📌 동시성 프로그래밍
💡 동시성 프로그래밍에서는 안전성(safety)과 응답 가능(libeness) 상태를 유지해야 한다.
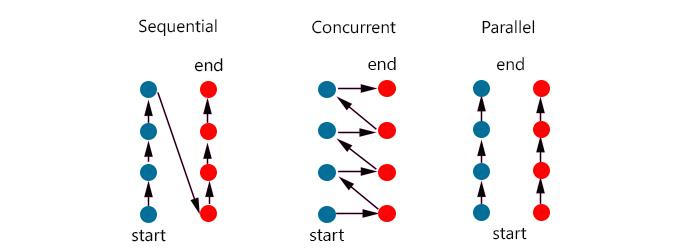
| 동시성 | 병렬성 |
| 동시에 실행되는 것처럼 보이는 것 | 실제로 동시에 여러 작업이 처리되는 것 |
| 싱글 코어에서 멀티 스레드 동작시키는 방식 | 멀티 코어에서 멀티 스레드 동작시키는 방식 |
| 한번에 많은 것을 처리 | 한번에 많은 일을 처리 |
| 논리적 개념 | 물리적 개념 |
- 주류 언어 중, 동시성 프로그래밍 측면에서 자바는 항상 앞서갔다.
- Java 7의 고성능 병렬 분해(parallel decom-position) 프레임워크인 포크-조인(fork-join) 패키지
- Java 8의 Stream.parallel() 만으로 파이프라인 병렬 실행
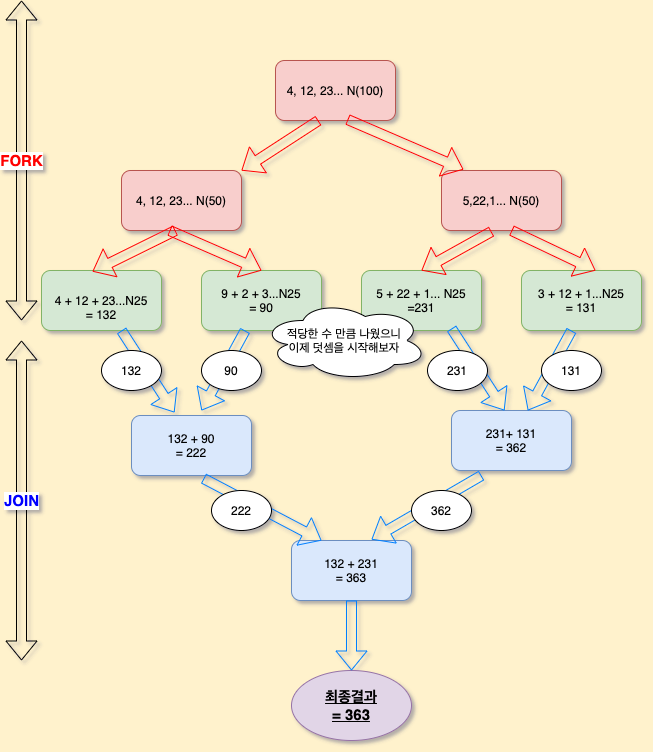
✒️ 포크-조인(Fork-Join) 프레임 워크• 포크 단계에서 전체 데이터를 서브 데이터로 분리
• 서브 데이터를 멀티 코어에서 병렬 처리
• 조인 단계에서 서브 결과를 결합해 최종 결과 생성
📌 Stream 병렬화 문제점
💡 데이터 소스가 Stream.iterate거나 중간 연산으로 limit을 쓰면 파이프라인 병렬화 성능 개선이 힘들다.
public class MersennePrime {
private static final BigInteger TWO = BigInteger.valueOf(2);
public static void main(String[] args) {
primes().map(p -> TWO.pow(p.intValueExact()).subtract(BigInteger.ONE))
.filter(mersenne -> mersenne.isProbablePrime(50))
.limit(20)
.forEach(mp -> System.out.println(mp.bitLength() + ": " + mp));
}
static Stream<BigInteger> primes() {
return Stream.iterate(TWO, BigInteger::nextProbablePrime);
}
}(Item 45의 메리센 소수 생성 프로그램)
- 성능 개선을 위해 parallel()호출 시 응답 불가(liveness failure) 상태가 된다.
- 프로그램이 느려진 이유는 Stream 라이브러리가 파이프라인을 병렬화하는 방법을 찾지 못했기 때문.
- limit의 문제점
- 파이프라인 병렬화는 limit을 다룰 때 CPU 코어가 남으면, 원소를 몇 개 더 처리하고 이후 결과를 버린다.
- 쿼드 코어 시스템이라면 20번째 연산 시점에 3개의 코어가 한가하므로 21, 22, 23번째 메르센 소수를 찾고 있다. 이는 20번 째 연산보다 2배, 4배, 8배의 시간이 필요한 작업이다.
