DRF로 진짜 쉽게 할 수 있는 건데..
스프링은 분명 아는 개념을 다른 방식으로 구현할 뿐인데, 초반에 무슨 소린지 감이 안 와서 제법 힘들었다.
그래도 열심히 정리를 해보도록 하자.
쓰다보니 느낀 건데, JPA와 영속성 컨텍스트에 대해서도 한 번 정리를 해두는 게 좋을 것 같다는 생각이 든다.
엔티티 매핑도...할 거 엄청 많네?
목차
1. 패러다임의 불일치
2. 연관관계 정의
3. 연관관계 매핑
1. 패러다임의 불일치
JPA란 자바 표준 ORM 기술 표준이다.
연관 관계에 대한 설명에 들어가기 전에 왜 필요한지부터 간략하게나마 짚고 넘어가보자.
Application은 규모가 커질수록 복잡도가 증가하는 것은 누구나 알 수 있는 사실이다.
로직은 제쳐두고 도메인만 따져보았을 때, 복잡성을 제어하기 위해 Spring의 객체와 DB의 테이블을 잘 관리해야 한다.
그런데 여기서 문제가 발생한다.
객체는 상속, 추상화, 캡슐화, 다형성 등의 특징으로 인해 복잡성 제어가 가능한데,
이를 DB에 저장하려고 보니 정작 테이블은 상속이라는 기능이 없다. (띠용)
만약, 이 상황에서 1개의 그룹에 속해있는 N개의 유저 정보를 저장하려면 어떻게 해야할지 감이 오는가?
조회는? 삭제는? 수정은??
물론 할 수야 있지만, 고작 한 개의 작업을 처리하는데 방대한 양의 코드와 무분별한 반복이 들어가야 할 것이다.
이게 바로 객체 지향 프로그래밍과 관계형 데이터 베이스의 패러다임 불일치로 인한 이슈인데
이 문제를 JPA가 개발자 대신에 처리해준다.
하지만 JPA의 세부 동작을 살펴보려면 꽤나 많은 분량의 글이 뽑힐 것 같으므로, 해당 내용은 따로 다루도록 하자.
2. 연관관계 정의
엔티티 매핑은 하나의 객체와 하나의 테이블의 관계를 연관짓는 것이라면,
연관관계 매핑은 테이블과 테이블 간의 관계성과 객체 간의 관계성을 서로 매칭시킨다고 보면 된다.
엥, 이게 대체 뭔 소리죠?
JPA는 결국 객체와 테이블 간의 패러다임 불일치로 인해 나온 ORM 기술이라고 했었는데,
ORM은 간단하게 SQL문으로 테이블 관리하던 것을 프로그램 언어로 쉽게쉽게 처리하는 것이다.
하지만 객체는 테이블하고는 엄연히 다르기 때문에 프레임 워크가 이해할 수 있는 관계를 정의해주어야 하는 것이다.
우선, 기본적인 개념들을 알고 넘어갈 것인데 막히는 개념이 있다면 이렇게 생각하면 된다.
"DB의 table을 Spring에서 객체로 다룰 수 있게 하려고 별 짓을 다하고 있는 거구나!"
1. Keyword
- 방향 : 단방향, 양방향
- 연관 관계 주인 : 양방향 관계에서 FK값을 가지고 있는 도메인
- 다중성 : 일대일, 일대다, 다대일, 다대다
2. 방향
방향에는 단방향, 양방향이 있다.
기본적으로 PK와 FK에 대한 지식이 있다고 판단하고 넘어갈 것이다.
[DB] Data Modeling
목차 1. 개념적 데이터 모델링 (feat. ERD) 2. 논리적 데이터 모델링 3. 물리적 데이터 모델링 4. 효율적 데이터 모델링 5. 참고 자료 1. 개념적 데이터 모델링 (feat. ERD) 모델링 이전에 가장 중요한 건
jaeseo0519.tistory.com
혹시나 모른다면 참고.
