, int sampleSize) throws SQLException {
PreparedStatement pstmt = conn.prepareStatement("INSERT INTO " + generatorName + "_table (id) VALUES (?)");
for (int i = 0; i < sampleSize; i++) {
E id = generator.execute();
if (id instanceof String) {
pstmt.setString(1, (String) id);
} else if (id instanceof Long) {
pstmt.setLong(1, (Long) id);
}
pstmt.executeUpdate();
}
long start = System.nanoTime();
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM " + generatorName + "_table a JOIN " + generatorName + "_table b ON a.id = b.id");
while (rs.next()) { // 결과 집합 반복하면서 모든 행 소비
}
return (System.nanoTime() - start) / 1_000_000; // 밀리 초로 변환
}DB Join 테스트는 더미 테이블을 하나 만들어줘야 할 지 고민을 많이 했었다.
그러나 Join이라는 게...어차피 PK와 PK를 참조하는 FK로 테이블을 묶는 거니까, 그냥 자기 자신이랑 묶게 만들면 되겠다 싶었다.
되긴 되지만, 부정확한 테스트일 수 있으니 더 좋은 아이디어가 있다면 그렇게 해보시길 바랍니다.
📌 Evaluation
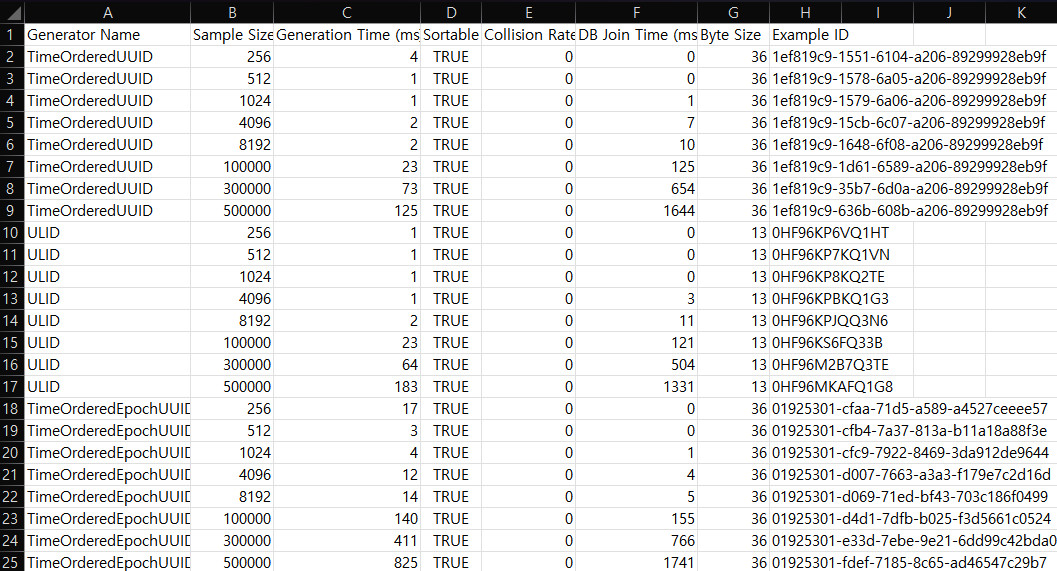
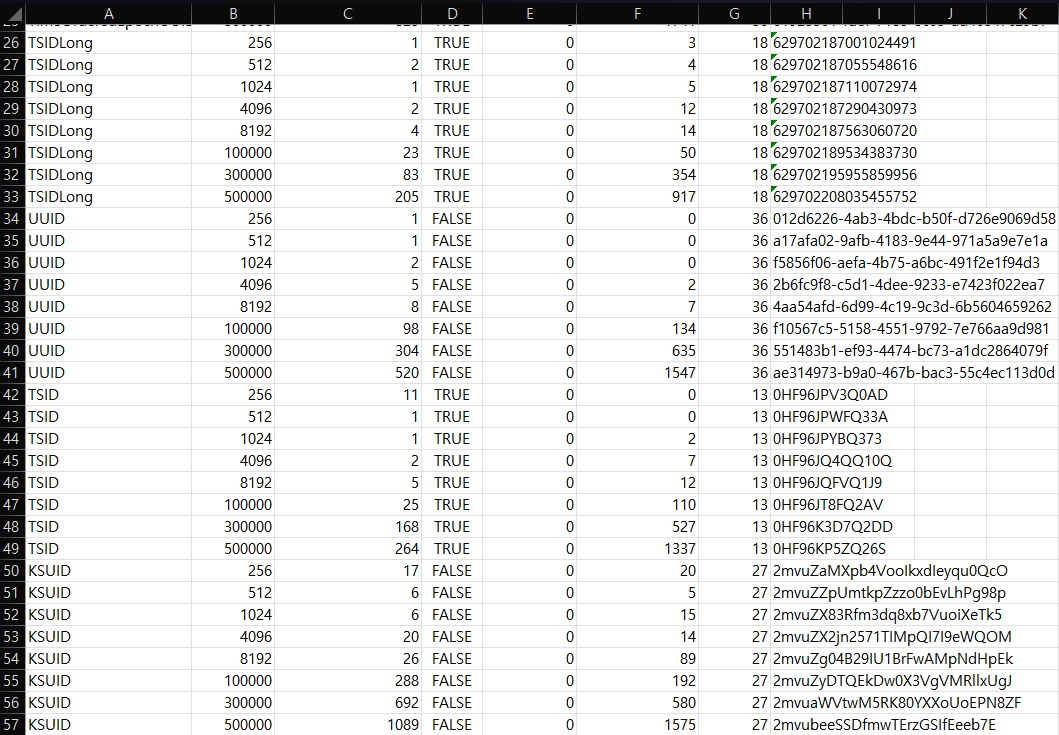
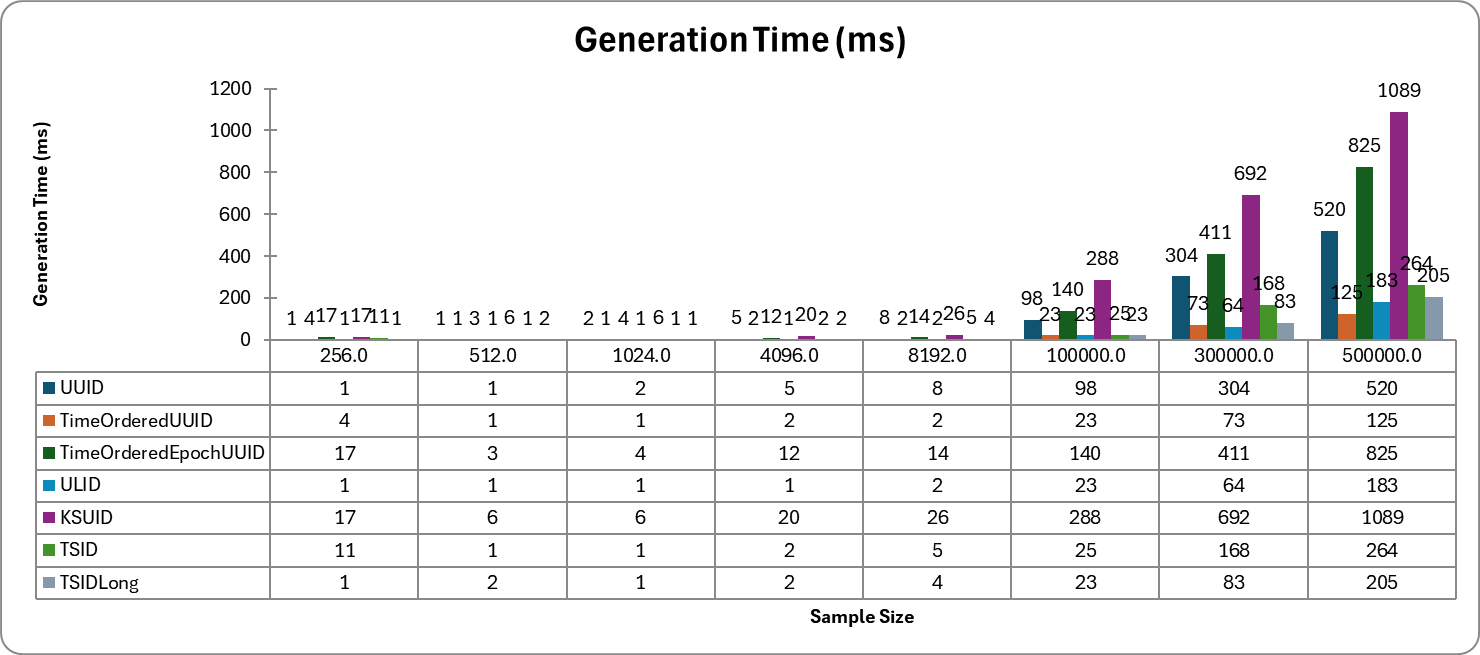
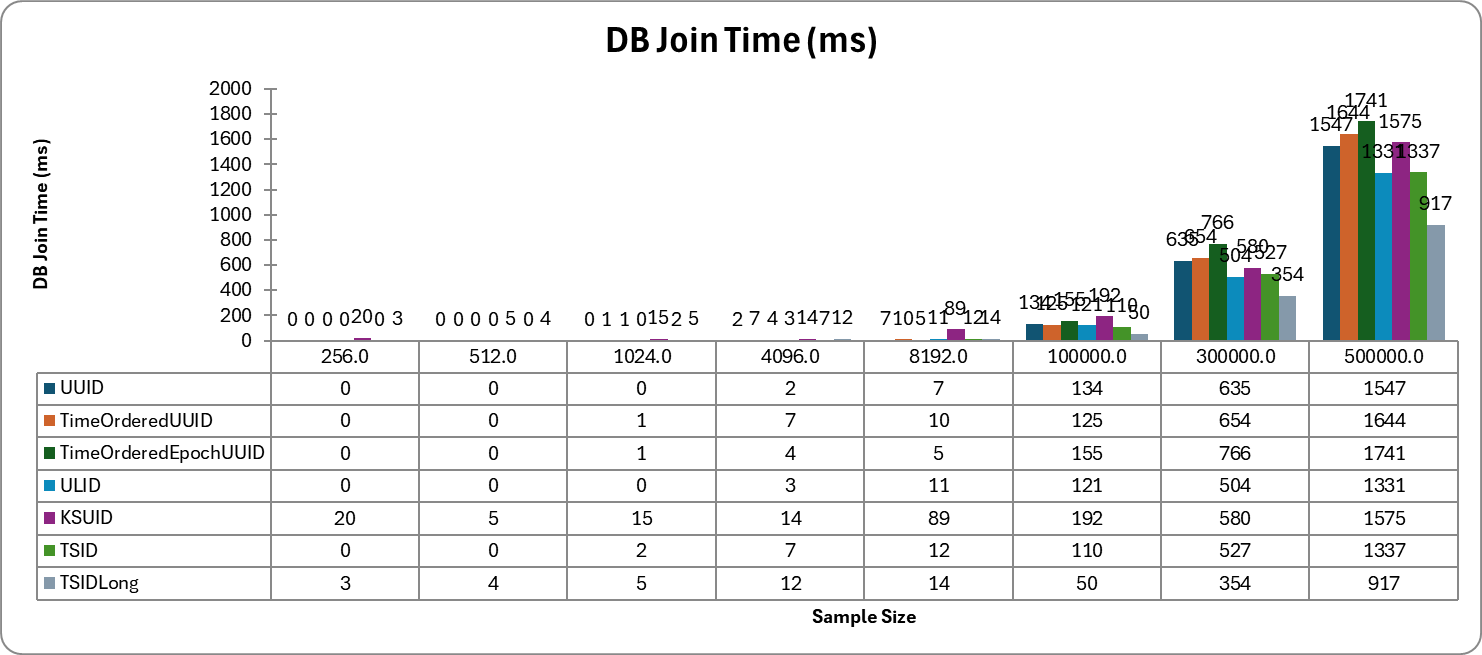
