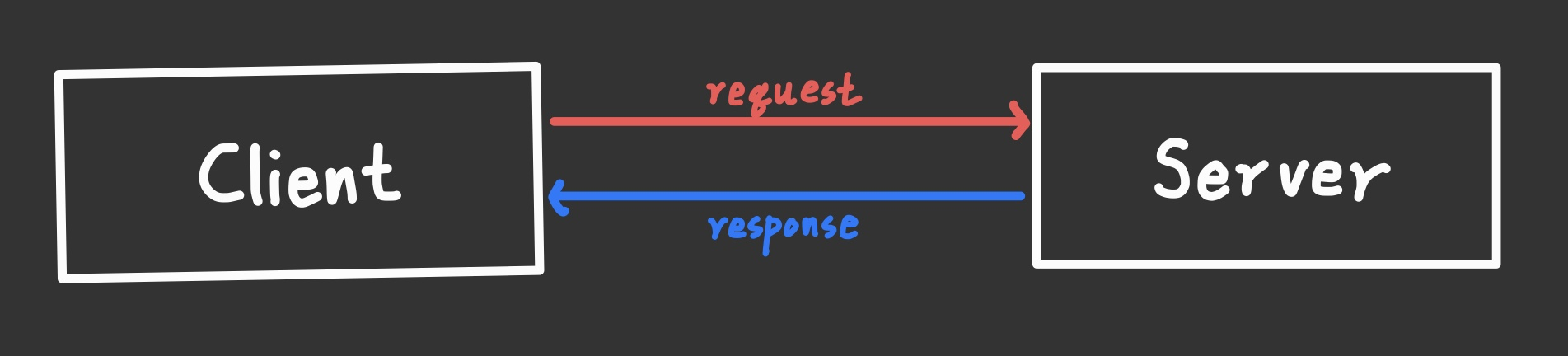
내가 상대측 CEO에게 메일을 주려고 하면 우선 내용을 작성하고, 편지 봉투에 넣고, 봉투에 받는이/보내는 이를 쓰고 우체국에 편지 봉투를 맡겨야 한다.
상대측 CEO 또한 편지 봉투를 받아서 자신에게 온 편지가 맞는지 확인을 하고, 편지 봉투를 뜯은 다음, 내용을 확인한다.
그런데 CEO가 동네 구멍 가게 사장님도 아니고 하는 일이 얼마나 많은데 이런 걸 다 하고 있겠는가.
그래서 체계적으로 분업을 하기 시작했다.
L5: 편지 내용을 쓰고 L4 비서에게 건넨다..
L4: 편지 종류에 따라 담을 편지 봉투를 선택한다.
L3: 봉투에 보내는 이와 받는 이의 회사 주소를 적는다.
L2: 봉투에 보내는 이와 받는 이의 회사 내의 직책(주소)를 적는다.
L1: 우체국에 맡겨 편지를 송/수신한다.
이렇게 하면 CEO인 나는 편지를 쓰고 밑으로 건네주기만 하면, 답장이 돌아오는 것을 기다리다가 받기만 하면 된다.
비서실은 편지 내용을 알 수도 없고 관심도 없다. 그저 어떤 편지 봉투를 고를지만 결정하면 되고, 이는 다른 계층 또한 마찬가지다.
만약, 비서실에 문제가 생기면 비서실 인력만 바꾸면 그만이기 때문에 해당 계층만 수정하여 전체 시스템에 미치는 영향 또한 적어진다.
또한 편지를 송/수신 방식이 서로 다른 우체국 종류가 많아지더라도 각 부서의 직무를 적절히 조합하여 처리한다면, 어떠한 우체국을 사용하더라도 송/수신이 가능해진다.
이 내용을 다시 TCP/IP 5계층 분리 목적으로 설명하면 이렇다.
