우재남님의 "혼자 공부하는 SQL"을 기반으로 학습한 게시물입니다.
📕 목차
1. MySQL의 데이터 형식
2. 두 테이블을 묶는 조인
3. SQL 프로그래밍
1. MySQL의 데이터 형식
📌 데이터 형식
1️⃣ 정수형
| 데이터 형식 | 바이트 수 | 숫자 범위 |
| TINYINT | 1 | -128 ~ 127 |
| SMALLINT | 2 | -32,768 ~ 32,767 |
| INT | 4 | -21^31 ~ 21^31-1 |
| BIGINT | 8 |
- UNSIGNED : 정수형 데이터 형식 뒤에 붙일 수 있다.
2️⃣ 문자형
| 데이터 형식 | 바이트 수 |
| CHAR(개수) | 1~255 |
| VARCHAR(개수) | 1~16,383 |
- char는 고정 길이, varchar는 가변 길이 문자형이다.
- 공간 측면으로는 varchar가 좋지만, 성능 측면으로는 char가 빠르다.
3️⃣ 대량의 데이터
| 데이터 형식 | 바이트 수 | |
| TEXT 형식 | TEXT | 1~65,535 |
| LONGTEXT | 1~4,294,967,295 | |
| BLOB 형식 | BLOB | 1~65,535 |
| LONGBLOG | 1~4,294,967,295 | |
- TEXT : 블로그 내용, 소설, 영화 대본과 같은 내용을 저장할 때 사용한다.
- BLOB(Binary Long Object) : 이미지, 동영상 등의 이진 데이터 저장
LONGTEXT, LONGBLOG은 최대 4GB까지 입력 가능하다.
4️⃣ 실수형
| 데이터 형식 | 바이트 수 | 설명 |
| FLOAT | 4 | 소수점 아래 7자리까지 |
| DOUBLE | 8 | 소수점 아래 15자리까지 |
- 과학 기술용 데이터가 아니라면 FLOAT으로 충분하다.
5️⃣ 날짜형
| 데이터 형식 | 바이트 수 | 설명 |
| DATE | 3 | 날짜만 저장. YYYY-MM-DD 형식 |
| TIME | 3 | 시간만 저장. HH:MM:SS 형식 |
| DATETIME | 8 | 날짜 및 시간 저장. YYYY-MM-DD HH:MM:SS 형식 |
📌 변수의 사용
SET @변수이름 = 값 ; -- 변수 선언
SELECT @변수이름 ; -- 변수 값 출력
🟡 사용 예시
USE market_db;
SET @myVar1 = 5;
SET @myVar2 = 4.25;
SELECT @myVar1;
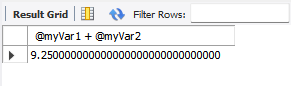
SELECT @myVar1 + @myVar2;
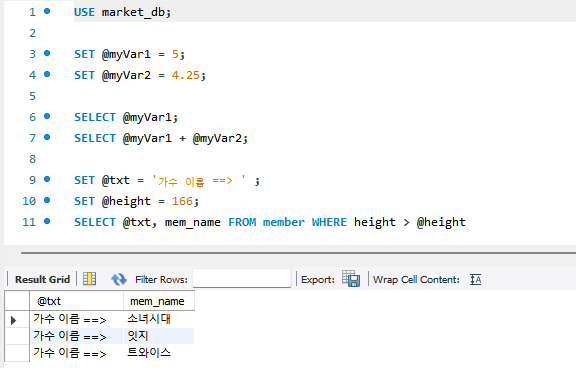
SET @txt = '가수 이름 ==> ' ;
SET @height = 166;
SELECT @txt, mem_name FROM member WHERE height > @height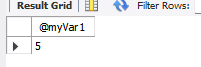
🟡 USING, PREPARE, EXECUTE
SET @count = 3;
PREPARE mySQL FROM 'SELECT mem_name, height FROM member ORDER BY height LIMIT ?';
EXECUTE mySQL USING @count;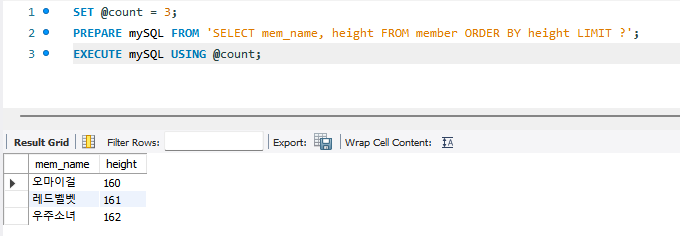
- SELECT 문의 LIMIT에는 변수를 사용할 수 없어 오류가 발생한다.
