[대규모 시스템 설계] 12장. 채팅 시스템 설계
📕 목차
1. 채팅 시스템
2. 프로토콜
3. 개략적 설계안
4. 데이터 모델
5. 상세 설계
6. 개인적인 추가 고민
1. 채팅 시스템
📌 과거와 현재 채팅 시스템 차이
💡 책에 나온 내용은 아니고, 예전에 어딘가에서 읽었던 내용인데 출처가 기억 안 나서 정확성이 떨어집니다.

과거에는 채팅 프로그램을 위해 서버가 하는 일은 그저, 두 클라이언트의 연결을 돕는 일이 고작이었다.
아마, stateless 환경의 HTTP 프로토콜 방식만으로는 한계가 있었기 때문이 아닐까 싶긴 한데, 그렇게 할 수밖에 없었던 이유를 당췌 못 찾겠다.
아무튼, 1:1 실시간 소통이 고작이라면 위 방식도 기능을 제공함에 있어 문제가 되진 않을 것이다. (데이터 보존 원칙같은 건 전부 무시하고, 순수하게 기능 제공 측면만을 고려했을 때)
하지만 그룹 채팅과 같은 시스템을 구축하기 위해서라면, 위 방식은 한계가 존재한다.
최근의 채팅 시스템을 제공하는 서버들은 사용자 간의 대화에 보다 적극적으로 참여한다.
따라서 클라이언트는 서로 직접 통신을 하지 않으며, 모든 데이터는 서버와 통신한다.
📌 요구 사항
- 응답 지연이 낮은 일대일 채팅 기능
- 최대 100명까지 참여할 수 있는 그룹 채팅 기능
- 메시지의 길이는 100,000자 이하이며, 일별 능동 사용자 수(DAU; Daily Active User) 기준 5천만 명을 처리 가능해야 함.
- 사용자의 접속 상태 표시 가능
- 다양한 단말 지원. 하나의 계정으로 여러 단말에 동시 접속 지원
- 푸시 알림
- 종단 간 암호화(end-to-end encryption)은 현재로선 필요 없으나, 논의해볼 수 있으면 좋다.
- 채팅 이력은 영원히 보관되어야 한다.
📌 채팅 서비스가 제공해야 할 기본 기능
클라이언트 간에 직접 통신이 아닌, 서버와의 통신이므로 채팅 서버가 지원해줘야 할 기능은 다음과 같다.

- 클라이언트들로부터 메시지 수신
- 메시지 수신자(recipient) 결정 및 전달
- 수신자가 접속(online) 상태가 아닌 경우, 접속할 때까지 해당 메시지 보관
2. 프로토콜
📌 HTTP 통신을 사용할 것인가?
메시지를 송신할 때는 sender에 해당하는 클라이언트가 먼저 통신을 요청하므로, HTTP 프로토콜을 사용할 수 있다.
채팅은 일반적으로 단시간에 많은 데이터를 송신하므로, keep-alive 헤더를 사용하여 채팅 서비스와의 연결을 끊지 않고 대기하도록 만들면 효율적이다. (TCP Three Hand-shake 오버헤드를 줄이기 위함)
하지만 HTTP는 클라이언트가 연결을 만드는 프로토콜임을 고려하면, 메시지 수신 시나리오는 다소 복잡해진다.
요청한 메시지를 클라이언트에게 전달하기 위해, 서버가 클라이언트 방향으로 통신을 요청해야 하는데 임의 시점에 메시지를 보내는 데는 쉽게 사용될 수 없다.
📌 폴링(Polling)

가장 단순하게 생각해볼 수 있는 방법.
Server가 Client에게 연결하는 게 쉽지 않다면, Client가 주기적으로 새 메시지 존재 여부를 확인하도록 만드는 것이다.
위 방식은 폴링 주기를 설정하는 게 매우 까다로운데,
주기가 너무 길면 최신 메시지를 받아오는 시간이 지연될 것이고, 너무 짧으면 서버 입장에서 부담스러워지게 된다. (폴링 비용 증가)
또한 답해줄 메시지가 없을 때, 서버 자원이 불필요하게 낭비된다.
서비스 사용자 수가 많을 수록 위 문제는 더 심해진다.
📌 롱 폴링(Long polling)

폴링 방식에서 새로운 메시지가 있는지 요청을 받았을 때, 바로 응답을 보내지 않고 잠깐 대기하는 방법
만약 응답이 존재하거나, 대기하던 도중 신규 메시지를 받으면 바로 반환한다.
그러나 일정 시간이 지나도록 신규 메시지가 없다면, 타임 아웃으로 인해 연결이 끊어진다.
three hand shake는 줄일 수 있겠지만, sender와 receiver가 같은 채팅 서버에 접속하지 않게 될 수 있다는 문제가 있다.
- HTTP 프로토콜은 무상태(stateless) 서버
- 채팅 서버는 여러 개일 수 있다. 어느 서버에 연결될 지 로드 밸런서에서 라운드 로빈 알고리즘으로 결정했다고 가정
- sender가 메시지를 보낸 서버와 receiver가 메시지를 수신할 서버가 다를 수 있다.
이외에도 클라이언트가 연결을 해제했는지 알기 좋은 방법이 아니며, 여전히 메시지를 많이 받지 않는 클라이언트도 타임아웃이 발생할 때마다 주기적으로 서버에 다시 접속한다.
📌 웹소켓(WebSocket)
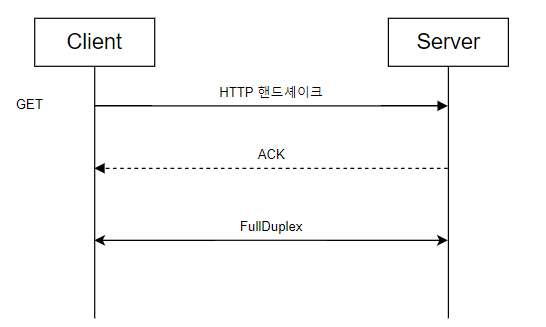
- 클라이언트가 연결을 요청할 때는 HTTP 연결로 수행하고, 성공하면 Web Socket 연결로 업그레이드된다.
- 한 번 맺어진 연결은 항구적(변하지 않고 오래가는)이며, 양방향(Full-duplex)이다.
- 여전히 80, 443과 같은 기본 포트 번호를 사용하기 때문에, 방화벽이 있는 환경에서도 잘 동작한다.
특히 sender와 receiver 모두 server와 web socket이란 동일 프로토콜을 사용하면, 구현이 단순하고 직관적이게 된다.
또한 사용자 접속 상태, 사용자 입력 상태 등과 같은 실시간 정보를 전달할 수 있다.
단, 웹소켓 연결은 항구적으로 유지되어야 하기 때문에 서버 측에서 연결 관리를 효율적으로 해야한다.
🤯 사용자가 1시간 동안 아무런 대화를 하지 않는다면? (feat. ping/pong)
문득 예전에 현직자분과 대화하다가 받았던 질문이 떠올랐다.
"socket 프로그래밍에서 ping pong이 왜 중요하다고 생각하나? OS가 socket을 파일처럼 취급하는 건 맞는데, 이 파일을 언제까지 유지할 건지? Short-Term이라면 고민할 이유가 없지만, Raw socket까지 사용해서 Long-Term과 Custom을 목적으로 한다면 반드시 알아야 한다.
1시간 동안 채팅을 하지 않았을 때 무슨 이유로 끊겼는지, 어떻게 회피해야 할 지 고민해봐라. WebSocket을 사용하면 이걸 경험할 수가 없다."