첫째, 계층을 분리함으로써 각 계층은 서로 독립적으로 설계될 수 있다. 즉, 각 계층은 자신의 기능에만 집중하면 되므로 복잡도가 낮아지고, 유지보수 및 업그레이드가 쉬워진다. 둘째, 계층을 분리하면 다른 계층과의 인터페이스를 통해 상호작용할 수 있다. 예를 들어, 전송 계층의 프로토콜인 TCP는 인터넷 계층의 프로토콜인 IP를 사용하여 데이터를 전송한다. 이러한 인터페이스를 통해 각 계층은 자신이 관리하는 일부 기능을 다른 계층에게 위임할 수 있다. 셋째, 계층을 분리함으로써 프로토콜을 교체하거나 추가하기 쉬워진다. 새로운 프로토콜을 추가하거나 기존의 프로토콜을 변경하려면 해당하는 계층만 수정하면 되므로, 전체 시스템에 미치는 영향이 최소화된다. 마지막으로, 계층을 분리함으로써 네트워크를 구성하는 다양한 기술들을 조합하여 사용할 수 있다. 예를 들어, 이더넷, Wi-Fi, DSL 등 다양한 물리 계층 기술을 사용하여 네트워크를 구성하고, 인터넷 계층과 전송 계층에서는 이러한 기술들을 추상화하여 사용할 수 있다. 이를 통해 다양한 환경에서 동작하는 네트워크 시스템을 구축할 수 있다.
📌 Flow
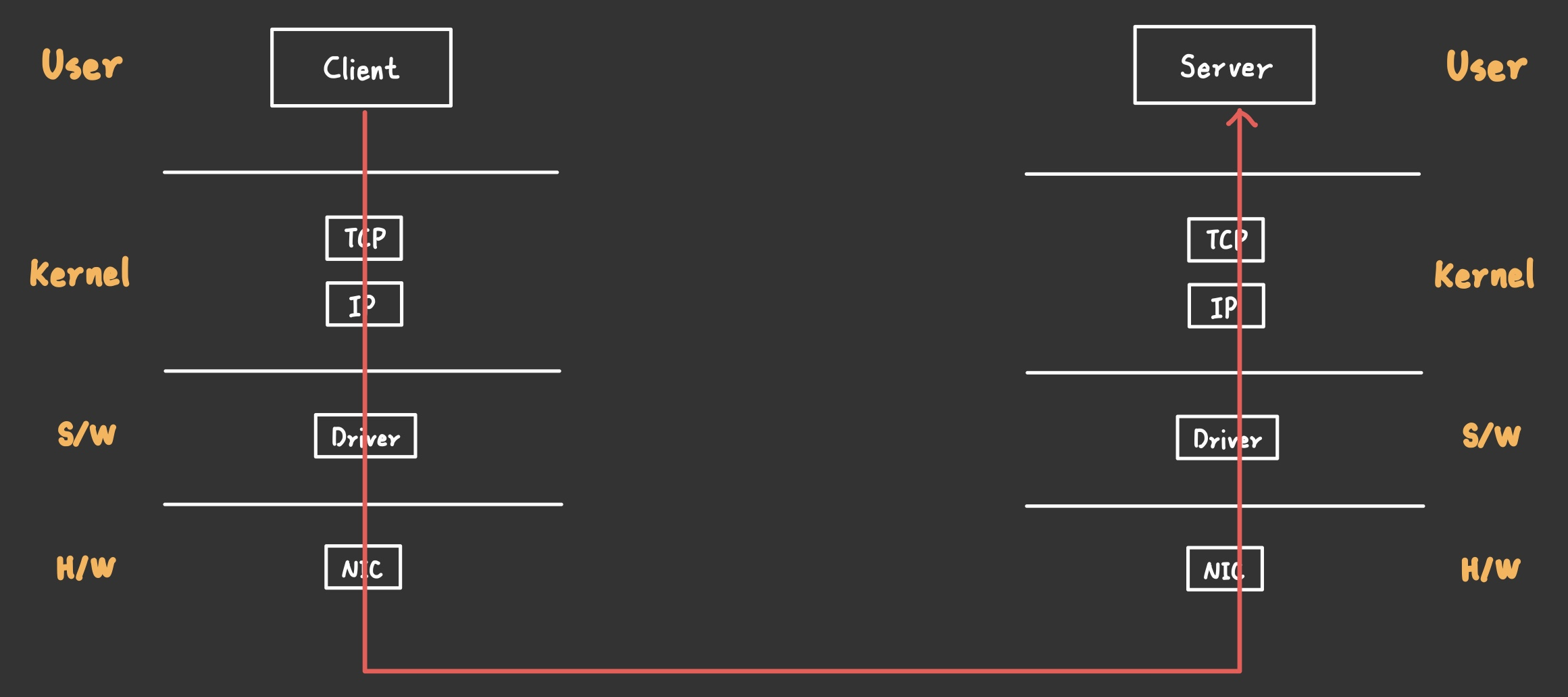
역할 분리 목적을 이해했다면 Client의 Request가 Server로 가기 위해서 어떤 흐름으로 가야하는지 이해했을 것이다.
