[Docker] Container monitoring
📕 목차
1. Monitoring Tech Stack at Containerized Application
2. Measured Value Output
3. Prometheus Container
4. Grafana Container
5. Level of Observability
6. Practice
1. Monitoring Tech Stack at Containerized Application
📌 Container 환경에서의 Monitoring
- 전통적인 Application 모니터링
- 서버 목록과 현재 동작 상태(잔여 disk 공간, memory와 CPU 사용량)가 표시된 대시보드가 존재
- 과부하가 걸리거나 응답하지 않는 Server 발생 시 경보 발생
- Container 환경에서 모니터링
- Container를 다룰 수 있음
- Container Platform과 연동하여 정적인 Container 혹은 IP 주소 목록 없이도 실행 중인 Application을 들여다 볼 수 있음
📌 프로메테우스(Prometheus)

- Container 환경의 모니터링 기능을 제공하는 오픈 소스 도구
- 프로메테우스도 Container에서 동작한다.
- 모니터링의 중요한 측면인 일관성 확보
- 모든 Application에서 똑같이 구성된 측정값을 내놓으므로 표준적인 형태로 모니터링할 수 있다.
- 측정값 추출을 위한 Query 언어도 한 가지만 익히면 된다.
- 전체 Application stack에 똑같은 모니터링을 적용할 수 있다.
"metrics-addr" : "0.0.0.0:9323",
"experimental" : true

- Docker engine의 측정값도 같은 형식으로 추출할 수 있다.
- Container Platform에서 벌어지는 일들을 파악할 수 있다.
📌 프로메테우스 출력 포맷
...
# HELP builder_builds_triggered_total Number of triggered image builds
# TYPE builder_builds_triggered_total counter
builder_builds_triggered_total 0
# HELP engine_daemon_container_actions_seconds The number of seconds it takes to process each container action
# TYPE engine_daemon_container_actions_seconds histogram
engine_daemon_container_actions_seconds_bucket{action="changes",le="0.005"} 1
engine_daemon_container_actions_seconds_bucket{action="changes",le="0.01"} 1
engine_daemon_container_actions_seconds_bucket{action="changes",le="0.025"} 1
engine_daemon_container_actions_seconds_bucket{action="changes",le="0.05"} 1
engine_daemon_container_actions_seconds_bucket{action="changes",le="0.1"} 1
...- key(이름)-value 형태의 텍스트 기반 포맷
- key-value 앞에는 어떤 정보인지, value의 데이터 타입이 무엇인지를 알려준다.
- 각 end-point를 통해 실시간으로 값을 제공한다.
- 값을 수집한 시간(TIMESTAMP)을 덧붙여 저장하므로 시간에 따른 변화를 추적할 수도 있다.
📌 Docker를 실행 중인 PC 정보 수집해보기
Container는 자신을 실행 중인 Server의 IP 주소를 알 수 없으므로, 환경 변수 형태로 직접 주입해주어야 한다.
# Window
$hostIP = $(Get-NetIPConfiguration | Where-Object {$_.IPv4DefaultGateway -ne $null}).IPv4Address.IPAddress
# Linux
hostIP = $(ip route get 1 | awk '{print $NF;exit}')
# macOS
hostIP = $(ifconfig en0 | grep -e 'inet\s' | awk '{print $2}')
docker container run -e DOCKER_HOST=$hostIP -d -p 9090:9090 diamol/prometheus:2.13.1
- 프로메테우스가 DOCKER_HOST에서 측정값을 수집하고 Timestamp를 덧붙여 Database에 저장한다.
- 프로메테우스 UI를 통해 '/metrics' end-point로 제공되는 모든 정보를 확인할 수 있다.
- 원하는 정보만 필터링하거나 표 혹은 그래프 형식으로 요약해 볼 수도 있다.


- engine_daemon_container_actions_seconds_sum(Container의 각 활동에 걸린 시간) 등의 정보를 확인할 수 있다.
- 각 상태별 Container 수, Health check 횟수 같은 고수준 정보
- Docker engine이 점유 중인 Memory 용량 같은 저수준 정보
- 원한다면 Host PC에 설치된 CPU 수와 같은 Infrastructure의 정적인 정보도 대시보드에 포함시킬 수 있다.
- execute를 누르면 프로메테우스 UI가 Query를 생성하고 결과를 보여준다.
- PromQL 문법으로 된 복잡한 쿼리를 쓸 수도 있다.
2. Measured Value Output
📌 라이브러리를 이용한 Application 측정값 수집
- 주요 Programming Language에는 프로메테우스 라이브러리가 제공된다.
- Go 언어에선 promhttp 모듈을 지원한다. (공식)
- Java 언어에서는 micrometer 패키지를 지원한다. (공식)
- Node.js 에서는 prom-client 패키지를 지원한다. (비공식)
- 각 Application의 공식/비공식 Client이 측정값을 출력하고 수집한다.
- 프로메테우스 Client 라이브러리를 통해 수집된 정보는 Runtime 수준의 측정값이다.
- 각각의 Runtime은 자신만의 중요도가 높은 측정값을 포함한다.
- Client 라이브러리 또한 이러한 정보를 수집하여 외부로 제공한다.