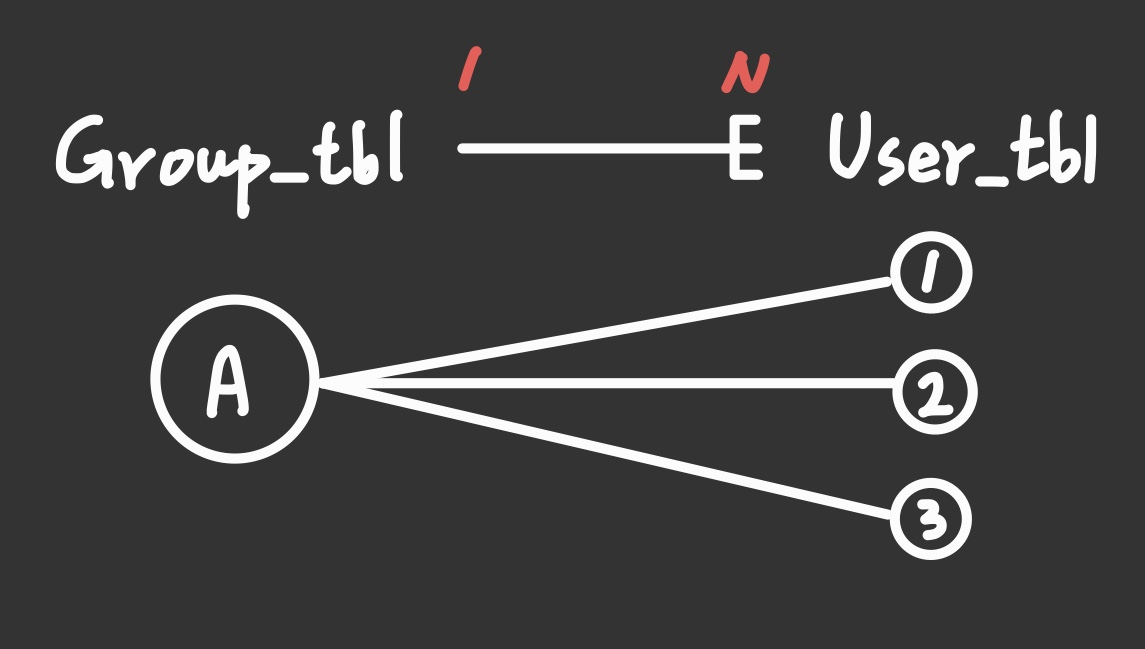
DB에서는 FK만 알고 있으면 양쪽 테이블로 Join이 가능하다. 참조가 된다고 생각하면 된다.
user1, user2, user3이 GroupA의 PK값으로 하는 FK를 가지고 있다고 한다면,
user_tbl에서 정방향으로 GroupA를 참조할 수도 있고 역방향으로 GroupA를 참조하고 있는 user1, 2, 3도 알 수 있다.
문제는 이 데이터를 자바 객체로 끌고왔을 때 어떻게 할 것인가가 관건이 되는 것이다.
애석하게도 스프링 객체는 FK 하나만으로 어떻게 할 수가 없다.
그래서 도메인 안에 참조 필드를 만들어서 인위적으로 관계를 매핑해주어야 하는데,
단방향은 말 그대로 User_tbl → Group_tbl 같이 한 쪽 방향으로만 참조가 가능하게 만드는 것이고
양방향은 User ↔ Group 역방향까지 추가해놓은 것이다. (사실상 단방향 2개 만들면 양방향이다.)
필드를 추가해뒀으므로 GroupA의 데이터를 불러오면 Group 도메인 안의 User 필드에 연관 관계가 매핑된 유저 정보가 들어오는 것이다.
🤔 양방향이 무조건 좋은가?
위에서 설명한 바를 잘 이해하면 한 가지 의문이 들었을 수 있다.
GroupA를 호출하면 user1,2,3의 정보가 GroupA의 필드에 쭉 들어오게 될 텐데,
GroupA에 10,000명의 유저가 가입되어 있다고 가정해보자.. 여기까지는 뭐 그럴 수 있다고 치더라도 GroupA가 과연 유저하고만 매핑이 되어 있을까..? 그렇지 않다.
엄청 많은 엔티티들과 양방향 관계를 맺게될 경우, Group Class 하나만 놓고 봐도 복잡성이 대폭 증가한다.
그렇다면 언제 단방향, 양방향으로 매핑할 지 구분할 수 있을까?
양방향 관계를 정의해두면 탐색이 편리한 것은 사실이지만, 굳이 역방향 탐색이 필요 없는 경우라면 양방향 매핑은 사치일 수 있고 코드의 복잡성만 증대시키는 결과를 초래한다.