Client의 NIC을 거쳐 Server의 NIC에 도달하면 우선 편지 봉투를 뜯어야 한다.
즉, 송신 과정은 수신 과정의 역순으로 진행되며, 각 계층이 서로 소통하고 있다.
(Client의 Data Link Layer가 한 작업은 Server의 Data Link Layer만이 해석할 수 있다.)
4. TCP/IP 5 Layer 동작
클라이언트가 메시지를 송신하는 과정부터 살펴보자.
도메인 주소로 부터 IP 주소를 획득하는 DNS 관련 내용은 생략한다.
여기서는 IP주소를 이미 알아냈다는 가정 하에 진행된다.
1️⃣ Application Layer
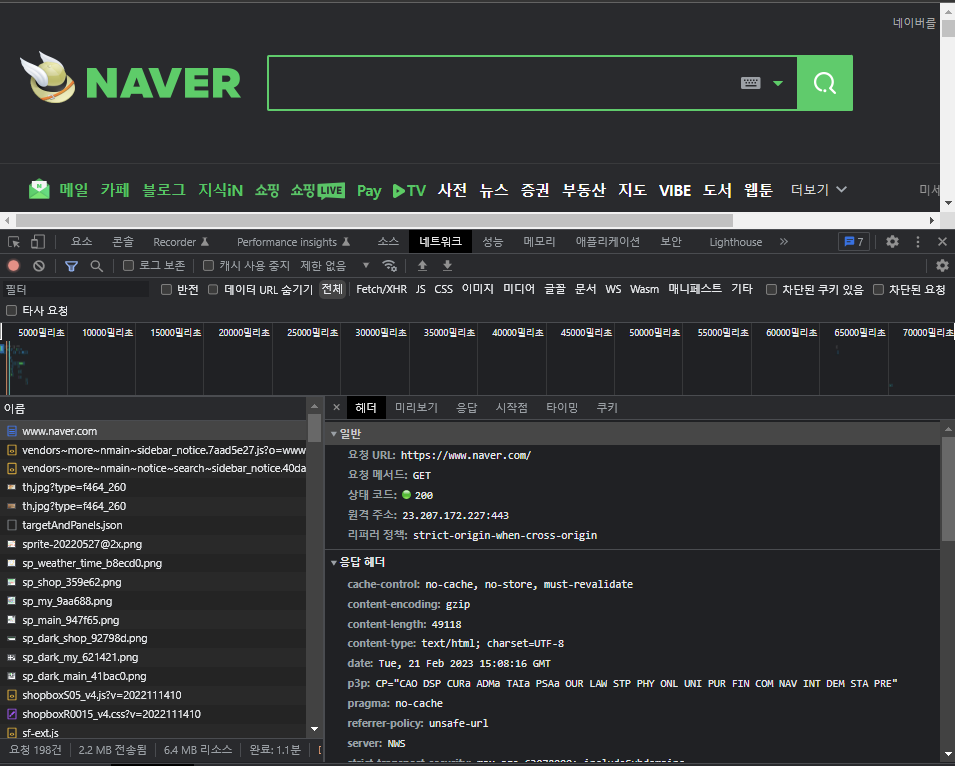
예시는 naver 포털 검색창에 "Hello, Naver"라는 검색어를 입력했을 때를 예시로 들 것이다.