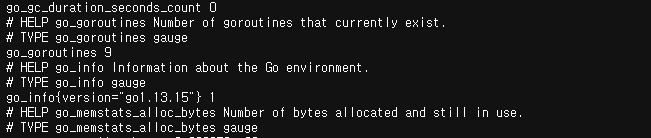

- 측정값 포맷은 프로메테우스 포맷이지만 내용은 Runtime 종류에 따라 다르다.
- Go Application 측정값은 현재 활성 상태인 goroutine을 측정한다.
- Java Application 측정값은 JVM이 사용 중인 Memory 용량 정보가 들어있다.
📌 측정값의 마지막 수준
지금까지 프로메테우스로 수집한 측정값은 2종류였다. 하지만 두 수준의 정보만으로 알 수 없는 마지막 수준이 있다.
- Docker engine에서 얻은 Infra-structure 측정값
- 프로메테우스 라이브러리를 이용해 얻은 Application Runtime 상태 측정값
- Application에서 프로그래머가 직접 노출시키는 핵심 정보로 구성된 Application 측정값
- 연산 중심 정보 : Component가 처리하는 Event 수, 평균 응답 처리 시간 등
- 비지니스 중심 정보 : System을 사용 중인 활성 사용자 수, 새로운 service를 사용하는 사용자 수 등
📌 Node.js Application에서 수집해보기
// 측정값 선언
const accessCounter = new prom.Counter({
name: "access_log_total",
help: "Access Log - total log requests"
});
const clientIpGauge = new prom.Gauge({
name: "access_client_ip_current",
help: "Access Log - current unique IP addresses"
});
// 측정값 갱신
function respond(req, res, next) {
log.Logger.debug("** POST /access-log called");
log.Logger.info("Access log, client IP: %s", req.body.clientIp);
logCount++;
//metrics:
accessCounter.inc();
ipAddresses.push(req.body.clientIp);
let uniqueIps = Array.from(new Set(ipAddresses));
clientIpGauge.set(uniqueIps.length);
res.send(201, "Created");
next();
}# Window
for ($i=1; $i -le 5; $i++) { iwr -useb http://localhost:8010 | Out-Null }
# Linux
for i in {i..5}; do curl http://localhost:8010 > /dev/null; done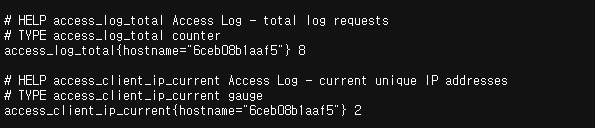
- Application 별로 가장 합리적인 방식은 따로 있다.
- Go Application에서는 counter와 gauge를 초기화 하지만, 측정값을 명시적으로 갱신하지 않고 라이브러리에서 제공하는 Handler로 처리한다.
- Java Application에서는 @Timed 어노테이션과 registry.counter 객체를 증가시키는 방법을 사용하고 있다.
- 프로메테우스의 측정값에 몇 가지 유형이 있는데, 프로그래머가 가장 적합한 방법을 택하여 사용하면 된다.
🤔 어떤 값을 측정하면 좋을까?
• 외부 시스템과의 통신에 걸린 시간과 응답 상태 여부 기록.
∘ 외부 시스템이 Application의 속도나 이상 상태에 영향을 줬는지 판단이 가능하다.
• 로그로 남길 가치가 있는 모든 정보
∘ 로그로 남기는 것보다 측정값으로 수집하는 편이 추세를 볼 수 있도록 시각화하기 좋다.
∘ memory, disk 용량, CPU 시간 면에서도 저렴하다.
• 사업 부서에서 필요로 하는 Application의 상태 및 사용자 행동에 관한 모든 정보
∘ 실시간 정보로 대시보드를 구성할 수 있다.
3. Prometheus Container
📌 스크래핑(Scraping)
- 프로메테우스는 Polling 방식으로 동작하며, 이런 측정값 수집을 스크래핑이라 한다.
- 프로메테우스 실행 시, 스프래핑 대상 end-point를 설정해야 한다.
- 운영 환경의 Container Platform
- Cluster에 있는 모든 Container을 찾도록 설정할 수 있다.
- 단일 Server의 Docker compose 환경
- Service 목록으로 Docker network의 DNS를 통해 대상 Container를 자동으로 찾는다.
- 운영 환경의 Container Platform
✒️ Client pulling
처음엔 풀링(pooling)인줄 알았는데 이건 AI 분야에서 나오는 말이고, 다음은 pulling인 줄 알았으나, 정답은 폴링(polling)이었다.
• polling
∘ Server에 결과룰 주기적으로 요청하는 것
∘ Client가 Server에 query를 던지고, query에 대한 결과를 Server가 response하는 것
∘ 사용자 정의된 protocol을 이용한 Server, Client가 여기에 속한다.