- 대신 PREPARE과 EXECUTE 예약어를 사용하라.
- ? : 나중에 채워질 값의 위치
- USING : ? 위치에 변수 값 대입
📌 데이터 형 변환
1️⃣ 명시적 형변환(Explicit Conversion)
CAST ( 값 AS 데이터_형식 [ (길이) ] )
CONVERT ( 값, 데이터_형식 [ (길이) ] )- 데이터 형식 : CHAR, SIGNED, UNSIGNED, DATE, TIME, DATETIME
🟡 실수형 → 정수형
SELECT CAST(AVG(price) AS SIGNED) '평균 가격' FROM buy;
-- 또는
SELECT CONVERT(AVG(price), SIGNED) '평균 가격' FROM buy;
🟡 정수형 → 문자형
SELECT num, CONCAT(CAST(price AS CHAR), 'X', CAST(amount AS CHAR), '=') '가격x수량',
price*amount '구매액' FROM buy;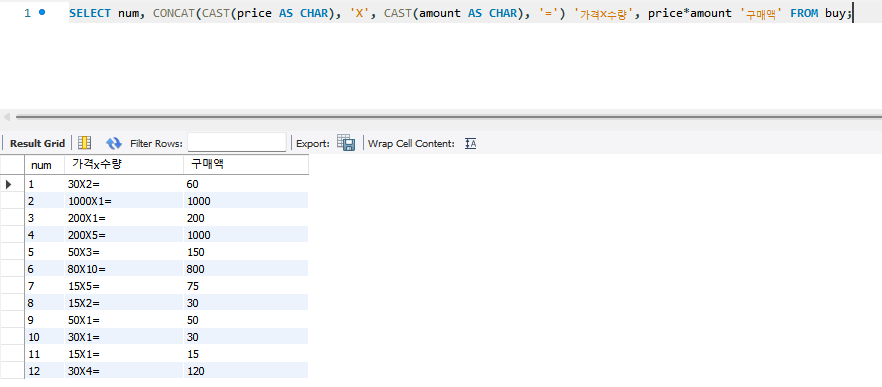
2️⃣ 암시적 형변환(Implicit Conversion)
SELECT '100' + '200'; -- 300
SELECT CONCAT('100' + '200'); -- 100200- 별도의 함수가 없이 자동 형 변환 되는 타입 연산
2. 두 테이블을 묶는 조인
- 조인(Join) : 여러 개 테이블을 서로 묶어서 하나의 결과를 내는 것
참고로 예시에서 들 member와 buy는 서로 일대다 관계에 있다.
📌 내부 조인(INNER JOIN)
일반적으로 조인이라 부르면 내부 조인을 의미한다.
두 테이블 모두 있는 내용만 JOIN이 되며, 성능 상 조인 전략중 가장 빠르다.
🟡 내부 조인의 기본
SELECT <열 목록>
FROM <첫 번째 테이블>
INNER JOIN <두 번째 테이블>
ON <조인 조건>
WHERE <검색 조건>- 3개 이상의 테이블도 가능하지만 대부분 2개로 조인한다. (3개 조인이면 모델링을 잘못했을 가능성이 크지 않을까)
- INNER JOIN 대신 JOIN라고만 써도 INNER JOIN으로 인식한다.
SELECT * FROM buy b
INNER JOIN member m
ON b.mem_id = m.mem_id
WHERE b.mem_id = 'GRL';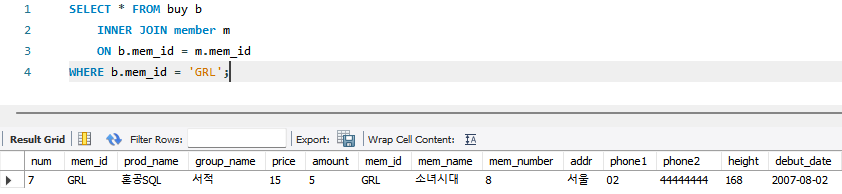
- 만약 두 테이블을 JOIN할 때 동일한 column 이름이 존재한다면 (테이블명).(열이름)으로 표기해야 한다.