우선 "Hello, Naver"라는 단어에 대한 결과를 조회하기 위해 서버로 문자열을 전송해야 한다.
그러기 위해서는 첫 번째로 네이버 서버와 클라이언트를 연결하는 작업이 필요하다.
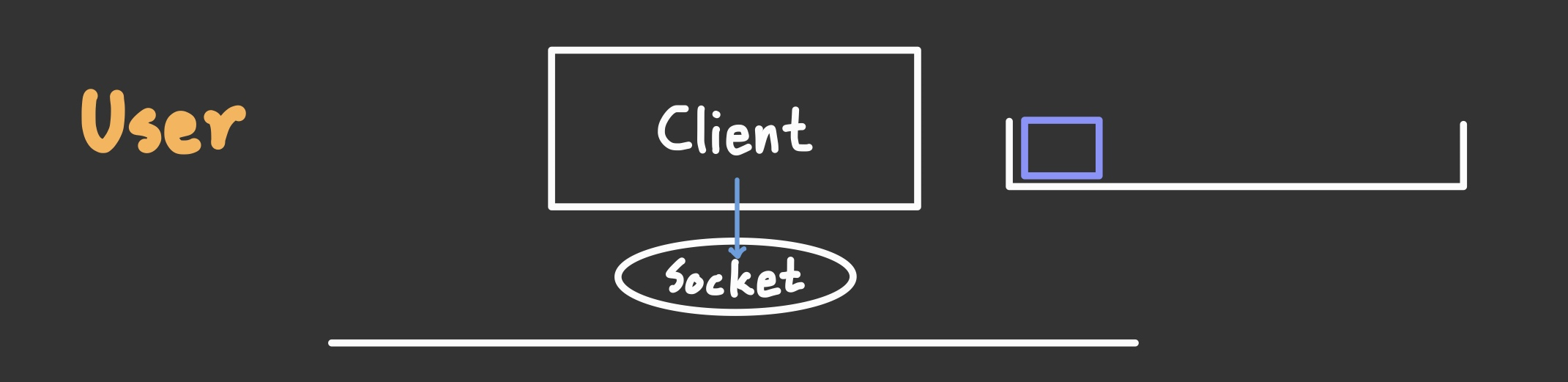
유저는 커널에 직접적인 접근이 불가능하다. (커널은 운영체제의 매우 핵심적인 부분이므로 잘못 접근했다가 손상이 되면 치명적인 에러가 발생할 수 있기 때문)
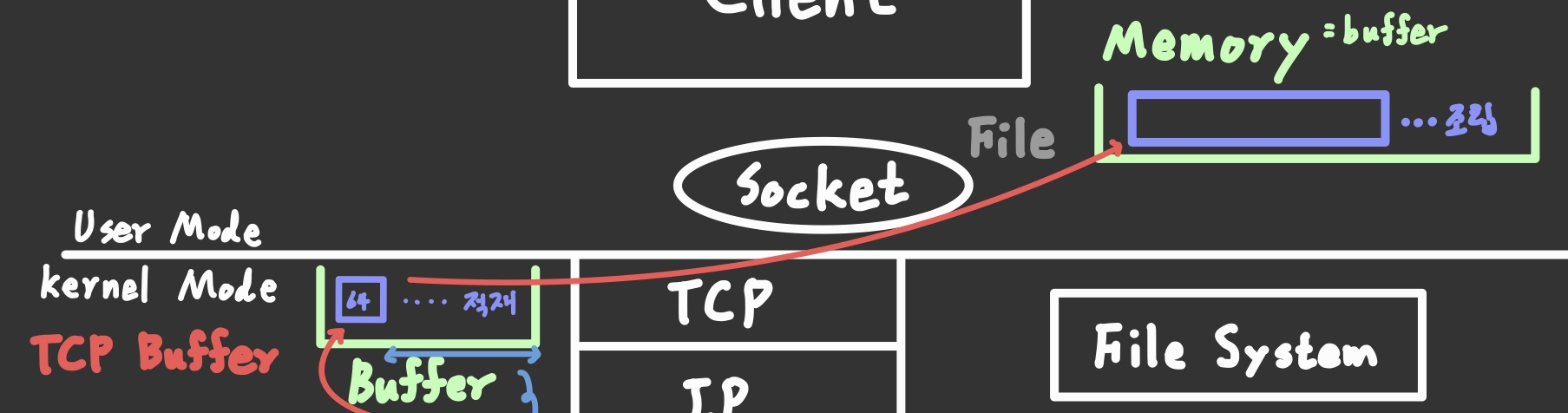
그래서 Socket 라이브러리의 socket 함수를 호출하여 IP주소와 TCP 프로토콜 사용 정보(여기선 tcp를 사용하기로 했으므로) 등을 넘겨주면 소켓을 작성한다.