• pulling
∘ Server의 data를 주기적으로 가져가는 것
∘ Client가 Server의 data를 알아서 가져가는 것
∘ Client가 Database에 직접 query해서 받아가는 경우
📌 prometheus.yml
# prometheus/Dockerfile
FROM diamol/prometheus:2.13.1
COPY prometheus.yml /etc/prometheus/prometheus.yml# prometheus/prometheus.yml
global:
scrape_interval: 10s
scrape_configs:
- job_name: "image-gallery"
metrics_path: /metrics
static_configs:
- targets: ["image-gallery"]
- job_name: "iotd-api"
metrics_path: /actuator/prometheus
static_configs:
- targets: ["iotd"]
- job_name: "access-log"
metrics_path: /metrics
scrape_interval: 3s
dns_sd_configs:
- names:
- accesslog
type: A
port: 80
- job_name: "docker"
metrics_path: /metrics
static_configs:
- targets: ["DOCKER_HOST:9323"]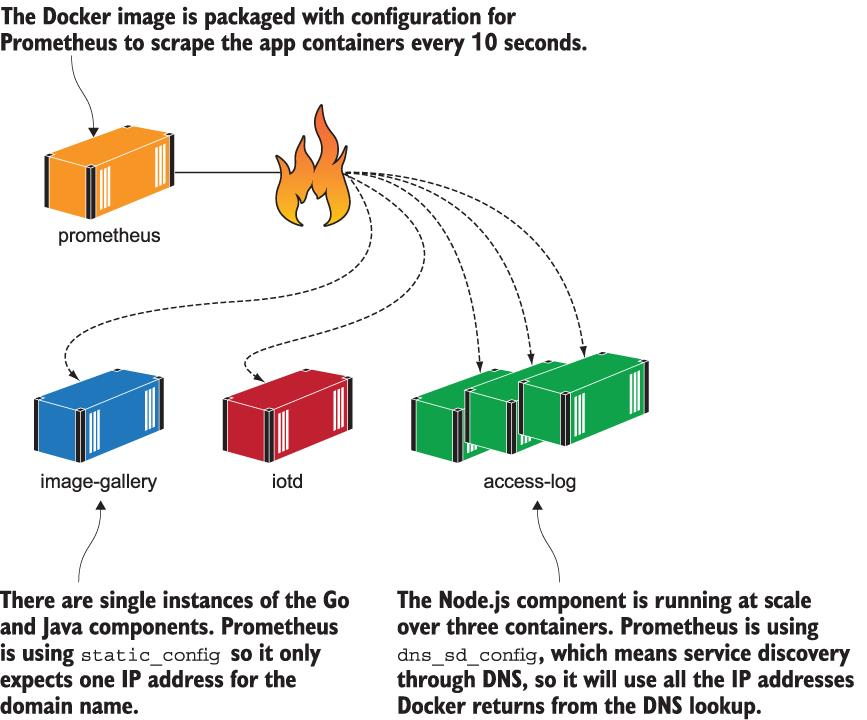
- 프로메테우스 설정
- global : 전역 설정값
- scrape_interval : Application으로부터 측정값을 scraping하는 간격
- scrape_configs : 각 Component 별 scraping 작업 지정
- job_name : scraping 작업의 이름
- metrics_path : 측정값 수집을 위해 request를 보낼 end-point
- 대상 Container 지정
- static_configs : Host 명을 통해 단일 Container를 지정하는 정적 설정
- dns_sd_configs : DNS service discovery 기능을 통해 여러 Container 지정이 가능하며, scaling에 따라 대상 Container를 자동으로 확대할 수 있다.
- global : 전역 설정값
- 프로메테우스는 DNS 응답 중에서 가장 앞에 오는 IP 주소를 사용한다.
- Docker engine이 DNS 응답을 통해 로드 밸런싱을 적용한 경우, 해당 Container 모두에서 측정값을 받아올 수 있다.
- access-log Component scraping은 dns_sd_configs를 적용했으므로 모든 Container의 IP 주소를 목록으로 만들어, 이들 모두에게서 같은 간격으로 측정값을 수집한다.
📌 Application 측정값 수집하기
docker-compose -f docker-compose-scale.yml up -d --scale accesslog=3
for ($i=1; $i -le 5; $i++) { iwr -useb http://localhost:8010 | Out-Null }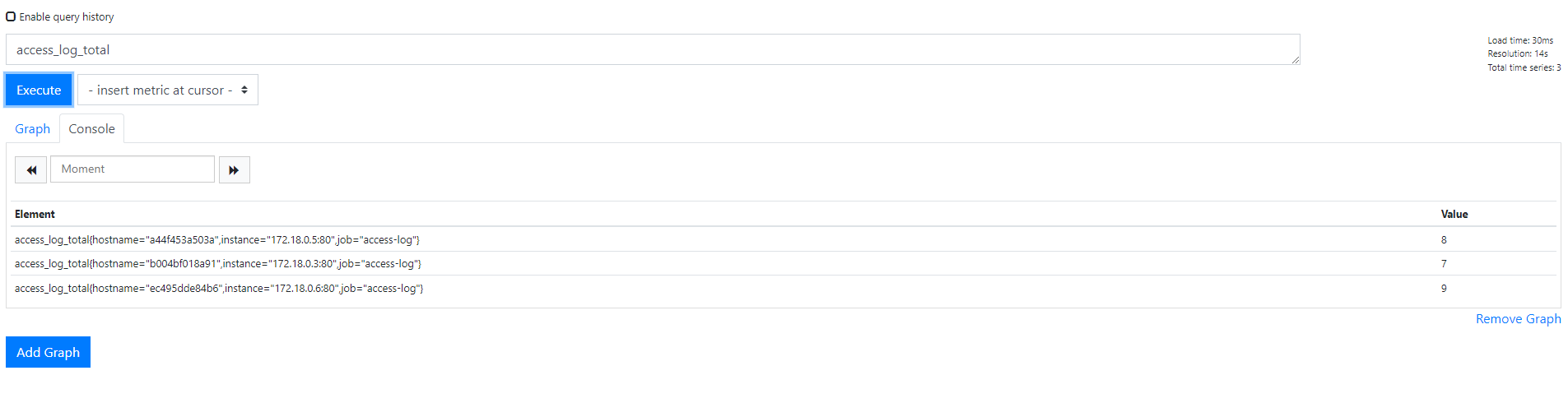
- 로드 밸런싱이 잘 되어 있기 때문에 access-log Service에 돌아가는 세 개의 Container에 고르게 요청이 분배되었다.