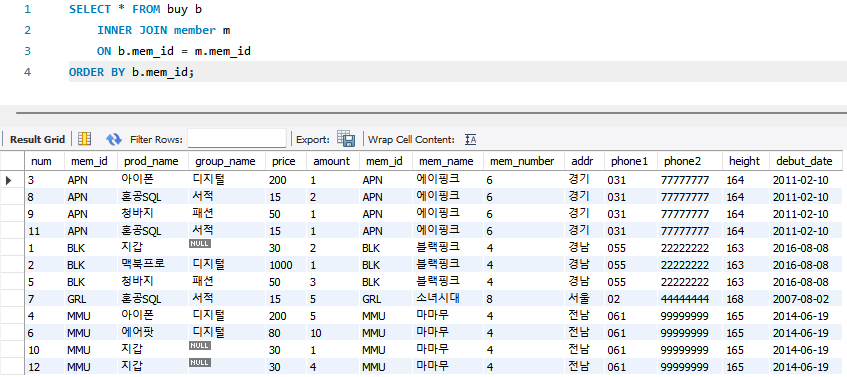
- WHERE 절을 생략하면 buy에 대한 member 정보가 모든 행에 걸쳐 결합한다.
🟡 내부 조인의 간결한 표현
SELECT b.mem_id, m.mem_name, b.prod_name, m.addr, CONCAT(m.phone1, m.phone2) '연락처' FROM buy b
INNER JOIN member m
ON b.mem_id = m.mem_id
ORDER BY b.mem_id;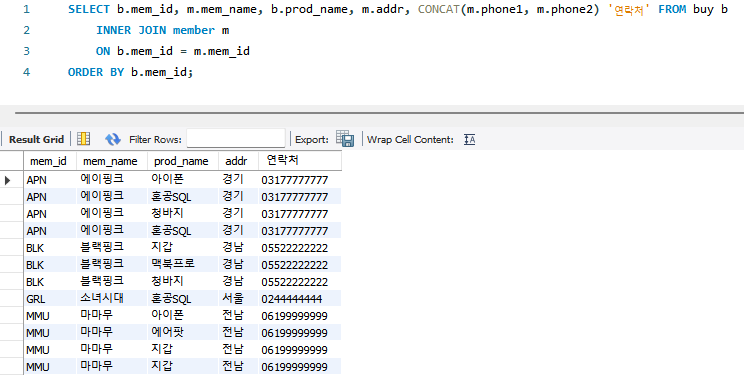
- 중복되는 column만 아니라면 굳이 테이블명을 명시하지 않아도 되지만 헷갈리니까 넣는 게 좋다.
📌 중복된 결과 1개만 출력하기
SELECT DISTINCT m.mem_id, m.mem_name, m.addr FROM buy b
INNER JOIN member m
ON b.mem_id = m.mem_id
ORDER BY b.mem_id;"우리 사이트에서 한 번이라도 구매한 기록이 있는 회원들"을 찾고 싶다면 DISTINCT절을 이용하면 된다.
내부 조인은 애초에 양쪽 테이블에 모두 데이터가 있는 경우만 결과를 가져오므로 별도의 필터링 과정조차 필요없다.
📌 외부 조인(OUTER JOIN)
SELECT <열 목록>
FROM <첫 번째 테이블(LEFT 테이블)>
<LEFT | RIGHT | FULL> OUTER JOIN <두 번째 테이블(RIGHT 테이블)>
ON <조인 조건>
WHERE <검색 조건>
🟡 외부 조인의 기본
SELECT m.mem_id, m.mem_name, b.prod_name, m.addr FROM member m
LEFT OUTER JOIN buy b
ON m.mem_id = b.mem_id
ORDER BY m.mem_id;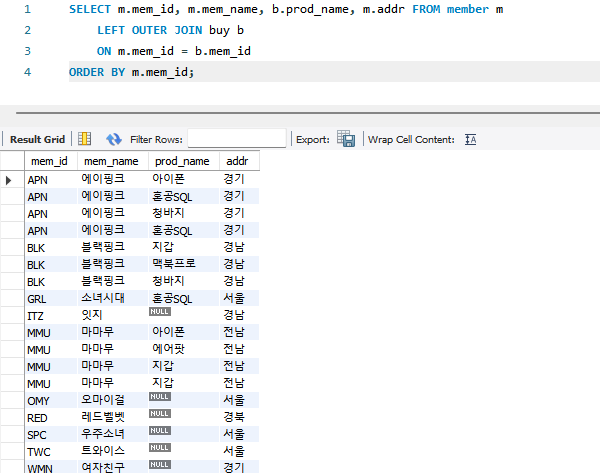
- 구매 기록이 없는 회원 정보도 함께 조회할 수 있다.