✒️ 구분을 위한용어 정리 • 소켓: 일종의 파일. 제어 정보가 기록되어 있다. • Socket: 라이브러리. 네트워크 통신을 위한 API를 제공하고, 다른 컴퓨터와 통신하기 위한 프로그램을 작성. • socket: Socket 라이브러리 안의 소켓 생성 함수
#include <sys/socket.h>
int socket(int domain, int type, int protocol);
작성된 소켓
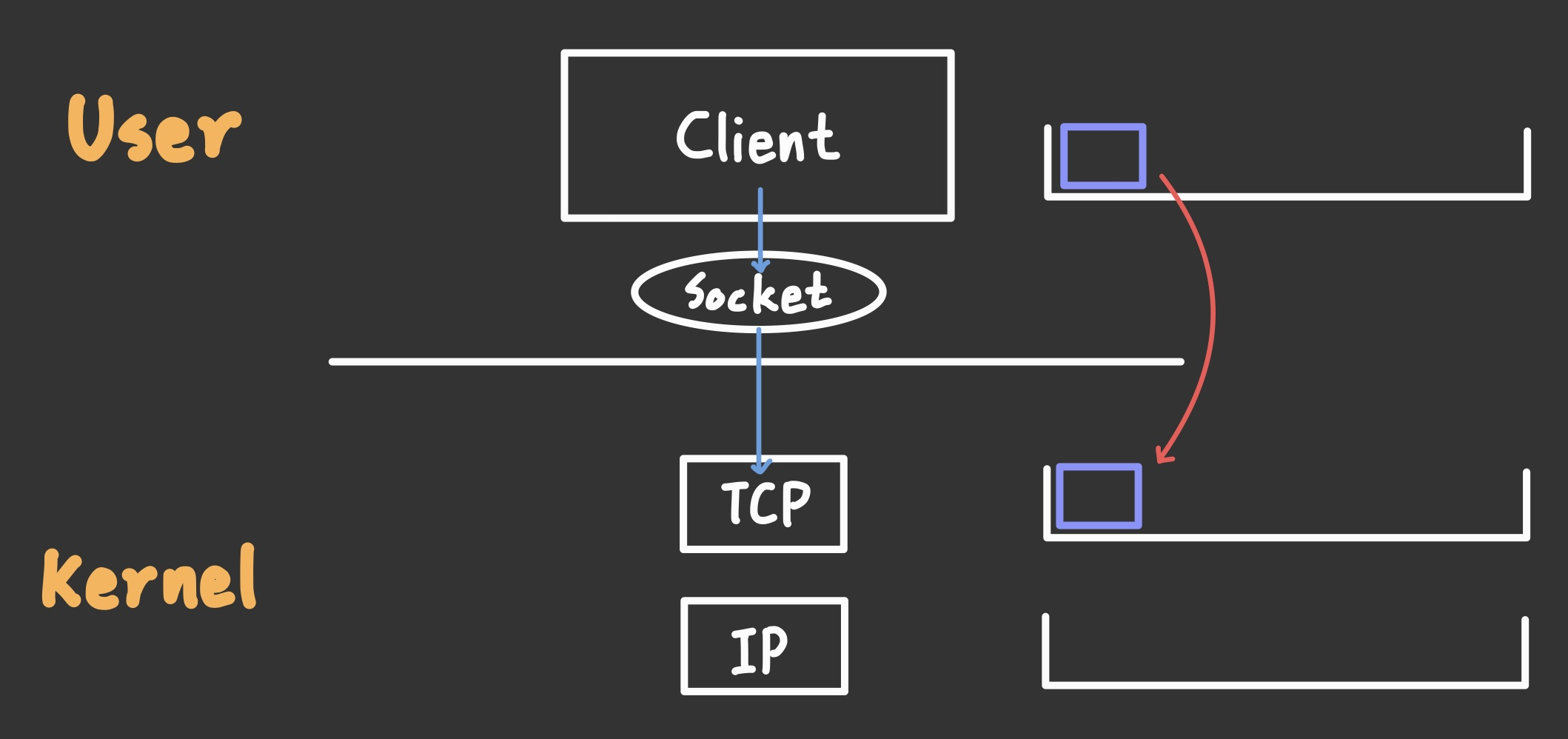
서버 측에서는 약속된 규정에 따라 포트를 열어놓고 포트와 매칭된 소켓을 열어놓고 대기하고 있기 때문에, Request payload를 보내기 전에 우선 소켓 정보를 서버와 일치시키는 작업이 필요하다. (이후에 깊게 다룰 예정)
여기서는 일단 어떻게 소켓을 잘 연결했다고 치고 메시지를 보내는 작업만 설명할 것이다.
우측의 ⨿ 모양은 버퍼를 의미한다.
소켓이 연결되면 서버 측과 정상적으로 송/수신이 가능한 상태가 되었으므로 "https Request message"를 작성하여 Kernel의 TCP에 넘긴다.
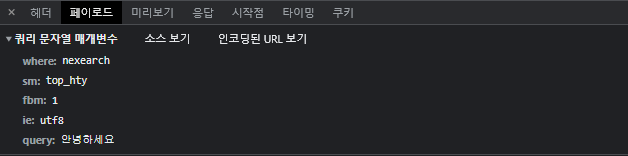
💻 실제 메시지 내용
query에 "안녕하세요"라는 문자열 정보가 넘어간다.