- 프로메테우스는 세 Container 각각의 식별자로 레코드를 구분한다.
- 레이블을 붙여 측정값에 정보를 추가하는 기능은 같은 측정값을 다양한 입도(granularity)에서 다룰 수 있다.
📌 Query 추가
sum(access_log_total) without(hostname, instance)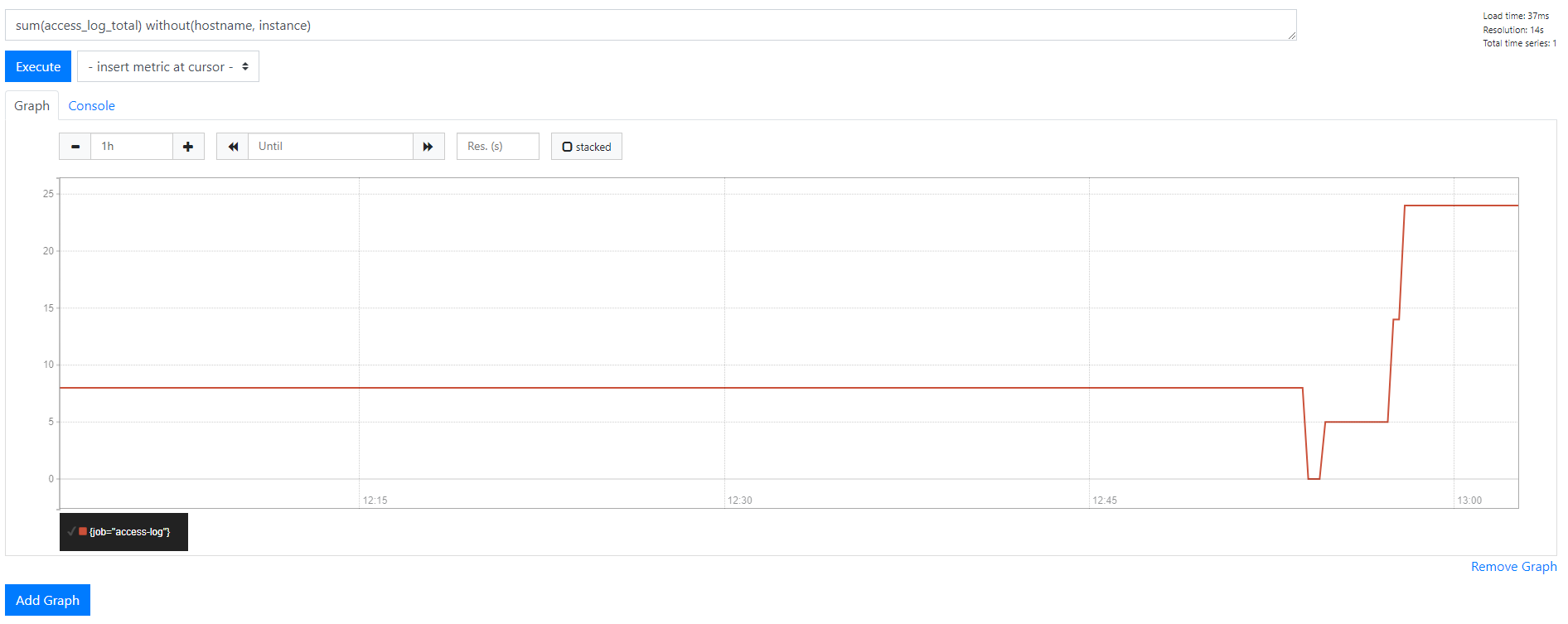
- PromQL : 프로메테우스 쿼리 언어
- Query 값의 시간에 따른 추이 또는 변화율을 확인하는 함수와
- 측정값 간의 상관 관계를 보여주는 여러 통계 함수를 갖추고 있다.
🟡 전형적인 Query 예시
sum(image_gallery_requests_total {code="200"}) without(instance)- image_gallery_request 측정값을 통합한다.
- response code가 200인 것을 추린다.
- instance 레이블과 무관하게 값을 합한다.
결과적으로 Query의 결괏값은 image-gallery Application 응답 중 response code가 200인 응답 총 횟수가 된다.