- 새로운 메르센 소수를 찾는 것이 이전 소수를 찾을 때보다 두 배 정도 더 걸린다.
- 즉, 원소 하나 계산 비용이 그 이전까지 원소 전부를 계산한 비용을 합친 정도가 소요된다.
- 파이프라인 병렬화는 limit을 다룰 때 CPU 코어가 남으면, 원소를 몇 개 더 처리하고 이후 결과를 버린다.
- 스트림 파이프라인을 마구잡이로 병렬화하면 안 된다.
📌 Stream 병렬화와 자료 구조
- 대체로 Stream의 Source가 다음과 같을 때 별렬화 효과가 가장 좋다.
- ArrayList
- HashMap, HashSet
- ConcurrentHashMap
- 배열
- int 범위, long 범위
- 데이터를 원하는 크기로 정확하고 손쉽게 나눌 수 있다. → 다수의 스레드에 분배하기 좋다.
- Stream이나 Iterable의 spliterator()로 얻은 Spliterator가 나누는 작업 담당
- 참조 지역성(locality of reference)이 뛰어나다.
- 이웃한 원소의 참조들이 연속된 메모리에 저장되어 있다.
- 다량의 데이터 처리를 위한 벌크 연산 병렬화에 중요하다.
- 참조 지역성이 낮으면 스레드는 데이터가 주 메모리에서 캐시 메모리로 전송되어 오는 시간 동안 지연된다.
📌 Stream 병렬화와 종단 연산
- 종단 연산 중 병렬화에 가장 적합한 것은 축소(reduction)
- 파이프라인에서 만들어진 모든 원소를 하나로 합치는 작업
- Stream의 reduce 메서드 중 하나, 혹은 min, max, count, sum
- anyMatch, allMatch, noneMatch처럼 조건에 맞으면 바로 반환되는 메서드도 적합
- 가변 축소(mutable reduction)를 수행하는 collect나 순차적인 연산이면 적합하지 않다.
- collect의 경우 컬렉션 합치는 부담이 크다.
- 직접 구현한 Stream, Iterable, Collection이 병렬화 이점을 누리게 하고 싶다면 spliterator 메서드를 재정의하고 결과 Stream 병렬화 성능을 강도 높게 테스트하라. (쉽지 않은 일이다.)
📌 안전 실패와 Stream 명세
💡 Stream을 잘못 병렬화하면 성능 저하 뿐만 아니라 결과 자체가 잘못되거나 예상 못한 동작이 발생 가능하다.
- 안전 실패(safety failure) : 결과가 잘못되거나 오동작하는 것
- 병렬화한 파이프라인이 사용하는 mappers, filters, 프로그래머가 제공하는 다른 함수 객체가 명세대로 동작하지 않을 때 발생할 수 있다.
- Stream 명세는 사용되는 함수 객체에 대한 엄중한 규약을 정의해놓았다.
- Stream의 reduce 연산에 쓰이는 누적기(accumulator)와 결합기(combiner) 함수는 아래 규약을 따른다.
- associative : 결합 법칙을 만족하고,
- non-interfering : 간섭받지 않고,
- stateless : 상태를 갖지 않아야 한다.
- 병렬 수행만 아니라면, 요구사항을 지키지 못하는 상태라도 파이프라인을 순차적으로 수행했을 때는 올바른 결과를 얻을 수도 있다.
📌 Stream 병렬화 성능 향상 추정
- 이상의 모든 조건을 만족해도 파이프라인을 수행하는 진짜 작업이 병렬화에 드는 추가 비용을 상쇄해야 한다.
- (스트림 안의 원소수) * (원소당 수행되는 코드 줄 수)가 최소 수십만은 되어야 성능 향상이 된다.
📌 Stream 병렬화를 할 경우는 거의 없다.
- Stream 병렬화는 오직 성능 최적화 수단이므로, 변경 전후로 성능 테스트를 통해 사용 가치를 판단해야 한다.
- 조건만 잘 갖춰지면 parallel 메서드 호출 하나로 거의 프로세서 코어 수에 비례하는 성능을 누릴 수도 있다.
- 예를 들어, 소수 계산 스트림 파이프라인에서 효율적일 수 있다.
- 그러나 n이 크다면, 레머의 공식(Lehmer's Formula)라는 알고리즘을 쓰는 것이 더 효율적이다.
- 무작위 수들로 이루어진 Stream 병렬화에는 ThreadLocalRandom 혹은 SplittableRandom 인스턴스를 사용하라.
- ThreadLocalRandom : 단일 스레드에서 사용
- SplittableRandom : 병렬화하면 성능이 선형으로 증가한다.
- Random : 모든 연산을 동기화하므로 병렬 처리하면 최악의 성능을 보인다.