따라서 매핑 이전에 '역방향 참조가 꼭 필요할까?'를 염두에 두고 개발을 하면 된다.
3. 연관 관계 주인
연관관계를 가지고 있는 두 도메인 중 FK(Foreign Key)를 가지고 있는 객체라고 보면 된다.
개념 자체는 그다지 어려운 게 아닌데, 대체 이 간단한 내용을 '연관 관계 주인'이라는 표현까지 써가며 여러 블로그에서 장황하게 설명하고 있나 싶었는데 JPA가 헷갈리지 않게 설정을 잘 해줘야 하기 때문이다.
단방향 관계에서는 굳이 필요 없지만, 양방향 관계에선 주인이 누구냐가 중요해진다.
위에서 언급했듯이 개발자가 보기 편해서가 아니라, 두 도메인 간의 실질적인 관계에 대해 JPA에게 설명해주는 것이다.
'주인'이라는 용어가 내포하는 의미에 따라서 fk를 쥐고 있는 객체는 두 객체 사이의 관계에 대한 CRUD를 모두 수행할 수 있지만, 주인이 아니라면 Read만 가능하다.

누가 주인이냐 아니냐를 정하는 것은 굉장히 단순하다.
주인이 아닌 쪽에 (mappedBy = '필드명')을 넣어주면 그 뒤로는 JPA가 알아서 판단할 수 있다.
💡 연관 관계 주인을 지정하는 좀 더 명확한 이유
Group을 참조하는 User_tbl이 있을 때, GroupA에 속해있던 user1이 그룹을 탈퇴하거나 (여러 그룹에 가입할 수 없다는 조건 하에)다른 그룹으로 이동하게 되는 경우가 발생했다고 치자.
양방향 매핑이므로 GroupA에서도 user1을 호출할 수 있고, user1에서도 GroupA를 탐색할 수 있다.
그렇다면 User 도메인에서 setGroup을 하는 게 맞을까, Group 도메인에서 getUser로 리스트를 불러오고 수정해주는 게 맞을까가 관건이 된다.
사실 둘 다 해줘야 한다. 그래야 user1이 탈퇴했는데, GroupA에서 user1을 데려오는 짓을 하지 않는다.
다만 위의 방법과는 조금 다르게 진행되어야 하고, 관계를 관리하는 주체는 FK를 가지고 있는 연관관계의 주인 User 도메인에서 해결해야할 문제다.
이렇게 해야지 JPA도 혼란을 겪지 않고 일을 잘 해낼 수 있다.
3. 연관관계 매핑
단방향을 기준으로 설명하긴 할 건데, 양방향도 언급하긴 할 것이다.
근데 양방향이라고 해봐야 단방향 2개 만들고 연관관계 주인 지정해주는 정도의 차이밖에 없다.
거기서 전략을 어떻게 세우냐에 따라 좀 더 귀찮은 작업을 수반하긴 하지만, 이번 포스팅은 정말 간단한 내용만 다룰 것이다.
그리고 위에서 굳이 양방향 필요한 거 아니면 단방향으로 해도 돼요~ 라고 자유도 높은 게임처럼 말했지만, 그렇진 않다.
다대다 관계는 미완성 관계라고 할 정도로 사용이 금지되었다고 보면 되고,
1이 관계의 주인인 일대다 관계의 경우엔 단방향, 양방향 둘 다 실무에서 썼다가 깨질 수 있다.
그런데 애초에 이런 식으로 매핑하려고 하는 사고 방식이 이해가 안 되긴 하지만..
1. 일대일(1:1)
얼마나 간단하냐면 @OneToOne 어노테이션 걸어주고 @JoinColumn을 걸어주면 된다.
User 도메인과 Blog 도메인을 1대 1로 매칭시켜보자.
@Entity(name="blog")
@Table(name="BLOG")
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Blog {
(...)
@OneToOne
@JoinColumn(name="USER_ID")
private UserDomain owner;
(...)
}나는 일단 블로그가 연관 관계의 주인이라고 가정하고 코드를 작성해보았다.
2개의 어노테이션을 걸어서 UserDomain 필드를 만들어 owner라는 이름을 지어주었다.
그럼 이제 User 도메인에서 똑같이 1대 1로 대응시켜주면 된다.
(밑에 작업을 안 하면 단방향)
@Entity(name="user")
@Table(name="USER")
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class UserDomain {
(...)