4. Grafana Container
📌 그라파나(Grafana)
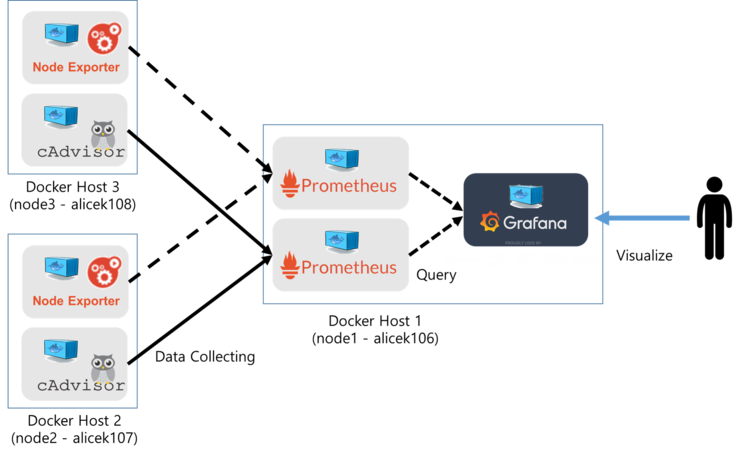
- Application 적용 표준 절차
- 측정값을 열람하거나 데이터 시각화를 위한 query를 확인하고 수정할 때는 프로메테우스 웹 UI를 사용한다.
- query를 연결해 대시보드를 구성하는 데는 그라파나를 사용한다.
- PromQL로 작성된 단일 query들만으로도 유용한 시각화된 그래프들을 만들 수 있다.
📌 그라파나 웹 UI 확인
# Window
$env:HOST_IP = $(GET-NetIPConfiguration | Where-Object {$_.IPv4DefaultGateway -ne $null}).IPv4Address.IPAddress
docker-compose -f .\docker-compose-with-grafana.yml up -d --scale accesslog=3
for ($i=1; $i -le 20; $i++) { iwr -useb http://localhost:8010| Out-Null }- 그라파나 웹 UI는 포트 3000을 사용하며, 초기 사용자명과 패스워드 모두 admin이다.
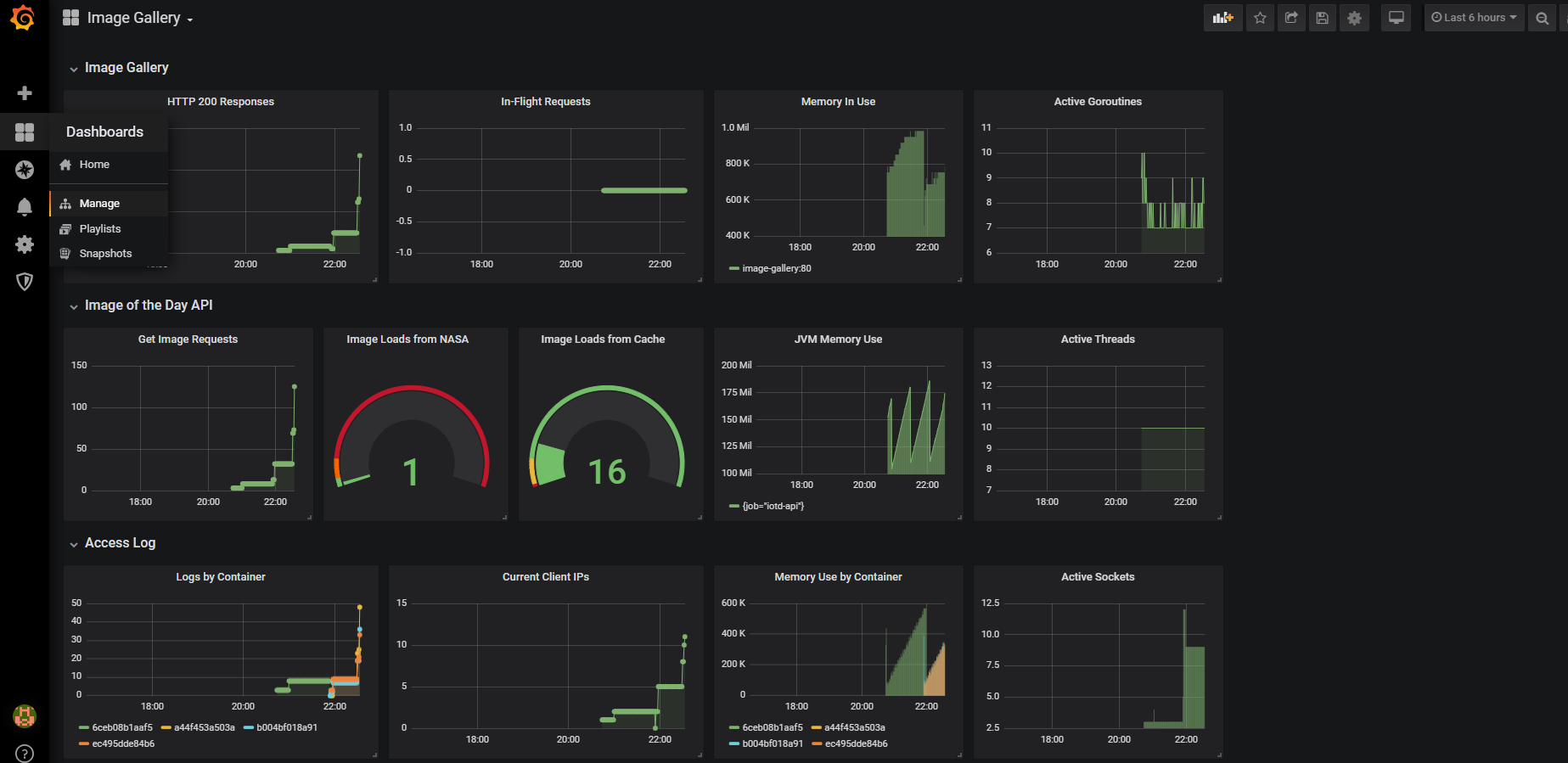
- 대시보드 측정값 구성 척도 (Site Reliability Engineering)
- 지연 시간, 트래픽, 오류, 가용 시스템 자원을 주요 측정값으로 지목한다.