(놀랍게도 정답을 알려주시지 않았다. 이 질문도 6개월 전에 받아놓고, 드디어 고민하고 있다.)
여기서 1시간 동안 채팅을 하지 않았을 때를 대체 왜 고려하라는 건지 이해가 안 갔었는데, 사용자가 앱을 종료하지 않고 화면 종료, 혹은 절전 모드로 전환했을 때가 문제였다.
• 사용자가 화면을 보고 있지 않더라도 메시지를 실시간으로 받을 수 있어야 한다.
• 화면을 다시 켰을 때, 즉시 최신 메시지를 볼 수 있어야 한다.
• 화면이 꺼지거나, 절전 모드일 때도 메시지 수신이 가능해야 한다.
• 앱이 백그라운드로 전환되었어도 메시지를 받을 수 있어야 한다.
물론 매번 끊었다가 다시 연결한다고 기능이 동작하지 않는 건 아니지만, 낮은 지연시간을 목표로 한다면 이걸 고민해야만 한다.
이러한 맥락에서 ping/pong 메커니즘의 역할은 다음과 같다.
• 절전 모드 상태에서도 최소한의 네트워크 활동을 유지하도록 한다. (앱이 종료된 것과 구분)
• 연결이 여전히 살아있음을 서버에 알려, 중요한 메시지나 알림을 지속적으로 수신한다.
• 배터리 소모를 최소화하면서도 실시간 통신 연결을 유지한다.
3. 개략적 설계안
📌 전체 아키텍처
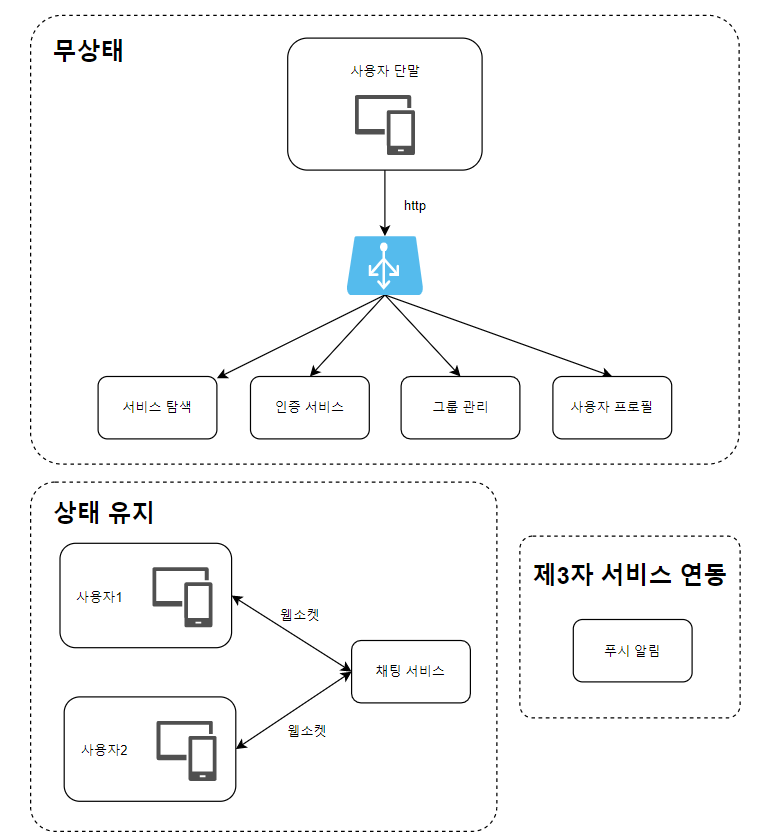
기존의 다른 서비스들까지 WebSocket 프로토콜로 업그레이드할 필요는 없다.
대부분의 기능(회원가입, 로그인, 사용자 프로필 등)은 HTTP 상으로 구현해도 충분하다.
이렇게 하면 서버는 총 세 부분으로 나누어 볼 수 있다.
HTTP 통신으로 무상태를 유지해도 충분한 영역과 사용자 활동을 실시간을 추적해야 하는 상태 유지 영역.
마지막으로 외부 Actor에 의존하는 제 3자 서비스 연동 영역이다. (여기선 채팅 푸시 알림을 보내기 위해 존재)
📌 무상태 서비스
무상태 서비스는 로드밸런서 뒤에 위치한다.
위에서 살펴봤듯 상태 유지가 필요한 채팅 서비스는 로드 밸런서로 연결을 결정하면, sender와 receiver가 서로 다른 채팅 서버에 연결될 우려가 있으므로 분리해야 한다.
현재 여기서 가장 눈여겨 봐야할 것은 서비스 탐색(service discovery)이다.
사용자가 접속할 최적의 채팅 서버 DNS 호스트명을 클라이언트에게 알려주는 역할을 수행한다.
이 단계가 바로 처음엔 HTTP 통신으로 진행되면서, 채팅 서버에 연결할 땐 WebSocket로 업그레이드 된다는 의미다.
📌 상태 유지 서비스
각 클라이언트는 채팅 서버와 독립적인 네트워크 연결을 유지해야 하기 때문에, 클라이언트는 서버가 살아 있는 한 다른 서버로 연결을 변경하지 않는다.
📌 제 3자 서비스 연동
새 메시지를 받았다면, 앱이 실행 중이지 않더라도 알림을 받아야 한다.
이건 3장에서 다뤘다는데, 난 이미 프로젝트에 구현하기도 했고 채팅 기능 설계가 급한 관계로 패스해서 블로그엔 현재 정리되어 있지 않다.
📌 규모 확장성
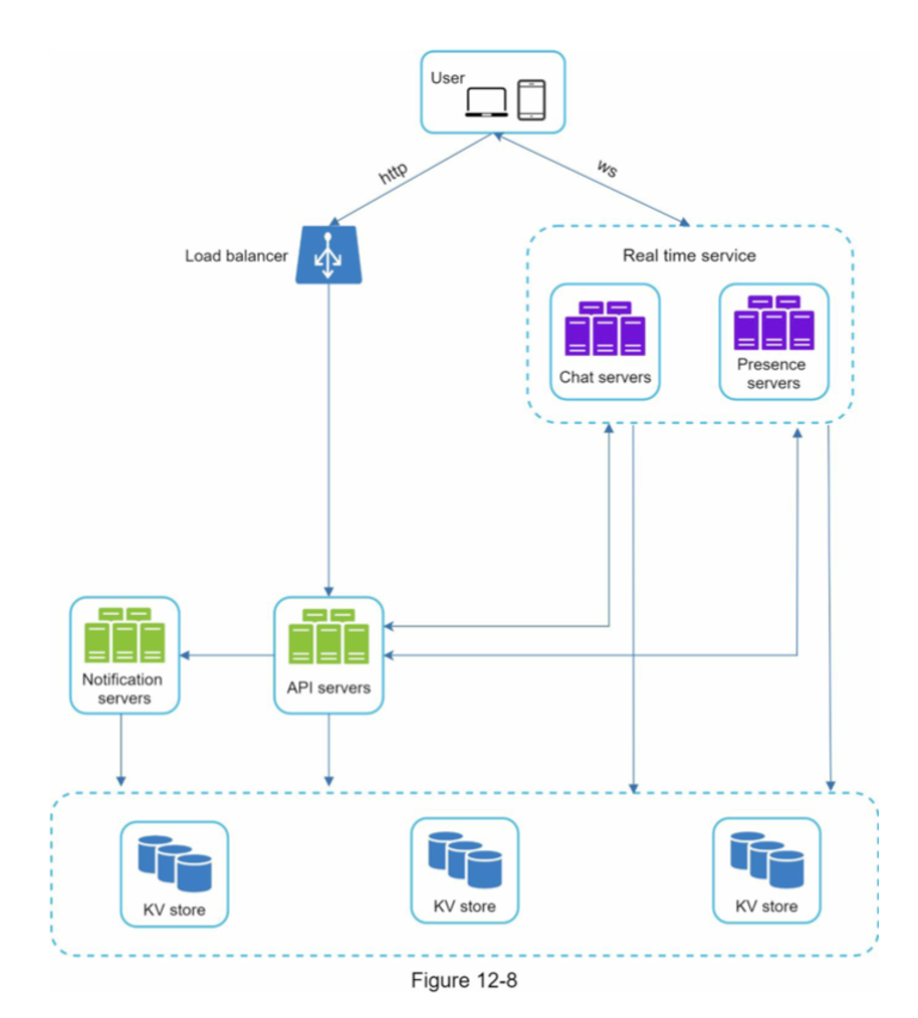
트래픽 규모가 얼마 되지 않을 때는 위 모든 기능을 서버 한 대로 구현할 수 있다. (난 그렇게 할 예정이다. 서버 증축할 돈과 시간적 여유 따위 가지고 있지 않다.)