@OneToOne(mappedBy = "owner")
@ToString.Exclude
private Blog blog;
(...)
}@ToString.Exclude는 순환참조에 걸려서 무한 반복이 돌길래 걸어둔 건데 이 내용은 이슈 컨트롤에서 따로 다룰 것이다.
연관 관계의 주인인 Blog 도메인이 필드명을 owner라고 지워놨기 때문에 User 도메인에선 "owner" 필드와 매핑 시켜달라는 의미로 mappedBy 키워드를 써주면 된다.
🧐 연관 관계의 주인은 누가 되어야 하는가?
보통 1:N 관계에선 N쪽이 가진다.
다만 1:1의 경우에는 약간 애매해질 때가 많은데 위의 코드를 예시로 들었을 때, User가 주인인 게 나을지, Blog가 주인이 되는 게 나을지가 이슈가 된다.
이걸 왜 신경써야 하냐면 테이블은 한 번 생성되고 나면 나중에 수정이 불가능하다고 봐야 하기 때문이다.
아무한테나 FK값 던져줬다가 나중에 문제가 생길 수 있다.
그렇다면 나중에 문제가 생기는 경우가 무엇이 있을지를 떠올려보면된다.
1:1 관계가 1:N 관계로 바뀌어야 하는 경우를 생각해보자.
하나의 Blog를 여러 유저가 관리하는 경우보단, 하나의 User가 여러 블로그를 가질 수 있는 것이 현실적으로 가능성이 높다.
물론 티스토리나 노션처럼 여러 유저가 참여할 수 있는 하나의 워크 스페이스를 마련하는 경우도 존재할 수 있긴 한데..애초에 이러면 다대다 관계가 되니까 테이블 분리를 해야 하는 이슈이므로 배제하도록 하자.
종종 명확한 정답이라고 볼 수 없는 케이스가 나올 텐데, 여러 경우의 수를 고려하여 가장 적합하다고 생각되는 도메인에 연관 관계의 주인을 던져주면 된다.
2. 다대일(N:1)
일대일이랑 똑같긴 한데, 주의해주어야 할 것이 있다.
우선 다대일은 '다'쪽에 FK를 넘겨주는 것이 일반적이고, 필드로 받을 때 1의 입장을 고려해야 한다.
1대1은 어차피 하나의 객체에 다른 하나의 객체가 연결되지만, Category와 Post 테이블이 1대 N으로 매핑되어 있으면 Category의 post 필드에는 N개의 객체가 들어오는 것이 된다.
감이 오는가? 그렇다. List로 받아주어야 한다.
@Entity(name="Post")
@Table(name="POST")
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Post {
(...)
@ManyToOne(fetch = FetchType.EAGER)
@JoinColumn(name="BLOG_ID")
private Blog blog;
(...)
}fetch는 나중에 다른 포스팅에서 다룰 내용이긴 한데 ManyToOne의 기본 전략은 FetchType.Lazy다.
1개의 Category에 100,000개의 Post가 있을 때, 굳이 당장 불러올 필요가 없다면 Lazy를 사용하지만
당장 화면에 죄다 뿌려야 하는 상황이라면 Eager 전략을 쓴다.
그냥 본인이 만들 UI에 맞춰서 알아서 잘 쓰자.
3. 일대다(1:N)
일대다를 쓰긴 하는데, 일대다를 연관관계의 주인으로 매핑하는 경우는...그냥 하지 않는 게 좋다.
여기서는 그냥 위의 Post 객체의 다대일 관계와 묶는 것만 하고 끝낼 것이다.
참고로 Post 기준에선 N:1이지만 Category 입장에선 1:N이므로 OneToMany를 사용해야 한다.
@Entity(name="Category")
@Table(name="CATEGORY")
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Category {
(...)
@OneToMany(mappedBy = "category")
@ToString.Exclude
private List<Post> posts = new ArrayList<>();
(...)
}마찬가지로 mappedBy를 걸어주는 센스가 필요하다.
4. 다대다(N:N) - 중계 테이블
다대다 관계는 미완성 관계라고 간주한다.
너무 복잡해지는 관계를 개발자가 파악할 수 없게 되기 때문에, 데이터와 테이블이 늘어날 수록 제어가 불가능한 수준으로 빠질 수 있다.
이런 경우에는 보통 중계 테이블을 만들어서 일대다, 다대일 관계로 풀어버린다.