- 이를 합쳐 골든 시그널이라 부른다.
📌 Query문 살펴보기
1️⃣ HTTP 응답 코드 200으로 처리된 응답의 수
sum(image_gallery_requsts_total{code="200"}) without(instance)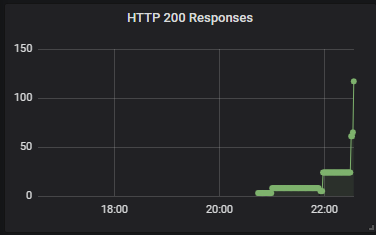
- 정상 처리된 request 수를 파악할 수 있다.
- 필터링 조건을 바꿔 code="500"을 적용하면 Server error 누적 개수가 된다.
2️⃣ 현재 처리 중인 요청 수
sum(image_gallery_in_flight_requests) without(instance)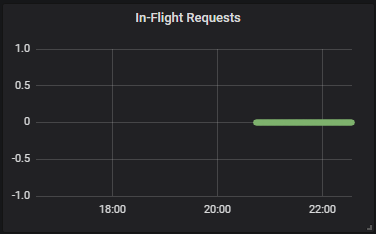
- in-flight packet을 처리 중인 개수
- guage 측정값이므로 증가와 감소가 가능하다.
- 필터링 조건 없이 전체 Container 측정값을 합산한다.
- 트래픽이 집중된 시점을 알 수 있다.
3️⃣ 메모리 사용량
go_memstats_stack_inuse_bytes{job="image-gallery"}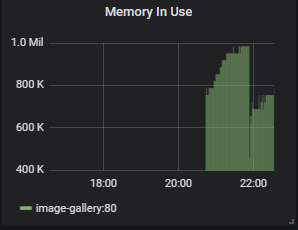
- image-gallery Application의 Container가 사용 중인 memory 용량
- 가용 시스템 자원을 판단할 수 있는 지표로써, 어떤 상황에서 memory가 부족해지는지 알 수 있다.
- scaling을 통해 Container 수를 증가시키면 막대 수가 늘어난다.
- Go Runtime 표준 측정값이므로 memory 사용량에서 job 이름에 필터링 조건을 걸었다.
4️⃣ 활성 고루틴 수
sum(go_goroutines{job="image_gallery"}) without(instance)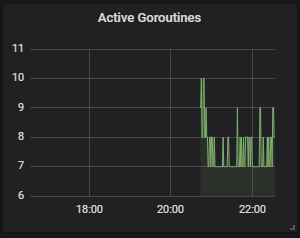
- 해당 Component의 부하를 나타내는 대략적 지표
- Go Application의 동작 상황과 가용 CPU 자원을 파악할 수 있다.
- 활성 고루틴은 Go Runtime 표준 측정값이므로 job 이름에 필터링 조건을 걸어 수집한다.
📌 Dash board
💡 중요한 것은 평균값에서 벗어나 수치가 튀어오르는 순간이 언제인지다.
- 대시보드의 그래프(그라파나에서는 Panel)는 절대적인 값보다 변화하는 추세에서 알 수 있는 정보가 더 많다.
- Application의 component의 이상 현상과 측정값 사이의 상관관계를 찾아야 한다.
- 만약 Server response error가 상승하고, 활성 go-routine 수가 초 단위로 두 배씩 증가하면서 component 잔여 처리 용량이 빠르게 감소하고 있다면, scaling을 통해 트래픽을 분산시켜야 한다.