물론 대량의 트래픽 또한 이론 상으로는 최신 클라우드 서버 한 대로 처리할 수 있다.
문제는 "서버 한 대가 얼마나 많은 접속을 동시에 허락하는가?"가 쟁점이다.
동시 접속자가 1M, 접속 당 10K 서버 메모리가 필요하다고 가정하면 10GB 메모리로 모든 연결을 처리 가능하다.
하지만 고가용성을 보장해야 할 채팅 서버가 SPOF가 된다.
따라서 위와 같은 설계를 제시해볼 수 있다.
- 채팅 서버: 클라이언트 간에 메시지 중계하는 역할
- 접속상태 서버(presence server): 사용자 접속 여부 관리
- API 서버: 무상태로 처리 가능한 모든 작업 수행
- 알림 서버: 푸시 알림 전송
- 키-값 저장소: 채팅 이력 보관
📌 저장소
1️⃣ DB가 필요한가?
만약 채팅 이력을 모두 사용자의 기기에 보관하고, 사용자가 앱을 삭제하면 모든 이력을 제거하기로 했다면 서버에서 chat 테이블을 관리할 이유가 없다.
그러나, 요구사항에서 모든 채팅 이력은 영구적으로 보관되어야 한다고 했으므로, DB는 필수적으로 존재해야 한다.
2️⃣ 어떤 DB를 사용할 것인가?
RDB과 NoSQL 중 어떤 것을 채택해야 할까?
이 질문에 답하기 위해서는 데이터의 유형과 읽기/쓰기 연산 패턴을 파악해야 한다.
채팅 시스템이 다루는 데이터는 보통 사용자 프로필, 채팅방 설정, 친구 목록과 채팅 이력(caht history)이다.
User와 Chat 데이터는 친구 조회나 친구 추가 join도 빈번하게 발생하므로, 모두 RDB를 통해 관리하는 것이 합리적인 것처럼 보일 수 있다.
그러나 채팅 이력이라는 데이터가 가지는 읽기/쓰기 연산 패턴을 분석해보면, RDB가 적절한지에 대한 의문이 생긴다.
- 채팅 이력 데이터 양은 매우 많다. 페이스북 메신저나 왓츠앱은 매일 600억 개의 메시지를 처리한다.
- 가장 빈번하게 조회되는 데이터는 최근에 주고 받은 메시지다. 대부분 오래된 메시지를 확인하지 않는다.
- 검색 기능, mention 기능을 포함하거나, 특정 메시지로 jump(답장하기 기능)하는 등 무작위적 데이터 접근을 하는 경우, 데이터 계층에서 해당 기능을 제공해야 한다.
- 1:1 채팅 앱에선 읽기:쓰기 = 1:1 비율 정도로 발생한다.
그렇다면 회원 정보는 RDB에 두고, 채팅 이력 정보만을 NoSQL에서 관리하는 것이 용이할 수 있는데, 이유는 다음과 같다.
- 키-값 저장소는 데이터 접근 지연시간(delay)가 낮다.
- RDB는 long tail에 해당하는 부분을 잘 처리하지 못 하는 경향이 있다.
- Index가 커지면 데이터에 대한 무작위적 접근(random access)을 처리하는 비용이 증가한다.
- 페이스북, 디스코드와 같은 많은 안정적인 채팅 시스템이 키-값 저장소를 채택하고 있다.
다만, 과거의 모든 이력까지 NoSQL에 보관할 필요는 없지 않을까? 이에 대한 내용은 `(7) 개인적인 고민`에서 다룬다.
✒️ 롱 테일(long tail)
처음 듣는 단어라 검색해봤는데, 대부분 AI, 통계학 쪽에서 거론되는 이야기라 이게 맞는 지 헷갈린다.
실제로 이 단어는 통계학에 근원을 두고 있는 용어라고 한다.
롱 테일이란 발생 가능성이 낮은 다수의 사건들이 통계 분포의 한 쪽에 길게 분포되어 있는 현상을 말한다.
그러니 채팅 이력에 대해서는 두 가지 관점에서 long tail이 존재한다. (더 있을 수 있는데, 내가 분석한 건 두 가지)
첫째, 시간의 흐름에 대한 long tail이다.
최근 데이터는 자주 접근되고, 높은 가치를 지닌다. (분포의 head 부분)
반면 과거 데이터는 접근 빈도가 낮다. 그러나 여전히 중요할 수 있다. (분포의 tail 부분)
따라서 최근 데이터는 고성능 스토리지 혹은 in-memory 저장소에 두어 빠른 접근이 가능해야 하지만, 오래된 데이터일 수록 저비용 스토리지의 외부 저장소에 보관하는 것이 좋다.
둘째, 사용자(혹은 채팅방) 별 채팅 데이터 양에 대한 long tail이다.
대다수의 채팅방은 비교적 적은 양의 메시지를 갖는 head 영역에 속한다.
그러나 소수의 매우 활발한 소통이 오고가는 채팅방은 매우 많은 양의 메시지를 갖는 tail 영역에 속한다.
이 말은 즉, 10%의 매우 활발한 사용자가 전체 메시지의 90%를 생성할 수도 있다.
이런 소수 사용자 데이터를 처리하기 위한 특별 조치가 필요할 수도 있다.
RDB는 모든 데이터를 동등하게 취급하므로, head와 tail 영역을 효율적으로 구분하기 어렵다.
또한 위에서도 나왔듯 RDB는 디스크 기반 저장소를 사용하기 때문에, random access가 성능에 큰 영향을 주는데
Long tail 데이터의 경우, 오래되거나 덜 접근되는 데이터가 디스크 여러 곳에 분산되어 있다.
이로 인해 특정 데이터를 찾기 위해 여러 번의 random access가 필요할 수 있으며, B-Tree의 깊이가 깊어져 검색 성능이 저하되어 최근 데이터의 빠른 조회를 어렵게 만들 수 있다.
3️⃣ 최근 채팅 시스템의 요구 사항 (책에 없는 내용)
AWS Summit Seoul 2023 | 천만 사용자를 위한 카카오의 AWS Native 글로벌 채팅 서비스
AWS Summit Seoul 2023 | 천만 사용자를 위한 카카오의 AWS Native 글로벌 채팅 서비스 - Download as a PDF or view online for free
www.slideshare.net
22번 슬라이드에서 보면, 채팅 시스템이 중점적으로 다루어야 할 최근 데이터는 접속 상태 확인, 메시지 즉시 전달 보다는 메시지 보관, 답글 달기, 공지, '좋아요'와 같은 반응 기능이다.