- LEFT OUTER JOIN(줄여서 LEFT JOIN)문은 "왼쪽 테이블(member)의 내용은 모두 출력되어야 한다"는 의미다.
- RIGHT OUTER JOIN으로 동일한 결과를 내고 싶다면 query에서 테이블 이름 위치만 바꾸어주면 된다.
- FULL OUTER JOIN은 오른쪽, 왼쪽 구분 없이 전부 불러온다.
🟡 외부 조인의 활용
SELECT DISTINCT m.mem_id, m.mem_name, b.prod_name, m.addr FROM member m
LEFT OUTER JOIN buy b
ON m.mem_id = b.mem_id
WHERE b.prod_name IS NULL
ORDER BY m.mem_id;회원가입만 하고 한 번도 사이트에서 구매하지 않는 회원들을 응징하기 위해 리스트를 뽑을 수 있다.
OUTER JOIN은 일반적으로 속도가 빠르지 않다.
위의 쿼리문은 쓸 데 없이 모든 테이블을 다 골라내고, 마지막에 필터링을 하고 있는데 의미가 없는 행위다.
애초에 구매를 아무 것도 하지 않았다면 mem에 매핑된 buy row 자체가 없을 텐데..
SELECT m.mem_id, m.mem_name, m.addr
FROM member m
WHERE NOT EXISTS (
SELECT 1
FROM buy b
WHERE m.mem_id = b.mem_id
AND b.prod_name IS NOT NULL
)
ORDER BY m.mem_id;EXISTS 절을 사용했다면 OUTER JOIN절 자체를 사용할 필요가 없다.
SELECT m.mem_id, m.mem_name, m.addr
FROM member m
LEFT JOIN buy b
ON m.mem_id = b.mem_id
WHERE b.mem_id IS NULL OR b.prod_name IS NULL
ORDER BY m.mem_id;그게 아니라면 적어도 LEFT OUTER JOIN을 할 때 필터링을 하면 보다 속도를 높일 수 있었을 것이다.
📌 기타 조인
여기서부턴 거의 사용 안 되므로 교양처럼 알고 넘어가면 될 듯 하다. 정처기 시험 문제 정도로 나오려나?
🟡 상호 조인(Cross Join)
SELECT * FROM buy CROSS JOIN member;- 한쪽 Table의 row마다 다른 쪽 Table 모든 row를 JOIN 시킨다.
- 카티션 곱(cartesian product)이라고도 부른다.
- ON 구문을 사용할 수 없다.
- 랜덤으로 Join하므로 결과 내용이 의미가 없다.
- 상호 조인의 주 용도는 테스트를 위한 대용량 데이터를 생성할 때다.
아마 인공지능 학습이나 빅데이터 분야의 개발자 분들께서 사용하지 않을까 싶다. (단순 추측)
🟡 자체 조인(Self Join)
SELECT <열 목록>
FROM <테이블>
INNER JOIN <테이블>
ON <조인 조건>
WHERE <검색 조건>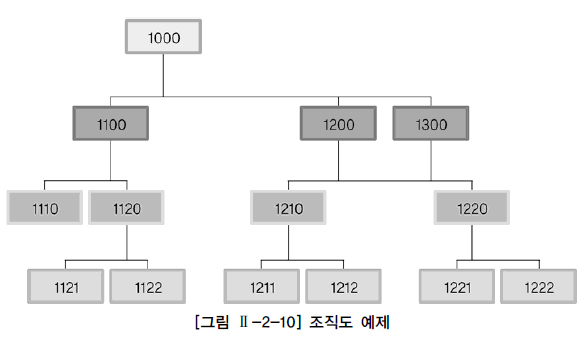
- 테이블을 따로 분리하지는 않고, 하나의 테이블로 JOIN을 걸면 SELF JOIN이 된다.
- 마치 하나의 테이블을 동일한 정보가 담긴 두 개의 테이블로 다룰 수 있다.
- 실무에서 많이 사용하진 않지만, 조직도에서 전화번호를 찾는 경우에 사용할 수 있다.