📌 Panel 추가하기

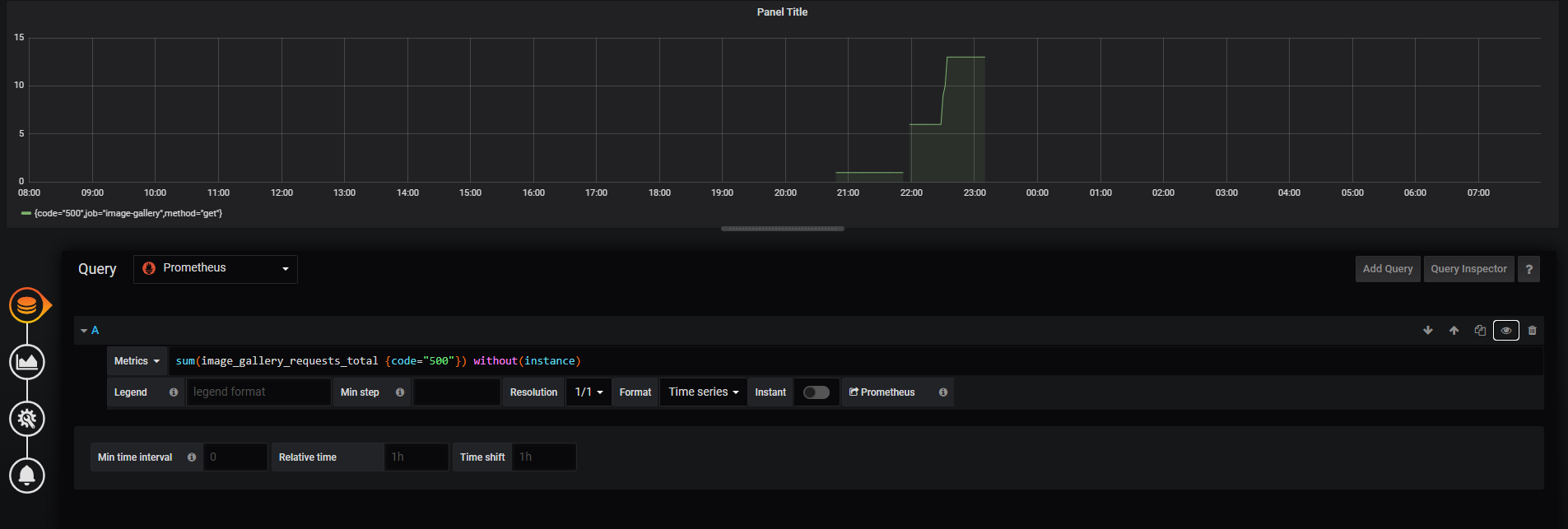
- 데이터 소스를 프로메테우스로 정하고 PromQL query 문을 작성하면 Panel이 추가된다.
FROM diamol/grafana:6.4.3
COPY datasource-prometheus.yaml ${GF_PATHS_PROVISIONING}/datasources/
COPY dashboard-provider.yaml ${GF_PATHS_PROVISIONING}/dashboards/
COPY dashboard.json /var/lib/grafana/dashboards/apiVersion: 1
providers:
- name: 'default'
orgId: 1
folder: ''
type: file
disableDeletion: true
updateIntervalSeconds: 0
options:
path: /var/lib/grafana/dashboardsapiVersion: 1
datasources:
- name: Prometheus
type: prometheus
access: proxy
url: http://prometheus:9090
basicAuth: false
version: 1
editable: true- 완성된 Dash board 설정을 Json으로 추출하여 그라파나 Docker Image를 만들 수도 있다.
- YAML 파일에는 각각 프로메테우스에 연결하기 위한 정보와 "/var/lib/grafana/dashboards" 디렉토리에서 dash board 구성을 읽으라는 내용을 담고 있다.
그라파나에서 이 기능은 일부에 불과하다.
5. Level of Observability
간단한 개념 검증 수준 Product에서 실제 서비스가 가능한 수준으로 나아가기 위해서는 투명성(observability)이 반드시 필요하다.
Docker의 진짜 매력은 Container를 중심으로 만들어진 생태계와 이들 생태계를 구성하는 도구를 적용하는 패턴에 있다.
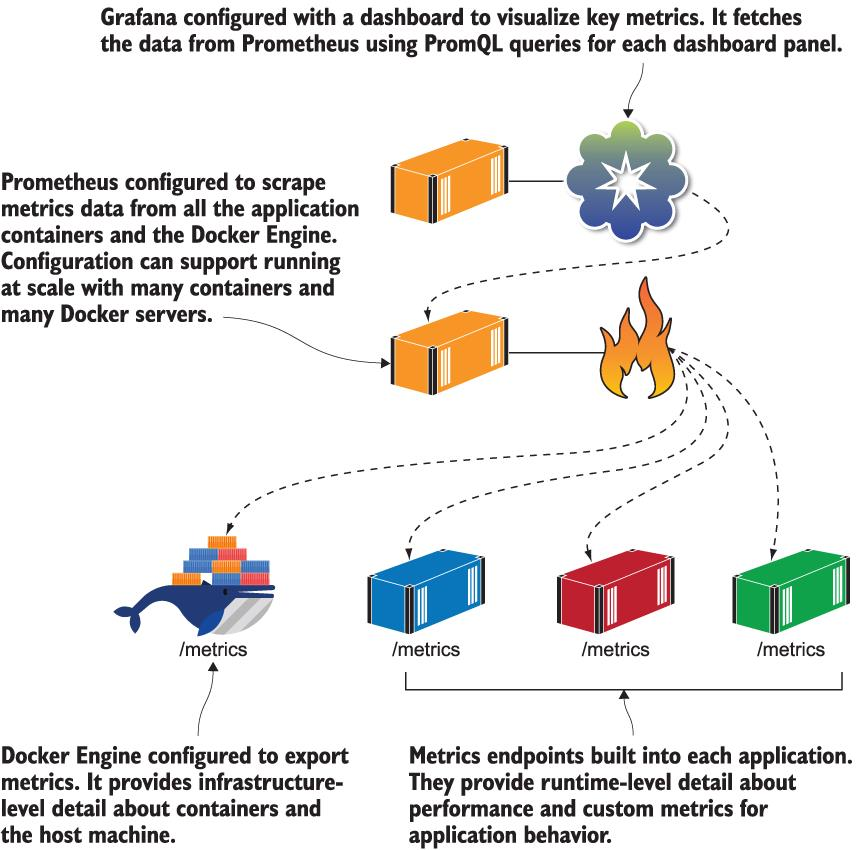
- 실제 운영 환경 모니터링이면 더 자세한 상황을 알려주는 Dash board가 필요하다.