- 메시지 보관: 채팅방과 채팅 이력 데이터에 대해 Duration을 보장해야 한다.
- 공지: 채팅방에 공지를 올리면 실시간으로 전달이 되어야 한다. 데이터 양이 많지 않으나, '실시간'이 문제다. 그러나 저장은 RDB에 하고, WebSocket으로 공지 알림을 뿌리면 그만 아닐까 싶다. 이전 공지 내역을 조회할 때는 RDB를 사용하면 그만이다.
- 답글 달기: 단순하지만 어렵다. 현재 채팅이 답글을 다는 이력의 ID를 가지고 있어야 한다. 그리고 대화를 선택했을 때, 답글이 있는 위치로 jump하는 기능을 제공해야 한다. (매우 오래된 채팅에 대한 답을 한다면? 답글 달기를 할 때, 해당 데이터도 캐싱해서 빠르게 전달해서 주면 되지 않을까)
- 좋아요(반응 기능): NoSQL을 사용하는 것이 합리적이다. 채팅만큼은 아니지만 이 또한 많은 데이터 읽기/쓰기가 발생할 것이라 예상한다. 채팅 ID에 대해서 반응 종류(하트, 좋아요, 체크 등)의 카운트를 체크해야 한다. 그러나 "누가 반응했는 지" 정보가 필요하므로, 반응 종류 별로 사용자의 ID를 트랜잭션 채로 저장하면 될 것이라 생각한다.
4️⃣ 병목 구간은 무엇일까? (책에 없는 내용)
빠른 전달을 방해하는 요소는 무엇이 있을까?
- 채팅방 멤버 조회: 채팅 이력과 사용자 정보를 관리하는 곳이 다르므로 join을 사용할 수 없다. (애초에 이 정도 양이면 join 전략을 구상하기도 힘들다.) 사용자 정보를 캐싱하면 빠른 속도를 보장할 수 있을 것이다.
- 채팅방이 느릴 때: 채팅 서버의 수를 늘리면 해결할 수 있다. 워커 로드에 컨테이너를 증축하거나, 카프카의 topic을 늘릴 수 있다.
카카오, 겁나 빠른 황소 프로젝트
오늘은 카카오의 지금을 만들어낸 프로젝트, '겁나 빠른 황소' 프로젝트에 대해 알아보려 합니다. 카카오톡은, '10년 3월 처음 출시했고, 그 당시 등장과 함께 엄청난 인기를 끌면서 굉장힌 트래
yunknows.tistory.com
카카오는 통신 프로토콜을 아예 바꿔버려서, packet을 경량으로 만들어 속도를 향상시키기도 했다.
4. 데이터 모델
📌 1:1 채팅을 위한 메시지 테이블
채팅 이력은 key-value store에 저장한다고 하자. (오래된 이력을 값싼 저장소로 옮기는 것은 고려하지 않음)

기본 키는 message_id를 사용하고, 식별 + 순서 지정용으로 사용한다.
순서를 정할 때 created_at을 사용할 수 없는 이유는 7장 ID 생성기에서 이야기했 듯, 서로 다른 두 메시지가 동시에 만들어질 수 있기 때문이다.
📌 그룹 채팅을 위한 메시지 테이블
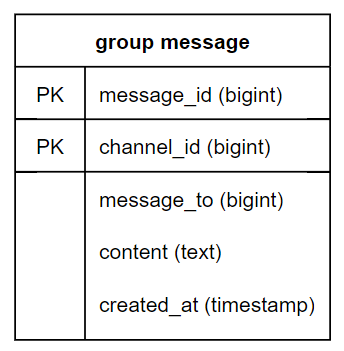
(channel_id, message_id)를 복합키로 사용한다.
여기서 채널(channel)은 채팅 그룹과 같은 의미를 갖는다.
이 때, channel_id는 파티션 키(partition key)로도 사용한다.
이는 그룹 채팅에 적용될 모든 질의는 특정 채널을 대상으로 하기 때문이다.
🤔 그룹 채팅에 적용될 질의문은 무엇이 있을까?
언뜻 보기에도 그룹 별로 파티셔닝을 수행하는 것은 합리적이지만, 어떤 경우에 쓸 수 있을까?
• 최근 메시지 조회: "채널 X에서 최근 메시지 50개 가져오기"
• 특정 시점 이후의 메시지 조회: "채널 X에서 message_id Y 이후의 모든 메시지 가져오기"
• 특정 기간 동안의 메시지 검색: "채널 X의 지난 24시간 동안의 모든 메시지 가져오기"
• 키워드 검색: "채널 X에서 'hello'를 포함한 모든 메시지 찾기"
• 특정 사용자의 메시지 조회: "채널 X에서 사용자 A가 보낸 모든 메시지 가져오기"
• 메시지 수 통계 계산: "채널 X의 총 메시지 수 계산"
• 읽지 않은 메시지 조회: "사용자 A가 채널 X에서 마지막으로 읽은 메시지 이후의 모든 메시지 가져오기"
위의 연산은 빈번하게 사용하면서, 전체 그룹이 아닌 하나의 그룹 X 내에서 이루어진다.
그래서 쿼리문을 작성할 때도 `WHERE channel_id = X`가 언제나 포함된다.
대용량 데이터인 group message 테이블에 channel_id로 파티션을 해두면, 데이터 분산, 빠른 조회, 확장성, 병렬 처리, 효율적인 인덱싱 처리 등이 가능해진다!
📌 message_id
💡 message_id의 속성
• message_id는 고유해야 한다. (uniqueness; 유일성)
• ID 값은 정렬 가능해야 하며, 시간 순서와 일치해야 한다. (신규 ID는 이전 ID보다 큰 값이어야 한다.)
[대규모 시스템 설계] 7장. 분산 시스템을 위한 유일 ID 생성기 설계
📕 목차1. 유일 ID 생성기2. 개략적 설계3. 상세 설계1. 유일 ID 생성기 📌 auto_increment는 답이 될 수 있을까?DB가 단일 서버라면 auto_increment가 답이 될 수 있다.하지만 사용자 트래픽이 높은 곳이라
jaeseo0519.tistory.com
이걸 위해 7장 내용을 빠르게 정리했었다! ㅎㅎ
NoSQL은 auto_increment 기능이 없으므로, 7장에서 배운대로 스노플레이크 접근법을 사용하는 것이 합리적이다.
하지만 채팅 이력의 ID가 전역적으로 관리되어야 할 이유가 있을까?
message_id의 유일성은 같은 그룹 내에서만 보증하면 충분하므로, 지역적 순서 번호 생성기(local sequence number generator)를 이용한다는 아이디어를 떠올릴 수 있다.
참고로 스노플레이크 방법과는 차이가 있다.
지역적 순서 번호 생성기는 각 채널(그룹)에 대해 독립적인 ID를 생성한다.
-- 카운터 테이블
CREATE TABLE channel_counters (
channel_id VARCHAR(255) PRIMARY KEY,
current_count BIGINT DEFAULT 0
);
-- ID 생성 및 증가 (의사 코드)
BEGIN TRANSACTION;
SELECT current_count FROM channel_counters WHERE channel_id = X FOR UPDATE;
UPDATE channel_counters SET current_count = current_count + 1 WHERE channel_id = X;
COMMIT TRANSACTION;
- DB에 채널별 카운터 테이블 생성
- 새 메시지 생성 시, 해당 채널의 카운터를 조회하고 증가
- 증가된 카운터 값을 message_id로 사용
지역적 순서 번호 생성기는 책에 없던 내용이라, 임시로 작성해봤을 뿐이니 참고만 하면 된다.