SELECT a.emp "직원", b.emp "직속상관", b.phone "직속상관연락처"
FROM emp_table a
INNER JOIN emp_table b
ON a.manager = b.emp
WHERE a.emp = "경리부장";- 위의 쿼리문은 "경리부장" 레코드에 직송상관에 매칭되는 "직속상관" 레코드를 찾은 후, 직속상관 연락처를 알아낼 수 있다.
계층형 질의와 셀프 조인
1. 계층형 질의 테이블에 계층형 데이터가 존재하는 경우 데이터를 조회하기 위해서 계층형 질의(Hierarchical Query)를 사용한다. 계층형 데이터란 동일 테이블에 계층적으로 상위와 하위 데이터가
dataonair.or.kr
뭔가 엄청 심의해보여서 읽어보는 재미가 있었다.
3. SQL 프로그래밍
DELIMITER $$
CREATE PROCEDURE 스토어드_프로시저_이름()
BEGIN
...
END $$ -- 스토어드 프로시저 종료
DELIMITER ;
CALL 스토어드_프로시저_이름() -- 실행- 스토어드 프로시저(Stored Procedures) : MySQL에서 프로그래밍 기능이 필요할 때 사용하는 Database 객체
- SQL 프로그래밍은 기본적으로 Stored Procedures에 들어가야 한다.
- 직접 Query로 작성할 수도 있다.
- 구분 문자(DELIMITER)는 /, &, @ 등을 사용해도 괜찮지만 보통 $$를 사용한다.
📌 IF
IF <조건식> THEN
...
END IF;
🟡 IF문 기본 형식
DROP PROCEDURE IF EXISTS ifProc1;
DELIMITER $$
CREATE PROCEDURE ifProc1()
BEGIN
IF 100 = 100 THEN
SELECT "100은 100이다!";
END IF;
END $$ -- 스토어드 프로시저 종료
DELIMITER ;
CALL ifProc1() -- 실행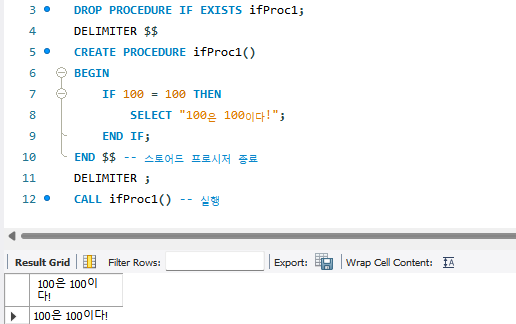
🟡 IF ~ ELSE
DROP PROCEDURE IF EXISTS ifProc2;
DELIMITER $$
CREATE PROCEDURE ifProc2()
BEGIN
DECLARE num INT;
SET num = 200;
IF num = 100 THEN
SELECT "100은 100이다!";
ELSE
SELECT "100이 아니다.";
END IF;
END $$ -- 스토어드 프로시저 종료
DELIMITER ;
CALL ifProc2(); -- 실행- DECLARE 예약어로 변수를 선언할 수 있다.
🟡 IF문 활용
DROP PROCEDURE IF EXISTS ifProc3;
DELIMITER $$
CREATE PROCEDURE ifProc3()
BEGIN
DECLARE debutDate DATE;
DECLARE curDate DATE;
DECLARE days INT;
SELECT debut_date INTO debutDate
FROM market_db.member
WHERE mem_id = 'APN';
SET curDate = CURRENT_DATE();
SET days = DATEDIFF(curDate, debutDate);
IF (days/365 >= 5) THEN
SELECT CONCAT("데뷔한 지 ", days, "일이나 지났네요.");
ELSE
SELECT "데뷔한 지 " + days + "일밖에 안되었네요.";
END IF;
END $$ -- 스토어드 프로시저 종료
DELIMITER ;
CALL ifProc3(); -- 실행
- SELECT INTO를 이용해서 변수에 값을 할당할 수 있다.
에이핑크가 데뷔한 지 12년이나 지났다는 게 더 놀랍다....
✒️ 날짜 관련 내장 함수
• CURRENT_DATE() : 오늘 날짜를 알려준다.
• CURRENT_TIMESTAMP() : 오늘 날짜 및 시간을 함께 알려준다.
• DATEDIFF() : 날짜2부터 날짜1까지 일수로 며칠인지 알려준다.
📌 CASE
CASE
WHEN 조건1 THEN
...