- Infra-structure Dash board도 추가할 수 있다.
- Application을 구성하는 각 Component가 자신만의 추가적인 정보를 모니터링하는 Dash board를 가질 수 있다.
- ex. API의 end-point 별 응답 시간 분류
- Application 전체 상황(가장 중요한 데이터들)을 조망하는 Dash board를 구성할 수 있어야 한다.
6. Practice
- 프로메테우스 Container와 그라파나 Container를 함께 실행하도록 Docker compose script를 작성하라
- 프로메테우스 Container는 to-do Application 측정값을 수집하도록 설정하라.
- 그라파나 Container는 미리 구성된 Dash board를 포함해야 한다. 해당 Dash board는 다음과 같은 Application의 세 가지 핵심 측정값으로 구성된다.
- 생성된 할 일 수
- 처리한 HTTP 요청 수
- 현재 처리 중인 HTTP 요청 수
version: "3.7"
services:
todo-list:
image: diamol/ch09-todo-list
ports:
- "8050:80"
networks:
- app-net
prometheus:
image: diamol/ch09-lab-prometheus
ports:
- "9090:9090"
networks:
- app-net
grafana:
image: diamol/ch09-lab-grafana
ports:
- "3000:3000"
depends_on:
- prometheus
networks:
- app-net
networks:
app-net:
external:
name: nat# promethes Dockerfile
FROM diamol/prometheus:2.13.1
COPY prometheus.yml /etc/prometheus/prometheus.yml# prometheus.yml
global:
scrape_interval: 10s
scrape_configs:
- job_name: "todo-list"
metrics_path: /metrics
static_configs:
- targets: ["todo-list"]# grafana Dockerfile
FROM diamol/grafana:6.4.3
COPY datasource-prometheus.yaml ${GF_PATHS_PROVISIONING}/datasources/
COPY dashboard-provider.yaml ${GF_PATHS_PROVISIONING}/dashboards/
COPY dashboard.json /var/lib/grafana/dashboards/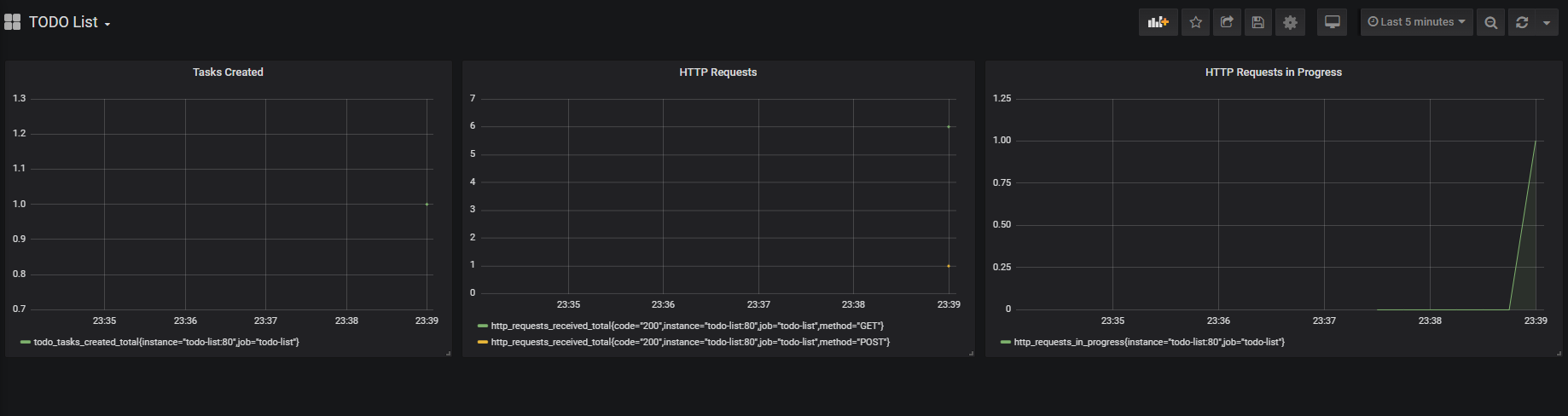
todo_tasks_created_total{instance="todo-list:80",job="todo-list"}http_requests_received_total{code="200",instance="todo-list:80",job="todo-list",method="GET"}
http_requests_received_total{code="200",instance="todo-list:80",job="todo-list",method="POST"}http_requests_in_progress{instance="todo-list:80",job="todo-list"}