5. 상세 설계
📌 서비스 탐색
클라이언트에게 가장 적합한 채팅 서버를 추천하기 위해선 어떤 기준이 필요할까?
- 클라이언트의 물리적 위치(geographical location)
- 서버의 용량(capacity)
아파치 주키퍼(Apache Zookeeper)같은 오픈 소스 솔루션을 많이 사용한다고 한다.
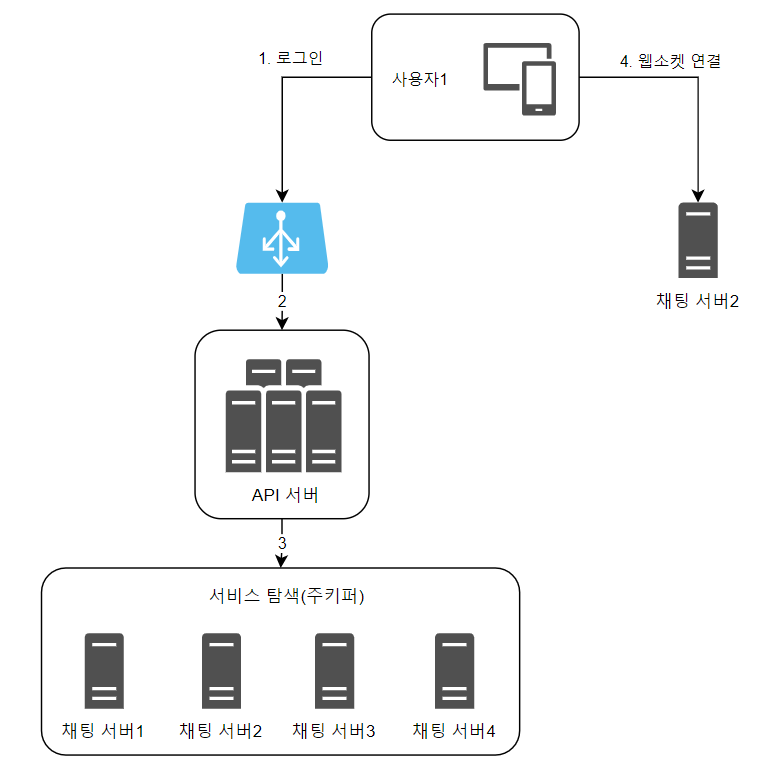
모든 사용 가능한 채팅 서버를 추키퍼에 등록하고,
클라이언트가 접속을 시도하면 사전에 정한 기준에 따라 최적의 채팅 서버를 연결해주면 된다.
📌 메시지 흐름
1️⃣ 1:1 채팅 메시지 처리 흐름

사용자 1이 채팅 서버로 메시지를 전달하면, ID 생성기로 ID를 지정해준 후 메시지 큐에 보관한다.
메시지 큐를 사용하는 이유는 사용자 2가 접속 중이 아니라면 전달해줄 채팅 서버가 없기 때문에, 푸시 알림 서버로 전달한다.
(사용자가 푸시 알림을 꺼놨다면, 그대로 drop하면 되는 걸까?)
2️⃣ 여러 단말 사이의 메시지 동기화

채팅 서비스를 이용할 때, 한 명의 사용자가 모바일과 웹, 혹은 2개의 모바일 기기(아이폰, 아이패드) 등으로 접속할 수도 있다.
이 때, 각 단말이 해당 단말에서 관측된 가장 최신 메시지의 ID(cur_max_message_id) 변수를 유지하도록 만든다.
여기서 두 조건을 만족하는 메시지는 새 메시지로 간주한다.
- 수신자 ID가 현재 로그인한 사용자 ID와 같다.
- 키-값 저장소에 보관된 메시지로서, 그 ID가 cur_max_message_id보다 크다.
🤔 기기 별로 분류를 안 하면, 동기화가 더 단순하고 쉽지 않나?
기기 별로 가장 마지막에 읽은 메시지를 관리해야 하는 이유가 뭘까? 차라리 분류를 안 하는 게 더 낫지 않은가?
예를 들어, 사용자 1에게 스마트폰과 랩탑이 있음을 가정하자.
같은 채팅방에 채팅 서버가 연결되어 있고, 스마트폰은 cur_max_message_id=100, 랩탑은 50이라는 값을 갖고 있다.
51~100이라는 데이터는 이미 읽었음에도 불구하고, 랩탑에서는 미확인 메시지로 간주한다.
그렇다면 읽음 상태가 불일치한다는 문제가 발생하는데, 차라리 기기를 분리하지 않고 관리하는 게 낫지 않을까?
라는 의문이 들었고, 여전히 명확하게 깨닫지는 못 했다.
하지만 위와 같이 처리를 하는 이유는 랩탑에서 어디까지 새 메시지라고 간주하고 데이터를 가져오기 위한 척도로 사용하기 위함이라 생각한다.
예를 들어, 랩탑에서 앱을 완전히 종료한 게 아니라 백그라운드로 실행 중이었거나 잠시 절전 모드로 전환한 것이라면?
세션은 여전히 연결되어 있지만, 채팅은 푸시 알림으로 계속 수신하게 된다.
그러다 다시 앱이 포그라운드로 전환되었을 때, 모든 채팅 데이터를 조회하는 게 아니라 마지막으로 읽은 시점 이후의 채팅 이력을 가져와야 하는데, 이를 위한 값이 아닐까 생각한다.
3️⃣ 소규모 그룹 채팅에서의 메시지 흐름
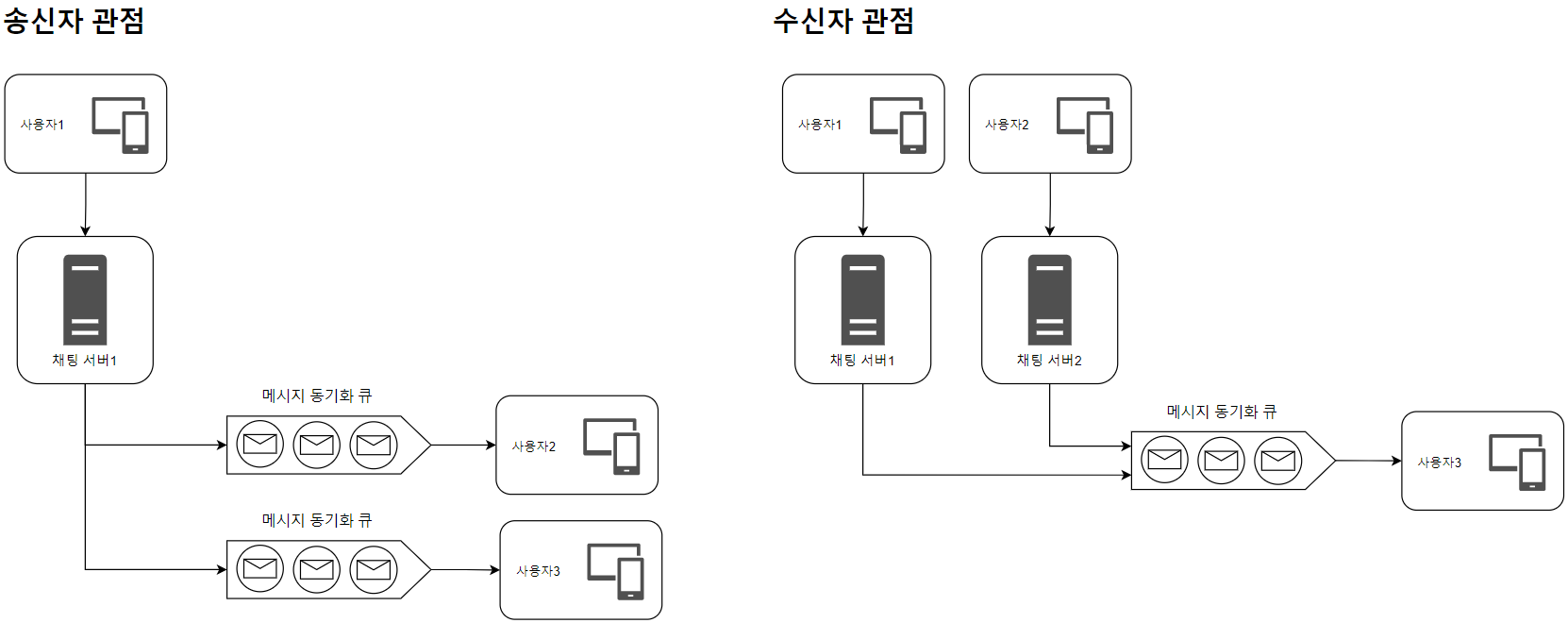
그룹 채팅에선 메시지 전달과 수신이 1:1이 아닌 1:N 관계가 되기 때문에 좀 더 복잡해진다.