WHEN 조건1 THEN
...
WHEN 조건1 THEN
...
...
ELSE
...
END CASE;
🌱 예제
| 총 구매액 | 회원 등급 |
| 1,500 ~ | 최우수고객 |
| 1,000 ~ 1,499 | 우수고객 |
| 1 ~ 999 | 일반고객 |
| 0 | 유령고객 |
CASE
WHEN (총구매액 >= 1500) THEN "최우수고객"
WHEN (총구매액 >= 1000) THEN "우수고객"
WHEN (총구매액 >= 1) THEN "일반고객"
ELSE "유령고객"
END최종적으로 위의 CASE문을 돌려야 할 텐데, 우선 총구매액을 구해야 한다.
따라서 전처리 과정을 선행할 필요가 있다.
SELECT m.mem_id, m.mem_name, SUM(price*amount) "총구매액"
FROM buy b
RIGHT JOIN member m
ON b.mem_id = m.mem_id
GROUP BY m.mem_id
ORDER BY SUM(price*amount) DESC;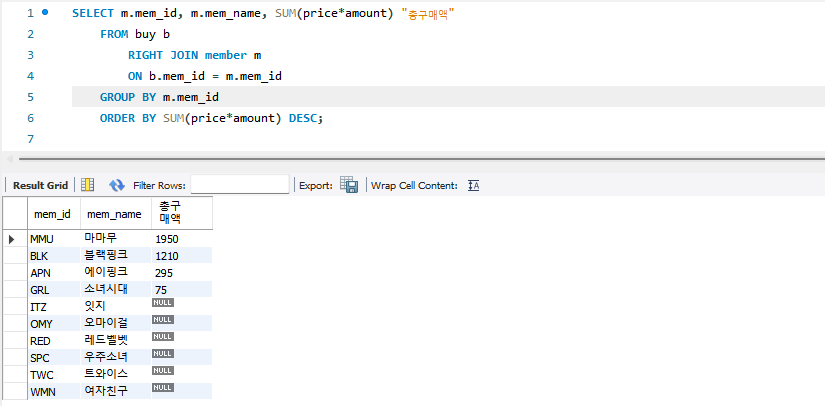
- 상품을 구매하지 않은 멤버도 결과에 포함시키기 위해 OUTER JOIN을 사용했고, mem_id는 buy Table이 아닌 member Table의 id를 참조했다.
DROP PROCEDURE IF EXISTS ifProc4;
DELIMITER $$
CREATE PROCEDURE ifProc4()
BEGIN
SELECT m.mem_id, m.mem_name, SUM(price*amount) "총구매액",
CASE
WHEN (SUM(price*amount) >= 1500) THEN "최우수고객"
WHEN (SUM(price*amount) >= 1000) THEN "우수고객"
WHEN (SUM(price*amount) >= 1) THEN "일반고객"
ELSE "유령고객"
END "회원등급"
FROM market_db.buy b
RIGHT JOIN market_db.member m
ON b.mem_id = m.mem_id
GROUP BY m.mem_id
ORDER BY SUM(price*amount) DESC;
END $$ -- 스토어드 프로시저 종료
DELIMITER ;
CALL ifProc4(); -- 실행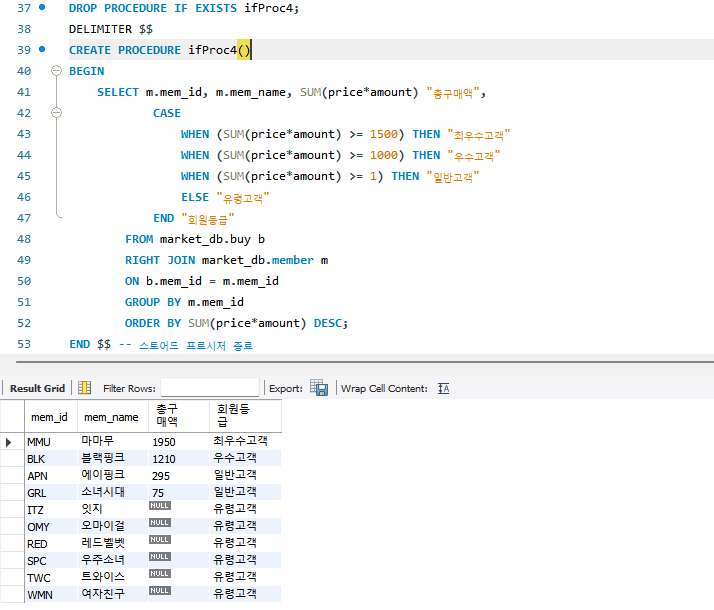
📌 WHILE
🟡 WHILE 문의 기본
WHILE <조건식> DO
...