평가 결과는 상당히 흥미로웠는데, 예상했던 대로 Long 타입의 TSID를 사용했을 때 가장 빠른 Join 성능을 보였다.
그 외에도 생성 시간에서도, 4등과 월등한 차이를 보이면서 3번 째로 빠른 성능을 보여주고 있다.
심지어 unsigned long 타입으로 관리하면, 처음 목표대로 64-bit로 관리 가능한 정수로 PK 생성 가능한 강력한 이점을 갖는다.
📌 결론
내가 만들 채팅 서비스에서 사용할 GUID는 TSID Long 타입으로 생성하기로 결정했다.
그야 이렇게 Zookeeper도 없는 나같은 놈을 위해, 생성도 빠르고, 정렬 가능하면서, DB 공간 효율적인 TSID를 사용하지 않을 이유가 없었다.
심지어 ms당 10,000개의 고유 아이디를 생성할 수 있어야 한다는 요구사항을 충족시키는 건 과욕이라고 생각했는데, 나는 Node가 어차피 1개라서 node bit를 줄이면, 2^14 - 1 = 16,383개/ms의 고유 ID를 생성할 수도 있다.
여튼 갑자기 급발진해서 찾아본 내용이었지만, 상당히 유의미했고 원하던 결과까지 얻을 수 있어서 너무 좋았다.