소규모 그룹 채팅(500명 내외의 규모)이라면, 사용자 별로 메시지 동기화 큐를 할당하는 방법이 적합하다.
- 새로운 메시지가 왔는지 확인하기 위해, 자신의 큐만 확인하면 된다.
- 그룹이 크지 않으면 메시지를 수신자별로 복사해서 큐에 넣는 작업의 비용이 크지 않다.
하지만 사용자 규모가 크다면 똑같은 메시지를 모든 사용자 큐에 복사하는 것은 바람직하지 않다.
🤔 그럼 사용자 규모가 클 땐 어떤 방식이 효율적일까?
진짜 모르겠다. (ㅋㅋㅋㅋ) 해당 내용은 100% 추론에 불과하다.
메시지 동기화 큐를 사용자마다 두고, 메시지를 사용자 수만큼 매번 복사하는 것이 문제인 것이라면
메시지를 중앙 저장소에 한 번만 관리해야 할 것이다.
그럼 각 사용자가 자신이 마지막으로 읽은 메시지 ID를 추적하도록 하고, 마찬가지로 사용자가 마지막으로 읽은 ID 이후의 메시지만 조회한다.
이렇게 되면 병목 현상이 발생할 수 있으므로, DB 분산화와 샤딩, 그리고 인덱싱이 매우 중요한 요소가 된다.
그러나 Message Queue를 사용했던 본질적인 이유를 되짚어봐야 한다.
컴포넌트 간의 decoupling과 비동기 통신, 안정성 등을 이유로 사용하지 않았던가?
사용자마다 Message Queue를 두지 않으면 이제 이걸 어떻게 구분할 것인지?
송신자가 메시지를 전송 → 메시지를 중앙 저장소에 저장 → 메시지 ID, 메타데이터를 그룹의 Message Queue에 추가 → 수신자별 워커, 혹은 MSA가 Queue를 구독하도록 처리 → 워커는 Queue에서 message metadata를 가져와 처리
이런 식으로 처리하면 적어도 같은 메시지를 N개 복사할 일은 없어질 것이다. 그런데 그룹 멤버 수만큼 Worker를 생성해야 하는데 이건 괜찮은 건지..?
+ 워커를 동적으로 할당한다면 어떨까. 워커를 활성화된 사용자 수만큼 생성/제거하고 새 메시지가 없다면 워커를 모두 비활성화처리 한다면?
아오, 드릅게 어렵네 진짜.
📌 접속 상태 표시

디스코드, 인스타그램처럼 활성화된 사용자를 보여주어야 하는 경우가 있다.
이를 접속 상태 서버(presense server)에서 사용자 상태를 관리한다고 했는데, 이 또한 실시간 서비스의 일부에 속한다.
이 사용자의 상태가 바뀌는 경우가 무엇인지 고민해봐야 한다.
1️⃣ 사용자 로그인
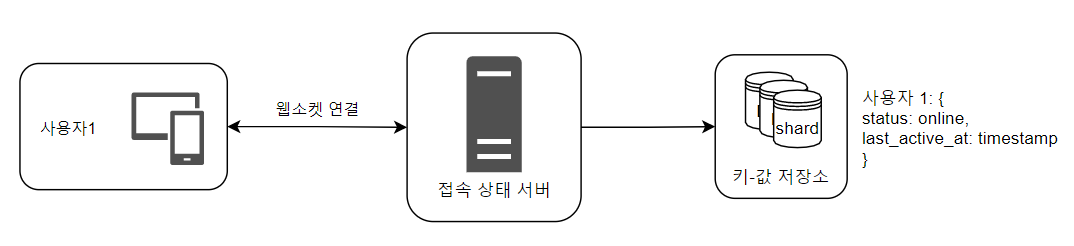
클라이언트와 실시간 서비스(real-time service) 사이 웹소켓 연결이 맺어진 이후, 접속 상태 서버는 사용자1의 상태와 last_active_at timestamp 값을 키-값 저장소에 보관한다.
2️⃣ 로그아웃
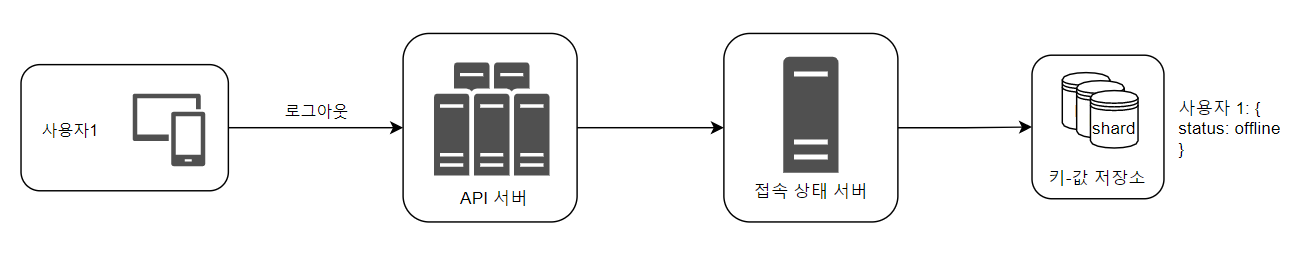
로그아웃 요청으로 웹소켓 연결이 끊어지면, 접속 상태 서버의 사용자1의 상태를 offline으로 수정한다.