2️⃣ Transport Layer
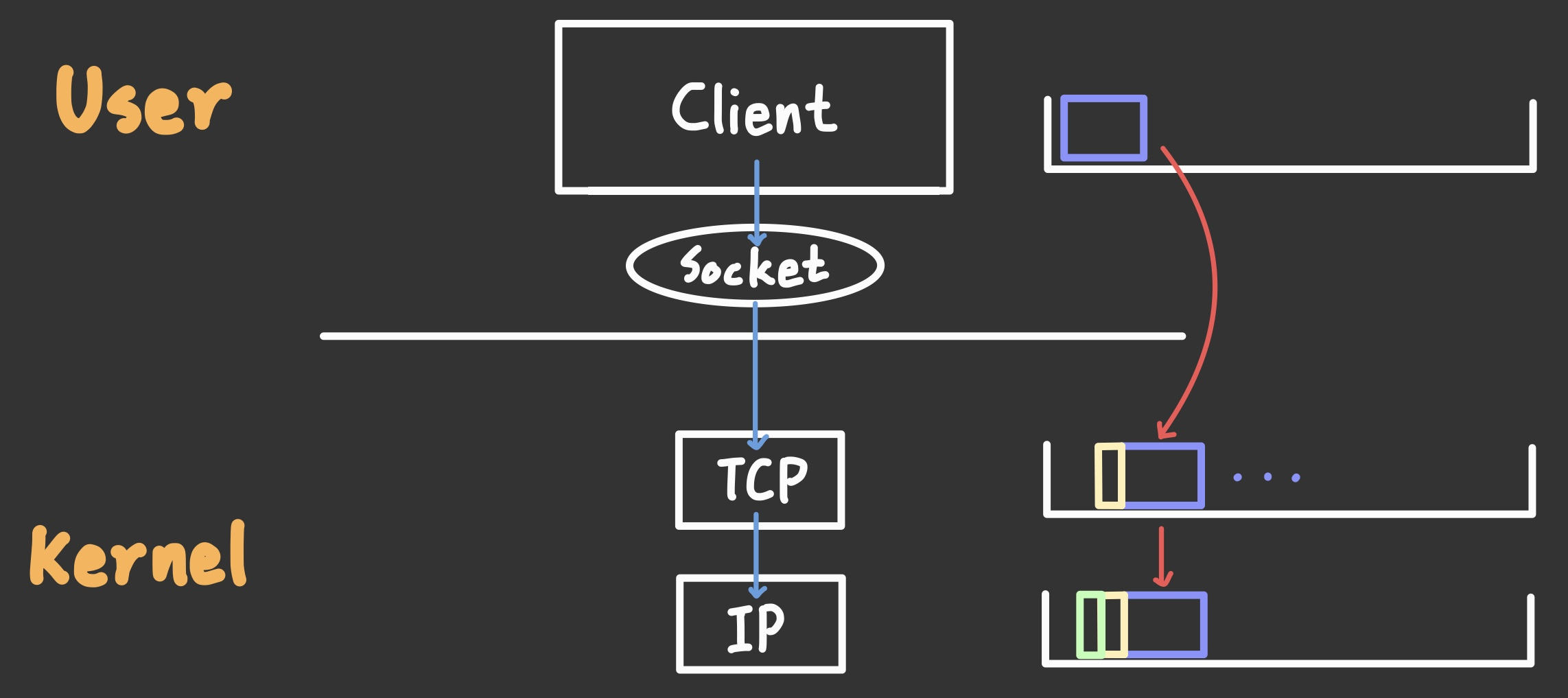
Client Memory에 있던 메시지가 TCP Memory에 적재가 되면, 이제 TCP는 상대 TCP와 대화하기 위한 헤더를 덧붙인다.
TCP 헤더는 소켓 제어 정보를 담는 것이 목적인데, 정보로는 송/수신처 각각의 포트 번호, 시퀀스 번호, ACK 번호 등을 보낸다. (모르겠으면 지금은 일단 "TCP끼리만의 정보가 필요하구나!" 정도로 넘어가시면 됩니다.)
계층이 내려갈 때마다 IP에서는 IP헤더를 붙이고 Data Link Layer에서는 Mac 헤더를 붙이는 식으로 이어지게 된다.
지금은 헤더에 어떤 정보가 담기느냐는 알 필요 없고, 계층이 내려갈 때마다 헤더가 붙고 반대로 수신동작에서는 헤더가 벗겨지는 걸 이해해도 충분하다.
이렇게 Message + TCP Header가 결합되면 여기서 부턴 Segment라고 부른다.
3️⃣ Network Layer
TCP에서 IP로 데이터를 내리면 마찬가지로 IP에서는 자신이 담당하고 있는 필요 정보를 IP 헤더로 덧붙인다.
(마찬가지로 지금 헤더 정보에 대해서 알 필요는 없다.)
Segment + IP 헤더가 붙으면 이제 Packet이라고 부른다.