END WHILE;
DROP PROCEDURE IF EXISTS whileProc;
DELIMITER $$
CREATE PROCEDURE whileProc()
BEGIN
DECLARE i INT;
DECLARE hap INT;
SET i = 1;
SET hap = 0;
WHILE (i <= 100) DO
SET hap = hap + i;
SET i = i + 1;
END WHILE;
SELECT "1부터 100까지의 합 ==> ", hap;
END $$ -- 스토어드 프로시저 종료
DELIMITER ;
CALL whileProc(); -- 실행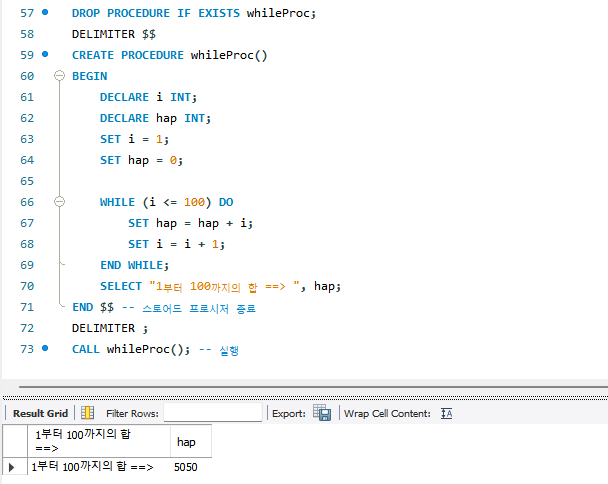
🟡 WHILE 문의 응용
DROP PROCEDURE IF EXISTS whileProc2;
DELIMITER $$
CREATE PROCEDURE whileProc2()
BEGIN
DECLARE i INT;
DECLARE hap INT;
SET i = 1;
SET hap = 0;
myWhile: -- 레이블 지정
WHILE (i <= 100) DO
IF (i%4 = 0) THEN
SET i = i + 1;
ITERATE myWhile; -- 지정한 label로 돌아감
END IF;
SET hap = hap + i;
IF (hap > 1000) THEN
LEAVE myWhile; -- 반복문 탈출
END IF;
SET i = i + 1;
END WHILE;
SELECT "1부터 100까지 합(4의 배수 제외, 1000 넘으면 종료) ==> ", hap;
END $$ -- 스토어드 프로시저 종료
DELIMITER ;
CALL whileProc2(); -- 실행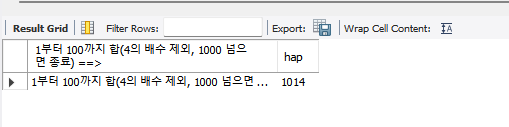
- ITERATE [레이블] : continue와 동일
- LEAVE [레이블] : break와 동일
📌 동적 SQL
🟡 PREPARE와 EXECUTE
PREPARE myQuery FROM 'SELECT * FROM member WHERE mem_id = "BLK"'; -- 쿼리 저장
EXECUTE myQuery; -- 실제 쿼리 실행 시점
DEALLOCATE PREPARE myQuery; -- 쿼리 삭제- PREPARE : 쿼리문 저장
- EXECUTE : 저장한 쿼리문 실행
- DEALLOCATE PREPARE : 저장한 쿼리문 삭제
🟡 동적 SQL의 활용
DROP TABLE IF EXISTS gate_table;
CREATE TABLE gate_table (id INT AUTO_INCREMENT PRIMARY KEY, entry_time DATETIME);
SET @curDate = CURRENT_TIMESTAMP();
PREPARE myQuery FROM 'INSERT INTO gate_table VALUES(NULL, ?)';
EXECUTE myQuery USING @curDate;
DEALLOCATE PREPARE myQuery;
SELECT * FROM gate_table;
Spring Boot에서 JPA가 생성한 쿼리문을 보면 ?로 비워져 있는 값들이 있고, 나중에 "execute를 쓰면 쿼리문이 날아간다" 정도로만 이해하고 있었는데 이제서야 원리가 이해가 되기 시작했다. 😄