3️⃣ 접속 장애
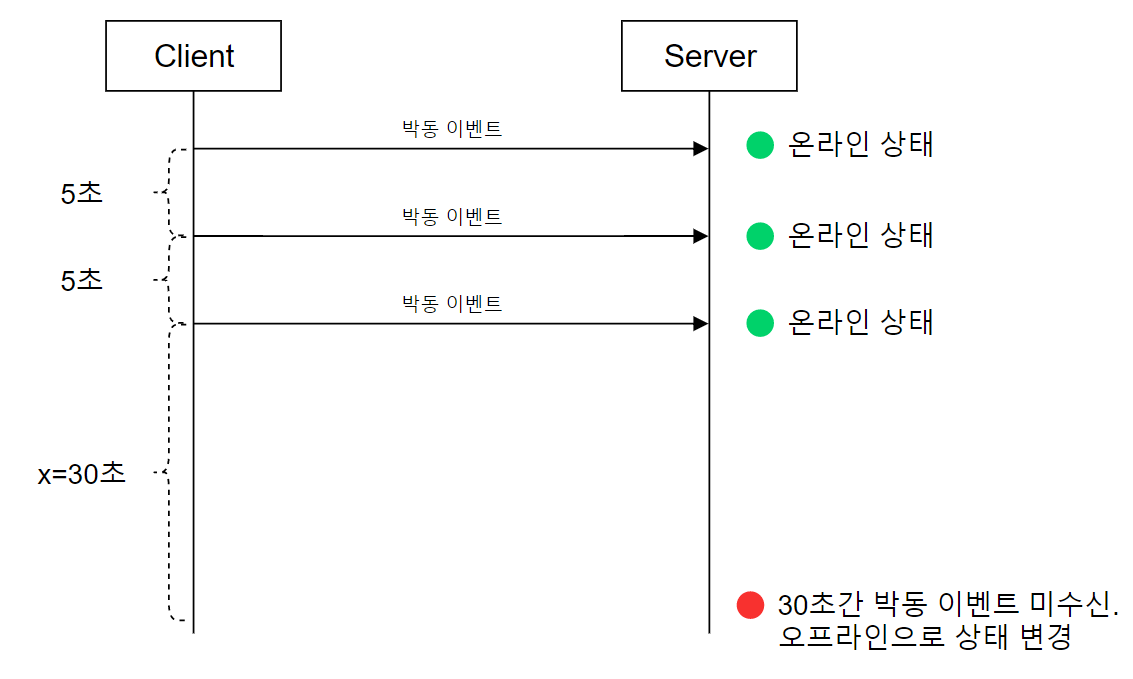
사용자의 인터넷 연결이 끊어지면 클라이언트와 서버 사이의 웹 소켓 연결도 끊어진다.
그러면 당연히 사용자 상태를 offline으로 바꿔버리면 되는 것이 아닌가 싶겠지만, 사용자의 상태가 아주 잠시 끊어진 것일 수도 있다. (ex. 사용자가 터널을 지나는 경우, 네트워크 환경이 잠시 악화되었던 경우)
이럴 때마다 사용자 점속 상태를 변경하는 것은 지나친 일이다.
여기선 박동(heartbeat) 검사를 하는데, 애플리케이션 헬스 체크(health check)와 동일한 원리로 동작한다.
온라인 상태의 사용자는 주기적으로 박동 이벤트를 전송하도록 하여, x초 이내에 수신하면 사용자를 온라인 상태로 유지한다.
그러다 x초 이내에 수신하지 못한 경우에만 offline으로 변경하는 것이다.
이 방식의 흥미로운 점은 사용자가 로그아웃 절차를 밟지 않고, 앱을 종료해버렸을 때도 결국 offline 상태로 변경됨을 감지할 수 있다는 것이다.
✒️ 백그라운드 상태
사용자가 앱을 로그아웃 했거나, x초 이내에 박동 이벤트를 전송하지 못 했을 경우엔 offline으로 수정하면 된다.
그런데 네트워크 불안정도 아니고, 로그아웃도 아닌 앱이 백그라운드로 전환된 경우는 어떻게 해야할까?
이 논제는 위에서 언급한 `사용자가 1시간 동안 아무런 대화도 하지 않는다면?`과 동일하다.
백그라운드로 전환된 앱은 여전히 웹소켓에 연결되어 있는 상태를 유지할 수도 있고, 아닐 수도 있다. (서비스 정책에 따라 다를 것이다.)
만약 연결된 상태를 유지한다고 하면, 백그라운드에서 박동 검사를 계속 수행해주어야 한다.
그러나 여기서 생각해보아야 할 점은 백그라운드로 전환된 사용자에겐 채팅 읽음 처리가 아닌 푸시 알림 전달을 수행해야 한다는 것이다.
그렇다면 박동 주기를 대체 얼마로 잡는 것이 적당할까? 그리고 사용자 상태 정보에서 백그라운드 전환 여부를 판단해야 할까?
여기에 대한 개인적인 생각은 다음과 같다.
모바일에선 백그라운드에서의 실시간성 보장보다도 배터리 소모를 줄이는 것을 최우선해야 한다고 생각한다.
따라서 포그라운드에선 짧은 주기의 박동 주기를 주고, 백그라운드에선 긴 주기의 박동 주기를 주어 동적으로 조절하는 것이 좋지 않을까 싶다.
그리고 박동 정보에 클라이언트가 포그라운드인지, 백그라운드인지 알려주어도 좋지만 백그라운드, 포그라운드로 전환되는 시점에 상태 변경을 알리는 것도 괜찮다고 생각한다.
이렇게 되면 접속 상태 서버에선 {online, offline}이 아니라, {active, background, inactive}로 상태를 구분해야 할 수도 있다.
4️⃣ 상태 정보의 전송
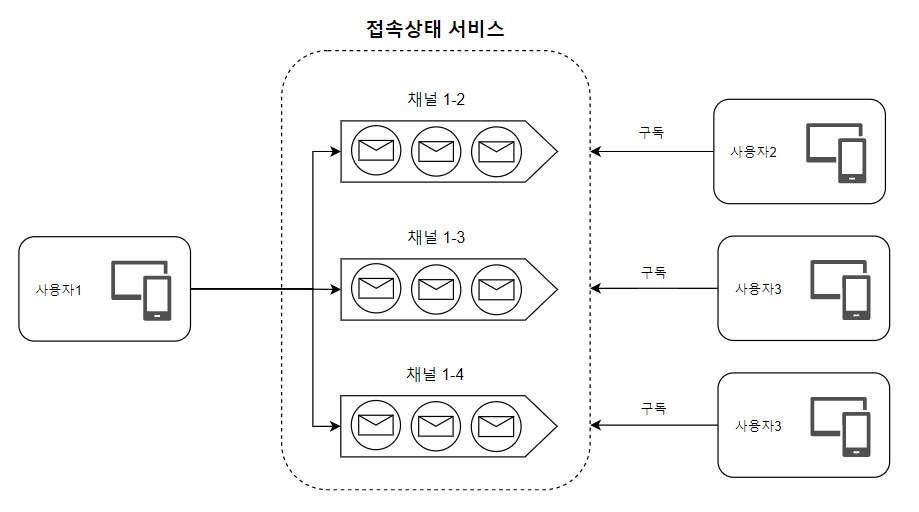
소규모 그룹 채팅과 동일한 방식으로 사용자의 상태 변화를 친구 관계에 있는 사용자들에게 알려줄 수 있다.
상태 정보 서버에서 사용자1의 상태가 변경되면, 이를 구독하던 친구들의 채널로 전달한다.
그룹 채팅 규모가 크다면, 위 방식은 적절하지 않다. (그룹 채팅방과 같은 이유)
- 그룹 채팅에 입장하는 순간에만 상태 정보를 읽게 할 수 있다.
- 친구 리스트에 있는 사용자 접속상태를 갱신하려면 수동으로(manual) 하도록 유도할 수도 있다.
이거 공부하다 디스코드 보니까 가슴이 웅장해진다.
📌 더 알아보면 좋을 것
- 채팅 앱을 확장하여 미디어를 지원하도록 하는 방법
- 미디어 파일은 텍스트에 비해 크기가 크다. (특히 요즘 모바일 기기의 사진, 영상 크기는 너무 크다.)
- 압축 방식, 클라우드 저장소, 섬네일 생성 등을 논의해보면 좋다.
- 참고로 이건 예전에 다룬 적이 있다.
- 종단 간 암호화
- 메시지를 end-to-end 간에만 확인 가능하도록 하며, 모든 과정을 암호화하는 것이다.