이쯤에서 알고 넘어가면 좋은 개념이 있는데, 바로Fragmentation(조각 나누기)동작이다.
✒️Fragment
TCP에서 IP로 데이터를 내릴 때, 조각으로 분할하여 보내는 것이다. 데이터는 어찌됐건 케이블이나 무선 신호와 같은 물리적인 매개체를 거쳐야 하기 때문에 전송 가능한 최대/최소 크기가 정해져 있다. 만약, 서버에서 클라이언트로 방대한 양의 자원을 보내야 하는 경우 데이터를 작게 분할한다. (혹은 네트워크 환경에 따라서 의도적으로 데이터를 잘게 쪼개어 보내는 경우도 있다.) 잘게 쪼개진 데이터를 IP가 내려 받으면 각각의 조각에 IP 헤더를 붙이는데, 이때 붙는 헤더 정보는 모두 동일하다.
4️⃣ Data Link Layer & Physical
Packet을 전달받으면 해당 기기의 고유 주소인 Mac 주소와 one-hop만큼 떨어진 라우터의 Mac 주소와 관련된 정보를 담은 MAC 헤더를 덧붙여 Frame을 완성시킨다. (위에서 언급하면 용어가 혼동될까봐 언급하지 않았지만, 관용적으로 Segment, Frame을 모두 Packet이라 하는 경우가 있다. 문맥에 따라 Packet이 어느 계층의 데이터를 언급하는지 판단해야 할 수도 있다.)
one-hop만큼 떨어진 Router가 뭔지도 지금은 알 필요가 없다. 어차피 플로우만 알면 되니까.
이렇게 완성된 프레임을 물리적인 장치(케이블)로 보내기 위해서 전기 신호로 바꾸어 송신을 한다.
그런데 케이블은 아무래도 물리적인 요소다 보니 전기 신호가 이동하다가 열 손실 등으로 인해, 데이터가 손상되거나 사라질 수도 있다.
또한 전기 신호는 다른 기기와 겹쳐질 경우 충돌(Collision)이 발생할 수 있으므로 이를 중재할 중재자가 필요하다.
따라서 중간중간 허브나 라우터 같은 기기들이 신호를 전달받아 목적지까지 잘 도착할 수 있도록 전달하는 역할을 한다.
5. Summary
여기까지 읽은 사람이 있을까 싶긴 하지만 여튼 서두에서 언급했던 "개발자가 Network 지식을 알아야 하는 이유"에 대해서 아주 짧게 소개하고자 한다.
서버의 데이터 수신 과정은 클라이언트의 역과정이라고 생각하면 된다.
헤더를 보고 주소를 판단하고, 목적지가 내가 맞다면 데이터를 위 계층으로 올려보내 정상적으로 수신할 수 있도록 만들어야 하는 것이다.
문제는 여기서 발생한다.
수신 측이 데이터를 받는 속도는 Network 속도보다 언제나 빨라야 한다.
만약 패킷을 다시 조립하여 데이터를 재구성하는 과정에서 속도 차이가 발생해 Receive 속도가 느려진다면, 제때 수신되지 못한 패킷은 버려지고, 그로인하여 전체 전송 속도 또한 떨어지게 되기 때문이다.
또한, 패킷 재구성 시간이 오래 걸리게 되면, 패킷 일부가 유효하지 않은 데이터로 처리되어 버릴 수 있는데, 이 경우 전체 데이터의 무결성 문제로 이어질 수도 있다.
트래픽이 증가하여 서버 응답 속도가 지연된다면 개발자는 로우 레벨로 내려가 문제를 개선해야 하는 때가 올 것이다.
그 때 네트워크 지식을 알고 있는 개발자와 전혀 이해조차 못하고 코드만 짤 수 있는 개발자.
과연 실무에서는 어떤 인재를 원할까?
+ API 개발을 해보면 Port, IP 같은 기본적인 지식을 알아야 클라우드 배포가 가능하다.