- 사건사고를 많이 일으켰던 페이스북은 특히 여기에 관심이 많다. (누가 보내고, 누가 받았는 지 조차 감추는 경우도 있다고 한다.)
- 캐시
- 클라이언트가 이미 읽은 메시지를 캐시해 두면, 서버와 주고받는 데이터 양을 줄일 수 있다.
- iOS의 경우 UserDefaults 혹은 CoreData 등을 사용해볼 수 있을 것이다.
- 로딩 속도 개선
- 슬랙(Slack)은 사용자 데이터, 채널 등을 지역적으로 분산한 네트워크를 구축하여 앱 로딩 속도를 개선했다.
- 오류 처리
- 채팅 서버 오류
- 채팅 서버 하나에 수십만 사용자가 접속해 있다면?
- 서버 하나가 죽으면, 서비스 탐색 기능이 클라이언트가 새로운 서버를 배정하고 다시 접속할 수 있도록 해야 한다.
- 메시지 재전송
- 재시도(retry)나 큐(queue)는 메시지 안정적 전송을 보장하기 위해 흔히 사용된다.
- 채팅 서버 오류
채팅 서버가 죽는 상황은 전혀 고민도 안 해봤다.
이건 진짜 어떻게 해야되냐..
7. 개인적인 추가 고민
📌 모놀리틱, 모노레포 vs MSA
시작부터 MSA를 적용하기엔 너무 부담이 크다.
예측 신규 가입자 수가 많지 않다면, 작은 채팅 서비스를 만들고 규모를 확장하는 것이 합리적이다.
대기업에서 새로운 기능을 개발하기 위한 프로젝트라도 하는 게 아니라면, 모노레포로 시작하는 게 합리적이다.
애초에 저 많은 서버 굴릴 돈도 없다.
📌 채팅 내용 보관 주기는 어느 정도로? 오래된 채팅은 어디에 저장?
이는 사용자 행동 패턴 분석이 우선되어야 한다고 생각한다.
- 메시지 조회 빈도
- 스크롤 깊이 (얼마나 오래된 메시지까지 읽는지)
- 검색 패턴 (얼마나 오래된 메시지를 검색하는지)
- 메시지 재인용 빈도
- 채팅방별 활성도
분석 방법으로는 다음과 같은 전략을 사용해볼 수 있다.
- 시계열 분석: 시간에 따른 메시지 접근 패턴 파악
- 클러스터링: 유사한 사용 패턴을 가진 사용자 그룹 식별
- 히트맵: 메시지 나이에 따른 접근 빈도 시각화
여기서 핵심 지표는 평균 메시지 조회 기간, 90 percentile 메시지 접근 나이, 채팅방 유형별 메시지 수명이 될 수 있을 것이다.
이를 기반으로 단계적 저장 전략을 구상해봐야 하는데, 나에게 자본과 기술적 한계 제약이 없다면 총 3단계로 구상해볼 것 같다.
- 핫 스토리지
- 최근 1-3개월 데이터
- 저장소: 고성능 데이터베이스 (ex. Redis, Cassandra) - NoSQL을 사용한다.
- 빠른 접근과 실시간 쿼리 중점
- 웜 스토리지
- 3개월-1년
- 저장소: 관계형 데이터베이스 혹은 NoSQL 데이터베이스 (과거 이력을 자주 조회한다면)
- 적당한 접근 속도와 구조화된 쿼리에 중점
- 콜드 스토리지
- 1년 이상
- 저장소: 객체 스토리지 (ex. Amazon S3)
- 비용 효율적이고, 사실상 조회될 일이 거의 없는 데이터. 접근 데이터가 느리다.
물론 위에서 정한 기간은 임의 수치일 뿐이고, 사용자 행동 패턴을 주기적으로 분석해서 업데이트할 필요가 있다.
애초에 좋은 전략인지도 잘 모르겠다.
📌 채팅방이 아닌 다른 View 혹은 Page에 있다면? 사용자의 상태 정보를 어떻게 관리할 것인지?
위에서 사용자 상태를 {activate, background, inactive}로 구분을 했으나, 하나 더 고민해봐야 할 것이 있다.
사용자가 포그라운드에 있지만, 메시지가 온 채팅방에 들어가 있지 않다면 어떡할 것인가?
이를 위해서는 상태를 한 번 더 세분화할 필요가 있는데, 채팅방 입장/퇴장 시에 한 번 더 신호를 보내 {active_in_chat, active_out_chat, background, inactive}로 구분하면 어떨까?
문제는 active_out_chat과 background는 푸시 알림을 받는 것은 같지만, 다른 차이가 있다.
바로 읽지 않은 메시지 카운트를 실시간으로 증가시켜줘야 한다는 것 😂
단순히 사용자에게 새로운 메시지가 존재하는지만을 알리도록 정책을 만들어도, 이는 실시간으로 보여져야 할 것이다. (사용자가 채팅 리스트에서 아무런 움직임이 없을 때도 읽지 않은 알림 신호를 보여줘야 한다.)
따라서 상태에 따른 메시지 처리 전략을 다음과 같이 잡아볼 수 있을 듯 하다.
- active_in_chat: 실시간으로 메시지 전달 및 읽음 처리
- active_out_chat: 푸시 알림, 읽지 않은 메시지 카운트 업데이트
- background: 푸시 알림 전송
- inactive: 메시지 큐에 저장하고 다음 접속 시 동기화
까지 생각했었는데, 사용자가 가입한 방이 하나가 아닐 수도 있지 않나?
만약 가입한 방이 채팅방A, 채팅방B, 채팅방C일 때, 사용자가 채팅방A View를 보고 있는 상태라면, 채팅방 B, C의 메시지는 푸시 메시지로 전달되어야 한다.
그럼 상태를 다음과 같이 관리해야 할 수도 있을 듯하다.
{
"status": "active",
"last_active_at": timestamp,
"room_id": ""
}이러면 status는 다시 3가지 상태 {active, backgraund, inactive}로 구분할 수 있다.
- active, room_id 있음: 사용자가 특정 채팅방에 있음
- active, room_id 없음: 사용자가 앱의 다른 화면에 있음
- status가 active가 아님: 백그라운드 또는 비활성 상태
📌 특정 시기에 트래픽이 몰리는 경우?
LINE 오픈챗 서버가 100배 급증하는 트래픽을 다루는 방법
Tech-Verse 2022에서 김인제 님이 발표한 LINE 오픈챗 서버가 100배 급증하는 트래픽을 다루는 방법 세션 내용을 옮긴 글입니다. 안녕하세요. Square Dev 팀 김인제입니다. 이번 글에서는 LINE 오픈챗(OpenCha
engineering.linecorp.com
단순하게 생각하면 인스턴스와 컨테이너를 미리 많이 올려두면 된다.
크리스마스 같은 날에는 예상할 수 있는 트래픽이 있을 수도 있지만, 외부의 어떤 이벤트 등으로 인해 예기치 못한 트래픽 급증 또한 발생할 수 있다.
언제 발생할지도 모르는 hot chat에 대비해 샤드를 추가하거나 애플리케이션 수를 늘리는 방법은 오버헤드가 크다.
(chat_id를 기반으로 샤딩하는 구조에선 더 이상 하나의 hot chat 안에서 발생하는 데이터를 분산할 수 없기 때문이다.)
그 이유를 라인에서 이야기해주든 hot chat의 비중이 매우 적기 때문이다.
그걸 해결하기 위해 라인에선 hot chat을 탐지하여 fetch 이벤트 API 요청을 줄이는 방법을 택했다는데, 여기서부턴 현재의 내가 고민하기엔 너무 깊어져서 패스